Compressed Learning of Deep Neural Networks for OpenCL-Capable Embedded Systems


Abstract
:1. Introduction
1.1. Related Work
1.1.1. Network Pruning
1.1.2. Network Pruning as Optimization
1.2. Contribution
- Full model training is required prior to model compression: in network pruning [23,24], including the state-of-the-art method [33], and low-rank approximation [16,17,18,19], full models have to be trained first, which would be too burdensome to run on small computing devices. In addition, compression must be followed by retraining or fine-tuning steps with a substantial number of training iterations, since, otherwise, the compressed models tend to show impractically low prediction accuracy, as we show in our experiments.
- Platforms are restricted: existing approaches [23,24,25] have been implemented and evaluated mainly on CPUs because sparse weight matrices produced by model compression typically have irregular nonzero patterns and therefore are not suitable for GPU computation. In Wen et al. [25], some evaluations have been performed on GPUs, but it was implemented with a proprietary sparse matrix library (cuSPARSE) only available on the NVIDIA platforms (Santa Clara, CA, USA). He et al. [39] considered auto-tuning of model compression experimented on NVIDIA GPU and a mobile CPU on Google Pixel-1 (Mountain View, CA, USA), yet without discussion on how to implement them efficiently on embedded GPUs.
2. Method
2.1. Sparse Coding in Training
2.2. Proximal Operators
2.3. Optimization Algorithm
| Algorithm 1. Prox-RMSProp Algorithm |
| Input: a learning rate , a safeguard parameter , : a decay rate Initialize the weight vector ; (Init. 1st moment vector); (Init. timestep); while not converged do  return ; |
| Algorithm 2. Prox-ADAM Algorithm |
| Input: a learning rate , a safeguard parameter , : decay rates Initialize the weight vector ; (Init. 1st moment vector); (Init. 2nd moment vector); (Init. timestep); while not converged do  |
2.4. Retraining
3. Accelerated OpenCL Operations
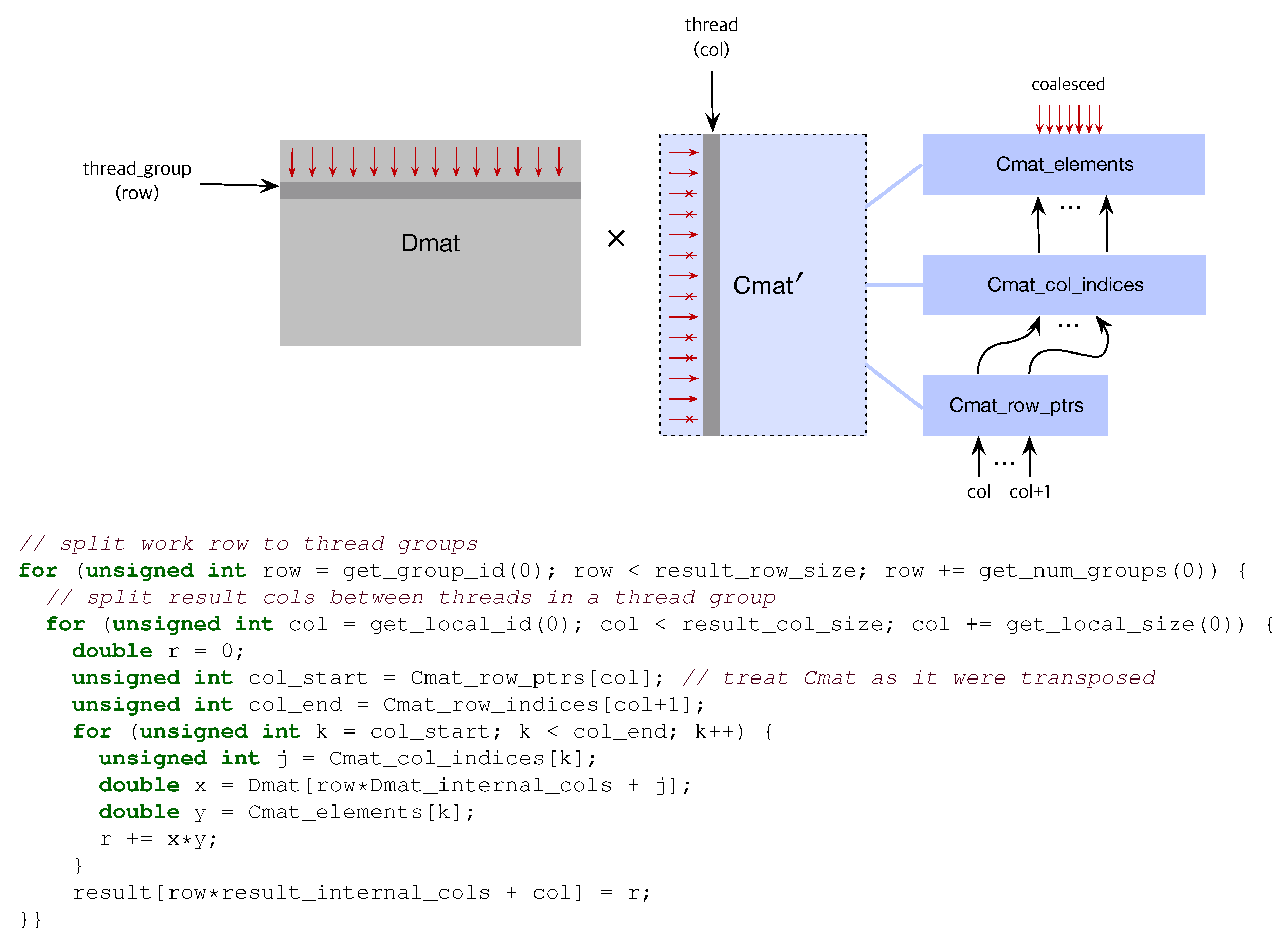
3.1. Compressed Sparse Matrix
3.2. Sparse Matrix Multiplication in OpenCL
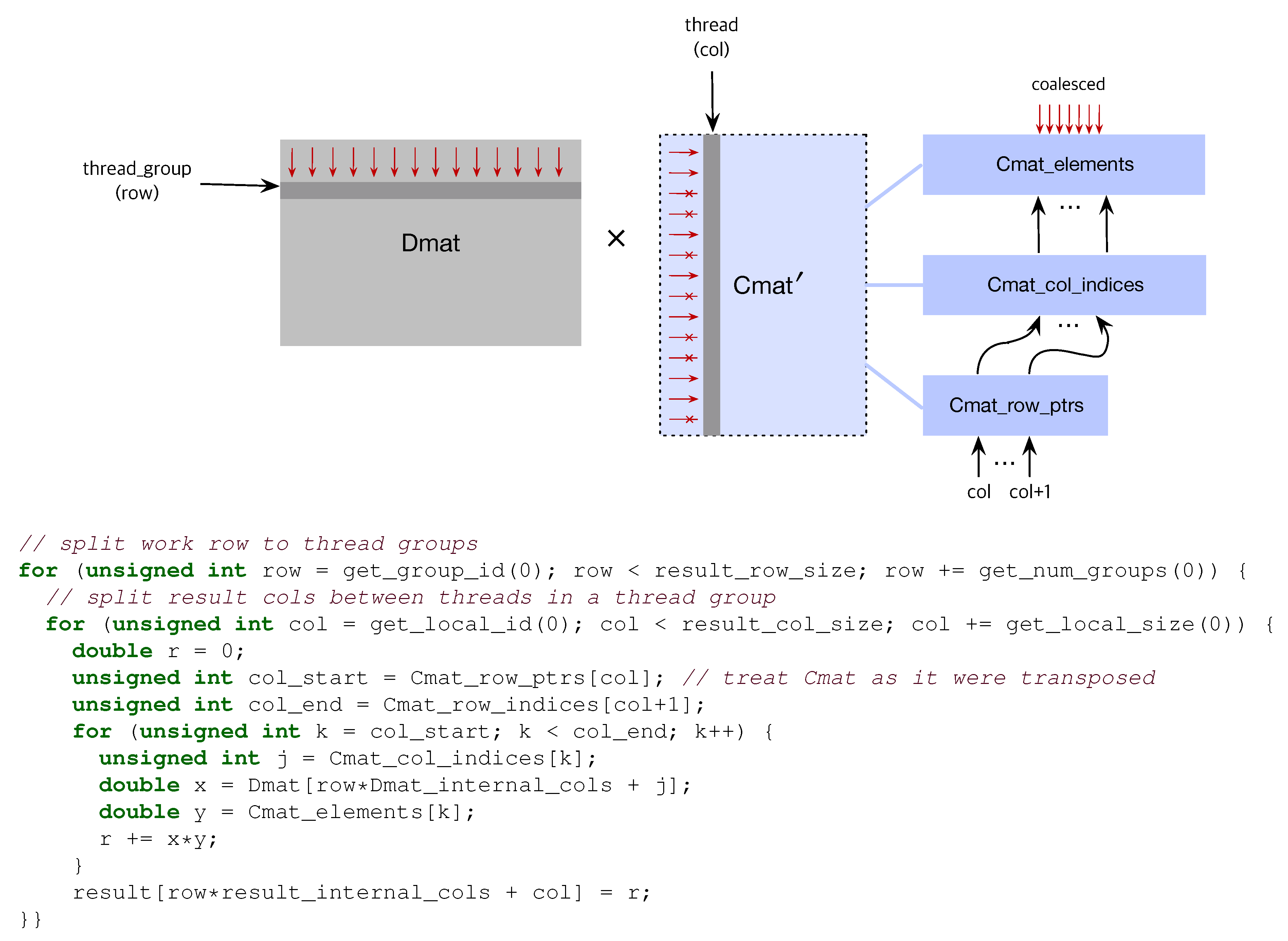
3.2.1. Dense × Compressed
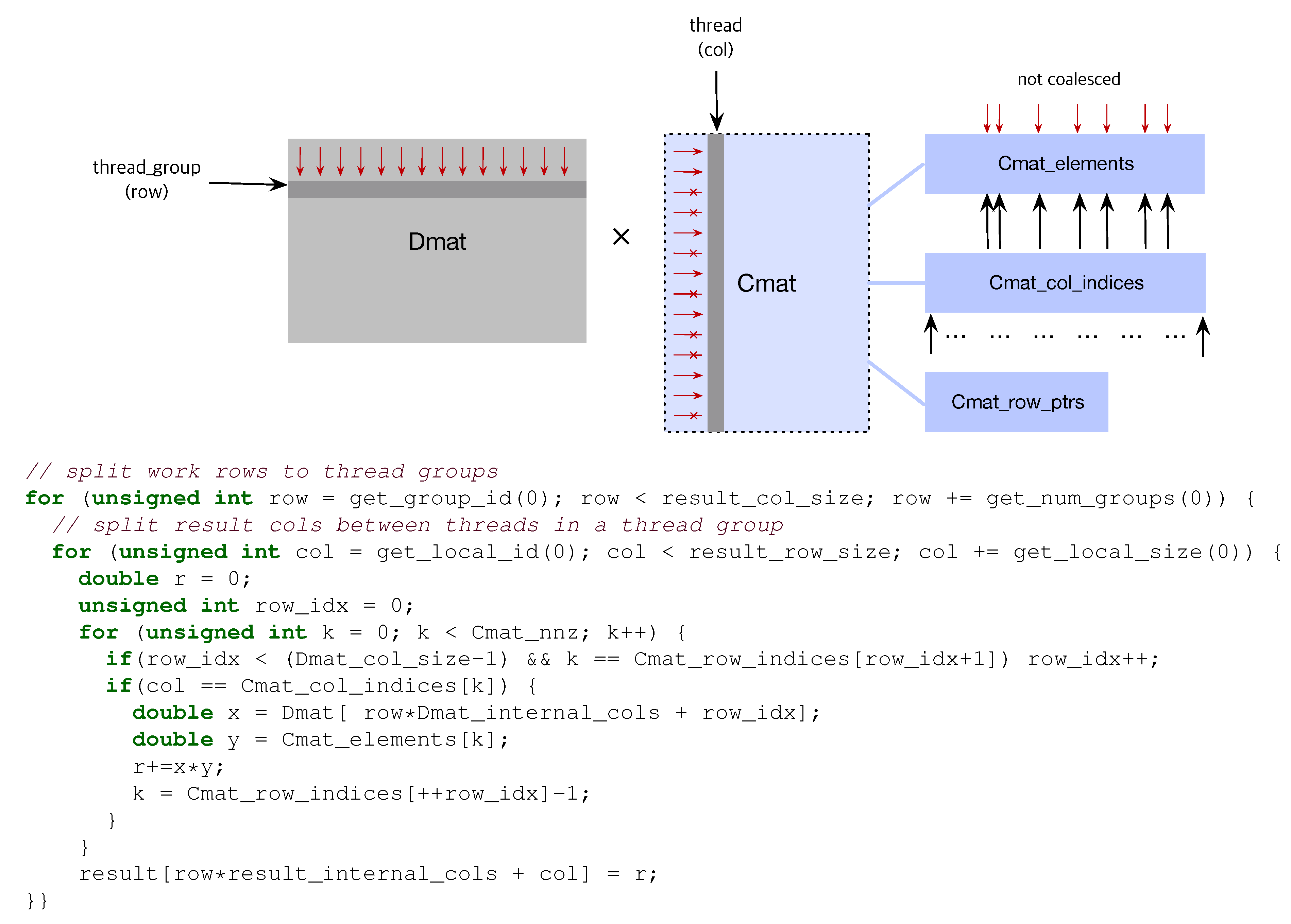
3.2.2. Dense × Compressed
3.3. Prox Operator in OpenCL
4. Experiments
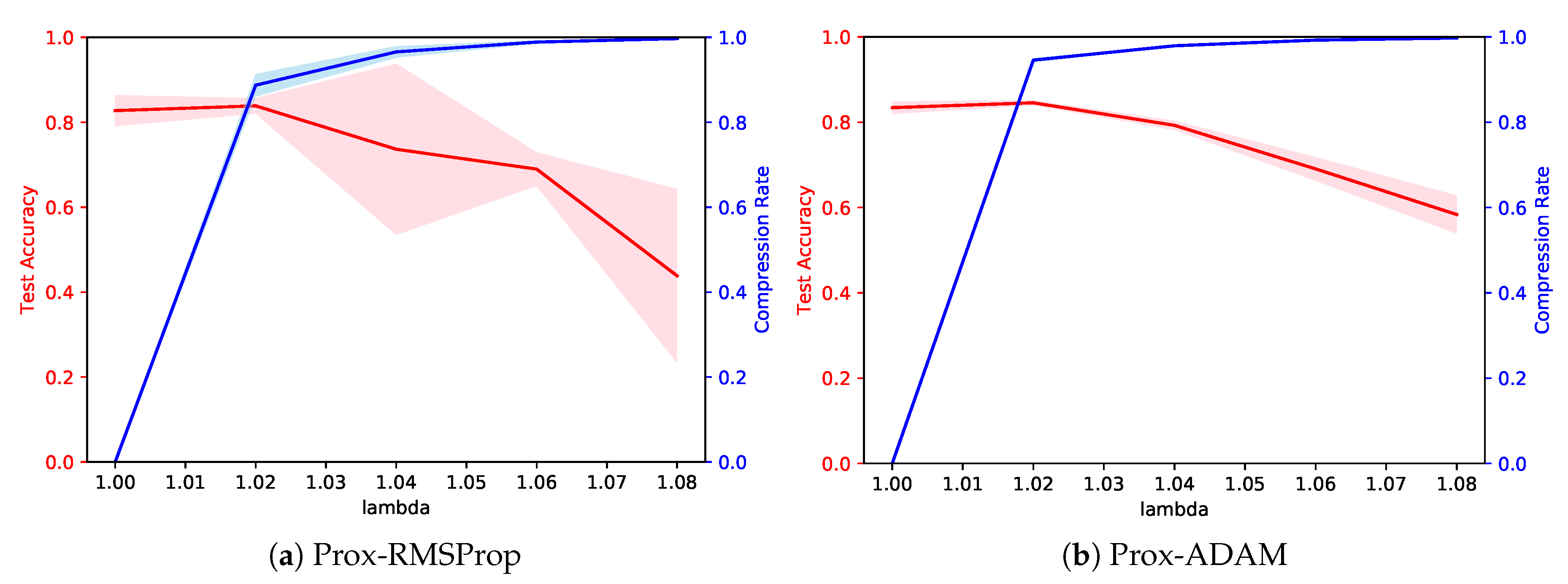
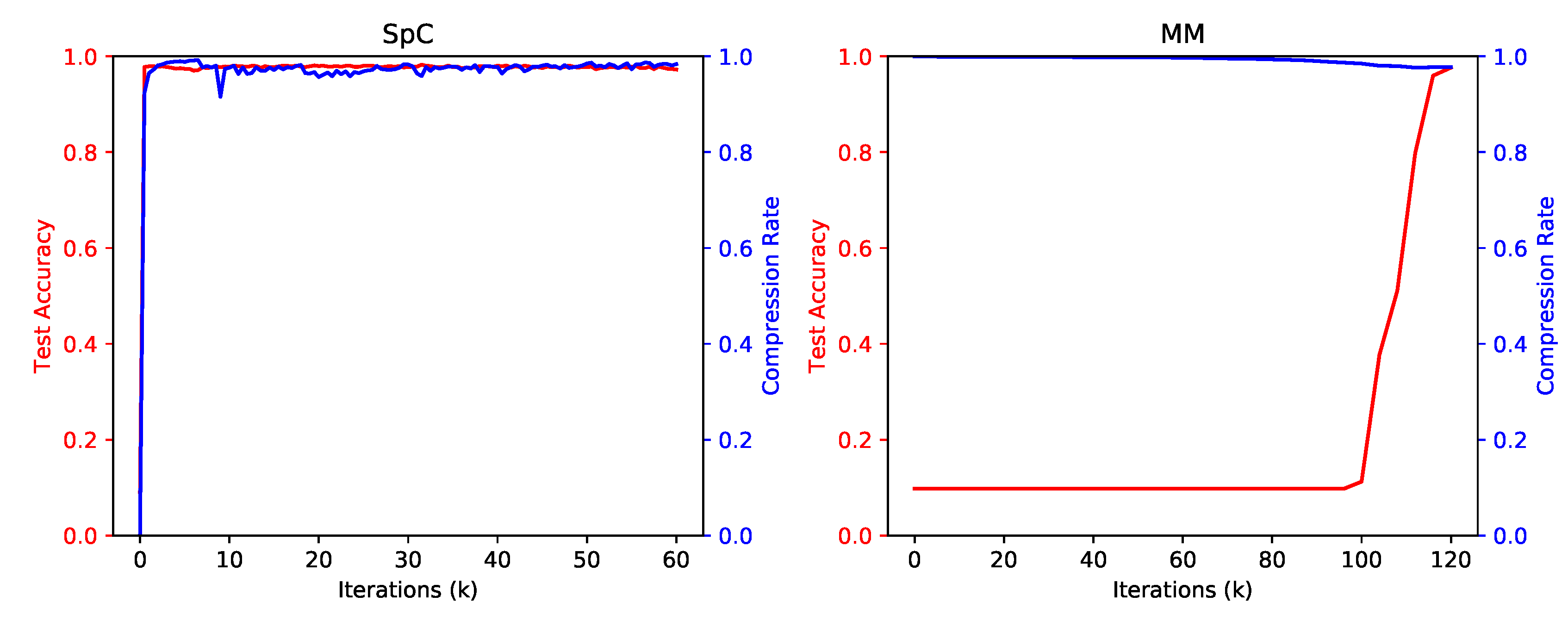
4.1. Comparison of Training Algorithms
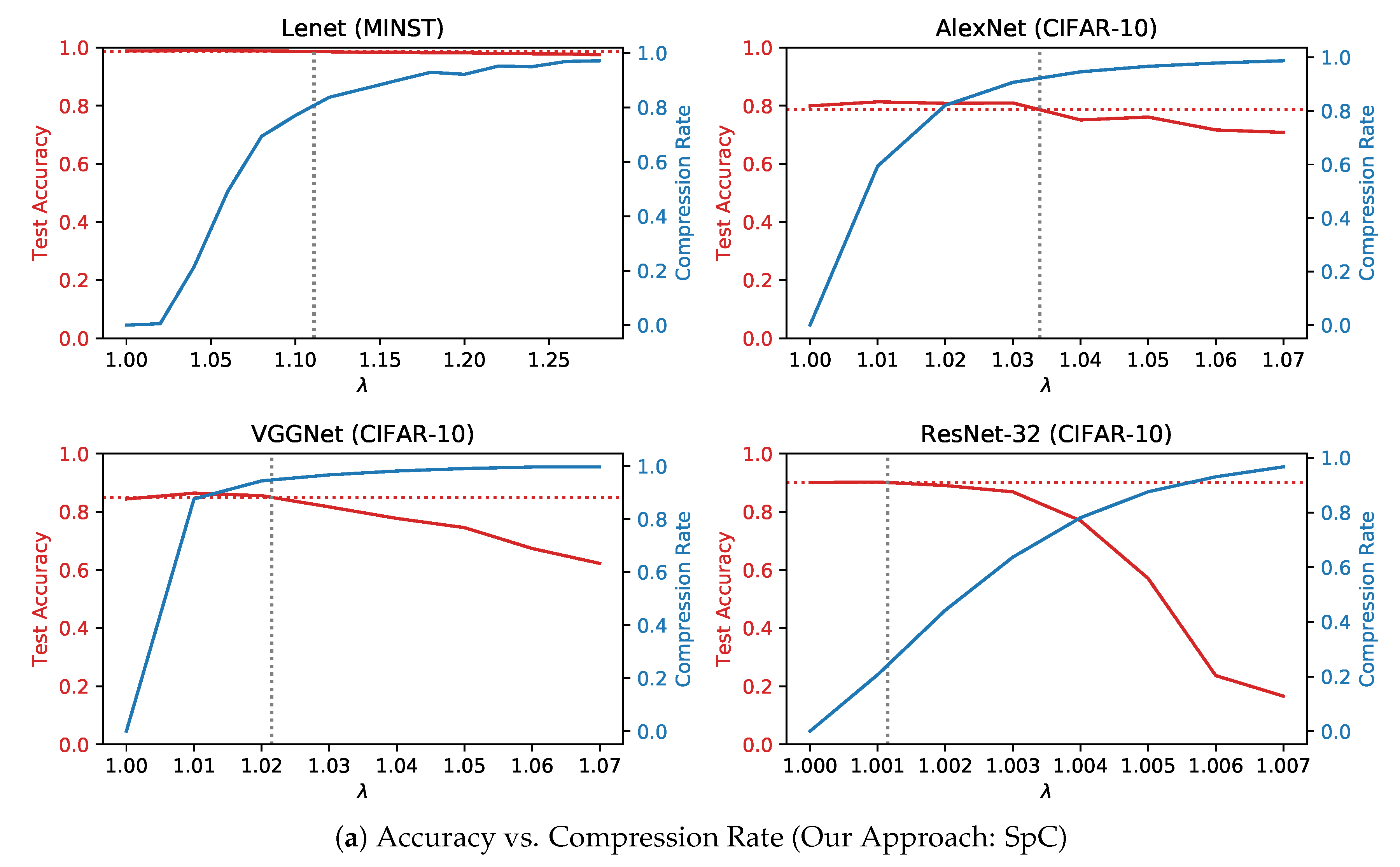
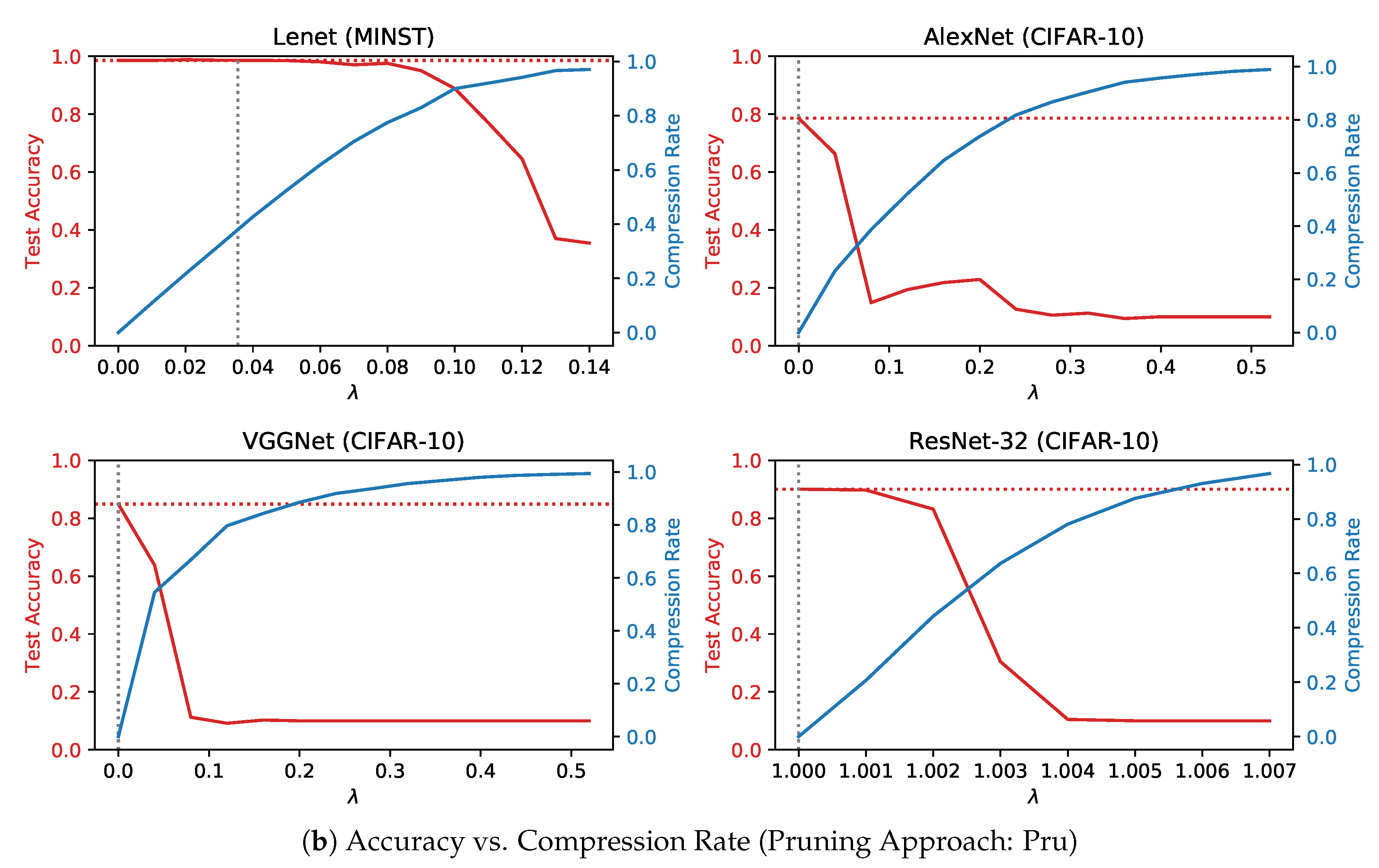
4.2. Compression Rate and Prediction Accuracy
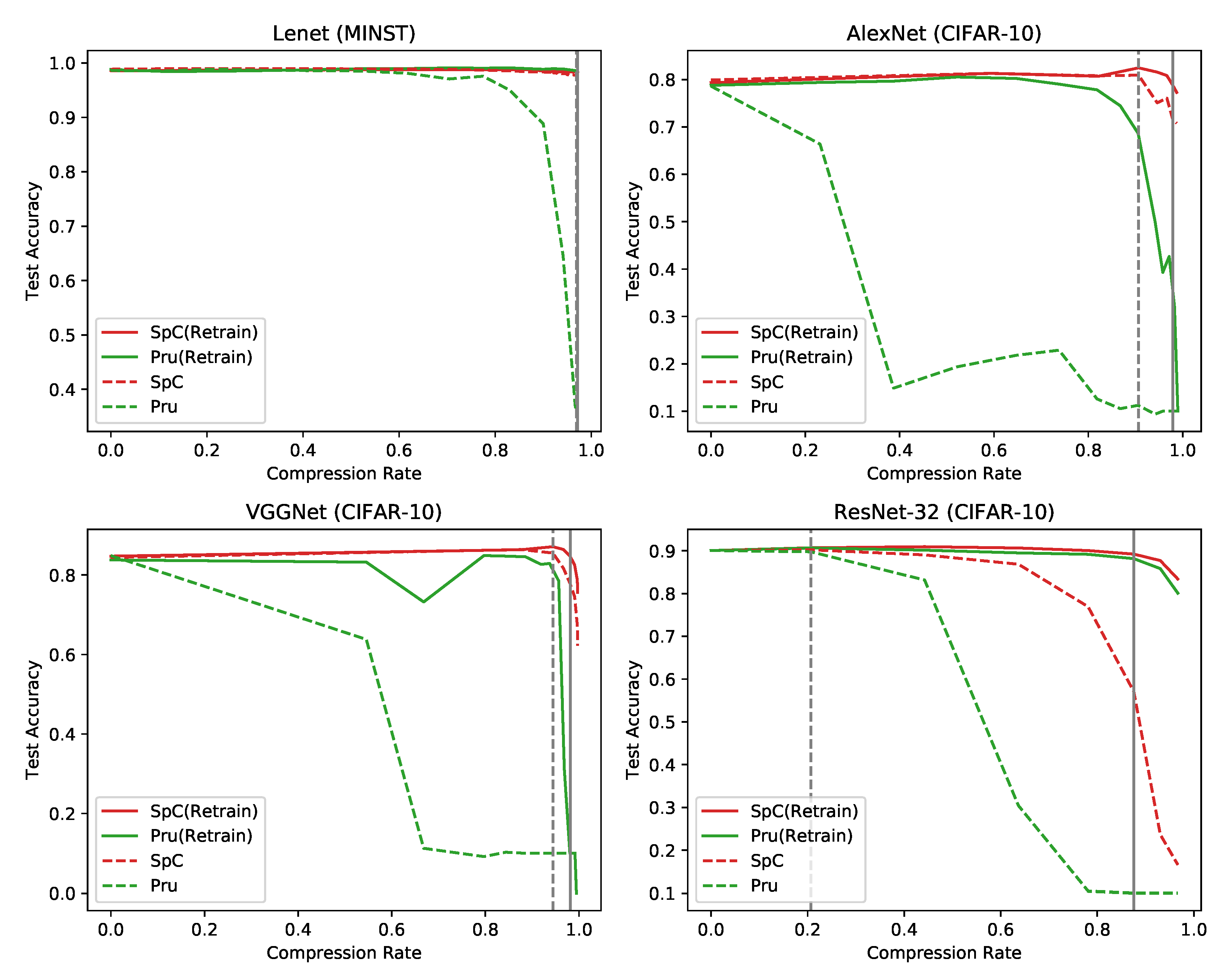
4.3. The Effect of Retraining
4.4. Comparison to the State-of-the-Art Approach
4.5. Performance on Embedded Systems
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Layer-Wise Compression Rate

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | SpC | SpC(Retrain) | ||
|---|---|---|---|---|
| Layers | NNZ/Total Weights | Compression Rate | NNZ/Total Weights | Compression Rate |
| conv1 | 158/500 | 68.40% (3×) | 142/500 | 71.60% (3×) |
| conv2 | 2101/25,000 | 91.60% (11×) | 1750/25,000 | 93.00% (14×) |
| fc1 | 10,804/400,000 | 97.30% (37×) | 10,045/400,000 | 97.49% (39×) |
| fc2 | 270/5000 | 94.60% (18×) | 280/5000 | 94.40% (17×) |
| Total | 13,333/430,500 | 96.90% (32×) | 12,217/430,500 | 97.16% (35×) |
| Test Accuracy | 0.9778 @ = 1.26 | Ref: 0.9861 | 0.9829 @ = 1.28 | Ref: 0.9861 |
| Methods | SpC | SpC(Retrain) | ||
|---|---|---|---|---|
| Layers | NNZ/Total Weights | Compression Rate | NNZ/Total Weights | Compression Rate |
| conv1 | 3922/7200 | 45.53% (1×) | 2054/7200 | 71.47% (3×) |
| conv2 | 76,321/307,200 | 75.16% (4×) | 19,464/307,200 | 93.66% (15×) |
| conv3 | 153,921/884,736 | 82.60% (5×) | 27,757/88,4736 | 96.86% (31×) |
| conv4 | 153,000/663,552 | 76.94% (4×) | 21,485/663,552 | 96.76% (30×) |
| conv5 | 516,47/442,368 | 88.32% (8×) | 15,690/442,368 | 96.45% (28×) |
| fc1 | 179,344/4,194,304 | 95.72% (23×) | 52,429/4,194,304 | 98.75% (79×) |
| fc2 | 84,495/1,048,576 | 91.94% (12×) | 18,841/1,048,576 | 98.20% (55×) |
| fc3 | 3701/10,240 | 63.86% (2×) | 2329/10,240 | 77.26% (4×) |
| Total | 706,351/7,558,176 | 90.65% (10×) | 160,049/7,558,176 | 97.88% (47×) |
| Test Accuracy | 0.8093 @ = 1.03 | Ref: 0.7861 | 0.7884 @ = 1.06 | Ref: 0.7861 |
| Methods | SpC | SpC(Retrain) | ||
|---|---|---|---|---|
| Layers | NNZ/Total Weights | Compression Rate | NNZ/Total Weights | Compression Rate |
| conv1-1 | 1160/1728 | 32.87% (1×) | 757/1728 | 56.19% (2×) |
| conv1-2 | 18,904/36,864 | 48.72% (1×) | 9389/36,864 | 74.53% (3×) |
| conv2-1 | 47,497/73,728 | 35.58% (1×) | 20943/73,728 | 71.59% (3×) |
| conv2-2 | 87,314/147,456 | 40.79% (1×) | 30,040/147,456 | 79.63% (4×) |
| conv3-1 | 133,402/294,912 | 54.77% (2×) | 40,039/294,912 | 86.42% (7×) |
| conv3-2 | 120,094/589,824 | 79.64% (4×) | 30,997/589,824 | 94.74% (19×) |
| conv3-3 | 94,612/589,824 | 83.96% (6×) | 16,071/589,824 | 97.28% (36×) |
| conv4-1 | 164,660/1,179,648 | 86.04% (7×) | 20,322/1,179,648 | 98.28% (58×) |
| conv4-2 | 133,944/2,359,296 | 94.32% (17×) | 22,145/2,359,296 | 99.06% (106×) |
| conv4-3 | 59,355/2,359,296 | 97.48% (39×) | 28,173/2,359,296 | 98.81% (83×) |
| conv5-1 | 16,749/2,359,296 | 99.29% (140×) | 21,349/2,359,296 | 99.10% (110×) |
| conv5-2 | 10,769/2,359,296 | 99.54% (219×) | 30,008/2,359,296 | 98.73% (78×) |
| conv5-3 | 10,987/2,359,296 | 99.53% (214×) | 24,027/2,359,296 | 98.98% (98×) |
| fc1 | 4176/524,288 | 99.20% (125×) | 6072/524,288 | 98.84% (86×) |
| fc2 | 5915/1,048,576 | 99.44% (177×) | 4007/1,048,576 | 99.62% (261×) |
| fc3 | 508/10,240 | 95.04% (20×) | 223/10,240 | 97.82% (45×) |
| Total | 910,046/16,293,568 | 94.41% (17×) | 304,562/16,293,568 | 98.13% (53×) |
| Test Accuracy | 0.8553 @ = 1.02 | Ref: 0.8488 | 0.8463 @ = 1.04 | Ref: 0.8488 |
| Methods | SpC | SpC(Retrain) | ||
|---|---|---|---|---|
| Layers | NNZ/Total Weights | Compression Rate | NNZ/Total Weights | Compression Rate |
| conv1 | 379/432 | 12.27% (1×) | 139/432 | 67.82% (3×) |
| conv1-1-1 | 1844/2304 | 19.97% (1×) | 327/2304 | 85.81% (7×) |
| conv1-1-2 | 1870/2304 | 18.84% (1×) | 337/2304 | 85.37% (6×) |
| conv1-2-1 | 1874/2304 | 18.66% (1×) | 334/2304 | 85.50% (6×) |
| conv1-2-2 | 1873/2304 | 18.71% (1×) | 341/2304 | 85.20% (6×) |
| conv1-3-1 | 1847/2304 | 19.84% (1×) | 330/2304 | 85.68% (6×) |
| conv1-3-2 | 1872/2304 | 18.75% (1×) | 322/2304 | 86.02% (7×) |
| conv1-4-1 | 1874/2304 | 18.66% (1×) | 363/2304 | 84.24% (6×) |
| conv1-4-2 | 1852/2304 | 19.62% (1×) | 344/2304 | 85.07% (6×) |
| conv1-5-1 | 1859/2304 | 19.31% (1×) | 355/2304 | 84.59% (6×) |
| conv1-5-2 | 1835/2304 | 20.36% (1×) | 326/2304 | 85.85% (7×) |
| conv2-1-1 | 3700/4608 | 19.70% (1×) | 666/4608 | 85.55% (6×) |
| conv2-1-2 | 7316/9216 | 20.62% (1×) | 1108/9216 | 87.98% (8×) |
| conv2-1-proj | 467/512 | 8.79% (1×) | 225/512 | 56.05% (2×) |
| conv2-2-1 | 7292/9216 | 20.88% (1×) | 1191/9216 | 87.08% (7×) |
| conv2-2-2 | 7325/9216 | 20.52% (1×) | 1160/9216 | 87.41% (7×) |
| conv2-3-1 | 7394/9216 | 19.77% (1×) | 1198/9216 | 87.00% (7×) |
| conv2-3-2 | 7371/9216 | 20.02% (1×) | 1160/9216 | 87.41% (7×) |
| conv2-4-1 | 7323/9216 | 20.54% (1×) | 1222/9216 | 86.74% (7×) |
| conv2-4-2 | 7368/9216 | 20.05% (1×) | 1200/9216 | 86.98% (7×) |
| conv2-5-1 | 7265/9216 | 21.17% (1×) | 1223/9216 | 86.73% (7×) |
| conv2-5-2 | 7303/9216 | 20.76% (1×) | 1179/9216 | 87.21% (7×) |
| conv3-1-1 | 14,757/18,432 | 19.94% (1×) | 2411/18,432 | 86.92% (7×) |
| conv3-1-2 | 29,393/36,864 | 20.27% (1×) | 4281/36,864 | 88.39% (8×) |
| conv3-1-proj | 1815/2048 | 11.38% (1×) | 638/2048 | 68.85% (3×) |
| conv3-2-1 | 29,423/36,864 | 20.19% (1×) | 4399/36,864 | 88.07% (8×) |
| conv3-2-2 | 29,372/36,864 | 20.32% (1×) | 4442/36,864 | 87.95% (8×) |
| conv3-3-1 | 29,332/36,864 | 20.43% (1×) | 4427/36,864 | 87.99% (8×) |
| conv3-3-2 | 29,244/36,864 | 20.67% (1×) | 4392/36,864 | 88.09% (8×) |
| conv3-4-1 | 29,264/36,864 | 20.62% (1×) | 4450/36,864 | 87.93% (8×) |
| conv3-4-2 | 28,954/36,864 | 21.46% (1×) | 4413/36,864 | 88.03% (8×) |
| conv3-5-1 | 28,770/36,864 | 21.96% (1×) | 4469/36,864 | 87.88% (8×) |
| conv3-5-2 | 28,455/36,864 | 22.81% (1×) | 4381/36,864 | 88.12% (8×) |
| fc1 | 570/640 | 10.94% (1×) | 298/640 | 53.44% (2×) |
| Total | 368,452/464,432 | 20.67% (1×) | 58,051/464,432 | 87.50% (8×) |
| Test Accuracy | 0.9022 @ = 1.001 | Ref: 0.9005 | 0.8922 @ = 1.005 | Ref: 0.9005 |
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 5–6. [Google Scholar] [CrossRef] [PubMed]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Computer Vision (ECCV 2014), Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–02826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Coates, A.; Huval, B.; Wang, T.; Wu, D.; Catanzaro, B.; Andrew, N. Deep learning with COTS HPC systems. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1337–1345. [Google Scholar]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C. Lessons in Neural Network Training: Overfitting May be Harder than Expected. In Proceedings of the Fourtheenth National Conference on Artificial Intelligence (AAAI’97), Providence, RI, USA, 27–31 July 1997. [Google Scholar]
- Buyya, R.; Yeo, C.S.; Venugopal, S.; Broberg, J.; Brandic, I. Cloud Computing and Emerging IT Platforms: Vision, Hype, and Reality for Delivering Computing As the 5th Utility. Future Gener. Comput. Syst. 2009, 25, 599–616. [Google Scholar] [CrossRef]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up Convolutional Neural Networks with Low Rank Expansions. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Denton, E.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation. In Advances in Neural Information Processing Systems 27; Curran Associates, Inc.: New York, NY, USA, 2014; pp. 1269–1277. [Google Scholar]
- Ioannou, Y.; Robertson, D.P.; Shotton, J.; Cipolla, R.; Criminisi, A. Training cnns with low-rank filters for efficient image classification. In Proceedings of the International Conference on Learning Representations, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Tai, C.; Xiao, T.; Wang, X.; E, W. Convolutional neural networks with low-rank regularization. In Proceedings of the International Conference on Learning Representations, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Hanson, S.J.; Pratt, L.Y. Comparing Biases for Minimal Network Construction with Back-Propagation. In Advances in Neural Information Processing Systems 1; Morgan-Kaufmann: Burlington, MA, USA, 1989; pp. 177–185. [Google Scholar]
- LeCun, Y.; Denker, J.S.; Solla, S.A. Optimal Brain Damage. In Advances in Neural Information Processing Systems 2; Morgan-Kaufmann: Burlington, MA, USA, 1990; pp. 598–605. [Google Scholar]
- Hassibi, B.; Stork, D.G. Second order derivatives for network pruning: Optimal Brain Surgeon. In Advances in Neural Information Processing Systems 5; Morgan-Kaufmann: Burlington, MA, USA, 1993; pp. 164–171. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning Both Weights and Connections for Efficient Neural Networks. In Advances in Neural Information Processing Systems 28; Curran Associates, Inc.: New York, NY, USA, 2015; pp. 1135–1143. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the International Conference on Learning Representations, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning Structured Sparsity in Deep Neural Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016; pp. 2082–2090. [Google Scholar]
- Lebedev, V.; Lempitsky, V. Fast ConvNets Using Group-Wise Brain Damage. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2554–2564. [Google Scholar]
- Shalev-Shwartz, S.; Tewari, A. Stochastic Methods for l1 Regularized Loss Minimization. In Proceedings of the 26th International Conference on Machine Learning (ICML), Montreal, QC, Canada, 14–18 June 2009; pp. 929–936. [Google Scholar]
- Duchi, J.C.; Singer, Y. Efficient Learning using Forward-Backward Splitting. In Advances in Neural Information Processing Systems 22; Curran Associates, Inc.: New York, NY, USA, 2009; pp. 495–503. [Google Scholar]
- Zhou, H.; Alvarez, J.M.; Porikli, F. Less Is More: Towards Compact CNNs. In Computer Vision (ECCV 2016); Springer: New York, NY, USA, 2016; pp. 662–677. [Google Scholar]
- Parikh, N.; Boyd, S. Proximal Algorithms. Found. Trends Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G. CSC321. Introduction to Neural Networks and Machine Learning; Lecture 6e.; Toronto University: Toronto, ON, Canada, February 2014. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Carreira-Perpiñán, M.Á.; Idelbayev, Y. Learning-Compression Algorithms for Neural Net Pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Hestenes, M.R. Multiplier and gradient methods. J. Optim. Theory Appl. 1969, 4, 303–320. [Google Scholar] [CrossRef]
- Powell, M.J.D. A method for nonlinear constraints in minimization problems. In Optimization; Fletcher, R., Ed.; Academic Press: New York, NY, USA, 1969; pp. 283–298. [Google Scholar]
- Chen, C.; Tung, F.; Vedula, N.; Mori, G. Constraint-Aware Deep Neural Network Compression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. arXiv 2017, arXiv:1707.07012. [Google Scholar]
- He, Y.; Lin, J.; Liu, Z.; Wang, H.; Li, L.J.; Han, S. AMC: AutoML for Model Compression and Acceleration on Mobile Devices. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. Model Compression and Acceleration for Deep Neural Networks: The Principles, Progress, and Challenges. IEEE Signal Process. Mag. 2018, 35, 126–136. [Google Scholar] [CrossRef]
- Lee, H.; Battle, A.; Raina, R.; Ng, A.Y. Efficient sparse coding algorithms. In Advances in Neural Information Processing Systems 19; MIT Press: Cambridge, MA, USA, 2007; pp. 801–808. [Google Scholar]
- Needell, D.; Tropp, J. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmon. Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef] [Green Version]
- Bao, C.; Ji, H.; Quan, Y.; Shen, Z. Dictionary Learning for Sparse Coding: Algorithms and Convergence Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1356–1369. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. (Ser. B) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Candes, E.; Tao, T. The Dantzig Selector: Statistical Estimation When P Is Much Larger Than N. Ann. Stat. 2007, 35, 2313–2351. [Google Scholar] [CrossRef]
- Candes, E.J.; Tao, T. Decoding by linear programming. IEEE Trans. Inf. Theory 2005, 51, 4203–4215. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candes, E.; Plan, Y. Matrix Completion with Noise. Proc. IEEE 2010, 98, 925–936. [Google Scholar] [CrossRef]
- Nemirovski, A.; Juditsky, A.; Lan, G.; Shapiro, A. Robust Stochastic Approximation Approach to Stochastic Programming. SIAM J. Optim. 2009, 19, 1574–1609. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Lee, S.; Wright, S. Manifold Identification of Dual Averaging Methods for Regularized Stochastic Online Learning. In Proceedings of the 28th International Conference on Machine Learning (ICML), Bellevue, WA, USA, 28 June–2 July 2011; pp. 1121–1128. [Google Scholar]
- Auslender, A.; Teboulle, M. Interior Gradient and Proximal Methods for Convex and Conic Optimization. SIAM J. Optim. 2006, 16, 697–725. [Google Scholar] [CrossRef]
- Nitanda, A. Stochastic Proximal Gradient Descent with Acceleration Techniques. In Advances in Neural Information Processing Systems 27; Curran Associates, Inc.: New York, NY, USA, 2014; pp. 1574–1582. [Google Scholar]
- Patrascu, A.; Necoara, I. Nonasymptotic convergence of stochastic proximal point methods for constrained convex optimization. J. Mach. Learn. Res. 2018, 18, 1–42. [Google Scholar]
- Rosasco, L.; Villa, S.; Vu, B.C. Convergence of Stochastic Proximal Gradient Algorithm. arXiv 2014, arXiv:1403.5074. [Google Scholar]
- Polyak, B.T. Some methods of speeding up the convergence of iteration method. USSR Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]
- Wright, S.J.; Nowak, R.D.; Figueiredo, M.A.T. Sparse reconstruction by separable approximation. IEEE Trans. Signal Process. 2009, 57, 2479–2493. [Google Scholar] [CrossRef]
- Figueiredo, M.; Nowak, R.; Wright, S. Gradient projection for sparse reconstruction: application to compressed sensing and other inverse problems. IEEE J. Sel. Top. Signal Process. 2007, 1, 586–598. [Google Scholar] [CrossRef]
- Donoho, D. De-noising by soft thresholding. IEEE Trans. Inf. Theory 1995, 41, 6–18. [Google Scholar] [CrossRef]
- OpenCL-Caffe. Available online: https://github.com/amd/OpenCL-caffe (accessed on 31 August 2018).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- ViennaCL. Available online: http://viennacl.sourceforge.net (accessed on 31 August 2018).
- Bell, N.; Garland, M. Efficient Sparse Matrix-Vector Multiplication on CUDA; NVIDIA Technical Report NVR-2008-004; NVIDIA Corporation: Santa Clara, CA, USA, 2008. [Google Scholar]
- Bell, N.; Garland, M. Implementing Sparse Matrix-vector Multiplication on Throughput-oriented Processors. In Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis, Portland, OR, USA, 14–20 November 2009; Volume 18, pp. 1–11. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV ’15), Santiago, Chile, 11–18 December 2015; pp. 1026–1034. [Google Scholar]








| Network | Lenet-5 | AlexNet | VGGNet | ResNet-32 | |
|---|---|---|---|---|---|
| Data | MNIST | CIFAR-10 | CIFAR-10 | CIFAR-10 | |
| Ref. Accuracy | |||||
| Pru | Accuracy | ||||
| Compression Rate | |||||
| Pru (Retrain) | Accuracy | ||||
| Compression Rate | |||||
| SpC | Accuracy | ||||
| Compression Rate | |||||
| SpC (Retrain) | Accuracy | ||||
| Compression Rate | |||||
| Network (Data) | Lenet-5 (MNIST) | ResNet32 (CIFAR10) | ||
|---|---|---|---|---|
| Method | SpC | MM | SpC | MM |
| Pretrained Model | - | Required (Test Acc = 99.1) | - | Required (Test Acc = 92.28) |
| Solver | Prox-Adam | SGD with Momentum | Prox-Adam | Nesterov |
| Aux. Parameter () | - | ( per 4k iter) | - | ( per 2k iter) |
| Accuracy | 97.25% | 97.65% | 89.22% | 92.37% |
| Compression Rate | 0.98 | 0.98 | 0.88 | 0.85 |
| GPU | NVIDIA GTX 1080 TI | ARM Mali-T860 | ||
|---|---|---|---|---|
| Compression | Yes | No | Yes | No |
| Model Size | 148 KB | 5.0 MB | 148 KB | 5.0 MB |
| Inference Time | 8572 ms | 16,977 ms | 506,067 ms | 606,699 ms |
| Speed up | 2× | 1.2× | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Lee, J. Compressed Learning of Deep Neural Networks for OpenCL-Capable Embedded Systems. Appl. Sci. 2019, 9, 1669. https://doi.org/10.3390/app9081669
Lee S, Lee J. Compressed Learning of Deep Neural Networks for OpenCL-Capable Embedded Systems. Applied Sciences. 2019; 9(8):1669. https://doi.org/10.3390/app9081669
Chicago/Turabian StyleLee, Sangkyun, and Jeonghyun Lee. 2019. "Compressed Learning of Deep Neural Networks for OpenCL-Capable Embedded Systems" Applied Sciences 9, no. 8: 1669. https://doi.org/10.3390/app9081669