
Multidisciplinary Intersections on Artificial-Human Vividness: Phenomenology, Representation, and the Brain


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
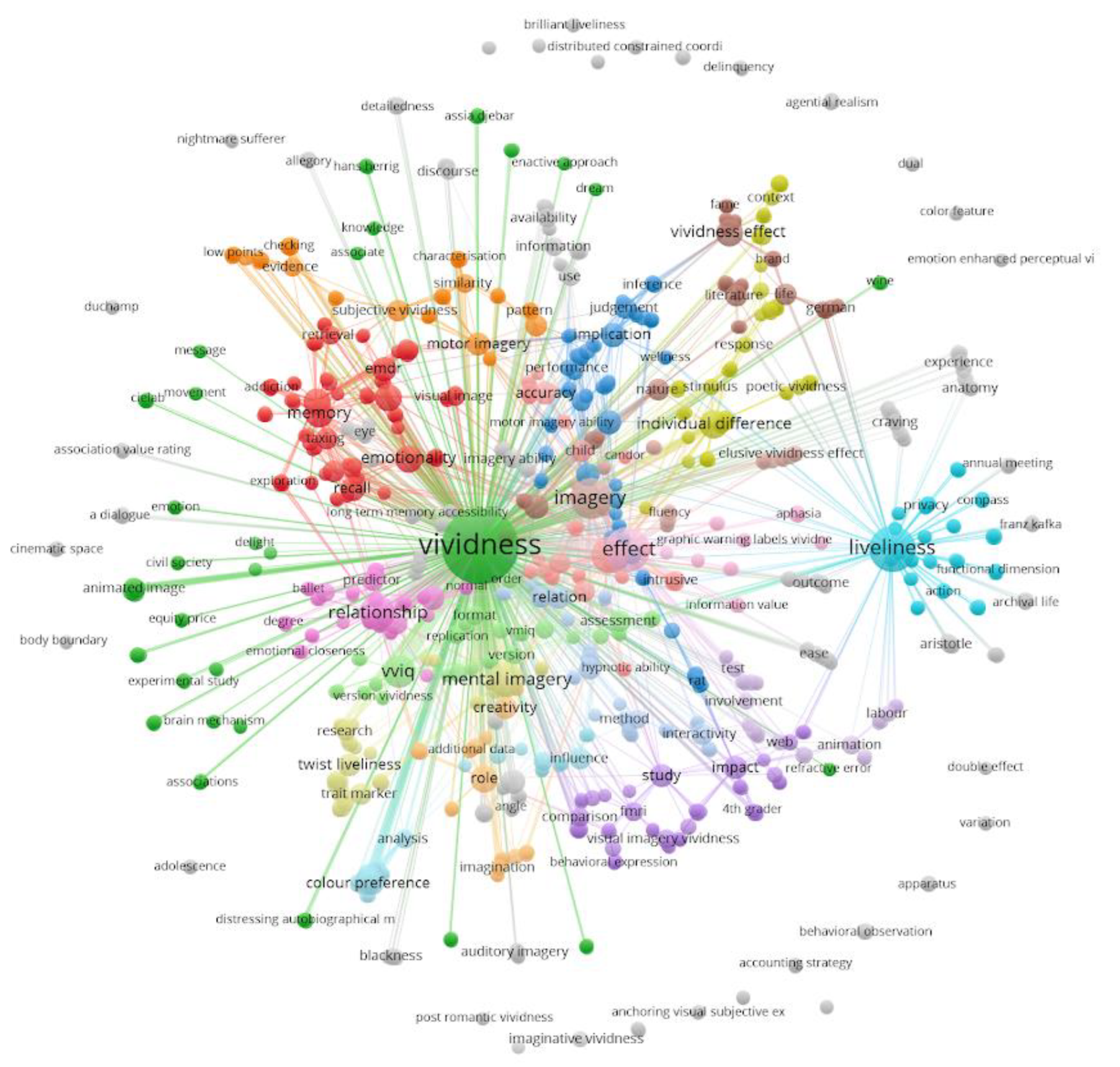
:1. Varieties of Vividness and Their Place in Science
2. Vividness in Artificial Intelligence
“Not much of interest in my version of vividness in the Cog Sci community to my knowledge. What mainly happened after a paper I wrote in 1986 ("Making believers out of computers") is that people in [knowledge representation] took it on as a simple constraint on how reasoning with sentences could be made computationally feasible. Until that point, reasoning with large collections of sentences looked quite impractical computationally, and even undecidable in some cases. (That my version of vividness happened to coincide with some constraints on psych plausibility and imagery was viewed as a bonus.) The bulk of the work since then builds on and extends the notion of vividness in various ways: how can you keep reasoning with sentences feasible while generalizing the scope of sentences allowed to account for ever richer forms of reasoning. All the work I know in this vein is pretty technical but "levesque vivid reasoning" gets a lot of hits in Google!”
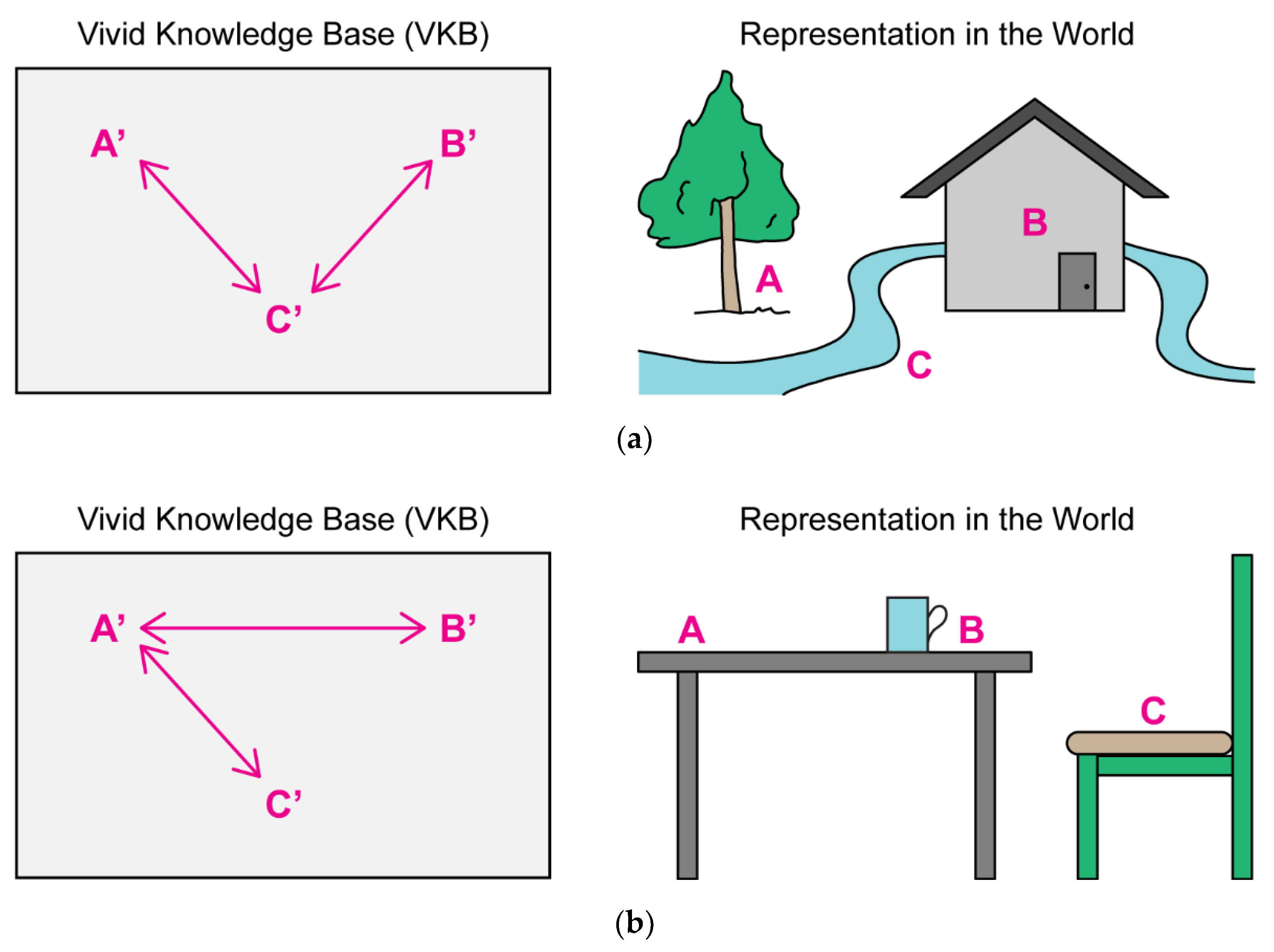
2.1. Vividness in Symbolic AI
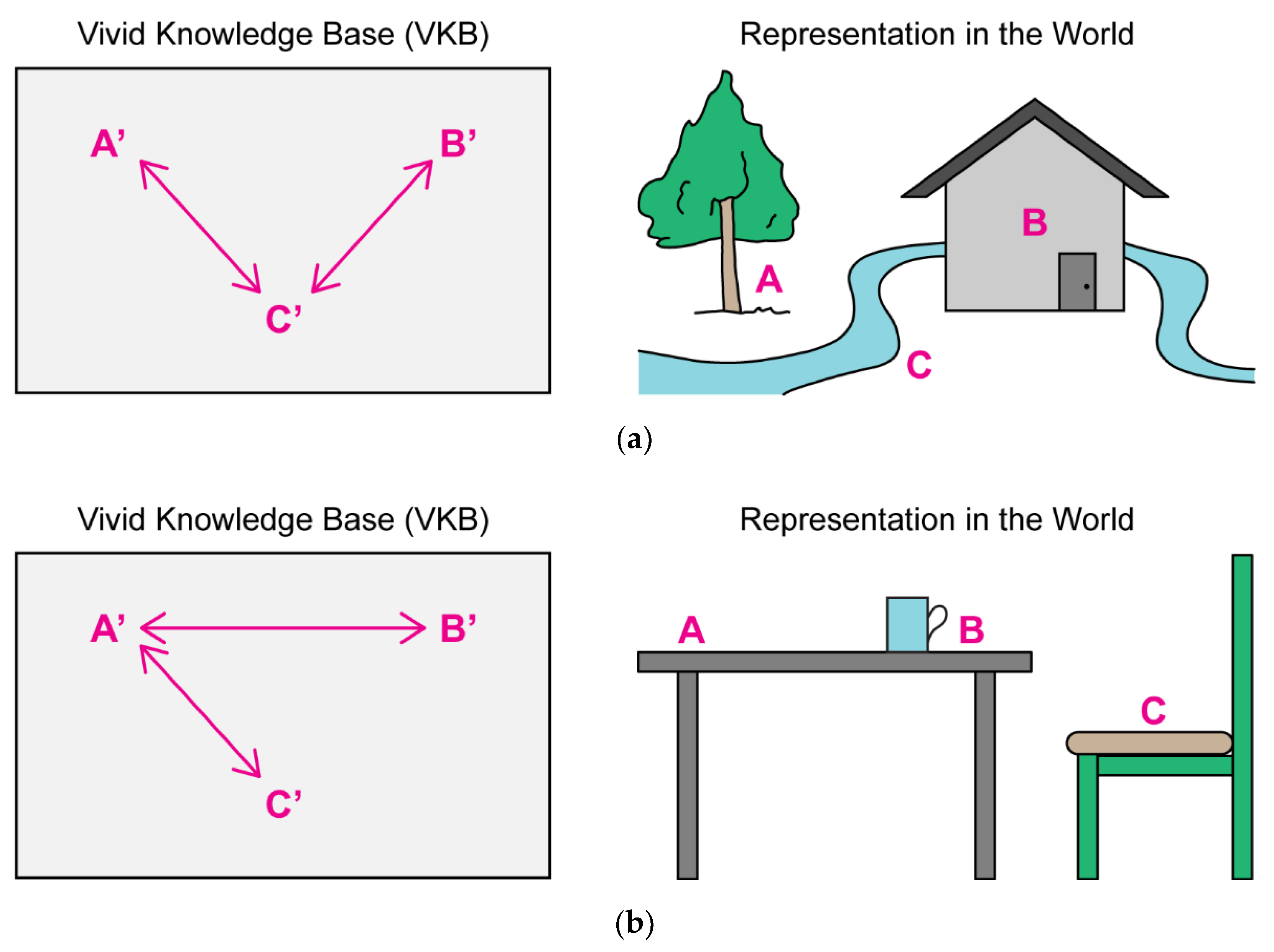
Levesque’s Vivid Knowledge Bases
2.2. Limitations
2.3. Reasoning beyond Vividness
3. Vividness in Natural Cognition
3.1. Vividness in Philosophy and Phenomenology
- (i)
3.2. Vividness in Psychology
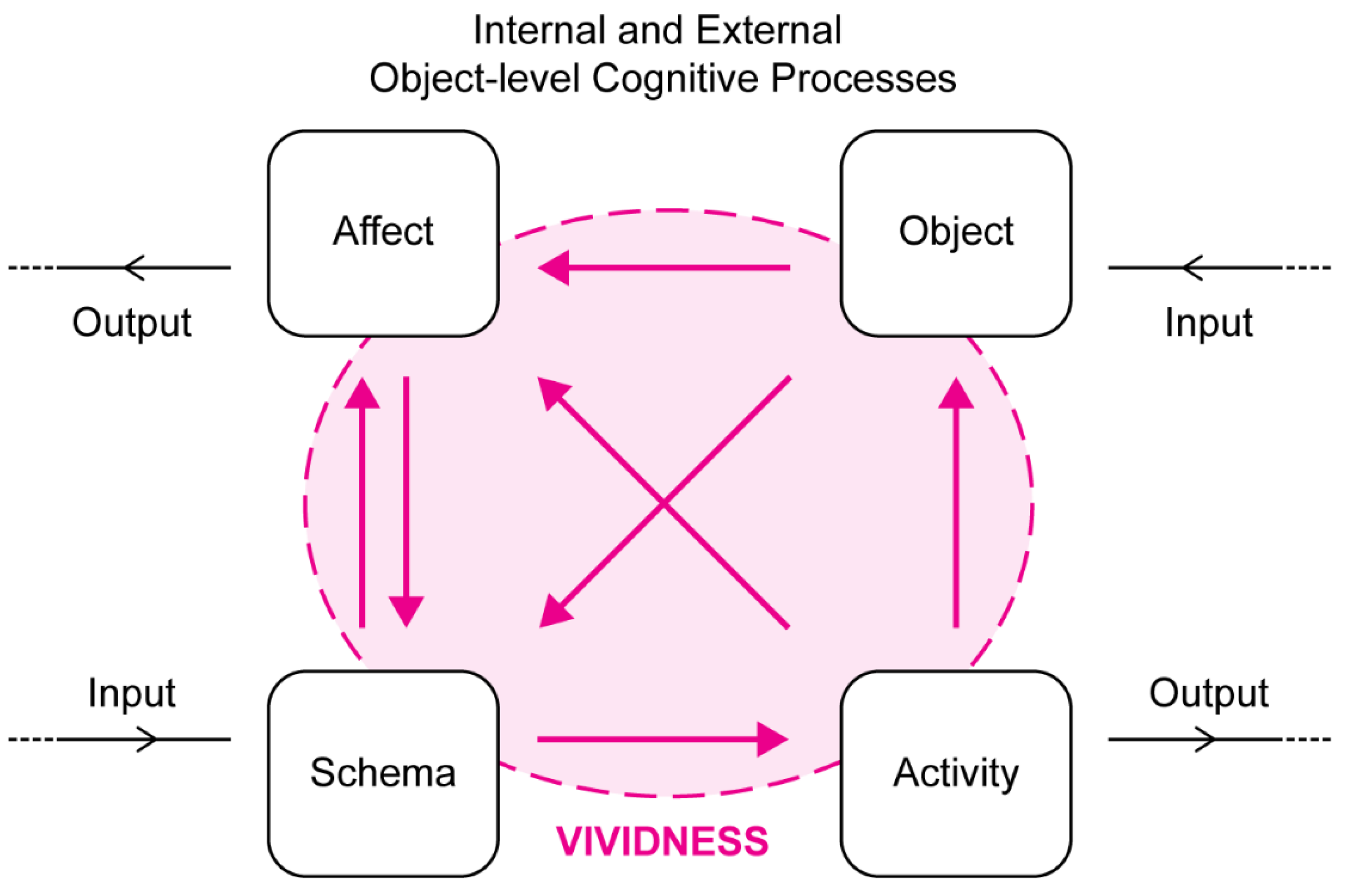
3.2.1. Vividness as a General Function of Perceptual Consciousness and Action (Marks’ VVIQ-Vividness)
3.2.2. Vividness as Episodic Memory
3.2.3. Vividness in Cognitive Science
3.2.4. Vividness, Simulation and Mental Models in Human Reasoning
3.2.5. Vividness in Neuroscience and Neuropsychology
4. Vividness in Brain-Inspired AI (Deep Learning)
4.1. Visual Representation in Artificial Neural Networks
4.2. From Vividness to Consciousness
4.3. Iconic Transfer and Intentionality
4.4. Future Directions
4.5. Ethical Caveats
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Haustein, S.; Vellino, A.; D’Angiulli, A. Insights from a Bibliometric Analysis of Vividness and Its Links with Consciousness and Mental Imagery. Brain Sci. 2020, 10, 41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Levesque, H.J. Making believers out of computers. Artif. Intell. 1986, 30, 81–108. [Google Scholar] [CrossRef]
- Levesque, H.J.; (University of Toronto, Toronto, ON, Canada); D’Angiulli, A.; (Carleton University, Ottawa, ON, Canada). Personal Communication, 2008.
- Chrisley, R. Synthetic Phenomenology. Int. J. Mach. Conscious. 2009, 01, 53–70. [Google Scholar] [CrossRef] [Green Version]
- Chrisley, R.; Parthemore, J. Synthetic Phenomenology: Exploiting Embodiment to Specify the Non-Conceptual Content of Visual Experience. J. Conscious. Stud. 2007, 14, 44–58. [Google Scholar]
- Levesque, H.J. Logic and the Complexity of Reasoning. In Philosophical Logic and Artificial Intelligence; Thomason, R.H., Ed.; Springer Netherlands: Dordrecht, the Netherlands, 1989; pp. 73–107. [Google Scholar] [CrossRef]
- Brachman, R.J.; Levesque, H.J. Knowledge Representation and Reasoning; Morgan Kaufmann: San Francisco, CA, USA, 2004; pp. 336–342. [Google Scholar]
- Etherington, D.W.; Borgida, A.; Brachman, R.J.; Kautz, H. Vivid Knowledge and Tractable Reasoning: Preliminary Report. IJCAI 1989, 2, 1146–1152. [Google Scholar]
- Davis, E. Lucid Representations; Technical Report #565; Courant Institute of Mathematical Sciences, New York University: New York, NY, USA, 1991. [Google Scholar]
- Kautz, H.A.; Kearns, M.J.; Selman, B. Reasoning with characteristic models. In Proceedings of the 1993 AAAI Symposium, Washington, DC, USA, 11–15 July 1993; pp. 34–39. [Google Scholar]
- Gogic, G.; Papadimitriou, C.H.; Sideri, M. Incremental recompilation of knowledge. J. Artif. Intell. Res. 1998, 8, 23–37. [Google Scholar] [CrossRef] [Green Version]
- Sartre, J.P. L’imaginaire: Psychologie Phénoménologique de L’imagination; Gallimard: Paris, France, 1940. [Google Scholar]
- Galton, F. Statistics of Mental Imagery. Mind 1880, 5, 301–318. [Google Scholar] [CrossRef]
- Betts, G.H. The Distribution and Functions of Mental Imagery; Teachers College, Columbia University: New York, NY, USA, 1990. [Google Scholar]
- Hebb, D.O. Concerning imagery. Psychol. Rev. 1968, 75, 466–477. [Google Scholar] [CrossRef]
- Hume, D. An Abstract of a Treatise of Human Nature; Cambridge University Press: London, UK, 1938. [Google Scholar]
- D’Angiulli, A.; Reeves, A. Experimental phenomenology meets brain information processing: Vividness of voluntary imagery, consciousness of the present, and priming. Psychol. Conscious. Theory Res. Pract. 2021, 8, 397–418. [Google Scholar] [CrossRef]
- Dainton, B. Temporal Consciousness. In The Stanford Encyclopedia of Philosophy; Zalta, E.N., Ed.; Metaphysics Research Lab, Stanford University: Stanford, MA, USA, 2018. [Google Scholar]
- Albertazzi, L. Experimental phenomenology: What it is and what it is not. Synthese 2021, 198, 2191–2212. [Google Scholar] [CrossRef]
- Albertazzi, L. Experimental phenomenology, a challenge. Psychol. Conscious. Theory Res. Pract. 2021, 8, 105–115. [Google Scholar] [CrossRef]
- Benussi, V. Auffälligkeit (Salience). In Archivio Vittorio Benussi 1897–1927; Archivio Storico Della Psicologia Italiana: Milan, Italy, 1905; Volume 1. [Google Scholar]
- Benussi, V. Experimentelles über Vorstellungsinadäquatheit. II. Gestaltmehrdeutigkeit und Inadäquatheitsumkehrung. Z. Psychol. 1907, 45, 188–230. [Google Scholar]
- Bonaventura, E. Il Problema Psicologico del Tempo; Soc. An. Instituto Editoriale Scientifico: Oxford, UK, 1929. [Google Scholar]
- Calabresi, R. La Determinazione del Presente Psichico [The Determination of the Psychological Present]; Bemporad: Florence, Italy, 1930. [Google Scholar]
- Albertazzi, L. Psicologia descrittiva e psicologia sperimentale: Brentano e Bonaventura sul tempo psichico. Axiomathes 1993, 4, 389–412. [Google Scholar] [CrossRef]
- Albertazzi, L.; Jacquette, D.; Poli, R. Meinong in his and our times. In The School of Alexius Meinong; Albertazzi, L., Jacquette, D., Poli, R., Eds.; Ashgate: Surrey, UK, 2001; pp. 3–48. [Google Scholar]
- Antonelli, M. Vittorio Benussi in the History of Psychology; Studies in the History of Philosophy of Mind; Springer: Cham, switzerland, 2018. [Google Scholar] [CrossRef]
- Albertazzi, L.; Cimino, G.; Gori-Savellini, S. Francesco de Sarlo E Il Laboratorio Fiorentino di Psicologia; Laterza Giuseppe Edizioni: Bari, Italy, 1999. [Google Scholar]
- Brentano, F. Psychology from an Empirical Standpoint; McAlister, L.L., Rancurello, A.C., Eds.; Routledge: London, UK, 1995. [Google Scholar]
- Meinong, A. Untersuchungen zur Gegenstandstheorie und Psychologie; JA Barth: Leipzig, Germany, 1904. [Google Scholar]
- Ameseder, R. Über Vorstellungsproduktion, Über absolute Auffälligkeit der Farben. In Untersuchungen zur Gegestandstheorie und Psychologie; Meinong, A., Ed.; Johann Ambrosius Barth: Leipzig, Germany, 1904. [Google Scholar]
- Benussi, V. Experimentelles über Vorstellungsinadäquatheit. Das Erfassen gestaltmehrdeutiger Komplexe. Z. Psychol. 1906, 42, 22–55. [Google Scholar]
- Benussi, V. Psychologie der Zeitauffassung; C. Winter: Heidelberg, Germany, 1913; Volume 6. [Google Scholar]
- Benussi, V. La Suggestione e L’ipnosi: Come Mezzi di Analisi Psichica Reale; N. Zanichelli: Bologna, Italy, 1925. [Google Scholar]
- Kosslyn, S. Image and Brain: The Resolution of the Imagery Debate; MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Miller, G.A.; Johnson-Laird, P.N. Language and perception. Language and Perception, Harvard University Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Todd, R.M.; Talmi, D.; Schmitz, T.W.; Susskind, J.; Anderson, A.K. Psychophysical and Neural Evidence for Emotion-Enhanced Perceptual Vividness. J. Neurosci. 2012, 32, 11201–11212. [Google Scholar] [CrossRef] [Green Version]
- Giusberti, F.; Cornoldi, C.; De Beni, R.; Massironi, M. Differences in vividness ratings of perceived and imagined patterns. Br. J. Psychol. 1992, 83, 533–547. [Google Scholar] [CrossRef]
- Marmolejo-Ramos, F.; Hellemans, K.; Comeau, A.; Heenan, A.; Faulkner, A.; Abizaid, A.; D’Angiulli, A. Event-related potential signatures of perceived and imagined emotional and food real-life photos. Neurosci. Bull. 2015, 31, 317–330. [Google Scholar] [CrossRef] [Green Version]
- Marks, D.F. Visual Imagery Differences in the Recall of Pictures. Br. J. Psychol. 1973, 64, 17–24. [Google Scholar] [CrossRef]
- McKelvie, S.J. The VVIQ and Beyond: Vividness and Its Measurement. J. Mental Imag. 1995, 19. [Google Scholar]
- Torgerson, W.S. Theory and Methods of Scaling; Wiley: New York, NY, USA, 1958. [Google Scholar]
- D’Angiulli, A. Is the Spotlight an Obsolete Metaphor of “Seeing with the Mind’s Eye”? A Constructive Naturalistic Approach to the Inspection of Visual Mental Images. Imagin. Cogn. Personal. 2008, 28, 117–135. [Google Scholar] [CrossRef]
- D’Angiulli, A. Vividness, Consciousness and Mental Imagery: A Start on Connecting the Dots. Brain Sci. 2020, 10, 500. [Google Scholar] [CrossRef] [PubMed]
- Perky, C.W. An Experimental Study of Imagination. Am. J. Psychol. 1910, 21, 422–452. [Google Scholar] [CrossRef]
- D’Angiulli, A. Descriptions and explanations in the mental imagery paradigm. In Semiotics as a Bridge between the Humanities and the Sciences; Perron, P., Sbrocchi, L.G., Colilli, P., Danesi, M., Eds.; Legas: Ottawa, ON, Canada, 2000; pp. 315–335. [Google Scholar]
- Haskell, R.E. Cognitive science, Vichian semiotics and the learning paradox of the Meno: Or what is a sign a sign of. In Semiotics as a Bridge between the Humanities and the Sciences; Perron, P., Sbrocchi, L.G., Colilli, P., Danesi, M., Eds.; Legas: Ottawa, ON, Canada, 2000; pp. 336–370. [Google Scholar]
- D’Angiulli, A.; Griffiths, G.; Marmolejo-Ramos, F. Neural correlates of visualizations of concrete and abstract words in preschool children: A developmental embodied approach. Front. Psychol. 2015, 6, 856. [Google Scholar] [CrossRef] [PubMed]
- Baddeley, A.D.; Andrade, J. Working memory and the vividness of imagery. J. Exp. Psychol. Gen. 2000, 129, 126–145. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; The University of Illinois Press: Champaign, IL, USA, 1964. [Google Scholar]
- Deacon, T.W. Incomplete Nature: How Mind Emerged from Matter; WW Norton & Company: New York, NY, USA, 2011. [Google Scholar]
- Piaget, J.; Garcia, R.; Davidson, P.; Davidson, P.M.; Easley, J. Toward a Logic of Meanings; Psychology Press: New York, NY, USA, 2013. [Google Scholar]
- McClelland, M.M.; Cameron, C.E.; Duncan, R.; Bowles, R.P.; Acock, A.C.; Miao, A.; Pratt, M.E. Predictors of early growth in academic achievement: The head-toes-knees-shoulders task. Front. Psychol. 2014, 5, 599. [Google Scholar] [CrossRef] [Green Version]
- Marks, D. Individual Differences in the Vividness of Visual Imagery and their Functions. In The Function and Nature of Imagery; Sheehan, P.W., Ed.; Academic Press: New York, NY, USA, 1972; pp. 83–108. [Google Scholar]
- Marks, D.F. A General Theory of Behaviour; SAGE Publications: London, UK, 2018. [Google Scholar]
- Marks, D.F. I Am Conscious, Therefore, I Am: Imagery, Affect, Action, and a General Theory of Behavior. Brain Sci. 2019, 9, 107. [Google Scholar] [CrossRef] [Green Version]
- McKelvie, S.J. Vividness of Visual Imagery: Measurement, Nature, Function & Dynamics; Brandon House: New York, NY, USA, 1995. [Google Scholar]
- Dijkstra, N.; Bosch, S.E.; van Gerven, M.A.J. Vividness of Visual Imagery Depends on the Neural Overlap with Perception in Visual Areas. J. Neurosci. 2017, 37, 1367–1373. [Google Scholar] [CrossRef] [Green Version]
- D’Argembeau, A.; Van der Linden, M. Individual differences in the phenomenology of mental time travel: The effect of vivid visual imagery and emotion regulation strategies. Conscious. Cogn. 2006, 15, 342–350. [Google Scholar] [CrossRef] [Green Version]
- Thakral, P.P.; Madore, K.P.; Schacter, D.L. The core episodic simulation network dissociates as a function of subjective experience and objective content. Neuropsychologia 2020, 136, 107263. [Google Scholar] [CrossRef]
- Loftus, E.F.; Palmer, J.C. Reconstruction of automobile destruction: An example of the interaction between language and memory. J. Verbal Learn. Verbal Behav. 1974, 13, 585–589. [Google Scholar] [CrossRef]
- Gilboa, A. Autobiographical and episodic memory—one and the same?: Evidence from prefrontal activation in neuroimaging studies. Neuropsychologia 2004, 42, 1336–1349. [Google Scholar] [CrossRef]
- Pylyshyn, Z.W. Seeing and Visualizing: It’s Not What You Think; MIT Press: Cambridge, MA, USA, 2003. [Google Scholar]
- Goebel, R. Spatial and VIsual Reasoning: Humans Versus Logic. Comput. Intell. 1993, 9, 406–412. [Google Scholar] [CrossRef]
- Rodway, P.; Gillies, K.; Schepman, A. Vivid imagers are better at detecting salient changes. J. Individ. Differ. 2006, 27, 218–228. [Google Scholar] [CrossRef]
- D’Angiulli, A.; Reeves, A. Generating visual mental images: Latency and vividness are inversely related. Mem. Cogn. 2002, 30, 1179–1188. [Google Scholar] [CrossRef] [Green Version]
- Gonsalves, B.; Reber, P.; Crawford, M.; Paller, K. Reading the mind’s eye using an occipital brain potential that indexes vividness of visual imagery. In Proceedings of the Annual Meeting of the Cognitive Neuroscience Society, San Francisco, CA, USA, 2002; p. 138. [Google Scholar]
- Cui, X.; Jeter, C.B.; Yang, D.; Montague, P.R.; Eagleman, D.M. Vividness of mental imagery: Individual variability can be measured objectively. Vis. Res. 2007, 47, 474–478. [Google Scholar] [CrossRef] [Green Version]
- Runge, M.; Bakhilau, V.; Omer, F.; D’Angiulli, A. Trial-by-Trial Vividness Self-Reports Versus VVIQ:A Meta-Analytic Comparison of Behavioral, Cognitive and Neurological Correlations. Imagin. Cogn. Personal. 2015, 35, 137–165. [Google Scholar] [CrossRef]
- Farah, M.J. Is visual imagery really visual? Overlooked evidence from neuropsychology. Psychol. Rev. 1988, 95, 307. [Google Scholar] [CrossRef]
- Amedi, A.; Malach, R.; Pascual-Leone, A. Negative BOLD Differentiates Visual Imagery and Perception. Neuron 2005, 48, 859–872. [Google Scholar] [CrossRef] [Green Version]
- Vianna, E.P.M.; Naqvi, N.; Bechara, A.; Tranel, D. Does vivid emotional imagery depend on body signals? Int. J. Psychophysiol. 2009, 72, 46–50. [Google Scholar] [CrossRef] [Green Version]
- Farah, M.J.; Peronnet, F. Event-related potentials in the study of mental imagery. J. Psychophysiol. 1989, 3, 99–109. [Google Scholar]
- Farah, M.J.; Péronnet, F.; Gonon, M.A.; Giard, M.H. Electrophysiological evidence for a shared representational medium for visual images and visual percepts. J. Exp. Psychol. Gen. 1988, 117, 248. [Google Scholar] [CrossRef]
- Farah, M.J.; Weisberg, L.L.; Monheit, M.; Peronnet, F. Brain activity underlying mental imagery: Event-related potentials during mental image generation. J. Cogn. Neurosci. 1989, 1, 302–316. [Google Scholar] [CrossRef] [PubMed]
- D’Esposito, M.; Detre, J.A.; Aguirre, G.K.; Stallcup, M.; Alsop, D.C.; Tippet, L.J.; Farah, M.J. A functional MRI study of mental image generation. Neuropsychologia 1997, 35, 725–730. [Google Scholar] [CrossRef]
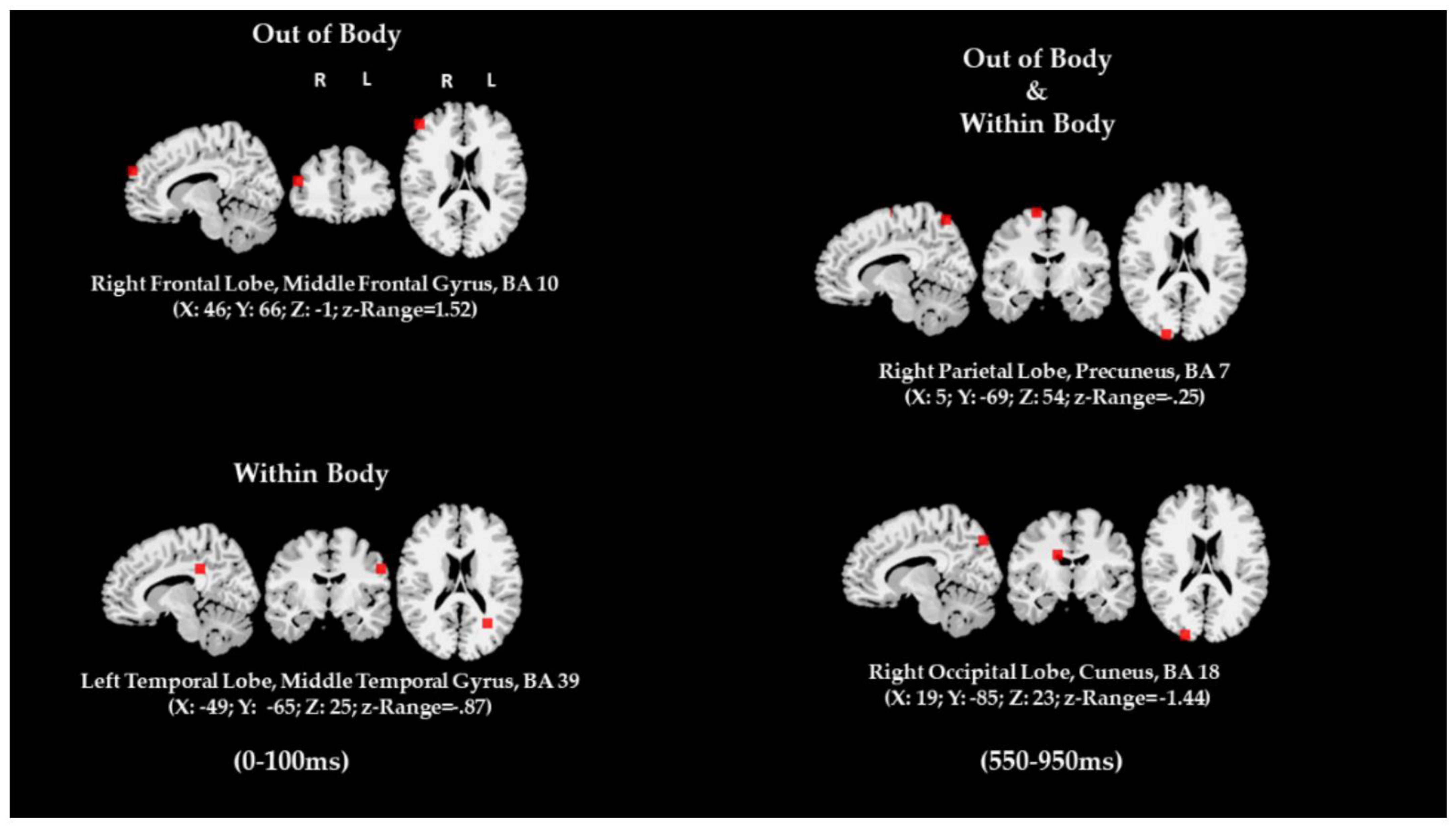
- D’Angiulli, A.; Kenney, D.; Pham, D.A.T.; Lefebvre, E.; Bellavance, J.; Buchanan, D.M. Neurofunctional Symmetries and Asymmetries during Voluntary out-of- and within-Body Vivid Imagery Concurrent with Orienting Attention and Visuospatial Detection. Symmetry 2021, 13, 1549. [Google Scholar] [CrossRef]
- Olivetti Belardinelli, M.; Palmiero, M.; Sestieri, C.; Nardo, D.; Di Matteo, R.; Londei, A.; D’Ausilio, A.; Ferretti, A.; Del Gratta, C.; Romani, G.L. An fMRI investigation on image generation in different sensory modalities: The influence of vividness. Acta Psychol. 2009, 132, 190–200. [Google Scholar] [CrossRef]
- Pearson, J.; Rademaker, R.L.; Tong, F. Evaluating the mind’s eye: The metacognition of visual imagery. Psychol. Sci. 2011, 22, 1535–1542. [Google Scholar] [CrossRef]
- Imms, P.; Domínguez, D.J.F.; Burmester, A.; Seguin, C.; Clemente, A.; Dhollander, T.; Wilson, P.H.; Poudel, G.; Caeyenberghs, K. Navigating the link between processing speed and network communication in the human brain. Brain Struct. Funct. 2021, 226, 1281–1302. [Google Scholar] [CrossRef]
- Zeman, A.; Dewar, M.; Sala, S. Lives without imagery—Congenital aphantasia. Cortex 2015, 72, 378–380. [Google Scholar] [CrossRef] [Green Version]
- Keogh, R.; Pearson, J. The blind mind: No sensory visual imagery in aphantasia. Cortex 2018, 105, 53–60. [Google Scholar] [CrossRef]
- Wicken, M.; Keogh, R.; Pearson, J. The critical role of mental imagery in human emotion: Insights from Aphantasia. bioRxiv 2019, 726844. [Google Scholar] [CrossRef]
- Zeman, A.; Milton, F.; Della Sala, S.; Dewar, M.; Frayling, T.; Gaddum, J.; Hattersley, A.; Heuerman-Williamson, B.; Jones, K.; MacKisack, M.; et al. Phantasia–The psychological significance of lifelong visual imagery vividness extremes. Cortex 2020, 130, 426–440. [Google Scholar] [CrossRef]
- Dawes, A.J.; Keogh, R.; Andrillon, T.; Pearson, J. A cognitive profile of multi-sensory imagery, memory and dreaming in aphantasia. Sci. Rep. 2020, 10, 10022. [Google Scholar] [CrossRef]
- D’Angiulli, A.; Reeves, A. Picture theory, tacit knowledge or vividness-core? Three hypotheses on the mind’s eye and its elusive size. In Proceedings of the Annual Meeting of the Cognitive Science Society, Stresa, Italy, 21–23 July 2005; Volume 27. [Google Scholar]
- Roy, D. Semiotic schemas: A framework for grounding language in action and perception. Artif. Intell. 2005, 167, 170–205. [Google Scholar] [CrossRef] [Green Version]
- Besold, T.R.; Garcez, A.d.A.; Kühnberger, K.-U.; Stewart, T.C. Neural-symbolic networks for cognitive capacities. Biol. Inspired Cogn. Archit. 2014, 9, iii–iv. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Caballero, A.; Martínez-Rodrigo, A.; Pastor, J.M.; Castillo, J.C.; Lozano-Monasor, E.; López, M.T.; Zangróniz, R.; Latorre, J.M.; Fernández-Sotos, A. Smart environment architecture for emotion detection and regulation. J. Biomed. Inform. 2016, 64, 55–73. [Google Scholar] [CrossRef]
- Colombo, F.; Seeholzer, A.; Gerstner, W. Deep Artificial Composer: A Creative Neural Network Model for Automated Melody Generation; Springer International Publishing: Cham, Switzerland, 2017; pp. 81–96. [Google Scholar]
- DiPaola, S.; McCaig, G. Using artificial intelligence techniques to emulate the creativity of a portrait painter. In Proceedings of the Electronic Visualisation and the Arts, London, UK, 12–14 July 2016; pp. 158–165. [Google Scholar]
- Searle, J.R. The Rediscovery of the Mind; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Gamez, D.; Aleksander, I. Taking a Mental Stance Towards Artificial Systems. In Proceedings of the 2009 AAAI Fall Symposium, Arlington, VA, USA, 5–7 November 2009. [Google Scholar]
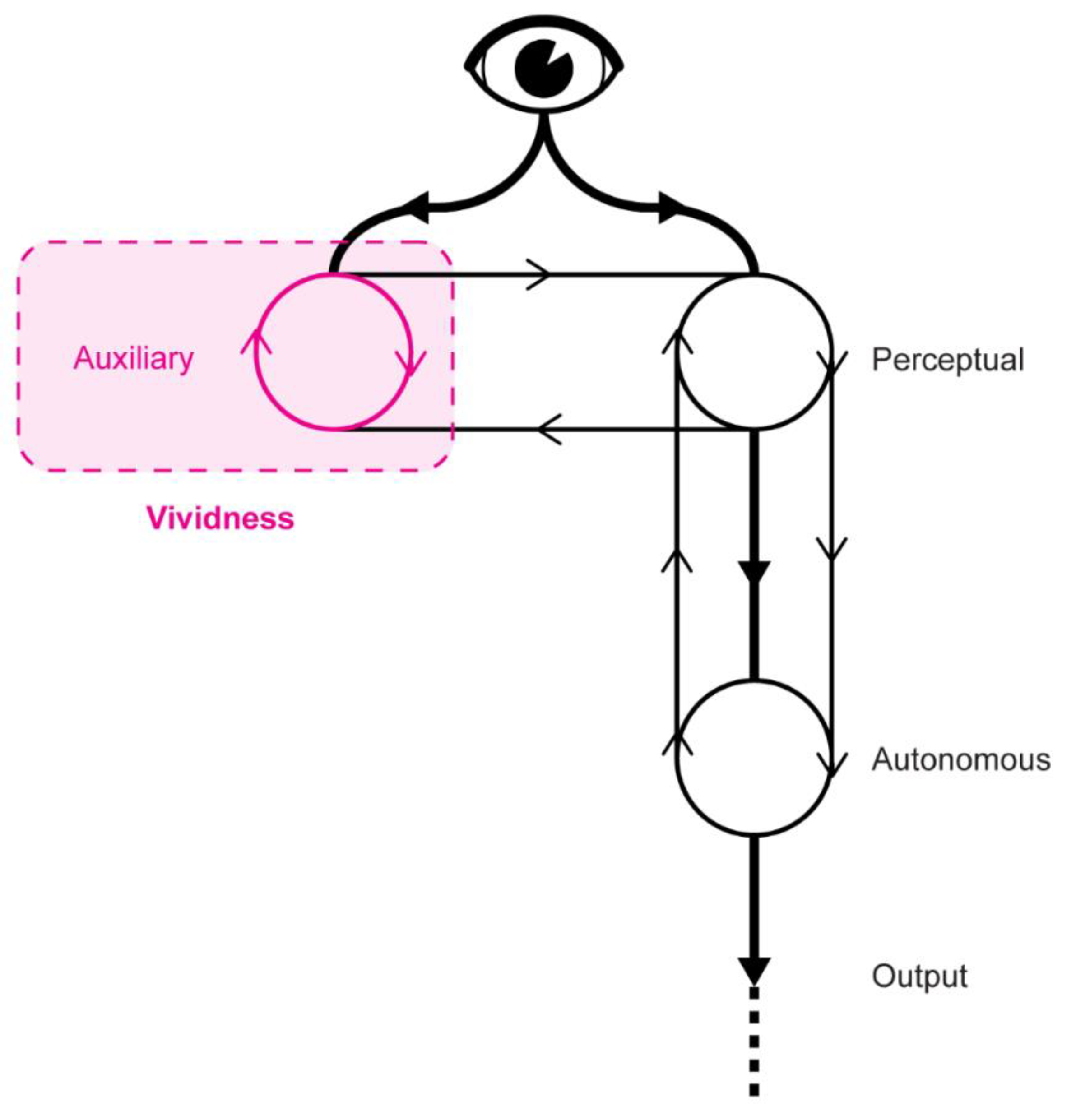
- Aleksander, I.; Gamez, D. Iconic Training and Effective Information: Evaluating Meaning in Discrete Neural Networks. In Proceedings of the 2009 AAAI Fall Symposium, Arlington, VA, USA, 5–7 November 2009. [Google Scholar]
- Balduzzi, D.; Tononi, G. Integrated information in discrete dynamical systems: Motivation and theoretical framework. PLoS Comput. Biol. 2008, 4, e1000091. [Google Scholar] [CrossRef] [Green Version]
- Gamez, D.; Aleksander, I. Accuracy and performance of the state-based Φ and liveliness measures of information integration. Conscious. Cogn. 2011, 20, 1403–1424. [Google Scholar] [CrossRef]
- Aleksander, I. Impossible Minds: My Neurons, My Consciousness (Revised Edition); Imperial College Press: London, UK, 2014. [Google Scholar]
- Aleksander, I.; Evans, R.G.; Sales, N. Towards Intentional Neural Systems: Experiments with MAGNUS. In Proceedings of the 4th International Conference on Artificial Neural Networks, Cambridge, UK, 26–28 June 1995; pp. 122–126. [Google Scholar]
- News, G. New Dog-Like Robot from Boston Dynamics Can Open Doors [Video]; Youtube: San Bruno, CA, USA, 2018; Available online: https://www.youtube.com/watch?v=wXxrmussq4E (accessed on 1 December 2021).
- Scott, T. An Actual, Real-World Use for Robot Dogs [Video]; Youtube: San Bruno, CA, USA, 2021; Available online: https://www.youtube.com/watch?v=PkW9wx7Kbws (accessed on 1 December 2021).
- Sputnik. Real Dog Meets Boston Dynamics Robot Dog for First Time [Video]; Youtube: San Bruno, CA, USA, 2016; Available online: https://www.youtube.com/watch?v=rEg6oeazTNY (accessed on 1 December 2021).
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- Irving, G.; Askell, A. AI safety needs social scientists. Distill 2019, 4, e14. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Molokopoy, V.; D’Angiulli, A. Multidisciplinary Intersections on Artificial-Human Vividness: Phenomenology, Representation, and the Brain. Brain Sci. 2022, 12, 1495. https://doi.org/10.3390/brainsci12111495
Molokopoy V, D’Angiulli A. Multidisciplinary Intersections on Artificial-Human Vividness: Phenomenology, Representation, and the Brain. Brain Sciences. 2022; 12(11):1495. https://doi.org/10.3390/brainsci12111495
Chicago/Turabian StyleMolokopoy, Violetta, and Amedeo D’Angiulli. 2022. "Multidisciplinary Intersections on Artificial-Human Vividness: Phenomenology, Representation, and the Brain" Brain Sciences 12, no. 11: 1495. https://doi.org/10.3390/brainsci12111495
APA StyleMolokopoy, V., & D’Angiulli, A. (2022). Multidisciplinary Intersections on Artificial-Human Vividness: Phenomenology, Representation, and the Brain. Brain Sciences, 12(11), 1495. https://doi.org/10.3390/brainsci12111495