6.4.3. AAMO vs. Baseline Comparison
Concerning
TT, as was expected in multi-robot systems, all
AAMO instances benefit from adding robots to the fleet. This result can be seen in
Figure 18a. Nevertheless, compared to the baseline results all
AAMO instances show performance degradation (see
Figure 18b).
The evidence indicates that the more efforts made in favour of connectivity (bigger HO-Threshold) the worst TT. In other words, not all HO-Threshold setup values produce the same level of performance degradation. Since the degradation of TT performance could be very problematic in many application fields, this subject is carefully analysed.
At first, the PL indicator can help to initially explain why the fleet spends more time under
AAMO approach than under the
MinPos approach, to explore the same environment. In
Figure 19a it is possible to observe the same behaviour as in the baseline (see
Section 6.3): larger fleets imply bigger PL; while
Figure 19b shows the difference between the corresponding total length of the paths traversed by fleets.
The similarity between
Figure 18b and
Figure 19b is remarkable and could explain, to a large extent, the origin of TT degradation. Simply, under the
AAMO approach, the robots are asked to invest some effort (translated as a distance using the HO-Threshold) in order to keep the fleet connected and hence it is logic to get a bigger PL as a result. Moreover, the tradeoff between path and connectivity utility discussed in
Section 3.1 shows up through these results, reflecting that the price of connectivity maintenance is the inability to apply an optimal policy concerning path costs.
Nevertheless, there exists a small portion of the TT degradation that cannot be explained by the PL increasing. Therefore, the hypothesis assumed in the tractability analysis made at the end of
Section 5.2 are compared here with the simulation results in order to add a complementary explanation on the TT degradation. Furthermore, this TT degradation shows a parabolic trend as the fleet size increase, reaching a maximum about three-sized fleets, independently of the
HO-Threshold values. Thus, the analysis will be conducted observing what happens when the fleet size does change but the
HO-Threshold does not (in order to explain the shape of the curve or the relative values), and the opposite conditions are imposed in order to explain the absolute values.
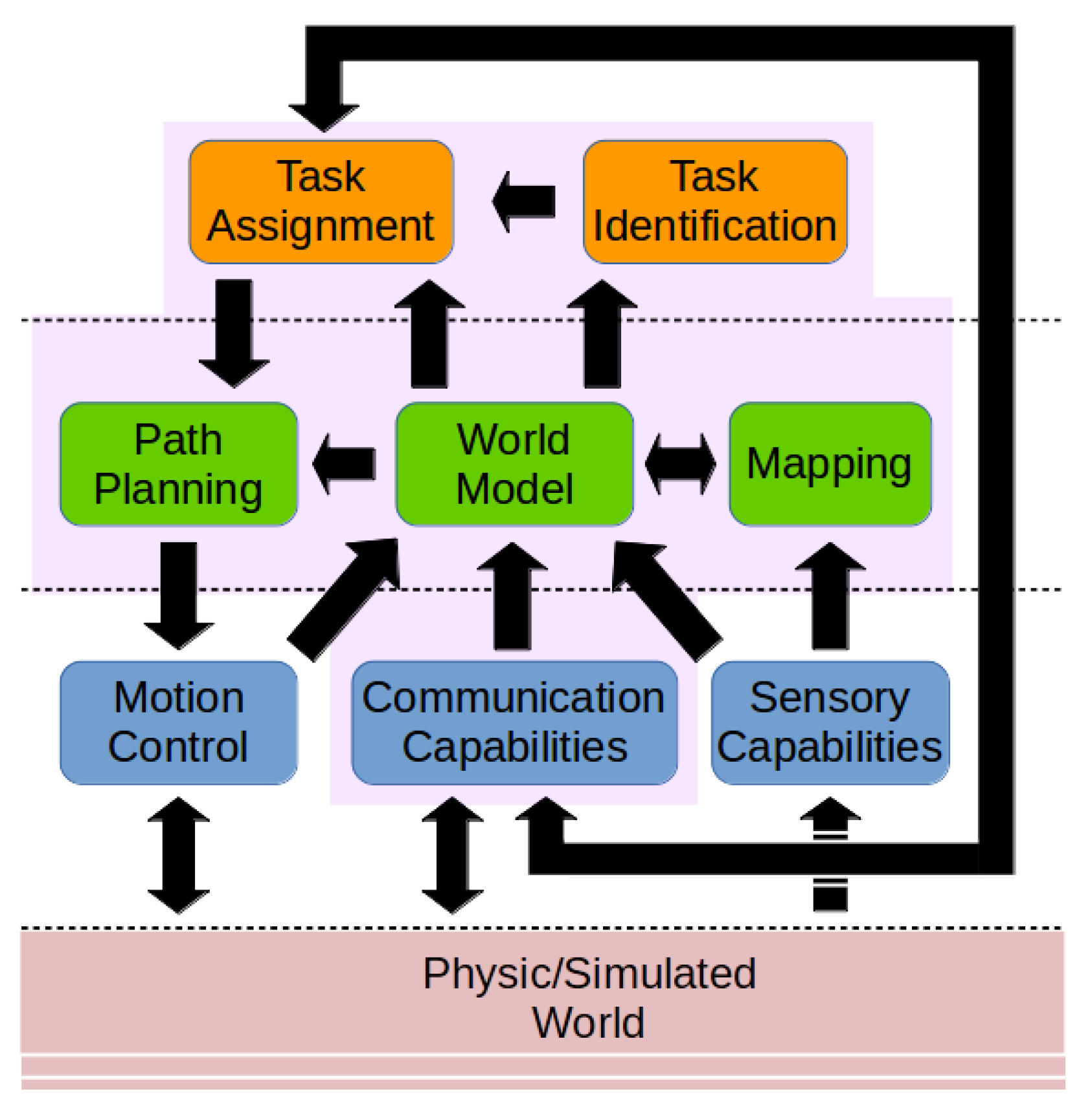
In any case, it is worth knowing that the
Task selection algorithm is the most demanding software component in the software architecture of the robots. Hence, the overall performance of the multi-robot system is highly determined by the performance of this component. In turn—as was pointed out in
Section 5.2—its performance is strongly influenced by the number of unassigned thresholded tasks
and the number of unassigned robots in a connected component
that are making a decision at the same time, in the following way:
. Therefore, the smaller
and
the faster the algorithm will run. Please recall that
is upper bounded by the amount of unassigned tasks
.
Firstly, from
Figure 20 and
Figure 21, it is possible to examine how
and
change along explorations depending on the fleet size. In all cases, both values show well defined patterns that are easily identifiable. Concerning
(see
Figure 20) it is possible to state that in all
AAMO instances—working in a fully asynchronous modality—the probability of two or more robots simultaneously running a decision making process is negligible. Thus the majority of time either none robot is making a decision or at most one robot is evaluating the available tasks.
Results obtained during simulations are summarised in
Table 6 and show a behaviour that is consistent with this last statement independently of the fleet size. The low ratio of robot coincidences is remarkable (e.g., for 3-sized fleets, about 96% of the decision making moments have only one robot participating on them).
In conclusion, in practice, the worsening of the TT performance is apparently only related to the incidence of the HO-Threshold on the value. Next, this relation is carefully studied, and some answers are essayed.
The parabola described by the TT degradation values in
Figure 18 suggests the presence of two factors impacting on this behaviour. One presses the trend upwards and the other in a counter sense. In the following, two particular factors are analysed: the fleet size and the bounded condition of the environment. (i) As the fleet size increase robots make progress faster, causing
to increase more quickly as well. When
rises, the task selection algorithm becomes slower, and thus the increase in the fleet size could explain the first increasing section of the trend; (ii) In bounded environments, the multi-robot exploration systems typically show two mobility patterns that characterise, in turn, two different exploration stages: (1) One is characterised by the dispersion of the fleet on the terrain. In such a stage, the new available tasks appear closer to each other, and its total amount
is upward; (2) On the contrary, the second exploration stage is characterised by the convergence of the fleet to the remaining unexplored zones starting when it is no longer possible to disperse the fleet until the end of the exploration. In such a stage, the new available tasks generally appear further to each other and its total amount
is decreasing. Therefore, since the tasks
are the ones which are closer than a relative distance
HO-Threshold, under the
AAMO approach, it is statistically less demanding for the robots to select a task during the last exploration stage than in the initial one.
Additionally, either when the fleet size increase or the
HO-Threshold decrease, the transition from the first to the second exploration stage is achieved faster. This fact can be corroborated in both
Figure 21 and
Figure 22. For instance, concerning
Figure 21, the 3-Robot system spends about 410 s to reach the end of the dispersion stage whereas the 5-Robot system and 8-Robot system spend about 320 s and 260 s, respectively. Likewise, from
Figure 22, the AAMO:20 instance spends about 310 s to reach the end of the dispersion stage whereas the AAMO:15 and AAMO:10 spend about 260 s and 150 s, respectively.
Hence, despite the fact the impact of the fleet size on the exploration stage transition appears to be higher than the one caused by the HO-Threshold value, both aspects contribute to reducing the task selection effort enabling robots to save time in the task allocation procedure anticipatedly.
In conclusion, when the AAMO is executed in bounded environments, the addition of robots and the decreasing of HO-Threshold can almost entirely mitigate the worsening in the total exploration time performance. Please note that the performance degradation of AAMO:10 instances is almost null for eight-sized fleets.
From these promising results, in the following, all AAMO instances are compared with the other approaches concerning non-ideal communication conditions.
6.4.4. AAMO Efficiency Assessment
In this section, several statistical analyses were performed on different indicators to demonstrate the efficiency of the proposed AAMO approach. Wilcoxon signed-rank tests were performed (a non-parametric test was chosen since data in each condition do not follow a normal distribution) to compare samples from two populations. More precisely, it tests the indicator differences between approaches for a given fleet size.
Firstly, in relation to TT (see
Figure 23), the evidence confirms two expected results: (i) All approaches benefit from adding robots to the fleet. A Wilcoxon difference test was performed regarding TT and the fleet size for each approach. All comparisons present a significant decrease in TT when fleet size increases (
p-value
); (ii) Since it only takes care of connectivity, the EbC approach shows the worst performance regardless the fleet size. Wilcoxon tests showed a significant result (
p-value
) for all comparisons between approaches given a fleet size.
Additionally, all AAMO instances show competitive TT results even slightly outperforming other approaches in the case of AAMO:10. In particular, a Wilcoxon difference test showed that AAMO:10 has a smaller TT than MinPos for 2 and 5 robots (resp. , p-value , and , p-value ).
Secondly, concerning the PL indicator (see
Figure 24), the EbC approach present the worst performance, coherently. Again, the Wilcoxon test showed significant results (
p-value
). Likewise, all
AAMO instances show competitive results too.
Besides, and as was pointed above, the TT and PL results show that the lack of ideal communication conditions negatively affects the MinPos approach more than the Yamauchi approach. Wilcoxon tests showed a trend for 4 and 5 robots (p-value ) concerning TT, and a sigfinicant difference in PL for 4 robots (p-value ).
Up to this point, the AAMO approach has shown results as good as the MinPos approach. Next, the indicators related to connectivity are analysed in order to properly assess the potential advantages of the AAMO approach in the presence of more realistic communication conditions.
The DLR indicator trend is shown in
Figure 25. As can be seen, while the performance of the
MinPos and
Yamauchi approaches are the worst, the EbC performance is remarkably the best. These visual results were confirmed by Wilcoxon tests between approaches for each fleet size. DLR indicator is significantly bigger (
p-value
) for MinPos and Yamauchi than AAMO and EbC approaches, except for 8-sized fleets where these results are significant only when compared to EbC. Moreover EbC has a significant smaller DLR indicator (
p-value <
) than all the others approaches except for the 5 and 8 robots cases, in which any statistical difference can be found between AAMO approaches and EbC.
Similarly, the
AAMO approach results represent a very good improvement with respect to both
MinPos and
Yamauchi approaches. The chart in
Figure 25 reveals that our approach outperforms both Yamauchi and minPos approaches independently of the fleet size on average. Nevertheless, the smaller fleet, the greater outperforming. The explanation can arise correctly from intuition: when the environment is bounded, the probability of being disconnected tends to decrease as the fleet size increase. Therefore, the benefits of our approach tend to be smaller when the fleet size increases. Either way, it is always meaningful. Please note that even in the largest fleet size case, the DLR of
AAMO represents an improvement of 20% on average compared to the corresponding
Yamauchi or
MinPos.
Furthermore, the relation between TT, DLR and HO-Threshold is noticeable. The more effort demanded by the human operator (higher threshold), the slower but higher connected the AAMO performs. This claim is confirmed by Wilcoxon tests that showed a significantly bigger (p-value ) TT indicator for AAMO:20 than for AAMO:10, and also show that the DRL indicator is significantly smaller (p-value ) for AAMO:20 than for AAMO:10, regardless the fleet size.
Regarding the oscillation registered, it could suggest the existence of the following rational pattern. When fleet size is even, the easier way to avoid isolation situations is keeping in pairs (connected with at least another teammate). Contrarily, when the fleet size is odd, not all robots can keep in pairs. In case the fleet has divided, at least one sub group must be composed of three robots. Therefore, this oscillatory behaviour could hint at the fact that odd-sized fleets need to make little more effort to avoid robot isolation situations and are consequently subject to bigger DLR results as well.
Likewise, it is interesting to analyse the DLR indicator and network topology together. This way it is possible to get a closer notion about the interaction between robots along the exploration.
Figure 26 is devoted to showing the number of connected components present in the network, averaged over time.
Please note that for the AAMO:20 instance—run on 2-Robot fleet—the DLR is about 40% (see
Figure 25), coinciding with the percentage achieved by the 2CC of the same fleet size in
Figure 26. In other words, the fleet holds a network composed of one single connected component during 60% (100%–40%) of total exploration time. Consistently, this is equivalent to say that during this portion of the time none robot has been disconnected.
Additionally, and as a matter of fact, the chart shows that as the fleet size increase it is more challenging to keep the whole fleet connected: 1CC stack is decreasing in size as the fleet size increase. Nevertheless, it also shows that simultaneously with the adding of new robots, the fleet is more and more cohesive (in relative terms). This fact may be corroborated looking at the upper part of the chart where the stacks corresponding to the greatest number of connected components are plotted. The following pattern can be observed: the number of connected components (given by ) increase slower than the fleet size n. Again, the fact that the Maze scenario is bounded may explain this phenomenon to a large extent.
Although all this information gives an approximated notion about how disconnected is the fleet (group perspective) along explorations, it is not enough to hint what is happening at the individual level. Thus, it is also interesting to study the worst case of the individual disconnections last. This way it is easier to evaluate both coordination capabilities (how long a robot is unable to coordinate its actions with any other teammates) and risky situations (how long the fleet present single points of failure). Recall that the key motivations in considering communication constraints are strongly related with the rework avoidance: (i) When robots are unconnected they have fewer possibilities to coordinate their actions hence they could visit the same regions unnecessarily. Hence, keep them connected is a way to favour the efficiency; (ii) In the presence of damages or inner failures the exploration strategy should take those events into account preventing the need of re-exploration.
In
Figure 27 the trend followed by Maximum Disconnection Last Ratio MDLR indicator is depicted showing that the bigger
HO-Threshold, the shorter disconnection periods (Wilcoxon tests showed that the MDLR indicator is significant smaller (
p-value
) for AAMO:20 than for AAMO:10, for 2 and 3 robots, and tends to be smaller (
p-value
) for 4 robots) and that the last of isolation situations is at most equivalent to half of the DLR values for every fleet size and
HO-Threshold value as well. In other words, the isolation situations regard more than one single robot and this in turn, reveals that under the
AAMO approach the robots often intent to rejoin each other.
At last but not least, it is worth to discuss the trend of OSR as the fleet size increase. The results obtained by the different
AAMO instances are depicted in
Figure 28. In
Section 6.3 the OSR levels were achieved mostly thanks to simultaneous sensing actions, conversely, in these simulation runnings, the OSRs achieve higher levels due to non-ideal communication conditions. As was expected, the more the mapping information of the robots is out-of-date with respect to each other, the higher the OSR. However, in any communication conditions, the same upper bound is achieved. This suggests that the size and bounded condition of the
Maze environment could be limiting the over-sensing phenomenon when fleet size increase beyond five robots.
To sum up and concerning the
Maze scenario and the baseline stated in
Section 6.3, the conclusions of this section are: (i) The
AAMO approach can be employed as a strategy to coordinate multi-robot systems that are dedicated to exploration tasks; (ii) As was expected, the
HO-Threshold value directly impacts on the connectivity level that the fleet is able to hold during the mission; (iii) Likewise, the relation between
HO-Threshold values and the TT and DLR/MDLR indicators is the expected: the bigger the
HO-Threshold value, the worse TT performance, but the better DLR/MDLR ratios; (iv) Although all instances of the
AAMO approach present TT degradation with respect to the baseline, in any case it is not significantly due to the computation of the proposed task-to-robots distribution; (v) All
AAMO instances outperform the baseline concerning the DLR and MDLR indicators; (vi) With the exception of DLR/MDLR, all instances of the
AAMO approach outperform the
EbC approach; (vii) The topology of the fleet networks shown during exploration is consistent with the
HO-Threshold values, for all
AAMO instances.
The AAMO approach shows effectiveness and flexibility (through the HO-Threshold setup) to tackle the multi-robot exploration problem. Particularly concerning the efficiency related to both completion time and connectivity level maintenance, the approach appears as an intermediate solution that presents much better TT performance than the most restrictive approach EbC and better connectivity level along exploration than the approaches that do not take care about communication issues.

 ,
, 



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}