

Intracerebral Hemorrhage Prognosis Classification via Joint-Attention Cross-Modal Network

 ,
,
Abstract
1. Introduction
- (1)
- We introduce a cross-modal loss function that accounts for the intrinsic correlation between the disparate data modalities.
- (2)
- We incorporate clinical data to enrich the model’s comprehension and enhance ICH prognosis accuracy.
- (3)
- Our fusion model incorporates a joint-attention mechanism, effectively facilitating the extraction of more salient and comprehensive fusion features.
2. Materials and Methods
2.1. Problem Formalization
2.2. Patient Population
2.3. Data Acquisition
2.4. ICH-Net Architecture
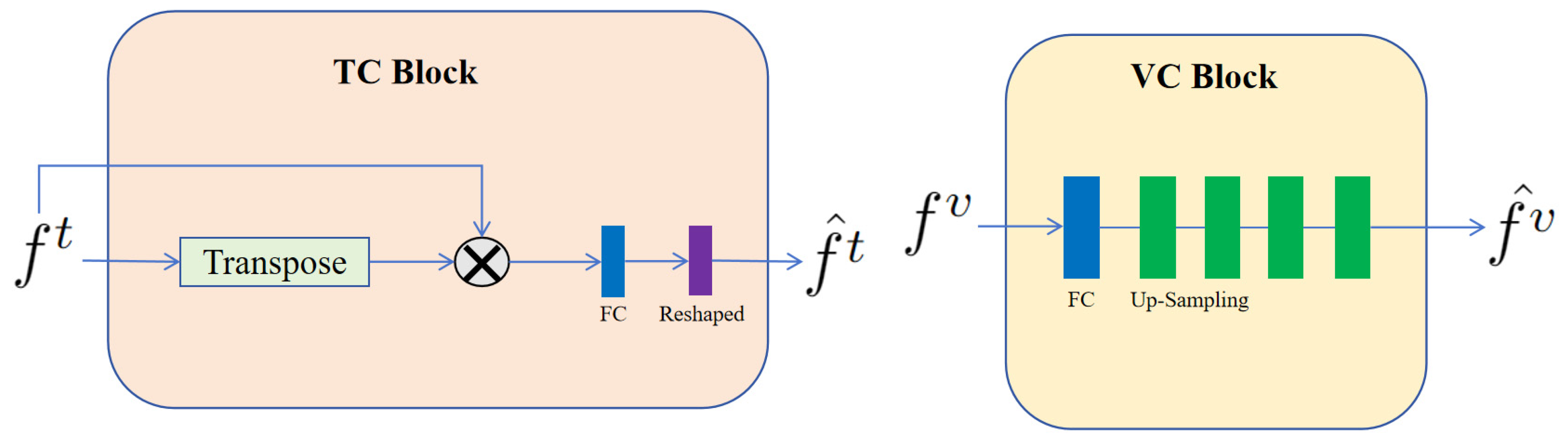
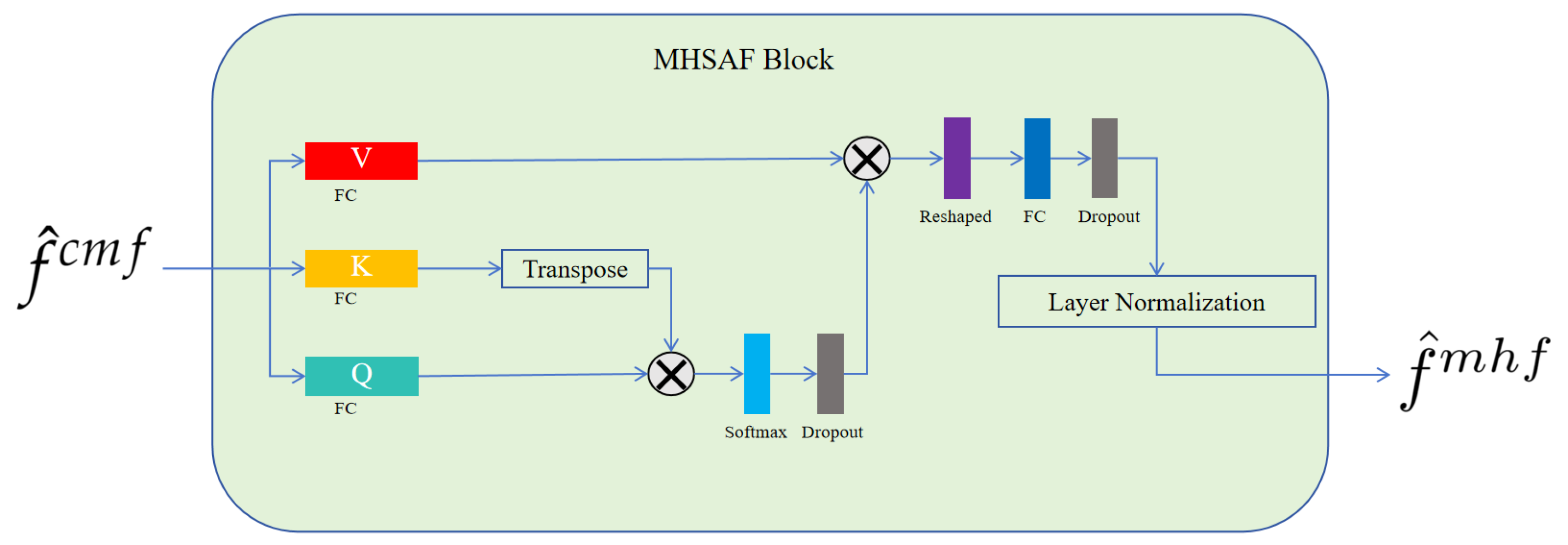
2.5. The Detail Blocks
2.6. Loss Function
3. Results
3.1. Data Pretreatment
3.2. Experiments
3.2.1. Comparative Experiments
- (1)
- Multimodal Information Fusion: Our model incorporated a CMF loss function, which effectively harnessed the intrinsic correlations between various modalities. By synergistically integrating CT images with clinical data, our model achieved a more holistic understanding of the tasks at hand, consequently enhancing its overall performance.
- (2)
- Feature Fusion Mechanism: Our CMAF module employed a cross-modal attention mechanism designed to extract salient and comprehensive fusion features. This method facilitated a more discerning aggregation of information from multiple sources, enhancing the representational power of the fused features.
- (3)
- Utilization of Advanced Pre-trained Models: Our framework incorporated two distinct modules for feature extraction—a visual feature extraction module utilizing the ResNet50 model and a text feature extraction module employing the BioClinicalBERT model. These pre-trained models were instrumental in enhancing the capability of our system to extract more robust and nuanced features. By leveraging the extensive knowledge encoded within these pre-trained models, our approach achieved superior feature extraction performance.
3.2.2. Ablation Experiment
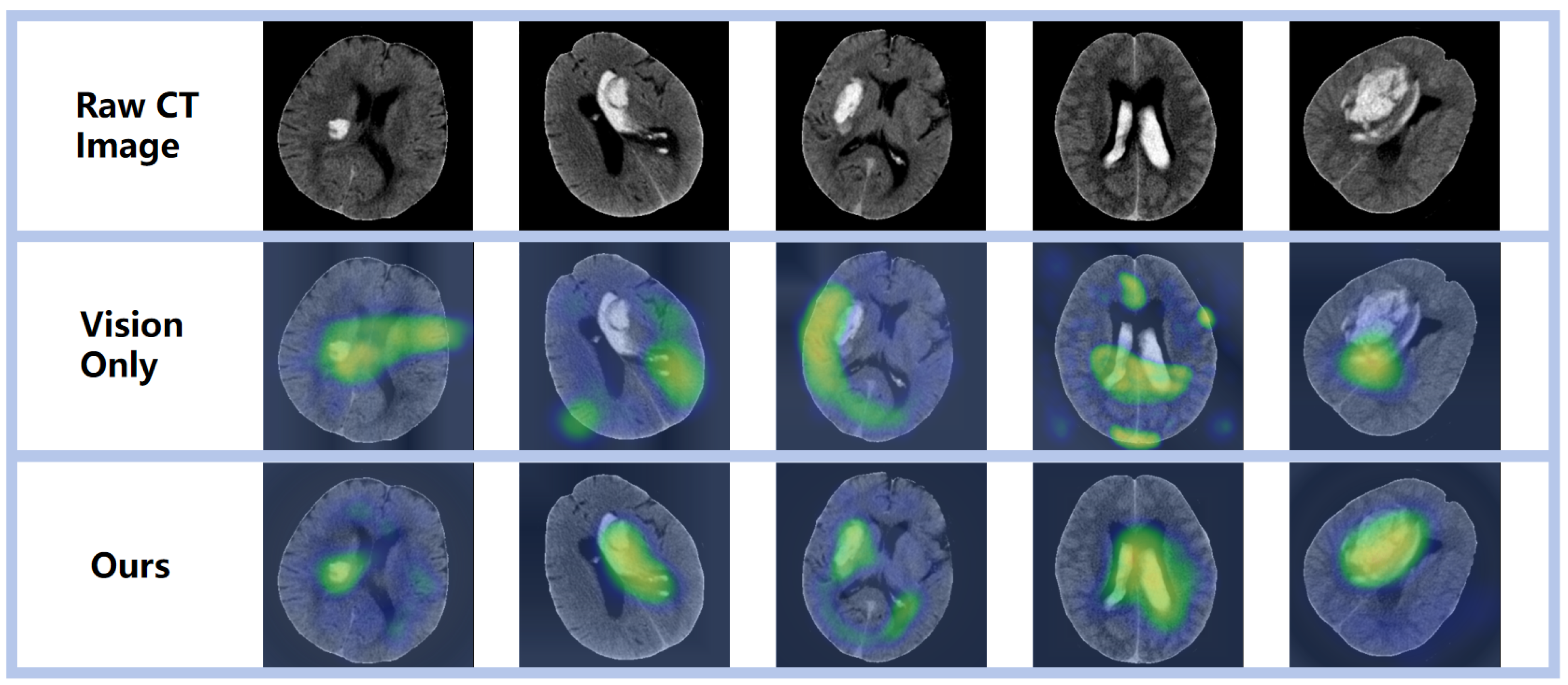
3.3. Visualization Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jakubovic, R.; Aviv, R.I. Intracerebral Hemorrhage; towards physiological imaging of hemorrhage risk in acute and chronic bleeding. Front. Neurol. 2012, 3, 24754. [Google Scholar] [CrossRef]
- Toffali, M.; Carbone, F.; Fainardi, E.; Morotti, A.; Montecucco, F.; Liberale, L.; Padovani, A. Secondary prevention after intracerebral haemorrhage. Eur. J. Clin. Investig. 2023, 53, e13962. [Google Scholar] [CrossRef]
- Øie, L.R.; Madsbu, M.A.; Solheim, O.; Jakola, A.S.; Giannadakis, C.; Vorhaug, A.; Padayachy, L.; Jensberg, H.; Dodick, D.; Salvesen, Ø.; et al. Functional outcome and survival following spontaneous intracerebral hemorrhage: A retrospective population-based study. Brain Behav. 2018, 8, e01113. [Google Scholar] [CrossRef]
- Hemphill III, J.C.; Greenberg, S.M.; Anderson, C.S.; Becker, K.; Bendok, B.R.; Cushman, M.; Fung, G.L.; Goldstein, J.N.; Macdonald, R.L.; Mitchell, P.H.; et al. Guidelines for the management of spontaneous intracerebral hemorrhage: A guideline for healthcare pr fessionals from the American Heart Association/American Stroke Association. Stroke 2015, 46, 2032–2060. [Google Scholar] [CrossRef]
- Teasdale, G.; Maas, A.; Lecky, F.; Manley, G.; Stocchetti, N.; Murray, G. The Glasgow Coma Scale at 40 years: Standing the test of time. Lancet Neurol. 2014, 13, 844–854. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, L.; Wang, L.; Qin, Y.; Cai, J. Black hole sign on noncontrast computed tomography in predicting hematoma expansion in patients with intracerebral hemorrhage: A meta-analysis. Curr. Med. Imaging 2020, 16, 878–886. [Google Scholar] [CrossRef]
- Cire ̧san, D.C.; Giusti, A.; Gambardella, L.M.; Schmidhuber, J. Mitosis detection in breast cancer histology images with deep neural networks. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2013: 16th International Conference, Nagoya, Japan, 22–26 September 2013, Proceedings, Part II 16; Springer: Berlin/Heidelberg, Germany, 2013; pp. 411–418. [Google Scholar]
- Litjens, G.; Sánchez, C.I.; Timofeeva, N.; Hermsen, M.; Nagtegaal, I.; Kovacs, I.; Hulsbergen-Van De Kaa, C.; Bult, P.; Van Ginneken, B.; Van Der Laak, J. Deep learning as a tool for increased accuracy and efficiency of histopathological diagnosis. Sci. Rep. 2016, 6, 26286. [Google Scholar] [CrossRef]
- El Refaee, E.; Ali, T.M.; Al Menabbawy, A.; Elfiky, M.; El Fiki, A.; Mashhour, S.; Harouni, A. Machine learning in action: Revolutionizing intracranial hematoma detection and patient transport decision-making. J. Neurosci. Rural Pract. 2024, 15, 62. [Google Scholar] [CrossRef]
- Huang, L.; Lin, Y.; Cao, P.; Zou, X.; Qin, Q.; Lin, Z.; Liang, F.; Li, Z. Automated detection and segmentation of pleural effusion on ultrasound images using an Attention U-net. J. Appl. Clin. Med. Phys. 2024, 25, e14231. [Google Scholar] [CrossRef]
- Wang, C.; Deng, X.; Yu, L.; Kuang, Z.; Ma, H.; Hua, Y.; Liang, B. Data fusion framework for the prediction of early hematoma expansion based on cnn. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 169–173. [Google Scholar]
- Pérez del Barrio, A.; Esteve Domínguez, A.S.; Menéndez Fernández-Miranda, P.; Sanz Bellón, P.; Rodríguez González, D.; Lloret Iglesias, L.; Marqués Fraguela, E.; González Mandly, A.A.; Vega, J.A. A deep learning model for prognosis prediction after intracranial hemorrhage. J. Neuroimaging 2023, 33, 218–226. [Google Scholar] [CrossRef]
- Louizos, C.; Shalit, U.; Mooij, J.M.; Sontag, D.; Zemel, R.; Welling, M. Causal effect inference with deep latent-variable models. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Wu, P.A.; Fukumizu, K. Identifying and Estimating Causal Effects under Weak Overlap by Generative Prognostic Model 2021. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual, 6–14 December 2021. [Google Scholar]
- Lee, C.; Van der Schaar, M. A variational information bottleneck approach to multiomics data integration. In Proceedings of the International Conference on Artificial Intelligence and Statistics; PMLR: London, UK, 2021; pp. 1513–1521. [Google Scholar]
- Shi, Y.; Paige, B.; Torr, P. Variational mixture-of-experts autoencoders for multi-modal deep generative models. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Yoon, J.; Jordon, J.; Van Der Schaar, M. GANITE: Estimation of individualized treatment effects using generative adversarial nets. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Nawabi, J.; Kniep, H.; Elsayed, S.; Friedrich, C.; Sporns, P.; Rusche, T.; Böhmer, M.; Morotti, A.; Schlunk, F.; Dührsen, L.; et al. Imaging-based outcome prediction of acute intracerebral hemorrhage. Transl. Stroke Res. 2021, 12, 958–967. [Google Scholar] [CrossRef]
- Gong, K.; Dai, Q.; Wang, J.; Shi, T.; Huang, S.; Wang, Z. Unified ICH quantification and prognosis prediction in NCCT images using a multi-task interpretable network. Front. Neurosci. 2023, 17, 1118340. [Google Scholar] [CrossRef]
- Asif, M.; Shah, M.A.; Khattak, H.A.; Mussadiq, S.; Ahmed, E.; Nasr, E.A.; Rauf, H.T. Intracranial hemorrhage detection using parallel deep convolutional models and boosting mechanism. Diagnostics 2023, 13, 652. [Google Scholar] [CrossRef]
- Xie, Y.; Zhang, J.; Xia, Y.; Wu, Q. Unimiss: Universal medical self-supervised learning via breaking dimensionality barrier. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 558–575. [Google Scholar]
- Shan, X.; Li, X.; Ge, R.; Wu, S.; Elazab, A.; Zhu, J.; Zhang, L.; Jia, G.; Xiao, Q.; Wan, X.; et al. GCS-ICHNet: Assessment of Intracerebral Hemorrhage Prognosis using Self-Attention with Domain Knowledge Integration. In Proceedings of the 2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Istanbul, Turkiye, 5–8 December 2023; pp. 2217–2222. [Google Scholar]
- Alsentzer, E.; Murphy, J.R.; Boag, W.; Weng, W.H.; Jin, D.; Naumann, T.; McDermott, M. Publicly available clinical BERT embeddings. arXiv 2019, arXiv:1904.03323. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Luo, X.; Chen, X.; He, X.; Qing, L.; Tan, X. CMAFGAN: A Cross-Modal Attention Fusion based Generative Adversarial Network for attribute word-to-face synthesis. Knowl. Based Syst. 2022, 255, 109750. [Google Scholar] [CrossRef]
- Jiang, D.; Ye, M. Cross-Modal Implicit Relation Reasoning and Aligning for Text-to-Image Person Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 2787–2797. [Google Scholar]
- Ganti, L.; Shameem, M.; Houck, J.; Stead, T.S.; Stead, T.G.; Cesarz, T.; Mirajkar, A. Gender disparity in stoke: Women have higher ICH scores than men at initial ED presentation for intracerebral hemorrhage. J. Natl. Med. Assoc. 2023, 115, 186–190. [Google Scholar] [CrossRef]
- Broberg, E.; Hjalmarsson, C.; Setalani, M.; Milenkoski, R.; Andersson, B. Sex Differences in Treatment and Prognosis of Acute Intracerebral Hemorrhage. J. Women’s Health 2023, 32, 102–108. [Google Scholar] [CrossRef]
- Foschi, M.; D’Anna, L.; Gabriele, C.; Conversi, F.; Gabriele, F.; De Santis, F.; Orlandi, B.; De Santis, F.; Ornello, R.; Sacco, S. Sex Differences in the Epidemiology of Intracerebral Hemorrhage over 10 Years in a Population-Based Stroke Registry. J. Am. Heart Assoc. 2024, 13, e032595. [Google Scholar] [CrossRef]
- Li, Z.Q.; Bu, X.Q.; Cheng, J.; Deng, L.; Lv, X.N.; Wang, Z.J.; Hu, X.; Yang, T.N.; Yin, H.; Liu, X.Y.; et al. Impact of early cognitive impairment on outcome trajectory in patients with intracerebral hemorrhage. Ann. Clin. Transl. Neurol. 2024, 11, 368–376. [Google Scholar] [CrossRef]
- An, S.J.; Kim, T.J.; Yoon, B.W. Epidemiology, risk factors, and clinical features of intracerebral hemorrhage: An update. J. Stroke 2017, 19, 3. [Google Scholar] [CrossRef]
- Teo, K.C.; Fong, S.M.; Leung, W.C.; Leung, I.Y.; Wong, Y.K.; Choi, O.M.; Yam, K.K.; Lo, R.C.; Cheung, R.T.; Ho, S.L.; et al. Location-specific hematoma volume cutoff and clinical outcomes in intracerebral hemorrhage. Stroke 2023, 54, 1548–1557. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ACC (%) | Recall (%) | Precision (%) | AUC |
|---|---|---|---|---|
| DL-Based Method (3D) [12] | 81.02 | 78.52 | 83.31 | 0.9141 |
| Image-Based Method (2D) [18] | 74.23 | 67.11 | 75.98 | 0.6933 |
| Multi-Task Method (3D) [19] | 85.42 | 79.86 | 89.80 | 0.8998 |
| GCS-ICH-Net (2D) [22] | 85.08 | 81.88 | 87.25 | 0.8590 |
| UniMiSS (2D + 3D) [21] | 82.03 | 78.52 | 87.59 | 0.8275 |
| ICH-Net (Our study) | 87.77 | 82.01 | 88.23 | 0.9168 |
| Methods | ACC (%) | Recall (%) | Precision (%) | AUC |
|---|---|---|---|---|
| Vision-Only | 76.59 | 73.10 | 80.84 | 0.8234 |
| Text-Only | 69.15 | 65.10 | 71.11 | 0.7534 |
| ICH-Net (Our study) | 87.77 | 82.01 | 88.23 | 0.9168 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, M.; Fu, X.; Jin, H.; Yu, X.; Xu, G.; Ma, Z.; Pan, C.; Liu, B. Intracerebral Hemorrhage Prognosis Classification via Joint-Attention Cross-Modal Network. Brain Sci. 2024, 14, 618. https://doi.org/10.3390/brainsci14060618
Xu M, Fu X, Jin H, Yu X, Xu G, Ma Z, Pan C, Liu B. Intracerebral Hemorrhage Prognosis Classification via Joint-Attention Cross-Modal Network. Brain Sciences. 2024; 14(6):618. https://doi.org/10.3390/brainsci14060618
Chicago/Turabian StyleXu, Manli, Xianjun Fu, Hui Jin, Xinlei Yu, Gang Xu, Zishuo Ma, Cheng Pan, and Bo Liu. 2024. "Intracerebral Hemorrhage Prognosis Classification via Joint-Attention Cross-Modal Network" Brain Sciences 14, no. 6: 618. https://doi.org/10.3390/brainsci14060618
APA StyleXu, M., Fu, X., Jin, H., Yu, X., Xu, G., Ma, Z., Pan, C., & Liu, B. (2024). Intracerebral Hemorrhage Prognosis Classification via Joint-Attention Cross-Modal Network. Brain Sciences, 14(6), 618. https://doi.org/10.3390/brainsci14060618