Abstract
We propose a local feature descriptor based on moment. Although conventional scale invariant feature transform (SIFT)-based algorithms generally use difference of Gaussian (DoG) for feature extraction, they remain sensitive to more complicated deformations. To solve this problem, we propose MIFT, an invariant feature transform algorithm based on the modified discrete Gaussian-Hermite moment (MDGHM). Taking advantage of MDGHM’s high performance to represent image information, MIFT uses an MDGHM-based pyramid for feature extraction, which can extract more distinctive extrema than the DoG, and MDGHM-based magnitude and orientation for feature description. We compared the proposed MIFT method performance with current best practice methods for six image deformation types, and confirmed that MIFT matching accuracy was superior of other SIFT-based methods.
1. Introduction
The scale invariant feature transform (SIFT) was proposed by Lowe [1] to extract image features invariant to changes in image scale, rotation, illumination, viewpoint, and partial occlusion. SIFT has been widely used in various areas, including image stitching [2], image registration [3], object recognition [4]. Several SIFT variants and extensions have been developed recently to facilitate robust feature extraction. Ke [5] used principal component analysis (PCA) rather than histograms to reduce computational time and compared SIFT and PCA-SIFT. Bay [6] proposed speeded-up robust features (SURF) to reduce computational time. Mikolajczyk [7] presented a comparative study for several local descriptors. Kang [8] proposed a modified local discrete Gaussian-Hermite moment based SIFT (MDGHM-SIFT) that significantly improved matching accuracy by replacing gradient magnitude and orientation with accumulated MDGHM based magnitude and orientation. Junaid [9] proposed binarization of gradient orientation histograms to reduce storage and computational resources. Although these SIFT based algorithms can improve feature extraction performance, they are all the different types of Gaussian based methods and, hence, sensitive to complicated deformations, e.g., large illumination changes [10].
Gaussian–Hermite moment (GHM) has been recently shown to have merit for image features [11]. GHM base functions have different orders with different numbers of zero crossings, hence GHM can distinguish image features more efficiently, and incorporating part of the Gaussian function makes GHM less sensitive to noise. Discrete GHM (DGHM) [12,13] is a global feature representation method, and modified DGHM (MDGHM) [8] is an efficient local feature representation method generated from DGHM. Kang [14] also proposed an MDGHM-SURF descriptor that used MDGHM to extract distinctive features.
This paper proposes MIFT, an MDGHM based invariant feature transform where the MDGHM based pyramid was constructed using input image MDGHMs, in contrast to the Gaussian pyramid and DoG used in the first SIFT stage, and MDGHM based magnitude and orientation were used to calculate orientation and keypoint descriptors in the third and fourth SIFT stages rather than the original gradient method.
2. Scale Invariant Feature Transform and Modified Discrete Gaussian–Hermite Moment
This section reviews the conventional SIFT algorithm [1] and MDGHM [8].
2.1. Scale Invariant Feature Transform
The SIFT is a robust local feature descriptor comprising four stages.
- Scale space extrema detection. Search keypoint candidates on the basis of the extrema over all scale images. This constructs a Gaussian pyramid and finds the local extrema in DoG images.
- Keypoint localization: Locate keypoints by removing unstable keypoint candidates having low contrast or poor localization along an edge.
- Orientation assignment. Identify the orientation for each keypoint based on local image gradient information.
- Build a descriptor for each keypoint.
2.2. Discrete Gaussian-Hermite Moment
The MDGHM has orthogonality, and calculates the moment for a local image area, acting like a filter mask to describe local features using neighboring information. Suppose I(i,j) is an image and t(u,v) is a mask with size . The coordinates for t(u,v) are transformed to by:
Hence, the Hermite polynomial is:
and the MDGHM mask can be expressed as:
Thus, MDGHM of an image at point can be expressed as:
Figure 1 shows MDGHM examples with three derivative orders. MDGHM acts like a Gaussian filter with multi-order derivatives. Since the base function of the nth order MDGHM changes sign n times, MDGHM can efficiently represent spatial characteristics and strongly separate image features using the multi-order derivatives. Therefore, MDGHM can be used as a filter to describe local features.
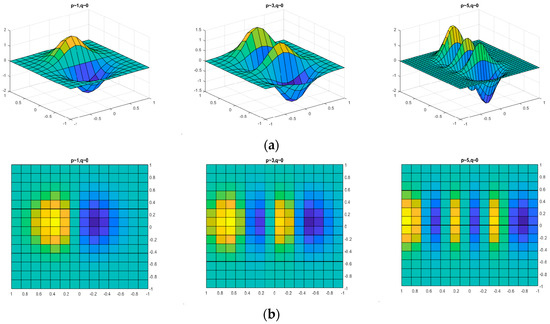
Figure 1.
Modified discrete Gaussian-Hermite moment examples with derivative orders p = 1, 3, 5; q = 0: (a) three-dimensional view and (b) two-dimensional view.
3. Proposed MIFT Algorithm
The scale invariant feature transform remains sensitive to deformations [1,8], because DoG and gradient methods do not provide distinctive information to accurately determine keypoint location in a deformed image. To obtain better matching accuracy, we propose MIFT, an MDGHM based invariant feature transform. Figure 2 shows an overview for SIFT and MIFT methods.
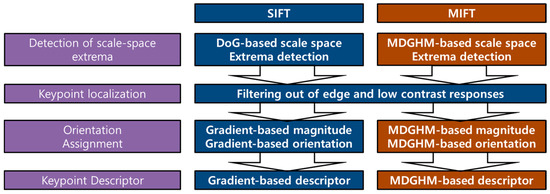
Figure 2.
Scale invariant feature transform (SIFT) and proposed MIFT methods.
3.1. Stage 1
We use MDGHM based scale space to detect extrema, rather than the Gaussian pyramid and DoG used for conventional SIFT, extracting more distinctive features. The input image is down-sampled by a factor of 2 to create an octave, and MDGHM is applied to create scale images according to selected parameters for derivative order, sigma, and mask size.
Let be an arbitrary pixel in a scale , then the local moment at can be expressed using MDGHM as:
and the vertical, and horizontal, , moments can be obtained for each keypoint. Therefore, we can calculate the scale space moment by summing the vertical and horizontal components:
and more distinctive keypoint candidates can be detected using MDGHM pyramid extrema than the DoG pyramid.
Figure 3 compares and contrasts DoG and MDGHM pyramids and feature detection methods between conventional SIFT and proposed MIFT methods, and Figure 4 provides example scale space using DoG and MDGHM. Since MDGHM can include more distinctive feature information, the MDGHM pyramid can represent feature information in more detail than conventional SIFT, and building the MDGHM scale space is also somewhat simpler.
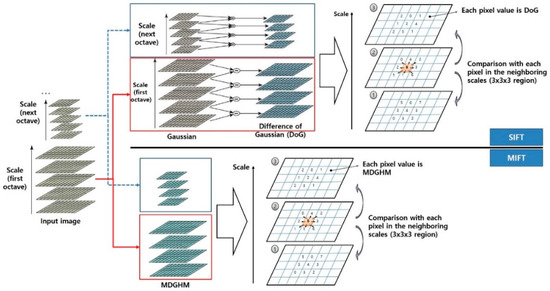
Figure 3.
SIFT and MIFT scale space construction.
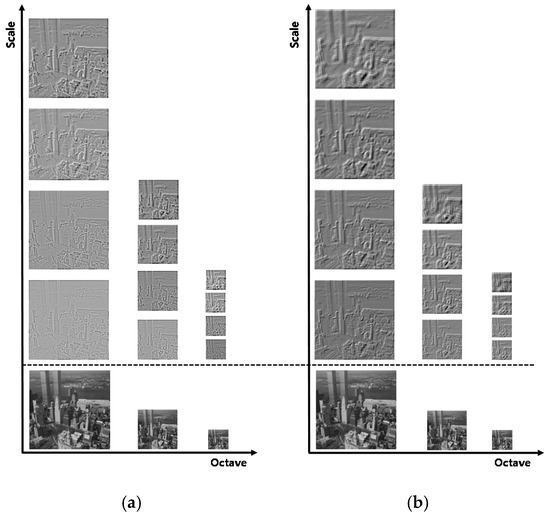
Figure 4.
Example scale space images for (a) DoG and (b) MDGHM.
The vertical and horizontal axes in Figure 4 represent octave and scale in scale space, respectively. MDGHM scale space images extract more distinctive feature information. Points with maximum or minimum MDGHM compared with its 26 neighbors at the consecutive three scales are regarded as keypoint candidates.
3.2. Stage 2
The proposed MIFT keypoint localization is similar to conventional SIFT, except that local DoG maxima and minima are replaced by the MDGHM counterparts. We then fit the candidates to filter those with low contrast or localized along an edge.
3.3. Stage 3
Figure 5 shows the SIFT and MIFT processes to assign keypoint orientation. Conventional SIFT uses gradient magnitude and orientation, whereas MIFT uses the MDGHM magnitude, , and orientation, , for each keypoint, where:
and:
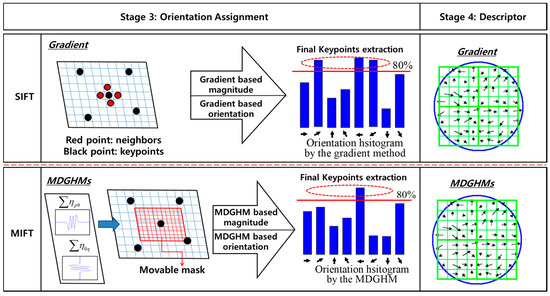
Figure 5.
Stage 3 process for conventional SIFT and proposed MIFT methods.
Each sample point around a keypoint has an MDGHM magnitude and an orientation, and the orientation histogram is calculated by summing these orientations weighted by the magnitudes. The highest histogram peak and other local peaks within 80% of the highest peak are selected as the orientations.
3.4. Stage 4
We calculate a descriptor that is invariant to deformations following a similar procedure to conventional SIFT, using MDGHM rather than gradient based magnitude and orientation, as shown in Figure 6. We calculate MDGHM magnitude and orientation for each sample point in a region around a given keypoint (Figure 6, left), and accumulate these orientations into the orientation histogram for eight directions weighted by their magnitude (Figure 6, right). Each descriptor consists of a 2 × 2 array of histograms, hence each keypoint descriptor has 2 × 2 × 8 = 32 dimensions. In this study, we used 4 × 4 × 8 = 128 dimensions to describe a keypoint.
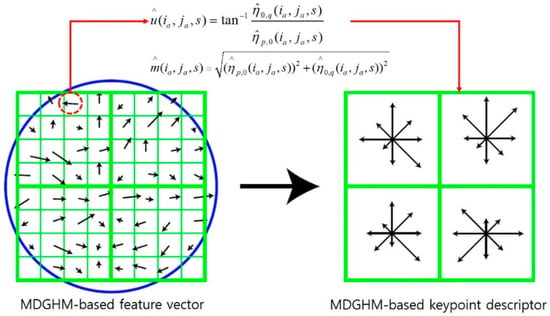
Figure 6.
Process to calculate MDGHM descriptors.
4. Experimental Results
We performed experiments to evaluate the proposed MIFT performance using keypoint matching accuracy, compared with five SIFT relative algorithms, and considered application to ego-motion compensation for a humanoid robot.
4.1. Keypoint Matching Accuracy
Table 1 compares the proposed MIFT method with five SIFT relative algorithms. SIFT relative algorithms generally have four stages and, hence, they are characterized by their differences.

Table 1.
Proposed MIFT and SIFT based algorithms used for comparison.
4.1.1. Image Deformation Dataset
We conducted an experiment to matching accuracy for a dataset containing six image deformations [15]: scale, image, viewpoint, blur, JPEG-compression, and illumination. Figure 7 shows some example testing images, where the left and right images represent reference and corresponding deformed images, respectively.

Figure 7.
Example dataset reference (left) and distorted (right) image pairs: (a) scale; (b) rotation; (c) viewpoint; (d) blur; (e) JPEG compression; and (f) illumination.
4.1.2. Matching Method and Evaluation Metrics
We utilized nearest neighbor distance ratio (NNDR) matching [7] for performance evaluation, since NNDR selects only the best match. Two descriptors were considered to match if they were nearest neighbors and the distance ratio was less than a threshold. We used DR as a short descriptor for NNDR for convenience.
We used recall, 1-precision, and F-score evaluation metrics [7,14]:
and:
where correct positive was a match for two keypoints corresponding to the same physical location, false positive was a match for two keypoints corresponding to different physical locations, and F score ϵ [0, 1].
4.1.3. Performance Evaluation
Figure 8 shows the resultant considered method performances, where each datapoint was the average for 3–6 continuously varying test images, and we increased DR 0–1 with 0.05 interval. MIFT achieved significantly superior performance than the other SIFT based algorithms for all deformations, with general performance order being MIFT, MDGHM-SIFT, SIFT, MDGHM-SURF, SURF and PCA-SIFT algorithms for most deformation cases. Thus, MDGHM had a positive effect on feature representation ability for image information.
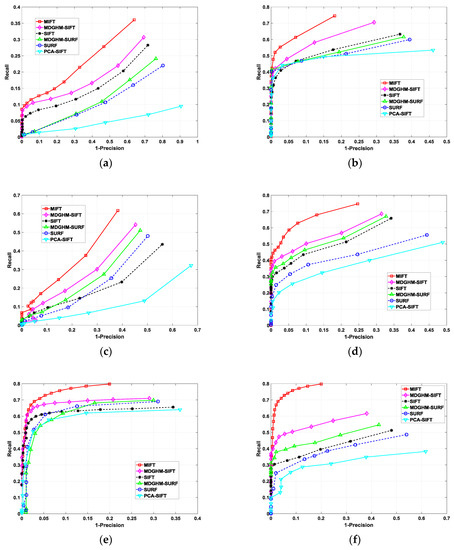
Figure 8.
Comparison between the proposed MIFT and five SIFT based algorithms (as defined in Table 1) for (a) scale; (b) rotation; (c) viewpoint; (d) blur; (e) JPEG compression; and (f) illumination distortion.
Table 2 shows performance metric outcomes. MIFT F-score increased approximately 32.5%, 21.4%, 41.9%, 14.9%, 20.1%, and 57.8% for scale, rotation, viewpoint, blur, JPEG compression, and illumination distortions, respectively, compared with conventional SIFT. The proposed MIFT method exhibited significantly superior performance compared with the other SIFT based algorithms for F-score. Thus, MIFT was the most effective method tested, which attributed to employing the MDGHM based pyramid and MDGHM based feature description. The MDGHM pyramid generated more distinctive keypoints from scale space extrema detection, producing stronger histogram peaks during MIFT orientation assignment. Therefore, MIFT extracted more distinguishable final keypoints and, hence, achieved superior matching accuracy.
Table 2.
Performance metrics.
4.1.4. MDGHM Parameter Effects on Performance
We examined the effects due to MDGHM parameters standard deviation and derivative degree by fixing the MDGHM mask size, using F-score, as shown in Figure 9. The lower plane in each subfigure represents the SIFT F-score, the curve represents the MIFT F-score. Although the performance results exhibit some oscillation, MIFT outperformed SIFT for most parameter settings. In particular, MIFT achieved high F-scores for rotation, viewpoint, and illumination deformations for all parameter settings, with margin > 0.1 between MIFT and SIFT. For scale, blur and JPEG compression deformations, MIFT F-score was higher than SIFT for most parameter cases.
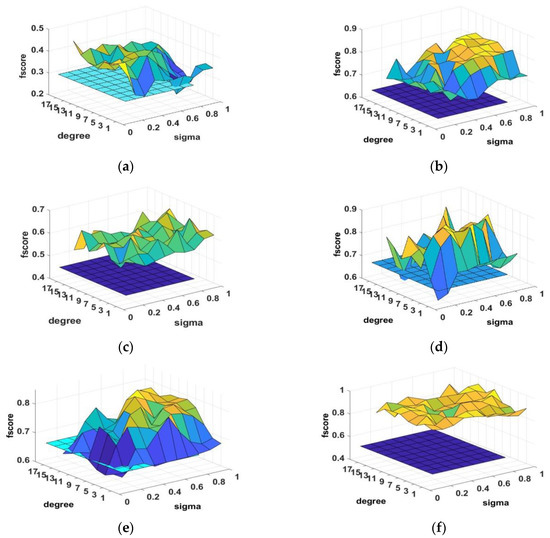
Figure 9.
F-score comparison between MIFT and SIFT for (a) scale; (b) rotation; (c) viewpoint; (d) image blur; (e) JPEG-compression; and (f) illumination distortions.
Thus, the proposed MIFT method always provided superior performance than SIFT for appropriate parameter choices. MIFT exhibited the best efficiency in terms of matching accuracy when derivative order ≈ 3–7 and sigma ≈ 0.3–0.5.
4.2. Motion Compensation Application
We applied MIFT to ego-motion compensation for a humanoid robot. Vision information obtained from a humanoid robot exhibits deformations while walking, hence compensation is mandatory to recognize the walking environment.
We first simulated an ego-motion image sequence from ideal data by including x and y axis displacement and rotation, and then calculated the apparent displacement using MIFT and SIFT, as shown in Figure 10, where the left images show the estimation, and the right images show the error. We calculated error by comparing SIFT and MIFT algorithm outcomes with ideal data. MIFT achieved significantly superior performance than SIFT, as shown in Figure 10 and summarized in Table 3.
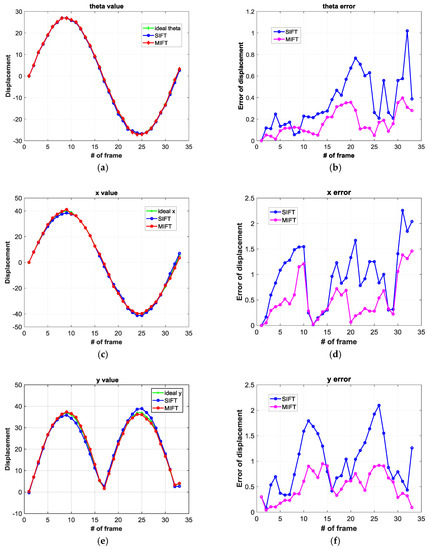
Figure 10.
Motion compensation for distorted ideal images, where left images are the recovered displacement, and right images show the error for (a,b) rotation angle (theta), (c,d) x axis displacement, and (e,f) y axis displacement distortions.
Table 3.
Distorted ideal image ego-motion estimation error.
Finally, we mounted an SR4000 camera on a humanoid robot and evaluated algorithm errors using real image sequences, as summarized in Table 4. Figure 11 shows a sample image sequence from the humanoid robot and Figure 12 shows the corresponding image sequence after ego-motion compensation calculated using the proposed MIFT method.
Table 4.
Humanoid robot [16] and camera specifications.

Figure 11.
Image sequence obtained from the humanoid robot. Sequence timeline proceeds left to right and top to bottom.

Figure 12.
Image sequence of Figure 11 after ego-motion compensation using the proposed MIFT method.
The proposed MIFT method provided significantly superior compensation and was practically useful and applicable to a real-world humanoid robot.
5. Conclusions
We proposed MIFT, an MDGHM based invariant feature transform descriptor. The SIFT-based descritpors are still sensitive to more complicated deformations because of the property of DoG used for the construction of scale-space. We proposed an MDGHM based pyramid which is less sensitive to noise and can provide more distinctive feature information than DoG, and calculated MDGHM based magnitude, orientation, and keypoint descriptors to improve the robustness of local features. We then performed experiment to compare the proposed MIFT method with various conventional SIFT approaches and parameter settings for six deformation types. The results confirmed that the proposed MIFT method provided significantly improved matching accuracy compared with conventional SIFT algorithms. We also evaluated performance effects for MDGHM parameter selections and showed that the proposed MIFT method outperformed conventional SIFT algorithms for most parameter settings. We then applied MIFT to ego-motion compensation for a humanoid robot.
However, adaptive parameter tuning for derivative orders, mask size, and MDGHM variance; and applying the proposed MIFT method to particular areas, such as image stitching and robot environment recognition, remain to be considered in future studies.
Author Contributions
Conceptualization, T.-K.K. and M.-T.L.; Funding acquisition, T.-K.K. and M.-T.L.; Methodology, H.-J.Z. and D.-W.K.; Project administration, T.-K.K.; Supervision, M.-T.L.; Validation, H.-Z.Z.; Visualization, D.-W.K. and M.-T.L.; Writing—original draft, H.-Z.Z; and Writing—review and editing, T.-K.K. and M.-T.L.
Funding
This work was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF2016R1D1A1B01016071 and NRF-2016R1D1A1B03936281).
Acknowledgments
This work was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF2016R1D1A1B01016071 and NRF-2016R1D1A1B03936281).
Conflicts of Interest
The authors declare that they have no conflict of interest with respect to this study.
References
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, G.; Jia, Z. An image stitching algorithm based on histogram matching and SIFT algorithm. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1754006. [Google Scholar] [CrossRef]
- Ma, W.; Wen, Z.; Wu, Y.; Jiao, L.; Gong, M.; Zheng, Y.; Liu, L. Remote sensing image registration with modified sift and enhanced feature matching. IEEE Geosci. Remote Sens. Lett. 2017, 14, 3–7. [Google Scholar] [CrossRef]
- Du, Y.; Wu, C.; Zhao, D.; Chang, Y.; Li, X.; Yang, S. SIFT-based target recognition in robot soccer. Key Eng. Mater. 2016, 693, 1419–1427. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 506–513. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed]
- Kang, T.K.; Zhang, H.Z.; Kim, D.W.; Park, G.T. Enhanced SIFT descriptor based on modified discrete Gaussian–Hermite moment. ETRI J. 2012, 34, 572–582. [Google Scholar] [CrossRef][Green Version]
- Junaid, B.; Dailey, M.N.; Satoh, S.; Nitin, A.; Maheen, B. BIG-OH: Binarization of gradient orientation histograms. Image Vis. Comput. 2014, 32, 940–953. [Google Scholar]
- Juan, L.; Gwun, O. A comparison of SIFT, PCA-SIFT and SURF. Int. J. Image Proc. 2009, 3, 143–152. [Google Scholar]
- Shen, J. Orthogonal Gaussian–Hermite moments for image characterization. SPIE Intelligent Robots Computer Vision XVI. In Proceedings of the Intelligent Systems and Advanced Manufacturing, Pittsburgh, PA, USA, 14–17 October 1997; pp. 224–233. [Google Scholar]
- Yang, B.; Dai, M. Image analysis by Gaussian–Hermite moments. Signal Process. 2011, 91, 2290–2303. [Google Scholar] [CrossRef]
- Lisin, D.; Mattar, M.; Blaschko, M.; Benfield, M.; Learned-Miller, E. Combining local and global image features for object class recognition. In Proceedings of the IEEE Workshop on Learning in Computer Vision and Pattern Recognition, San Diego, CA, USA, 21–23 September 2005; p. 47. [Google Scholar]
- Kang, T.K.; Choi, I.H.; Lim, M.T. MDGHM-SURF: A robust local image descriptor based on modified discrete Gaussian-Hermite moment. Pattern Recognit. 2015, 48, 670–684. [Google Scholar] [CrossRef]
- Available online: http://www.robots.ox.ac.uk/~vgg/research/affine (accessed on 10 April 2019).
- Kang, T.K.; Zhang, H.Z.; Park, G.T.; Kim, D.W. Ego-motion-compensated object recognition using type-2 fuzzy set for a moving robot. Neurocomputing 2013, 120, 130–140. [Google Scholar] [CrossRef]

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).