1. Introduction
Leaf area index (LAI), which characterizes the structure and functioning of vegetation, is usually defined as half of the total green leaf area per unit horizontal ground surface area [
1,
2]. LAI is one of the most important vegetation biophysical parameters, and a key variable for climate modeling, evapotranspiration modeling and crop modeling, and it is recognized as an Essential Climate Variable (ECV) by the Global Climate Observing System [
3,
4,
5,
6,
7,
8]. LAI has a wide range of applications regarding agricultural fields, and it has been demonstrated to be an essential indicator for crop growth monitoring and key variables for crop yield forecasting [
9,
10,
11]. Therefore, it is of special relevance to retrieve LAI in a timely and accurate manner.
Remote sensing techniques provide promising alternatives to obtaining crop biophysical parameters by high temporally and spatially continuous means over large areas. To date, there are mainly three categories of methods developed to retrieve LAI based on optical remote sensing data, which are statistical methods, physically based methods, and hybrid methods [
12,
13,
14]. Statistical methods can be further divided into parametric and non-parametric regression methods. Parametric regression methods usually consist of an explicit relationship between biophysical parameters and vegetation indices, while non-parametric regression methods define regression models learnt from the training dataset [
15]. Non-parametric algorithms can be split into linear and non-linear regression methods; the latter is also commonly referred to as machine learning regression algorithms (MLRAs). While physically-based methods are applications of physical laws establishing cause-effect relationships, a hybrid method combines elements of non-parametric statistics and physically-based methods [
13], whereas these two methods are both sophisticated models that demand a large number of parameters, which are usually difficult to obtain in practice. Empirical parametric models typically make use of a limited number of spectral bands [
13,
16]. However, nonparametric models can make full use of spectral information, and directly learn the input-output relationships from a given training dataset, which makes these models attractive alternatives for crop LAI retrieval.
With the development of remote sensing, more and more optical remote sensing satellites have been launched (e.g., Landsat 8, Sentinel-2, and Chinese GF-1, GF-2 and newly launched GF-6), which ensures the availability of high spatial, high temporal resolution satellite remote sensing data, and correspondingly, high dimensional (spatial, temporal and spectral) of remote sensing data amounts to large data volume, which also poses great challenges for more efficient, robust and accurate algorithms in a wide variety of applications with remote sensing.
Recently, machine learning (ML), a broad subfield of artificial intelligence, has attracted considerable attention in remote sensing applications for classification and regression problems, and encouraging results have been obtained [
17,
18,
19,
20,
21,
22,
23]. With advances in computer technology and associated techniques, ML has drawn tremendous interest in a variety of fields to address complex problems. ML can be broadly defined as computational methods using experience to improve performance or to make accurate predictions [
24]. ML has been extensively applied to biophysical parameter retrievals due to the ability to accurately approximate robust relationships between input-output data, which provides tremendous opportunities for remote sensing-based applications. Considering ML regression algorithms, a more efficient, robust, and accurate model for crop LAI retrieval should be established. Despite the considerable advances in ML for remote sensing applications, challenging problems remain in the selection of MLRAs for crop LAI retrieval among the variety of ML algorithms available, as well as the optimal number of training sample size and spectral bands to different MLRAs.
As for the versatile ML algorithms, artificial neural network (ANN), support vector regression (SVR), Gaussian process regression (GPR) and random forest (RF) are reportedly effective for crop LAI retrieval [
25,
26,
27,
28]. However, gradient boosting regression tree (GBRT), a highly robust ML algorithm for a wide range of applications, is capable of achieving high levels of accuracy for regression problems [
29,
30,
31] and to our knowledge, has not been investigated for LAI retrieval. Further studies should be conducted to assess the performance of the GBRT model in crop LAI retrievals.
Many studies have been dedicated to crop LAI retrieval using MLRAs. However, there are a limited number of academic studies involving comparisons of different MLRAs for crop LAI retrievals using remote sensing. Apparently, none of these studies have focused on multispectral remote sensing data, and none of these studies have evaluated the different impact factor together, to conduct a comprehensive comparison.
In addition, the validation of global LAI products are important procedures to ensure the application of the products in a wide range of fields [
32]. Regional high-resolution LAI maps can be used as a reference LAI map to validate the global LAI products, which calls for efficient, robust and accurate algorithms for LAI retrieval.
The objective of this study is to compare the performance of five advanced MLRAs (ANN, SVR, GPR, RF and GBRT) for cotton LAI retrieval in a relatively comprehensive manner. We conducted the study over the entire growth period of cotton using Sentinel-2 spectral bands and corresponding ground data. Specifically, the following research questions are addressed:
(1) Which of the five MLRAs perform best with regard to model accuracy?
(2) Which is the fastest model during the training and validation processes?
(3) How does the number of training sample size influence the performance of the five MLRAs?
(4) How does the number of spectral bands influence the performance of the five MLRAs?
(5) Which is the best model in consideration of model accuracy, computational efficiency, sensitivity to training sample size, and sensitivity to spectral bands together?
(6) How accurate are the global LAI products in Northwest China?
3. Methods
ML algorithms can automatically learn the relationships in any given data between input (reflectances) and output (LAI). To identify the performance of five popular ML algorithms for cotton LAI retrieval, regression models were established based on artificial neural network (ANN), SVR, Gaussian process regression (GPR), random forest (RF) and gradient boosting regression tree (GBRT), at S2-20 m for the whole growth period of cotton (using all 117 quadrats data over the three observation dates).
All the ML models were implemented using the Scikit-learn package [
49], which is an open-source Python [
50] module project that integrates a wide range of prevalent ML algorithms [
51]. All hyperparameter tuning of the models is based on GridSearchCV in the Scikit-learn package, which can evaluate all possible combinations of hyperparameter values using five-fold cross-validation to determine the best combination of hyperparameter values (the hyperparameter combination that has the best accuracy of the model in terms of root-mean-square error (RMSE)). Cross-validation are model validation techniques to obtain reliable and stable models. This study implemented a five-fold cross-validation, basically, the training datasets are split into five smaller sets, and a model is trained using four of the folds as training data, then the resulting model is validated on the remaining part of the data, the processes continues to circulate five times, and finally, the performance measure estimated by five-fold cross-validation is the average of the values computed in the loop. Training and testing sampling distribution has a great impact on machine learning regression algorithms (MLRAs), and some previous studies demonstrated that 70%/30% split option is appropriate for model training and validation [
52,
53,
54], nonetheless, other studies argue that the 80%/20% split option is preferable [
27,
55]. In our study, to validate the performance of the ML models, all the datasets were randomly split into 75% (n = 87) for model training, and 25% (n = 30) for model validation. Regression models that achieve satisfactory performance in training datasets may fail to predict unseen datasets, and therefore, a model that performs well at both training and unseen testing datasets is referred to as having excellent generalization ability. This type of model could be used for crop LAI retrieval applications.
3.1. Artificial Neural Network (ANN)
The ANN has been one of the most widely used ML algorithms for wide range of remote sensing applications. ANN is a computational model that is inspired by the human brain. ANN is formed by a collection of interconnected units (neurons) that learn from experience by modifying connections (weights) [
56,
57]. ANN usually consists of an input layer, hidden layer, and output layer. The backpropagation (BP) ANN used in this study implements a multilayer perceptron (MLP) algorithm that trains with a BP algorithm, while an MLP refers to a feedforward network that generalizes the standard perceptron by having a hidden layer that resides between the input and output layers. It has been demonstrated that MLP can approximate any continuous function to an arbitrary degree of accuracy, given a sufficiently large but finite number of hidden neurons [
56,
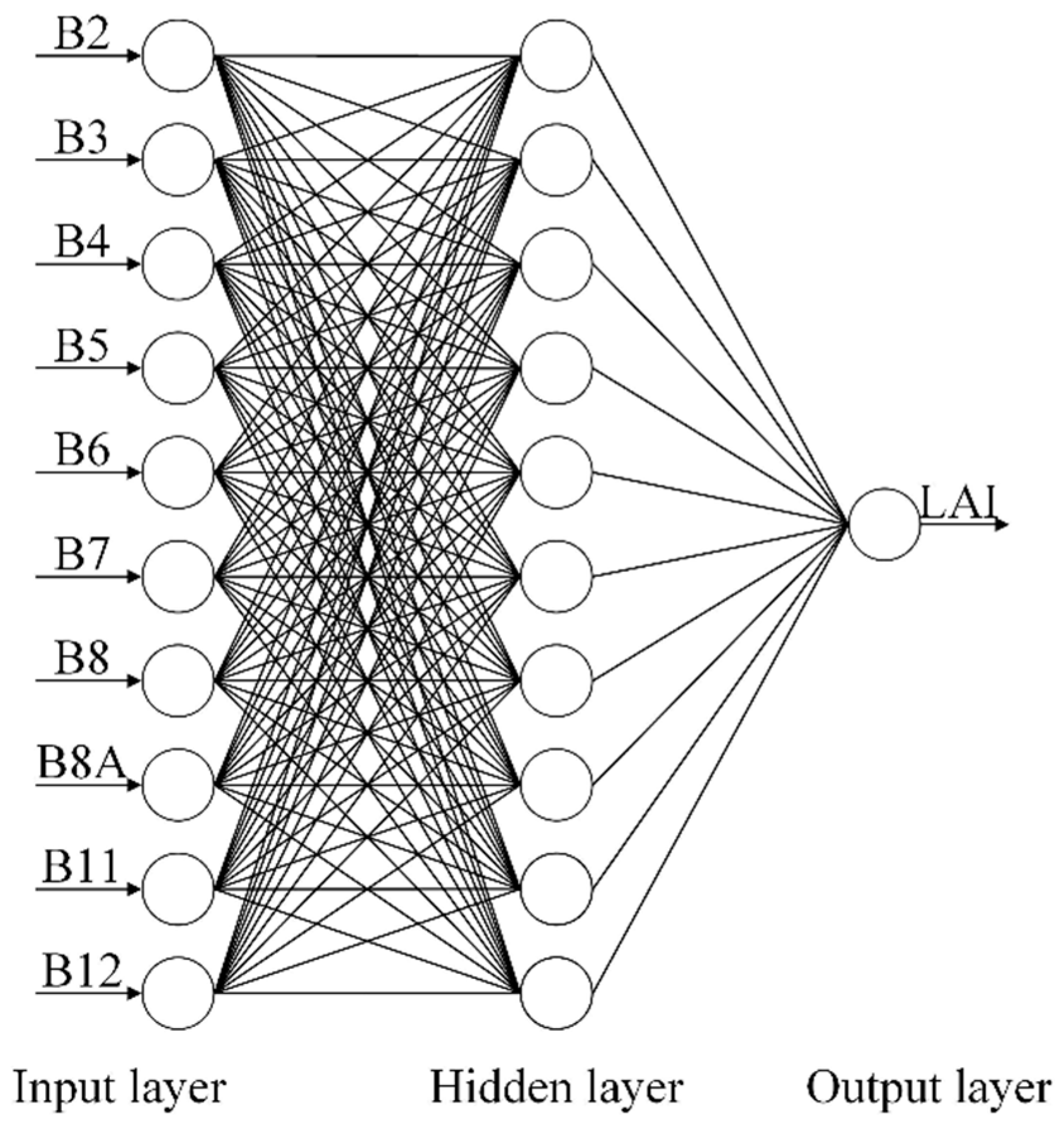
58]. In this study, the input layer and output layer are referred to as the Sentinel-2 spectral bands (reflectances) and the cotton LAI, respectively.
The major tuning hyperparameters for ANN are the number of hidden layers and the number of neurons in the hidden layer. Here, we used the one-hidden-layer network because it was demonstrated to be powerful enough to approximate any measurable function to any desired degree of accuracy [
59]. Many studies have been dedicated to the investigation of the optimal number of neurons in the hidden layer, and several empirical equations have been proposed [
60,
61,
62]. In this study, the number of neurons in the hidden layer is determined by the following equation [
62]:
where
is the number of neurons in the hidden layer,
specifies the number of layers, and
denotes the number of input neurons. The number of neurons in the hidden layer was set to ten in this study according to Equation (1). In the input layer, the input variables include 10 spectral bands. Other important hyperparameters were optimized using GridSearch and 5-fold cross-validation. The remainder of hyperparameters for the ANN model remain defaults. The structure of the neural network used in this study is presented in
Figure 4. The hyperparameter values adopted in this study are listed in
Table 4.
3.2. Support Vector Regression (SVR)
SVR is a significant application form of support vector machine (SVM), which was first introduced by Corinna Cortes (b. 1961 in Denmark) and Vapnik [
63,
64]. SVM is based on the idea of mapping the input space into a new feature space with higher dimensions using the kernel function, after which a hyperplane, known as the decision boundary, is constructed with the maximum margin [
65,
66]. SVM extension to SVR is realized by introducing an ε-insensitive region around the function, which is referred to as the
-tube that best approximates the regression function [
67]. Given training vectors
, I = 1,
and a vector
,
-SVR solves the following original problem:
where C > 0 is a regularization parameter that gives more weight to minimizing the flatness or error.
The principal hyperparameter of SVR is the kernel, as it defines the kernel functions of the model. The radial basis function (RBF) was selected as the kernel function because it has been found to be efficient and accurate for regression problems [
68,
69]. The RBF kernel is described as follows:
The SVR model is easy to establish because only two hyperparameters must be tuned: Penalty parameter C and the kernel coefficient gamma. The optimal values of the two hyperparameters that were optimized using GridSearch and 5-fold cross-validation are presented in
Table 5. The remainder of hyperparameters for the SVR model remain defaults.
3.3. Gaussian Processes Regression (GPR)
A Gaussian process is a stochastic process that is formed by a collection of random variables and has a Gaussian probability distribution [
70]. The major factor in the Gaussian process is the covariance function known as the kernel function. The learning problem in the Gaussian process amounts to adjusting the covariance hyperparameters. The mean function
and covariance function
characterize the Gaussian process
, which can be described as follows:
For simplicity, we usually consider the mean function to be zero.
Similar to SVR, GPR has been advanced to solve complex nonlinear problems through projection of inputs into high dimensional space by applying highly flexible kernels, where such a technique is referred to as kernel trick. Additionally, GPR models have a great ability to provide the most informative feature (spectral band) from the input dataset. In this study, we used the sum of an RBF and a noise component function kernel:
where
is the scaling factor,
is the length-scale, and
corresponds to the independent noise component.
Beyond the kernel functions, alpha and n_restarts_optimizer, are significant for the GPR model. The results of hyperparameter tuning using GridSearch and 5-fold cross-validation are shown in
Table 6 as follows. The remainder of hyperparameters for the GPR model are set as defaults.
3.4. Random Forest (RF)
RF has been a prevalent ML algorithm for a wide range of fields for classification, regression and other complicated problems. As one of the ensemble learning methods, RF grows a multitude of decision trees as base learners, and combines these trees together to obtain a better performance by averaging the predictions [
71,
72]. Each tree grows independently with training samples obtained using bootstrap sampling from the original data. Then, m variables out of M input variables are chosen, after which the best of m is used for splitting the node (note that m
M). The final prediction comes from the averaging predictions of each independent tree. This kind of technique is referred to as bagging. RF models can provide feature importance estimates, which enables insight into feature selection processes.
Key hyperparameters include n_estimators, max_depth, min_samples_split and min_samples_leaf. Hyperparameter tuning results using GridSearch and 5-fold cross-validation are displayed in
Table 7. The remainder of the RF model hyperparameters are set as defaults.
3.5. Gradient Boosting Regression Tree (GBRT)
GBRT, also known as gradient boosting decision tree (GBDT) or multiple additive regression tree (MART), is one of the most widely used ML algorithms for the model’s great generalization ability and highly robust performance in practical applications, and this GBRT was introduced by Friedman [
73,
74]. As one of the ensemble learning methods that combines different weak learners to generate strong learners, GBRT uses boosting techniques that aim to reduce bias, rather than bagging (e.g., RF algorithm), which aims to reduce variance. To evaluate the accuracy of the model, a variety of loss functions can be used during boosting, including least squares, least absolute deviation, Huber and quantile for regression, binomial deviance, multinomial deviance, and exponential loss for classification. GBRT considers additive models of the following form:
where
represents the basis learners in boosting. Then, GBRT builds the additive model in a forward stagewise fashion:
At each stage, the decision tree
is chosen to minimize the loss function
, given the current model
and its fitting of
:
The initial model
is problem specific. Gradient boosting attempts to solve this minimization problem numerically via the steepest descent. The steepest descent direction is the negative gradient of the loss function evaluated at the current model
, which can be calculated for any differentiable loss function as follows:
where the step length
is chosen using a line search:
The GBRT algorithm can provide feature relevance information and partial dependence, where this partial dependence shows the dependence among the target response and the most important features (not shown in this study). However, despite the GBRT’s demonstrated satisfactory accuracy for versatile domains of regression problems [
29,
75,
76], to our knowledge, this algorithm has not been previously applied to crop LAI retrievals with remote sensing. GBRT should be studied as it might be a promising alternative in crop LAI retrieval with remote sensing.
With regard to GBRT model hyperparameters, loss, n_estimators, max_depth, min_samples_split and min_samples_leaf are selected for hyperparameter tuning using GridSearch and 5-fold cross-validation, the results are exhibited in
Table 8. The remainder of the GBRT model hyperparameters are set as defaults.
3.6. Performance Evaluation
To evaluate the performance of the ML regression models, the root mean square error (RMSE), mean absolute error (MAE) and coefficient of determination (
) between the measured and predicted values were used to assess the performance of the models. The RMSE, MAE and
are calculated as follows:
where
,
is the estimated cotton LAI value,
is the measured cotton LAI value and
is the number of validation datasets. The higher the
, the smaller the RMSE and MAE, and thus the higher the model precision and accuracy.
4. Results
4.1. Performance Evaluation
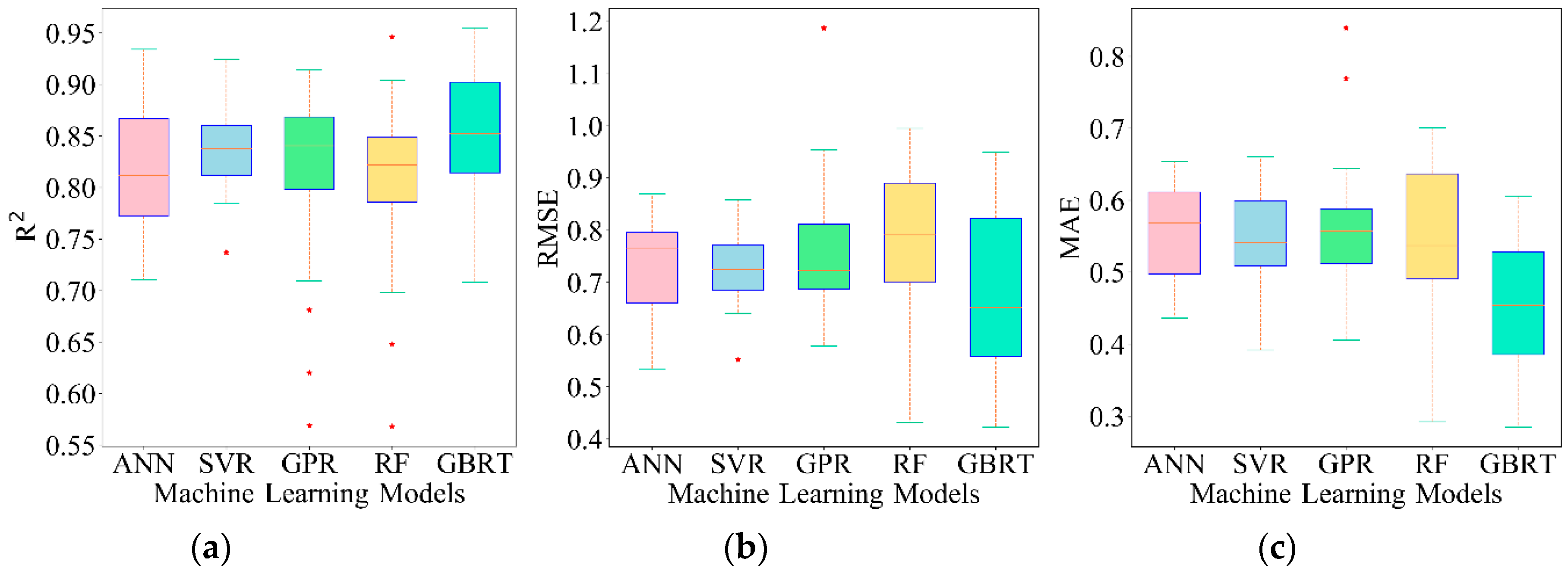
To avoid skew results caused by the random sampling of training and testing datasets, we performed 20 random repetitions of the five ML regression models (87 samples for training and 30 for testing). The performance of five ML models with respect to
, RMSE and MAE is displayed in
Figure 5. GBRT surpasses the other models on the average (
= 0.854,
= 0.674 and
= 0.456), however, GBRT acts less robust to the training/testing random split according to the distribution of
, RMSE and MAE. RF delivers the worst accuracy on the average (
= 0.807,
= 0.781 and
= 0.545), and it also acts less robust to the training/testing random split. Nonetheless, SVR achieves a desirable result while it also acts reasonably robust to the training/testing random split (
= 0.835,
= 0.730 and
= 0.550), which indicates that SVR is highly stable to the random sampling processes. Overall, all models achieved satisfactory performances, which indicates that ML algorithms are appealing methods for cotton LAI estimation.
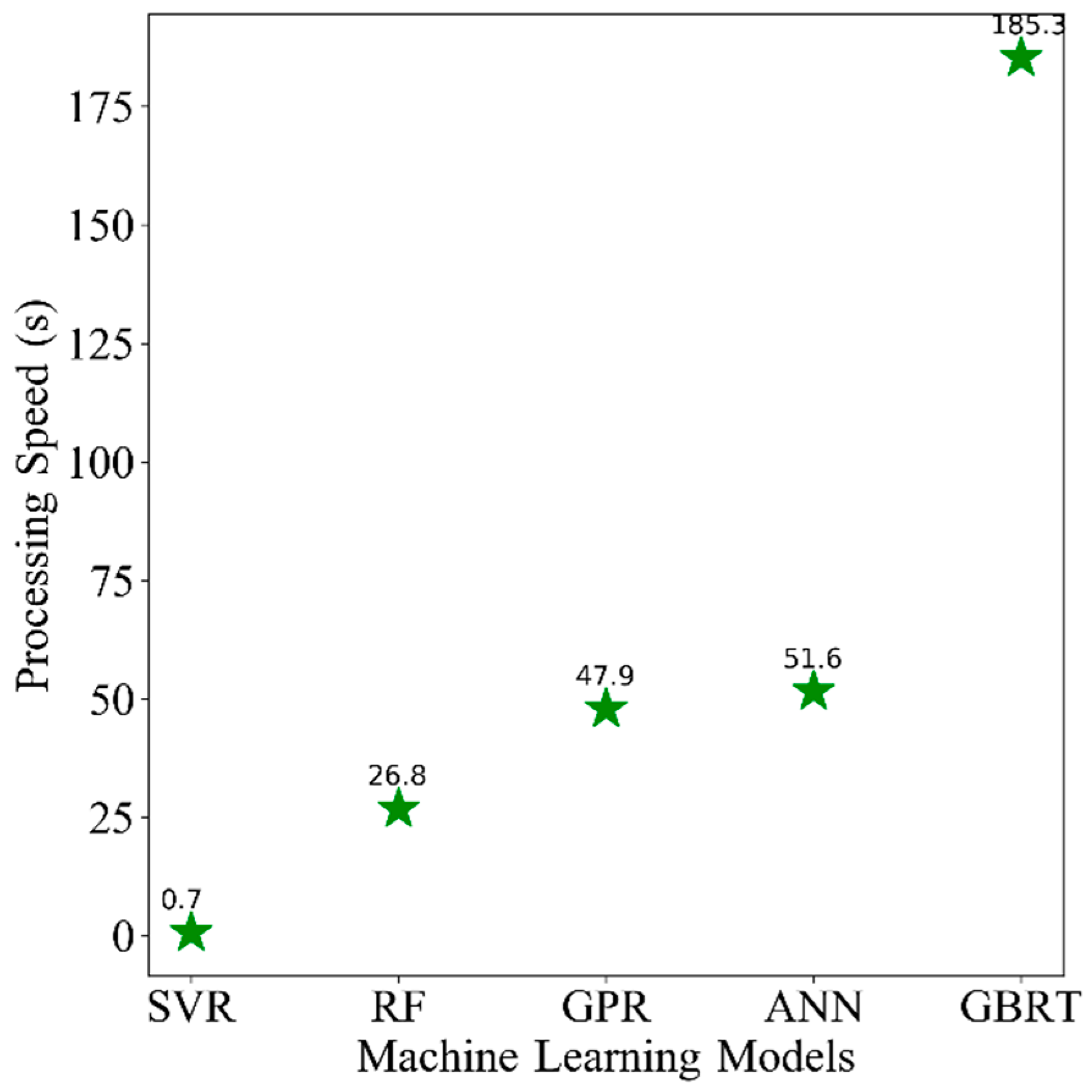
4.2. Computational Efficiency
Beyond the model accuracy of the five models for the training and testing random split, it is of particular relevance to compare the computational efficiency (time required to the model during training and validation processes) of the models, as it is an important criterion for operational algorithms. All models were implemented in a Python environment on an Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10 GHz processor and installed memory (RAM) of 32.0 GB. The computational efficiency is recorded from the 20 repetitions in
Section 4.1. The averaged results of 20 repetitions are illustrated in
Figure 6. Large differences among the five ML models are clearly found. SVR performs incredibly fast (less than 1 s). However, GBRT is frustrating, owing to the large amounts of its hyperparameter tuning processes. In general, SVR is able to deliver near real time operational products with a highly efficient processing speed, whereas the GBRT model is not recommended for this kind of application, because the GBRT model is computationally more demanding. RF, GPR and ANN showed moderate performances in terms of computational efficiency.
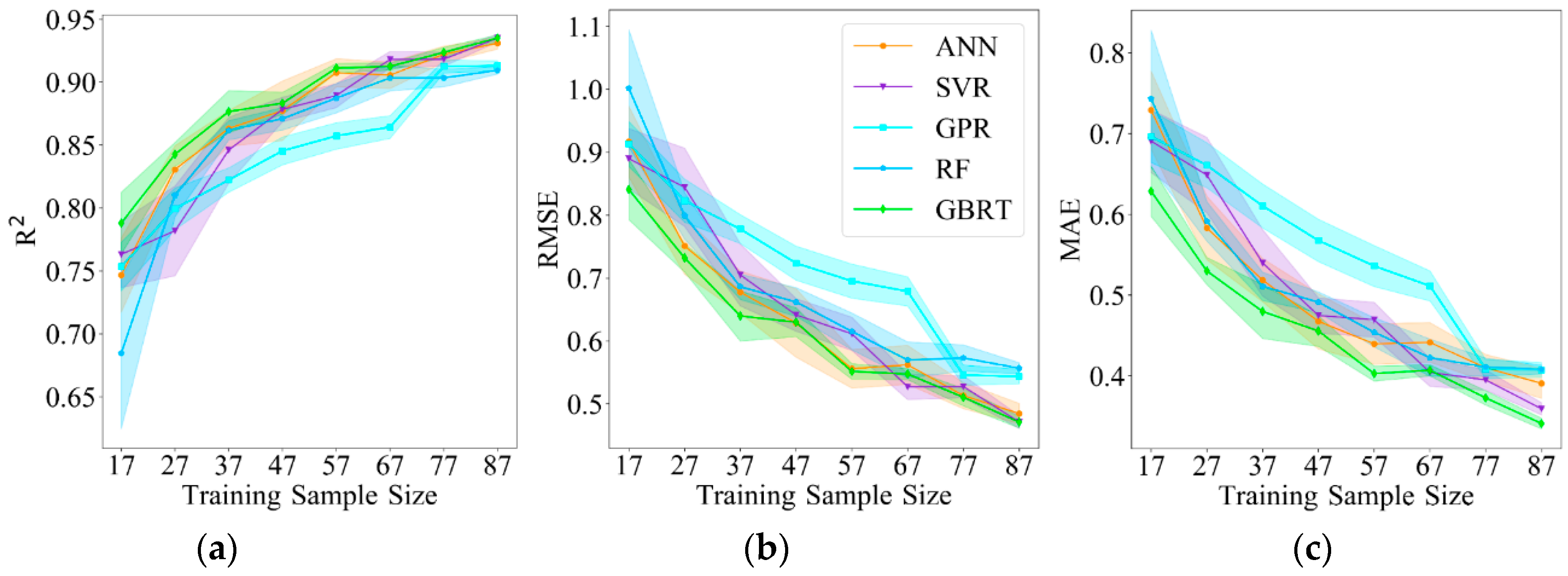
4.3. Sensitivity to Training Sample Size
We use
, RMSE and MAE between the predicted LAI values and measured LAI values to assess the sensitivity of five ML methods to the training sample size. Eight datasets with different sample sizes (17-87) were generated by randomly sampling from the total training datasets (87 samples) at intervals of 10.
Table 9 shows the number of training and testing samples of the eight datasets, while the testing datasets keep as the same datasets with 30 samples.
To evaluate the robustness of five ML models for the training samples, we conducted 10 random repetitions of each model and provided the corresponding standard error. The standard error is given as follows:
where
denotes the standard deviation,
represents the number of repetitions.
Figure 7 shows the changes in
, RMSE and MAE as the training sample sizes varied, the standard error is given at each training sample size (filling area of each model), lower values of the filling area corresponds to smaller standard error, and consequently, more robust model performance. According to
Figure 7, different sensitivity performances of the sample size variation are found among the ML models. GPR and GBRT show robust performances for the training samples according to the standard error of different models. GBRT produces a remarkable performance for the training samples that is more robust than the other models, GPR behaves suboptimally. ANN and SVR are very sensitive to the training samples. Moreover, all models behave more robust with the growth of training sample size according to the variation of standard error. In summary, the model accuracy improves overall with an increasing training sample size, while GBRT provides the most robust performance for the training samples, and the best model accuracy among the variations in training sample size on average (
= 0.884,
= 0.615 and
= 0.452, calculated by all the 8 groups of training sample size).
4.4. Sensitivity to Spectral Bands
Variable and feature selection have been one of the most significant processes in ML, with the aim of improving model accuracy and accelerating model processing. With 10 spectral bands of Sentinel-2 available (B2, B3, B4, B5, B6, B7, B8, B8A, B11, B12), it may not be practical to evaluate the performance of all the possible band combinations. This process could be challenging, as the characteristics of different ML models are distinct, and thus it is challenging to conduct a comparison among the different models under a unified standard. For example, GPR, RF and GBRT could provide feature relevance (spectral bands relevance) information that enables insight into feature selection processes, however, the feature relevance results are subject to the model itself, in other words, we could obtain different feature selection schemes, and such information is practical with single ML model based applications. In addition, ANN and SVR are not able to deliver feature relevance information.
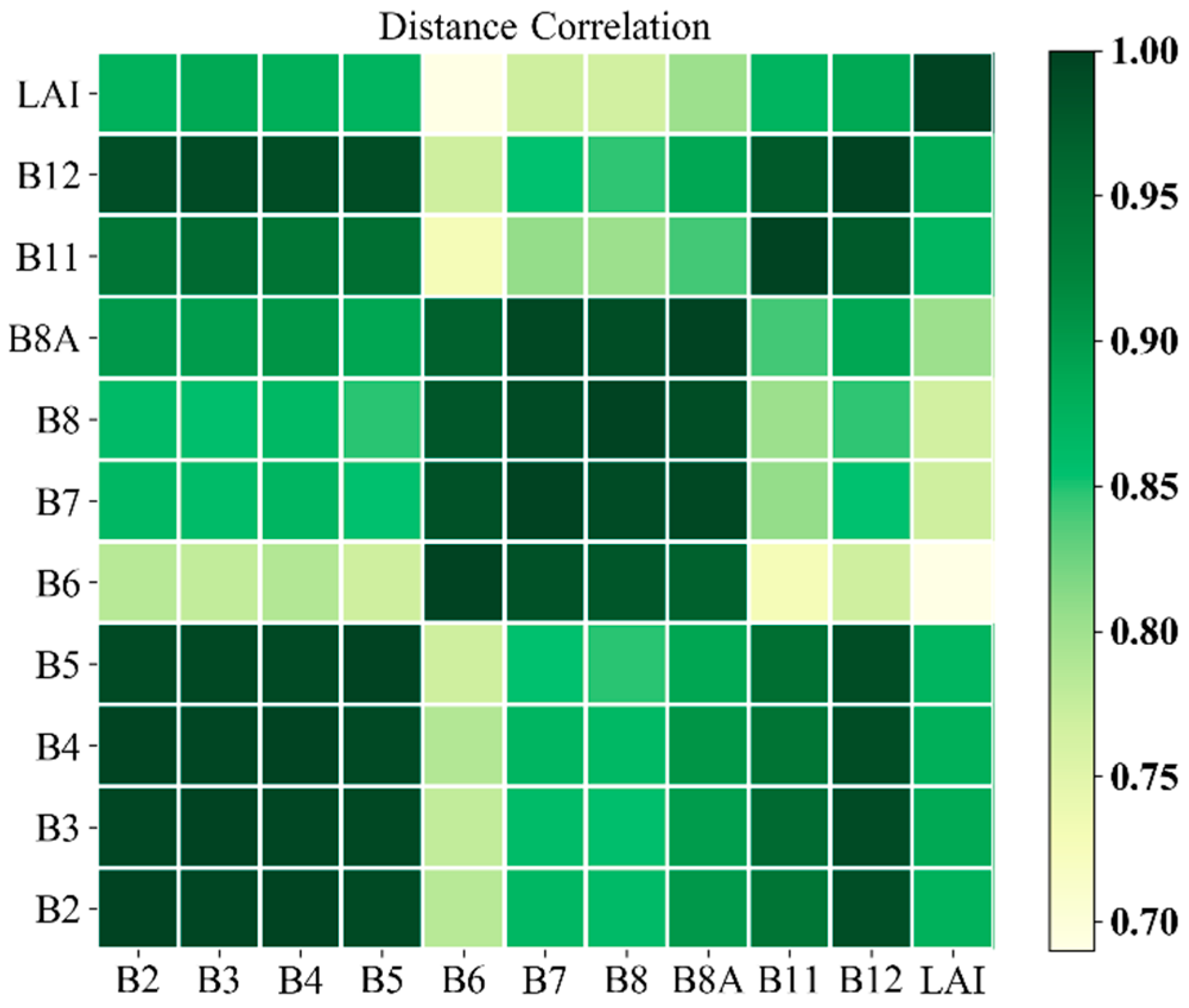
Székely, Rizzo, and Bakirov [
77] proposed the distance correlation (dCor) to measure the dependence of random vectors. dCor ranges between 0 and 1, and dCor (
X,
Y) = 0 only if
X and
Y are independent, which is effective in the feature selection processes [
78,
79,
80]. To identify the optimal number of Sentinel-2 spectral bands required for cotton LAI retrieval using MLRAs, we used the distance correlation combined with the backward elimination method [
81,
82]. We also performed 10 random repetitions of each model to assess the model’s robustness with the spectral bands. Notably, the distance correlation is subject to the training dataset adopted in this study.
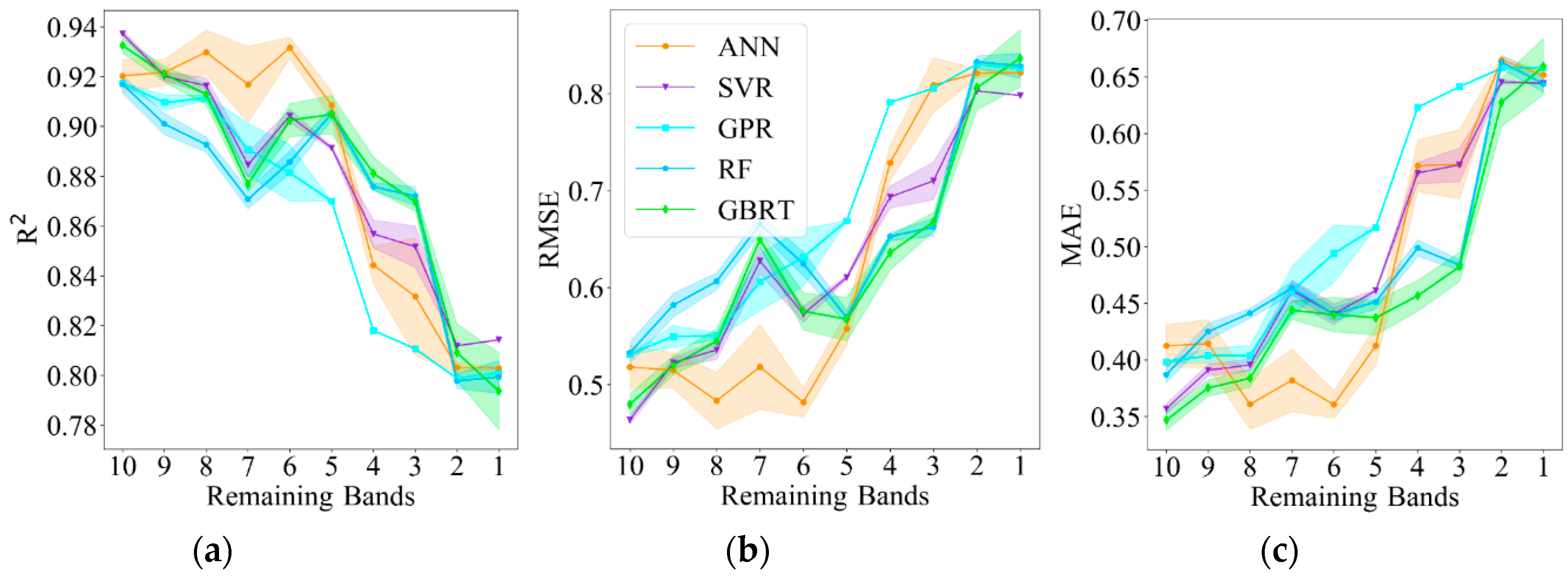
Figure 8 displays the distance correlation among the 10 spectral bands and LAI. The ranking of the dCor values between the 10 spectral bands and LAI are identified as B12 > B3 > B4 > B2 > B5 > B11 > B8A > B7 > B8 > B6 (B12: 0.88631, B3: 0.88630, B4: 0.88016, B2: 0.87721, B5: 0.87400, B11: 0.87338, B8A: 0.80219, B7: 0.76812, B8: 0.76585, B6: 0.68998). The visible and SWIR bands occupied the top rankings, while differences among the red-edge bands were distinct. The sensitivity results of different ML models to spectral bands using dCor and the backward elimination method (iteratively removing the spectral band with the lowest dCor value until only one spectral band is left) are shown in
Figure 9, similarly, the standard error is given at each spectral bands combination (filling area of each model), lower values of the filling area corresponds to smaller standard error, and consequently, more robust model performance. Differences exist among the sensitivity of the models with the reduction in spectral bands. A turning point occurred at 6 for ANN, the accuracy begins to increase with the reduction in spectral bands before 6, though with some fluctuations, and then, the accuracy begins to decrease dramatically until reaching approximately 3. Similar trends are found among all the models except for GPR, as there is a relatively strong fluctuation at 7. GPR has a stable performance after 4. SVR, GPR and RF are robust for the spectral bands according to the standard error. Overall, model accuracy decreases as the spectral bands decrease, although there are some fluctuations in the models, whereas ANN provides the best model accuracy among the spectral band reductions on average (
= 0.881,
= 0.625 and
= 0.480, calculated by all the 10 groups of spectral bands).
The minimum number of bands required for cotton LAI retrieval are recognized as 6 for ANN and SVR, 5 for RF and GBRT, and 8 for GPR, in other words, increasing of the spectral bands of Sentinel-2 does not significantly improves the model accuracy. Given the recognized number of spectral bands of each of the ML models, this is vital for associated applications with great amounts of samples, as it may reduce model processing time and desirable model accuracy could be acquired in the meantime.
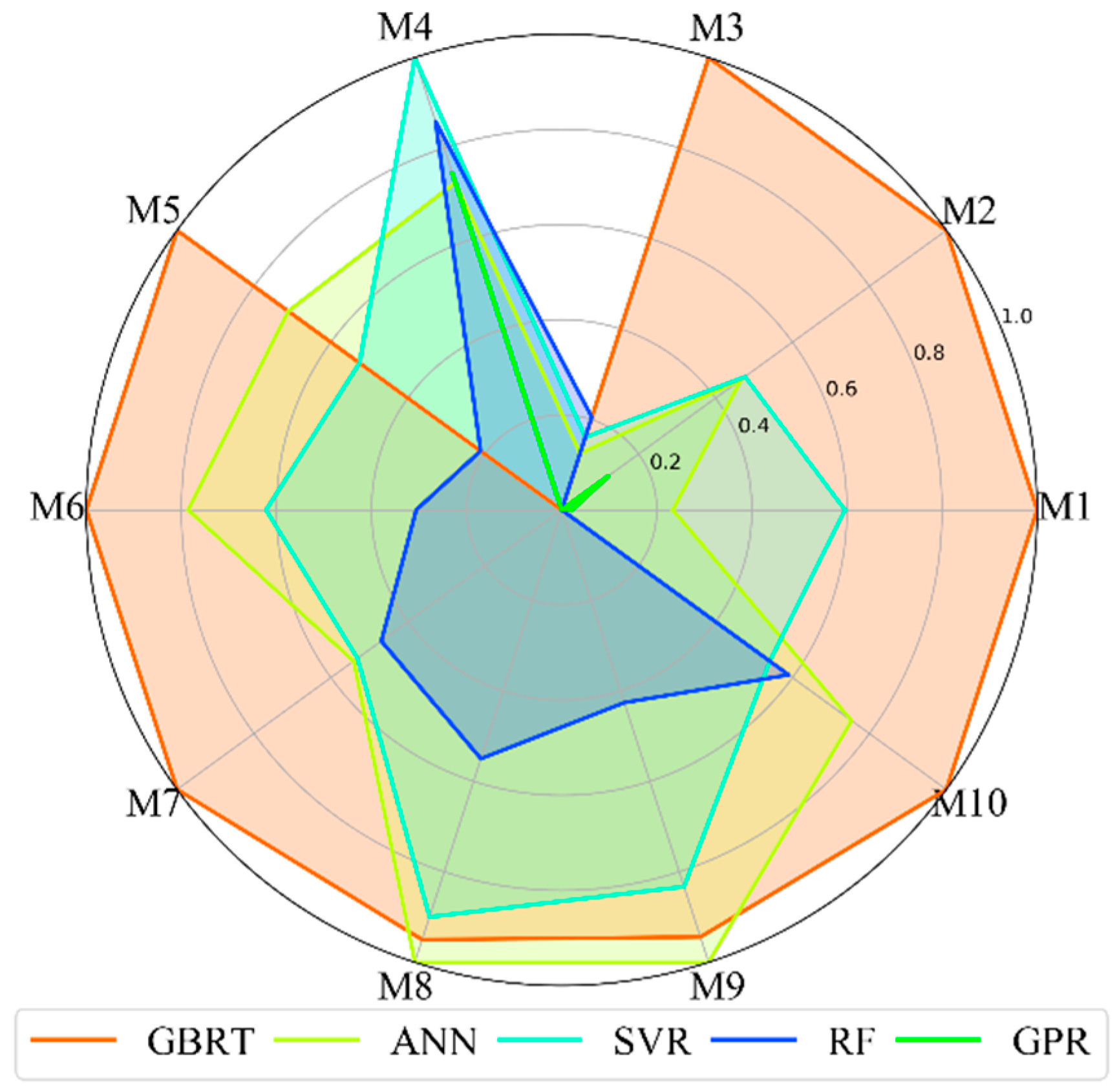
4.5. Comprehensive Evaluation
In this study, we conducted a comparison of five universal MLRAs for cotton LAI retrieval with regard to model accuracy, computational efficiency, sensitivity to training sample size and sensitivity to spectral bands. In this section, we provide a comprehensive evaluation of five ML algorithms according to the obtained results, which were discussed earlier in this paper. To combine all the metrics, we performed a standardization process on the results. The mean values of the results in the sensitivity analysis (training sample size and spectral bands) were used, and we make RMSE, MAE and processing speed negative for the sake of comprehensive comparison. An alternative standardization is interval scaling, which is as follows:
where
denotes the maximum value of the data, and
represents the minimum value of the data. The results are displayed in
Figure 10, and the metrics used in the radar chart and its corresponding implications are displayed in
Table 10. Clearly, GBRT shows an outstanding performance from a comprehensive viewpoint, however, GPR shows the worst performance. ANN and SVR show moderate performances.
4.6. Final LAI Maps
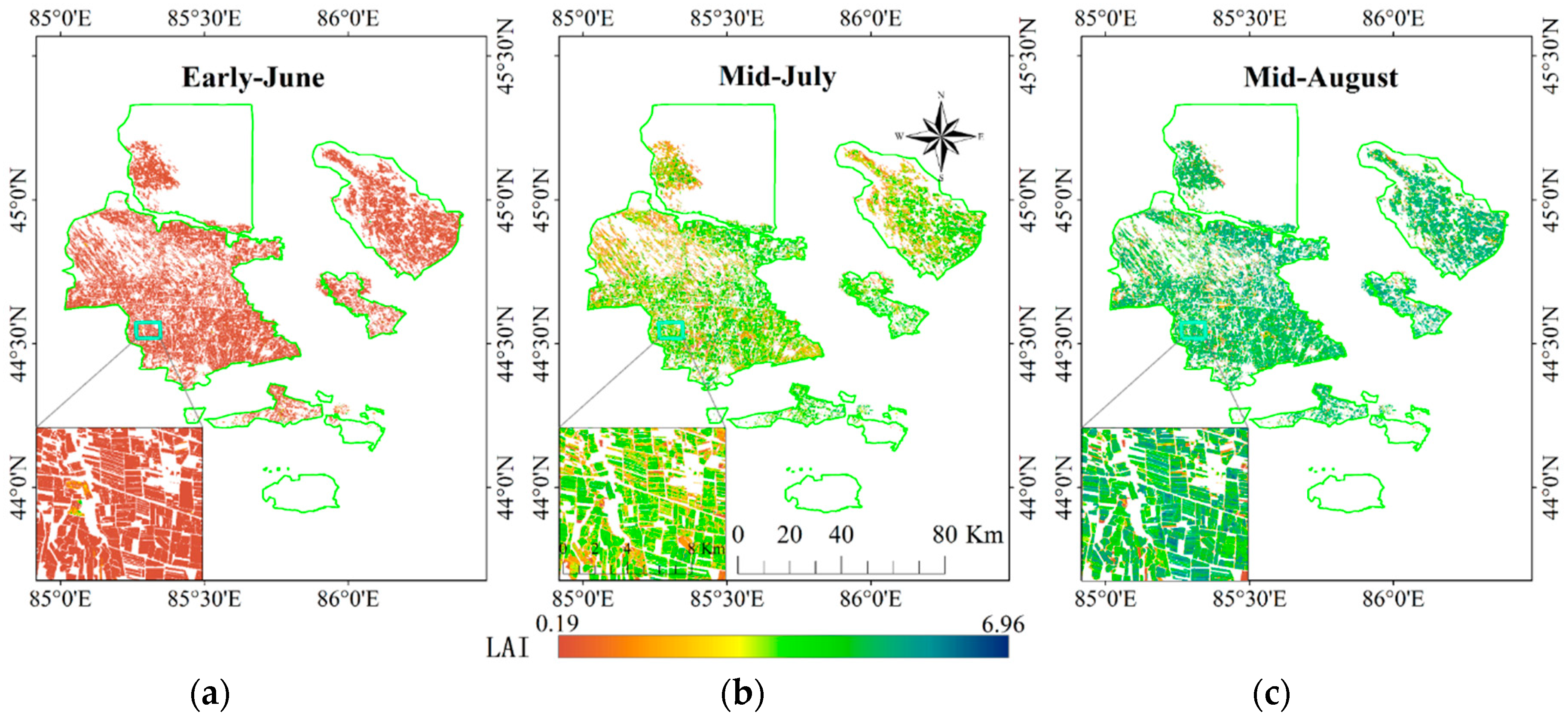
The best performing ML regression model has been applied to map cotton LAI with Sentinel-2 imagery, as analyzed in previous sections, we use the GBRT model to map cotton LAI in the study area. The fields in the study area are regular, we conducted a manual vectorization based on Google Earth image data to obtain accurate agricultural fields boundaries, and Landsat 8 image data were collected to update the fields, as Google Earth image data has poor temporal information. Totally, 40,211 fields were collected by this way in the study area.
Figure 11 displayed the agricultural fields boundaries. A per-field crop classification was performed to extract cotton fields. The final cotton LAI map was obtained by masking the results using the extracted cotton fields.
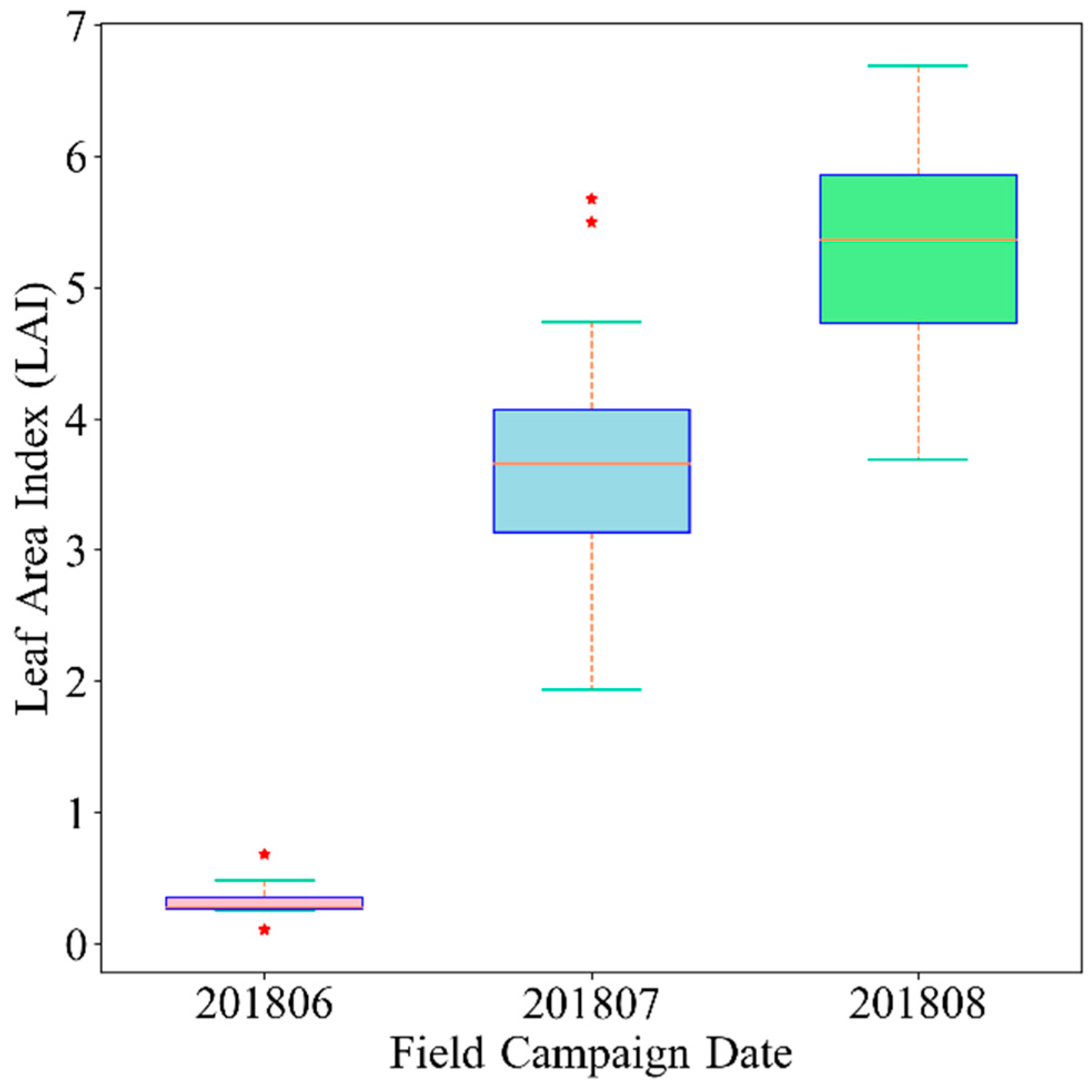
Figure 12 presents the final cotton LAI map. From
Figure 12, it is clear to find that there is an increasing trend of cotton LAI growth, as revealed by
Figure 2.
In the early June cotton LAI map, some areas have LAI values much larger than the whole map (green color), as well as LAI values much smaller found in mid-July and mid-August (orange color), these fields are some other crops rather than cotton, and it can be ascribed to the misclassification.
4.7. Comparison with Global LAI Products
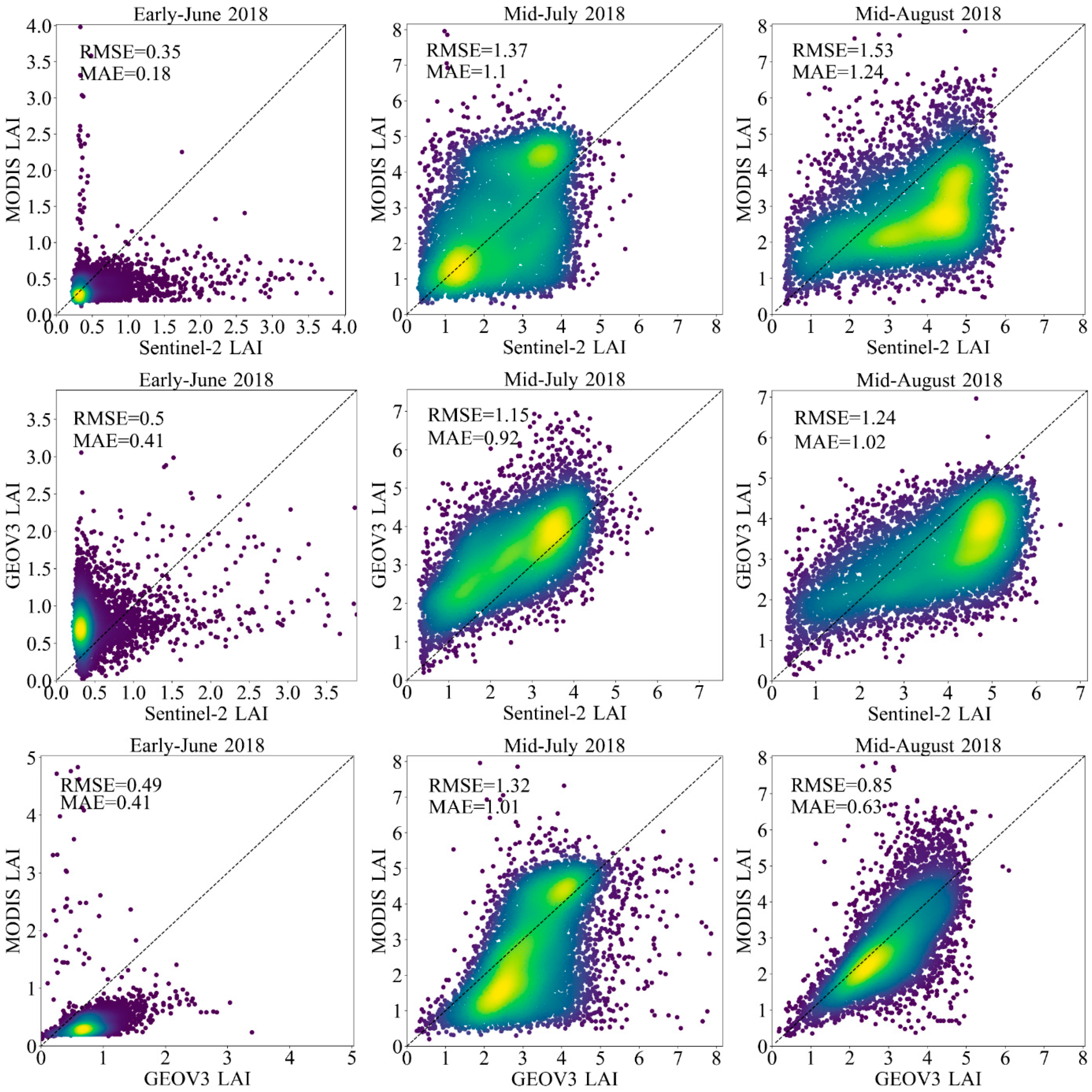
The validation of moderate-resolution products are key steps to assess the quality of the global LAI products. In this study, we performed a comparison among GEOV3, MODIS LAI products and upscaled Sentinel-2 LAI to assess the quality of these two products in Northwest China. To conduct the comparison of the cotton LAI results obtained using the GBRT model with global LAI products, we choose the closest dates of the products at a spatial resolution of the products to minimize the spatial and temporal differences [
2].
All Sentinel-2 LAI maps were resampled to the same spatial resolution of MODIS and GEOV3 LAI products, and then GEOV3 LAI product were also resampled to the same spatial resolution of MODIS LAI product to make a straight comparison of these two products.
Figure 13 shows the scatter plots among the comparison of GEOV3, MODIS and Sentinel-2 cotton LAI over three observation dates. Regarding the comparison of the MODIS LAI product and Sentinel-2 LAI maps, it was found that both the MODIS LAI product and the Sentinel-2 LAI suffered from the influence of the background, and are kind of overestimated in some areas in early June 2018. MODIS LAI product underestimated a little bit in mid-August 2018. In terms of GEOV3 LAI product and Sentinel-2 LAI maps, the GEOV3 LAI product overestimated at some areas both in early June and mid-July 2018, and underestimated in mid-August 2018. Finally, with respect to the comparison of the two global LAI products, relatively, large differences are found in early June and mid-July 2018, whereas a good relationship appeared in mid-August 2018.
5. Discussion
Over the last decade, there has been a considerable increase in the introduction of ML algorithms to remote sensing for a wide range of fields. Crop biophysical parameters (e.g., LAI) are key variables for a wide range of applications. With the progress of remote sensing techniques, we are able to acquire high dimensional (spatial, temporal, and spectral) remote sensing data, which demands more efficient, accurate and robust algorithms in a wide variety of applications with remote sensing. In this context, there is great potential for ML algorithms to be used in a wide range of remote sensing applications.
The diversity of available ML algorithms poses great challenges for the selection of MLRAs, as well as the decision of optimal number of training sample size and spectral bands to different MLRAs. Besides, another significant problem that may arise involves hyperparameter tuning in the application of ML algorithms. In general, experience is required to obtain satisfactory results for ML algorithms, and experiments with a large number of datasets may be needed, which are generally not available. Accordingly, it is necessary to perform a comparison of different fashionable ML models to support better remote sensing applications. In this study, we focus on the comparison of five well-known ML algorithms for cotton LAI retrievals with Sentinel-2 imagery, because these algorithms have a wide range of applications in remote sensing. Additionally, the hyperparameter tuning results of five prominent ML models are provided. Our study could provide support for associated remote sensing studies based on ML algorithms.
Furthermore, a comparatively great fluctuation is observed at 7 among all the models except for GPR in
Figure 9, the previous removing spectral band is the red-edge band (B7), which indicates that having low dCor values do not necessarily correspond to being less important for LAI retrieval. Notably, ensemble methods (RF and GBRT) and GPR models have a great benefit of delivering feature importance information (not shown in our study), which provides insight into the greatest contributing features of the model. Such information could be used for better model interpretation, and this information is also useful for feature selection processes when applied to models that contain a great number of features.
In related studies, Verrelst, et al. [
55] compared four ML algorithms (NN, SVR, KRR and GPR) using simulated Sentinel-2 and 3 data to assess three biophysical parameters (Chlorophyll content, LAI and FVC). GPR outperformed the other regression methods for the majority of Sentinel configurations, whereas in our study, GPR performed worse than the other regression methods. Results that differ from our study may be for the following reasons. First, we used real Sentinel-2 data rather than simulation data, and it may be difficult to represent the performance of real Sentinel-2 data with simulation data. Second, we focus on cotton crops over the entire growth period rather than on various crop types. In addition, there may be different hyperparameter settings between models. Finally, there are differences between the Sentinel-2 bands, and we used 10 spectral bands (SWIR included). Yuan, et al. [
83] compared the RF, ANN and SVM regression models for soybean LAI retrieval using unmanned aerial vehicle (UAV) hyperspectral data with different sampling methods. The results showed that RF is suitable for the whole growth period of soybean LAI estimation, while ANN is appropriate for a single growth period. Siegmann and Jarmer [
84] compared SVR and RFR for wheat LAI estimation using hyperspectral data, and the results showed that SVR provided the best performance of the entire dataset. Different from previous studies, we considered the GBRT model due to its highly robust performance over a wide range of applications. We further explored the sensitivity of different ML algorithms to training sample size and Sentinel-2 spectral bands. The results show that GBRT achieves the best performance, and GBRT was more robust for the training samples than the other models.
Despite the promising results revealed by five ML regression methods, there are some limitations of our study, and further studies are needed to assess the generalization ability of the five ML regression methods. Firstly, we focus on only one crop type, and the performance of ML regression methods for other crop types has not been validated. It is necessary to evaluate ML algorithms with various crop types, provided there are enough field measurement LAI data of different crop types available.
Secondly, some other crop biophysical parameters (e.g., Chlorophyll content and FVC) demand evaluation as well as ML regression methods, as different results may appear with different ML algorithms and different crop biophysical parameters. Thirdly, there are limitations with Sentinel-2 spectral bands sensitivity analysis, since some spectral bands are highly correlated, and redundancies remain among the spectral bands, so this process would be worth further investigations to explore a better spectral bands sensitivity analysis. Additionally, there are limitations to our quadrats in the field campaigns, as we chose only three sample points to represent a quadrat (20 m
20 m). Finally, the performance of five MLRAs has not yet been evaluated for large amounts of data (e.g., tens of thousands of data) due to the limited number of samples in our study, however, it remains to be seen whether a favorable performance can be obtained. In consideration of the ability of ML techniques, it is expected to obtain a better accuracy of the regression models provided there are enough samples, and a turning point should be obtained, as has been demonstrated in previous studies [
19]. While before the turning point, the model accuracy increased rapidly with the increase in the training sample size, whereas, after the turning ponits, the model behaves more stable, in other words, the model accuracy remmained unchanged with the increasing of training sample szie. Future studies are required to investigate this problem.
With the advance in ML technology, deep learning, a new subfield of ML, has been applied successfully to many remote sensing domains, especially with a large quantity of data [
85]. It is not necessary to construct complex ML models (deep learning-based models) in our study, as traditional ML algorithms have the capability of establishing efficient, accurate and robust estimation models for cotton LAI retrieval. However, as there are greater amounts of data available, deep learning techniques may be promising alternatives for handling such large volume datasets and complex relationships among the input datasets, which deserve further study.
6. Conclusions
With the challenges of selecting ML algorithms for crop LAI estimation, the results of this study have great implications for the selection of appropriate ML models from the diversity of available ML algorithms, and at the same time, these same results provide the optimal number of training sample size and spectral bands of Sentinel-2 for each model required for cotton LAI retrieval. Regarding the comparison of different ML models for cotton LAI retrieval employed in our study, the GBRT model outperforms the other ML models according to our results. Our findings increase the potential for cotton LAI retrieval with Sentinel-2 imagery, and may be transferrable to other associated problems related to agricultural remote sensing applications. On the other hand, the GBRT model is computationally demanding, which may be a significant problem with a large scale of data. However, GBRT can challenge the model accuracy and computational efficiency selection problems. Considering the computational efficiency, SVR exhibits considerable computational superiority over the other ML models.
Regarding the sample size sensitivity of ML models, model accuracy increases with the growth of the training sample size, and the GBRT produces the most robust performance for the training samples with respect to the standard error and the best model accuracy on average.
In terms of spectral band sensitivity analysis, the distance correlation results showed that the SWIR and visible bands have great potential to improve the accuracy of cotton LAI retrievals. By using dCor combined with the backward elimination method, the model accuracy decreases with the reduction in spectral bands. SVR, GPR and RF perform robustly with the spectral bands, and ANN provides the best accuracy on average. The minimum number of bands required for cotton LAI retrieval are recognized as 6 (ANN), 6 (SVR), 5 (RF), 5 (GBRT) and 8 for GPR.
A comprehensive evaluation has been employed to identify the performance of five ML models, considering a combination of model accuracy, computational efficiency, sensitivity to training sample size and sensitivity to spectral bands. The comprehensive performance of the models is identified as GBRT > ANN > SVR > RF > GPR.
Despite the different performances of the five ML regression models, MLRAs are promising ways to retrieve cotton LAI with Sentinel-2 imagery because the MLRAs all achieved encouraging accuracies. With profound applications for a diversity of ML algorithms in remote sensing, MLRAs may provide positive effects for remote sensing applications in terms of classification, regression, and other associated problems.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}