
Machine Learning Classification of Patients with Amnestic Mild Cognitive Impairment and Non-Amnestic Mild Cognitive Impairment from Written Picture Description Tasks


Abstract
1. Background
2. Methods
2.1. Participants
2.2. Written Picture Description Task
2.3. Machine Learning Process
2.4. Analysis of Narrative Speech
2.5. Semantic Measures from BERT
2.6. Addressing Imbalance and Cross-Validation
2.7. Model Evaluation and Selection
2.8. Hyperparameter Tuning and Model Comparison
3. Results
- Accuracy (0.90 for most models) reflects the ML model’s overall correctness in classifying the MCI type.
- F1 score balances precision and recall, with values around 0.70–0.72, indicating a good balance between false positives and false negatives.
- Precision (0.74–0.75) measures the proportion of correctly identified positive cases among all positive calls made by the model.
- Recall (ranging from 0.66 to 0.70) indicates the model’s ability to identify all actual positive cases.
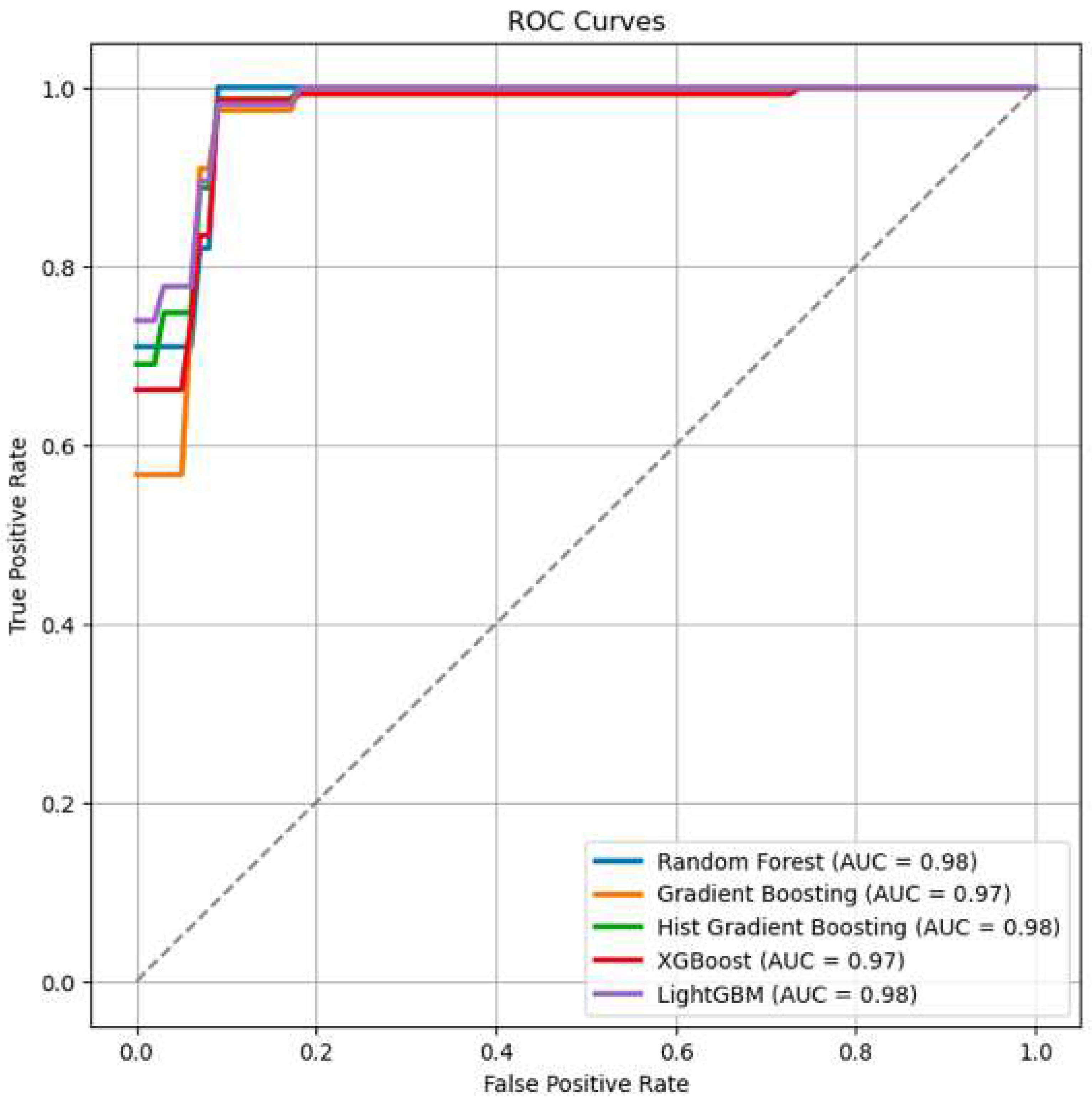
- ROC/AUC (between 0.97 and 0.98) reflects the model’s ability to distinguish between the two classes across various thresholds, with values close to 1 indicating excellent performance.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alzheimer’s Association. 2019 Alzheimer’s disease facts and figures. Alzheimer’s Dement. 2019, 15, 321–387. [Google Scholar] [CrossRef]
- Ong, S.C.; Tay, L.J.; Ng, T.; Parumasivam, T. Economic Burden of Alzheimer’s Disease: A Systematic Review. Value Health Reg. Issues 2024, 40, 1–12. [Google Scholar]
- Zissimopoulos, J.; Crimmins, E.; St Clair, P. The value of delaying Alzheimer’s disease onset. Forum Health Econ. Policy 2015, 18, 25–39. [Google Scholar]
- Petersen, R.C.; Smith, G.E.; Waring, S.C.; Ivnik, R.J.; Tangalos, E.G.; Kokmen, E. Mild cognitive impairment: Clinical characterization and outcome. Arch. Neurol. 1999, 56, 303–308. [Google Scholar] [CrossRef] [PubMed]
- López-Sanz, D.; Bruña, R.; Garcés, P.; Martín-Buro, M.C.; Walter, S.; Delgado, M.L.; Montenegro, M.; López Higes, R.; Marcos, A.; Maestú, F. Functional connectivity disruption in subjective cognitive decline and mild cognitive impairment: A common pattern of alterations. Front. Aging Neurosci. 2017, 9, 109. [Google Scholar] [CrossRef]
- Villemagne, V.L.; Chételat, G. Neuroimaging biomarkers in Alzheimer’s disease and other dementias. Ageing Res. Rev. 2016, 30, 4–16. [Google Scholar] [CrossRef] [PubMed]
- Tabatabaei-Jafari, H.; Shaw, M.E.; Cherbuin, N. Cerebral atrophy in mild cognitive impairment: A systematic review with meta-analysis. Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2015, 1, 487–504. [Google Scholar] [CrossRef]
- Gauthier, S.; Reisberg, B.; Zaudig, M.; Petersen, R.C.; Ritchie, K.; Broich, K.; Belleville, S.; Brodaty, H.; Bennett, D.; Chertkow, H.; et al. Mild cognitive impairment. Lancet 2006, 367, 1262–1270. [Google Scholar] [CrossRef] [PubMed]
- Winblad, B.; Palmer, K.; Kivipelto, M.; Jelic, V.; Fratiglioni, L.; Wahlund, L.O.; Nordberg, A.; Bäckman, L.; Albert, M.; Almkvist, O.; et al. Mild cognitive impairment–beyond controversies, towards a consensus: Report of the International Working Group on Mild Cognitive Impairment. J. Intern. Med. 2004, 256, 240–246. [Google Scholar] [CrossRef]
- Mitchell, A.J.; Shiri-Feshki, M. Rate of progression of mild cognitive impairment to dementia–meta-analysis of 41 robust inception cohort studies. Acta Psychiatr. Scand. 2009, 119, 252–265. [Google Scholar] [CrossRef]
- Ansart, M.; Epelbaum, S.; Bassignana, G.; Bône, A.; Bottani, S.; Cattai, T.; Couronné, R.; Faouzi, J.; Koval, I.; Louis, M. Predicting the progression of mild cognitive impairment using machine learning: A systematic, quantitative and critical review. Med. Image Anal. 2021, 67, 101848. [Google Scholar] [CrossRef]
- Iraniparast, M.; Shi, Y.; Wu, Y.; Zeng, L.; Maxwell, C.J.; Kryscio, R.J.; St John, P.D.; SantaCruz, K.S.; Tyas, S.L. Cognitive reserve and mild cognitive impairment: Predictors and rates of reversion to intact cognition vs. progression to dementia. Neurology 2022, 98, e1114–e1123. [Google Scholar] [CrossRef]
- Giau, V.V.; Bagyinszky, E.; An, S.S.A. Potential fluid biomarkers for the diagnosis of mild cognitive impairment. Int. J. Mol. Sci. 2019, 20, 4149. [Google Scholar] [CrossRef]
- Busse, A.; Angermeyer, M.C.; Riedel-Heller, S.G. Progression of mild cognitive impairment to dementia: A challenge to current thinking. Br. J. Psychiatry 2006, 189, 399–404. [Google Scholar] [CrossRef] [PubMed]
- Guo, T.; Korman, D.; Baker, S.L.; Landau, S.M.; Jagust, W.J. Longitudinal Cognitive and Biomarker Measurements Support a Unidirectional Pathway in Alzheimer’s Disease Pathophysiology. Biol. Psychiatry 2021, 89, 786–794. [Google Scholar] [CrossRef]
- Roberts, R.O.; Knopman, D.S.; Mielke, M.M.; Cha, R.H.; Pankratz, V.S.; Christianson, T.J.H.; Geda, Y.E.; Boeve, B.F.; Ivnik, R.J.; Tangalos, E.G.; et al. Higher risk of progression to dementia in mild cognitive impairment cases who revert to normal. Neurology 2014, 82, 317–325. [Google Scholar] [CrossRef]
- Glynn, K.; O’Callaghan, M.; Hannigan, O.; Bruce, I.; Gibb, M.; Coen, R.; Green, E.; ALawlor, B.; Robinson, D. Clinical utility of mild cognitive impairment subtypes and number of impaired cognitive domains at predicting progression to dementia: A 20-year retrospective study. Int. J. Geriatr. Psychiatry 2021, 36, 31–37. [Google Scholar] [CrossRef] [PubMed]
- Pelka, O.; Friedrich, C.M.; Nensa, F.; Mönninghoff, C.; Bloch, L.; Jöckel, K.-H.; Schramm, S.; Sanchez Hoffmann, S.; Winkler, A.; Weimar, C. Sociodemographic data and APOE-ε4 augmentation for MRI-based detection of amnestic mild cognitive impairment using deep learning systems. PLoS ONE 2020, 15, e0236868. [Google Scholar] [CrossRef]
- Yeung, M.K.; Chau, A.K.-Y.; Chiu, J.Y.-C.; Shek, J.T.-L.; Leung, J.P.-Y.; Wong, T.C.-H. Differential and subtype-specific neuroimaging abnormalities in amnestic and nonamnestic mild cognitive impairment: A systematic review and meta-analysis. Ageing Res. Rev. 2022, 80, 101675. [Google Scholar] [CrossRef] [PubMed]
- Qu, Y.; Ma, Y.-H.; Huang, Y.-Y.; Ou, Y.-N.; Shen, X.-N.; Chen, S.-D.; Dong, Q.; Tan, L.; Yu, J.-T. Blood biomarkers for the diagnosis of amnestic mild cognitive impairment and Alzheimer’s disease: A systematic review and meta-analysis. Neurosci. Biobehav. Rev. 2021, 128, 479–486. [Google Scholar] [CrossRef]
- van Maurik, I.S.; Zwan, M.D.; Tijms, B.M.; Bouwman, F.H.; Teunissen, C.E.; Scheltens, P.; Wattjes, M.P.; Barkhof, F.; Berkhof, J.; van der Flier, W.M.; et al. Interpreting biomarker results in individual patients with mild cognitive impairment in the Alzheimer’s biomarkers in daily practice (ABIDE) project. JAMA Neurol. 2017, 74, 1481–1491. [Google Scholar] [CrossRef]
- Handels, R.L.H.; Vos, S.J.B.; Kramberger, M.G.; Jelic, V.; Blennow, K.; van Buchem, M.; van der Flier, W.; Freund-Levi, Y.; Hampel, H.; Rikkert, M.O. Predicting progression to dementia in persons with mild cognitive impairment using cerebrospinal fluid markers. Alzheimer’s Dement. 2017, 13, 903–912. [Google Scholar] [CrossRef] [PubMed]
- van Harten, A.C.; Visser, P.J.; Pijnenburg, Y.A.L.; Teunissen, C.E.; Blankenstein, M.A.; Scheltens, P.; van der Flier, W.M. Cerebrospinal fluid Aβ42 is the best predictor of clinical progression in patients with subjective complaints. Alzheimer’s Dement. 2013, 9, 481–487. [Google Scholar] [CrossRef] [PubMed]
- Davatzikos, C.; Bhatt, P.; Shaw, L.M.; Batmanghelich, K.N.; Trojanowski, J.Q. Prediction of MCI to AD conversion, via MRI, CSF biomarkers, and pattern classification. Neurobiol. Aging 2011, 32, 2322-e19. [Google Scholar] [CrossRef] [PubMed]
- Snyder, P.J.; Lim, Y.Y.; Schindler, R.; Ott, B.R.; Salloway, S.; Daiello, L.; Getter, C.; Gordon, C.M.; Maruff, P. Microdosing of scopolamine as a “cognitive stress test”: Rationale and test of a very low dose in an at-risk cohort of older adults. Alzheimer’s Dement. 2014, 10, 262–267. [Google Scholar] [CrossRef] [PubMed]
- Fleming, V.B.; Harris, J.L. Complex discourse production in mild cognitive impairment: Detecting subtle changes. Aphasiology 2008, 22, 729–740. [Google Scholar] [CrossRef]
- Hayes, J.; Flower, L. Identifying the Organization of Writing Processes. In Cognitive Processes in Writing; Gregg, L.W., Steinberg, E.R., Eds.; Lawrence Erlbaum Associates: Hillsdale, NJ, USA, 1980; pp. 3–30. [Google Scholar]
- Kim, H.; Walker, A.; Shea, J.; Hillis, A.E. Written Discourse Task Helps to Identify Progression from Mild Cognitive Impairment to Dementia. Dement. Geriatr. Cogn. Disord. 2021, 50, 446–453. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Obermeyer, J.; Wiley, R.W. Written discourse in diagnosis for acquired neurogenic communication disorders: Current evidence and future directions. Front. Hum. Neurosci. 2024, 17, 1264582. [Google Scholar] [CrossRef] [PubMed]
- Ulatowska, H.K.; Olness, G.S.; Williams, L.J. Coherence of narratives in aphasia. Brain Lang. 2004, 91, 42–43. [Google Scholar] [CrossRef]
- Ulatowska, H.K.; Streit Olness, G.; Samson, A.M.; Keebler, M.W.; Goins, K.E. On the nature of personal narratives of high quality. Adv. Speech Lang. Pathol. 2004, 6, 3–14. [Google Scholar] [CrossRef]
- Goodglass, H.; Kaplan, E.; Barresi, B. BDAE-3: Boston Diagnostic Aphasia Examination, 3rd ed.; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2001. [Google Scholar]
- Themistocleous, C.; Neophytou, K.; Rapp, B.; Tsapkini, K. A tool for automatic scoring of spelling performance. J. Speech Lang. Hear. Res. 2020, 63, 4179–4192. [Google Scholar] [CrossRef]
- Themistocleous, C.; Eckerström, M.; Kokkinakis, D. Voice quality and speech fluency distinguish individuals with Mild Cognitive Impairment from Healthy Controls. PLoS ONE 2020, 15, e0236009. [Google Scholar] [CrossRef] [PubMed]
- Themistocleous, C.; Eckerström, M.; Kokkinakis, D. Identification of Mild Cognitive Impairment From Speech in Swedish Using Deep Sequential Neural Networks. Front. Neurol. 2018, 9, 975. [Google Scholar] [CrossRef] [PubMed]
- Fraser, K.C.; Lundholm Fors, K.; Kokkinakis, D. Multilingual word embeddings for the assessment of narrative speech in mild cognitive impairment. Comput. Speech Lang. 2019, 53, 121–139. [Google Scholar] [CrossRef]
- Hernández-Domínguez, L.; Ratté, S.; Sierra-Martínez, G.; Roche-Bergua, A. Computer-based evaluation of Alzheimer’s disease and mild cognitive impairment patients during a picture description task. Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2018, 10, 260–268. [Google Scholar] [CrossRef] [PubMed]
- Fraser, K.C.; Lundholm Fors, K.; Eckerström, M.; Themistocleous, C.; Kokkinakis, D. Improving the Sensitivity and Specificity of MCI Screening with Linguistic Information. In Proceedings of the LREC 2018 Workshop “Resources and ProcessIng of Linguistic, Para-Linguistic and Extra-Linguistic Data from People with Various Forms of Cognitive/Psychiatric Impairments (RaPID-2)”, Miyazaki, Japan, 8 May 2018; pp. 19–26. [Google Scholar]
- König, A.; Satt, A.; Sorin, A.; Hoory, R.; Toledo-Ronen, O.; Derreumaux, A.; Manera, V.; Verhey, F.; Aalten, P.; Robert, P.H.; et al. Automatic speech analysis for the assessment of patients with predementia and Alzheimer’s disease. Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2015, 1, 112–124. [Google Scholar] [CrossRef]
- Calzà, L.; Gagliardi, G.; Rossini Favretti, R.; Tamburini, F. Linguistic features and automatic classifiers for identifying mild cognitive impairment and dementia. Comput. Speech Lang. 2021, 65, 101113. [Google Scholar] [CrossRef]
- López-de-Ipiña, K.; Solé-Casals, J.; Eguiraun, H.; Alonso, J.B.; Travieso, C.M.; Ezeiza, A.; Barroso, N.; Ecay-Torres, M.; Martinez-Lage, P.; Beitia, B. Feature selection for spontaneous speech analysis to aid in Alzheimer’s disease diagnosis: A fractal dimension approach. Comput. Speech Lang. 2015, 30, 43–60. [Google Scholar] [CrossRef]
- Toledo, C.M.; Aluísio, S.M.; Dos Santos, L.B.; Brucki, S.M.D.; Trés, E.S.; de Oliveira, M.O.; Mansur, L.L. Analysis of macrolinguistic aspects of narratives from individuals with Alzheimer’s disease, mild cognitive impairment, and no cognitive impairment. Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2018, 10, 31–40. [Google Scholar] [CrossRef] [PubMed]
- Clarke, N.; Barrick, T.R.; Garrard, P. A comparison of connected speech tasks for detecting early Alzheimer’s disease and mild cognitive impairment using natural language processing and machine learning. Front. Comput. Sci. 2021, 3, 634360. [Google Scholar] [CrossRef]
- Fraser, K.C.; Meltzer, J.A.; Graham, N.L.; Leonard, C.; Hirst, G.; Black, S.E.; Rochon, E. Automated classification of primary progressive aphasia subtypes from narrative speech transcripts. Cortex 2014, 55, 43–60. [Google Scholar] [CrossRef]
- Themistocleous, C.; Ficek, B.; Webster, K.; den Ouden, D.-B.; Hillis, A.E.; Tsapkini, K. Automatic subtyping of individuals with Primary Progressive Aphasia. bioRxiv 2020. bioRxiv:2020.04.04.025593. [Google Scholar] [CrossRef]
- Yan, J.H.; Rountree, S.; Massman, P.; Doody, R.S.; Li, H. Alzheimer’s disease and mild cognitive impairment deteriorate fine movement control. J. Psychiatr. Res. 2008, 42, 1203–1212. [Google Scholar] [CrossRef] [PubMed]
- Jack, C.R., Jr.; Bennett, D.A.; Blennow, K.; Carrillo, M.C.; Dunn, B.; Haeberlein, S.B.; Holtzman, D.M.; Jagust, W.; Jessen, F.; Karlawish, J. Research Framework: Toward a biological definition of Alzheimer’s disease. Alzheimers Dement. 2018, 14, 535–562. [Google Scholar] [CrossRef] [PubMed]
- Folstein, M.F.; Folstein, S.E.; McHugh, P.R. “Mini-mental state”: A practical method for grading the cognitive state of patients for the clinician. J. Psychiatr. Res. 1975, 12, 189–198. [Google Scholar] [CrossRef] [PubMed]
- Wechsler, D. WAIS-III: Wechsler Adult Intelligence Scale, 3rd ed.; The Psychological Corporation: Harcourt Brace & Company San Antonio: San Antonio, TX, USA, 1997. [Google Scholar]
- Rey, A. L’examen psychologique dans les cas d’encephalopathie traumatique. (Les problems.) The psychological examination in cases of traumatic encepholopathy. (Problem.). Arch. Psychol. 2014, 28, 215–285. [Google Scholar]
- Reitan, R.M.; Wolfson, D. A selective and critical review of neuropsychological deficits and the frontal lobes. Neuropsychol. Rev. 1994, 4, 161–198. [Google Scholar] [CrossRef] [PubMed]
- Trenerry, M.R.; Crosson, B.A.; DeBoe, J.; Leber, W.R. Stroop Neuropsychological Screening Test; Psychological Assessment Resources: Lutz, FL, USA, 1989. [Google Scholar]
- Themistocleous, C. Open Brain AI: An AI Research Platform. In Proceedings of the Huminfra Conference, Gothenburg, Sweden, 10–11 January 2024; Volodina, E., Bouma, G., Forsberg, M., Kokkinakis, D., Alfter, D., Fridlund, M., Eds.; Linköping Electronic Conference Proceedings: Gothenburg, Sweden, 2024; Volume 205, pp. 1–9. [Google Scholar]
- Themistocleous, C.; Webster, K.; Afthinos, A.; Tsapkini, K. Part of Speech Production in Patients With Primary Progressive Aphasia: An Analysis Based on Natural Language Processing. Am. J. Speech-Lang. Pathol. 2020, 30, 1–15. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:181004805. [Google Scholar]
- Menardi, G.; Torelli, N. Training and assessing classification rules with imbalanced data. Data Min. Knowl. Discov. 2014, 28, 92–122. [Google Scholar] [CrossRef]
- Torres, V.L.; Rosselli, M.; Loewenstein, D.A.; Curiel, R.E.; Uribe, I.V.; Lang, M.; Arruda, F.; Penate, A.; Vaillancourt, D.E.; Greig, M.T.; et al. Types of Errors on a Semantic Interference Task in Mild Cognitive Impairment and Dementia. Neuropsychology 2019, 33, 670–684. [Google Scholar] [CrossRef] [PubMed]
- Buschke, H.; Mowrey, W.B.; Ramratan, W.S.; Zimmerman, M.E.; Loewenstein, D.A.; Katz, M.J.; Lipton, R.B. Memory Binding Test Distinguishes Amnestic Mild Cognitive Impairment and Dementia from Cognitively Normal Elderly. Arch. Clin. Neuropsychol. Off. J. Natl. Acad. Neuropsychol. 2017, 32, 29–39. [Google Scholar] [CrossRef] [PubMed]
- Jester, D.J.; Andel, R.; Cechov, K. Cognitive phenotypes of older adults with subjective cognitive decline and amnestic mild cognitive impairment: The Czech Brain Aging Study. J. Int. Neuropsychol. Soc. 2021, 27, 329–342. [Google Scholar] [CrossRef] [PubMed]
- Kwak, K.; Giovanello, K.S.; Bozoki, A.; Styner, M.; Dayan, E. Subtyping of mild cognitive impairment using a deep learning model based on brain atrophy patterns. Cell Rep. Med. 2021, 2, 100467. [Google Scholar] [CrossRef]
- McLane, H.C.; Berkowitz, A.L.; Patenaude, B.N.; McKenzie, E.D.; Wolper, E.; Wahlster, S.; Mateen, F.J. Availability, accessibility, and affordability of neurodiagnostic tests in 37 countries. Neurology 2015, 85, 1614–1622. [Google Scholar] [CrossRef]
- Beeson, P.; Rapcsak, S. Clinical Diagnosis and Treatment of Spelling Disorders. In The Handbook of Adult Language Disorders; Hillis, A., Ed.; Psychological Press: London, UK, 2015; pp. 145–170. [Google Scholar]
- He, R.; Chapin, K.; Al-Tamimi, J.; Bel, N.; Marqui, M. Automated classification of cognitive decline and probable Alzheimer’s dementia across multiple speech and language domains. Am. J. Speech-Lang. Pathol. 2023, 32, 2075–2086. [Google Scholar] [CrossRef] [PubMed]
- Love, T.; Oster, E. On the categorization of aphasic typologies: The SOAP (a test of syntactic complexity). J. Psycholinguist Res. 2002, 31, 503–529. [Google Scholar] [CrossRef] [PubMed]
- Pekkala, S.; Wiener, D.; Himali, J.; Beiser, A.; Obler, L.; Liu, Y. Lexical retrieval in discourse: An early indicator of Alzheimer’s dementia. Clin. Linguist. Phon. 2013, 27, 905–921. [Google Scholar] [CrossRef] [PubMed]
- Forbes-McKay, K.; Shanks, M.; Venneri, A. Charting the decline in spontaneous writing in Alzheimer’s disease: A longitudinal study. Acta Neuropsychiatr. 2014, 26, 246–252. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Chang, H.T.; Chiu, M.J.; Chen, T.F.; Liu, M.Y.; Fan, W.C.; Cheng, T.W.; Hua, M.S. Deterioration and predictive values of semantic networks in mild cognitive impairment. J. Neurolinguistics 2022, 61, 101025. [Google Scholar] [CrossRef]
- Juncos-Rabadn, O.; Facal, D.; Lojo-Seoane, C.; Pereiro, A.X. Tip-of-the-tongue for proper names in non-amnestic mild cognitive impairment. J. Neurolinguistics 2013, 26, 409–420. [Google Scholar] [CrossRef]
- Mueller, K.D.; Hermann, B.; Mecollari, J.; Turkstra, L.S. Connected speech and language in mild cognitive impairment and Alzheimer’s disease: A review of picture description tasks. J. Clin. Exp. Neuropsychol. 2018, 40, 917–939. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Variant | Gender | N | Mean | SD | Median | Mode | |
|---|---|---|---|---|---|---|---|
| Age | Amnestic | F | 71 | 67.4 | 12.99 | 70 | 53 |
| M | 53 | 69.7 | 15.28 | 74 | 69 | ||
| Non Amnestic | F | 21 | 54.2 | 13.48 | 52 | 48 | |
| M | 25 | 65.6 | 12.04 | 66 | 65 | ||
| Education | Amnestic | F | 70 | 16.1 | 3.19 | 16 | 16 |
| M | 52 | 17.5 | 3.42 | 18 | 16 | ||
| Non Amnestic | F | 21 | 15.5 | 3.53 | 16 | 16 | |
| M | 24 | 16 | 3.06 | 16.5 | 12 |
| Variant | Mean | Median | Mode | SD | |
|---|---|---|---|---|---|
| MMSE | Amnestic | 27.5081 | 28 | 28 | 1.746 |
| Non-amnestic | 28.0476 | 29 | 29 | 1.821 | |
| WMS | Amnestic | 13.25 | 14 | 14 | 0.942 |
| Non-amnestic | 13.6804 | 14 | 14 | 0.592 | |
| Digit forward | Amnestic | 6.7016 | 7 | 7 | 1.169 |
| Non-amnestic | 6.7391 | 7 | 6 | 1.437 | |
| Digit backward | Amnestic | 4.2984 | 4 | 4 | 1.044 |
| Non-amnestic | 4.4565 | 4 | 4 | 1.187 | |
| RAVLT (total) | Amnestic | 29.2177 | 29 | 30 | 9.373 |
| Non-amnestic | 37.8587 | 37 | 37 | 11.187 | |
| RAVLT (delayed) | Amnestic | 3.5081 | 3 | 3 | 2.95 |
| Non-amnestic | 6.8333 | 7 | 7 | 3.151 | |
| RCF (immediate) | Amnestic | 7.8487 | 7 | 0 | 5.934 |
| Non-amnestic | 14.5435 | 12 | 6 | 8.989 | |
| RCF (delayed) | Amnestic | 6.2391 | 5 | 0 | 5.25 |
| Non-amnestic | 13.1739 | 12.25 | 0 | 8.568 | |
| BNT | Amnestic | 49.2033 | 52 | 56 | 10.265 |
| Non-amnestic | 52.2826 | 54 | 56 | 7.12 | |
| Verbal fluency (FAS) | Amnestic | 35.5772 | 35 | 32 | 13.073 |
| Non-amnestic | 34.3261 | 32.5 | 23 | 12.994 | |
| BDAE writing | Amnestic | 4.1441 | 4 | 4 | 3.733 |
| Non-amnestic | 3.7778 | 4 | 4 | 0.56 | |
| TMT A | Amnestic | 55.2218 | 48.5 | 30 | 31.634 |
| Non-amnestic | 45.5993 | 36.5 | 25 | 24.149 | |
| TMT A error | Amnestic | 0.042 | 0 | 0 | 0.302 |
| Non-amnestic | 0.087 | 0 | 0 | 0.354 | |
| TMT B | Amnestic | 132.8319 | 113 | 110 | 99.71 |
| Non-amnestic | 121.9254 | 96 | 57 | 75.288 | |
| TMT B error | Amnestic | 0.5439 | 0 | 0 | 1.863 |
| Non-amnestic | 0.3696 | 0 | 0 | 0.878 | |
| Color | Amnestic | 111.7168 | 112 | 112 | 2.647 |
| Non-amnestic | 110.55 | 112 | 112 | 8.852 | |
| Color(Word) | Amnestic | 67.2 | 66 | 112 | 29.593 |
| Non-amnestic | 68.8158 | 64.5 | 112 | 25.877 |
| Non-Amnestic | Amnestic | |||
|---|---|---|---|---|
| Mean | SD | Mean | SD | |
| Adjectival clause | 0.021 | 0.054 | 0.014 | 0.031 |
| Adjectival complement | 0.007 | 0.016 | 0.009 | 0.017 |
| Adjective | 0.022 | 0.032 | 0.028 | 0.033 |
| Adposition | 0.097 | 0.054 | 0.113 | 0.058 |
| Adverb | 0.013 | 0.022 | 0.015 | 0.025 |
| Adverbial clause | 0.022 | 0.030 | 0.021 | 0.031 |
| Adverbial modifier | 0.012 | 0.021 | 0.014 | 0.024 |
| Agent | 0.000 | 0.004 | 0.000 | 0.002 |
| Adjectival modifier | 0.021 | 0.031 | 0.017 | 0.033 |
| Apposition | 0.004 | 0.016 | 0.003 | 0.013 |
| Attribute | 0.003 | 0.007 | 0.002 | 0.007 |
| Auxiliary | 0.080 | 0.060 | 0.075 | 0.065 |
| Auxiliary (passive) | 0.001 | 0.005 | 0.002 | 0.007 |
| Case marking | 0.002 | 0.008 | 0.002 | 0.007 |
| Coordinating conjunction | 0.019 | 0.026 | 0.018 | 0.026 |
| Clausal complement | 0.020 | 0.033 | 0.021 | 0.035 |
| Coordinating conjunction | 0.019 | 0.026 | 0.018 | 0.026 |
| Character–word ratio | 5.244 | 0.410 | 5.256 | 0.517 |
| Compound | 0.032 | 0.044 | 0.034 | 0.057 |
| Conjunction | 0.020 | 0.028 | 0.020 | 0.028 |
| Dative case | 0.002 | 0.008 | 0.004 | 0.013 |
| Dependent | 0.046 | 0.095 | 0.032 | 0.056 |
| Determiner | 0.125 | 0.086 | 0.110 | 0.088 |
| Direct object | 0.086 | 0.045 | 0.084 | 0.067 |
| Expletive | 0.003 | 0.007 | 0.001 | 0.006 |
| Interjection | 0.001 | 0.008 | 0.001 | 0.006 |
| Marker | 0.018 | 0.028 | 0.007 | 0.016 |
| Meta data | 0.000 | 0.004 | 0.010 | 0.056 |
| Negation modifier | 0.005 | 0.012 | 0.004 | 0.012 |
| Noun | 0.362 | 0.109 | 0.376 | 0.119 |
| Nominal subject | 0.137 | 0.055 | 0.142 | 0.057 |
| Nominal subject (passive) | 0.001 | 0.005 | 0.002 | 0.007 |
| Numeral | 0.004 | 0.012 | 0.004 | 0.013 |
| Numeric modifier | 0.003 | 0.011 | 0.004 | 0.012 |
| Object predicate | 0 | 0 | 0.001 | 0.009 |
| Parataxis | 0 | 0 | 0.000 | 0.002 |
| Particle | 0.026 | 0.026 | 0.025 | 0.029 |
| Prepositional complement | 0.000 | 0.002 | 0.002 | 0.008 |
| Prepositional object | 0.078 | 0.052 | 0.096 | 0.052 |
| Possessive modifier | 0.011 | 0.021 | 0.011 | 0.021 |
| Preposition | 0.083 | 0.057 | 0.099 | 0.058 |
| Pronoun | 0.037 | 0.041 | 0.027 | 0.033 |
| Proper noun | 0.003 | 0.014 | 0.003 | 0.012 |
| Particle | 0.012 | 0.017 | 0.011 | 0.018 |
| Punctuation | 0.111 | 0.073 | 0.104 | 0.081 |
| Relative clause | 0.004 | 0.010 | 0.004 | 0.010 |
| Root | 0.105 | 0.056 | 0.099 | 0.061 |
| Subordinating conjunction | 0.018 | 0.028 | 0.008 | 0.017 |
| Symbol | 0.000 | 0.003 | 0.001 | 0.007 |
| Verb | 0.196 | 0.071 | 0.192 | 0.057 |
| Other | 0.002 | 0.013 | 0.010 | 0.051 |
| Open clausal complement | 0.015 | 0.021 | 0.018 | 0.024 |
| Words [count] 1 | 31.943 | 15.318 | 29.650 | 14.205 |
| Characters [counts] 1 | 170.927 | 78.647 | 158.829 | 70.947 |
| RF | GB | HGB | XGB | LGBM | |
|---|---|---|---|---|---|
| Accuracy | 0.90 | 0.90 | 0.89 | 0.89 | 0.89 |
| F1 | 0.71 | 0.72 | 0.70 | 0.71 | 0.70 |
| Precision | 0.74 | 0.75 | 0.75 | 0.75 | 0.75 |
| Recall | 0.68 | 0.70 | 0.67 | 0.68 | 0.66 |
| ROC/AUC | 0.98 | 0.97 | 0.98 | 0.97 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.; Hillis, A.E.; Themistocleous, C. Machine Learning Classification of Patients with Amnestic Mild Cognitive Impairment and Non-Amnestic Mild Cognitive Impairment from Written Picture Description Tasks. Brain Sci. 2024, 14, 652. https://doi.org/10.3390/brainsci14070652
Kim H, Hillis AE, Themistocleous C. Machine Learning Classification of Patients with Amnestic Mild Cognitive Impairment and Non-Amnestic Mild Cognitive Impairment from Written Picture Description Tasks. Brain Sciences. 2024; 14(7):652. https://doi.org/10.3390/brainsci14070652
Chicago/Turabian StyleKim, Hana, Argye E. Hillis, and Charalambos Themistocleous. 2024. "Machine Learning Classification of Patients with Amnestic Mild Cognitive Impairment and Non-Amnestic Mild Cognitive Impairment from Written Picture Description Tasks" Brain Sciences 14, no. 7: 652. https://doi.org/10.3390/brainsci14070652
APA StyleKim, H., Hillis, A. E., & Themistocleous, C. (2024). Machine Learning Classification of Patients with Amnestic Mild Cognitive Impairment and Non-Amnestic Mild Cognitive Impairment from Written Picture Description Tasks. Brain Sciences, 14(7), 652. https://doi.org/10.3390/brainsci14070652