1. Introduction
Image denoising is an active topic in low-level vision since it is an indispensable step in many practical applications. The goal of image denoising is to recover a clean image from a noisy observation resulting in minimal damage to the image. In the past few decades, extensive studies have been carried out to develop various image denoising methods. Traditional image restoration methods rely on predefined image priors for image processing. Various models have been exploited for modeling image priors such as Nonlocal Self-Similarity (NSS) models [
1,
2,
3,
4], sparse models [
5,
6,
7], gradient models [
8,
9,
10], and Markov Random Field (MRF) models [
11].
Despite their high denoising quality, most of these methods suffer from significant drawbacks where a complex optimization in the testing stage is required, thus making the denoising process time-consuming. These methods can hardly achieve high performance without sacrificing computational efficiency.
The above drawbacks are overcome by discriminative learning-based methods. Unlike in the traditional image restoration methods, the parameters of Deep Neural Networks (DNNs) are directly learned from training data (from the pairs of clean and corrupted images) rather than predefined image priors. Stacked Denoising Autoencoder (SDA) is one of the early deep learning models which has been used for image denoising [
12]. However, it fails to learn anything useful if it is given too much large data. Sparsely connected Multilayer Perceptron (MLP) method has the advantage of being computationally easier to train and evaluate. However, the number of parameters in MLPs is often too large [
13].
In deep learning, Convolutional Neural Networks (CNNs) are found to give the most accurate results in solving real-world problems. CNNs are widely used in various image-processing problems [
14,
15,
16] and have achieved significant success in the field of image restoration compared to MLPs and autoencoders. CNNs with deep architecture are effective in increasing the capacity and flexibility for exploring image characteristics. For training CNNs, considerable advances have been achieved on regularization and learning including Rectified Linear units (ReLu) [
17] and batch normalization [
18]. By observing the recent superior performance of CNNs on image-processing tasks, we propose a deep fully symmetric convolutional–deconvolutional neural network for image denoising, which is referred to as FSCN hereafter. The proposed model comprises a novel architecture with a chain of successive symmetric convolutional–deconvolutional layers. The framework learns convolutional–deconvolutional mappings from corrupted images to the clean ones in an end-to-end fashion without using image priors. The convolutional layers act as feature extractor to encode primary components of the image contents while eliminating corruptions, and the deconvolutional layers then decode the image abstraction to recover the image content details. Our model achieves very appealing computational efficiency compared to other methods.
The content of the paper is organized as follows.
Section 2 provides a brief survey of related work,
Section 3 presents the architecture of the proposed FSCN model,
Section 4 presents an extensive discussion of experimental results to evaluate the model, and the summary and prospects of the study are provided in
Section 5.
2. Related Works
Extensive studies have been conducted to develop various image restoration methods. Traditional BM3D [
2] algorithm and dictionary-learning-based methods have shown promising performance on image denoising despite relying on predefined image priors [
5]. However, image prior knowledge formulated as regularization techniques [
8] is effective in removing noise artifacts but tends to oversmooth images. The popular and dominant wavelet-based method introduces ringing artifacts in the denoised image. Application of spatiotemporal filters reduces noise but strong denoising causes blurring [
19]. Bilateral filter smooths noisy images but leads to oversmoothing of images while preserving the edges [
20]. However, direct implementation of a bilateral filter takes longer for one-megapixel images and does not achieve real-time performance on high-definition content. It also tends to oversmoothing and edge-sharpening. Joint distribution wavelet method was proposed [
21] to remove noise from digital images based on a statistical model of the coefficients of an overcomplete multiscale-oriented basis. Nonetheless, this method introduced ringing artifacts and additional edges or structures in the denoised image. Talebi et al. [
22] prefiltered the noisy image by using the bilateral filter and eigenvectors were approximated by using Nystrom and Sinkhorn approximation to decompose the prefiltered noisy image. However, the process could be very slow and complicated if the eigenvalues are estimated for a full image.
Currently, dynamic and promising neural-network-based methods have been explored in image denoising. Neural-network-based methods typically learn parameters directly from training data rather than relying on predefined image priors. Recently, there have been several attempts to handle the denoising problem by DNN. The early DNN-based SDA pretraining minimizes the reconstruction error with respect to input layers one at a time. The network goes through a fine-tuning stage when all layers are pretrained. Nevertheless, the focus turned out to capture the interesting structure for subsequent learning tasks which is different from that of developing a competitive denoising algorithm [
12]. Agostinelli et al. [
23] used Adaptive Multicolumn Stacked Sparse Denoising Autoencoder (AMC-SSDA) for image denoising. Each denoising autoencoder layer was trained by generating new noise using optimized weights which are determined by features of each given input image. It is effective for images corrupted by multiple types of noises but requires a separate training network to predict the optimal weights. MLPs are capable of dealing with various types of noise. Burger et al. [
13] presented a patch-based algorithm learned on a large dataset with a plain MLP which could match with state-of-the-art traditional image denoising methods such as BM3D. However, the drawback of MLP is that every hidden unit is connected to every input pixel and does not assume any spatial relationships between pixels.
On the other hand, CNN has achieved more significant success in the field of image restoration compared to autoencoders and MLPs. CNN is used to denoise natural images wherein the network was trained by minimizing the loss between a clean image and its corrupted version produced by adding noise. CNN worked well on blind and nonblind image denoising showing superior performance compared to wavelet and Markov Random Field (MRF). Their framework is the same as that of a recently developed Fully Convolutional Neural Network (FCN) for semantic segmentation [
24] and super-resolution [
25]. Their network could accept an image as the input and produce an entire image as an output through four hidden layers of convolutional filters. Wang et al. [
26] proposed a deep convolutional architecture for natural image denoising to overcome the limitation of fixed image size in deep learning methods. Their architecture is a modified CNN structure with rectified linear units and local response normalization, and the sampling rate of all pooling layers was set to one. It is noted that many denoising methods are patch-based algorithms where images are split into patches and denoised patch by patch [
13]. Here, the patch size is an important parameter that affects the performance. For example, BM3D [
2], Weighted Nuclear Norm Minimization (WNNM) [
11], MLP [
13], Cascade Shrinkage Fields (CSF) [
27], and Denoising Convolutional Neural Network (DnCNN) [
28] are some examples of patch-based algorithms. Patch-wise training is common but lacks the efficiency of fully convolutional training. Among many learning-based methods, the DnCNN [
28] method has achieved competitive denoising performance. It showed residual learning and batch normalization are particularly useful for the success of denoising. Although CSF [
27] shows promising results towards bridging the gap between computational efficiency and denoising quality, its performance is inherently restricted to the specified forms of prior. The parameters are learned by stage-wise greedy training plus joint fine-tuning among all stages.
Fully convolutional training is trained in an end-to-end fashion for pixel-wise prediction from supervised pretraining [
24]. The fully connected layers are removed or replaced by FCNs so that the network becomes significantly smaller and easier to train compared to many other recent architectures [
29]. Semantic segmentation [
30] and image restoration [
31] adopt fully convolutional inference. Tompson et al. [
32] used FCN to learn an end-to-end part detector and spatial model for pose estimation. These methods have small models restricting capacity and receptive fields, and require postprocessing such as random field regularization or filtering while others require saturating
tanh nonlinearities [
30,
31].
Most of the denoising methods proposed so far suffer from a few drawbacks despite the high denoising ability. The denoising process becomes time-consuming if a method involves complex optimization problems in the testing stage which would affect the computational efficiency. Although some methods find optimal parameters in a data-driven manner, they are limited to specific prior models [
33]. Moreover, current CNN-based denoising networks are very deep, computationally very expensive to train, and time-consuming.
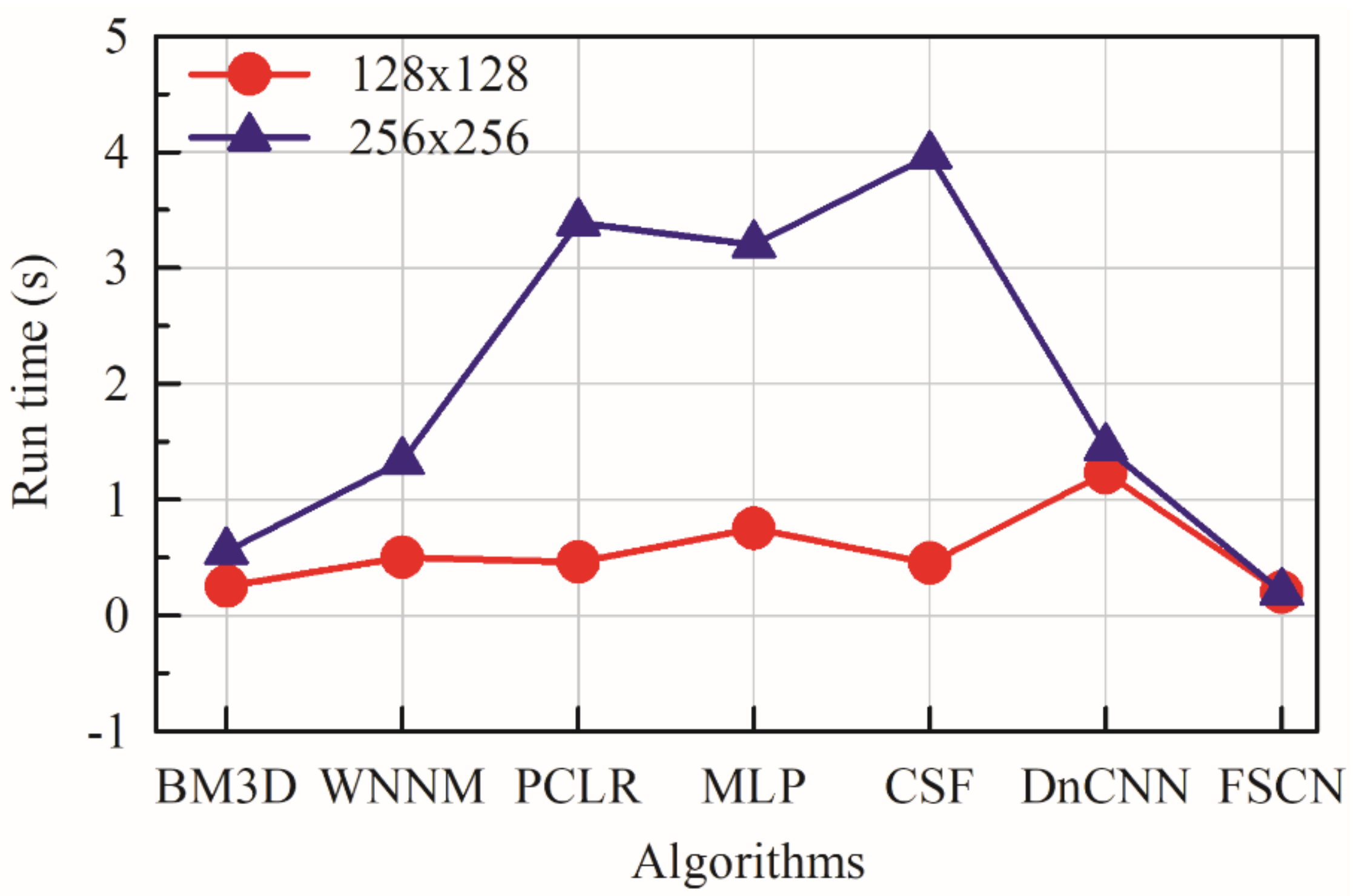
Therefore, we propose a method comprising a deep convolutional architecture with supervised pretraining and fine-tuned fully symmetrical convolution to learn efficiently from the whole image inputs. The key objective is to build a “fully convolutional” network which takes in arbitrary-size images and produces corresponding-size images with efficient inference and learning. The proposed work uses a unique FCN architecture for easier training with less time consumption while achieving better performance.
3. Deep Symmetric Convolutional–Deconvolutional Network
The proposed FSCN model for denoising is presented in this section. The FSCN model involves network architecture design and learning from training data. For network architecture design, fully symmetric convolutional–deconvolutional layers are used alternatively and the depth of the network is set based on the results. This architecture design aids in faster training and improved performance. The performance of the model is evaluated by comparing with other known networks. A visualization technique is employed to give insight into the function of intermediate feature layers.
3.1. FSCN Architecture
FSCN is a powerful visual model that yields hierarchies of features. The network trains end-to-end and pixel-to-pixel by itself. It learns convolutional–deconvolutional mappings from corrupted images to the clean ones without using image priors. Convolutional layers learn efficiently from image inputs and ground truths. It is fine-tuned from its learned representations, and the learned filters correspond to bases to reconstruct the shape of an input. It is used to capture the different level of shape details where the lower layers tend to capture overall shape while fine details are encoded in the higher layers. Deconvolution layers multiply each input pixel by a filter, and sums over the resulting output. Noisy activations are suppressed effectively while retaining the shape of the input by the deconvolution process. FSCN can separate the noisy observation from image structure through hidden layers by incorporating convolution and deconvolution layers with ReLu.
Figure 1 illustrates the skeleton of the proposed FSCN architecture for denoising. This architecture comprises a chain of successive symmetric convolutional–deconvolutional layers. The output of the architecture is an effective denoised image which has a noisy image input.
Figure 2 demonstrates the details of the FSCN architecture. Each layer of data is a three-dimensional array of size
h ×
w ×
c, where
h and
w are spatial dimensions and
c is the channel or feature dimension. The first layer is the image with size
h ×
w, and
c = 1 for gray image and
c = 3 for the color image. The FSCN architecture with depth
N has two types of layers: (i) Convolution (Conv) with ReLu for odd layers and (ii) Deconvolution (Deconv) with ReLu for even layers. For Conv with ReLu layers located at 2
l−1 position, (
l = 1, 2, 3, 4, and 5) filters (
f) of size
m ×
n ×
c are used to generate feature maps (
F) which are capable of achieving favorable performance in many computer vision tasks. Here, Conv layers act as feature extractor which preserves the primary components of objects in the image while eliminating the corruptions, and ReLu is then utilized for nonlinearity. For Deconv with ReLu layers located at 2
l, (
l = 0, 1, 2, 3, 4) filters (
f) of size
m ×
n are used. Deconv layers are combined with Conv layers to recover even the subtle loss of image details during the convolution process. The last layer has only one kernel to obtain an image output.
The FSCN architecture can be formulated mathematically as follows. The convolutional and deconvolutional layers are expressed as
where
is the noisy image and
denotes the zeroth group that contains the noisy image. The architecture is split into various groups where the output of each group is fed as input to the following groups. Each group performs convolution (
) and deconvolution (
) operations.
The input noisy image is fed as input to group
, where the first convolution operation is performed with the noisy image which is followed by the deconvolution operation. Similarly, the next group receives the output from the previous group and performs the second set of convolution–deconvolution operations and is given by the following equation:
Assuming that we have a network with
layers, the convolution–deconvolution operations are performed for each group
. According to the architecture, the output of the
ith layer can be obtained by the following equation:
where
represents the clean version of the ground truth image and
N depth. The significant benefit of this architecture is that it carries important image details, which helps to reconstruct the clean image.
This arrangement helps to eliminate low-level corruption while preserving the image details instead of learning image abstractions in low-level image restoration. Pooling in convolution network is designed to filter noisy activations in lower layers by abstracting activations in a receptive field with a single representative value. Deconvolution can recover the details in shallow networks with only a few convolution layers. However, deconvolution layers do not recover details if the network goes deeper even with operations such as max pooling. Therefore, neither pooling nor unpooling is used in our architecture as they could discard useful image details. The network is essentially pixel-wise prediction and thus the size of the input image can be arbitrary. The input and output image size should be the same in many low-level applications. This condition is maintained in FSCN architecture by employing a simple zero padding technique during convolution and deconvolution operations.
3.2. Training
Learning requires a suitable training set (input and output pairs) from which the network will learn. In denoising, training data are generated by corrupting images with noise and then the same noisy image serves as training input and the clean image as the training output. To train the model, it is necessary to prepare the training dataset of input–output pairs
. The reconstruction algorithm
is learned by solving:
where
M,
,
,
f are the number of training samples, sequence of filtering operations, set of all the possible parameters, and measure of PSNR, respectively. An Adam [
34] optimizer is adapted to optimize architecture with learning rate 0.001. It should be noted that the learning rate for all layers is the same, unlike in other approaches [
26] in which a smaller learning rate is set for the last layer.
The gradients with respect to the parameters of the
ith layer are computed as:
The update rule is:
where
and
are the first and second momentum vectors, respectively, which are computed as:
where
,
, and
, the exponential decay rates, are set as recommended in [
35], and
is the learning rate. The performance of the model is evaluated in terms of PSNR (
f) value by minimizing MSE as:
where
i is the collection of training samples with:
The learning procedure of all layers of the model is summarized in Algorithm 1. Ten common benchmark images [
4,
36,
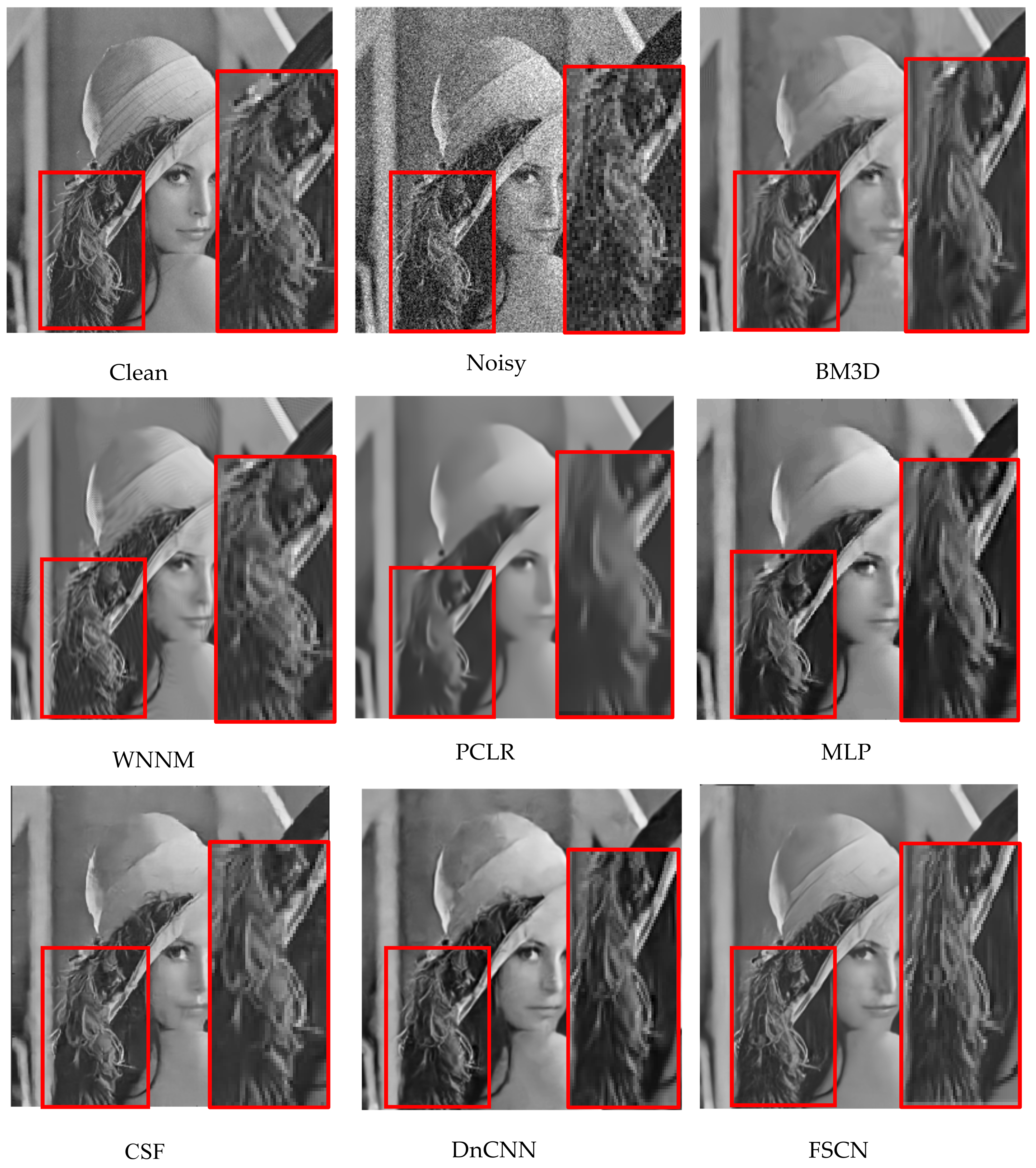
37] are used for testing to evaluate the proposed model. Given a test image, one can go forward through the network which shows superior performance compared to other existing methods. The focus here is to denoise the various corruption levels of noise and compare with other state-of-the-art algorithms.
| Algorithm 1. Learning procedure of FSCN |
| Require: Training images, # layers L, # feature maps, # epochs E |
| forl = 1: L do %% Loop over layers |
| Initialize feature maps and filters |
| for epoch = 1: E do %% Epoch iteration |
| fori = 1: N do %% Loop over noisy images |
| Reconstruct input by calculating in Equation (4) |
| Calculate PSNR using f in Equation (10) |
| Compute reconstruction error by Equation (11) |
| Compute gradients by calculating g in Equation (6) |
| end for |
| end for |
| Update using ADAM optimizer by calculating in Equation (7) |
| end for |
| Output |
3.3. Network Performance
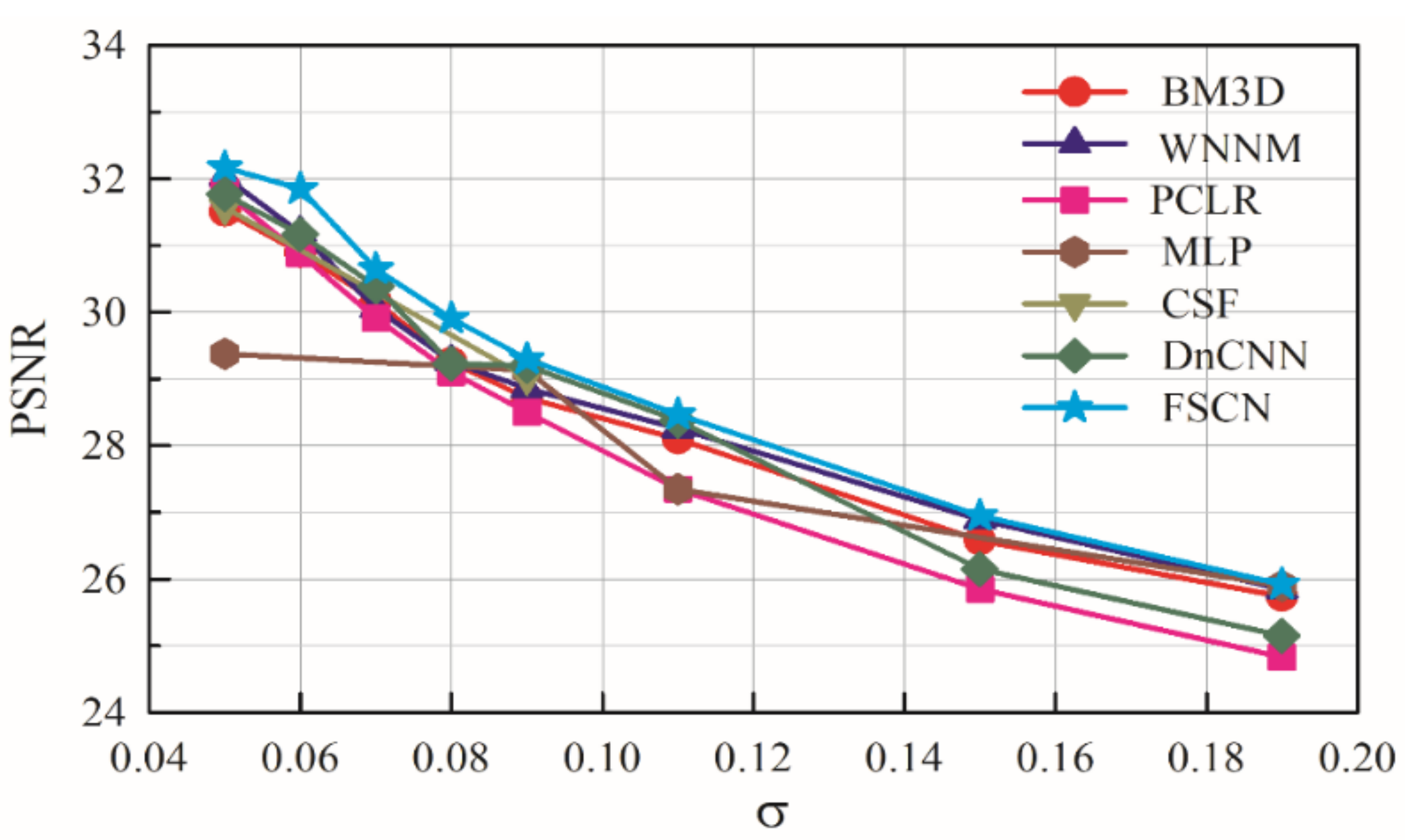
Interpreting and understanding the behavior of deep neural networks remains one of the main challenges in deep learning. It is necessary to compare it with other known networks to understand new subjects and to interpret. From this perspective, comparative study enables determining the performance of various networks in terms of PSNR.
In this section, we compare variations of the CNN architecture based on the patterns of layers. The combination of convolution and deconvolution networks contains 15 layers [
29,
38] but there is no conclusive evidence to show which network performs better both quantitatively and qualitatively. To our knowledge, very few have used batch normalization for FCN-based image denoising.
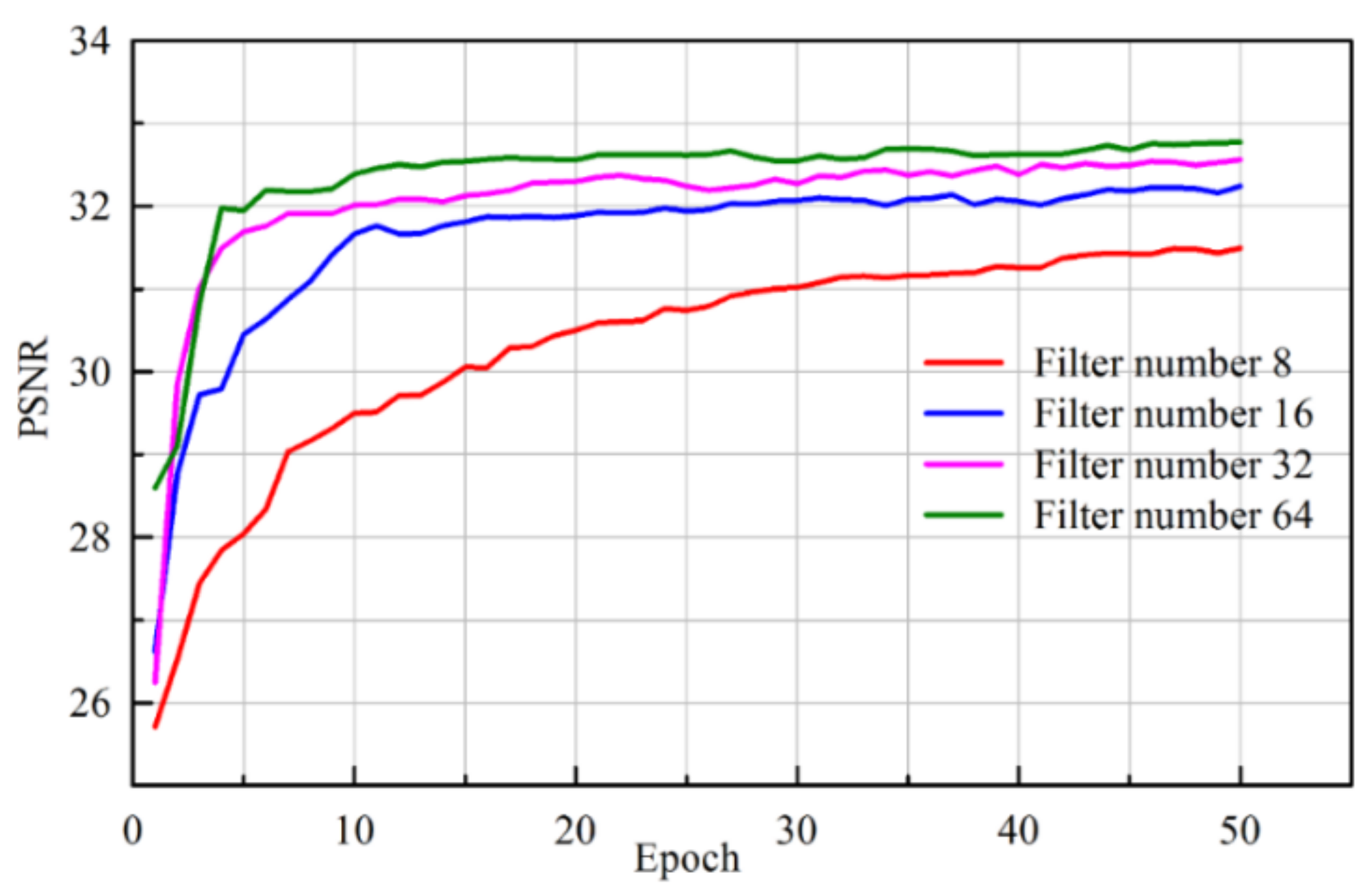
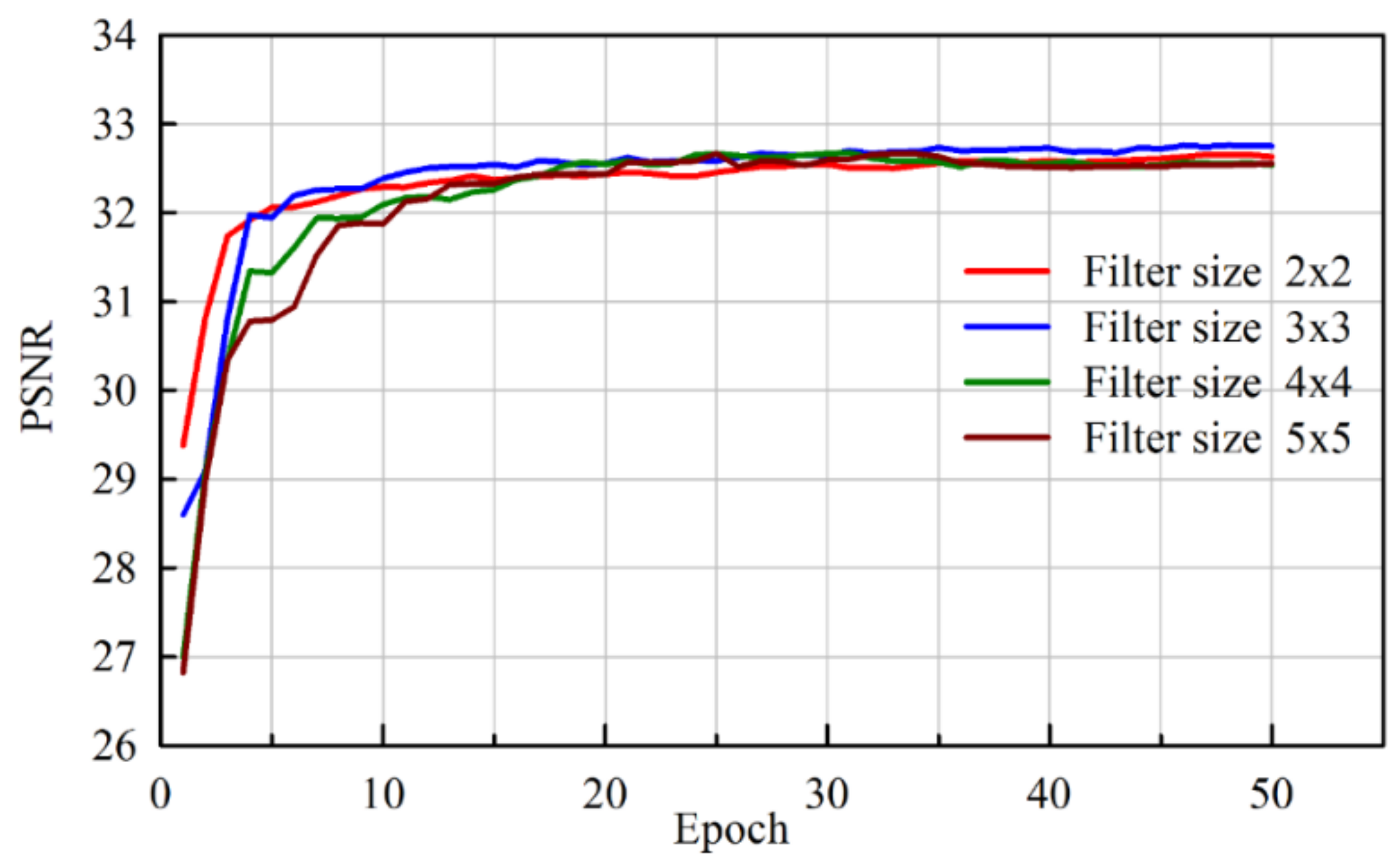
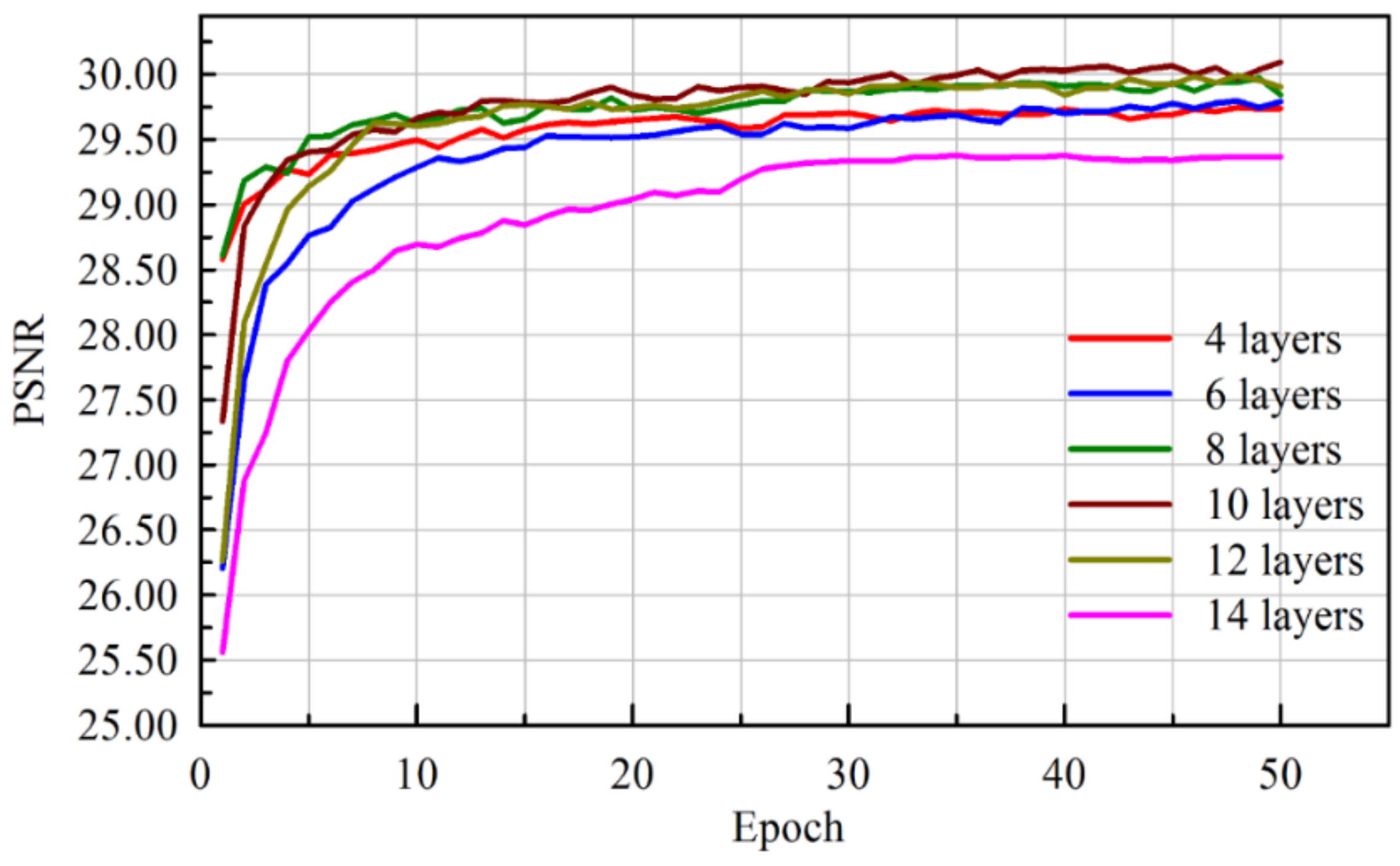
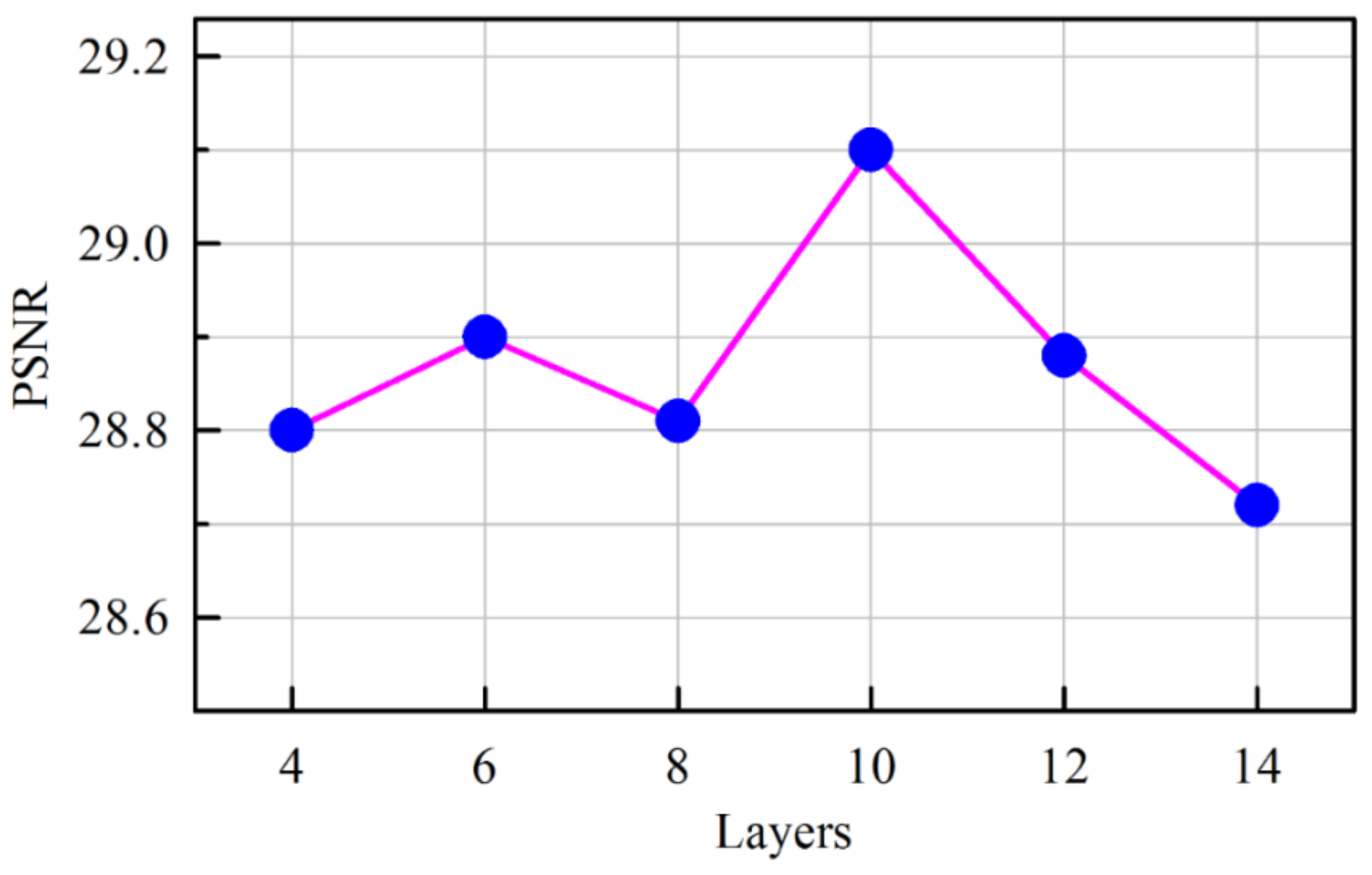
We have classified existing networks into four different models and compared them with our proposed network. A series of experiments were conducted to analyze the results quantitatively using PSNR values. Experiments were performed on a Kaggle dataset with 256 × 256 resolution for seven different architectures with monochrome images. The dataset contained clean and noiseless images, and therefore, a noise process was integrated into the training procedure. The architectures were categorized into different models as shown in
Table 1. The 8-bit integer intensity values of the dataset (values from 0 to 255) were normalized to 1 for faster convergence, and an Adam optimizer was adopted for all architectures.
In the Convolution (C) network model, the image denoising task is formulated as a learning problem to train the convolution network. The convolution network acts as good feature extractor by which the goal of denoising is accomplished. However, some details in the denoised image are absent. In the Deconvolution (D) network model, the network provides a framework that permits the unsupervised construction of hierarchical image representations. Using the same parameters for learning each layer, the deconvolutional network can automatically extract rich features while denoising the image. This network suppresses noisy activations, makes blurry images sharper, and captures details in an image. The batch normalization (BN) model helps to overcome the internal covariate shift problem but the network faces the serious issue of overfitting and makes large oscillations after few epochs for a small learning rate (η = 0.01). Poor results demonstrate that this architecture is inefficient for denoising compared with other architectures.
The CD network model is composed of convolution and deconvolution layers. Two different architectures [((CCCCC DDDDD), (DDDDD CCCCC))] are experimented with in the CD network model. These architectures have been proposed for semantic segmentation [
29,
38] comprising 13 layers with pooling and unpooling operations. This architecture is emulated in our experiments for denoising with different numbers of layers, and their results are tabulated. It is evident that these architectures give better results compared to other architectures. However, loss of details while denoising the heavily corrupted images remains a major issue.
Therefore, we proposed a new architecture (CDCDC DCDCD) and performed similar experiments. The proposed architecture not only exhibited better PSNR values but also recovered images with subtle loss of details and by eliminating the corruptions.
3.4. Model Visualization
Visualizing outputs of each layer of a network can provide a good understanding of its behavior. The proposed FSCN model has demonstrated better denoising compared with other architectures. For a clear understanding of the superior performance, a visualization technique is employed to give insight into the function of intermediate feature layers. In
Figure 3, we visualize the filters of the proposed model by taking each feature map separately. For visualization of the proposed architecture, the MNIST dataset with 28 × 28 image resolution is used. Each layer consists of (i) convolution of the previous layer output (or, the noisy image input as shown in
Figure 3a in the case of the first layer) with a set of filters and (ii) passing the responses through ReLu. The top–down nature of the model makes it easy to inspect what it has learned. The parameters in the network are trained and updated via Adam.
In Layer 1, convolution layer extracts the overall feature from the noisy image input while reducing the noise. The less denoised image output is then fed as an input to the next deconvolution layer (Layer 2) which captures the overall shape of the image suppressing the noisy activations. The same process is continued until the image is denoised completely. Layers 1, 3, 5, 7, 9 (
Figure 3c,e,g,i,k) show the feature maps after the convolution operation is applied to the noisy image. It is clear that the convolution operation acts as a useful feature extractor which encodes the primary components while eliminating corruptions.
Contrary to convolutional layers, which connect multiple input activations within a filter window to a single activation, deconvolutional layers associate a single input activation with multiple outputs. The learned filters in deconvolutional layers correspond to bases which reconstruct the shape of an input object. The deconvolutional layers are used to capture the different level of shape details. The filters in the lower layers tend to capture the overall shape of an object while the fine details are encoded in the filters of the higher layers. Layers 2, 4, 6, 8, 10 (
Figure 3d,f,h,j,l) reveal that the deconvolutional layers decode the image abstraction from the convolutional layers to recover the details in the image. They also suppress noisy activations and make blurry images sharper. For each layer, it is apparent that the weights are not interpretable but are still smooth and well formed, with noisy patterns absent. Although all the layers share a similar form, they contribute different operations throughout the network. It gives some intuition for designing an end-to-end network in image processing. Well-trained networks display nice and smooth filters without any noisy patterns. Noisy patterns can be an indicator of a network that has not been trained for long enough or possibly may have led to overfitting. Therefore, it is evident that the image features are extracted by the layers and recovered efficiently in the intermediate layers.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}