
Ecological Momentary Assessment to Obtain Signal Processing Technology Preference in Cochlear Implant Users

Abstract
:1. Introduction
2. Materials and Methods
2.1. Research Subjects
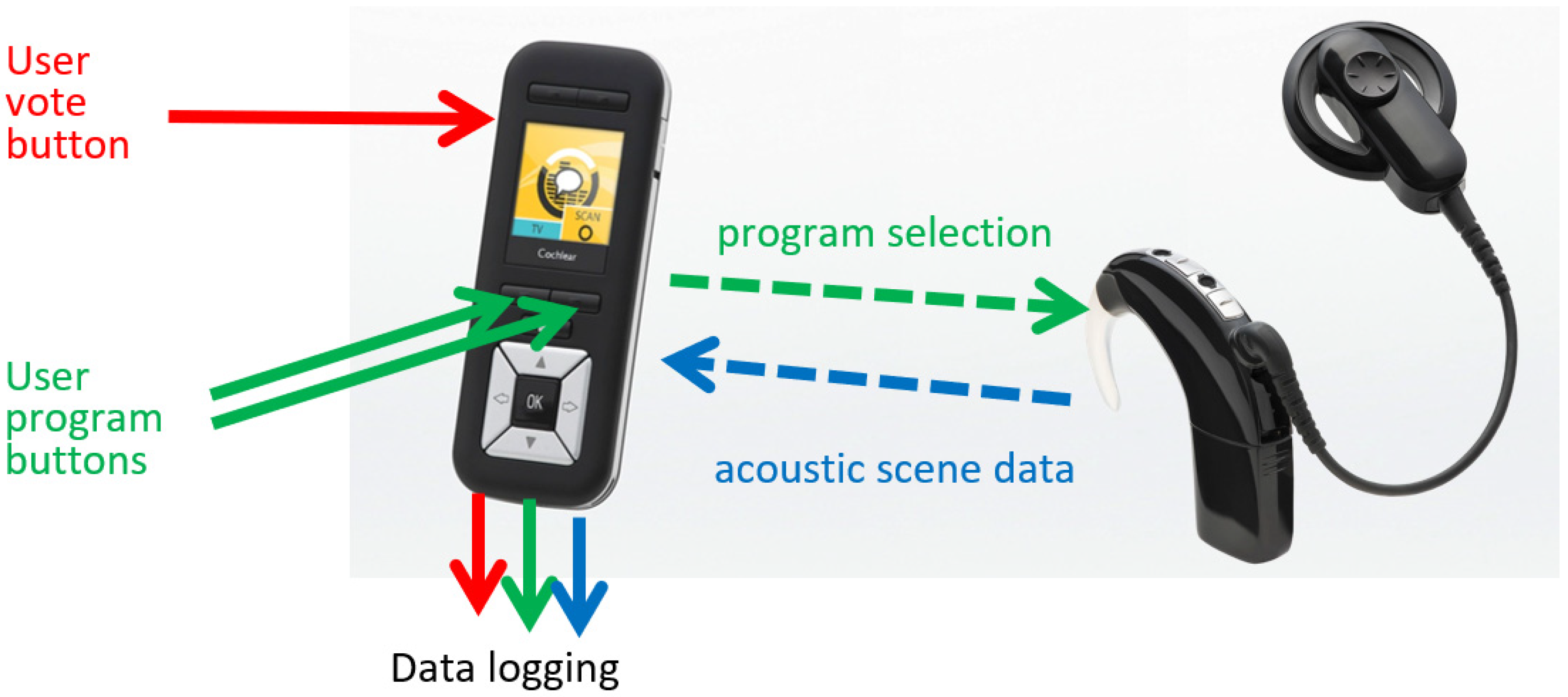
2.2. Programming the Sound Processor Settings
2.3. EMA Data Capture and Analysis
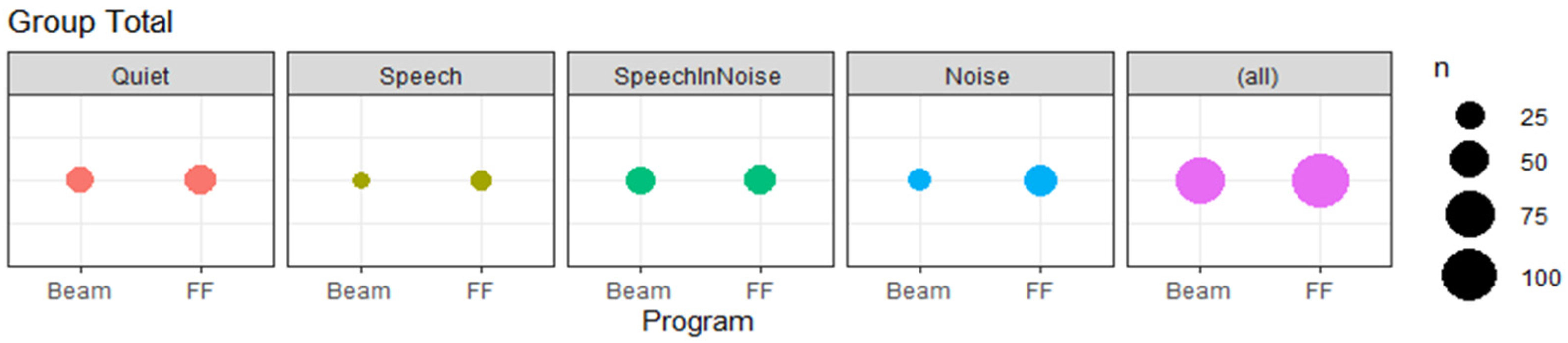
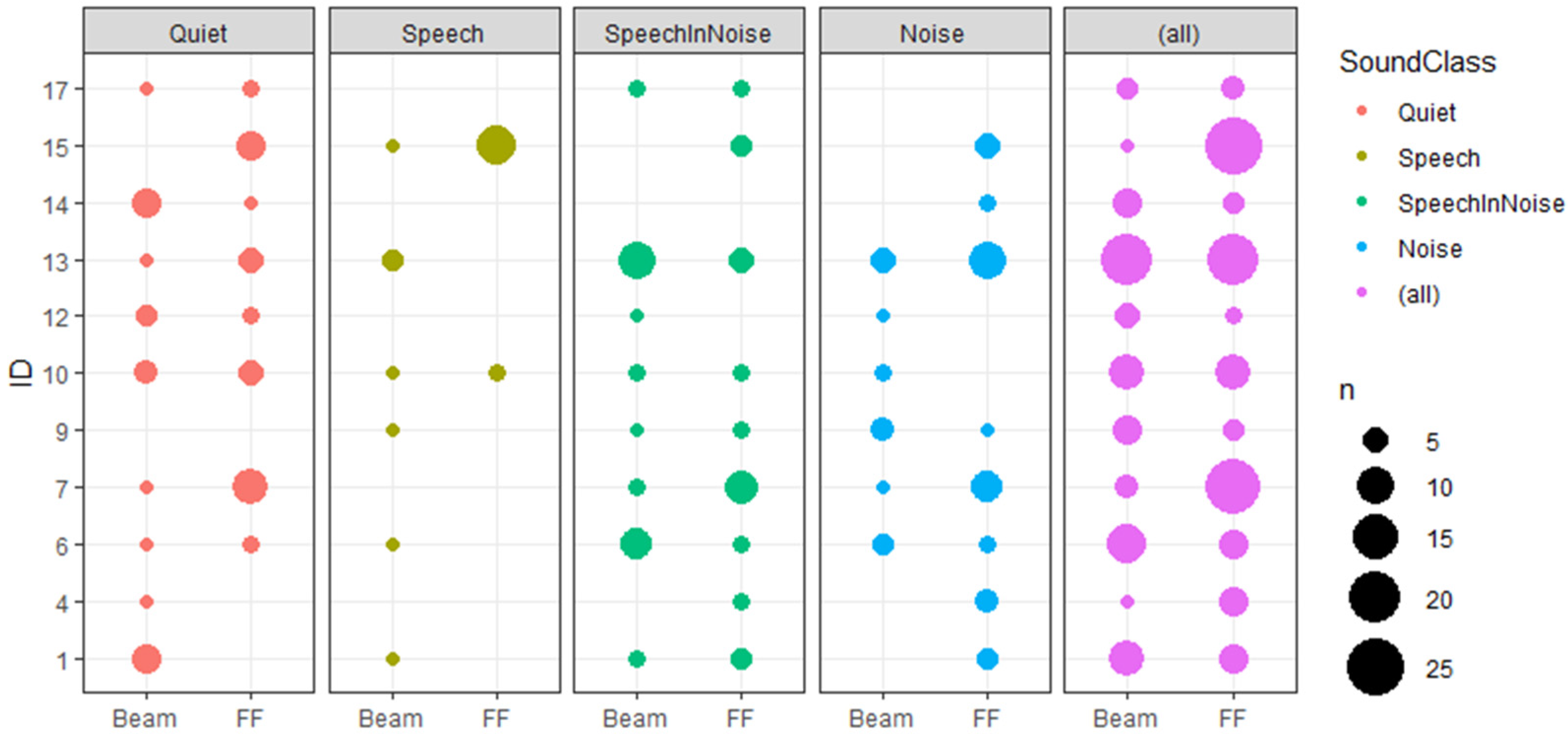
3. Results
EMA Results
4. Discussion
Study Limits and Future Improvements
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Buchman, C.A.; Gifford, R.H.; Haynes, D.S.; Lenarz, T.; O’Donoghue, G.; Adunka, O.; Biever, A.; Briggs, R.J.; Carlson, M.L.; Dai, P.; et al. Unilateral Cochlear Implants for Severe, Profound, or Moderate Sloping to Profound Bilateral Sensorineural Hearing Loss: A Systematic Review and Consensus Statements. JAMA Otolaryngol. Head Neck Surg. 2020, 146, 942–953. [Google Scholar] [CrossRef] [PubMed]
- Hoppe, U.; Hast, A.; Hocke, T. Audiometry-Based Screening Procedure for Cochlear Implant Candidacy. Otol. Neurotol. 2015, 36, 1001–1005. [Google Scholar] [CrossRef] [PubMed]
- Clark, G.M.; Tong, Y.C.; Martin, L.F.A.; Busby, P.A. A multiple-channel cochlear implant: An evaluution using an open-set word test. Acta Otolaryngol. 1981, 91, 173–175. [Google Scholar] [CrossRef]
- Lehnhardt, E.; Battmer, R.D.; Nakahodo, K.; Laszig, R. Cochlear implants. HNO 1986, 34, 271–279. [Google Scholar]
- Clark, G.M.; Tong, Y.C.; Martin, L.F.A. A multiple-channel cochlear implant: An evaluation using open-set cid sentences. Laryngoscope 1981, 91, 628–634. [Google Scholar] [CrossRef]
- Gifford, R.H.; Dorman, M.F.; Shallop, J.K.; Sydlowski, S.A. Evidence for the expansion of adult cochlear implant candidacy. Ear Hear. 2010, 31, 186–194. [Google Scholar] [CrossRef] [Green Version]
- De Raeve, L.; Wouters, A. Accessibility to cochlear implants in Belgium: State of the art on selection, reimbursement, habilitation, and outcomes in children and adults. Cochlear Implant. Int. 2013, 14, S18–S25. [Google Scholar] [CrossRef] [Green Version]
- Blamey, P.; Artieres, F.; Başkent, D.; Bergeron, F.; Beynon, A.; Burke, E.; Dillier, N.; Dowell, R.; Fraysse, B.; Gallégo, S.; et al. Factors affecting auditory performance of postlinguistically deaf adults using cochlear implants: An update with 2251 patients. Audiol. Neurotol. 2012, 18, 36–47. [Google Scholar] [CrossRef] [Green Version]
- Holden, L.K.; Finley, C.C.; Firszt, J.B.; Holden, T.A.; Brenner, C.; Potts, L.G.; Gotter, B.D.; Vanderhoof, S.S.; Mispagel, K.; Heydebrand, G.; et al. Factors affecting open-set word recognition in adults with cochlear implants. Ear Hear. 2013, 34, 342–360. [Google Scholar] [CrossRef] [Green Version]
- Hoppe, U.; Hocke, T.; Hast, A.; Iro, H. Cochlear Implantation in Candidates With Moderate-to-Severe Hearing Loss and Poor Speech Perception. Laryngoscope 2021, 131, E940–E945. [Google Scholar] [CrossRef]
- Hersbach, A.A.; Arora, K.; Mauger, S.J.; Dawson, P.W. Combining directional microphone and single-channel noise reduction algorithms: A clinical evaluation in difficult listening conditions with cochlear implant users. Ear Hear. 2012, 33, e13–e23. [Google Scholar] [CrossRef] [PubMed]
- Hey, M.; Hocke, T.; Mauger, S.; Müller-Deile, J. A clinical assessment of cochlear implant recipient performance: Implications for individualized map settings in specific environments. Eur. Arch. Oto-Rhino-Laryngol. 2016, 273, 4011–4020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- James, C.J.; Blamey, P.J.; Martin, L.; Swanson, B.; Just, Y.; Macfarlane, D. Adaptive dynamic range optimization for cochlear implants: A preliminary study. Ear Hear. 2002, 23, 49S–58S. [Google Scholar] [CrossRef]
- Mosnier, I.; Marx, M.; Venail, F.; Loundon, N.; Roux-Vaillard, S.; Sterkers, O. Benefits from upgrade to the CP810TM sound processor for Nucleus® 24 cochlear implant recipients. Eur. Arch. Oto-Rhino-Laryngol. 2014, 271, 49–57. [Google Scholar] [CrossRef] [PubMed]
- Patrick, J.F.; Busby, P.A.; Gibson, P.J. The Development of the Nucleus®FreedomTM Cochlear Implant System. Trends Amplif. 2006, 10, 175–200. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wolfe, J.; Parkinson, A.; Schafer, E.C.; Gilden, J.; Rehwinkel, K.; Mansanares, J.; Coughlan, E.; Wright, J.; Torres, J.; Gannaway, S. Benefit of a commercially available cochlear implant processor with dual-microphone beamforming: A multi-center study. Otol. Neurotol. 2012, 33, 553–560. [Google Scholar] [CrossRef]
- Dillier, N.; Lai, W.K. Speech Intelligibility in Various Noise Conditions with the Nucleus® 5 Cp810 Sound Processor. Audiol. Res. 2015, 5, 69–75. [Google Scholar] [CrossRef] [Green Version]
- Hey, M.; Böhnke, B.; Mewes, A.; Munder, P.; Mauger, S.J.; Hocke, T. Speech comprehension across multiple CI processor generations: Scene dependent signal processing. Laryngoscope Investig. Otolaryngol. 2021, 6, 807–815. [Google Scholar] [CrossRef]
- Lazard, D.S.; Vincent, C.; Venail, F.; van de Heyning, P.; Truy, E.; Sterkers, O.; Skarzynski, P.H.; Skarzynski, H.; Schauwers, K.; O’Leary, S.; et al. Pre-, Per- and Postoperative Factors Affecting Performance of Postlinguistically Deaf Adults Using Cochlear Implants: A New Conceptual Model over Time. PLoS ONE 2012, 7, e48739. [Google Scholar] [CrossRef] [Green Version]
- Spriet, A.; Van Deun, L.; Eftaxiadis, K.; Laneau, J.; Moonen, M.; Van Dijk, B.; Van Wieringen, A.; Wouters, J. Speech understanding in background noise with the two-microphone adaptive beamformer BEAMTM in the nucleus FreedomTM cochlear implant system. Ear Hear. 2007, 28, 62–72. [Google Scholar] [CrossRef]
- Hey, M.; Hocke, T.; Böhnke, B.; Mauger, S.J. ForwardFocus with cochlear implant recipients in spatially separated and fluctuating competing signals–Introduction of a reference metric. Int. J. Audiol. 2019, 58, 869–878. [Google Scholar] [CrossRef] [PubMed]
- Meis, M.; Krueger, M.; Gablenz, P.V.; Holube, I.; Gebhard, M.; Latzel, M.; Paluch, R. Development and Application of an Annotation Procedure to Assess the Impact of Hearing Aid Amplification on Interpersonal Communication Behavior. Trends Hear. 2018, 22, 1–17. [Google Scholar] [CrossRef]
- Shiffman, S.; Stone, A.A.; Hufford, M.R. Ecological momentary assessment. Annu. Rev. Clin. Psychol. 2008, 4, 1–32. [Google Scholar] [CrossRef] [PubMed]
- Galvez, G.; Turbin, M.B.; Thielman, E.J.; Istvan, J.A.; Andrews, J.A.; Henry, J.A. Feasibility of ecological momentary assessment of hearing difficulties encountered by hearing aid users. Ear Hear. 2012, 33, 497–507. [Google Scholar] [CrossRef] [Green Version]
- Timmer, B.H.B.; Hickson, L.; Launer, S. The use of ecological momentary assessment in hearing research and future clinical applications. Hear. Res. 2018, 369, 24–28. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.H.; Stangl, E.; Zhang, X.; Bentler, R.A. Construct validity of the ecological momentary assessment in audiology research. J. Am. Acad. Audiol. 2015, 26, 872–884. [Google Scholar] [CrossRef] [Green Version]
- Holube, I.; von Gablenz, P.; Bitzer, J. Ecological Momentary Assessment in Hearing Research: Current State, Challenges, and Future Directions. Ear Hear. 2020, 41, 79S–90S. [Google Scholar] [CrossRef]
- Myin-Germeys, I.; Oorschot, M.; Collip, D.; Lataster, J.; Delespaul, P.; Van Os, J. Experience sampling research in psychopathology: Opening the black box of daily life. Psychol. Med. 2009, 39, 1533–1547. [Google Scholar] [CrossRef]
- Badajoz-Davila, J.; Buchholz, J.M. Effect of test realism on speech-in-noise outcomes in bilateral cochlear implant users. Ear Hear. 2021, 42, 1687–1698. [Google Scholar] [CrossRef]
- Keidser, G.; Naylor, G.; Brungart, D.S.; Caduff, A.; Campos, J.; Carlile, S.; Carpenter, M.G.; Grimm, G.; Hohmann, V.; Holube, I.; et al. The Quest for Ecological Validity in Hearing Science: What It Is, Why It Matters, and How to Advance It. Ear Hear. 2020, 41, 5S–19S. [Google Scholar] [CrossRef]
- Plasmans, A.; Rushbrooke, E.; Moran, M.; Spence, C.; Theuwis, L.; Zarowski, A.; Offeciers, E.; Atkinson, B.; McGovern, J.; Dornan, D.; et al. A multicentre clinical evaluation of paediatric cochlear implant users upgrading to the Nucleus 6 system. Int. J. Pediatr. Otorhinolaryngol. 2016, 83, 193–199. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mauger, S.J.; Warren, C.D.; Knight, M.R.; Goorevich, M.; Nel, E. Clinical evaluation of the Nucleus 6 cochlear implant system: Performance improvements with SmartSound iQ. Int. J. Audiol. 2014, 53, 564–576. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cristofari, E.; Cuda, D.; Martini, A.; Forli, F.; Zanetti, D.; Di Lisi, D.; Marsella, P.; Marchioni, D.; Vincenti, V.; Aimoni, C.; et al. A Multicenter Clinical Evaluation of Data Logging in Cochlear Implant Recipients Using Automated Scene Classification Technologies. Audiol. Neurotol. 2017, 22, 226–235. [Google Scholar] [CrossRef] [PubMed]
- Ye, H.; Deng, G.; Mauger, S.J.; Hersbach, A.A.; Dawson, P.W.; Heasman, J.M. A wavelet-based noise reduction algorithm and its clinical evaluation in cochlear implants. PLoS ONE 2013, 8, e75662. [Google Scholar] [CrossRef] [Green Version]
- Goehring, T.; Bolner, F.; Monaghan, J.J.M.; van Dijk, B.; Zarowski, A.; Bleeck, S. Speech enhancement based on neural networks improves speech intelligibility in noise for cochlear implant users. Hear. Res. 2017, 344, 183–194. [Google Scholar] [CrossRef]
- Oberhoffner, T.; Hoppe, U.; Hey, M.; Hecker, D.; Bagus, H.; Voigt, P.; Schicktanz, S.; Braun, A.; Hocke, T. Multicentric analysis of the use behavior of cochlear implant users. Laryngorhinootologie 2018, 97, 313–320. [Google Scholar] [CrossRef]
- Busch, T.; Vanpoucke, F.; van Wieringen, A. Auditory environment across the life span of cochlear implant users: Insights from data logging. J. Speech Lang. Hear. Res. 2017, 60, 1362–1377. [Google Scholar] [CrossRef]
- Wu, Y.-H.; Stangl, E.; Oleson, J.; Caraher, K.; Dunn, C.C. Personal Characteristics Associated with Ecological Momentary Assessment Compliance in Adult Cochlear Implant Candidates and Users. J. Am. Acad. Audiol. 2021, 9, 065007. [Google Scholar] [CrossRef]
- Mauger, S.J.; Arora, K.; Dawson, P.W. Cochlear implant optimized noise reduction. J. Neural Eng. 2012, 9, 065007. [Google Scholar] [CrossRef]
- Balling, L.W.; Molgaard, L.L.; Townend, O.; Nielsen, J.B.B. The Collaboration between Hearing Aid Users and Artificial Intelligence to Optimize Sound. Semin. Hear. 2021, 42, 282–294. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Patient ID | Age (Years) | Usage of CI (Years) | Side | Gender | Rate (pps) | Maxima |
|---|---|---|---|---|---|---|
| #1 | 75.7 | 1.5 | r | m | 1200 | 12 |
| #1 | 75.7 | 1.0 | l | m | 1200 | 12 |
| #4 | 73.7 | 10.7 | r | m | 1200 | 8 |
| #6 | 43.3 | 8.2 | r | f | 1200 | 12 |
| #6 | 43.3 | 2.1 | l | f | 1200 | 12 |
| #7 | 56.0 | 7.3 | r | f | 1200 | 12 |
| #7 | 56.0 | 8.6 | l | f | 1200 | 12 |
| #9 | 47.4 | 3.4 | r | m | 1200 | 12 |
| #9 | 47.4 | 2.5 | l | m | 1200 | 12 |
| #10 | 64.9 | 1.5 | r | f | 1200 | 12 |
| #12 | 61.1 | 6.1 | r | f | 500 | 8 |
| #12 | 61.1 | 8.7 | l | f | 500 | 10 |
| #13 | 56.0 | 3.0 | r | f | 900 | 8 |
| #14 | 65.0 | 10.9 | r | f | 500 | 12 |
| #14 | 65.0 | 9.1 | l | f | 500 | 12 |
| #15 | 73.4 | 2.6 | l | m | 900 | 10 |
| #17 | 55.8 | 9.5 | r | m | 1200 | 12 |
| Subject | Total Votes Cast | Logistic Regression of Preference with Subject (p-Value) | Logistic Regression of Preference with SoundClass (p-Value) | Category | Comments |
|---|---|---|---|---|---|
| #13 | 40 | 0.509 | 0.011 * | B | Preference varied with SoundClass |
| #7 | 28 | 0.004 * | 0.807 | A | Overall preference for FF |
| #15 | 27 | <0.001 * | 0.682 | A | Overall preference for FF |
| #6 | 18 | 0.692 | 0.419 | C | No conclusive preference |
| #10 | 18 | 0.566 | 0.358 | C | No conclusive preference |
| #1 | 15 | 0.442 | 0.004 * | B | Preference varied with SoundClass |
| #9 | 9 | 0.744 | 0.268 | C | No conclusive preference |
| #14 | 9 | 0.744 | 0.017 * | B | Preference varied with SoundClass |
| #4 | 7 | 0.068 | 0.057 | C | No conclusive preference |
| #12 | 7 | 0.605 | 0.439 | C | No conclusive preference |
| #17 | 7 | 0.455 | 0.658 | C | No conclusive preference |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hey, M.; Hersbach, A.A.; Hocke, T.; Mauger, S.J.; Böhnke, B.; Mewes, A. Ecological Momentary Assessment to Obtain Signal Processing Technology Preference in Cochlear Implant Users. J. Clin. Med. 2022, 11, 2941. https://doi.org/10.3390/jcm11102941
Hey M, Hersbach AA, Hocke T, Mauger SJ, Böhnke B, Mewes A. Ecological Momentary Assessment to Obtain Signal Processing Technology Preference in Cochlear Implant Users. Journal of Clinical Medicine. 2022; 11(10):2941. https://doi.org/10.3390/jcm11102941
Chicago/Turabian StyleHey, Matthias, Adam A. Hersbach, Thomas Hocke, Stefan J. Mauger, Britta Böhnke, and Alexander Mewes. 2022. "Ecological Momentary Assessment to Obtain Signal Processing Technology Preference in Cochlear Implant Users" Journal of Clinical Medicine 11, no. 10: 2941. https://doi.org/10.3390/jcm11102941
APA StyleHey, M., Hersbach, A. A., Hocke, T., Mauger, S. J., Böhnke, B., & Mewes, A. (2022). Ecological Momentary Assessment to Obtain Signal Processing Technology Preference in Cochlear Implant Users. Journal of Clinical Medicine, 11(10), 2941. https://doi.org/10.3390/jcm11102941