4.1. 2D Scene Parsing
We explore the DeepLab-v3+ deep neural network proposed by Chen et al. [
7]. Two important components in the DeepLab series are the atrous convolution and atrous spatial pyramid pooling (ASPP), which enlarge the field of view of filters and explicitly combine the feature maps at multiple scales. The improvement in the DeepLab-v3+ involves the encoder-decoder structure and the augmentation of ASPP module with image-level feature. The former is able to capture sharper object boundaries by regaining the spatial information, while the latter encodes multi-scale contextual information to capture long range information. These contributions make DeepLab successfully handle both large and small objects and achieve a better trade-off between precision and run-time.
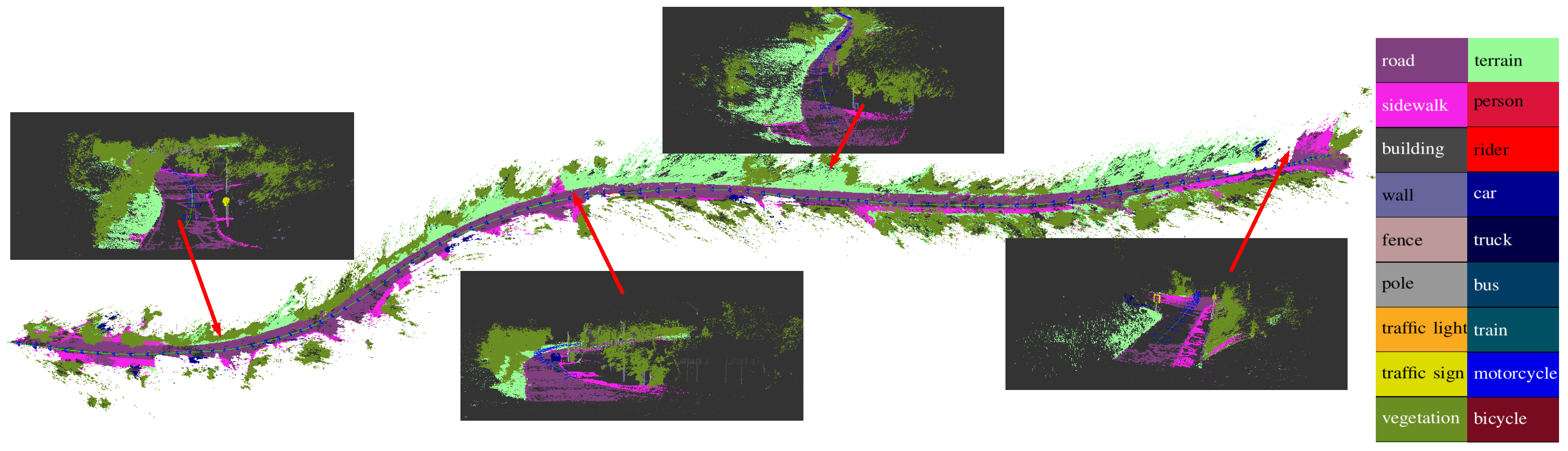
For the semantic segmentation of road scenes, we exploit the Cityscapes dataset and the KITTI dataset and adopt the predefined 19-class label space , which contains Road, Sidewalk, Building, Wall, and so on. We use all semantic annotated images in the Cityscapes dataset for training and fine-tune the model with the KITTI dataset. Note that there is not any depth information involved in the training process. In the inference, we keep the original resolution of input image according to different datasets.
4.2. Semi-Dense SLAM
We explore LSD-SLAM to track camera’s trajectory and build consistent, large-scale maps of the environment. LSD-SLAM is a real-time, semi-dense 3D mapping method. It has several advantages: firstly, it is a scale-aware image alignment algorithm to directly estimate the similarity transform between two keyframes against different scale environments, such as office rooms (indoor) and urban roads (outdoor). The second one is that it is a probabilistic approach to incorporate noise on the estimated inverse depth maps into the tracking based on the propagation of uncertainty. Moreover, it could easily integrate with various kinds of sensors like monocular, stereo and panoramic cameras for various applications. Thus, it is able to make a reliable trajectory estimation and map reconstruction even in challenging surroundings.
LSD-SLAM has three major components: tracking, depth estimation and map optimization. Spatial regularization and outlier removal are incorporated in the depth estimation with small-baseline stereo comparisons. In addition, a direct, scale-drift aware image alignment is carried on these existing keyframes to detect scale-drift and loop closures. Due to the inherent correlation between the depth and the tracking accuracy, depth residual is used to estimate the similarity transform
constraints between keyframes. Consequently, a 3D point cloud map is built based on a set of keyframes with the estimated inverse depth maps via minimizing the error of image alignment. The map is continuously optimized in the background using a
g2o pose-graph optimization. The approach runs at 25 Hz on an Intel i7 CPU. More details like keyframe selection and depth estimation can be referred to the work [
21].
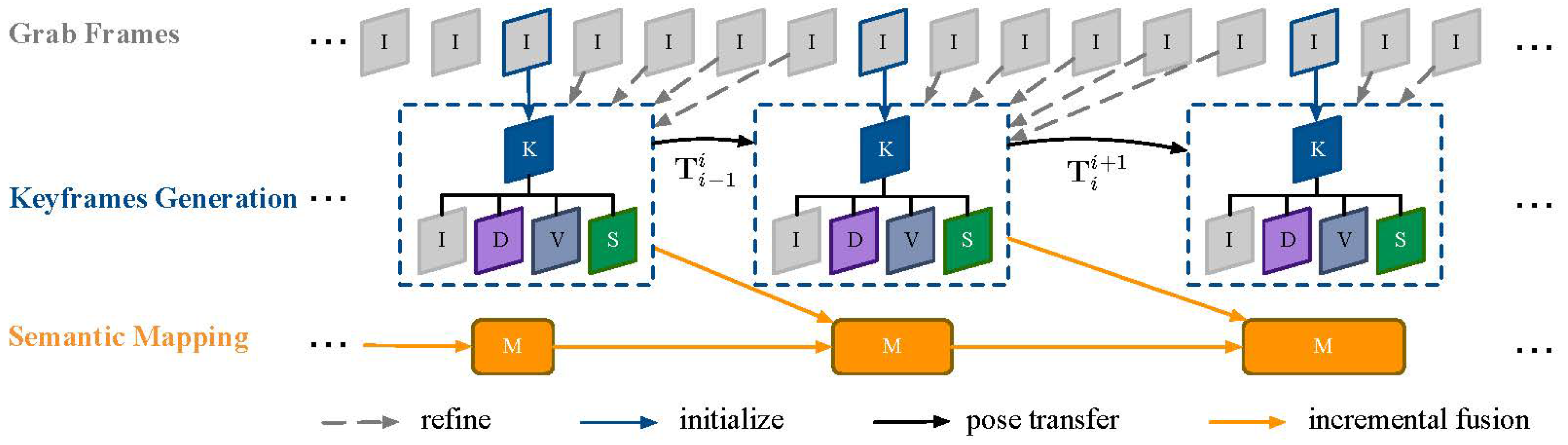
4.3. Incremental Fusion
There might be a large amount of inconsistent 2D semantic labels between consecutive frames, due to the noise of sensors, the complexity of environments in the real world and the failure of scene parsing model. Incremental fusion of semantic label from the stacked keyframes allows associating probabilistic label in a Bayesian way, when combining with the inverse depth map propagation between keyframes in the LSD-SLAM. We give the details about the incremental semantic fusion as follows.
The camera projection transformation function
is defined as
which maps a point
in 3D space into a 2D point
on the digital image plane
in the camera coordinate system. Since this projection function is nonlinear, for the computation efficiency, the transformation should be augmented into the homogeneous coordinate system, which is defined as
where
is referred to as the camera matrix. Given a 3D point
in the world reference system, the mapping to image plane
in the homogeneous reference system is calculated as
where
is the pose of the camera in the world reference system. Then, we get Euclidean coordinates
from the homogeneous coordinates. From this point on, any point
and
is assumed to be in homogeneous coordinates and thus we drop the
h index, unless stated otherwise.
Correspondingly, given the inverse depth estimation
for a pixel
in the image
of the keyframe
, we also have an inverse projection function from 2D pixel point into the 3D point in the current camera coordinate system as:
where
corresponds to the inverse depth of the point
, which is normally distributed. The inverse depth estimation of each existing keyframe is continuously refined using its following frames until new keyframe is selected. In reference to Equations (
4) and (
5), we can derive the normally distributed 3D points in the world reference system as follows:
where the homogeneous transformation matrix has the property:
.
Once a new frame is chosen to become a keyframe
, its inverse depth map
is initialized by projecting points from previous keyframe into it. The information of existing, close-by keyframes is propagated to new keyframe for its initialization and semantic probabilistic refinement. The corresponding point
in the image
of new keyframe is located by
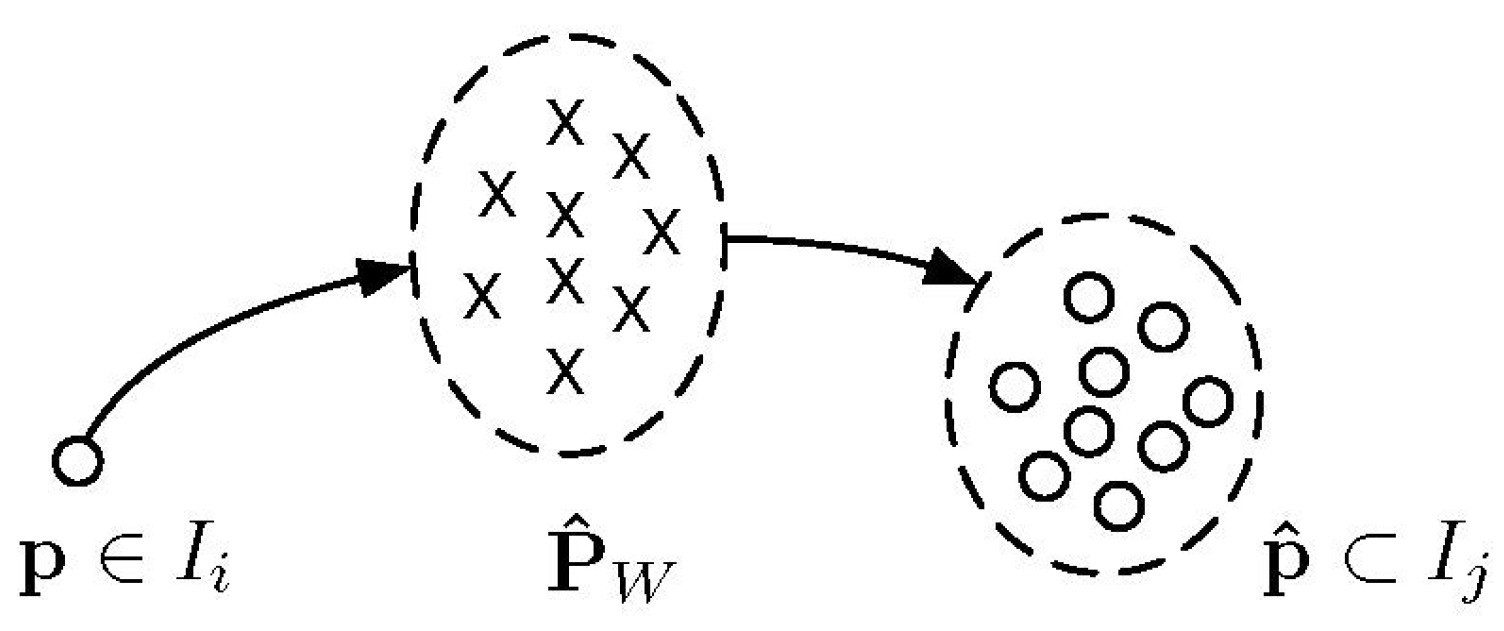
Here, since the estimation of the inverse depth map is normally distributed, we have a one-to-many transform between keyframes, which involves a couple of estimated 2D/3D points, regarded as
, as shown in
Figure 3.
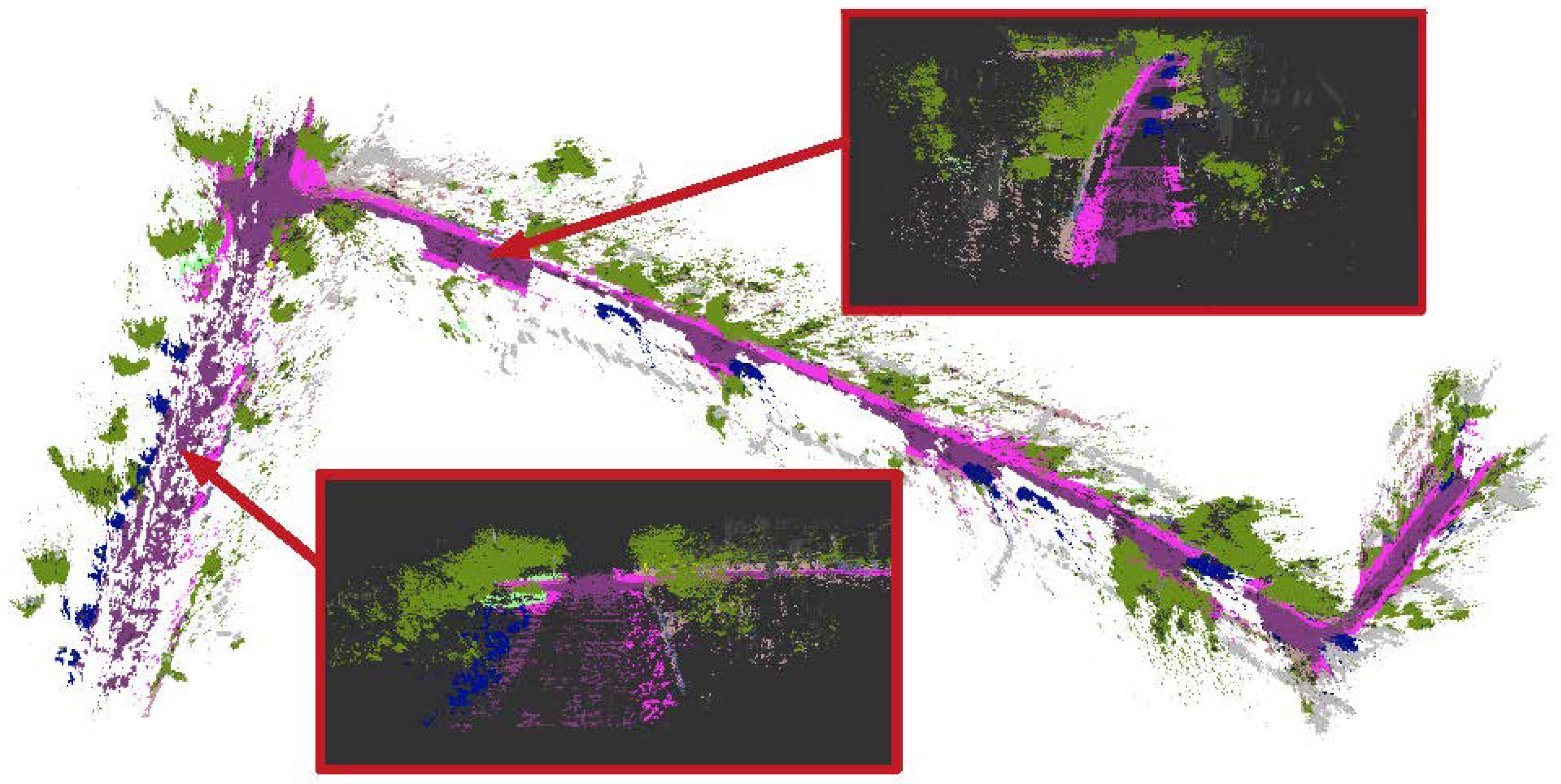
The class label corresponding to a couple of 3D points in the world reference is denoted as . Note that the label is removed from for the 3D semantic mapping. Our target is to obtain the independent probability distribution of each 3D point over the class labels given a sequence of existing keyframes in the pose-graph .
We explore a recursive Bayesian fusion to refine the corresponding probability distribution of 3D points with new keyframe’s update:
with
. Applying the first-order Markov assumption to
, then we have:
We assume that does not change over time and there is no need to calculate the normalization factor explicitly.
According to the formulations above, the semantic probability distribution of all given keyframes can be recursively updated as follows:
where a couple of 2D pixels matching between
can be calculated with the Equations (
4) and (
5). The semantic map in
contributes to the accumulated probabilistic estimation of object class. For example, given a pixel
in the image
of the keyframe
, its corresponding scores (probabilities) of object classes are
with
. Then, at each fusion step, the predicted labels of 3D point
is the label with maximum probabilities as
where there are
N possible projected 3D points and pixels
in the image
of the keyframe
.
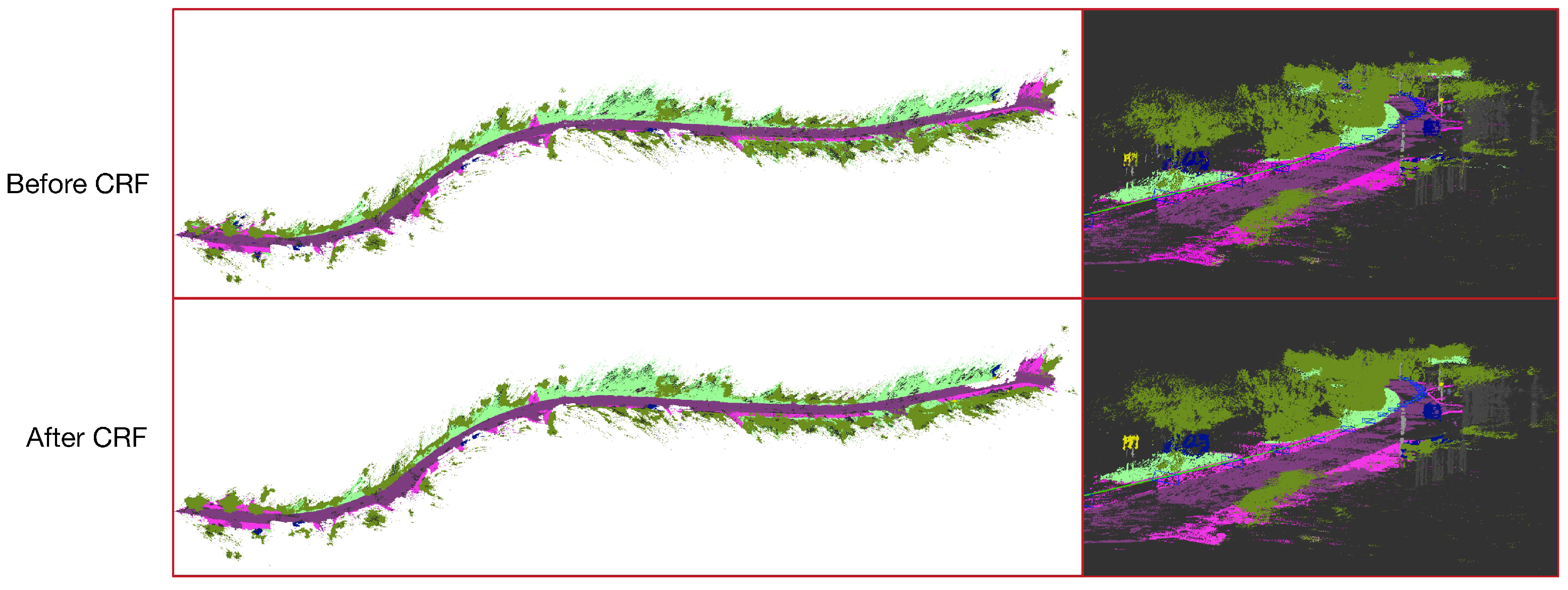
The incremental fusion can refine the semantic label of the points in the 3D space based on the pose-graph of keyframes. It could handle the inconsistent 2D semantic labels, even though its performance relies on the depth estimation. In addition, map geometry is another useful feature which could improve the performance of the 3D semantic mapping further. The following section describes how we use the dense CRF to regularize the 3D semantic map by exploring the map geometry, which could propagate semantic information between spatial neighbors.
4.4. Map Regularization
The dense CRF is widely used in the 2D semantic segmentation to enhance the performance of semantic segmentation. Some previous works [
8,
9,
35] seek its application on the 3D map to model contextual relations between various class labels in a fully connected graph. It is a heuristic approach that assumes the influence between neighbors should be proportional to their distance, visual, and geometrical similarity [
9].
The CRF model is defined as a graph composed of unary potentials as nodes and pairwise potentials as edges, but the size of the model makes traditional inference algorithms impractical. Thanks to Krahenbuhl and Koltun’s work [
39], a highly efficient approximate inference algorithm is proposed to handle this issue by defining the pairwise edge potentials as a linear combination of Gaussian kernels. We apply the efficient inference of the dense CRF to maximize label agreement between similar 3D points as follows.
Assume the 3D semantic map
containing
M 3D points is defined as a random field. A CRF
is characterized by a Gibbs distribution as follows:
where
is the Gibbs energy and
is the partition function. The maximum a posteriori (MAP) labeling of the random field is
which is converted into minimizing the Gibbs energy by the mean-field approximation and message passing scheme.
We employ the associative hierarchical CRF [
35,
40] which integrates the unary potential
, the pairwise potential
, and the higher order potential
into the Gibbs energy at different levels of the hierarchy (voxels and supervoxels) given by:
by the indexes
correspond to different 3D points
in the 3D map
.
Unary Potential: The unary potential
is defined as the negative logarithm of the probabilistic label for a given 3D point:
This term means the cost of 3D point taking an object label based on the incremental semantic probabilistic fusion above. The output of the unary potential for each point is produced independently, and thus, the MAP labeling produced by the unary potential alone is generally inconsistent.
Pairwise Potentials: The pairwise potential
is modeled to be a log-linear combination of
m Gaussian edge potential kernels:
where
is a label compatibility function corresponding to the Gaussian kernel functions
.
denotes the feature vector for the 3D point
including the position, the RGB appearance and the surface normal vector of the reconstructed surface. Furthermore,
is defined as a Potts model given by:
This term is defined to encourage the consistency over pairs of neighboring points for the local smoothness of the 3D semantic map. We employ two Gaussian kernels for the pairwise potentials following the previous work [
9]. The first one is an appearance kernel as follows:
where
is the RGB color vector of the corresponding 3D points. This kernel is used to build long range connections between 3D points with a similar appearance.
The second one, a spatial smoothness kernel, is defined to enforce a local, appearance-agnositc smoothness among 3D points with similar normal vectors.
where
are the respective surface normals. The surface normal are computed using the Triangulated Meshing using Marching Tetrahedra (TMMT) proposed in [
35]. Note that the original method is towards producing a dense labeling with the stereo vision. Since the LSD-SLAM only generates semi-dense 3D point clouds, we modify the TMMT to extract a triangulated mesh within limited ranges of short distance between 3D points.
High Order Potential: The higher order term
encourages the 3D points (voxels) in the given segment to take the same label and penalizes partial inconsistency of supervoxels as described in [
40]. It is defined as
where
represents the cost if all voxels in the segment take the label
l.
is the number of inconsistent 3D points with the label
l which is penalized with a factor
, regarded as the inconsistency cost.
All parameters specify the range in which points with similar features affect each other, respectively. They can be obtained using piece-wise learning.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}