A Smart System for Text-Lifelog Generation from Wearable Cameras in Smart Environment Using Concept-Augmented Image Captioning with Modified Beam Search Strategy †



Abstract
:Featured Application
Abstract
1. Introduction
- We propose a system for automatically capture footage of users’ daily event and convert the collected images into text format via image captioning method. The system will enable users to keep track of special events in their daily life. The system will keep the information of the events in text format, helping save storage capacity. We also develop smart glasses with cameras. This device not only can easily capture images automatically for processing but also is wearable and fashionable.
- We also propose two improvements in the image captioning method. The first is using more tags to enhance the information input into the caption generator module. The second is adding a new criterion for selecting longer caption during beam search strategy.
2. Materials and Methods
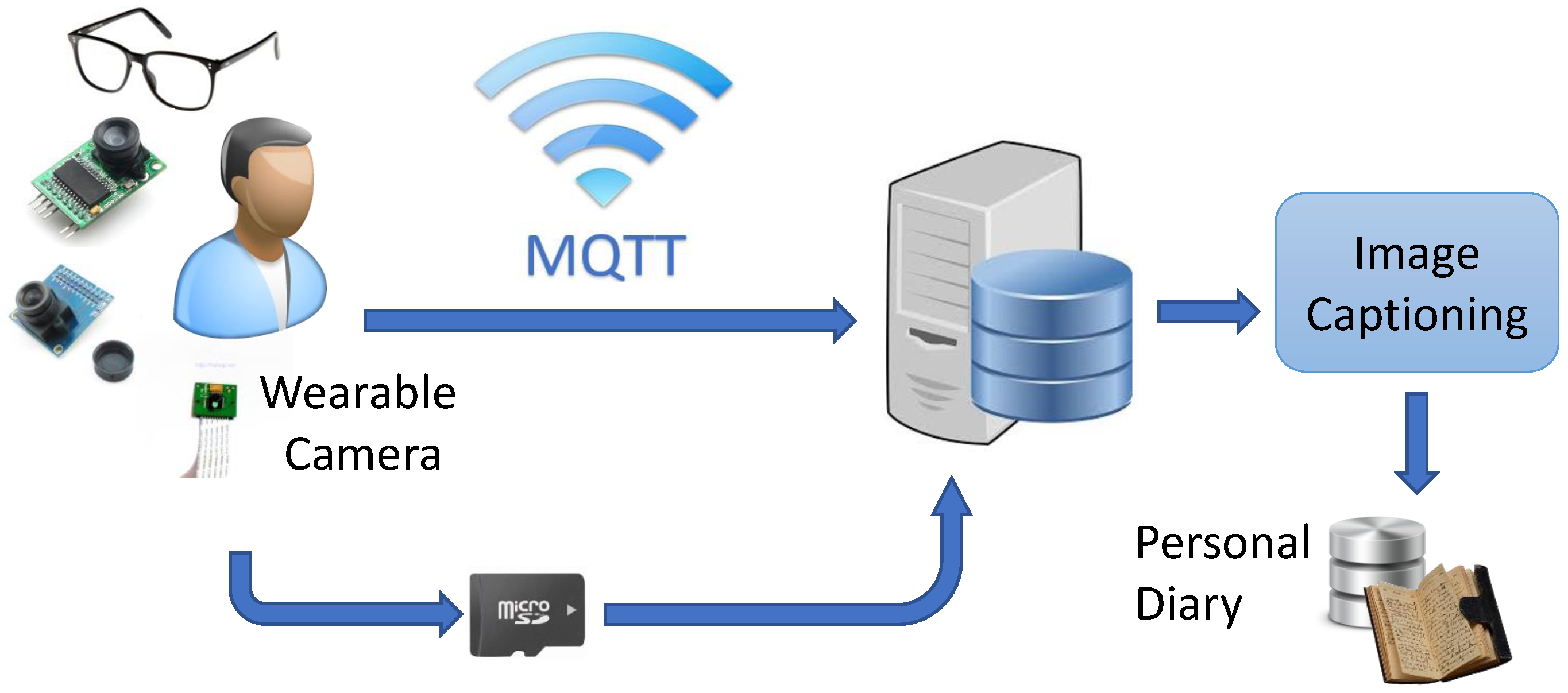
2.1. System Overview
2.2. System Implementation
2.2.1. Smart Glasses With Camera
2.2.2. Connection and Server
2.3. Our Image Captioning Method
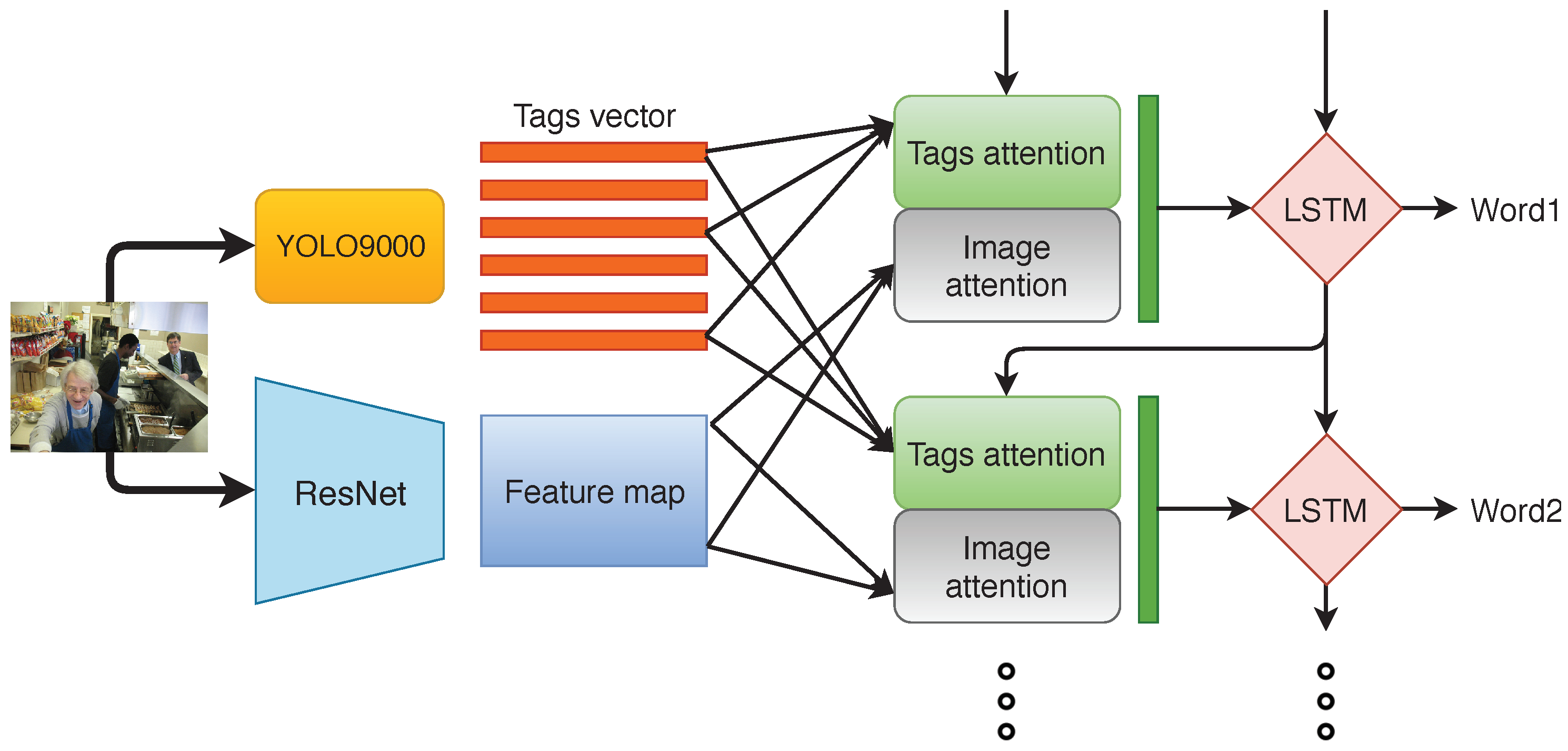
2.3.1. Model Overview
2.3.2. Extracting Image Features
2.3.3. Extracting Tags with YOLO9000
2.3.4. Attention Modules
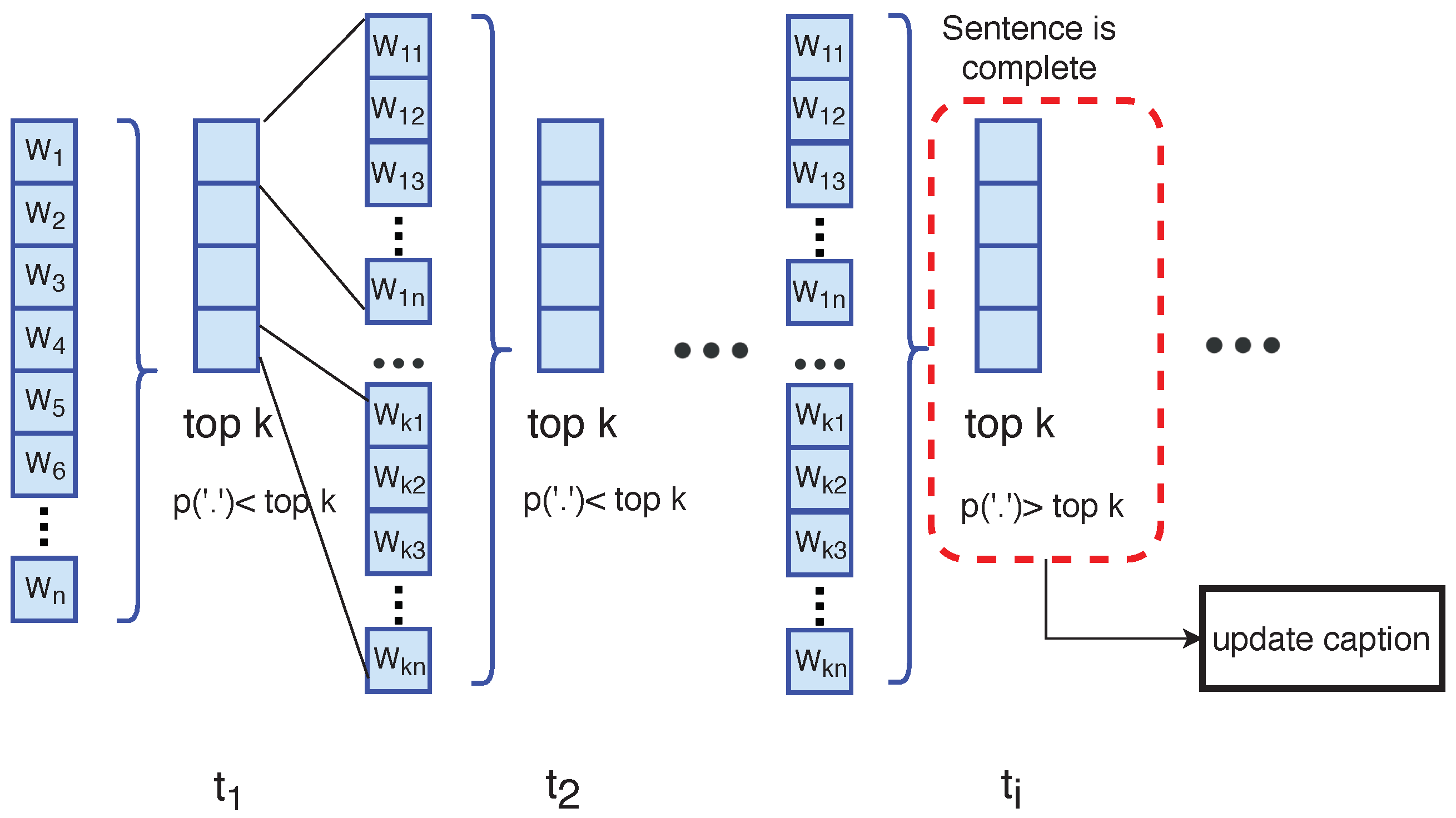
2.3.5. Beam Search Strategy
3. Results
3.1. Datasets
3.2. Evaluation Metrics
3.3. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| LSTM | Long short-term memory |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| IoT | Internet of Things |
| SoICT | Symposium on Information and Communication Technology |
| MS | Microsoft |
| COCO | Common Objects in COntext |
| CLEF | Conference and Labs of the Evaluation Forum |
References
- Nguyen, V.T.; Le, K.D.; Tran, M.T.; Fjeld, M. NowAndThen: A Social Network-based Photo Recommendation Tool Supporting Reminiscence. In Proceedings of the 15th International Conference on Mobile and Ubiquitous Multimedia, Rovaniemi, Finland, 12–15 December 2016; ACM: New York, NY, USA, 2016; pp. 159–168. [Google Scholar]
- Dang-Nguyen, D.T.; Piras, L.; Riegler, M.; Zhou, L.; Lux, M.; Gurrin, C. Overview of ImageCLEFlifelog 2018: Daily Living Understanding and Lifelog Moment Retrieval. In Proceedings of the 5th Italian Workshop on Artificial Intelligence and Robotics (AIRO 2018), Trento, Italy, 22–23 November 2018. [Google Scholar]
- Gurrin, C.; Smeaton, A.F.; Doherty, A.R. LifeLogging: Personal Big Data. Found. Trends Inf. Retr. 2014, 8, 1–125. [Google Scholar] [CrossRef] [Green Version]
- Rawassizadeh, R.; Tomitsch, M.; Wac, K.; Tjoa, A.M. UbiqLog: A generic mobile phone-based life-log framework. Pers. Ubiquitous Comput. 2013, 17, 621–637. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Minh-Triet, T.; Thanh-Dat, T.; Tung, D.D.; Viet-Khoa, V.H.; Quoc-An, L.; Vinh-Tiep, N. Lifelog Moment Retrieval with Visual Concept Fusion and Text-based Query Expansion. In Proceedings of the CLEF 2018 Working Notes, Avignon, France, 10–14 September 2018. [Google Scholar]
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every Picture Tells a Story: Generating Sentences from Images. In Proceedings of the 11th European Conference on Computer Vision: Part IV, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 15–29. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. Baby Talk: Understanding and Generating Simple Image Descriptions. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 1601–1608. [Google Scholar]
- Yatskar, M.; Galley, M.; Vanderwende, L.; Zettlemoyer, L. See No Evil, Say No Evil: Description Generation from Densely Labeled Images. In Proceedings of the Third Joint Conference on Lexical and Computational Semantics (*SEM 2014), 2014, Dublin, Ireland, 23–24 August 2014; pp. 110–120. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep Visual-Semantic Alignments for Generating Image Descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 2048–2057. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image Captioning With Semantic Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Viet-Khoa, V.H.; Quoc-An, L.; Duy-Tam, N.; Mai-Khiem, T.; Minh-Triet, T. Personal Diary Generation from Wearable Cameras with Concept Augmented Image Captioning and Wide Trail Strategy. In Proceedings of the Ninth International Symposium on Information and CommunicationTechnology (SoICT 2018), DaNang City, Viet Nam, 6–7 December 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems (NIPS); Curran Associates, Inc.: Palais des Congrès de Montréal, Montréal, QC, Canada, 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Lavie, A.; Agarwal, A. Meteor: An Automatic Metric for MT Evaluation with High Levels of Correlation with Human Judgments. In Proceedings of the Second Workshop on Statistical Machine Translation, Prague, Czech Republic, 23 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 228–231. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Workshop on Text Summarization Branches Out (WAS 2004), Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. CIDEr: Consensus-Based Image Description Evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical Sequence Training for Image Captioning. arXiv 2016, arXiv:1612.00563. [Google Scholar]
- Mun, J.; Cho, M.; Han, B. Text-guided Attention Model for Image Captioning. arXiv 2016, arXiv:1612.03557. [Google Scholar]
- Devlin, J.; Gupta, S.; Girshick, R.B.; Mitchell, M.; Zitnick, C.L. Exploring Nearest Neighbor Approaches for Image Captioning. arXiv 2015, arXiv:1505.04467. [Google Scholar]
Sample Availability: The source code of the model from the authors is available in the following https://github.com/vhvkhoa/image-captioning-with-concept. |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Frameworks | mAP | FPS |
|---|---|---|
| Faster R-CNN VGG-16 [21] | 73.2 | 7 |
| Faster R-CNN ResNet [21] | 76.4 | 5 |
| SSD300 [22] | 74.3 | 46 |
| SSD500 [22] | 76.8 | 19 |
| YOLO9000 [20] 480 × 480 | 77.8 | 59 |
| YOLO9000 [20] 544 × 544 | 78.6 | 40 |
| Beam Size | B-1 | B-2 | B-3 | B-4 | METEOR | Rouge-L | CIDEr |
|---|---|---|---|---|---|---|---|
| 1 | 0.713 | 0.542 | 0.397 | 0.291 | 0.245 | 0.525 | 0.934 |
| 2 | 0.727 | 0.560 | 0.420 | 0.316 | 0.252 | 0.536 | 0.984 |
| 3 | 0.727 | 0.560 | 0.422 | 0.321 | 0.254 | 0.538 | 0.989 |
| 4 | 0.725 | 0.559 | 0.423 | 0.322 | 0.253 | 0.537 | 0.990 |
| 5 | 0.724 | 0.557 | 0.422 | 0.322 | 0.253 | 0.536 | 0.985 |
| 6 | 0.722 | 0.556 | 0.421 | 0.322 | 0.252 | 0.535 | 0.984 |
| 7 | 0.721 | 0.555 | 0.420 | 0.320 | 0.252 | 0.534 | 0.983 |
| 8 | 0.720 | 0.555 | 0.420 | 0.321 | 0.252 | 0.534 | 0.981 |
| 9 | 0.720 | 0.554 | 0.419 | 0.320 | 0.252 | 0.534 | 0.980 |
| 10 | 0.720 | 0.554 | 0.419 | 0.319 | 0.252 | 0.533 | 0.980 |
| Length Norm | B-1 | B-2 | B-3 | B-4 | METEOR | Rouge-L | CIDEr |
|---|---|---|---|---|---|---|---|
| 0.0 | 0.727 | 0.560 | 0.422 | 0.321 | 0.254 | 0.538 | 0.989 |
| 0.1 | 0.727 | 0.560 | 0.422 | 0.321 | 0.254 | 0.539 | 0.991 |
| 0.2 | 0.727 | 0.560 | 0.423 | 0.321 | 0.254 | 0.539 | 0.991 |
| 0.3 | 0.727 | 0.560 | 0.423 | 0.322 | 0.254 | 0.539 | 0.992 |
| 0.4 | 0.728 | 0.562 | 0.424 | 0.323 | 0.254 | 0.539 | 0.995 |
| 0.5 | 0.728 | 0.561 | 0.424 | 0.322 | 0.254 | 0.539 | 0.993 |
| 0.6 | 0.727 | 0.560 | 0.423 | 0.321 | 0.254 | 0.538 | 0.990 |
| 0.7 | 0.727 | 0.561 | 0.423 | 0.322 | 0.254 | 0.539 | 0.992 |
| 0.8 | 0.727 | 0.560 | 0.423 | 0.322 | 0.254 | 0.538 | 0.992 |
| 0.9 | 0.726 | 0.560 | 0.422 | 0.320 | 0.253 | 0.538 | 0.990 |
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDEr | |
|---|---|---|---|---|---|---|---|
| Watson Multimodal [30] | 0.781 | 0.619 | 0.470 | 0.352 | 0.270 | 0.563 | 1.147 |
| Postech_CV [31] | 0.743 | 0.575 | 0.431 | 0.321 | 0.255 | 0.539 | 0.987 |
| ATT [15] | 0.731 | 0.565 | 0.424 | 0.316 | 0.250 | 0.535 | 0.943 |
| Google-NIC [11] | 0.713 | 0.542 | 0.407 | 0.309 | 0.254 | 0.530 | 0.943 |
| Montreal/Toronto [14] | 0.707 | 0.492 | 0.344 | 0.243 | 0.239 | - | - |
| Nearest Neighbor [32] | 0.697 | 0.521 | 0.382 | 0.28 | 0.237 | 0.507 | 0.886 |
| NeuralTalk [12] | 0.650 | 0.464 | 0.321 | 0.224 | 0.21 | 0.475 | 0.674 |
| 80_tags_model [17] | 0.701 | 0.527 | 0.384 | 0.277 | 0.230 | 0.511 | 0.835 |
| 9000_tags_model (ours) | 0.723 | 0.554 | 0.414 | 0.310 | 0.250 | 0.532 | 0.942 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vo-Ho, V.-K.; Luong, Q.-A.; Nguyen, D.-T.; Tran, M.-K.; Tran, M.-T. A Smart System for Text-Lifelog Generation from Wearable Cameras in Smart Environment Using Concept-Augmented Image Captioning with Modified Beam Search Strategy. Appl. Sci. 2019, 9, 1886. https://doi.org/10.3390/app9091886
Vo-Ho V-K, Luong Q-A, Nguyen D-T, Tran M-K, Tran M-T. A Smart System for Text-Lifelog Generation from Wearable Cameras in Smart Environment Using Concept-Augmented Image Captioning with Modified Beam Search Strategy. Applied Sciences. 2019; 9(9):1886. https://doi.org/10.3390/app9091886
Chicago/Turabian StyleVo-Ho, Viet-Khoa, Quoc-An Luong, Duy-Tam Nguyen, Mai-Khiem Tran, and Minh-Triet Tran. 2019. "A Smart System for Text-Lifelog Generation from Wearable Cameras in Smart Environment Using Concept-Augmented Image Captioning with Modified Beam Search Strategy" Applied Sciences 9, no. 9: 1886. https://doi.org/10.3390/app9091886
APA StyleVo-Ho, V.-K., Luong, Q.-A., Nguyen, D.-T., Tran, M.-K., & Tran, M.-T. (2019). A Smart System for Text-Lifelog Generation from Wearable Cameras in Smart Environment Using Concept-Augmented Image Captioning with Modified Beam Search Strategy. Applied Sciences, 9(9), 1886. https://doi.org/10.3390/app9091886