
Electroencephalographic Signal Data Augmentation Based on Improved Generative Adversarial Network

 , ,
, ,
Abstract
:1. Introduction
- Innovative generative adversarial network model: We propose an improved generative adversarial network model, L–C–WGAN–GP, to generate artificial EEG signal data. The model uses LSTM as generator and a CNN as discriminator, combining the advantages of deep learning to learn the statistical features of EEG signals and generate synthetic EEG signal data close to the real samples.
- Data augmentation and training set augmentation: It can be used to enhance existing training sets by generating EEG data generated from an adversarial network model. This data-augmented approach can extend the scale and diversity of the training data, combined with using the gradient penalty-based Wasserstein distance as the loss function in model training to improve the performance and robustness of deep learning models.
- Applied to the compressed perceptual reconstruction model: we added the generated EEG data to the original dataset to train the compressed perceptual reconstruction model of EEG signals. Experimental results show that using the enhanced dataset can significantly improve the accuracy of compressed perceptual reconstruction, and thus improve the reconstruction quality of EEG signal data.
2. Related Theories
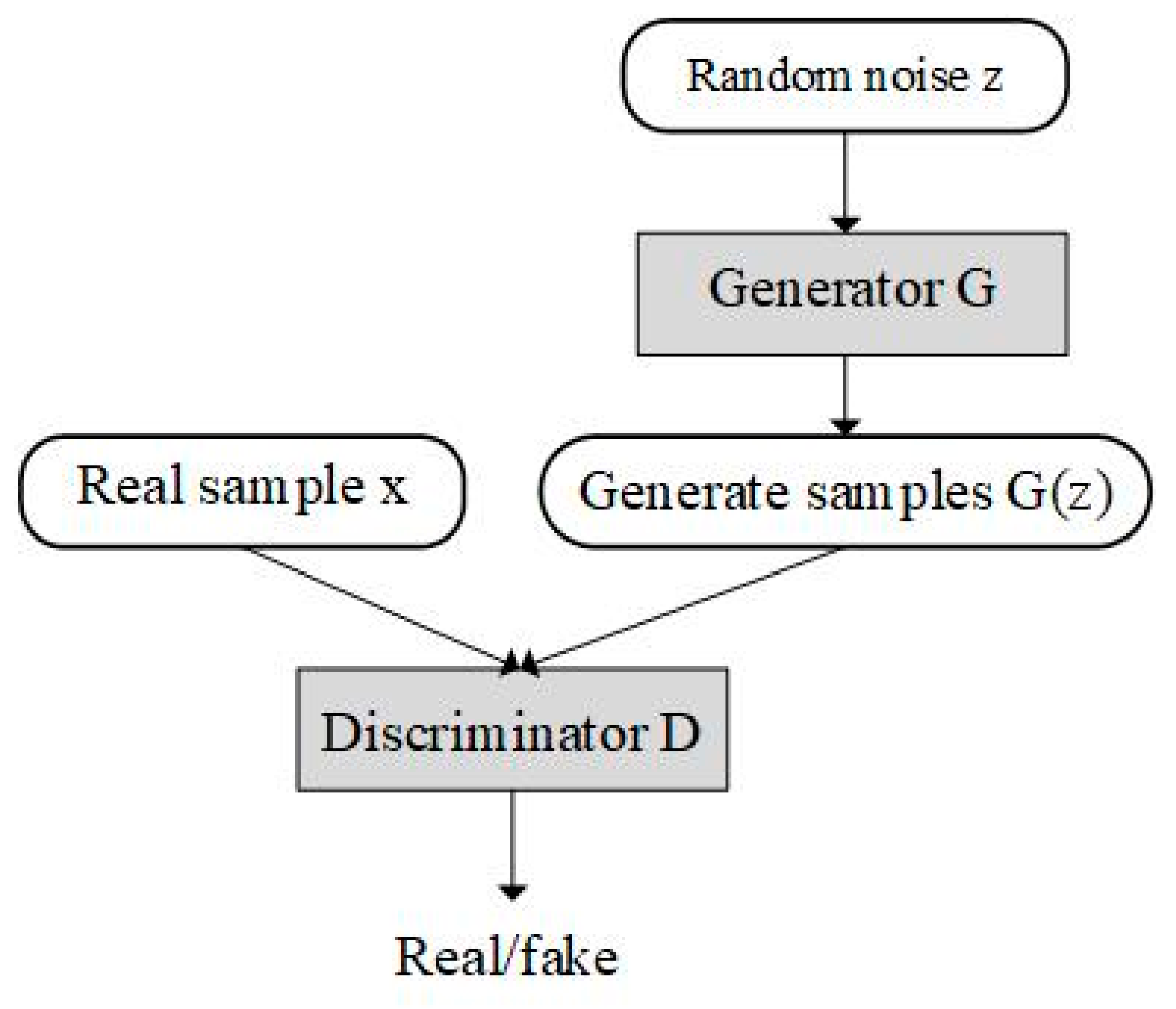
2.1. Generative Adversarial Network
2.2. WGAN–GP
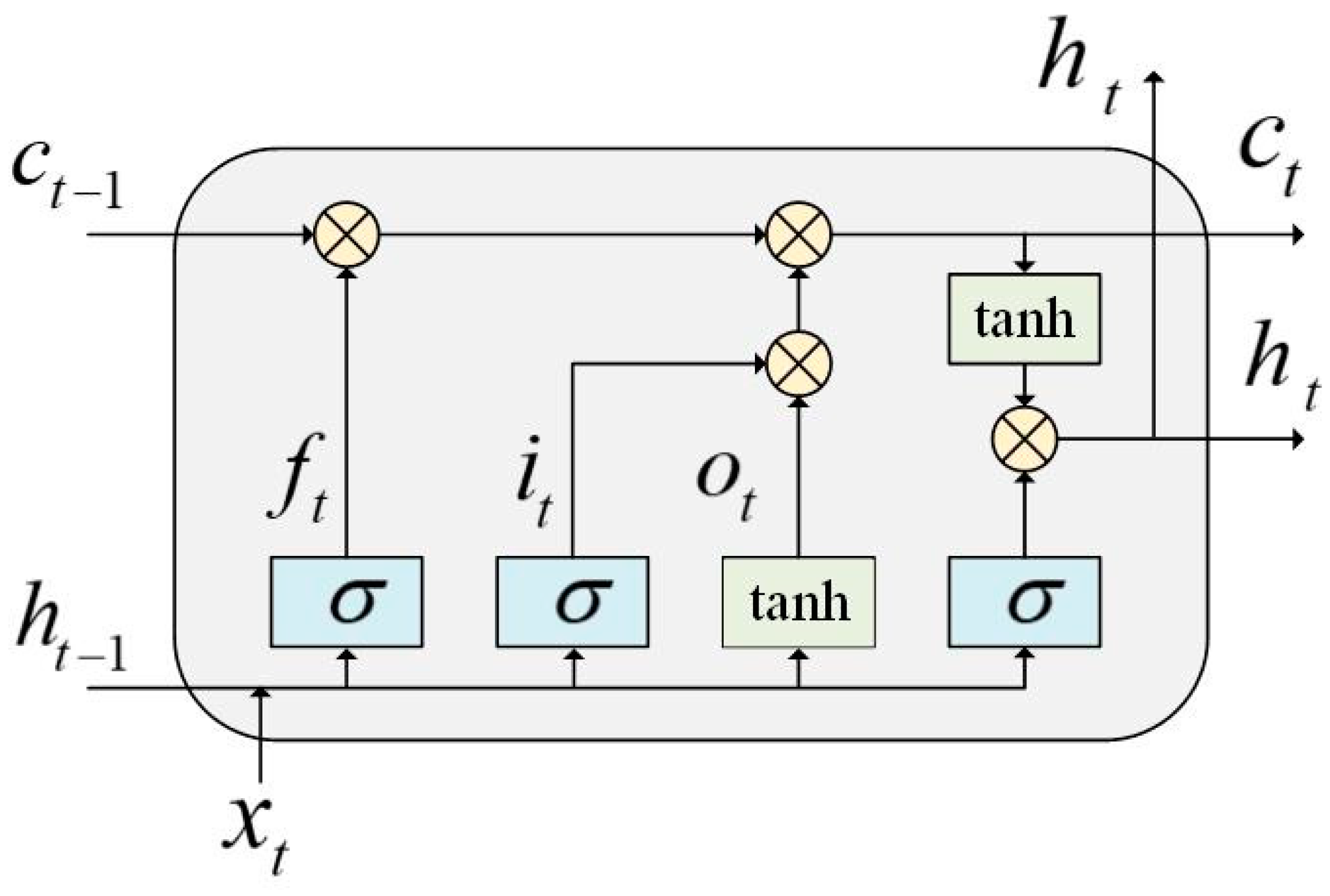
2.3. Long Short-Term Memory Network
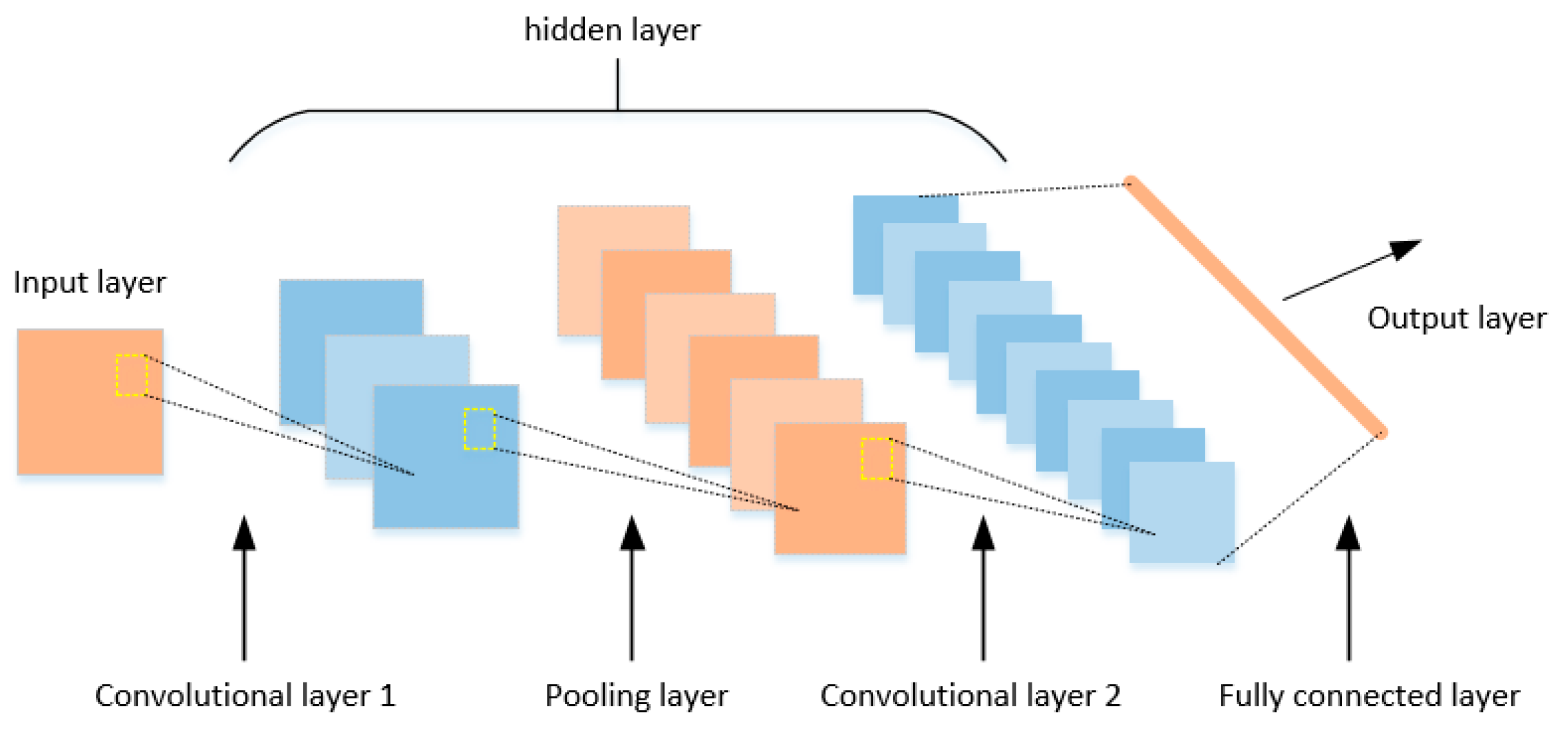
2.4. Convolutional Neural Network
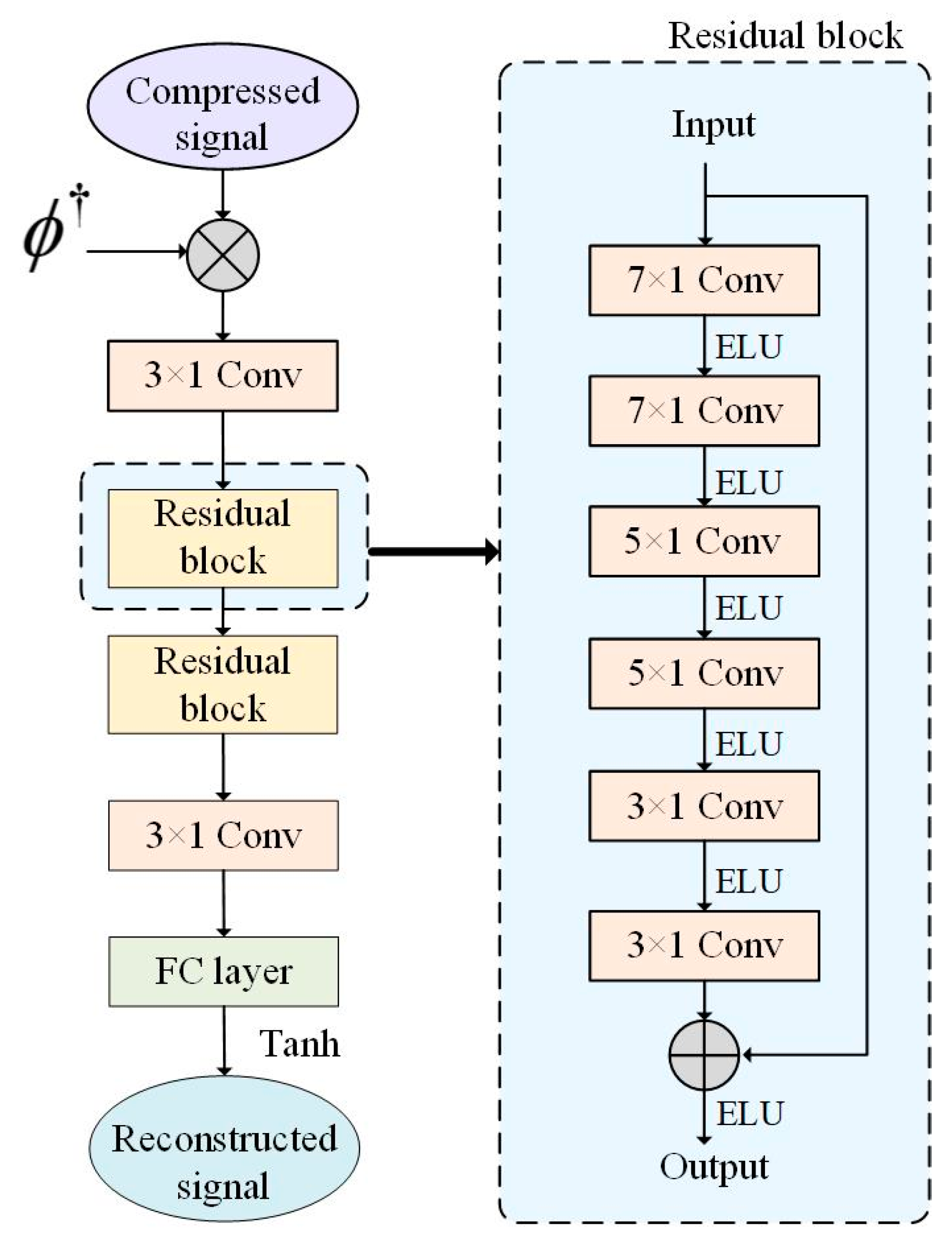
3. Approach
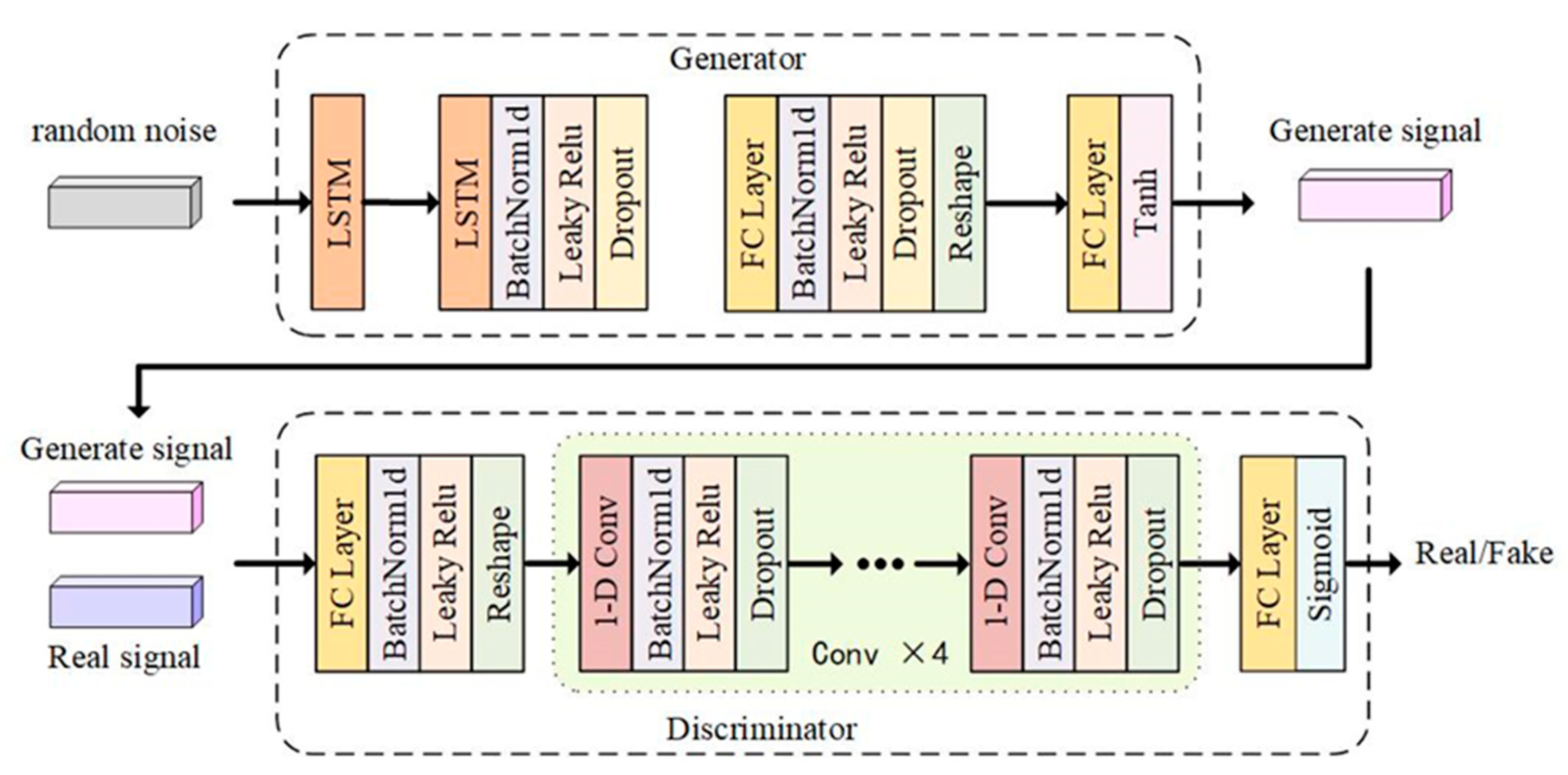
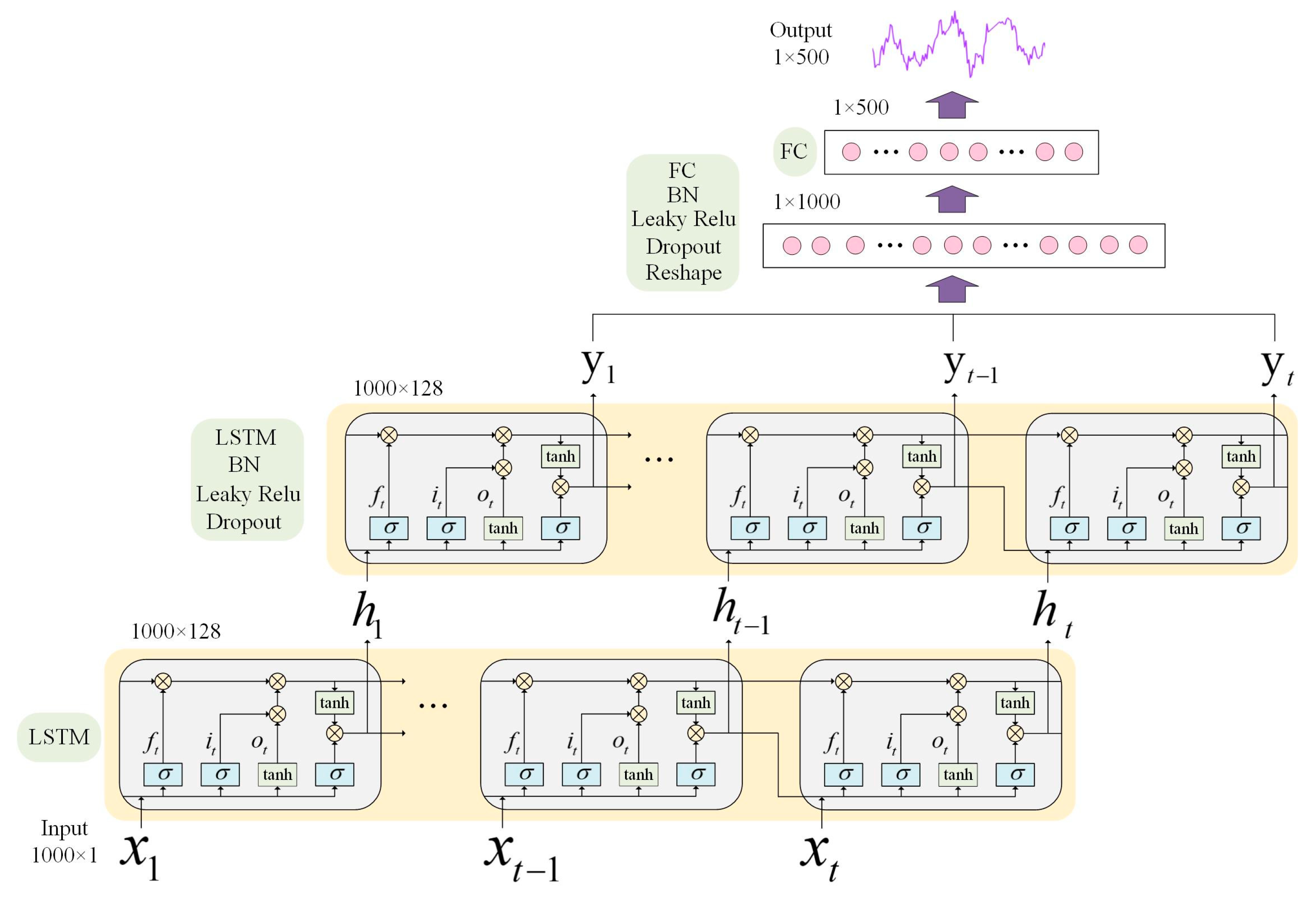
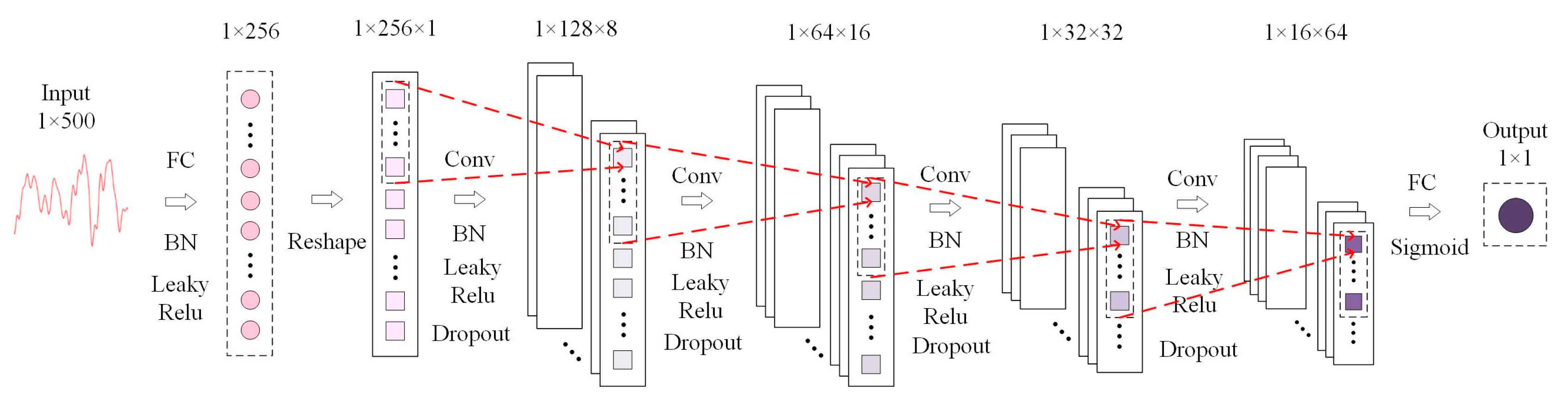
3.1. L–C–WGAN–GP Model
3.2. Generator Design
- Add the dropout layer to process the output of this layer;
- Set the discard rate to 0.5;
- Discard half of the network unit output in each layer;
- Set it to 0 in the discard bit, which can effectively prevent the occurrence of the over-fitting phenomenon.
3.3. Discriminator Design
4. Experimental Simulation and Analysis
4.1. Experimental Datasets
4.2. Experimental Environment
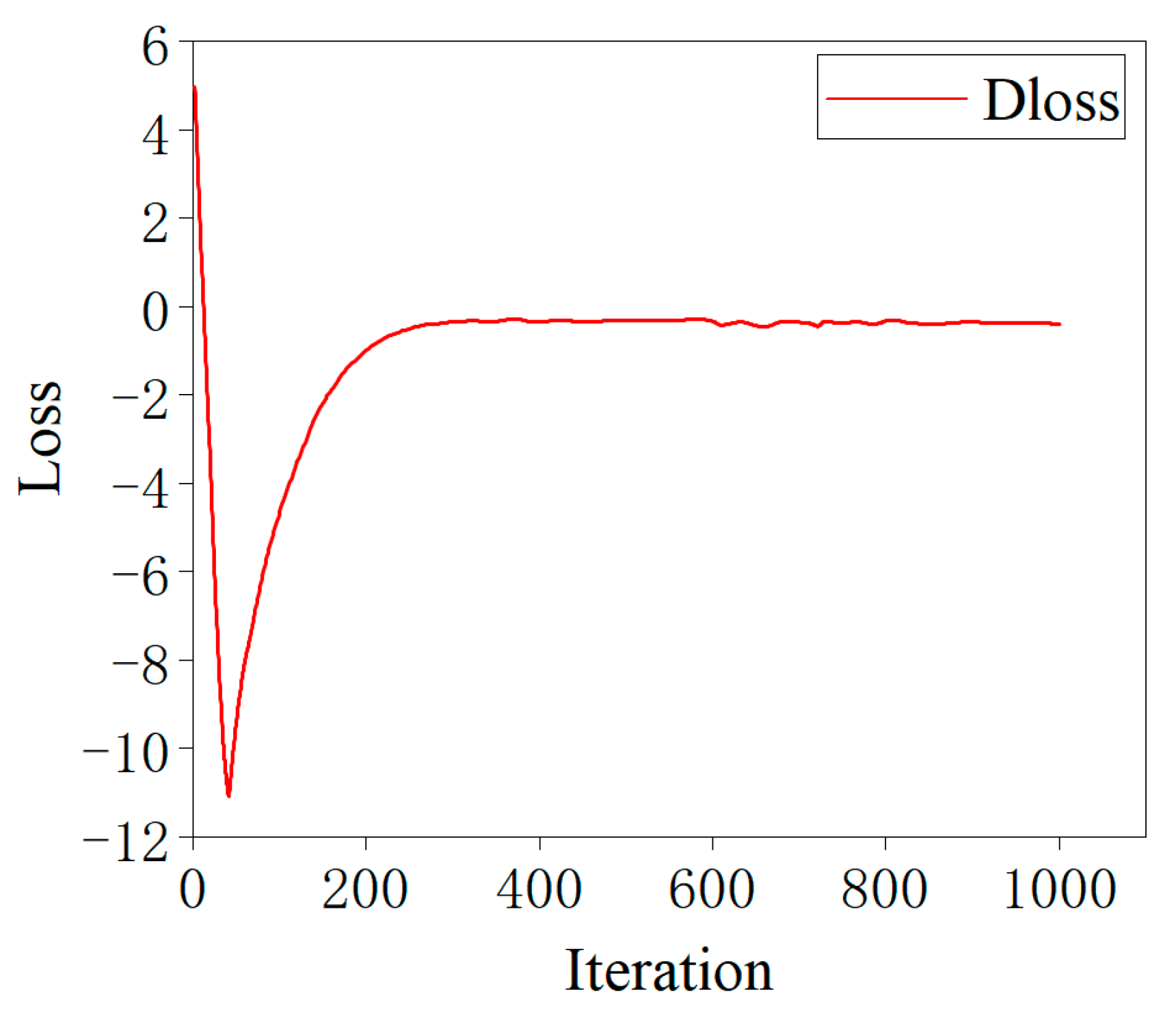
4.3. Trial Protocol and Model Training
4.3.1. Data Preprocessing
4.3.2. Model Training Scheme
4.3.3. Experimental Detail
4.4. Evaluation Indicators
4.4.1. Similarity Evaluation Indicators
4.4.2. Evaluation Index of Compressed Sensing Reconstruction
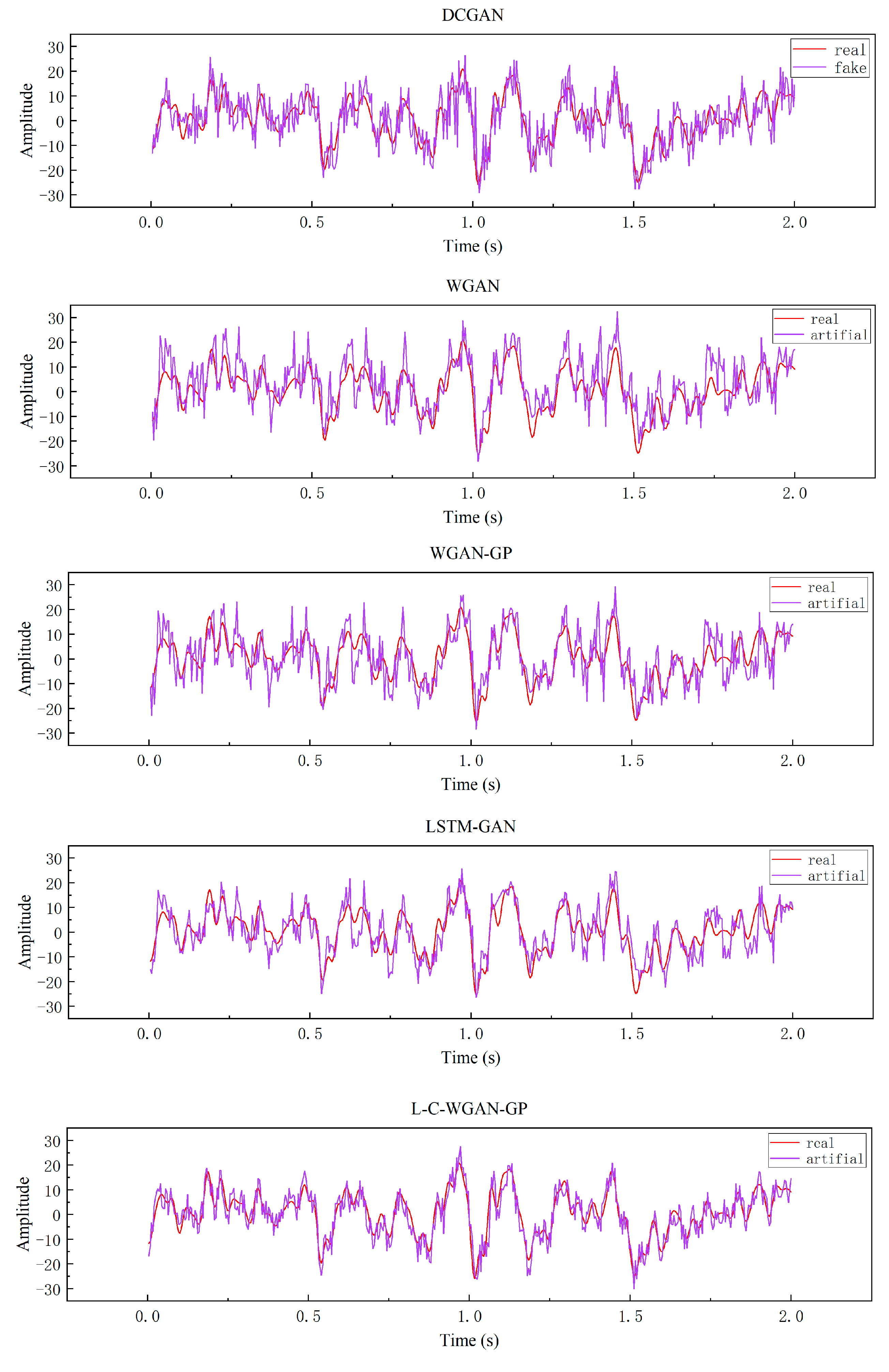
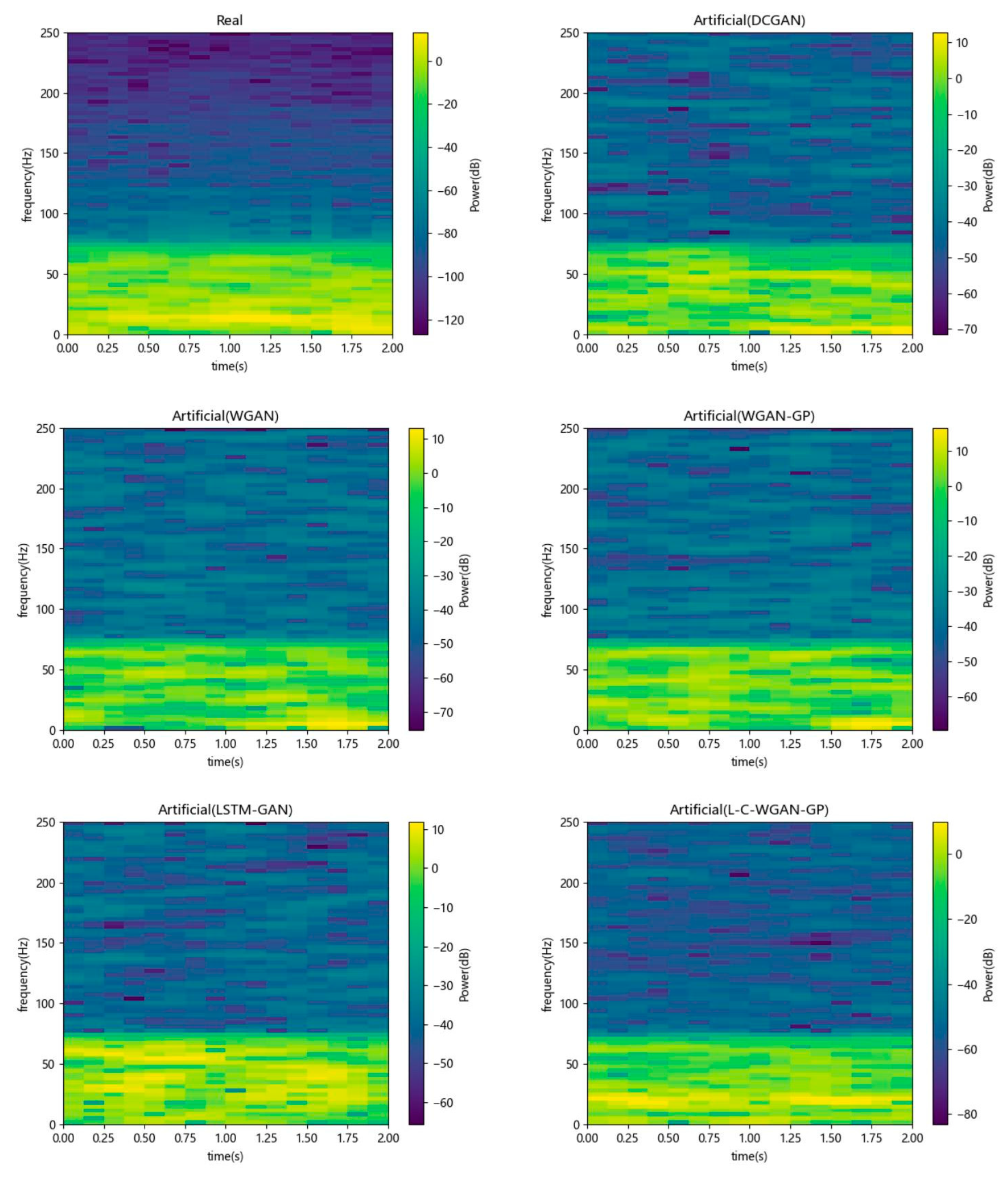
4.5. Experimental Analysis
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaid, S.; Singh, P.; Kaur, C. EEG signal analysis for BCI interface: A review. In Proceedings of the 2015 Fifth International Conference on Advanced Computing & Communication Technologies, Haryana, India, 21–22 February 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 143–147. [Google Scholar]
- Hosseini, M.P.; Hosseini, A.; Ahi, K. A Review on Machine Learning for EEG Signal Processing in Bioengineering. In IEEE Reviews in Biomedical Engineering; IEEE: Piscataway, NJ, USA, 2020; p. 1. [Google Scholar]
- Ahangi, A.; Karamnejad, M.; Mohammadi, N.; Ebrahimpour, R.; Bagheri, N. Multiple classifier system for EEG signal classification with application to brain-computer interfaces. Neural Comput. Appl. 2013, 23, 1319–1327. [Google Scholar] [CrossRef]
- Lalitharatne, T.D.; Teramoto, K.; Hayashi, Y.; Kiguchi, K. Towards hybrid EEG-EMG-based control approaches to be used in bio-robotics applications: Current status, challenges and future directions. Paladyn J. Behav. Robot. 2013, 4, 147–154. [Google Scholar] [CrossRef]
- Li, J.Y.; Du, X.B.; Zhu, Z.L.; Deng, X.M.; Ma, C.X.; Wang, H.A. A review of deep learning research on EEG emotion recognition. J. Softw. 2023, 34, 255–276. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. Deap: A Database for Emotion Analysis; Using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef]
- Fahimi, F.; Dosen, S.; Ang, K.K.; Mrachacz-Kersting, N.; Guan, C. Generative adversarial networks-based data augmentation for brain–computer interface. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: Piscataway, NJ, USA, 2020; pp. 4039–4051. [Google Scholar]
- Veeranki, Y.R.; Ganapathy, N.; Swaminathan, R. Analysis of Fluctuation Patterns in Emotional States Using Electrodermal Activity Signals and Improved Symbolic Aggregate Approximation. Fluct. Noise Lett. 2022, 21, 2250013. [Google Scholar] [CrossRef]
- Veeranki, Y.R.; McNaboe, R.; Posada-Quintero, H.F. EEG-Based Seizure Detection Using Variable-Frequency Complex Demodulation and Convolutional Neural Networks. Signals 2023, 4, 816–835. [Google Scholar] [CrossRef]
- Angus-Leppan, H. Diagnosing Epilepsy in Neurology Clinics: A Prospective Study. Seizure 2008, 17, 431–436. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Mao, X.; Sun, L.; Yang, Y. EEG data augmentation for personal identification using SF-GAN. In Proceedings of the 2022 3rd International Conference on Computer Vision, Image and Deep Learning & International Conference on Computer Engineering and Applications (CVIDL & ICCEA), Changchun, China, 20–22 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Hasan, M.A.; Khan, M.U.; Mishra, D. A Computationally Efficient Method for Hybrid EEG-fNIRS BCI Based on the Pearson Correlation. BioMed Res. Int. 2020, 2020, 1838140. [Google Scholar] [CrossRef]
- Saini, M.; Satija, U.; Upadhyay, D.M. Wavelet Based Waveform Distortion Measures for Assessment of Denoised EEG Quality with Reference to Noise-Free EEG Signal. In IEEE Signal Processing Letters; IEEE: Piscataway, NJ, USA, 2020; pp. 1260–1264. [Google Scholar]
- Gaur, P.; Gupta, H.; Chowdhury, A.; McCreadie, K.; Pachori, R.B.; Wang, H. A Sliding Window Common Spatial Pattern for Enhancing Motor Imagery Classification in EEG-BCI. IEEE Trans. Instrum. Meas. 2021, 70, 4002709. [Google Scholar] [CrossRef]
- de Souza, V.L.T.; Marques, B.A.D.; Batagelo, H.C.; Gois, J.P. A review on Generative Adversarial Networks for image generation. Comput. Graph. 2023, 114, 13–25. [Google Scholar] [CrossRef]
- Contreras-Cruz, M.A.; Correa-Tome, F.E.; Lopez-Padilla, R.; Ramirez-Paredes, J.P. Generative Adversarial Networks for anomaly detection in aerial images. Comput. Electr. Eng. 2023, 106, 108470. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X. High-resolution concrete damage image synthesis using conditional generative adversarial network. Autom. Constr. 2023, 147, 104739. [Google Scholar] [CrossRef]
- Tian, C.; Ma, Y.; Cammon, J.; Fang, F.; Zhang, Y.; Meng, M. Dual-encoder VAE-GAN with Spatiotemporal Features for Emotional EEG Data Augmentation. In IEEE Transactions on Neural Systems and Rehabilitation Engineering: A Publication of the IEEE Engineering in Medicine and Biology Society; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar]
- Liu, Q.; Hao, J.; Guo, Y. EEG Data Augmentation for Emotion Recognition with a Task-Driven GAN. Algorithms 2023, 16, 118. [Google Scholar] [CrossRef]
- Hartmann, K.G.; Schirrmeister, R.T.; Ball, T. EEG-GAN: Generative adversarial networks for electroencephalograhic (EEG) brain signals. arXiv 2018, arXiv:1806.01875. [Google Scholar]
- Abdelfattah, S.M.; Abdelrahman, G.M.; Wang, M. Augmenting the size of EEG datasets using generative adversarial net-works. In 2018 International Joint Conference on Neural Networks (IJCNN); IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Luo, Y.; Lu, B.L. EEG data augmentation for emotion recognition using a conditional Wasserstein GAN. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 2535–2538. [Google Scholar]
- Hu, M.; Chen, J.; Jiang, S.; Ji, W.; Mei, S.; Chen, L.; Wang, X. E2SGAN: EEG-to-SEEG translation with generative adversarial networks. Front. Neurosci. 2022, 16, 971829. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhong, S.H.; Liu, Y. GANSER: A self-supervised data augmentation framework for EEG-based emotion recognition. In IEEE Transactions on Affective Computing; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Abdelghaffar, Y.; Hashem, A.; Eldawlatly, S. Generative Adversarial Networks for Augmenting EEG Data in P300-based Applications: A Comparative Study. In Proceedings of the 2022 IEEE 35th International Symposium on Computer-Based Medical Systems (CBMS), Shenzhen, China, 21–23 July 2022; pp. 1–6. [Google Scholar]
- Zhang, Z.; Shenghua, Z.; Yan, L. Beyond Mimicking Under-Represented Emotions: Deep Data Augmentation with Emotional Subspace Constraints for EEG-Based Emotion Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 10252–10260. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Villani, C.; Villani, C. The wasserstein distances. In Optimal Transport: Old and New; Springer: Berlin/Heidelberg, Germany, 2009; pp. 93–111. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Singh, K.; Malhotra, J. Two-layer LSTM network-based prediction of epileptic seizures using EEG spectral features. Complex Intell. Syst. 2022, 8, 2405–2418. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Khare, S.K.; Bajaj, V. Time–Frequency Representation and Convolutional Neural Network-Based Emotion Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2901–2909. [Google Scholar] [CrossRef]
- Pan, X. Time series data anomaly detection based on LSTM-GAN. Front. Comput. Intell. Syst. 2022, 1, 35–37. [Google Scholar] [CrossRef]
- Liu, Y.; Jebelli, H. Enhanced Robotic Teleoperation in Construction Using a GAN-Based Physiological Signal Augmentation Framework. In Proceedings of the Canadian Society of Civil Engineering Annual Conference 2021: CSCE21 General Track Volume 1; Springer Nature Singapore: Singapore, 2022; pp. 295–307. [Google Scholar]
- Ma, Z.; Mei, G.; Piccialli, F. An Attention Based Cycle-Consistent Generative Adversarial Network for IoT Data Generation and Its Application in Smart Energy Systems. IEEE Trans. Ind. Inform. 2022, 19, 6170–6181. [Google Scholar] [CrossRef]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Willmott, C.J. Some comments on the evaluation of model performance. Bull. Am. Meteorol. Soc. 1982, 63, 1309–1313. [Google Scholar] [CrossRef]
- Aronov, B.; Har-Peled, S.; Knauer, C.; Wang, Y.; Wenk, C. Fréchet distance for curves, revisited. In Proceedings of the Algorithms–ESA 2006: 14th Annual European Symposium, Zurich, Switzerland, 11–13 September 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 52–63. [Google Scholar]
- Keogh, J.; Pazzani, M.J. Derivative Dynamic Time Warping. In Proceedings of the First SIAM International Conference on Data Mining, Arlington, VA, USA, 11–13 April 2002. [Google Scholar]
- Cao, W.; Zhang, J. Real-Time Deep Compressed Sensing Reconstruction for Electrocardiogram Signals. In Proceedings of the 2022 14th International Conference on Machine Learning and Computing (ICMLC), Guangzhou, China, 18–21 February 2022; p. 490. [Google Scholar]
- Abu-Srhan, A.; Abushariah, M.A.M.; Al-Kadi, S.O. The effect of loss function on conditional generative adversarial networks. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 6977–6988. [Google Scholar]
- Radford, A.; Metz, L. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Xu, Z.; Du, J.; Wang, J.; Jiang, C.; Ren, Y. Satellite image prediction relying on GAN and LSTM neural networks. In Proceedings of the ICC 2019-2019 IEEE International Conference on Communications (ICC); IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Du, X.; Liang, K.; Lv, Y.; Qiu, S. Fast reconstruction of EEG signal compression sensing based on deep learning. Sci. Rep. 2024, 14, 5087. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | DCGAN | WGAN | WGAN–GP | LSTM–GAN | L–C–WGAN–GP |
|---|---|---|---|---|---|
| RMSE | 0.71 | 0.40 | 0.37 | 0.26 | 0.21 |
| FD | 0.99 | 0.92 | 0.89 | 0.81 | 0.75 |
| DTW | 23.71 | 16.89 | 15.23 | 12.87 | 10.38 |
| CR/% | CNN (PRD/%) | ||||
|---|---|---|---|---|---|
| None | Add 25% | Add 50% | Add 75% | Add 100% | |
| 90% | 0.9728 | 0.9291 | 0.8852 | 0.8477 | 0.8212 |
| 80% | 1.0507 | 0.9913 | 0.9343 | 0.9064 | 0.8796 |
| 70% | 1.2605 | 1.1954 | 1.1436 | 1.1108 | 1.0954 |
| 60% | 1.3053 | 1.2589 | 1.1997 | 1.1539 | 1.1297 |
| 50% | 1.5008 | 1.4321 | 1.3847 | 1.3583 | 1.3178 |
| 40% | 2.2074 | 2.1282 | 2.0693 | 2.0165 | 1.9855 |
| 30% | 6.2556 | 5.9215 | 5.7764 | 5.3842 | 5.0331 |
| 20% | 25.7751 | 24.8785 | 24.0494 | 22.7955 | 21.9786 |
| 10% | 44.2411 | 42.7291 | 41.2338 | 39.8773 | 38.6593 |
| CR/% | CS-ResNet (PRD/%) | ||||
|---|---|---|---|---|---|
| None | Add 25% | Add 50% | Add 75% | Add 100% | |
| 90% | 0.5485 | 0.4889 | 0.4465 | 0.4178 | 0.3966 |
| 80% | 0.5976 | 0.5447 | 0.4979 | 0.4766 | 0.4498 |
| 70% | 0.6198 | 0.5623 | 0.5244 | 0.4981 | 0.4763 |
| 60% | 0.6506 | 0.5991 | 0.5493 | 0.5212 | 0.5049 |
| 50% | 0.7996 | 0.7268 | 0.6881 | 0.6549 | 0.6411 |
| 40% | 1.0016 | 0.9546 | 0.9173 | 0.8896 | 0.8588 |
| 30% | 3.9906 | 3.6824 | 3.4564 | 3.3151 | 3.189 |
| 20% | 20.1886 | 19.2756 | 18.2276 | 17.3934 | 16.4784 |
| 10% | 30.2299 | 29.3579 | 27.9547 | 26.6872 | 25.5369 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, X.; Wang, X.; Zhu, L.; Ding, X.; Lv, Y.; Qiu, S.; Liu, Q. Electroencephalographic Signal Data Augmentation Based on Improved Generative Adversarial Network. Brain Sci. 2024, 14, 367. https://doi.org/10.3390/brainsci14040367
Du X, Wang X, Zhu L, Ding X, Lv Y, Qiu S, Liu Q. Electroencephalographic Signal Data Augmentation Based on Improved Generative Adversarial Network. Brain Sciences. 2024; 14(4):367. https://doi.org/10.3390/brainsci14040367
Chicago/Turabian StyleDu, Xiuli, Xinyue Wang, Luyao Zhu, Xiaohui Ding, Yana Lv, Shaoming Qiu, and Qingli Liu. 2024. "Electroencephalographic Signal Data Augmentation Based on Improved Generative Adversarial Network" Brain Sciences 14, no. 4: 367. https://doi.org/10.3390/brainsci14040367