1. Introduction
Mild cognitive impairment (MCI) is considered as a prodromal stage of Alzheimer’s disease based on clinical symptoms [
1]. It is also a transitional period between healthy aging, where cognitive decline is a normal phenomena, and dementia [
2]. MCI usually impacts cognitive abilities such as reasoning, memory, and logic [
3]. People with this condition are usually forgetful, and need more time to think or express certain thoughts. However, they do not need assisted living facilities, because they are able to take care of themselves in everyday life. People with MCI may or may not convert to Alzheimer’s disease [
4,
5,
6] or dementia [
4]. The condition every year affects millions of people worldwide and attracts large investments from governments into research and drug production. There is no cure for this disease; however, certain treatments can reduce symptoms if applied on time. Therefore, early diagnosis is crucial, which allows patients and their caregivers enough time to prepare for the future. However, currently, there is no standardized assessment that would allow one to accurately diagnose MCI [
7]. Due to this fact, researchers try to find new ways to accurately detect MCI via a vast number of different data modalities, for example, electroencephalogram (EEG) [
8], 18F fluoro-deoxy-glucose positron emission tomography (FDG-PET) [
9], cerebrospinal fluid (CSF) biomarkers [
10], natural language [
11], or T1w and T2w MRI [
12,
13]. Neuroimaging markers are becoming more popular and show great potential towards accurately identifying MCI [
14,
15]. Certain structural changes in the brain are present when a patient has MCI, for example, a decrease in gray matter volume in the medial temporal lobe [
16] and hippocampal, entorhinal cortex atrophy with cortical volume decrease [
17,
18]. The task of detecting MCI is challenging, because it usually affects elderly people, and it is hard to distinguish if changes in the brain volume are impacted due to normal aging [
19] or due to MCI, since some of the regions, for example, the temporal lobe, show a volume decrease in both scenarios. Therefore, it is crucial for the tools to not only focus on the specific known regions of interest (ROI), but also to incorporate other regions of the brain, which may have a correlation to the presence of MCI. Particularly, enhancing smaller regions with finer details in MRI may allow diagnostic tools such as deep learning (DL) models to find other important regions and more accurately detect MCI.
Super-resolution technology has been a helpful tool in many different science areas, for example, hyperspectral imaging [
20], nature sciences [
21], satellite imagery [
22], license plate recognition [
23], and medical imaging—this paper. This technology utilizes deep learning models to increase the quality of low-resolution data by upscaling and reconstructing an image, which would be accurate and meaningful. Usually, researchers focus their super-resolution solutions into improvements in a controlled environment, where a small dataset with a highly specialized solution can reach high results, but all of these solutions are impractical in real world scenarios, where data are usually not a controlled factor. A small change in the data domain means the model will be incapable of reconstructing that image. In these challenging scenarios, “real-world” super-resolution solutions become useful. These solutions do not rely on paired image datasets, where a low-resolution image is known for each high-resolution image. Here, low-resolution images are generated randomly by utilizing degradation (augmentation) techniques in a completely random order [
24]. By using degradation techniques, we can cover a wider distribution of possible input images, making the model more practical. Therefore, this paper utilizes the real-world super-resolution paradigm. Another problem with super-resolution is that many solutions are not focusing on the perceptual quality of the reconstructed images. Many researchers only focus on peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) to report their results, even though subjectively generated images are blurry and noisy. In the medical imaging field, preserving the structural part of the image quality is as important as the perceptual part. Therefore, just like in our previous paper [
25], we maintain the focus to improve the main important aspects of the image quality—structural and perceptual.
Deep learning model hyperparameter optimization plays a crucial role in enhancing the performance and accuracy of diagnostic models in the field of medical imaging [
26]. By fine-tuning parameters such as learning rates, layer configurations, and activation functions, these models can be better adapted to the nuances of medical datasets, which often contain complex patterns and subtle features critical for accurate diagnosis [
27]. Optimizing hyperparameters enables the models to effectively learn from high-dimensional imaging data, such as MRI, CT scans, and X-rays, leading to improved sensitivity and specificity in detecting and classifying diseases [
28].
In medical imaging diagnostics, the stakes are high, as the early and accurate identification of conditions can significantly impact patient outcomes [
26]. Hyperparameter optimization ensures that deep learning models are not only tailored to the unique challenges of medical data but also generalized enough to handle variations across different imaging modalities and patient demographics [
27]. This process also helps in reducing overfitting, ensuring that the model’s performance is robust across unseen data, which is paramount in clinical settings where the model’s predictions can directly influence treatment decisions [
29].
Bayesian networks, a class of probabilistic graphical models, represent complex relationships between a set of variables using directed acyclic graphs (DAGs) [
30]. Each node in a Bayesian network symbolizes a variable, while the edges denote conditional dependencies between them, encapsulating the probabilistic influences of variables on one another [
31]. In the context of hyperparameter optimization for machine learning models, Bayesian networks serve as a powerful tool to model and understand the intricate dependencies between various hyperparameters and their impact on model performance metrics [
32]. By capturing these relationships, Bayesian networks facilitate a structured exploration of the hyperparameter space, enabling the identification of optimal configurations [
33]. This approach not only streamlines the optimization process by focusing on the most influential hyperparameters but also enhances the efficiency and efficacy of the model tuning phase, leveraging probabilistic reasoning to guide the search towards hyperparameter sets that are likely to yield improved performance outcomes [
32,
33].
The novelty and contribution of this study lie in its innovative integration of super-resolution imaging techniques and advanced machine learning optimization strategies to enhance the detection of MCI from structural MRI scans. Specifically, the study introduces the following novel contributions to the field of medical imaging and diagnostics:
By employing super-resolution techniques within a generative adversarial network (GAN) framework, this study improves the perceptual quality of structural MRI images. This enhancement is pivotal, as higher-resolution images can reveal subtle brain changes associated with MCI, which are often not discernible in low-resolution scans.
This research advances the state of the art by incorporating a combination of loss functions, including perceptual loss and adversarial loss, to not only increase the resolution of MRI images but also to maintain their diagnostic integrity. This approach addresses common issues in super-resolution, such as checkerboard artifacts, ensuring that the enhanced images are both high in quality and clinically reliable.
A key contribution is the application of a POMB approach for hyperparameter optimization in deep learning models used for MCI detection. This method systematically evaluates and selects hyperparameters to balance model complexity and performance, reducing overfitting and improving generalizability. The use of POMB in this context is novel, offering a structured framework for enhancing model accuracy in medical diagnostics.
This study validates the effectiveness of super-resolution preprocessing on MCI detection across various state-of-the-art deep learning architectures. This empirical evidence supports the premise that super-resolution can serve as a valuable preprocessing step in medical imaging analysis, potentially applicable beyond MCI detection.
The investigation into the impact of different discriminator architectures within the GAN framework on the quality of super-resolved images underscores the critical role of discriminator choice. This insight contributes to the broader understanding of how GAN components influence the outcome of super-resolution tasks, guiding future research and application in neuroimaging enhancement.
The main purpose of this study is to improve the processing of MRI data and validate the proposed methodology effectiveness in mild cognitive impairment detection.
The rest of the paper is organized as follows:
Section 2 discusses the related studies.
Section 3 explains the proposed methodology improvements to our previous work to improve perceptual quality of MR images.
Section 4 presents the research findings in terms of quantitative and qualitative evaluation of the proposed methodology.
Section 5 discusses and summarizes the findings and presents the conclusions.
2. Related Works
Neuroimage enhancement is a compelling field of study that is increasingly gaining traction in research circles. As advancements in imaging technology continue to improve, the need for enhancing neuroimages to extract more accurate diagnostic information becomes more pronounced. For identification of similar studies, we utilized the database engines—Web of Science, Scopus, IEEE Xplore, Springer Link, and Science Direct (Last accessed on 7 March 2024). We constructed the search queries using these keywords: super, resol*, mild*, mci, detect*, class*. We combined the keywords with Boolean operators (AND, OR) and filtered only to articles and conference proceedings. Asterisk (*) was used to include words with different suffixes. Only sources published after 2014 and written in English were included. After the initial screening, 157 sources were identified. After removing duplicates, 86 entries were left. After the title and abstract screening, 22 sources were left. After full-text eligibility review, 6 sources were included in the study, and are compared in
Table 1.
Alwakid et al. [
34] used ESRGAN [
35] to upscale retinal images, and then used the Inception v3 model [
36] to classify the images into five different classes of diabetic retinopathy (mild, moderate, proliferative, severe, undetected). The dataset they used was APTOS [
37]. Their experiments show that using super-resolution improves baseline accuracy by nearly 18%.
Tan et al. [
38] used the SRGAN [
39] model to upscale computed tomography (CT) scans of patient lungs, which then were used to classify with the VGG-16 [
40] model whether the patient has COVID-19 pneumonia or not. The dataset they used was COVID-CT [
41]. Their experiments also show that the super-resolution technique improves baseline accuracy by approximately 8%.
Nagayama et al. [
42] utilized super-resolution software PIQE (SR-DLR) [
43], which is being sold by Canon alongside their CT scanners. It is a custom 3D CNN trained on CT images. No other details are disclosed by the company. However, validation of the method shows that it improves not only image quality, but also the detection of coronary lumens, calcifications, and non-calcified plaques approximately. The methodology of the source describes using the detectability index to measure performance [
44]. The authors have not disclosed the dataset used in their study. The method shows an approximately 5% improvement over the other state-of-the-art solutions.
De Farias et al. [
45] slightly modified GAN-CIRCLE [
46] and used it to evaluate whether super-resolution improves feature selection in CT scans. For this reason, they used principal component analysis (PCA) with spatial pyramid pooling (SPP), and then checked which features were selected as the most important ones. The authors used the NSCLC [
47] dataset. Experiments show that using super-resolution improves feature selection by relatively 2% if ranking by the feature importance using the intraclass correlation coefficient (ICC).
Huang et al. [
48] combined wavelet transform with DDGAN [
49] to improve the resolution of the ADNI [
50] dataset images. They used T1w image slices from the coronal plane and performed ×4 times upscaling from 48 × 48 to 192 × 192 resolution. First, they downscaled the original images and then tried to reconstruct them with super-resolution. The experiments with the support vector machine (SVM) as classifier show a relative 2% performance increase by using super-resolution.
Zhang et al. [
51] used a custom 3D encoder–decoder GAN with residual connections to super-resolve T2w MRI images. The dataset that they used consisted of 200 patients who went through an inflammatory bowel disease clinical trial, but it is not publicly available. After super-resolving the images, they used ResNet to classify the images, and found no improvement over the baseline.
Table 1.
Comparison of different approaches for image super-resolution and classification in medical imaging.
Table 1.
Comparison of different approaches for image super-resolution and classification in medical imaging.
| Reference | Super-Resolution Model | Classification Model | Dataset | Improvement |
|---|
| Fundus photography | | | | |
| Alwakid et al. [34] | ESRGAN | Inception v3 | APTOS | 18% |
| CT Scans | | | | |
| Tan et al. [38] | SRGAN | VGG-16 | COVID-CT | 8% |
| Nagayama et al. [42] | PIQE (SR-DLR) | - | - | 5% |
| de Farias et al. [45] | Modified GAN-CIRCLE | PCA+SPP | NSCLC | 2% |
| MRI | | | | |
| Huang et al. [48] | DDGAN | SVM | ADNI | 2% |
| Zhang et al. [51] | 3D Encoder–Decoder GAN | ResNet | - | 0% |
| This paper | Hybrid Transformer GAN | Various Models | ADNI, OASIS-4 | 1–4% |
Naturally, the accuracy varies depending on the application and the size of the dataset used in training, but overall, super-resolution technology improves the accuracy of classification models in the majority of tasks.
4. Results
4.1. Preparation of Datasets Used for Detection of MCI
For the validation of the methodology in the detection of the MCI task, we used ADNI (Alzheimer’s Disease Neuroimaging Initiative) [
50] and the Open Access Series of Imaging Studies (OASIS) v4 [
74] datasets. We combined both datasets to have a broader spectrum of images in our training and validation sets, and we prepared three datasets out of the combined full dataset. Initially, all datasets were preprocessed with our suggested MRI preprocessing pipeline [
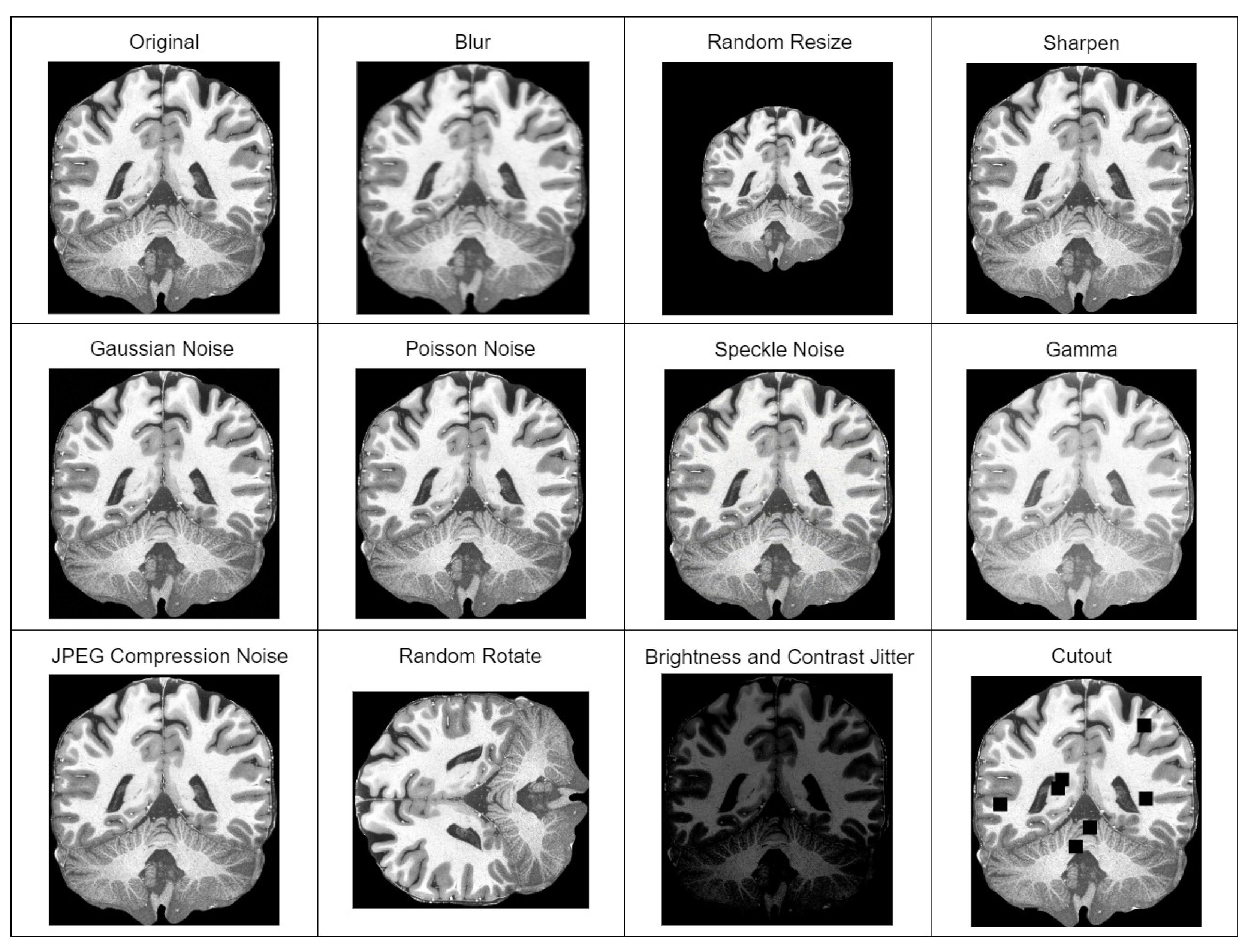
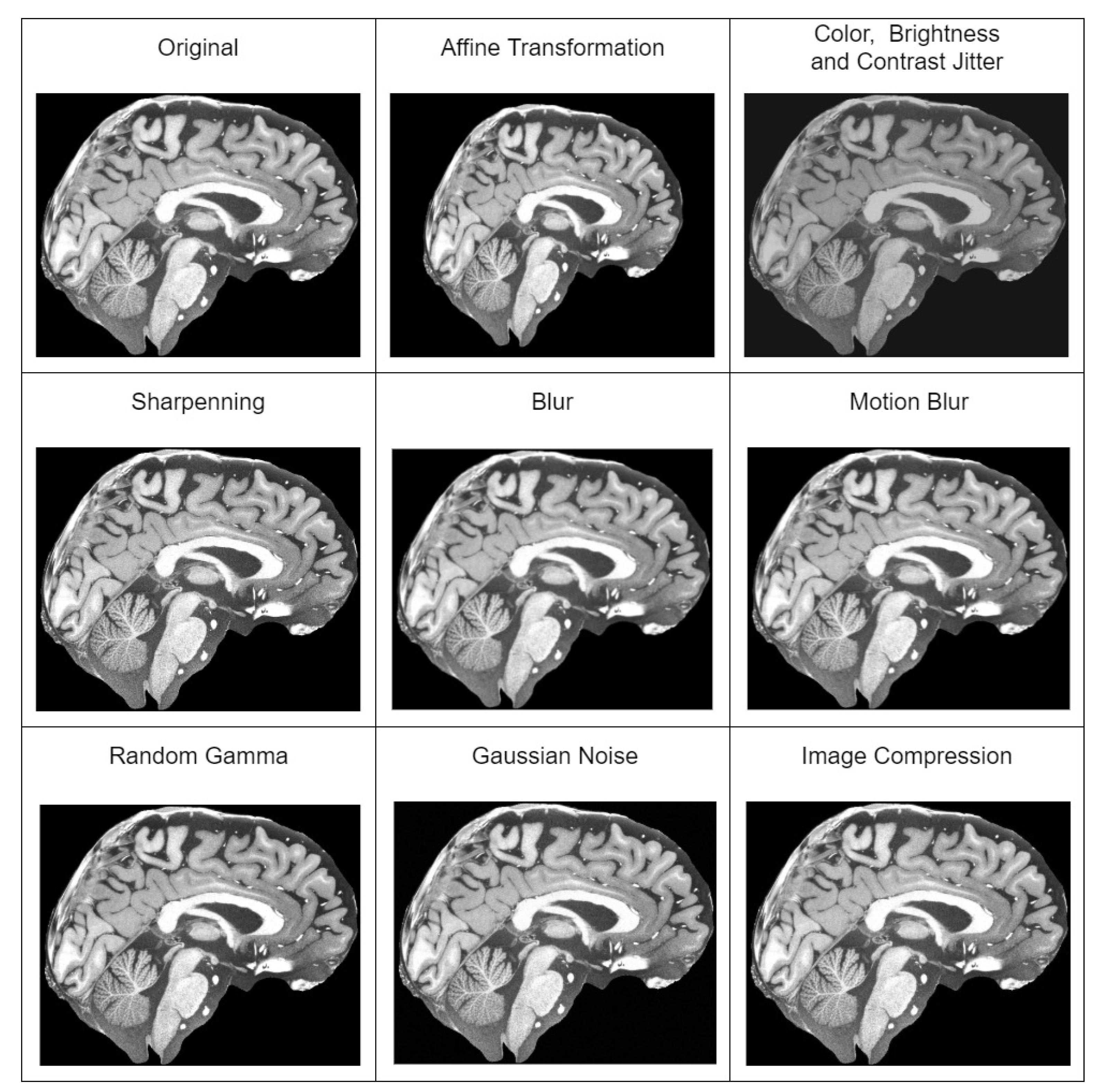
25], which included spatial normalization, intensity normalization, and skull stripping. Then, we extracted mid slices (sagittal, coronal and axial) of the brain from each patient, which were resized to 256 × 256 resolution. Dataset descriptions are given below:
Each dataset was split in training and validation sets with a proportion of 80/20. Since we only used three slice images of the brain in each plane (sagittal, coronal, axial) for each patient, there was no risk of data leakage. The same patient slices cannot appear in training and in validation.
4.2. Models Used in Detection of MCI
For the model architectures to use in the detection of MCI, we chose some of the state-of-the-art models that are not vision transformers due to the fact that transformers are very resource-hungry. Therefore, all selected models were either based on dense or convolution layers. The evaluated model architectures are listed in
Table 5.
4.3. Implementation Details
The training environment is a personal computer with an AMD Ryzen 5900X CPU, RTX 4090 GPU and 32GB RAM.
The super-resolution model was trained with the batch size of 4, cosine annealing learning rate scheduler, 600 k iterations with a minimum learning rate of 1 × 10−7. The starting learning rate was equal to 1 × 10−4. For the optimizer, we used Adam with a weight decay of 1 × 10−3.
The classification model was trained with a batch size of 32, cross-entropy loss for 600 epochs, and an Adam optimizer with fixed learning rate of 2 × 10−5.
4.4. Results and Discussion of Improved Super-Resolution Method
All of the results that we captured during validation of trained models with different discriminators are listed in
Table 6.
In
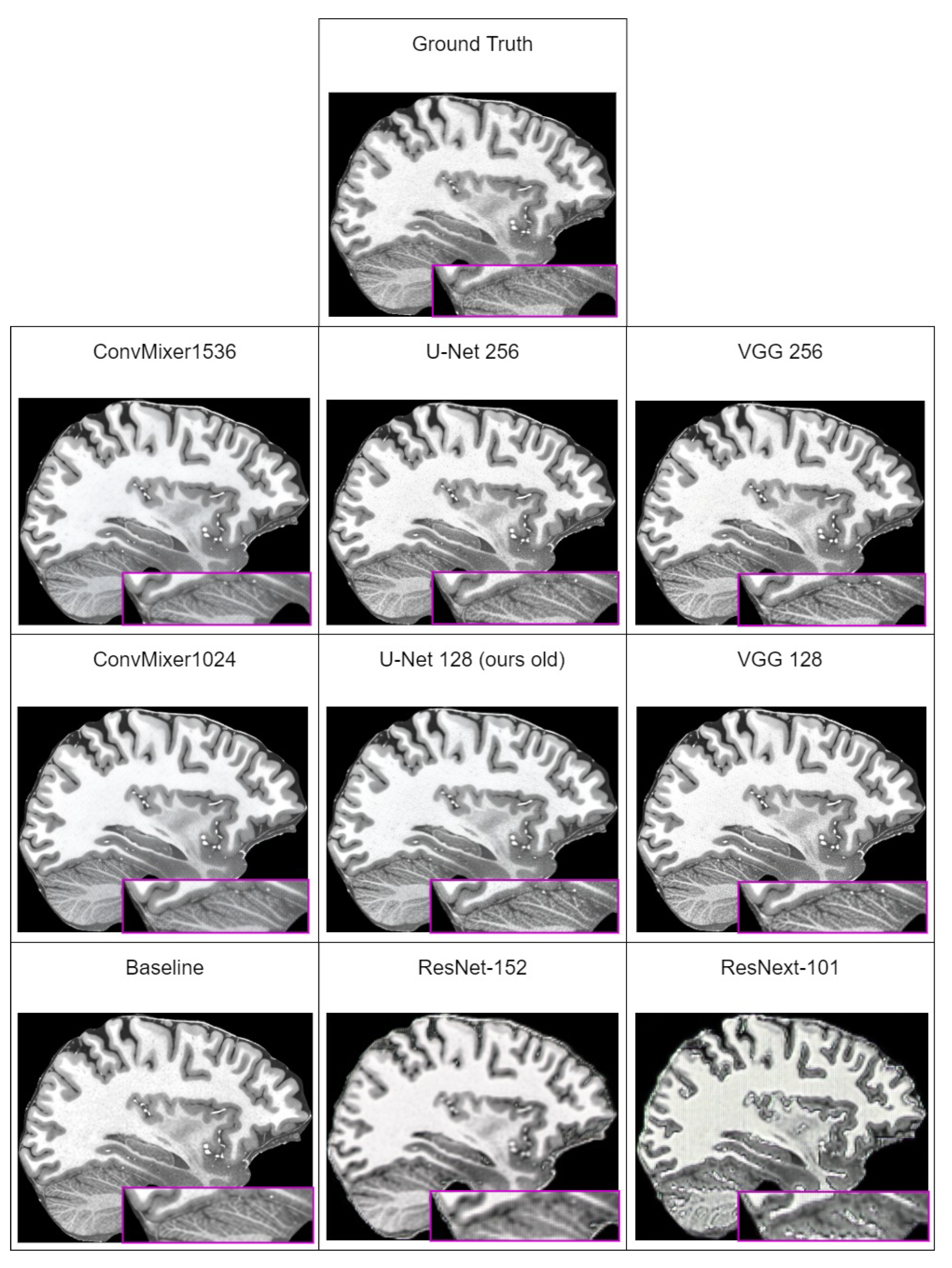
Table 6, we can see that the best perceptual quality results are achieved with the ConvMixer1536 model used as discriminator. However, looking at the subjective comparison in
Figure 4, it seems that the LPIPS metric does not capture artifacts that are present in images generated by ConvMixer models. Comparing subjectively generated images, images generated using U-Net or VGG are far more close to ground-truth images. This means that LPIPS is unable to correctly quantify perceptual quality of generated images. Similar remarks were made by other researchers, for example, those in [
78] (which investigated why artifacts appear and how to reduce them) that all currently used perceptual quality metrics are unable to capture existence of these artifacts in the generated images as a decrease in the metric score.
Excluding the fact that LPIPS does not capture artifacts, and therefore, results with ConvMixers are not subjectively best, new methodology improvements increased all of the metric values over the last iteration. The best overall result is achieved with the U-Net discriminator, which uses 256 input features.
4.5. Results and Discussion of Detection of MCI Task
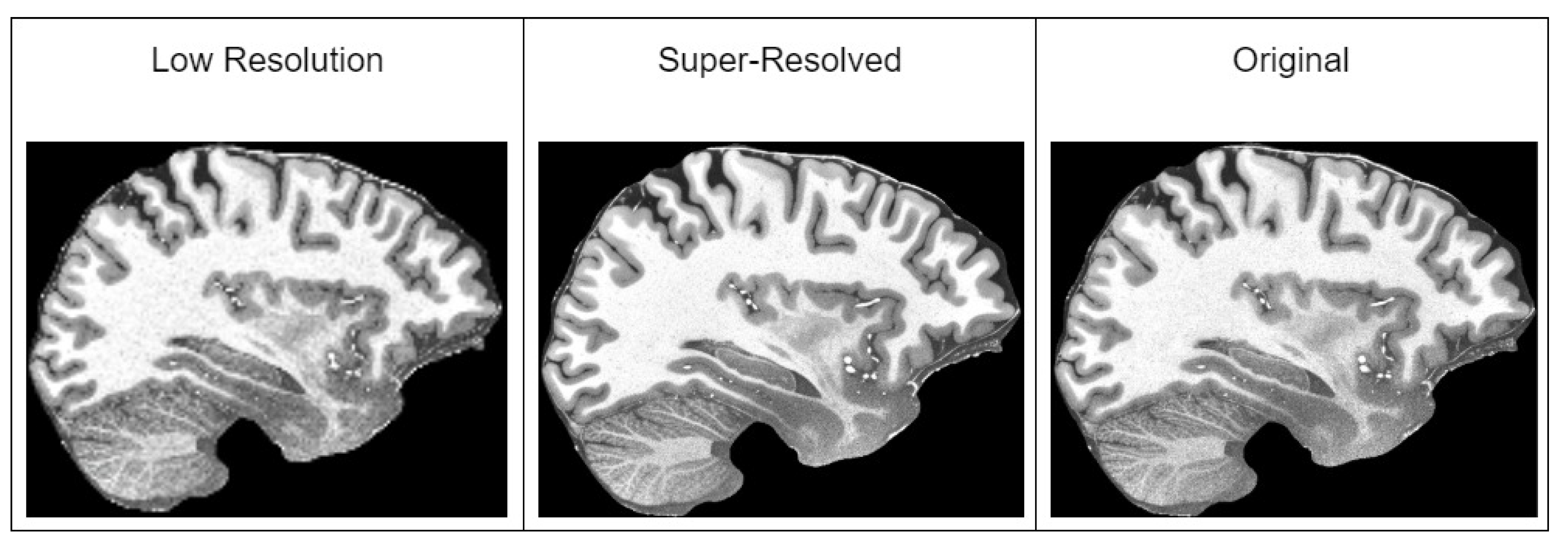
Preparing a third dataset required us to use our new methodology to upscale images into 1024 × 1024 resolution. Initial upscaling finding showed us that we faced a domain shift problem, where our developed model performed poorly on a different dataset used in training. We used the ultra-high-resolution MRI dataset “human phantom” [
52]. Our model subjectively was generating good results on the OASIS-4 dataset, but when we tried to run it against ADNI dataset, we found that generated images in some cases contain what we could call “black spot” artifacts
Figure 5. This is a typical generalization problem, when the dataset used in real-life usually differs from the one used during training. The best solution in our case is to expose the model to the new data during training using fine-tuning—taking the already-trained model and re-training it with the new data added to the dataset.
The first step was to upscale all ADNI dataset images and then manually pick those that did not contain “black spot” artifacts, then add those images to the original dataset and fine-tune the already-trained model. After training, the model was able to generate images without “black spot” artifacts.
The second step was to train MCI detection models with three prepared datasets. Validation results are listed in
Table 7.
Across a majority of trained models, there were big differences between sensitivity and specificity metrics, which means that models tended to overfit the data. However, in the sagittal and coronal planes, ConvMixer reached the best overall accuracy in the detection of MCI. In the axial plane, the best model was EfficientNet.
The next step was to validate the models against dataset with augmentation techniques. The results are listed in
Table 8.
The overall improvement using augmentation was on average around 5%. Here again, ConvMixer showed a lead in the sagittal and coronal planes, whereas on the axial plane, it fell shortly behind AlexNet. The last step to verify the effect of super-resolution on the detection of MCI was to validate models on the third dataset, which used super-resolution and all the augmentation techniques that the second dataset used. The validation results are listed in
Table 9.
Comparing results between the second dataset and third, it is obvious that the super-resolution methodology has improved the stability of models, because all models show a small difference between sensitivity and specificity. Additionally, all models across the table show performance improvements of 1–8%, on average 4%, which means that our proposed methodology has a positive effect on the performance of models in the MCI detection task. What is interesting is that in the sagittal and coronal planes with super-resolution, ResNet is showing the best results. This may be due to the fact that the third dataset is using higher-quality images, which yields more features, and it is possible that ResNet residual connections allow the model to retain more important features that are contributing to the accuracy of prediction.
5. Discussion and Conclusions
This study introduces a novel advancement in the detection of mild cognitive impairment (MCI) by applying super-resolution techniques to structural MRI images and optimizing deep learning models using a Pareto optimal Markov blanket (POMB). This approach notably enhances the perceptual quality of MRI images, which subsequently improves the accuracy of various state-of-the-art classifiers in identifying MCI. An improvement in detection accuracy ranging from 1–4% was observed, underscoring the efficacy of super-resolution in enhancing diagnostic models.
The incorporation of a POMB for hyperparameter optimization emerges as a key innovation, streamlining the exploration of complex hyperparameter spaces by focusing on parameters that impact the target variable, either directly or indirectly. This strategy not only accelerates the optimization process but also significantly mitigates the risk of overfitting by ensuring a balance between model complexity and performance. As a result, models demonstrate robustness and generalizability across different datasets, a critical advantage in medical diagnostics.
An important insight from this research is the impact of discriminator choice in generative adversarial network (GAN) setups on the perceptual quality of super-resolved images. The study’s comparison reveals that discriminators like VGG and U-Net produce significantly different outcomes, with U-Net marginally superior in PSNR and SSIM metrics. This highlights the profound influence of discriminator selection on both subjective and objective image quality.
A notable discovery pertains to the limitations of the learned perceptual image patch similarity (LPIPS) metric. Despite indicating high perceptual quality for images generated by ConvMixer models, subjective assessments contradicted these findings, revealing poor quality. This discrepancy suggests a pressing need for a new metric capable of accurately detecting "checkerboard" artifacts and properly quantifying perceptual quality differences.
In conclusion, this study advances the field of medical imaging and MCI detection, demonstrating the potent application of super-resolution processing and the crucial role of hyperparameter optimization and discriminator selection in creating accurate and reliable diagnostic models. The findings advocate for ongoing research into more effective perceptual quality metrics, further enhancing the utility of super-resolution in medical diagnostics.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




