1. Introduction
An emotion is a psycho-physiological experience resulting from a conscious or unconscious perception of a situation, object, or characteristic. It is often related to mood, temperament, and personality [
1]. Emotions are vital aspects of human existence and play an imperative role in our lives. The ability to understand emotions is crucial when it comes to human–computer interaction (HCI) and clinical settings. Currently, emotion recognition has attracted major attention due to its potential applications in a variety of fields. A wide range of application areas are developing very rapidly, such as virtual reality (VR), gaming, health care, marketing, e-learning, and recommendation systems [
2]. These application areas use emotion recognition to interact with humans at high levels.
Many studies have been previously conducted on emotion recognition. The input modes used in these studies can generally be divided into physiological and non-physiological signals. A non-physiological signal is composed of external signals such as gestures, facial expressions, verbal tones, etc. [
3]. Most modern HCI systems still lack emotional intelligence and the ability to utilize these signals. An individual’s consciousness can easily influence and control non-physiological signals, but physiological signals represent their emotional state more accurately and consistently [
4,
5]. There are several types of physiological signals, such as electroencephalograms (EEGs), electrooculography (EOGs), electromyography (EMGs), etc. Among the types of physiological signals, EEG signals originate from the cortex of the brain, the region believed to be largely responsible for individual thoughts, emotions, and behaviors. EEG measures electrical activity in the brain using small metal electrodes attached to the scalp [
6]. With recent advances in battery technology, EEG has become a more portable, reliable, and relatively inexpensive method of monitoring brain activity compared to other methods [
7].
Although EEG offers many advantages in recognizing emotions, it still has some limitations. EEG has a very low spatial resolution in comparison to its temporal resolution. Furthermore, EEG signals suffer from poor signal-to-noise ratios (SNR) [
8]. Besides these limitations, EEG signals also have poor homogeneity and generalizability across participants, which has hampered cross-subject emotion recognition studies [
9]. Consequently, most of the studies are aimed at developing subject-dependent systems rather than subject-independent systems. Various approaches have also been studied to overcome the limitations, which generally divide the entire emotion recognition pipeline into three stages: signal preprocessing, feature extraction, and classification.
Today, several datasets for emotion recognition using EEG signals are available, of which the most well-known are DEAP (A dataset for emotion analysis using EEG, physiological, and video signals) [
10], DREAMER (A Database for Emotion Recognition through EEG and ECG Signals from Wireless Low-cost Off-the-Shelf Devices) [
7], SEED (SJTU Emotion EEG Dataset with three emotion classes) [
11], and SEED-IV (SJTU Emotion EEG Dataset (SEED) with four emotion classes) [
11]. The SEED and SEED-IV datasets were used here as there are extensive studies on them that provide ground for comparison. Moreover, to the best of our knowledge, this is the first time that spatio-temporal features have been used in SEED and SEED-IV.
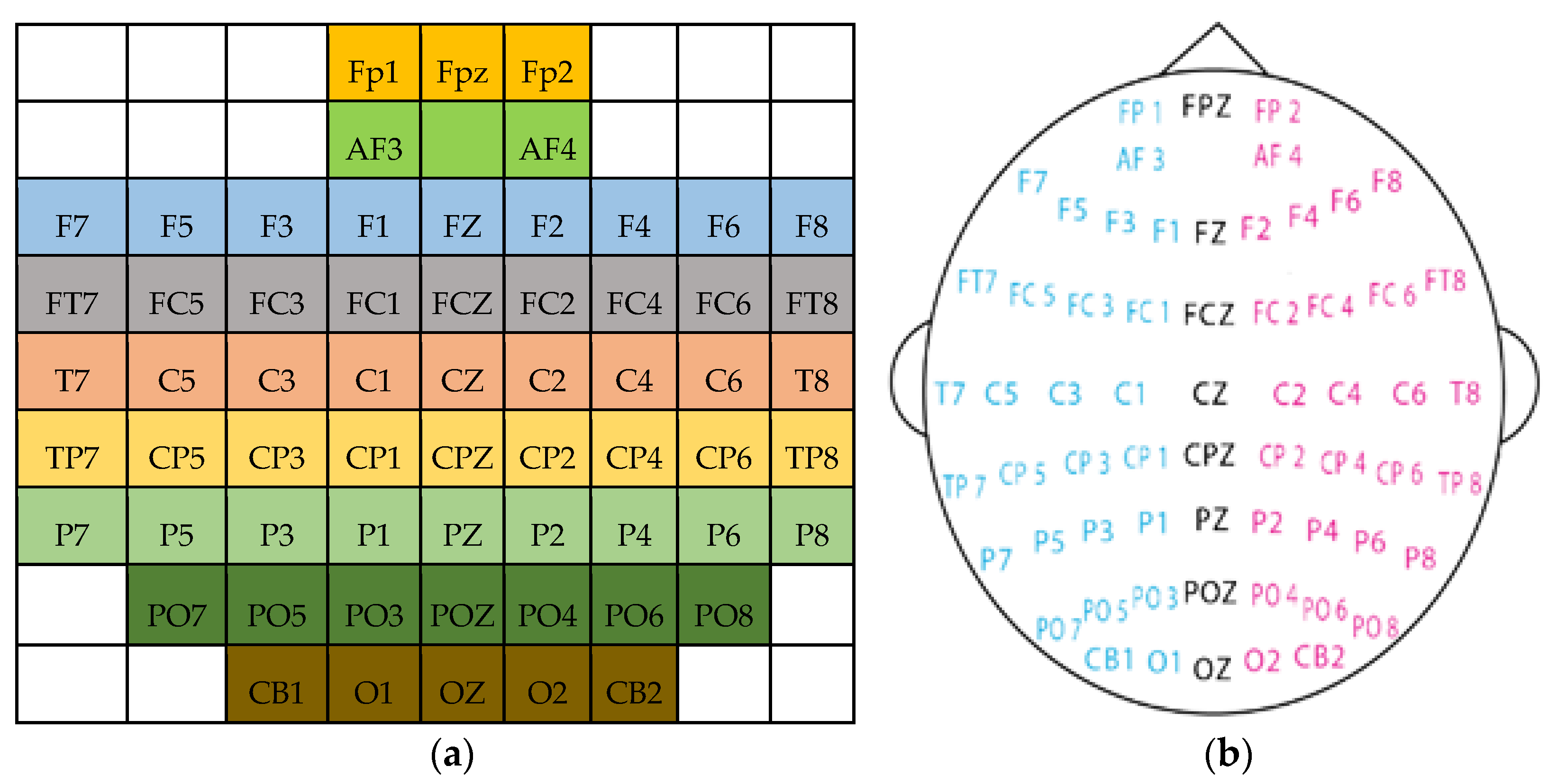
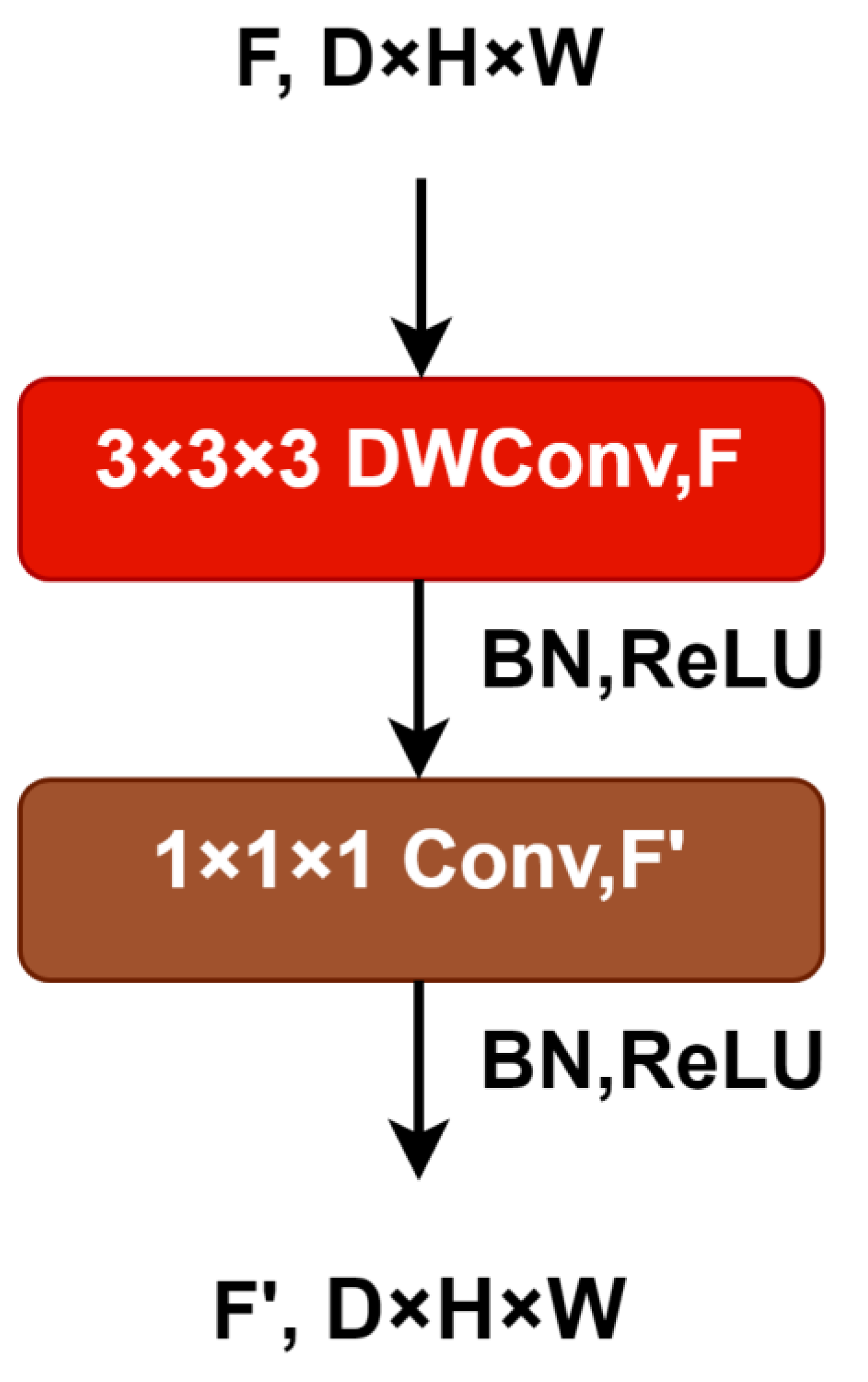
This paper aims to investigate subject-dependent emotion recognition using the SEED and SEED-IV datasets. Spatial-temporal representations of EEG signals were used as the input modality on which a pre-trained 3D-CNN model coupled with transfer learning was used for feature extraction. To preserve the spatial and temporal information in the EEG signals, the signals were preprocessed and given a 3D block representation based on electrode arrangements.
The main contributions of this work are as follows:
A 3D-CNN model pre-trained using transfer learning was used to extract features from spatio-temporal 3D representations of EEG signals. The study used spatial information from 62 electrodes to create input modality. Using 3D-CNN and transfer learning with post-filtering, this is the first time that emotion classification has been performed on the SEED datasets based on spatiotemporal features.
Apart from the traditional fully connected layers (used for classifying after feature extraction from CNN), other major classifiers, including k-nearest neighbor (KNN), extreme learning machine (ELM), XGBoost, and random forest in hybrid models, were also used. Furthermore, the post-filtering of output labels was studied.
A comprehensive set of results is presented to demonstrate the accuracy and efficiency of the proposed approaches on the SEED and SEED-IV datasets. Both the individual subject’s accuracy and the average subject’s accuracy across subjects are reported. The reporting of each subject’s accuracy enhances transparency and provides a baseline against which other researchers can compare their work. The computation time to evaluate EEG signals is also reported to demonstrate the efficiency of the proposed methodologies.
2. Related Works
The use of deep neural networks (DNNs) for emotion recognition has received considerable attention and has achieved notable success in recent years. This section reviews previous literature on emotion identification using EEG signals based on DNNs. Using statistical features (mean, median, mode, and range) with shallow classifiers [
12], 75% accuracy was achieved on the DEAP dataset using Naive Bayes, KNN, decision trees, and SVM. Qing et al. [
13] achieved 74.87% accuracy on the SEED dataset and 62.63% on the DEAP dataset using an ensemble model (EM) consisting of shallow classifiers, including k-nearest neighbor (KNN), decision tree (DT), and random forest (RF), with a soft-voting strategy. Chen et al. [
14] proved that the DNN-based approaches outperformed shallow classifiers in terms of performance in recognizing emotions. Tarán et al. [
15] proposed using a combination of sample entropy (SampEn), Tsallis entropy (TE), Higuchi fractal dimension (HFD), and Hurst exponent (HE) with a multiclass least squares support vector machine (SVM) model for their analysis. They employed empirical mode decomposition (EMD)/intrinsic mode function (IMF) filters to clean the data, along with variational mode decomposition (VMD) filters to ensure data integrity. They achieved an accuracy of 90.63% on their dataset for four emotion classifications (happiness, sadness, fear, and neutral). Using the CNN-SAE (sparse autoencoder)-DNN model in combination with the Pearson correlation coefficient (PCC) between different channels as a feature, Liu et al. [
16] achieved 96.77% accuracy on the SEED dataset, which is considered to be state-of-the-art.
To make use of the spatial information contained in EEG signals, several graph-based techniques that use the signals’ spatial information were studied. Using differential entropy (DE), power spectral density (PSD), differential asymmetric feature (DASM), rational asymmetric feature (RASM), and differential causality (DCAU), Song et al. [
17] proposed a dynamic graph convolution network (DGCNN) model with handcrafted features (DE, PSD, DASM, and DCAU) to classify emotions. They achieved an accuracy of 90.4% (three emotions) on the SEED dataset. In a subsequent study by Zhang et al. [
18], the same features used by Song et al. for a graph convolutional broad network model were applied, and the model’s accuracy increased to 94.24% on the SEED dataset. Zhong et al. [
19] adopted regularized graph neural networks (RGNN) as a means of computing pre-computed differential entropy features of the SEED and SEED-IV datasets and achieved a state-of-the-art performance of 79.34% for the SEED-IV dataset.
Convolutional neural networks (CNNs) are neural networks with one or more convolutional layers. They are generally used for image processing, classification, segmentation, and other autocorrelated data processing [
20]. As a result of their computational efficiency, CNNs are highly effective at detecting and learning important features without any intervention from humans. CNNs can be classified based on their convolutional kernel dimension. 2D CNNs use 2D convolutional kernels and utilize context across the height and width of 2D frames (spatial features) to make predictions. However, they are inherently incapable of leveraging information from adjacent frames. Three-dimensional CNNs solve this problem, as they are the 3D equivalent of two-dimensional CNNs [
21].
In recent years, 3D-CNN has achieved a considerable amount of success when it comes to processing spatio-temporal information such as action recognition [
1,
7,
22]. This capability was also used in several studies to recognize emotions using 3D-CNN. 3D convolutional kernels are capable of handling the voxel information from adjacent frames, making them powerful models for learning representations of volumetric data, such as videos and 3D medical images (MRI, CT scan) [
23]. 3D-CNN has been used in several studies to effectively extract features from videos. Therefore, the current study used 3D-CNNs to extract features from the 3D spatio-temporal representation of EEG data [
6,
24,
25]. Salama et al. [
24] used a 3D-CNN model to classify emotions, and a 3D representation of the data was created for the inputs of the model. They achieved an accuracy of 87.44% for arousal (two classes) and 88.49% for valence (two classes) on the DEAP dataset. A study by Cho et al. [
6] used two different end-to-end 3D-CNN architectures, C3D and R(2) + 1D, to extract features in their study. They achieved an accuracy of 99.73% (4 classes) on the DEAP dataset. The authors proposed the use of a novel method to represent EEG signals in a 3D spatio-temporal block by setting the position of the channels at the sampling time at their original positions, after which the interpolation of 2D EEG frames was used to reconstruct the 3D signals. A transfer learning method was used by Cimtay et al. [
26] to recognize emotions based on a pre-trained Inception-Resnet-V2 model. They achieved a cross-subject accuracy of 86.56% for two classes (positive-negative) and 78.34% for three classes (positive-neutral-negative) on the SEED dataset. In [
25], EEG data were extracted from three international open-source datasets, such as DREAMER, SEED, and DEAP, to classify emotions using 3D-CNN. The maximum mean classification rate was 97.64% using SEED datasets.
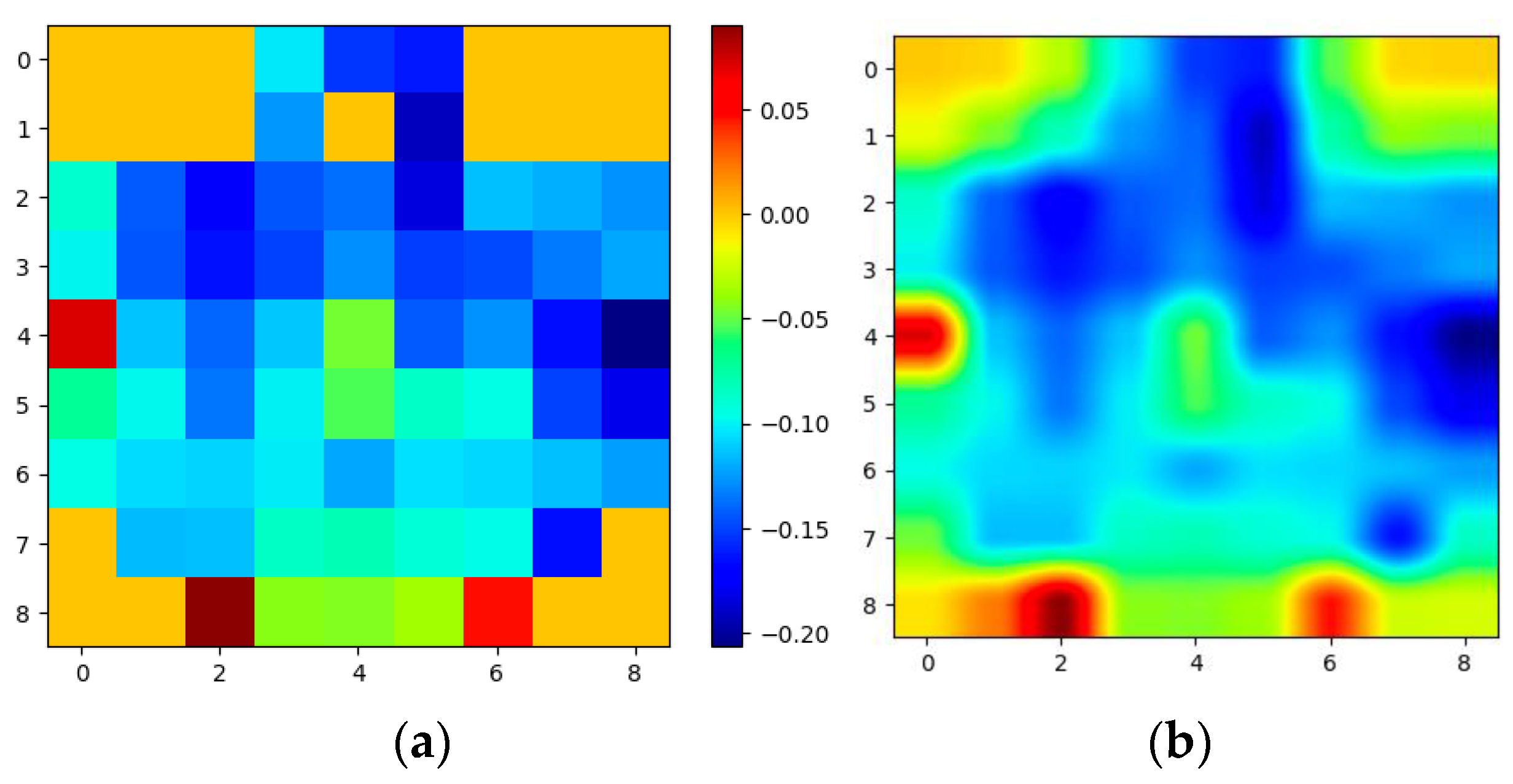
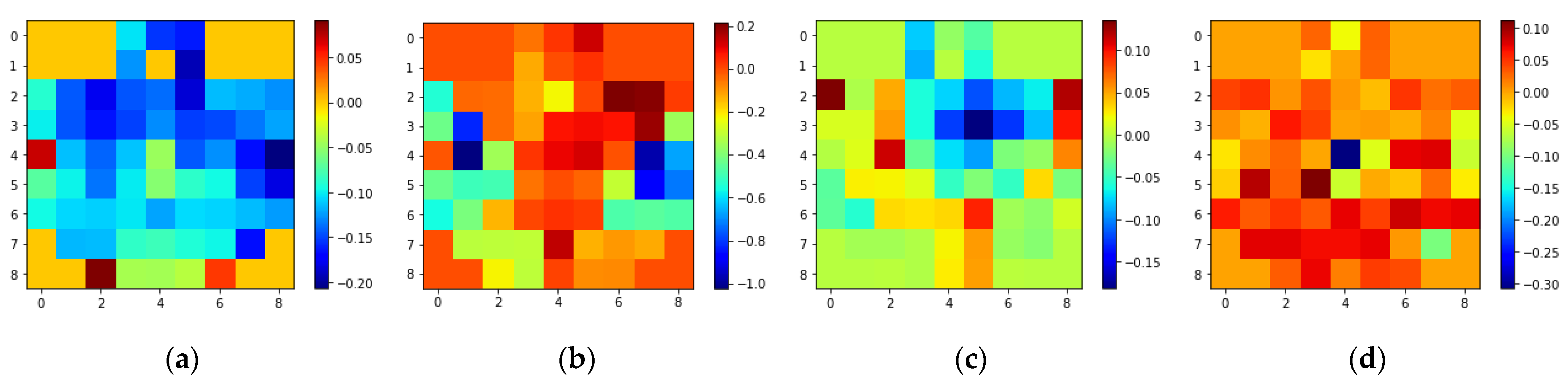
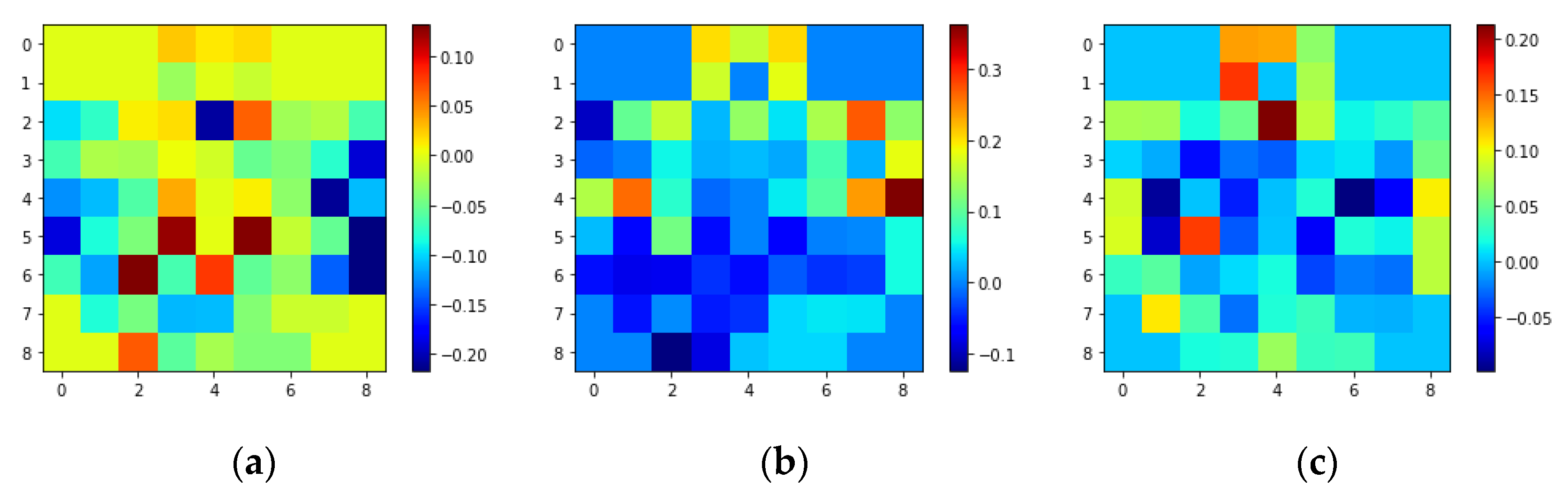
Most earlier studies did not use the spatial information between the adjacent electrodes, which, according to some studies, is an important aspect of the input. Unlike most studies that have handcrafted features using different techniques like Pearson correlation coefficient (PCC), Principal Component Analysis (PCA), Higuchi Fractal Dimension (HFD), entropy studies, etc., for the input of the DNN, the current study created a simple 3D representation using the raw EEG signals, which preserves both the spatial and temporal information of the data. Additionally, this study completely relied on DNN’s ability to extract meaningful features that could be fed into the classifier for the classification of emotions. Furthermore, this work used a pre-trained 3D-CNN model with transfer learning as the DNN model in the study. Earlier studies on SEED datasets that used 3D CNNs did not take spatial information into account, alongside the transfer learning approach, in emotion recognition. Some studies have used graph-based neural networks that use spatial information. The novelty of this paper is the use of 3D CNNs with spatio-temporal features to recognize emotion on SEED datasets. In the study, the spatial information from 62 electrodes was used to create input modality. As far as we know, this is the first time that transfer learning has been used on SEED datasets to classify emotions using spatio-temporal features with 3D-CNN and an ensemble classifier.
6. Conclusions
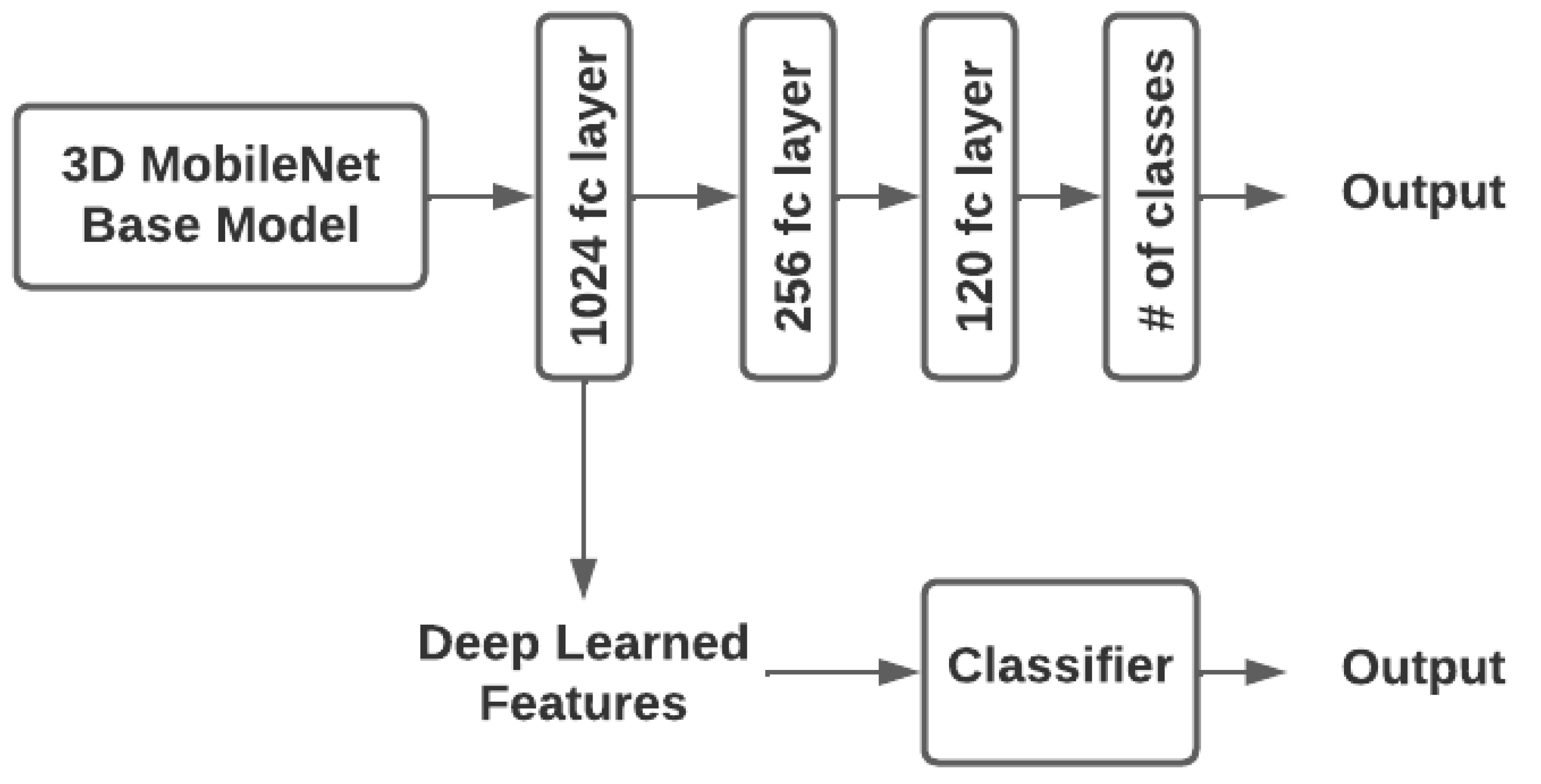
This study adopted the success of 3D-CNNs in video analysis, owing to their capacity to extract and learn temporal features in addition to spatial features. Using 3D-CNN, the EEG signals are represented in 3D spatio-temporal space by first converting the 1D raw EEG streams into 2D spatial streams and then stacking the 2D spatial streams into 3D EEG block streams. A 3D MobileNet network with transfer learning was used to extract and learn features from 3D EEG blocks. Additional pools and dense layers were added to the CNN network to enhance classification capabilities. In the SEED-IV dataset, four classes of samples were classified: happiness, sadness, fear, and neutral, with an accuracy of 78.32%. The SEED dataset showed an accuracy of 88.58% for classifying the samples into three groups: positive, neutral, and negative.
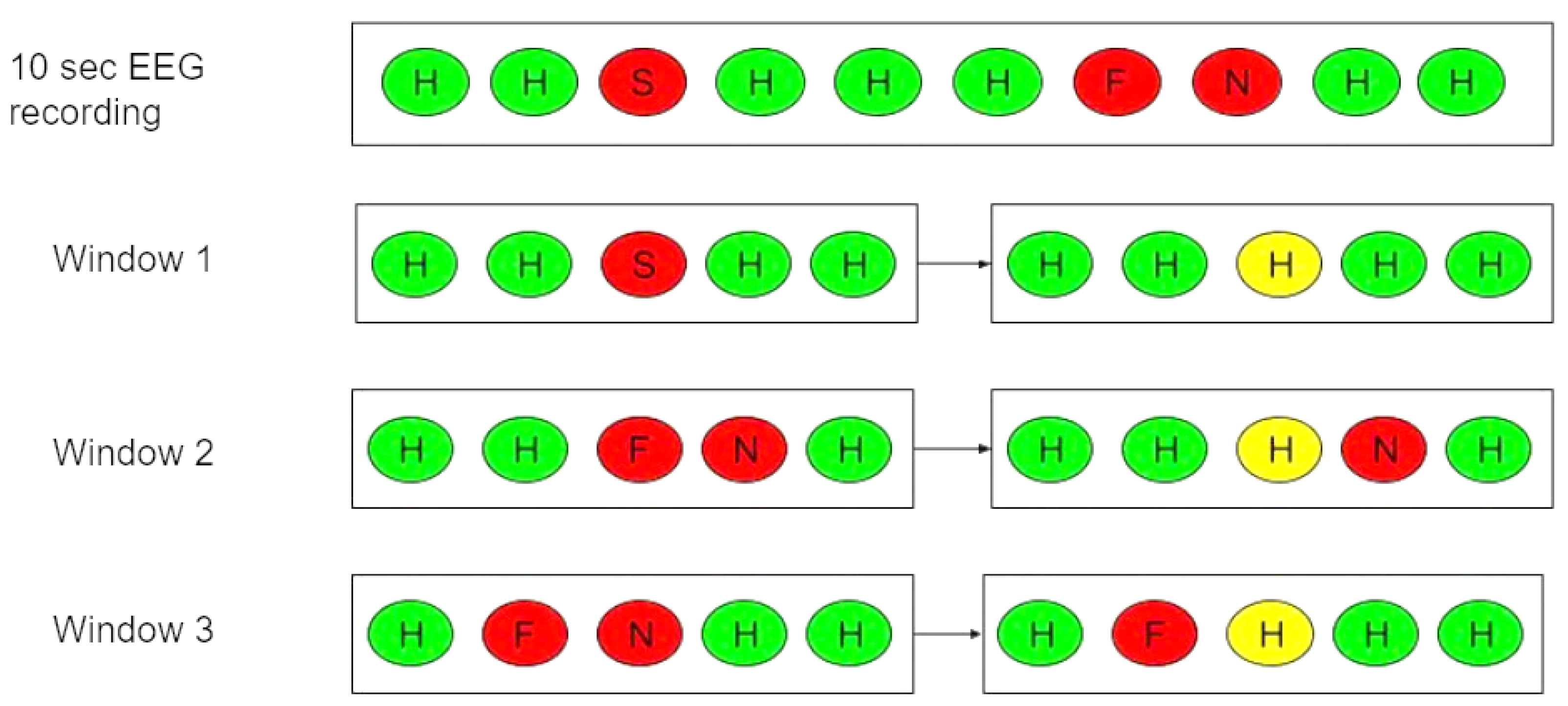
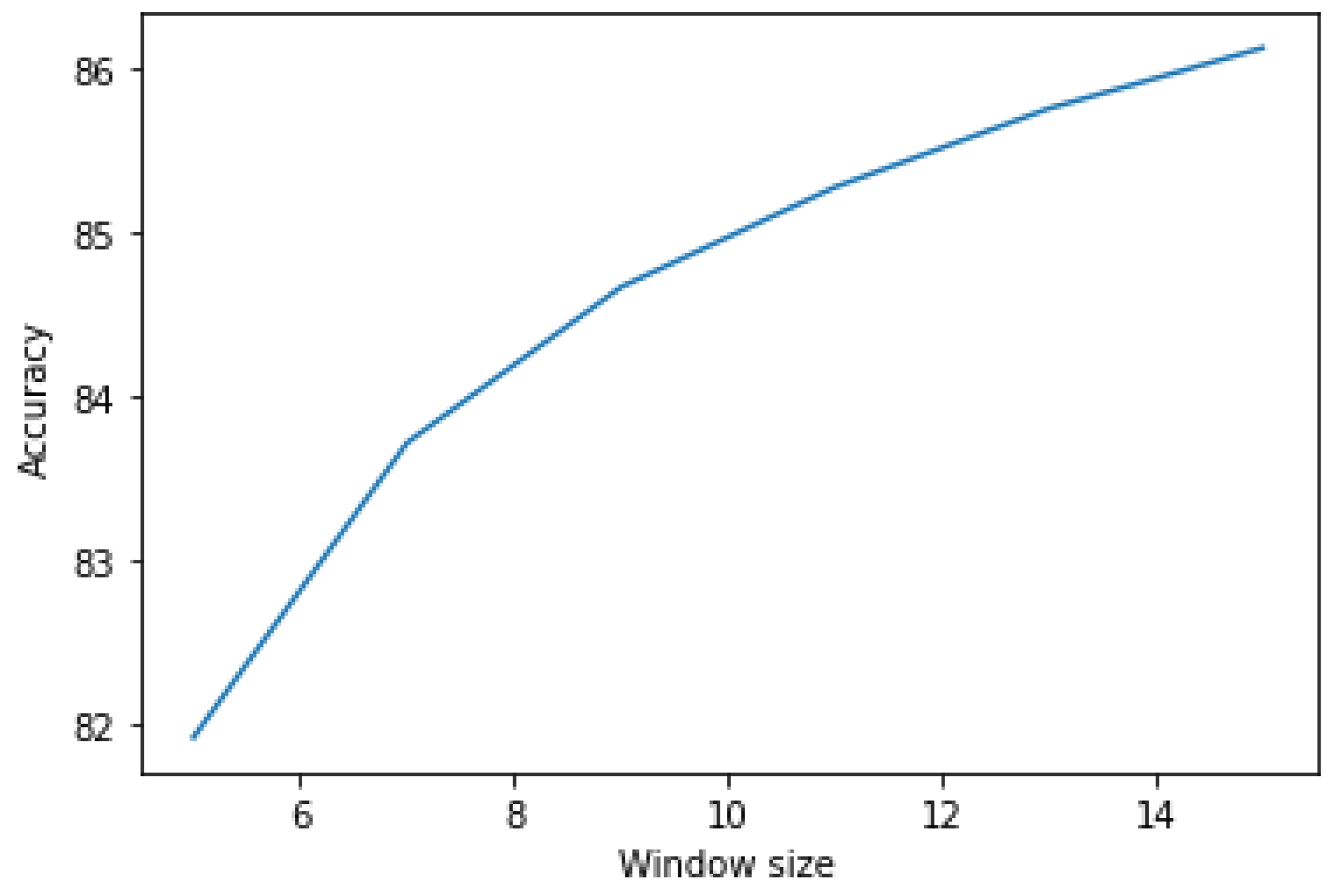
Additionally, the performance of hybrid models that were fed the extracted features from the 3D-CNN network into different classifiers (XG boost, random forest, support vector machine, k-nearest neighbor, and extreme learning machine), in addition to the MLP classifier (dense layers and pool layers), was examined. Compared to SEED-IV and SEED, 3D-CNN-ELM hybrid models delivered significant improvements in performance with an accuracy of 81.60% and 89.18%, respectively. The emotions of a healthy person vary very little, so it could be assumed that emotions will remain constant for a short period. These studies were used to investigate the model’s performance when post-filtering the output labels with mode filters. A time window ranging from 5 to 15 s was selected. The accuracy of the model increased as the time window of the mode filter increased. A CNN-ELM hybrid model that applied post-filtering to a 15-s window achieved an accuracy of 87.50%. The proposed model could be used for emotion recognition in HCI-related fields, healthcare, etc.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}