Abstract
Clinical studies have shown that speech pauses can reflect the cognitive function differences between Alzheimer’s Disease (AD) and non-AD patients, while the value of pause information in AD detection has not been fully explored. Herein, we propose a speech pause feature extraction and encoding strategy for only acoustic-signal-based AD detection. First, a voice activity detection (VAD) method was constructed to detect pause/non-pause feature and encode it to binary pause sequences that are easier to calculate. Then, an ensemble machine-learning-based approach was proposed for the classification of AD from the participants’ spontaneous speech, based on the VAD Pause feature sequence and common acoustic feature sets (ComParE and eGeMAPS). The proposed pause feature sequence was verified in five machine-learning models. The validation data included two public challenge datasets (ADReSS and ADReSSo, English voice) and a local dataset (10 audio recordings containing five patients and five controls, Chinese voice). Results showed that the VAD Pause feature was more effective than common feature sets (ComParE: 6373 features and eGeMAPS: 88 features) for AD classification, and that the ensemble method improved the accuracy by more than 5% compared to several baseline methods (8% on the ADReSS dataset; 5.9% on the ADReSSo dataset). Moreover, the pause-sequence-based AD detection method could achieve 80% accuracy on the local dataset. Our study further demonstrated the potential of pause information in speech-based AD detection, and also contributed to a more accessible and general pause feature extraction and encoding method for AD detection.
1. Introduction
Alzheimer’s disease (AD) is an irreversible disease and there is little physicians can do when patients progress to advanced stages [1]. According to estimates from the World Alzheimer’s Disease Report 2019 and Alzheimer’s Disease International, there are over 50 million people living with dementia in the world, and the projected estimates for 2050 reach above 150 million [2]. Early detection holds great value for AD patients, as patients that are diagnosed early and seek treatment can be helped by numerous interventions to maintain their current state or delay cognitive decline [3].
Deterioration in speech and language production is among the first signs of the disease [4], and people with AD exhibit language impairment long before they are diagnosed [5]. In clinical practice, neuropsychological assessments are often used to initially screen for AD, evaluating their cognitive status through the patients’ manner of speaking and content [6]. However, this evaluation method relies on subjective assessment by human experts, which is difficult to quantify and meet the needs of AD patients for home testing.
Several researchers have focused on the use of spontaneous speech to detect AD. Yuan et al. [7] obtained the best accuracy of 89.6% using text-based features and acoustic features. Agbavor et al. [8] developed an end-to-end AD detection method with average area under the curve of 0.846. Although these methods have achieved good performance, they are still prone to voice-to-text transcriptional accuracy issues. For patients who are not native English speakers, and elderly people with dialect accents, the generalization ability of text-based feature AD detection methods may be limited.
Compared to text-based feature approaches, using only acoustic features allows for extracting direct information from the speech itself, which is more robust to the native language of the subject. Luz [9] used spontaneous speech data from the “cookie theft” picture description task in the Pitt database, extracted statistical and nominal acoustic features, and achieved a 68% accuracy using a Bayesian classifier. Eyben et al. [10] designed a unified feature set, Computational Paralinguistics ChallengE (ComParE), based on the features and lessons learned from the 2009–2012 challenge, which has general applicability in paralinguistic information extraction. Eyben et al. [11] proposed a standard acoustic parameter set, the extended Geneva minimalistic acoustic parameter set (eGeMAPS), such that the research results obtained in various areas of automatic speech analysis could be properly compared. Moreover, some researchers explored acoustic features for AD diagnosis from the perspective of digital signal processing, such as higher-order spectral features [12], fractal features [13], and wavelet-packet-based features [14].
Speech pauses can reflect the speaker’s cognitive function. Patients with neurodegenerative diseases have decreased cognitive function and often exhibit language impairment, such as frontotemporal lobar degeneration [15], Lewy body spectrum disorders [16], primary progressive aphasia [17] and AD [18]. Patients with AD experience disfluency, a high number of pauses, and repetition in speech, which is attributed to lexical retrieval difficulties due to cognitive decline [19]. Therefore, pauses are often used to analyze the speech and language of AD patients in order to assess their cognitive level [7,20,21].
Pauses mainly include filled and silent (unfilled) pauses. English has two common filled pauses: “uh” and “um” [7]. The term “silent pause” represents a temporal region in which a speaker does not utter a word, phrase, or sentence during spontaneous speech [22]. Researchers detected AD by calculating features such as the location, duration and frequency of the two types of pauses [23,24,25]. However, in some AD-related classification tasks, silent pauses performed better than filled pauses [23,26]. Moreover, silent pauses are easier to obtain from speech signals and more convenient for AD detection in daily conversation. In addition, silent pauses can be used to detect other acquired language disorders [27,28]. Therefore, this paper focuses on the study of silent pauses (hereafter, silent pauses are referred to as pauses).
Pauses have been shown to be effective in the detection of AD. Vincze et al. [23] acquired speech recordings by stimulating participants’ memory systems through three connected speech tasks, and used the PRAAT software for language analysis. The results show that the length, number, and rate of pauses differed between AD patients and healthy controls. Yuan et al. [7] likewise studied the variability of speech pauses between AD and healthy controls, classifying pauses into three discrete categories (under 0.5 s, 0.5–2 s, and over 2 s) based on their duration, with three types of punctuation (“,”, “.”, and “…”), marking the pauses in different groups and encoding them into word sequences to form pause-encoded transcripts. They used the ERNIE model for classification and achieved a high accuracy on the ADReSS test set. However, the approach remains a method of speech and language fusion, relying on speech transcription. Moreover, the discrete representation of pause features may not necessarily reflect all cognitive impairment information contained in the pause.
In order to provide a simple, widely available screening method for AD, this paper further explores the use of pauses in AD detection and proposes a voice activity detection (VAD)-based pausing feature recognition strategy, which can automatically generate pausing sequences in patients’ spontaneous speech. We compare the performance of the constructed pause features, with the public feature set on different machine-learning classifiers. The effectiveness of VAD Pause was verified on a local dataset. The main contributions of this study are listed as follows:
(1) We introduce an acoustic feature named the VAD Pause, extracted from speech signals on the newly shared ADReSS and ADReSSo English datasets, and the VAD Pause features are tested on a local Chinese dataset.
(2) A machine-learning-based ensemble approach using only acoustic features is proposed for AD classification.
(3) Statistical results revealed that VAD Pause features are higher in classification accuracy than the acoustic feature sets, and the ensemble method has higher classification value than the public feature-set-based method.
2. Materials and Methods
2.1. System Framework
The framework of the proposed method is shown in Figure 1. First, the participant was asked to perform a picture description task (“Cookie Theft” picture), during which their voice was recorded. Second, the speech signal was pre-processed to standardize it for next processing. Then, two types of features were extracted from speech signals. The first was the VAD-based pause feature proposed by the research, and the other was the feature from the common feature set. We compare the effectiveness of features on different classifiers. At the same time, in order to integrate the advantages of different types of features, we also designed a feature ensemble method based on the major voting strategy to obtain a better AD detection performance.
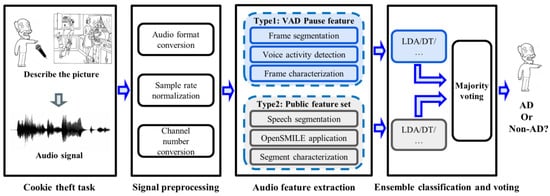
Figure 1.
System framework for AD detection. LDA, linear discriminant analysis; DT, decision trees; AD, Alzheimer’s Disease.
The following will be introduced in detail from dataset descriptions, information preprocessing, feature extraction, ensemble classification methods, and evaluation methods.
2.2. Dataset Descriptions
2.2.1. Public Dataset
To evaluate the performance of our method, publicly available English audio datasets from references [29,30] were used for training and testing (ADReSS Challenge and ADReSSo Challenge). The challenges were organized by Reacher Saturnino Luz, Fasih Haider, and Sofia de la Fuente Garcia from the University of Edinburgh, and Davida Fromm and Brian MacWhinney of Carnegie Mellon University. They targeted a difficult automatic prediction problem of societal and medical significance, namely the detection of cognitive impairment and Alzheimer’s dementia. The competitions provide standard datasets of spontaneous speech, defining a shared task by which different spontaneous speech-based AD detection approaches can be compared.
The datasets consist of a set of recordings of picture descriptions produced by patients with an AD diagnosis and cognitively normal subjects, who were asked to describe the “Cookie Theft” picture from the Boston Diagnostic Aphasia Examination [31,32]. The ADReSS Challenge dataset consists of recordings of 156 participants, while the ADReSSo Challenge dataset contains speech clips of 237 participants, both of which have been balanced with respect to age and gender to eliminate potential confounding and bias. For the data used in the classification task, competitions were classified as both mild cognitive impairment (MCI) and the dementia stage as AD, with matched controls as non-AD.
The details of the ADReSS and the ADReSSo Challenge dataset are as follows:
- Dataset ADReSS: 70% of the ADReSS2020 data were used as the training set, and 30% of the data were used as the test set;
- Dataset ADReSSo: 70% of the ADReSSo2021 data were used as the training set, and 30% of the data were used as the test set. Table 1 shows the composition and distribution of the datasets we used.
 Table 1. Data composition of English public datasets.
Table 1. Data composition of English public datasets.
2.2.2. Local Dataset
A total of 10 audio signals (Chinses) were recorded in this study, including 5 in the AD group, and 5 in the control group (CN).
Patients were recruited from the Nanjing Brain Hospital in the Jiangsu Province, China. Cases assessed by experienced neurologists were based on the criteria for the clinical diagnosis of AD, which were established by the National Institute of Neurological and Communicative Disorders and Stroke (NINCDS) and the Alzheimer’s Disease and Related Disorders Association (ADRDA) workgroup in 1984 [33]. The Mini-Mental State Examination (MMSE) were adopted. A professional conducted the MMSE measurements prior to the picture description experiment.
The inclusion criteria varied according to the educational level of the patients. The inclusion criteria for illiterate patients were MMSE ≤ 17 and meeting the criteria for NINCDS-ADRDA. The inclusion criteria for primary school patients were MMSE ≤ 20 and meeting the criteria for NINCDS-ADRDA. The inclusion criteria for middle school and above patients were MMSE ≤ 24 and meeting the criteria for NINCDS-ADRDA. The exclusion criteria included: (1) speech impairment; (2) a history of severe stroke, extensive multiple cerebral infarction, critical cerebral infarction or severe white matter lesions; (3) previous psychiatric or psychological disorders; (4) other neurological disorders that cause cognitive impairment, e.g., Lewy body dementia, Parkinson’s disease, hydrocephalus, vascular cognitive; (5) other diseases that can cause dementia, such as severe anemia, thyroid disease, syphilis, HIV infection, etc.; (6) combined with serious heart, liver, kidney and other medical diseases, or combined with serious hypertension, diabetes and other complications; (7) unable to cooperate with the completion of cranial MRI or CT scan. The regional review board approved the use of human participants in this study. Patients signed written informed consent forms before participation. The study was approved by the ethics committee of The First Affiliated Hospital with Nanjing Medical University, Nanjing, China, in accordance with the Helsinki Declaration.
Referring to the challenges, participants were asked to describe the “Cookie Theft” picture. Speech signals were recorded using the SONY recording pen (ICD-TX660, Nanjing City, China). We collected 10 voice messages ranging in length from 25 s to 183 s. The audio recording information details are summarized in Table 2.
Table 2.
Audio information of local Chinese dataset.
2.3. Preprocessing
Speech signal preprocessing was divided into three steps: audio format conversion, sample rate normalization, and channel number conversion. Based on the format conversion algorithm, the audio was unified into the ‘.wav’ format at first. Then, to normalize the audio, the audio sampling rate was unified to 44,100 Hz. Finally, we detected the number of channels of the audio, and converted them to mono audio.
2.4. Feature Extraction
Two kinds of acoustic features used in this study were introduced in detail. One was a pause feature based on the speech signal called VAD Pause, while the other was two commonly used acoustic feature sets, ComParE and eGeMAPS. We extracted the public feature sets for comparison with the VAD Pause, and fused them to propose an ensemble method for detecting AD.
2.4.1. VAD Pause Feature
Initially, we sectioned a voice recording into audio frames, and then used WebRTC VAD to detect each audio frame. Ultimately, a piece of audio datum was marked as the voiced and non-voiced frame according to the scale of audio frame, and this sequence was regarded as the pause feature of the speech. As shown in Figure 2, we set the frame duration to 0.03 s, such that the original 0.12 s of audio data turned into the VAD Pause feature, which was a sequence with four labels. Zero represents the non-voiced frame, and one represents the voiced frame.
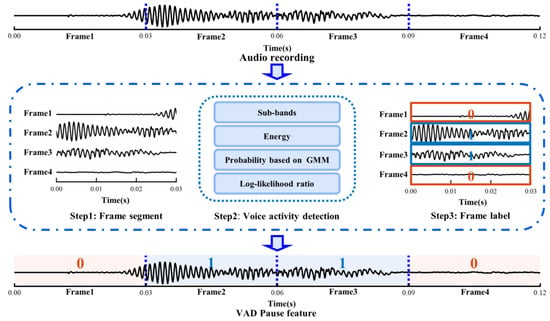
Figure 2.
Schematic diagram of extracting VAD Pause. GMM, Gaussian mixture model.
The Google WebRTC VAD method was used to identify whether the audio frame was in a voiced or silent state. The detection procedure was as follows:
First, according to the correspondence between human speech pronunciation regulation and acoustic frequency, an audio frame was divided into six sub-bands: 80–250 Hz, 250–500 Hz, 500 Hz–1 kHz, 1–2, 2–3, 3–4 kHz. Next, the energy of the six sub-bands was calculated and denoted as E1, E2, E3, E4, E5, E6, and the total energy of the audio frame Et.
Then, if the total energy of the audio frame Et was greater than the energy threshold Tm, we proceeded to the following step:
- For each sub-band, we made the assumptions that:
H0.
the energy of the sub-band satisfied the Gaussian distribution of silent states.
H1.
the energy of the sub-band satisfied the Gaussian distribution of voiced states.
- 2.
- For each sub-band, the probability that it belonged to the silent state was calculated based on the silent Gaussian mixture model (GMM):
For each sub-band, the probability that it belonged to the voiced state was calculated based on the voiced GMM:
where Ei (i = 1, 2, …, 6) denotes the energy of the sub-band; ws1, ws2 and wv1, wv2 denote the weights for silent and voiced mixture Gaussian distributions, respectively; μs1, μs2, and μv1, μv2 denote the respective means; σs1, σs2, and σv1, σv2 denote the respective standard deviations.
- 3.
- The log-likelihood ratio Li for each sub-band and the total log-likelihood ratio Lt were calculated according to the formula:
- 4.
- The thresholds Tτ and Ta were compared to determine whether the audio frame was audible or silent:
2.4.2. Common Acoustic Feature Sets
We used an open-source software package openSMILE toolkit, widely employed for emotion and affect recognition in speech [34], for acoustic feature set extraction of speech fragments. Following is a brief description of the two feature sets constructed in this manner:
ComParE: The ComParE 2013 [10] feature set includes energy, spectral, Mel-Frequency Cepstral Coefficients (MFCC), and logarithmic harmonic-to-noise ratio, voice quality features, Viterbi smoothing for F0, spectral harmonicity, and psychoacoustic spectral sharpness. Furthermore, statistical functions were applied to these features, bringing the total to 6373 features for every speech segment.
eGeMAPS: The eGeMAPS [11] feature set contains the F0 semitone, jitter, shimmer, loudness, spectral flux, MFCC, F1, F2, F3, alpha ratio, Hammarberg index, and slope V0 features. Statistical functionals were also computed, for a total of 88 features per speech segment.
2.5. Ensemble Classification and Voting
A novel fusion method was introduced based on the mentioned features and classifiers, as illustrated in Figure 3. Two-step classification experiments were conducted to detect AD. First, the signal was segmented into four s-long sequences after preprocessing and use of the segment-level classification, where classifiers were trained and tested to predict whether a speech segment was uttered by an AD or non-AD patient. Then, we calculated the majority vote from the segment-level results of classifiers, and returned a class label for each subject.
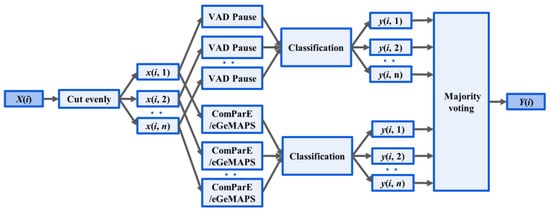
Figure 3.
Ensemble Method: X(i), the audio recording, was divided into n segments x(i, n). Acoustic feature extraction (VAD Pause, ComParE and eGeMAPS) was performed at the segment level. The output of classification for the nth segment of the ith recording is denoted y(i, n). Y(i) outputs the majority voting for classification.
The classify model included five classic machine-learning methods, namely: linear discriminant analysis (LDA), decision trees (DT), k-nearest neighbor (KNN), support vector machines (SVM with a linear kernel and a sequential minimal optimization solver), and tree bagger (TB).
In order to focus on the effect of speech features and avoid the interference of classifier factors, the traditional machine-learning model, with relatively mature research and strong interpretability, was used as the classifier of this paper. When the validity of the proposed pause feature sequence was determined, such sequence could be directly used as input for training the depth neural network classifier. It could also be further fused with other semantic-based AD detection features to obtain better classification performance.
2.6. Evaluation
2.6.1. Classification Metrics
Depending on whether the predicted label matched with the true label, the outputs of a binary classification algorithm fell into one of the four categories: true positives (TP), false positives (FP), false negatives (FN), and true negatives (TN). The classification metrics are defined as follows:
2.6.2. Statistical Analysis
To explore whether the feature was truly effective from the perspective of data analysis, the effects of classifiers and features on classification accuracy were tested with a two-way ANOVA (feature (ComParE, eGeMAPS, VAD Pause, ensemble) and classifier (LDA, DT, KNN, SVM, TB) as factors. If there was no interaction between the factors, further multivariate analysis could be performed to analyze the inter-group differences of a single factor, while if the interaction between the factors appeared significant, multiple analysis was further conducted to determine which level of combination of classifiers and features had the highest average classification accuracy.
3. Results
The results are presented in four parts. First, an intuitive comparison of pause features in AD and non-AD populations is provided. Second, quantitative comparison results of our method are shown in two datasets. Then, a statistical analysis of the classification methods was conducted to demonstrate the validity of the proposed pause feature and the ensemble method. Finally, the VAD Pause features were tested on our own collected Chinese dataset.
3.1. Comparison of VAD Pauses in AD and Non-AD Subjects
To investigate whether the speech of the AD and controls differed in pauses, we visualized the original speech recordings and VAD Pause features to analyze and confirm the difference from a visual point of view. We selected ten audio clips (half of the speakers were AD subjects, and half were non-AD) of about 1 min length from the test set of the ADReSS2020 dataset. Then, we intercepted the first 24 s of data and extracted their VAD Pause features from them. Figure 4 shows the raw voice waveform (A,B) and VAD Pause features of the voice recordings (C,D).
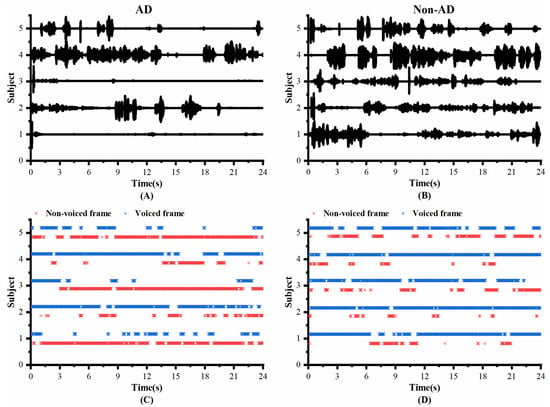
Figure 4.
Contrast display of representative signals from AD and non-AD subjects: (A) raw audio recordings of AD; (B) raw audio recordings of non-AD; (C) VAD Pause features of AD; (D) VAD Pause features of non-AD. The blue asterisks represent voiced frames, whereas red represent non-voiced frames in the figure of pause features.
Figure 4 shows some differences in the speech between the AD and non-AD subjects. From the comparison, the subjects with AD had more pauses in every group, and exhibited poor speech coherence compared to healthy controls. The speech recordings of healthy controls contained more voiced frames. Although pauses were present, the speech was more continuous than in the AD group.
3.2. Quantitative Results in Classic Machine-Learning Methods
We applied the VAD Pause to five machine-learning methods employed previously by [29,30], namely LDA, DT, KNN, SVM, and TB, for AD and non-AD classification. The classification results of all methods on the datasets ADReSS and ADReSSo, are reported in Figure 5 and Figure 6, respectively. For a fair comparison, the ComParE with the best effect used in the literature [29] was selected and tested on the dataset ADReSS, while the eGeMAPS used in the literature [30] was selected and tested on the dataset ADReSSo. All classifiers used the same parameters as those in the literature, and each classification was performed with five runs and shuffling the data order. The average results of the operations are shown in the figures.
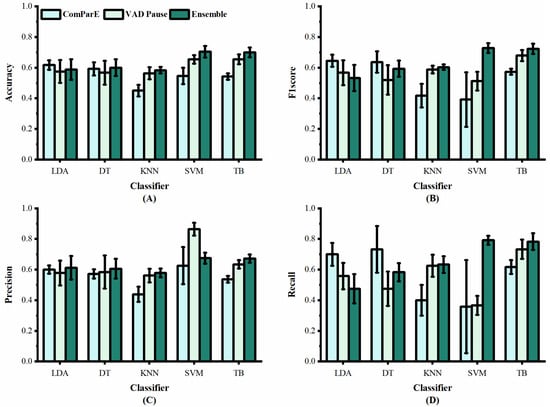
Figure 5.
Performance of features from our study and [29] on dataset ADReSS: (A) accuracy; (B) F1 score; (C) precision; (D) recall.
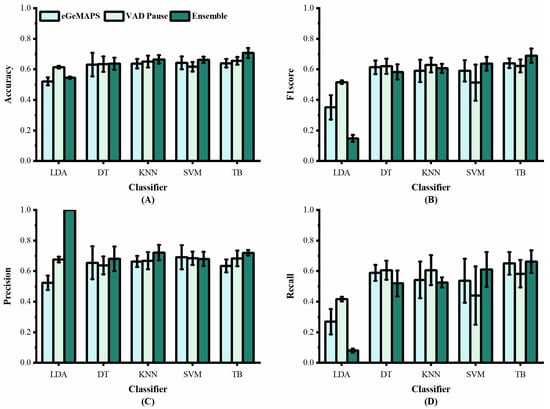
Figure 6.
Performance of features from our study and [30] on dataset ADReSSo: (A) accuracy; (B) F1 score; (C) precision; (D) recall.
Figure 5 shows the classification results of the proposed VAD Pause feature and ComParE, using five machine-learning methods on dataset ADReSS. It can be observed that the VAD Pause had a better classification effect and smaller error bars than the ComParE on three machine-learning methods KNN, SVM, and TB. Our VAD Pause with the TB had the best effect, reaching 65.4% accuracy, 67.9% F1 score, 63.4% precision, and 73.3% recall. This indicates better performance than the acoustic feature-based baseline accuracy of 62.5% obtained by [29].
Figure 6 shows the classification results of the proposed VAD Pause feature and eGeMAPS, using five machine-learning methods on the dataset ADReSSo. It can be observed that the VAD Pause feature proposed in this study had a better classification performance and smaller error bars than the eGeMAPS on the same dataset using LDA, KNN, DT, and TB. Our VAD Pause with the TB had the best effect, reaching 65.6% accuracy, 62.3% F1 score, 68.3% precision, and 58.3% recall. Thus, it performed better than the acoustic feature-based baseline accuracy of 64.8% obtained by [30].
Although the VAD Pause gains advantages compared to ComParE and the eGeMAPS, a method that can improve the classification results is required. Thus, we introduced the ensemble procedure. We observed that the TB performs best (in terms of accuracy and stability), and the results are shown in Table 3. Our findings indicate that combining the public feature set (ComParE and eGeMAPS) with the VAD Pause improves the classification results. We further observe the variance from Figure 5 and Figure 6. The proposed ensemble method (dark green) improves the mean and reduces variance overestimates.
Table 3.
Accuracy (ACC) comparison of the ensemble method with other approaches, using only acoustic features on the test sets in the literature.
The classification performance of the presented ensemble method was also compared against other AD detection approaches on the test sets in the literature, shown in Table 3. Our proposed ensemble method achieved the best performance among methods without the deep-learning (DL) model.
3.3. Statistical Analysis of Classification Methods
To verify whether our method achieves significant improvement, statistical analysis was used to compare the classification results. Figure 7 illustrates the overall effect of different features or the ensemble method, using five machine-learning classifiers on the two datasets. In contrast to the public feature set, the proposed feature and method have a higher average recognition rate, with less recognition dispersion in testing. Thus, the proposed feature and method exhibit better generalization ability.
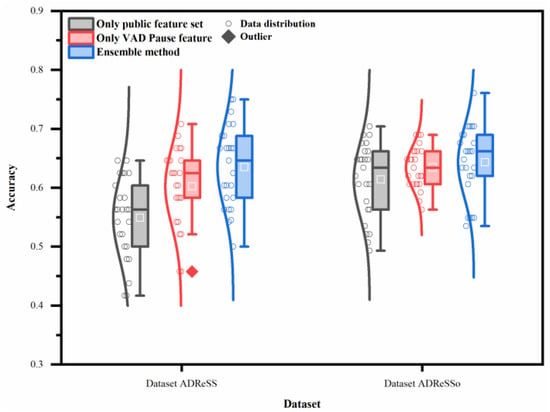
Figure 7.
Performance of different features or ensemble method on two datasets (datasets ADReSS and ADReSSo), using five machine-learning classifiers.
The two-way ANOVA reveals that both classifiers and features contribute to the differences noted in the classification accuracy (p < 0.05). The interaction between them is also very significant on the datasets ADReSS and ADReSSo (p < 0.05).
Multiple analysis is further conducted to determine the level of combination of classifiers and features that had the highest average classification accuracy, as the interaction between classifiers and features appeared significant on the datasets ADReSS and ADReSSo. The results of the multiple analysis (Figure 8A,B) show that slightly different results are obtained from different datasets. These combinations achieved the best results on both sets of data: the ensemble method with DT, the ensemble method with SVM, the VAD Pause feature with TB, and the ensemble method with TB. The simple effects analyses confirmed that the proposed ensemble method and VAD Pause-based method have significantly higher classification accuracies than the public feature set-based method, which is consistent with our results in Section 3.2.
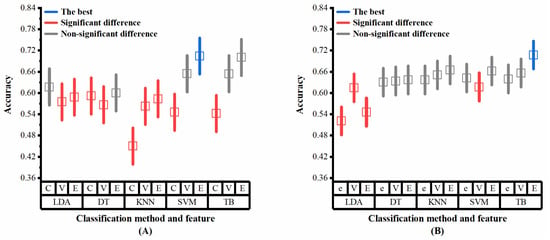
Figure 8.
Multiple analysis results (classifiers and features as factors) on the two datasets: (A) dataset ADReSS; (B) dataset ADReSSo. C, ComParE; V, VAD Pause; E, ensemble; e, eGeMAPS. Blue lines represent the optimal performance, red lines represent significant difference from the optimal performance, gray lines represent non-significant difference from the optimal performance.
3.4. Experimental Results on a Local Dataset
In aiming to test the effectiveness of VAD Pause features in practical applications, we initially collected ten Chinese speech recordings for experimentation. The ADReSS and ADReSSo English datasets were mixed to serve as the training set after the overlapping data were removed. Then, the five classifiers were fed separately for training, and finally the classification results were tested separately on the local Chinese dataset.
As shown in Table 4, the VAD Pause feature obtained good classification results on the local Chinese dataset. The classification was basically correct for all AD patients, but there was potential for improvement in the classification of healthy individuals. To further explore the causes of classification errors, the raw waveforms and VAD Pause features of the local Chinese speech dataset are shown in Figure 9.
Table 4.
Performance of the VAD Pause feature on a local dataset, using five machine-learning classifiers.
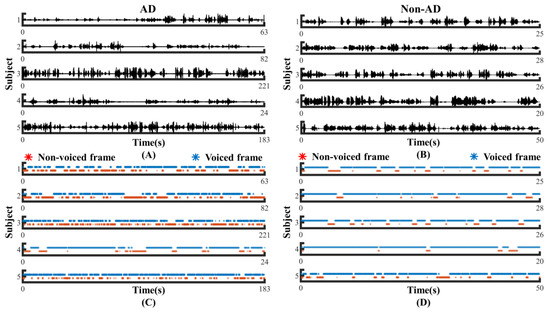
Figure 9.
Contrast display of clinical data from AD and non-AD subjects: (A) raw audio recordings of AD; (B) raw audio recordings of non-AD; (C) VAD Pause features of AD; (D) VAD Pause features of non-AD. The blue asterisks represent voiced frames, whereas the red asterisks represent non-voiced frames in the figure of pause features.
As seen in Figure 9, there were more and longer pauses in the speech of AD patients compared to healthy people in the local dataset, which is consistent with our previous results discussed in Figure 4. It is normal that 1, 3, and 5, which have a relatively high number of pauses in healthy people, have the possibility of being misclassified, which may be related to the existence of pauses in or between utterances in Chinese itself. Additionally, the native language of the participating subjects in the local dataset was Chinese with interspersed dialects, while the public dataset was English. Our proposed features have significant discriminative power on the test subjects of different languages, which shows the advantage of AD recognition based on speech features only.
4. Discussion
In this paper, we tried to mine the AD symptom information contained in the speech signal itself from the pause perspective, and proposed a VAD-Pause-based method for AD detection that can be applied to easily and conveniently screen for AD in the future. The method was tested for AD classification on the English public datasets and our own local Chinese dataset. We explored the effect of applying the VAD Pause and machine-learning methods, and a novel ensemble method, as well as possible independence/interdependence of their association with the AD classification. The results confirm that AD subjects use more pauses than healthy controls, and that the VAD Pause and ensemble method have higher classification values and better generalization ability than public acoustic feature sets.
The effectiveness and generalization ability of the VAD Pause for AD detection constitute the most intriguing results. VAD Pause performance can be attributed to the difference in pauses in speech between the two groups. Previous studies reported that in speech production, disfluencies, such as hesitations and speech errors, are correlated with cognitive functions, such as cognitive load, arousal, and working memory [45,46]. Semantic verbal fluency and phonological verbal fluency tests are widely used in the diagnosis of AD, and they are reliable indicators of language deterioration in the early detection of AD [47]. Another study suggested that AD patients require more effort to speak than healthy individuals: namely, patients speak more slowly with longer pauses [48]. Yuan et al. [7] studied the function of pauses from the perspective of manual transcription, and concluded that AD subjects used more and longer pauses than healthy people. All of these results seem to suggest that pauses have a potential status in the distinction between the AD and non-AD. Furthermore, the VAD Pause may be a valid feature that represents pauses well. Figure 4 and Figure 9 show that generalizing the difference between the two for original recordings, which hold a significant amount of information, is not a trivial task, whereas the VAD Pause feature proposed in this study shows the difference visually.
Notably, our result is representative of the performance of AD detection when using only audio recordings, without transcription. Several reasons account for the advantages of this practice. First, it is more practical to detect AD using speech directly. When a physician conducts a clinical interview, they usually evaluate the patient directly based on their voice, rather than transcribing the words. When the program detects AD directly via speech, it takes less time than when needing to transcribe it into text. Moreover, in this study, we use pauses as detection features, while transcription had an effect on the detection of pauses. A prior study showed that transcription errors impacted findings related to the usefulness of prosodic features in parsing [49]. Several state-of-the-art approaches rely on this manually generated text for feature extraction, and their performance may vary depending on whether the transcription is automated [3]. If we use speech directly for feature extraction and AD detection, the influence of transcription can be avoided, and the error generated in the process may be reduced.
Comparisons with other methods using the same data attract particular interest. Table 3 shows that methods using acoustic features for AD detection can be divided into two categories: those that use DL and those that do not. Our ensemble method achieves the best results among methods that do not rely on DL [29,30,39,44]. In the dataset ADReSS, the pre-trained VGGish model and Uni-CRNN are used in the method proposed by [35]. An accuracy of 72.9% was achieved with this method. In addition, among the DL-related approaches, some studies use neural networks as classifiers, while others focus on using them to extract acoustic embeddings. Cummins et al. [36] and Rohanian et al. [37] combined public acoustic features with neural networks and achieved an accuracy of 70.8 and 66.6%, respectively. Acoustic embeddings as speech features started to attract the attention of numerous researchers, and have gained good performance in AD detection [38,40,41,42,43]. There appears to be a trade-off in accuracy and convenience. Methods using DL are more accurate, but methods without DL are more convenient. A better approach could involve using VAD Pause and acoustic embeddings to represent speech information. Due to time cost and practicality, we will further explore this idea in future.
We showed that both the features and classifiers used in this study contribute to the classification performance, as the results of the two-way ANOVA were significant in all two datasets. Moreover, in the datasets ADReSS and ADReSSo, the factor contribution to the highest average classification accuracy was intertwined. Statistically, the ensemble method with DT, the ensemble method with SVM, the VAD Pause feature with TB, and the ensemble method with TB have similarly high accuracies. Based on the analysis of these results, we recommend the ensemble method with TB, as it achieves stable and high accuracy, while several other methods are likewise available (ensemble method with DT, ensemble method with SVM, VAD Pause feature with TB). Additionally, we did not explore the effect of using DL networks for classification. Yet, usually DL classification requires a significant amount of data and time, such that it is necessary to optimize and improve the algorithm, which will be a future direction of our study.
Silent pauses have been implemented to other populations beyond AD. Some researchers have investigated the use of silent pause features for disease detection. Mignard et al. [50] investigated fluency disorders in Parkinson’s patients by the pause ratio. Potagas et al. [51] used speech rate, articulation rate, pause frequency, and pause duration as analytical indicators, and the results showed that silent pauses can be used as complementary biomarkers for PPA. Imre et al. [52] conducted a study on the temporal speech characteristics of elderly patients with type 2 diabetes (T2DM). The healthy cognition participants in the T2DM group showed higher duration rate of silent pause and total pause, and a higher average duration of silent pauses and total pauses compared to the group without T2DM group. These methods were mainly carried out based on the calculation of the frequency and duration of silent pauses, etc. Compared to previous publications, the method we propose to encode speech into a sequence of pauses can characterize the temporal sequence of pauses in speech more accurately, while the data processing is simpler and easy to implement and repeat.
Spontaneous speech analysis plays an important role in the study of acquired language disorders. Ditthapron et al. [27] used smartphones to passively capture changes in acoustic characteristics of spontaneous speech for continuous traumatic brain injury monitoring. Spontaneous speech can also be used for research on depression [53] and aphasia [28,54]. Thus, our proposed spontaneous speech-based approach has the potential to be used in other clinical populations with acquired language disorders. In future work, we consider investigating the feasibility of applying this method to other populations.
5. Conclusions
We proposed a pause/non-pause feature sequence (VAD Pause) encoded using only speech, and investigated its effectiveness when applied to distinguish AD patients from healthy subjects. Its classification effect was tested on both public datasets and a local dataset. We further introduced an ensemble method for AD classification from spontaneous speech and investigated the impact of features and classifiers on the results in detail, further demonstrating the superiority of the ensemble method through a comprehensive comparison of classification results of different datasets (two English datasets and one Chinese dataset). The results of the study suggest that our method can be partly immune to AD detection errors due to the language environment, which is of greater value for the widespread screening of AD. In future work, the proposed AD screening method will be considered extended to the detection of other acquired speech disorders, with appropriate modifications. We will also collect more local data to further demonstrate the reliability and potential of our proposed method.
Author Contributions
J.L. (Jianqing Li) and B.L. designed the research. J.Y., D.Z., S.Z. and Y.Z. supervised the study. J.L. (Jiamin Liu), F.F. and L.L. performed the research. J.L. (Jiamin Liu) and F.F. analyzed the data. J.L. (Jiamin Liu), F.F. and L.L. interpreted the results. J.L. (Jiamin Liu), F.F. and L.L. wrote the original draft. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the National Key Research and Development Program of China (2022YFC2405600), NSFC (81871444, 62071241, 62075098, 62001240), the Leading-edge Technology and Basic Research Program of Jiangsu (BK20192004D), the Key Research and Development Program of Jiangsu (BE2022160), and the Postgraduate Research and Practice Innovation Program of Jiangsu Province (KYCX22_1779).
Institutional Review Board Statement
The study was approved by the ethics committee of The First Affiliated Hospital with Nanjing Medical University, Nanjing, China, in accordance with the Helsinki Declaration. Approval code: 2019-SR-310, date: 27 November 2019.
Informed Consent Statement
All of the participants signed written informed consent forms before participation.
Data Availability Statement
The local datasets analyzed during the current study are not publicly available due to patient privacy, but are available from the corresponding author on reasonable request. Public challenge datasets can be found at: https://dementia.talkbank.org/ADReSS-2020/ and https://dementia.talkbank.org/ADReSS-2021/ (accessed on 8 October 2021).
Acknowledgments
The authors thank Yiding Lv for performing clinical assessments of AD patients.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Derby, C.A. Trends in the public health significance, definitions of disease, and implications for prevention of Alzheimer’s disease. Curr. Epidemiol. Rep. 2020, 7, 68–76. [Google Scholar] [CrossRef] [PubMed]
- Alzheimer’s Disease International. World Alzheimer Report 2019: Attitudes to Dementia; Alzheimer’s Disease International: London, UK, 2019. [Google Scholar]
- Mahajan, P.; Baths, V. Acoustic and language based deep learning approaches for Alzheimer’s dementia detection from spontaneous speech. Front. Aging Neurosci. 2021, 13, 623607. [Google Scholar] [CrossRef] [PubMed]
- Mueller, K.D.; Koscik, R.L.; Hermann, B.P.; Johnson, S.C.; Turkstra, L.S. Declines in connected language are associated with very early mild cognitive impairment: Results from the Wisconsin registry for Alzheimer’s prevention. Front. Aging Neurosci. 2018, 9, 437. [Google Scholar] [CrossRef] [PubMed]
- Mesulam, M.; Wicklund, A.; Johnson, N.; Rogalski, E.; Léger, G.C.; Rademaker, A.; Weintraub, S.; Bigio, E.H. Alzheimer and frontotemporal pathology in subsets of primary progressive aphasia. Ann. Neurol. 2008, 63, 709–719. [Google Scholar] [CrossRef]
- Meghanani, A.; Anoop, C.; Ramakrishnan, A.G. Recognition of alzheimer’s dementia from the transcriptions of spontaneous speech using fasttext and cnn models. Front. Comput. Sci. 2021, 3, 624558. [Google Scholar] [CrossRef]
- Yuan, J.; Cai, X.; Bian, Y.; Ye, Z.; Church, K. Pauses for detection of Alzheimer’s disease. Front. Comput. Sci. 2021, 2, 624488. [Google Scholar] [CrossRef]
- Agbavor, F.; Liang, H. Artificial Intelligence-Enabled End-To-End Detection and Assessment of Alzheimer’s Disease Using Voice. Brain Sci. 2023, 13, 28. [Google Scholar] [CrossRef]
- Luz, S. Longitudinal monitoring and detection of Alzheimer’s type dementia from spontaneous speech data. In Proceedings of the 2017 IEEE 30th International Symposium on Computer-Based Medical Systems (CBMS), Thessaloniki, Greece, 22–24 June 2017; pp. 45–46. [Google Scholar]
- Eyben, F.; Weninger, F.; Gross, F.; Schuller, B. Recent developments in opensmile, the munich open-source multimedia feature extractor. In Proceedings of the 21st ACM International Conference on Multimedia, Barcelona Spain, 21–25 October 2013; pp. 835–838. [Google Scholar]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S. The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE Trans. Affect. Comput. 2015, 7, 190–202. [Google Scholar] [CrossRef]
- Nasrolahzadeh, M.; Rahnamayan, S.; Haddadnia, J. Alzheimer’s disease diagnosis using genetic programming based on higher order spectra features. Mach. Learn. Appl. 2022, 7, 100225. [Google Scholar] [CrossRef]
- Lopez-de-Ipiña, K.; Alonso-Hernández, J.; Solé-Casals, J.; Travieso-González, C.M.; Ezeiza, A.; Faundez-Zanuy, M.; Calvo, P.M.; Beitia, B. Feature selection for automatic analysis of emotional response based on nonlinear speech modeling suitable for diagnosis of Alzheimer’s disease. Neurocomputing 2015, 150, 392–401. [Google Scholar] [CrossRef]
- Nasrolahzadeh, M.; Haddadnia, J.; Rahnamayan, S. Multi-objective optimization of wavelet-packet-based features in pathological diagnosis of alzheimer using spontaneous speech signals. IEEE Access 2020, 8, 112393–112406. [Google Scholar] [CrossRef]
- Ash, S.; Moore, P.; Vesely, L.; Gunawardena, D.; McMillan, C.; Anderson, C.; Avants, B.; Grossman, M. Non-fluent speech in frontotemporal lobar degeneration. J. Neurolinguist. 2009, 22, 370–383. [Google Scholar] [CrossRef] [PubMed]
- Ash, S.; Xie, S.X.; Gross, R.G.; Dreyfuss, M.; Boller, A.; Camp, E.; Morgan, B.; O’Shea, J.; Grossman, M. The organization and anatomy of narrative comprehension and expression in Lewy body spectrum disorders. Neuropsychology 2012, 26, 368. [Google Scholar] [CrossRef] [PubMed]
- Wilson, S.M.; Henry, M.L.; Besbris, M.; Ogar, J.M.; Dronkers, N.F.; Jarrold, W.; Miller, B.L.; Gorno-Tempini, M.L. Connected speech production in three variants of primary progressive aphasia. Brain 2010, 133, 2069–2088. [Google Scholar] [CrossRef]
- Lindsay, H.; Tröger, J.; König, A. Language impairment in alzheimer’s disease—Robust and explainable evidence for ad-related deterioration of spontaneous speech through multilingual machine learning. Front. Aging Neurosci. 2021, 228, 642033. [Google Scholar] [CrossRef]
- Pistono, A.; Jucla, M.; Barbeau, E.J.; Saint-Aubert, L.; Lemesle, B.; Calvet, B.; Köpke, B.; Puel, M.; Pariente, J. Pauses during autobiographical discourse reflect episodic memory processes in early Alzheimer’s disease. J. Alzheimer’s Dis. 2016, 50, 687–698. [Google Scholar] [CrossRef] [PubMed]
- Yuan, J.; Xu, X.; Lai, W.; Liberman, M. Pauses and pause fillers in Mandarin monologue speech: The effects of sex and proficiency. In Proceedings of the Speech Prosody 2016, Boston, MA, USA, 31 May–3 June 2016; pp. 1167–1170. [Google Scholar]
- Shea, C.; Leonard, K. Evaluating measures of pausing for second language fluency research. Can. Mod. Lang. Rev. 2019, 75, 216–235. [Google Scholar] [CrossRef]
- Ogata, J.; Goto, M.; Itou, K. The use of acoustically detected filled and silent pauses in spontaneous speech recognition. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 4305–4308. [Google Scholar]
- Vincze, V.; Szatlóczki, G.; Tóth, L.; Gosztolya, G.; Pákáski, M.; Hoffmann, I.; Kálmán, J. Telltale silence: Temporal speech parameters discriminate between prodromal dementia and mild Alzheimer’s disease. Clin. Linguist. Phon. 2021, 35, 727–742. [Google Scholar] [CrossRef]
- Pistono, A.; Pariente, J.; Bézy, C.; Lemesle, B.; Le Men, J.; Jucla, M. What happens when nothing happens? An investigation of pauses as a compensatory mechanism in early Alzheimer’s disease. Neuropsychologia 2019, 124, 133–143. [Google Scholar] [CrossRef] [PubMed]
- Pastoriza-Domínguez, P.; Torre, I.G.; Diéguez-Vide, F.; Gomez-Ruiz, I.; Gelado, S.; Bello-López, J.; Ávila-Rivera, A.; Matias-Guiu, J.A.; Pytel, V.; Hernández-Fernández, A. Speech pause distribution as an early marker for Alzheimer’s disease. Speech Commun. 2022, 136, 107–117. [Google Scholar] [CrossRef]
- Gayraud, F.; Lee, H.-R.; Barkat-Defradas, M. Syntactic and lexical context of pauses and hesitations in the discourse of Alzheimer patients and healthy elderly subjects. Clin. Linguist. Phon. 2011, 25, 198–209. [Google Scholar] [CrossRef] [PubMed]
- Ditthapron, A.; Lammert, A.C.; Agu, E.O. Continuous TBI Monitoring From Spontaneous Speech Using Parametrized Sinc Filters and a Cascading GRU. IEEE J. Biomed. Health Inform. 2022, 26, 3517–3528. [Google Scholar] [CrossRef] [PubMed]
- Lfab, C.; Abb, C.; Lba, D.; Jfb, C. Speech timing changes accompany speech entrainment in aphasia—ScienceDirect. J. Commun. Disord. 2021, 90, 106090. [Google Scholar]
- Luz, S.; Haider, F.; de la Fuente, S.; Fromm, D.; MacWhinney, B. Alzheimer’s dementia recognition through spontaneous speech: The ADReSS challenge. arXiv 2020, arXiv:2004.06833. [Google Scholar] [CrossRef]
- Luz, S.; Haider, F.; de la Fuente, S.; Fromm, D.; MacWhinney, B. Detecting cognitive decline using speech only: The ADReSSo Challenge. arXiv 2021, arXiv:2104.09356. [Google Scholar] [CrossRef]
- Becker, J.T.; Boiler, F.; Lopez, O.L.; Saxton, J.; McGonigle, K.L. The natural history of Alzheimer’s disease: Description of study cohort and accuracy of diagnosis. Arch. Neurol. 1994, 51, 585–594. [Google Scholar] [CrossRef]
- Goodglass, H.; Kaplan, E.; Weintraub, S. BDAE: The Boston Diagnostic Aphasia Examination; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2001. [Google Scholar]
- Jack Jr, C.R.; Albert, M.; Knopman, D.S.; McKhann, G.M.; Sperling, R.A.; Carillo, M.; Thies, W.; Phelps, C.H. Introduction to revised criteria for the diagnosis of Alzheimer’s disease: National Institute on Aging and the Alzheimer Association Workgroups. Alzheimer’s Dement. J. Alzheimer’s Assoc. 2011, 7, 257. [Google Scholar] [CrossRef]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multimedia, New York, NY, USA; 2010; pp. 1459–1462. [Google Scholar]
- Koo, J.; Lee, J.H.; Pyo, J.; Jo, Y.; Lee, K. Exploiting multi-modal features from pre-trained networks for Alzheimer’s dementia recognition. arXiv 2020, arXiv:2009.04070. [Google Scholar] [CrossRef]
- Cummins, N.; Pan, Y.; Ren, Z.; Fritsch, J.; Nallanthighal, V.S.; Christensen, H.; Blackburn, D.; Schuller, B.W.; Magimai-Doss, M.; Strik, H. A comparison of acoustic and linguistics methodologies for Alzheimer’s dementia recognition. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 2182–2186. [Google Scholar]
- Rohanian, M.; Hough, J.; Purver, M. Multi-modal fusion with gating using audio, lexical and disfluency features for Alzheimer’s dementia recognition from spontaneous speech. arXiv 2021, arXiv:2106.09668. [Google Scholar]
- Pappagari, R.; Cho, J.; Moro-Velazquez, L.; Dehak, N. Using State of the Art Speaker Recognition and Natural Language Processing Technologies to Detect Alzheimer’s Disease and Assess its Severity. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 2177–2181. [Google Scholar]
- Edwards, E.; Dognin, C.; Bollepalli, B.; Singh, M.K.; Analytics, V. Multiscale System for Alzheimer’s Dementia Recognition Through Spontaneous Speech. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 2197–2201. [Google Scholar]
- Balagopalan, A.; Novikova, J. Comparing Acoustic-based Approaches for Alzheimer’s Disease Detection. arXiv 2021, arXiv:2106.01555. [Google Scholar]
- Pan, Y.; Mirheidari, B.; Harris, J.M.; Thompson, J.C.; Jones, M.; Snowden, J.S.; Blackburn, D.; Christensen, H. Using the Outputs of Different Automatic Speech Recognition Paradigms for Acoustic-and BERT-Based Alzheimer’s Dementia Detection Through Spontaneous Speech. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 3810–3814. [Google Scholar]
- Pérez-Toro, P.A.; Bayerl, S.P.; Arias-Vergara, T.; Vásquez-Correa, J.C.; Klumpp, P.; Schuster, M.; Nöth, E.; Orozco-Arroyave, J.R.; Riedhammer, K. Influence of the Interviewer on the Automatic Assessment of Alzheimer’s Disease in the Context of the ADReSSo Challenge. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 3785–3789. [Google Scholar]
- Pappagari, R.; Cho, J.; Joshi, S.; Moro-Velázquez, L.; Zelasko, P.; Villalba, J.; Dehak, N. Automatic Detection and Assessment of Alzheimer Disease Using Speech and Language Technologies in Low-Resource Scenarios. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 3825–3829. [Google Scholar]
- Chen, J.; Ye, J.; Tang, F.; Zhou, J. Automatic detection of Alzheimer’s disease using spontaneous speech only. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; p. 3830. [Google Scholar]
- Daneman, M. Working memory as a predictor of verbal fluency. J. Psycholinguist. Res. 1991, 20, 445–464. [Google Scholar] [CrossRef]
- Arciuli, J.; Mallard, D.; Villar, G. “Um, I can tell you’re lying”: Linguistic markers of deception versus truth-telling in speech. Appl. Psycholinguist. 2010, 31, 397–411. [Google Scholar] [CrossRef]
- Laws, K.R.; Duncan, A.; Gale, T.M. ‘Normal’semantic–phonemic fluency discrepancy in Alzheimer’s disease? A meta-analytic study. Cortex 2010, 46, 595–601. [Google Scholar] [CrossRef] [PubMed]
- López-de-Ipiña, K.; Alonso, J.-B.; Travieso, C.M.; Solé-Casals, J.; Egiraun, H.; Faundez-Zanuy, M.; Ezeiza, A.; Barroso, N.; Ecay-Torres, M.; Martinez-Lage, P. On the selection of non-invasive methods based on speech analysis oriented to automatic Alzheimer disease diagnosis. Sensors 2013, 13, 6730–6745. [Google Scholar] [CrossRef]
- Tran, T.; Toshniwal, S.; Bansal, M.; Gimpel, K.; Livescu, K.; Ostendorf, M. Parsing speech: A neural approach to integrating lexical and acoustic-prosodic information. arXiv 2017, arXiv:1704.07287. [Google Scholar] [CrossRef]
- Mignard, P.; Cave, C.; Lagrue, B.; Meynadier, Y.; Viallet, F. Silent pauses in Parkinsonian patients during spontaneous speech and reading: An instrumental study. Rev. De Neuropsychol. 2001, 11, 39–63. [Google Scholar]
- Potagas, C.; Nikitopoulou, Z.; Angelopoulou, G.; Kasselimis, D.; Laskaris, N.; Kourtidou, E.; Constantinides, V.C.; Bougea, A.; Paraskevas, G.P.; Papageorgiou, G.; et al. Silent Pauses and Speech Indices as Biomarkers for Primary Progressive Aphasia. Medicina 2022, 58, 1352. [Google Scholar] [CrossRef]
- Imre, N.; Balogh, R.; Gosztolya, G.; Tóth, L.; Hoffmann, I.; Várkonyi, T.; Lengyel, C.; Pákáski, M.; Kálmán, J. Temporal Speech Parameters Indicate Early Cognitive Decline in Elderly Patients With Type 2 Diabetes Mellitus. Alzheimer Dis. Assoc. Disord. 2022, 36, 148. [Google Scholar] [CrossRef]
- Lu, X.; Shi, D.; Liu, Y.; Yuan, J. Speech depression recognition based on attentional residual network. Front. Biosci.-Landmark 2021, 26, 1746–1759. [Google Scholar] [CrossRef]
- Le, D.; Licata, K.; Provost, E.M. Automatic Quantitative Analysis of Spontaneous Aphasic Speech. Speech Commun. 2018, 100, 1–12. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).