1. Introduction
When perceiving speech, listeners not only extract the linguistic message but also information about the talker’s identity. Typically, listeners can learn to recognize the voice of unfamiliar talkers very soon after being introduced to that talker [
1]. However, individuals with hearing loss and/or cochlear implant(s) often have difficulty recognizing voices [
2,
3,
4]. Although feedback training has been shown to help train those with good hearing in learning to recognize voices [
1,
5], this training technique has not been as effective for those with hearing impairments or implants [
6]. For example, Cleary and Pisoni [
6] found that cochlear implant users had greater difficulty discriminating talkers during test trials compared to normal-hearing individuals after completing a short set of practice trials. The question then arises of whether effective training methods can be designed to help with voice recognition. The goal of the following project was to examine the utility of a multisensory method for learning talker’s voices.
Voice recognition is usually thought to be accomplished by listening for a talker’s specific vocal qualities, such as the fundamental frequency of phonation and breathiness [
7,
8,
9]. However, other recent research has shown that talkers can also be identified through their articulatory style or idiolect—the idiosyncratic way that a talker articulates segments and syllables [
9,
10,
11]. As shown by Remez and colleagues [
11], talkers can still be identified even when speech signals do not contain fundamental frequency or timbral properties (e.g., breathiness). Talkers can be recognized from sinewave speech composed of nothing more than three simple sinewaves that track center formant frequencies of a speech utterance. Remez and his colleagues argue that while sinewave speech does not contain the acoustic properties typically thought to support talker identification, the signals do contain talker-specific articulatory information that can also identify a talker. Interestingly, this talker-specific articulatory information is also available in the visual speech modality (for lipreading). In fact, talkers can be recognized from isolated visual speech alone [
12]. As shown by Rosenblum and colleagues [
12], familiar talkers were recognized at better than chance levels from isolated visible articulatory information (using a point-light method). Research suggests that there is also common talker-specific articulatory information available
across auditory and visual modalities [
11,
13]. For instance, Lachs and Pisoni [
13] found evidence for cross-modal talker matching using sinewave and point-light talker stimuli to isolate the articulatory information in both modalities.
Finally, a recent study [
14] examined whether learning talkers from their articulatory style in one modality could facilitate learning the same talkers in the other modality. Simmons and colleagues [
14] observed that learning to recognize talkers from the isolated visible articulatory information of point-light speech facilitated learning of those same talkers from the auditory articulatory information of sinewave speech. The authors interpreted their results as showing that perceivers can learn to use ‘amodal’ talker-specific articulatory information that is available across—and can be shared between—the modalities for talker learning.
Based on these findings, the question arises whether adding visual speech to the auditory signal can facilitate the learning of new voices from auditory-alone information. It is well known that adding visual information facilitates the intelligibility of speech [
15,
16,
17]. There are a small number of studies showing that voice learning can also be facilitated in this manner, e.g., [
5,
18]; see also [
19]. von Kriegstein and colleagues [
18] examined this question by performing behavioral and neuroimaging experiments with prosopagnosics and matched controls. Participants either both heard and saw three talkers (voice-face condition) uttering sentences or just heard sentences while being presented with static symbols of different occupations (voice-occupation condition). Participants were later tested on their ability to match the name to the voices, which included both speech and nonspeech (vehicle) sounds. Results indicated that participants were more accurate in recognizing (auditory-only) voices for the talkers presented during the voice-face learning condition compared to those presented in the voice-occupation learning condition. However, this face benefit was not observed in the prosopagnosic patients. Interestingly, a positive correlation between fusiform face area (FFA) activity and face benefit in speaker recognition in the control group was found. This could mean that FFA activity during audio-only talker recognition (for talkers who were part of the voice-face learning condition) might have optimized voice recognition. It is important to note that the study of von Kriegstein et al. [
18] used (a) nonface test stimuli (vehicle sounds) that are different from the more common audio-alone control stimuli more typically used in the literature, and(b) the training phase only included a small set of talkers (three).
In a more recent study, von Kriegstein and her colleagues [
20] showed that prior audiovisual talker learning facilitates audio-alone voice recognition even when the auditory information is weaker (i.e., speech-in-noise). Their training method was similar to the one discussed above [
18]. The authors interpreted their findings as showing that learning to recognize a talker after seeing their face may recruit visual mechanisms, allowing a better recognition of audio-alone voices under challenging listening conditions.
In another study, Sheffert and Olson [
5] also attempted to determine whether multisensory speech training would facilitate voice learning. Because our own study is based on their design, details will now be provided on Sheffert and Olson’s [
5] method. The study consisted of three phases: familiarization, talker training, and test. During the familiarization phase, participants were presented with 10 talkers uttering words and were provided with their identity (e.g., “That was Tom”). Next, the talker training phase consisted of one of two conditions—audiovisual and auditory-only—in which participants were presented with a set of words spoken by the talkers and were asked to verbally name the talker who presented each word. After each trial, participants received feedback about whether they were correct and, if not, the name of the correct talker. The final phase tested if participants learned the talkers’ voices by presentations of just the voices alone (without accompanying faces). Participants were required to achieve an average of 75% correct voice recognition during this test phase, which was auditory-only, regardless of the training modality (audiovisual or audio-only). If participants failed to achieve an average of 75% correct voice recognition, they were asked to come back the next day to complete another training and test phase. For this reason, the experiment lasted over multiple days.
There are several noteworthy findings from the Sheffert and Olson [
5] study. First, results from the training sessions revealed an advantage for learning voices presented audiovisually vs. just auditorily. This is not surprising because, during training, the task in the audiovisual condition could be accomplished by face as well as voice recognition. More impressively, participants who were trained to see the talkers’ faces were significantly more accurate (especially during the first couple of days of training) at identifying the talkers’ voices during the audio-alone test phase compared to those trained with just auditory stimuli. These results are consistent with the findings of von Kriegstein and colleagues [
18,
20] and suggest that seeing a talker speaking can facilitate the learning of the talker information present in the auditory signal.
While there is evidence that the presence of a face can help perceivers better learn a voice, it is unclear which specific dimensions of facial information allow for this facilitation. Based on the earlier discussion, it could be that the amodal talker-specific information that supports face-voice matching also facilitates voice learning. However, the nonarticulatory information in a face might also help voice learning.
In fact, there is evidence of a perceivable connection between a person’s (static) facial appearance and voice. Mavica and Barenholtz [
21] found that the voices of unfamiliar talkers could be matched to
static images of their faces at better-than-chance levels. In addition to the matching task, participants were asked to rate the faces and voices on physical (e.g., weight, height, age, and attractiveness) and personality (e.g., extraversion, openness, and agreeableness). However, the authors found no obvious relationship between the matching task and these ratings. The authors concluded that participants might have used a set of properties—available in both faces and voices—containing amodal information that helped them group the facial and vocal characteristics.
Related research has shown that correlations exist between individuals’ facial and vocal attractiveness [
22] when participants were asked to make independent judgments of static images and voices [
23]. These findings show that it is possible that cross-modal attractive information is used to match static images of faces to their voices. Other characteristics such as height, age [
24,
25,
26], and personality traits (e.g., extroversion) [
27,
28,
29] can be inferred from static images and/or recordings of voices as well.
Research has been conducted to examine the relevance of dynamic facial information in matching faces to voices. In a study conducted by Huestegge [
30], participants were asked to match a voice to either two static or two dynamic faces. Results showed that the performance between the static and dynamic face-voice matching was similar. This may suggest that the information used by participants to match faces to voices is available in the static faces, thereby indicating that the dynamic information may not offer further advantages.
While dynamic facial information may not always provide additional benefits over static face information in the context of a matching task, it has been shown to play a role in the recognition of familiar voices. In a study carried out by Schweinberger and his colleagues [
31,
32], participants were simultaneously presented with a face (dynamic or static) along with either corresponding or noncorresponding voices (both familiar and unfamiliar). Participants were asked to judge the familiarity of the
voice. Results showed that recognizing the voices of familiar talkers was better when the voices were paired with their correct corresponding faces. This improvement was stronger with the (corresponding) dynamic than static faces (with either dynamic or static faces; also see [
33,
34]). Importantly, this improvement was larger for faces presented in a time-synchronized- vs. unsynchronized manner, suggesting that synchronization of dynamic information may play a role in identifying familiar speakers.
However, a recent study has shown that unfamiliar voices (compared to novel voices) were recognized better (i.e., categorized as new) on their own after being paired with static faces [
35]. In that study, EEG recordings during both the learning and voice recognition phases also revealed an early interaction between voice and face processing areas. Thus, there is evidence that static faces can be matched to voices and that, in some contexts, static faces can facilitate the identification of voices as unfamiliar. However, it is unclear if static face information alone might help facilitate the
learning of novel voices without the presence of visible articulation. This question will be tested in the following study.
It should also be mentioned that while a number of studies have shown face facilitation of voice recognition, some studies have reported that the presence of faces can
inhibit voice recognition [
1,
36]. In what is known as the ‘facial overshadowing effect’, e.g., [
1,
36,
37], the presentation of the face has been thought to direct attention away from the voice, thereby impairing performance during voice-only recognition [
1,
36,
37,
38]. In fact, this inhibitory effect has been shown to be stronger with the presence of direct eye gaze in the face, which may be linked to capturing more attention [
39]. Although it is true that in the present study, both the articulating and static face training conditions included a direct gaze of the speakers, it is important to note that the training included other characteristics that may have outweighed the effect. For example, in the present study, participants were presented with audio-alone probe trials during training to ensure they were learning the voices. Additionally, during the test phase, participants were asked to identify the talkers (compared to categorizing voices as old/new).
However, it is important to note that the procedures involved in studies showing the ‘facial overshadowing effect’ focused on voice
recall and not voice identification. Participants in these studies, i.e., [
1,
36,
37,
38], were asked to study a set of talkers’ voices and were then tested on whether they could recall hearing a particular voice. The findings of these studies run contrary to those that focused on voice
identification—learning to identify particular talkers based on vocal characteristics—discussed earlier [
5,
18], which showed an advantage of the presence of the talkers’ faces during training. The current study will examine this latter scenario.
Purpose of the Current Study
The purpose of the current study was to examine the effect of multisensory training in facilitating voice identity learning. We were interested in examining the role of visible articulatory information and static face information in learning to recognize audio-only voices. Our method involved training participants using audio-only or audiovisual stimuli and had all participants tested on (audio-only) voice learning. Thus, in the current experiment, we attempted to confirm the findings of Sheffert and Olson [
5] using a modified procedure and test the benefit of visible articulatory information more directly. For this reason, we added two new conditions to the Sheffert and Olson [
5] paradigm for training voice recognition in which we (a) presented static images of the speakers along with their audio files and (b) isolated the mouth area of the speakers as they were articulating sentences. It should be mentioned that Sheffert and Olson [
5] conducted an informal follow-up control experiment to evaluate the importance of mouth movements during their audiovisual training sessions. Using a small group of participants, they presented their training audiovisual stimuli with the talkers’ mouths occluded (including the lower cheeks, the jaw, and the nose) on the presentation screen. Results showed that these reduced face stimuli failed to facilitate voice learning over audio-only training conditions. Based on this result, Sheffert and Olson [
5] concluded that the advantage of audiovisual training observed in their main experiment was likely due to the presence of visible articulatory information rather than nonarticulatory facial identity information.
While the data from this informal follow-up experiment are useful, the conclusions must be considered preliminary. It could be, for example, that occluding the mouth in this manner removes not only articulatory information but also nonarticulatory (e.g., mouth and chin features) information that may, in principle, be useful for voice learning. For these reasons, we decided to more directly test the possible facilitative utility of both static facial and articulatory information for voice learning by including both static face and isolated (moving) mouth visual stimuli in our tests. Four hypotheses were made based on the assumption that the multisensory voice learning facilitation observed in the prior research was based on the availability of visible articulatory information. First, if participants can use visible talker-specific articulatory information to facilitate voice learning, then participants in the (full-face) articulating face condition would significantly outperform those in the audio-only condition when identifying the voices during the (audio-only) test phase. Second, if the visible articulatory information is sufficient to facilitate voice learning, then those trained with isolated mouth stimuli should also outperform those with audio-only training in the test phase. Third, performance after training with both articulating face and mouth-only stimuli should be better than that after training with static face stimuli. Finally, if visible articulatory information provides the necessary information for multisensory facilitation of voice learning, then performance in the static face condition should be no better than that in the audio-only condition.
3. Results
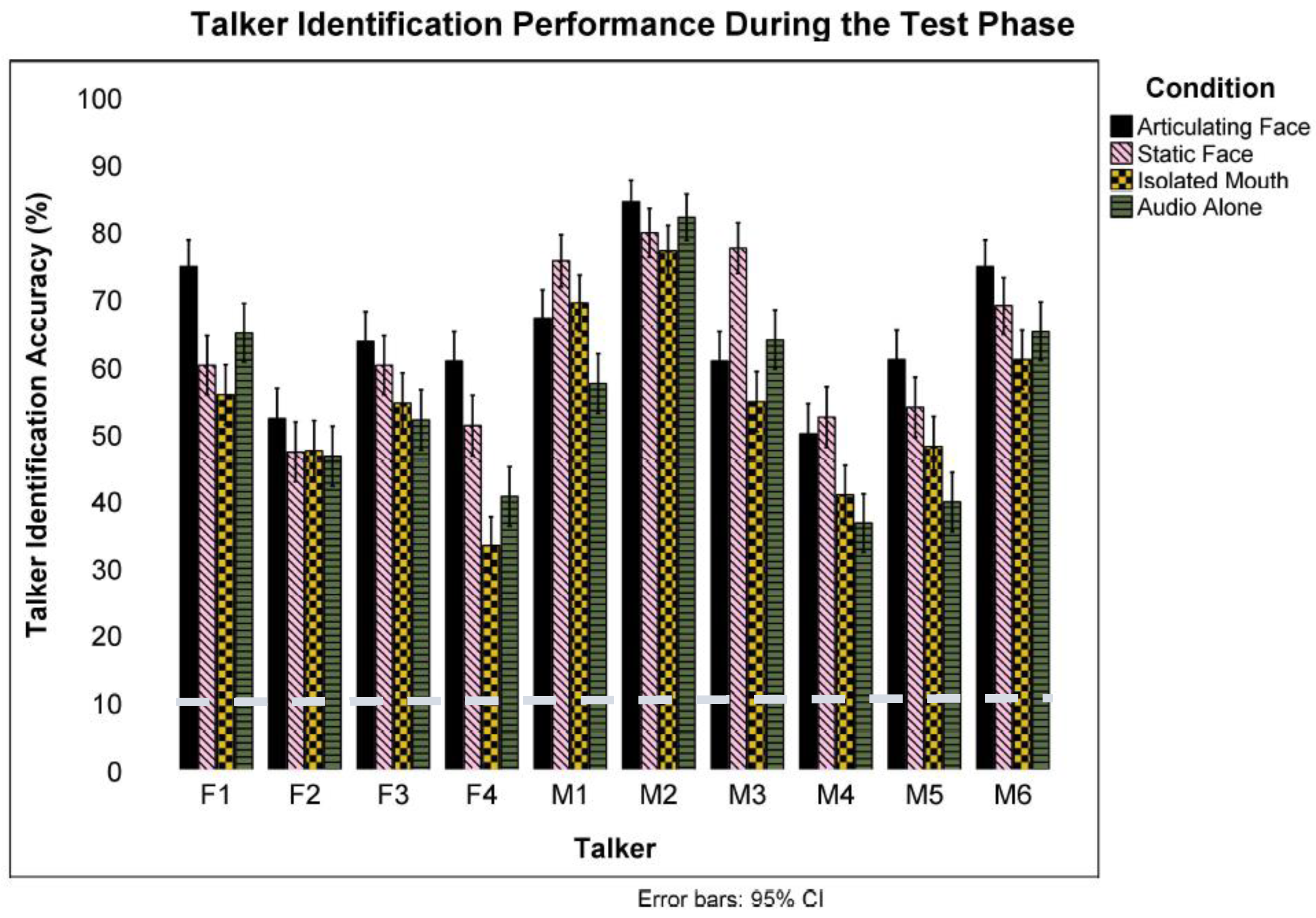
3.1. Test Phase
To examine the effect of the various training methods in facilitating voice learning (audio-only), we first performed a one-sample
t-test to test against chance performance (10%) and then analyzed the data using mixed-effect logistic regressions and analysis of variance (ANOVA; significance was set at
p < 0.05). A one-sample
t-test revealed a significant result indicating that participants in the
articulating face condition identified talkers at a better than chance (10%) level (
M = 0.65,
S = 0.19),
t(23) = 14.20,
p < 0.001,
Cohen’s d = 2.90. Talker identification rate varied significantly across talkers,
F(9) = 24.72,
p < 0.001,
np2 = 0.04 (see
Figure 2). All talkers were identified at above chance levels at a Bonferroni-corrected
α = 0.005. Another one-sample
t-test revealed a significant result indicating that participants in the
isolated mouth condition identified talkers at a better than chance (10%) level (
M = 0.54,
S = 0.15),
t(23) = 14.61,
p < 0.001,
Cohen’s d = 2.99. Talker identification rate again varied significantly across talkers,
F(9) = 34.23,
p < 0.001,
np2 = 0.06 (see
Figure 2). Yet, talkers were identified at above chance levels at a Bonferroni-corrected
α = 0.005.
Next, another one-sample
t-test showed that those in the
static face condition identified talkers at better than chance levels (
M = 0.63,
S = 0.19),
t(23) = 13.34,
p < 0.001,
Cohen’s d = 2.72. The Bonferroni-corrected (
α = 0.005) analyses revealed that talker identification varied significantly across talkers,
F(9) = 6.31,
p < 0.001,
np2 = 0.01. A final set of one-sample
t-tests revealed that participants in the
audio-only condition identified talkers at a better than chance level (
M = 0.55,
S = 0.13),
t(23) = 16.74,
p < 0.001,
Cohen’s d = 3.41. Talker identification rate varied significantly across talkers,
F(9) = 43.65,
p < 0.001,
np2 = 0.08 (see
Figure 2). The post hoc
t-test analyses revealed that all talkers were identified at a better than chance level at a Bonferroni-corrected
α = 0.005.
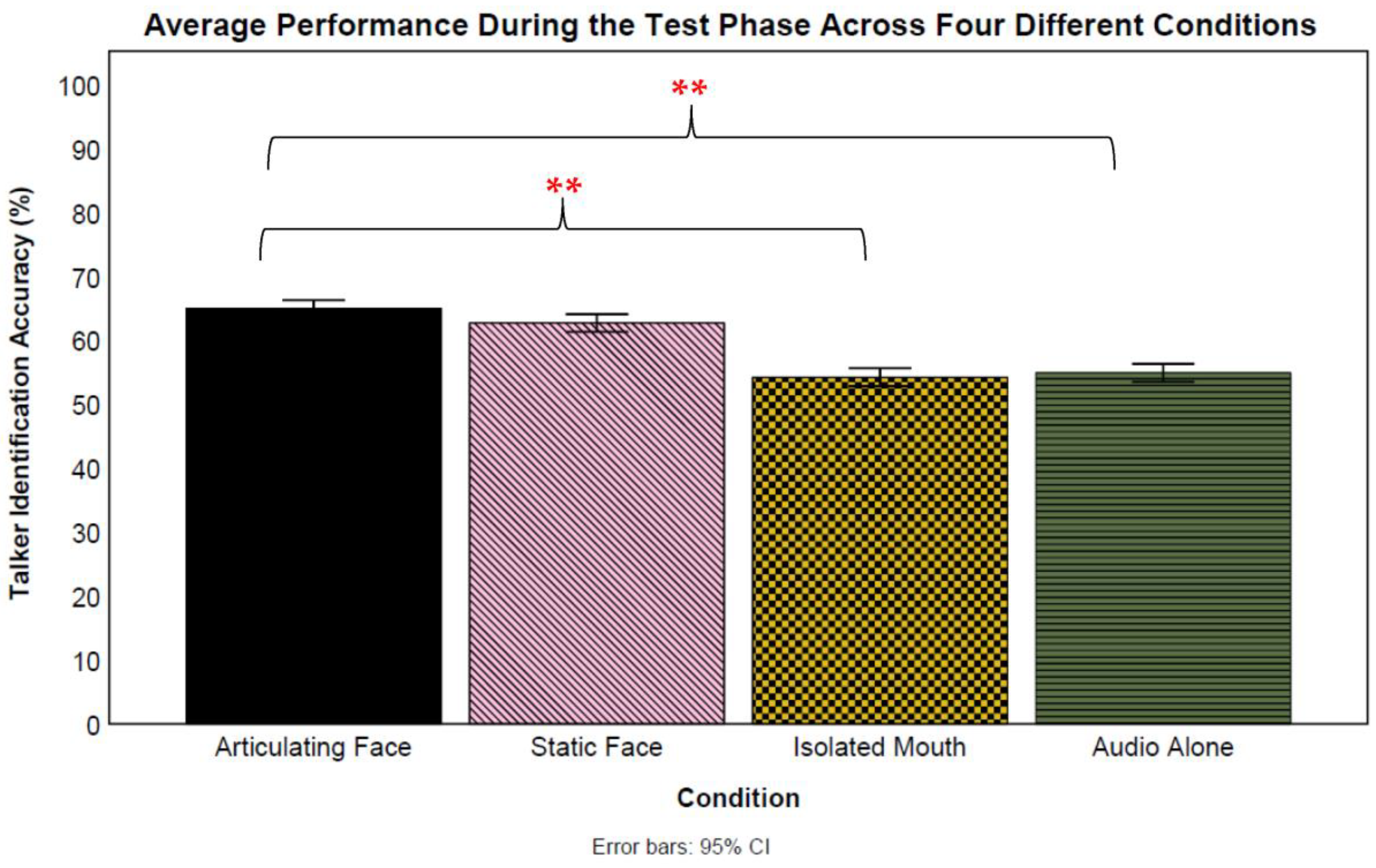
A set of logistic mixed-effect models was used to compare the test means between the four conditions (see
Figure 3). All of the reported analyses treated the condition as a fixed effect and participants and talkers as random effects. The first analysis revealed a significant difference between the articulating face and audio-only conditions (
β = 0.57,
SE = 0.24,
z = 2.36,
p = 0.018, CI: 0.09–1.04) favoring the
articulating face condition (65% vs. 55%, respectively). Next, no significant difference was found between the isolated mouth and audio-only conditions (
β = −0.02,
SE = 0.24,
z = −0.08,
p = 0.936, CI: −0.50–0.46) (54% vs. 55%, respectively). There was no significant difference between the test means of the static face and audio-only conditions (
β = 0.43,
SE = 0.24,
z = 1.78,
p = 0.076, CI: −0.05–0.90).
A significant difference was found between the test means of the isolated mouth and articulating face conditions (β = −0.59, SE = 0.24, z = −2.44, p = 0.015, CI: −1.06–−0.11) favoring the articulating face condition (53% vs. 65%, respectively). However, no significant difference was found between the static face and articulating face conditions (β = −0.14, SE = 0.24, z = −0.59, p = 0.558, CI: −0.62- 0.34) (63% vs. 65%, respectively). Moreover, there was no significant difference between the isolated mouth and static face conditions (β = 0.45, SE = 0.24, z = 1.85, p = 0.064, CI: −0.03–0.92). Additionally, there was a variability in both the talkers (var = 0.31, S = 0.56) and participants (var = 0.67, S = 0.82). A final Analysis of variance revealed a significant interaction between the talkers and conditions F(27) = 6.65, p < 0.001, np2 = 0.01.
3.2. Training Phase: Probe Trials
In addition to the test trials, we also were able to examine how fast participants in different conditions were learning to recognize the voices in the training phase. As mentioned previously, probe trials were audio-only trials included during the training phase of the four conditions. These trials were originally designed to draw the attention of participants in the audiovisual training conditions (articulating face, isolated mouth, and static face) to learn the voices and not simply the faces. However, these trials could also be used to track how quickly participants learned the voices based on the training condition in which they participated. We analyzed the probe data by performing a set of post hoc mixed-effect logistic regression analyses examining the difference in the overall mean performance. In order to examine the learning rate, we also performed post hoc slope analyses comparing the conditions.
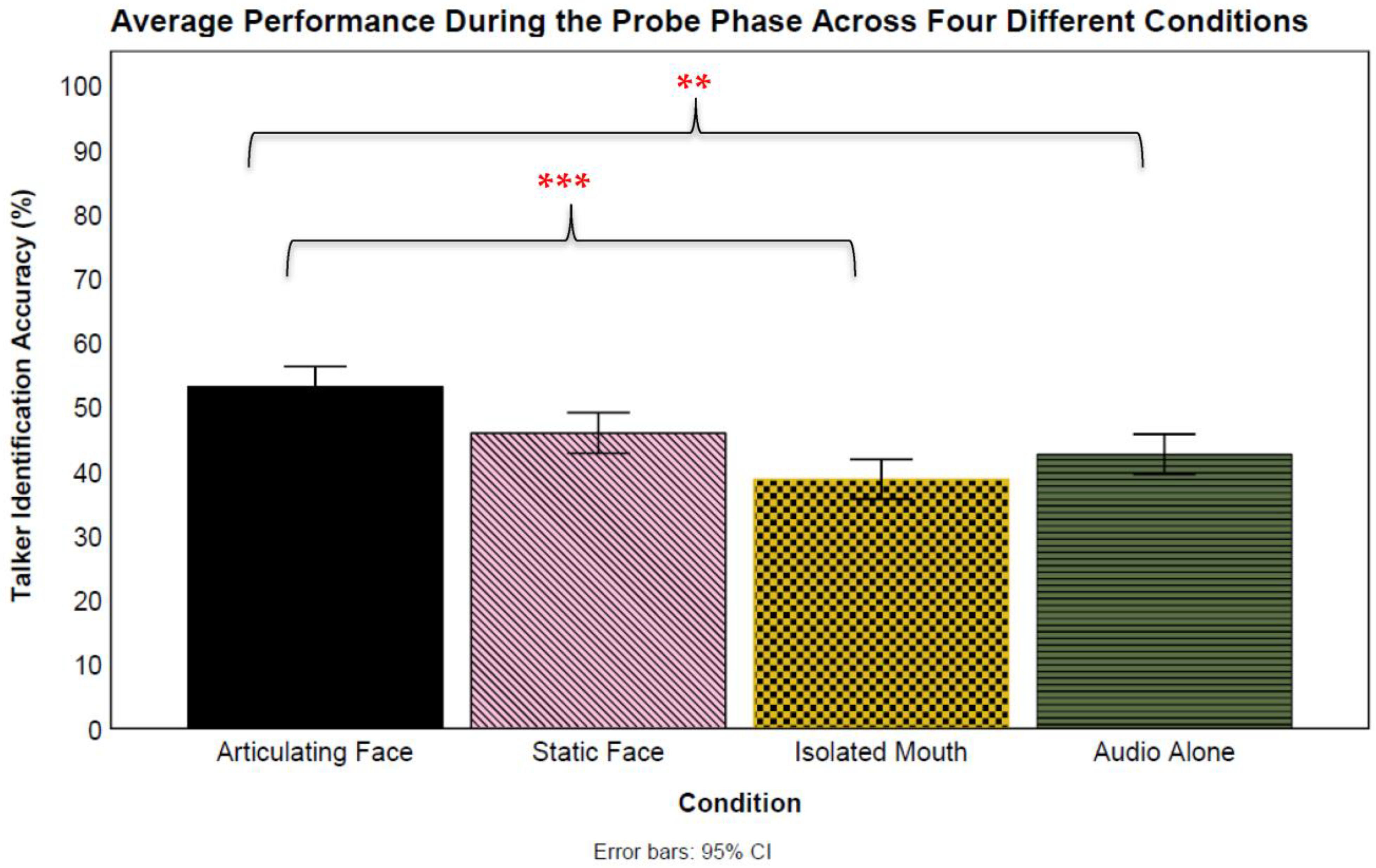
A post hoc mixed-effect logistic regression model compared the overall magnitude of the audio-alone probe trials across conditions (see
Figure 4). In the analysis, conditions were added as a fixed effect, and participants and talkers as random effects. Results showed a significant difference between the articulating face and audio-only conditions (
β = 0.46,
SE = 0.16,
z = 2.84,
p = 0.005, CI: 0.14–0.78) favoring the
articulating face condition (53% vs. 43%, respectively). Next, a significant difference was not observed between the isolated mouth and audio-only conditions (
β = −0.17,
SE = 0.16,
z = −1.04,
p = 0.297, CI: −0.49–0.15; 39% vs. 43%, respectively). Similarly, no significant differences were found for the static face and audio-only conditions (
β = 0.05,
SE = 0.41,
z = 0.13,
p = 0.894, CI: −0.77–0.87; 46% vs. 43%, respectively). The next analysis compared the articulating face and isolated mouth condition probe trials, finding a significant difference (
β = −0.63,
SE = 0.16,
z = −3.88,
p < 0.001, CI: −0.95–−0.31) favoring the articulating face condition (53% vs. 39%, respectively). However, no significant differences were found between the articulating face and static face conditions (
β = −0.40,
SE = 0.41,
z = −0.98,
p = 0.325, CI: −1.23–0.41; 53% vs. 46%, respectively). Similarly, no significant differences were found between the isolated mouth and static face conditions (
β = 0.22,
SE = 0.41,
z = 0.54,
p = 0.586, CI: −0.60–1.04; 39% vs. 46%, respectively). Lastly, the random effects results indicated a variability for both participants (
var = 0.20,
S = 0.45) and talkers (
var = 0.18,
S = 0.42).
To examine the learning rates, we ran another set of regression models in which condition, probe trials, and the interaction between condition and probe trials were treated as fixed effects, and participants and probe talkers were included as random effects. Accuracy on the probe trials was included as the dependent variable. The analysis revealed a significant main effect of the probe trials (β = 0.05, SE = 0.01, z = 5.49, p < 0.001, CI: 0.03–0.06). The analysis also revealed a significant difference in the learning rate of those who were trained with articulating faces compared to those trained auditorily (β = 0.02, SE = 0.01, z = 2.79, p < 0.01, CI: 0.01–0.04), favoring the articulating face condition. However, a significant difference was not observed between the isolated mouth and audio-only conditions (β = 0.01, SE = 0.01, z = 1.50, p = 0.13, CI: −0.003–0.03). There was no significant difference between the static face and audio-only conditions (β = −0.04, SE = 0.02, z = −1.71, p = 0.087, CI: −0.08–0.01).
Additionally, a significant difference was not observed between those who were trained with articulating faces compared to those trained with the isolated mouths (β = −0.01, SE = 0.01, z = −1.27, p = 0.203, CI: −0.03–0.01). However, a significant difference between the articulating face and static face conditions was found (β = −0.06, SE = 0.02, z = −2.87, p < 0.01), favoring the articulating face condition. Similarly, the analysis revealed a significant difference between the isolated mouth and static face conditions (β = −0.05, SE = 0.02, z = −2.33, p = 0.020) favoring the static face condition. Lastly, the random effects results revealed variability within both the participants (var = 0.24, S = 0.49) and the probe talkers (var = 0.14, S = 0.38).
3.3. Training Phase: Training Trials
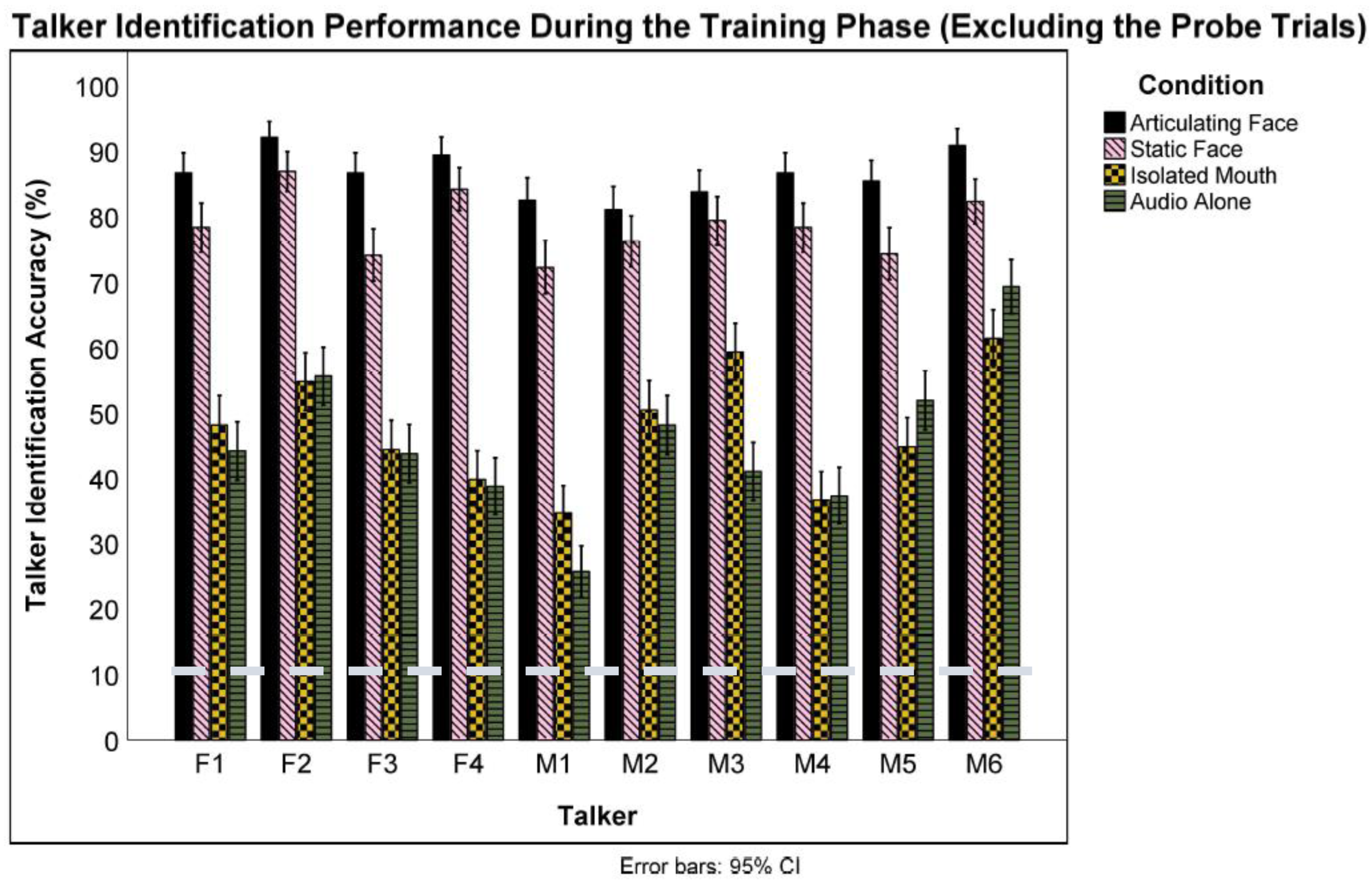
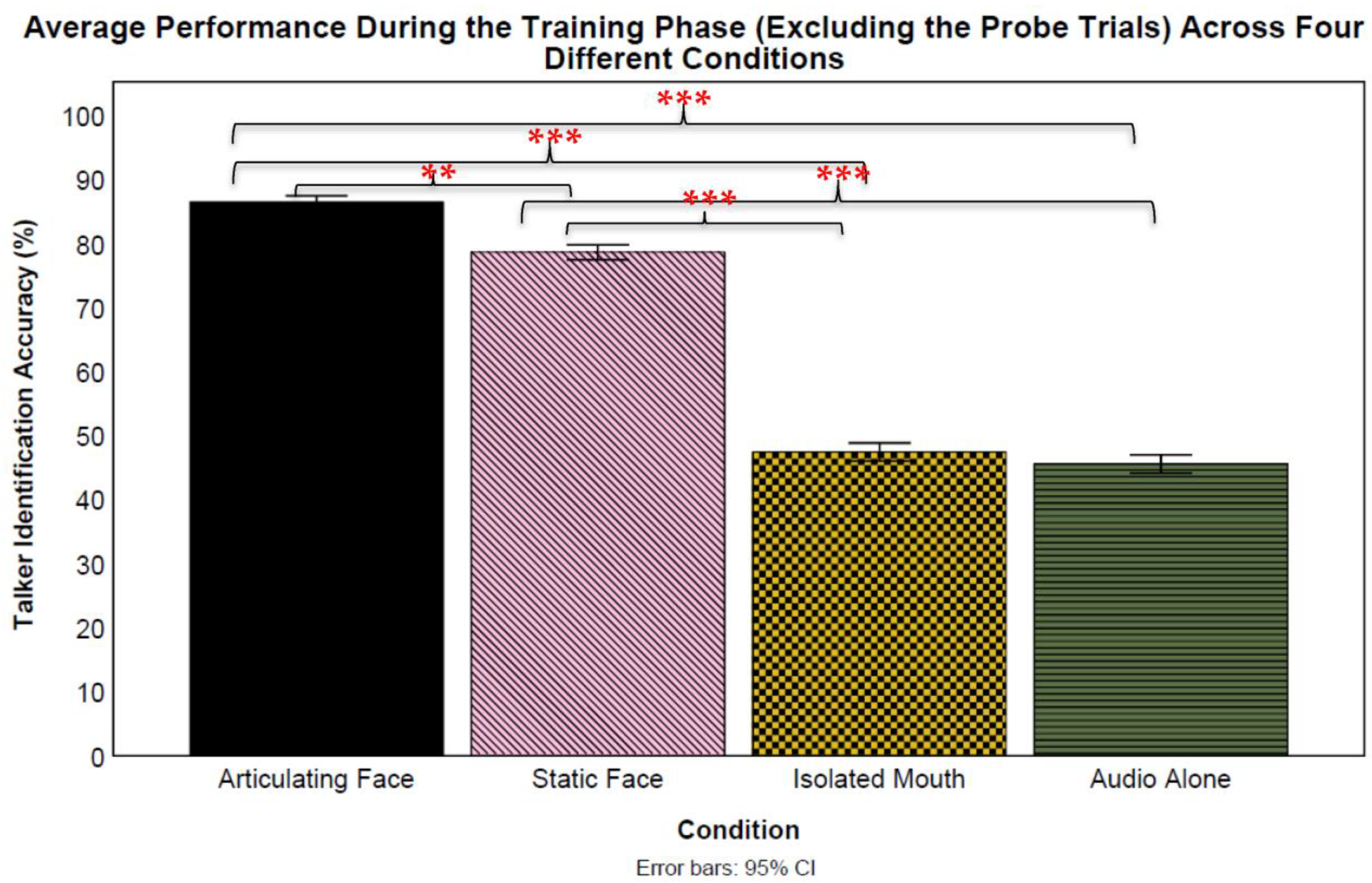
Lastly, we examined recognition performance for the nonprobe training trials. Because for three of the conditions, these trials involved audiovisual presentations, and performance on these trials does not represent just voice learning, per se. While the participants were told to concentrate on learning the voices, it is likely that they used the facial information to respond to these trials. Thus, the results of this analysis necessarily inform less about patterns of voice learning. The training analyses examining performance for the
articulating face condition against chance level only included the trials with articulating faces and not the audio-only probe trials. A one-sample
t-test revealed that participants in the
articulating face condition identified talkers at a better than chance (10%) level during the training phase (
M = 0.87,
S = 0.10),
t(23) = 37.93,
p < 0.001,
Cohen’s d = 7.74. Talker identification rate varied significantly across talkers,
F(9) = 5.19,
p < 0.001,
np2 = 0.01 (see
Figure 5). Based on the Bonferroni-corrected (
α = 0.005) analyses, all talkers were identified at above chance levels.
Similarly, a one-sample
t-test revealed that participants in the
isolated mouth condition identified talkers at a better than chance (10%) level during the training trials (
M = 0.47,
S = 0.12),
t(23) = 15.38,
p < 0.001,
Cohen’s d = 3.14. Talker identification rate varied significantly across talkers,
F(9) = 16.700,
p < 0.001,
np2 = 0.300 (see
Figure 5). Based on the Bonferroni-corrected (
α = 0.005) analyses, all talkers were identified at above chance levels. Next, another one-sample
t-test showed that those in the
static image condition identified talkers at better than chance levels (
M = 0.79,
S = 0.15),
t(23) = 20.27,
p < 0.001,
Cohen’s d = 4.13. The Bonferroni-corrected (
α = 0.005) analyses revealed that talker identification varied significantly across talkers,
F(9) = 6.31,
p < 0.001,
np2 = 0.01 (see
Figure 5). A final one-sample
t-test revealed that participants in the
audio-only condition identified talkers at a better than chance level (
M = 0.46,
S = 0.10),
t(23) = 16.80,
p < 0.001,
Cohen’s d = 3.42. Talker identification rate varied significantly across talkers as well,
F(9) = 25.94,
p < 0.001,
np2 = 0.05 (see
Figure 5).
According to the post hoc
t-test analyses, all talkers were identified at above chance levels at a Bonferroni-corrected
α = 0.005. Logistic mixed-effect models were used to compare the training means across the four conditions (see
Figure 6). We compared the training means (excluding the probe trials) of all conditions against the audio-only condition by treating the condition as a fixed effect and participants and talkers as random effects. This analysis revealed a significant difference between the articulating face and audio-only training methods (
β = 2.30,
SE = 0.20,
z = 11.23,
p < 0.001, CI: 1.90–2.71) favoring the
articulating face condition (87% vs. 46%, respectively). However, a significant difference was not observed in the isolated mouth (
β = 0.08,
SE = 0.20,
z = 0.41,
p = 0.683, CI: −0.32–0.48) condition when compared to the audio-only condition (47% vs. 46%, respectively).
Similar to the articulating face condition, there was a significant difference in the static face (β = 1.69, SE = 0.20, z = 8.36, p < 0.001, CI: 1.29–2.10) condition when compared to the audio-only condition favoring the static face condition (79% vs. 46%, respectively). Next, there was a significant difference between the articulating face and isolated mouth training methods (β = −2.22, SE = 0.21, z = −10.82, p < 0.001, CI: −2.63–−1.82) favoring the articulating face condition (87% vs. 47%, respectively). Similarly, there was a significant difference between the articulating face and static face training methods (β = −0.61, SE = 0.21, z = −2.93, p = 0.003, CI: −1.02–−0.20) favoring the articulating face condition (87% vs. 79%, respectively). Additionally, there was a significant difference between the isolated mouth and static face training method (β = 1.61, SE = 0.20, z = 7.94, p < 0.001, CI: 1.21–2.02) favoring the static face condition (47% vs. 79%, respectively). Lastly, variability was found both across the talkers (var = 0.11, S = 0.33) and participants (var = 0.46, S = 0.68). A final Analysis of Variance was conducted to examine the interaction between the training conditions and training talkers, which revealed a significant interaction F(27) = 8.93, p < 0.001, np2 = 0.01.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





