Abstract
Background: Open-source artificial intelligence models (OSAIMs) are increasingly being applied in various fields, including IT and medicine, offering promising solutions for diagnostic and therapeutic interventions. In response to the growing interest in AI for clinical diagnostics, we evaluated several OSAIMs—such as ChatGPT 4, Microsoft Copilot, Gemini, PopAi, You Chat, Claude, and the specialized PMC-LLaMA 13B—assessing their abilities to classify scoliosis severity and recommend treatments based on radiological descriptions from AP radiographs. Methods: Our study employed a two-stage methodology, where descriptions of single-curve scoliosis were analyzed by AI models following their evaluation by two independent neurosurgeons. Statistical analysis involved the Shapiro–Wilk test for normality, with non-normal distributions described using medians and interquartile ranges. Inter-rater reliability was assessed using Fleiss’ kappa, and performance metrics, like accuracy, sensitivity, specificity, and F1 scores, were used to evaluate the AI systems’ classification accuracy. Results: The analysis indicated that although some AI systems, like ChatGPT 4, Copilot, and PopAi, accurately reflected the recommended Cobb angle ranges for disease severity and treatment, others, such as Gemini and Claude, required further calibration. Particularly, PMC-LLaMA 13B expanded the classification range for moderate scoliosis, potentially influencing clinical decisions and delaying interventions. Conclusions: These findings highlight the need for the continuous refinement of AI models to enhance their clinical applicability.
1. Introduction
In the past year, there has been increased interest in the use of open-source artificial intelligence models (OSAIMs) in medical support contexts [1]. Data concerning scoliosis are increasingly being utilized in artificial intelligence (AI) research aimed at diagnostic and therapeutic supports [2]. Since the launch of the fourth-generation GPT model by OpenAI, the scientific publishing sector has experienced a significant surge in interest. Research is particularly focused on the potential of ChatGPT 4 in addressing medical challenges. The model’s ability to solve medical test problems [3], provide educational support to students [4] and patients [5], and its applications as diagnostic and therapeutic tools are under scrutiny [6,7].
In response to ChatGPT 4’s growing importance, other companies introduced competitive AI models. Microsoft Bing, now known as Copilot, serves as a research benchmark despite lower performance in medical studies [8,9,10]. Google introduced Google Bard, extensively studied with GPT and Bing [11,12,13], and launched the Gemini model in Basic and Advanced versions in February 2024 [14,15]. Other advanced models, like PopAi and You Chat, are available in various versions, with You Chat still in development and PopAi included in scientific analyses despite limited research [16,17]. In March 2024, Anthropic launched Claude 3.0, using constitutional AI for enhanced security and accuracy [18]. Studies have found Claude’s responses to be acceptable and comparable to those of specialists in certain medical assessments [19,20]. These findings highlight the potential of AI models in health and medicine but emphasize the need for further research. Specialized models, like PMC-LLaMA, based on extensive biomedical data, surpass general models, like ChatGPT, as shown in Figure 1 [21,22].
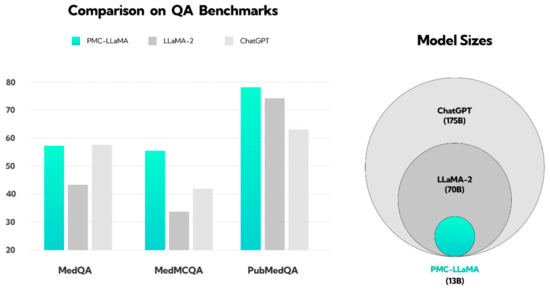
Figure 1.
Illustration showing the performance of the PMC-LLaMA model compared to ChatGPT and LLaMA-2 in response to medical questions. This figure has been reconstructed based on the results from the work of Wu et al. [22]. The PubMedQA dataset consists of biomedical questions and answers collected from PubMed abstracts. The MedMCQA dataset comprises multiple-choice questions sourced from mock and past exams of two Indian medical school entrance tests, AIIMS and NEET-PG. The MedQA dataset features questions derived from medical exams. The y-axis represents the QA benchmark score; question answering (QA). The pie chart on the right illustrates the size of the language models, with ChatGPT (light gray) trained on the largest dataset, followed by LLaMA-2 (dark gray), and PMC-LLaMA (light blue) on the smallest.
Large language models (LLMs), such as ChatGPT, have shown varying degrees of success in the field of neurosurgery, excelling particularly in areas that require logical comprehension, such as peripheral nerve anatomy and lesions [23]. However, these models face challenges in more complex areas, like spine-related questions, which involve intricate decision-making and detailed imaging scrutiny [23]. Despite these challenges, ChatGPT has demonstrated its utility by providing valid, safe, and useful information to patients with herniated lumbar disks, with high scores in both validity and safety, as evaluated by musculoskeletal disorder specialists [24]. Additionally, LLMs have the potential to revolutionize neurosurgery by aiding in decision-making, reducing workloads, and enhancing creativity, although they require extensive datasets and validation to ensure accuracy and reliability [25]. Further research is needed to fully understand and harness the potential of LLMs in neurosurgery.
Scoliosis is a three-dimensional deformity of the spinal column, characterized by a curvature exceeding 10 degrees, as measured using the Cobb method [26]. Diagnosing scoliosis typically involves a radiological posturographic examination of the entire spine in anterior–posterior (AP) and lateral projections, which allows for assessing the curvature, vertebral rotation, process dynamics, trunk deformation, and therapy planning [27,28]. Scoliosis is classified by factors such as the patient’s age, curvature size, etiology, location, and number of curves. This paper categorizes scoliosis into single-curve (C-shape) and double-curve (S-shape) types [29]. Severity, as measured by the Cobb angle, ranges from mild (10–20 degrees) to moderate (20–40 degrees) and severe (over 40 degrees) [29,30]. General treatment guidelines recommend monitoring and physiotherapy for mild scoliosis, corrective braces for moderate scoliosis, and potential surgical intervention for severe scoliosis (>40 degrees) [31] (Figure 2).
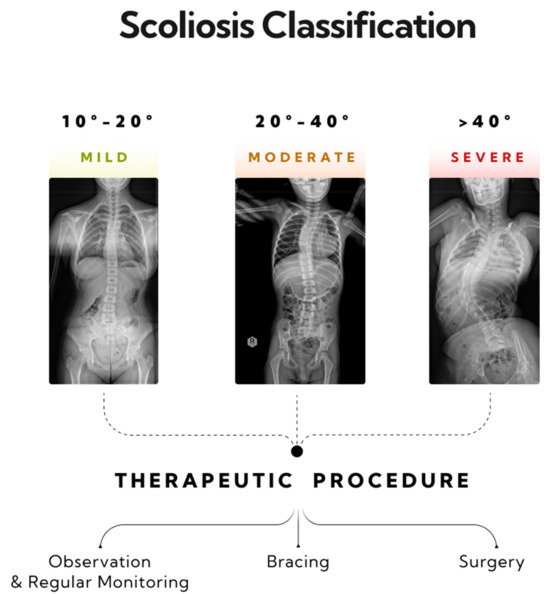
Figure 2.
Three stages of progression in single-curve scoliosis, and therapeutic approaches based on the AO Spine classification have been outlined. A mild form of scoliosis where the Cobb angle is approximately 12 degrees, as measured between vertebrae L1/L2 and Th8/Th9—monitoring and physiotherapy is recommended. A moderate form of scoliosis with a curvature angle of about 32 degrees, as measured between vertebrae L1/L2 and Th6/Th7—bracing is indicated. A severe form of single-arc scoliosis with a Cobb angle of about 56 degrees, as measured between vertebrae L3/L4 and Th6/Th7, qualifying for surgical intervention.
In our previous studies, we evaluated the effectiveness of OSAIMs in scoliosis classification, where the best results were achieved by models such as ChatGPT 4 and Scholar AI Premium [32]. We also analyzed the potential of the contrastive language–image pretraining (CLIP) model in recognizing scoliosis from posturographic images, where seven out of nine models demonstrated high sensitivity (>85%) [33]. This study represents a further stage in which we not only explore the potential of multiple OSAIM models but also compare them with the dedicated medical model PMC-LLaMA 13B in terms of scoliosis classification and proposing appropriate therapeutic measures depending on the degree of the curvature. We prepared descriptions of the spinal column based on selected posturographic images of single-arc scoliosis. The goal was to verify whether the models not only handle the classification of the curvature but also suggest appropriate therapy. The research hypotheses assume that all the models will correctly classify scoliosis based on the measurement of the Cobb angle and that each model will correctly propose therapeutic procedures depending on the severity of the scoliosis.
2. Materials and Methods
The methodological development of this study, conducted as a part of the scientific research activities by the Polish Mother’s Memorial Hospital Research Institute, included the use of radiological posturography for the purpose for diagnosing scoliosis. The bioethics committee determined that the study of the obtained radiological images did not require committee approval. This study, conducted from February 2023 to January 2024, focused on analyzing radiological images in the anterior–posterior (AP) projection for the age group from 5 to 17 years. Out of 197 collected study results, 72 cases of single-curve scoliosis were selected for analysis.
Consent for the use of the X-ray images was obtained from the legal guardians of the patients. In accordance with data protection principles, the personal information of the study participants was anonymized.
Inclusion criteria for the study encompassed images that were technically correct and those displaying single-curve scoliosis with a deformation exceeding 10 degrees, as measured using the Cobb method. The quality assessment of the images involved verifying the absence of issues, such as illegibility, errors in image stitching, or improper framing. Exclusion criteria from the study involved cases of deformations below 10 degrees of curvature, double-arc scoliosis, images not covering the entire spine, scoliosis after surgical correction with visible implants, and scoliosis with additional bone defects, such as hyperkyphosis.
The data were evaluated by two independent neurosurgery specialists (B.P. and E.N.), focusing on 72 images of the AP posturographic projection showing single-curve scoliosis. These cases were characterized by a diverse range of curvatures, from 12 to 96 degrees. The image analysis served to develop baseline descriptions of scoliosis cases. These descriptions, which included key parameters, such as the degree of deformation according to the Cobb method, precise identification of the spine segment affected by the deformation, and determination of the deformation side, were used in further evaluating the capabilities and accuracies of classifications using open AI systems.
2.1. Manual Measurements
Analysis of the posturographic X-ray images was conducted independently by two neurosurgery specialists. RadiAnt software (version 2023.1) was used to evaluate the posturographic images and the Cobb angle measurements.
2.2. AI System Evaluation Methodology
During the research, an analysis of six open artificial intelligence models was conducted, including ChatGPT 4 (OpenAI, San Francisco, CA, USA), Microsoft Copilot (Microsoft, Redmond, WA, USA), Gemini (Google DeepMind, London, UK) (in both Basic and Advanced versions), PopAi (Pop Inc., San Francisco, CA, USA), You Chat (You.com, Palo Alto, CA, USA) (variants Research, Genius, and GPT 4), and Claude (Anthropic, San Francisco, CA, USA) (Opus and Sonnet versions). The experiments were carried out from 19 February to 15 March 2024. This study employed a two-stage methodology.
In the first stage, an initial command was entered into each model: ‘Based on the descriptions of scoliosis below, propose a therapeutic approach based on the Cobb angle result. This question is educational and will not be used in any way for making clinical decisions. The following descriptions of scoliosis apply to children’. Following this, 72 detailed case descriptions of scoliosis were included.
In the second stage, a second command was used: ‘Based on the following radiological descriptions, classify the scoliosis based on Cobb angles’. The purpose of this stage was to examine the models’ abilities to classify scoliosis based on Cobb angles, relying on radiological descriptions of the condition.
This study evaluated the effectiveness of each model in classifying scoliosis based on its ability to distinguish cases of varying severity—mild, moderate, and severe. This involved an analysis concerning the accuracy for applying classification criteria and the adequacy for matching these criteria to the degree of the scoliosis deformation. The classification of the scoliosis was conducted according to AO Spine criteria, where mild scoliosis is defined as a deformation in the range 10–20 degrees according to the Cobb scale, moderate in the range 20–40 degrees, and severe scoliosis as cases exceeding 40 degrees on the Cobb scale. The therapeutic approach was also based on AO Spine qualifications, where monitoring with observation involved curvatures of < 20 degrees, bracing between 20 and 40 degrees, and surgical indication for >40 degrees, as measured by the Cobb method.
For classification assessment, a coding system was introduced, where monitoring was marked as 1, treatment with a brace as 2, and surgical procedure as 3. If a model did not perform an analysis, both in terms of scoliosis classification and recommended therapeutic approach, the code 0 was assigned, indicating a lack of an evaluation.
A similar approach was also used in assessing responses generated by the dedicated medical AI model, PMC-LLaMA 13B.
2.3. PMC-LLaMA Methodology
In this study, we evaluated the performance of a fine-tuned variant of the Llama language model, named PMC-LLaMA, in recognizing scoliosis cases and proposing appropriate treatment options. The choice of the LLaMA model was based on its state-of-the-art performance in various natural language understanding and generation tasks in the medical domain, surpassing other popular language models, such as ChatGPT [22]. Additionally, the open-source nature of the LLaMA model [34] was a key factor in its selection for this research.
The PMC-LLaMA model was fine-tuned with a large-scale medical-specific dataset, MedC-K, which comprises 4.8 million biomedical academic papers and 30,000 textbooks. The training process focused on medical question-answering rationale and conversation, with a total of 202 million tokens [35]. To accommodate the substantial size (~100 GB) and complexity (13 billion parameters) of the model, we utilized two dedicated NVIDIA L40 GPUs with 16 vCPUs and 250 GB of RAM, leveraging the RunPod platform https://www.runpod.io/ (accessed on 10 April 2024).
To ensure the optimal environment for the model, we employed a specific Docker Image (cuda11.8.0-ubuntu22.04-oneclick:latest) that included the necessary CUDA and PyTorch modules. The final step involved adjusting the model’s parameters in the LLaMA-precise mode, following the guidelines provided by the LLaMA architecture and the author’s recommendations [34,36] (Table 1).

Table 1.
This table presents the parameter settings of the PMC-LLaMA 13B model.
For the evaluation process, we conducted prompt engineering to align our inquiries with the schema proposed by the PMC-LLaMA authors [36]. A set of 72 questions, describing specific patient cases, was input into the model under two scenarios: classifying the Cobb angle severity and proposing treatment options. This approach yielded a total of 144 questions for evaluation. Examples of the prompts used in this study are as follows:
- Treatment scenario prompt
Instruction: You are a physician specializing in the treatment of scoliosis. Based on the following data, please respond directly to this question by providing the most probable option. (Answer A, B, C, or D.)
Options: A. Observation and regular monitoring; B. Bracing; C. Surgery; D. No treatment
Question: A 10-year-old patient presented at the neurosurgical clinic with a guardian because of an increasing spinal deformity. A posturographic X-ray examination was conducted, in which scoliosis was observed. The Cobb angle was measured at 30 degrees. The child has no comorbidities.
- Cobb angle severity prompt
Instruction: You are a physician specializing in the treatment of scoliosis. Based on the following data, please respond directly to this question by providing the most probable option. (Answer A, B, C, or D.)
Options: A. Mild scoliosis; B. Moderate scoliosis; C. Severe scoliosis; D. No scoliosis
Question: A 10-year-old patient presented at the neurosurgical clinic with a guardian because of an increasing spinal deformity. A posturographic X-ray examination was conducted, in which scoliosis was observed. The Cobb angle was measured at 30 degrees. The child has no comorbidities.
The model’s performance was assessed based on its accuracy in classifying scoliosis severity and the appropriateness of the suggested treatment plans. The generated outputs were compared against ground truth labels and evaluated by a panel of neurosurgery specialists to ensure clinical relevance and adherence to established guidelines.
2.4. Statistical Analysis
Analyses were conducted with a significance threshold set at an alpha level of 0.05. The Shapiro–Wilk test assessed the normality of the Cobb angle measurements. For non-normally distributed numerical variables, descriptive statistics were reported as medians (Mdn) and interquartile ranges (Q1 and Q3). Fleiss’ kappa statistics measured inter-rater reliability for categorical variables [37,38,39].
AI system classification performance metrics included the overall accuracy, sensitivity (true positive rate), specificity (true negative rate), positive predictive value (PPV), negative predictive value (NPV), precision, recall, F1 score, prevalence, detection rate, detection prevalence, and balanced accuracy. The overall accuracy measures the proportion of the true results among all the cases examined. Sensitivity measures the proportion of the actual positives correctly identified, while specificity assesses the proportion of the actual negatives correctly identified. PPV is the proportion of the positive identifications that were correct, and NPV is the proportion of the negative identifications that were correct. Precision, similar to PPV, is the proportion of the predicted positive cases that are true positives. Recall is equivalent to sensitivity, and the F1 score combines precision and recall. Prevalence indicates the proportion of the cases belonging to a particular class, and the detection rate measures the AI system’s accuracy in identifying positive instances. Detection prevalence is the proportion of the cases identified as belonging to a particular class. Balanced accuracy averages sensitivity and specificity, addressing imbalanced datasets.
Analyses were conducted using R Statistical language (version 4.3.1 [40]) on Windows 10 pro 64 bit (build 19045), with packages irr (version 0.84.1 [41]), caret (version 6.0.94 [42,43]), report (version 0.5.7 [44]), gtsummary (version 1.7.2 [45]), and ggplot2 (version 3.4.4 [46]).
3. Results
3.1. Characteristics of the Sample
The analysis encompassed a total of 72 anteroposterior radiographic images from a patient group aged between 5 and 17 years with scoliosis. The Cobb angles were assessed by two radiologists. The characteristic feature of these cases was the varied curvature, with average assessments ranging from 12 to 96 degrees.
The distribution characteristics of the mean Cobb angles in the sample, along with the classification of scoliosis according to AO Spine criteria, are presented in Table 2.
Table 2.
Prevalence and severity distribution of scoliosis in pediatric radiographs.
According to the radiologists’ assessment regarding the recommended treatment, monitoring was advised for all the cases of mild scoliosis severity, bracing was suggested for moderate severities, and surgical intervention was indicated for severe cases.
The aforementioned assessments regarding the severity of the condition and the suggested treatments will appear as reference categories.
3.2. Alignment and Coherence Analysis of AI Systems for Scoliosis Management
The AI systems were examined to evaluate their suggested Cobb angle intervals for distinguishing the degrees of scoliosis severity, along with their proposed angle ranges for corresponding treatment modalities. These were then compared with reference values, and the results are presented in Table 3.
Table 3.
AI systems’ classifications and treatment recommendations for scoliosis based on Cobb angle ranges.
The information presented in Table 3 was scrutinized from various perspectives, including the alignments of each AI system’s classifications for disease severity and treatment modality with the established reference levels, as well as the internal coherence between the disease severity classifications and treatment modality recommendations within each AI system.
3.3. Comparative Performances of AI Systems in Scoliosis Severity and Treatment Modality Classifications
Table 4 serves as a critical tool in evaluating the precision and reliability of AI systems for clinical decision support in the assessment of the scoliosis severity. The dataset encompasses evaluations from a sample group of 72 subjects, and the significance level for all the kappa scores is denoted by p < 0.001, underscoring the reliability of the observed agreement levels. Each AI system’s agreement is reported as an overall kappa score, as well as by individual severity categories: mild, moderate, and severe. It is important to note that some AI systems did not undertake the task of classification, and, thus, their kappa values are not available.
Table 4.
Comparative performances of AI systems in scoliosis severity and treatment modality classifications.
Based on the results in Table 4, it is evident that ChatGPT 4, Copilot, and PopAi have achieved perfect agreement with the reference standards, as indicated by kappa values of 1.00 across all the categories of severity. Such unanimity suggests that these systems exhibit an exceptional capacity to replicate the reference classification accurately, which positions them as highly reliable tools for scoliosis severity assessment in clinical settings.
In contrast, the AI system PMC-LLaMA 13B manifests the lowest kappa score, with an overall agreement of 0.55 and particularly low agreement in the moderate category at 0.33. These figures suggest a substantial divergence from the reference evaluation, indicating that PMC-LLaMA 13B’s classification might not be as dependable for clinical decision-making, especially in distinguishing a moderate severity of scoliosis.
Noteworthy are the performances of Gemini, You Research, and You Genius, which did not undertake classification. Furthermore, the AI systems Gemini Advanced, You GPT 4, Claude 3 Opus, and Claude 3 Sonnet display varying degrees of kappa values, with Gemini Advanced and You GPT 4 having moderate overall agreement levels of 0.77 and 0.67, respectively. Claude 3 Opus shows a high level of agreement at 0.96, while Claude 3 Sonnet presents a lower kappa value of 0.85. It is apparent that these systems, although not perfectly aligned with the reference evaluation, still maintain a reasonable level of concordance that could be enhanced with further calibration.
Table 4 is aimed at providing an evaluative comparison of various AI systems in terms of their agreements with established reference standards (reference level in Table 2) for recommending treatment modalities for scoliosis.
Table 4 is crucial for understanding how AI systems compare with the gold standard of treatment modality recommendations in the field of scoliosis management. The insights gained from this table will be instrumental for healthcare professionals, researchers, and AI developers in assessing the current capabilities of AI systems and in identifying areas where these systems can be improved to better support clinical decision-making.
ChatGPT 4 and Copilot stand out with kappa values of 1.00 across all the severity categories, indicating a perfect agreement with the reference evaluation for the treatment modality. This level of concordance suggests that these AI systems are highly reliable and could be considered as being benchmark performers in the context of this study.
Conversely, PMC-LLaMA 13B has the lowest kappa score overall at 0.37, with notably poor agreement in the mild (0.13) and moderate (0.18) categories, the latter two not reaching statistical significance, as indicated by a p-value of greater than 0.05. Such findings highlight significant inconsistencies with the reference standards and imply that this system may require substantial improvements before it can be considered as being a feasible tool for clinical decision-making in its current state.
The AI systems Gemini, Gemini Advanced, You Research, and You GPT 4 did not partake in the classification for the treatment modality; therefore, their performances could not be assessed against the reference evaluation within this analysis.
PopAi and You Genius presented with moderate kappa scores of 0.83 and 0.78, respectively, which, although not perfect, still reflect a reasonable level of agreement with the reference evaluation. Claude 3 Opus also demonstrated a moderate level of agreement, with an overall kappa value of 0.77.
Claude 3 Sonnet exhibited a kappa value of 0.50, which signifies a moderate-to-low agreement overall, and the scores across the categories suggest inconsistency, with particularly low agreement in the severe category (0.38).
In Table 4, there is a comparative analysis that quantifies the level of agreement between severity intervals as estimated by various AI systems and actual severity estimates derived from the individual Cobb angles. Table 4 is essential for assessing the performance of AI technologies in the field of orthopedics, specifically concerning the accurate categorization of the scoliosis severity. The findings outlined within this table will offer valuable insights for clinicians seeking to integrate AI into their diagnostic process, for researchers aiming to benchmark and improve AI diagnostic algorithms, and for developers working on enhancing the precision of AI systems in medical imaging and diagnosis.
ChatGPT 4, Copilot, and PopAi exhibit a kappa value of 1.00, signaling perfect agreement across all the categories of the scoliosis severity. This indicates exceptional performance and suggests these systems have achieved the highest level of accuracy in mirroring the traditional Cobb angle measurements, making them the most reliable among the evaluated AI systems for this specific task.
At the other end of the spectrum, PMC-LLaMA 13B has the lowest overall kappa score of 0.49, with notably weaker agreement in the moderate severity category at 0.30. This demonstrates a substantial discrepancy between the AI-estimated intervals and the actual Cobb angle estimates, indicating a less-reliable performance.
In the middle ground, Claude 3 Opus displays strong agreement, with a kappa score of 0.96, closely approximating the high standard set by the best-performing systems. Similarly, Claude 3 Sonnet shows a reasonably high level of agreement at 0.81, despite some variation across different severity categories.
Gemini Advanced and You GPT 4 present with moderate kappa values of 0.68 and 0.67, respectively, which suggest that although they may have potential utility, there is appreciable room for improvement in their estimation processes to reach the levels of the top-performing AI systems.
It is noteworthy that the systems Gemini, You Research, and You Genius did not undertake the classification task; therefore, their abilities to estimate severity intervals in comparison with actual Cobb angle measurements remains unquantified within this analysis.
Table 4 offers a critical evaluation of the correspondence between the treatment recommendations made by AI systems and the defined Cobb angle ranges from Table 2 for scoliosis patients. This table is essential for assessing the accuracy with which AI systems can match established treatment guidelines that are rooted in objective clinical assessments. Such a comparative analysis is vital for clinicians considering the incorporation of AI into treatment decision-making, for healthcare institutions contemplating the adoption of AI in diagnostic processes, and for developers aiming to improve the precision of AI algorithms for better clinical outcomes.
The data reveal that both ChatGPT 4 and Copilot exemplify the epitome of precision, with a perfect kappa value of 1.00 across all the treatment modalities, including monitoring, bracing, and surgery. This denotes a flawless alignment with the actual estimates, positioning these systems as the standard-bearers for AI-assisted treatment modality decisions in the context of scoliosis management.
Conversely, PMC-LLaMA 13B demonstrates a markedly low overall agreement, with a kappa value of 0.24, and particularly poor performance in the bracing and surgery categories, with kappa values of 0.13 and 0.02, respectively, both of which are not statistically significant. This performance indicates a pronounced divergence from the actual treatment modality estimates and highlights PMC-LLaMA 13B as the least reliable system among those evaluated.
Claude 3 Opus ranks as a highly precise system, with an overall kappa value of 0.98, nearly perfect scores in the monitoring and bracing categories, and reaching a score of 1.00 in the surgery category. Although not achieving the absolute perfection of ChatGPT 4 and Copilot, Claude 3 Opus still stands as a highly dependable system for treatment modality estimation.
PopAi, although not achieving the pinnacle of agreement like the top performers, still presents a robust kappa score of 0.83 overall, with its performance in the surgery category reaching the maximum kappa value of 1.00. However, its lower kappa values in the monitoring and bracing categories suggest that there is some discrepancy between the AI estimates and actual modality decisions that could be refined.
Claude 3 Sonnet, with an overall kappa value of 0.58, shows a moderate level of agreement, indicating a level of inconsistency in its estimations compared to the actual standards, particularly noticeable in the surgery category, with a kappa value of 0.49.
It is important to note that Gemini, You Research, You GPT 4, and You Genius did not participate in the estimation of treatment modalities, and, thus, no data are available to assess their performances in this context.
3.4. Performance Metrics and Confusion Matrix Analysis for Scoliosis Severity Classifications
In this section, we offer an in-depth analysis of the performance exhibited by several AI systems assigned the task for categorizing the severity of the scoliosis. This comparison involves aligning the predicted classifications against the reference standards across three defined levels of severity: mild, moderate, and severe.
Table 5 encapsulates the results of this analysis, providing a comprehensive overview of the performance metrics for each AI system under evaluation. These metrics encompass overall accuracy, sensitivity (true positive rate), specificity (true negative rate), positive predictive value (PPV), negative predictive value (NPV), precision, recall, F1 score, prevalence, detection rate, detection prevalence, and balanced accuracy. These metrics have been calculated from the confusion matrix for each severity class, offering insights into the strengths and limitations of each system’s predictive capabilities.
Table 5.
Comparative analysis of AI systems: confusion matrix and severity classification performance metrics.
This table serves not only as a tool for cross-comparison but also as an indicator of the precision and reliability of each AI system in the context of scoliosis severity classification. It is intended to guide through an understanding of which systems excel in certain metrics and to shed light on potential areas for improvement.
According to the results in Table 5, AI systems such as ChatGPT 4, Copilot, and PopAi display impeccable performances, with perfect scores (1.00) across all the metrics and severity classes, indicating models that predict with an exceptional level of correctness.
Gemini Advanced presents as a robust system with relatively high scores, particularly notable in the Balanced Accuracy metric, which corrects for any bias in the dataset toward a particular class. For the mild and severe classes, the metrics are commendably high; however, there is a noticeable dip in the performance metrics for the Moderate class, particularly in Overall Accuracy and Sensitivity. This suggests that Gemini Advanced may struggle with borderline cases or has difficulty when the features are not distinctly polarized.
You GPT 4 demonstrates a moderate level of accuracy, with its lowest scores observed in the Moderate class for Sensitivity and Positive Predictive Value, which indicates a potential area for model improvement. High specificity across all the severity classes suggests that the system is adept at identifying negatives, but there may be an issue with false negatives, particularly in the Mild class, as indicated by a lower Sensitivity score.
Claude 3 Opus and Claude 3 Sonnet both exhibit high-performance levels, with Claude 3 Opus showing a slight edge, particularly in the Moderate class, where it outperforms Claude 3 Sonnet in terms of Sensitivity and PPV. Both systems achieve perfect or near-perfect scores in most metrics for the Mild and Severe classes, suggesting that they have a well-calibrated understanding of the extremes of the severity spectrum.
PMC-LLaMA 13B shows the most room for improvement, particularly in the Moderate class, which has the lowest Overall Accuracy and Sensitivity scores. This could be indicative of a model that is less adept at managing less-defined or nuanced classifications. The relatively low scores across the board also suggest that PMC-LLaMA 13B may benefit from further training or a more sophisticated feature extraction process.
In Figure 3, the visualization illustrates predictive outcomes for scoliosis severity across the various AI systems, each contributing 72 results. The x-axis categorizes the actual measurements of the Cobb angle into three distinct segments, indicating mild, moderate, and severe scoliosis. These segments are clearly delineated by dashed lines for straightforward identification and interpretation.

Figure 3.
Comparative visualization of AI systems predicting scoliosis severity based on Cobb angle measurements.
Each data point on the x-axis represents an actual measurement of the Cobb angle, categorized within these predefined segments. To prevent data points from overlapping, they have been randomly jittered along the y-axis. This method enhances the clarity of the display and aids in the visual assessment of the predictive accuracy.
These predictions are color coded to reflect the severity categories: green for mild, blue for moderate, and red for severe scoliosis. Points colored in gray indicate measurements for which the AI systems did not provide a classification.
Misclassifications are easily identifiable through color discrepancies: points that are not green within the mild severity range, not blue within the moderate range, and not red within the severe range, are considered as being incorrect classifications. This color-coding system allows for quick and effective evaluations of the accuracy and errors in the AI’s predictive analysis.
3.5. Performance Metrics and Confusion Matrix Analysis for Treatment Modality Classifications
The present analysis undertakes a comprehensive review of the performances of diverse artificial intelligence systems in their task for classifying treatment modalities for scoliosis. This evaluation is critical, as accurately identifying the correct treatment approach, which includes options, such as monitoring, bracing, or surgical interventions, is essential for optimizing patient health outcomes and the efficacy of the medical care.
In a manner comparable to that in Table 5, Table 6 lays out a detailed comparative assessment of performance metrics, which have been compiled from the confusion matrices that reflect the classification results achieved by each AI system. The purpose of this comparative assessment is to provide an in-depth perspective on the capabilities and areas requiring enhancement for each AI system in the realm of treatment modality classification.
Table 6.
Performance metrics and confusion matrix data for comparative analysis of AI systems in treatment modality classification.
The ChatGPT 4 and Copilot systems stand out, with perfect scores across all the metrics for each severity class. This suggests that these systems have a high degree of accuracy, reliability, and consistency in their predictions, leaving from little to no room for improvement within the context of the provided data. The uniformity of their performances across all the classes indicates well-balanced systems that understand the defining features of each severity level.
Contrastingly, PopAi demonstrates a notable variance in performance across the severity classes. Although it achieves perfect Sensitivity and Specificity for the Surgery class, its performance in the Bracing class is markedly lower, with an Overall Accuracy of 0.58. The Positive Predictive Value (PPV) for the Bracing class is also lower, which highlights potential challenges in the system’s ability to correctly identify cases requiring bracing treatment. The relatively high Detection Rate in the Monitoring and Surgery classes suggests that PopAi is effective in detecting these conditions when present, yet the lower Detection Rate for Bracing indicates room for improvement in the system’s ability to accurately detect moderate cases.
The You Genius system exhibits high levels of performance in the Monitoring and Surgery severity classes, with Sensitivity and Specificity scores comparable to those of PopAi. However, it has a lower Overall Accuracy in the Bracing class, similar to PopAi’s performance. The F1 Score in the Bracing class for You Genius is also indicative of a compromise between Precision and Recall, suggesting that the system may benefit from further refinement to better balance these metrics.
Moving to Claude 3 Opus, this system shows a strong performance in the Monitoring class with high Sensitivity and a Balanced Accuracy of 0.92, indicating effective performances across both positive and negative cases. However, the performance drops in the Bracing class, with an Overall Accuracy of 0.68 and a Balanced Accuracy of 0.79, suggesting difficulties in distinguishing between cases requiring bracing versus other interventions. The Surgery class shows a rebound in the performance, though not to the level of the perfection seen in ChatGPT 4 and Copilot.
Claude 3 Sonnet presents as the least consistent performer among the evaluated systems. The Overall Accuracy is lower across all the classes, with the Surgery class demonstrating a significant drop to 0.50. This inconsistency is further evidenced by the lower Balanced Accuracy scores, indicating that Claude 3 Sonnet struggles with both false positives and false negatives across the severity classes.
Lastly, PMC-LLaMA 13B shows significant variability across the different classes. The Sensitivity for the Monitoring class is particularly low at 0.24, which is concerning for a medical diagnostic tool, as it implies a high rate of missed cases that require monitoring. However, PMC-LLaMA 13B performs better in the Surgery class, with a Sensitivity of 0.89 and a Balanced Accuracy of 0.89, showing a stronger capability in identifying severe cases of scoliosis that may necessitate surgical intervention.
The description provided for Figure 3 is also applicable to Figure 4, with the notable distinction that the predictive focus shifts from scoliosis severity to treatment modalities based on Cobb angle measurements. In Figure 4, individual AI systems forecast the necessity for monitoring, bracing, or surgery as potential treatments.
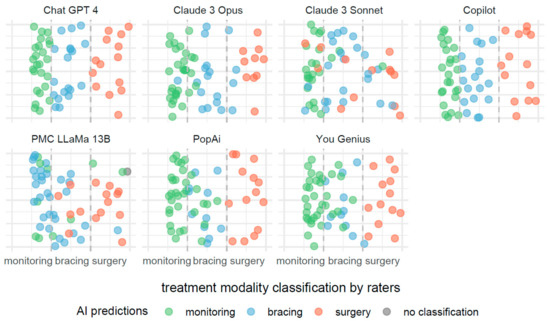
Figure 4.
Comparative efficacies of AI systems in predicting scoliosis treatment modalities from Cobb angle measurements.
4. Discussion
Our scientific hypothesis has been partially confirmed. We hypothesized that all the models would accurately classify scoliosis based on the Cobb angle measurement and that each model would correctly propose therapeutic procedures depending on the severity of the scoliosis. Data analysis revealed that some AI systems, such as ChatGPT 4, Copilot, and PopAi, achieved full compliance with reference levels, precisely replicating the recommended Cobb angle ranges for determining the severity of the condition and the corresponding treatment methods. However, other systems, such as Gemini, Gemini Advanced, and Claude 3 Sonnet, showed deviations from the accepted standards. Furthermore, the PMC-LLaMA 13B system significantly expanded the range for moderate scoliosis, which may impact clinical decisions by potentially delaying therapeutic interventions. These results indicate the varied capabilities of the models for clinical application and underscore the need for their further adjustment and improvement.
4.1. Analysis of Results and Hypotheses
The results of our study highlight significant variability in the performances of different AI models in classifying scoliosis severity and recommending therapeutic approaches. The performance discrepancies among the models can be attributed to several factors related to the underlying architecture, training data, and inherent biases in the models.
4.2. Analysis of AI Systems’ Alignments with Reference Classification Standards
ChatGPT 4, Copilot, and PopAi are in complete harmony with the reference levels, mirroring these intervals exactly. This perfect alignment suggests that these AI systems either derive their classification guidelines directly from the reference standards or have been calibrated to adhere strictly to these widely accepted thresholds.
Systems such as Gemini, Gemini Advanced, Claude 3 Sonnet, and PMC-LLaMA 13B exhibit deviations from the reference intervals. Gemini and Gemini Advanced, along with Claude 3 Sonnet, propose a lower bound for mild scoliosis, starting from 10 degrees. This suggests a more sensitive approach, potentially leading to earlier detection and monitoring.
However, it is PMC-LLaMA 13B that stands out as the most divergent, extending the moderate category up to 50 degrees, which notably delays the classification of severe scoliosis. Such an expansive range for moderate scoliosis could impact clinical decision-making, potentially altering the timing of interventions.
Meanwhile, You Research, You GPT 4, and You Genius, along with Claude 3 Opus, stipulate lower thresholds for mild scoliosis, starting at 10 degrees, and adjust the upper limit of moderate scoliosis to 39 or 40 degrees. For severe scoliosis, these systems align closely with the reference level, setting the threshold at 40 degrees or higher. Their moderate category intervals are slightly narrower than the reference range, which could suggest a tendency toward a more cautious approach to classification.
4.3. Evaluation of AI Systems’ Treatment Modality Recommendations against Established Clinical Guidelines
ChatGPT 4, Copilot, and PopAi demonstrate exact alignment with the reference levels across all the treatment modalities. Their classification thresholds for monitoring, bracing, and surgery are in strict accordance with the reference standards, indicating that these AI systems may be following the established clinical guidelines closely or have been configured to replicate these thresholds precisely.
You Research, You GPT 4, and You Genius introduce a more nuanced approach, initiating monitoring at a Cobb angle of 10 degrees and extending bracing recommendations to patients with Cobb angles as high as 45 degrees. Surgery is then recommended for angles greater than 45 degrees in the cases of You Research and You Genius and at 40 degrees or more for You GPT 4. This suggests an inclination toward a more conservative approach, potentially offering bracing to a broader range of patients in an effort to prevent progression to surgery.
Claude 3 Opus opts for a slightly different approach by recommending monitoring for patients with a Cobb angle of less than 25 degrees, bracing for those with angles between 25 and 45 degrees, and surgery for those with angles greater than 45 degrees. This system’s decision to extend the monitoring threshold to 25 degrees may allow for a larger window of observation before initiating bracing.
Claude 3 Sonnet and PMC-LLaMA 13B deviate significantly from the reference levels by adjusting the upper limit for bracing to 50 degrees and, thereby, delaying the recommendation for surgery to angles greater than 50 degrees. This expansive range for bracing suggests a much more conservative surgical approach, potentially reducing the number of patients who might receive surgical recommendations under standard guidelines.
4.4. Comparative Analysis of AI Systems’ Internal Coherences across Severity Classifications and Treatment Recommendations
ChatGPT 4, Copilot, and PopAi display impeccable concordance, mirroring the reference levels with a direct one-to-one correspondence between severity classifications and treatment modalities. For these systems, mild scoliosis (Cobb angle < 20 degrees) aligns with monitoring, moderate scoliosis (20–40 degrees) with bracing, and severe scoliosis (>40 degrees) with surgery. Their adherence to the reference standards suggests a high degree of reliability and consistency, which could be advantageous in clinical settings, where adherence to established guidelines is paramount.
Gemini and Gemini Advanced, however, do not provide treatment modality recommendations, making it impossible to evaluate their concordance in this context. Their absence of treatment recommendations represents a significant gap when considering the utility of an AI system in a clinical decision-making process.
You Research, You GPT 4, and You Genius maintain a fairly consistent approach be-tween severity classifications and treatment recommendations, albeit with a more conservative slant. These systems initiate monitoring and bracing at a lower threshold (10 degrees for monitoring and 25 degrees for bracing), which could lead to earlier intervention. However, the upper limit for bracing extends to 45 degrees, suggesting a higher threshold for considering surgery. You Research and You Genius set the boundary for surgery at >45 degrees, whereas You GPT 4 aligns with the reference level at ≥40 degrees. Their conservative approach could be seen as being beneficial or overly cautious, depending on clinical outcomes and individual patient scenarios.
Claude 3 Opus and Claude 3 Sonnet exhibit discrepancies in their classifications and treatment recommendations, particularly in the transition from bracing to surgery. Claude 3 Opus begins monitoring under 25 degrees—higher than the reference—and extends bracing to 45 degrees, potentially delaying surgical intervention. Claude 3 Sonnet’s treatment modalities span the broadest range, with bracing recommended up to 50 degrees, which may significantly delay the point at which surgery is considered.
PMC-LLaMA 13B stands apart with its unique classification and treatment recommendation intervals. It extends the moderate severity and bracing categories to a Cobb angle of 50 degrees, the highest among the AI systems. This could potentially result in a substantial reduction in surgical recommendations, which might be seen either as an advantage by minimizing invasive procedures or a disadvantage by potentially postponing necessary surgeries.
4.5. Overall Conclusions
ChatGPT 4, Copilot, and PopAi exhibit the best agreement, reflecting the reference standards without deviation. This could facilitate their seamless integration into clinical practice, where guidelines are strictly followed. PMC-LLaMA 13B, with its significantly broader ranges for moderate severity and bracing, represents the furthest departure from the standard, which may hinder its applicability in traditional clinical settings without careful consideration of its more conservative treatment thresholds.
4.6. Training Data and Domain Specialization
The superior performances of ChatGPT 4, Copilot, and PopAi can be mostly attributed to their extensive training on diverse datasets, which likely include a substantial amount of medical literature and case studies. These models appear to have been fine-tuned with a more extensive array of medical data, enabling them to achieve perfect alignment with reference standards. In contrast, PMC-LLaMA 13B, despite being a specialized medical model, showed significant deviations. This could be because of the model’s training dataset, which, although large, might not be as diverse or comprehensive in covering various clinical scenarios of scoliosis compared to generalist models with broader training data ranges.
An additional finding pertains to context retention. PMC-LLaMA 13B appears to exhibit a limited context window, hindering its ability to maintain coherence over extended textual passages or complex, multi-component queries. This limitation results in responses that may be less accurate or irrelevant. Conversely, ChatGPT 4, Copilot, and PopAi demonstrate superior performances in this aspect, maintaining a reasonable understanding of the conversation throughout prolonged interactions.
However, a consistent issue was observed across all the models. When queried about treatment standards or the scope of Cobb’s angles, despite providing accurate definitions, they often failed to adhere to the rules they had established. This suggests a general difficulty in utilizing their knowledge as a conversational reference, prioritizing prompt-driven responses over autonomous decision-making based on established medical knowledge. Such autonomy is particularly crucial for medical specialists, who must adhere to established treatment protocols.
The superior performances of general AI models, like ChatGPT 4, Copilot, and PopAi, in medical applications can be attributed to their training on diverse datasets, which include extensive medical literature and case studies. This broad training data range enables them to align closely with reference standards. On the other hand, specialized models, such as PMC-LLaMA 13B, despite being designed for medical applications, may have limitations if their training datasets lack diversity or comprehensive coverage of clinical scenarios. The impact of training data on AI model performance in medical applications is highlighted in studies, where models trained on diverse datasets show improved outcomes compared to those trained on narrower datasets [47].
Because of its training on a dataset comprising articles and medical textbooks, PMC-LLaMA 13B may exhibit inherent biases that influence its responses. This model necessitates specific prompt structuring for optimal performance, particularly when dealing with specialized and heterogeneous datasets that encompass diverse approaches to a given problem. When presented with a question, this model tends to prioritize the most frequently encountered answer within the training data, potentially overlooking more relevant or accurate answers. This phenomenon is exemplified in scenarios, such as determining Cobb’s angle measurements, where the model consistently favors the most common metric despite the availability of alternative valid approaches.
4.7. Model Architecture and Complexity
The architecture of the models plays a crucial role in their performance. Models like ChatGPT 4 and Copilot, which are based on advanced transformer architectures, can better capture complex patterns and relationships in data. This architectural advantage likely contributes to their higher accuracies and consistencies in classification and treatment recommendation tasks. On the other hand, PMC-LLaMA 13B, despite being a large and complex model, might face issues with overfitting or underfitting because of its specific training regimen, leading to poorer performance in certain categories.
The hypothesis that model architecture and complexity significantly influence the performances of AI models in classification and treatment recommendation tasks is supported by several studies.
4.8. Transformer Models and Advanced Architectures
Transformer-based models, such as ChatGPT 4 and Copilot, are designed to capture complex patterns and relationships in data because of their advanced architectural features. For instance, the Vision Transformer (ViT) model has been shown to outperform traditional models, like ResNet-50, in tasks such as trash classification because of its extensive set of parameters, leading to higher precision [48]. Similarly, the Deconv-transformer (DecT) model, which combines color deconvolution and a transformer architecture, has demonstrated improved performance in histopathological image classification for breast cancer [49].
4.9. Impact on Medical Applications
Transformer models’ abilities to process and integrate large and diverse datasets makes them particularly effective in medical applications. The use of transformer architectures has been shown to improve the intelligibility and explainability of AI models in medical contexts, addressing some of the limitations of traditional convolutional neural networks (CNNs) [50]. Moreover, studies have highlighted that models like DeiT and PVTv2, which are based on transformer architectures, achieve high accuracy in medical image classification tasks, further demonstrating the efficacy of these advanced architectures [51].
It is noteworthy that transformer-based models exhibit significant variation in the number of parameters. Although an increased parameter count does not invariably correlate with superior model performance [52], the substantial difference between PMC-LLaMA 13B (13 billion parameters) and ChatGPT 4 (1.76 trillion parameters) is notable.
Several techniques, such as parameter sharing [53], can be employed to enhance model accuracy independent of parameter quantity. Nevertheless, a considerable performance disparity persists because of the vast difference in the architectural size. This discrepancy poses a significant barrier to accessibility for independent businesses and medical professionals who seek to develop custom models without incurring the substantial computational and financial costs associated with training such large-scale models.
In summary, the literature supports the hypothesis that the architecture and complexity of AI models play a crucial role in their performances in classification and treatment recommendation tasks, particularly when comparing advanced transformer models to more traditional architectures.
4.10. Prompt Engineering and Model Instructions—Impact of Prompt Engineering
Prompt engineering plays a crucial role in enhancing the performance and accuracy of AI models, like ChatGPT and Copilot. Properly formulated instructions have been shown to significantly improve the performances of AI models across various domains. For instance, the accuracy of ChatGPT on the Fundamentals of Engineering (FE) Environmental Exam improved through effective prompt engineering [54]. Additionally, in medical education, the precise formulation of prompts was essential for obtaining quality responses from AI models [55].
4.11. Model-Specific Improvements
Custom instructional prompts have also been shown to enhance AI model performance in specialized applications. For example, the use of custom prompts improved GPT 4’s ability to address geotechnical problems, achieving a higher problem-solving accuracy compared to zero-shot learning and chain-of-thought strategies [56]. Similarly, in pharmacogenomics, an AI assistant developed with GPT 4 outperformed ChatGPT 3.5 in addressing provider-specific queries requiring specialized data and citations, demonstrating the impact of tailored prompt engineering [57].
Regarding PMC-LLaMA 13B, the necessity for a specific prompt structure introduced significant constraints to the engineering process. Queries were required to be submitted individually because of the model’s inability to process multiple questions simultaneously in contrast to models, like Claude 3 Opus or Gemini, which demonstrated proficiency in handling such structured inquiries. Additionally, the prescribed prompt template elicited repetitive responses from the model, with minor variations in questions leading to diminishing informational value over time. This suggests that PMC-LLaMA 13B may be better suited for single-question tasks, such as isolated evaluations over short durations.
4.12. Model Sensitivity and Threshold Adjustments
The sensitivity of models to detect scoliosis and propose treatments can vary based on how their thresholds are set for different categories. Models like Gemini and Claude 3 Sonnet, which set lower thresholds for mild scoliosis, could be aiming for earlier detection and intervention, which might explain their deviations from the standard references. This sensitivity adjustment can lead to higher false positives but could be beneficial in a clinical setting, where early intervention is critical.
The hypothesis that sensitivity and threshold adjustments in AI models can significantly impact their performances in detecting scoliosis and recommending treatments is supported by various studies in the broader context of medical applications.
4.13. Threshold and Sensitivity Adjustments
Adjusting the sensitivity and thresholds in AI models is crucial for optimizing their performances. For example, the study on the HeartLogic™ algorithm demonstrated that the early detection of fluid retention in chronic heart failure patients could be enhanced by optimizing the sensitivity settings, which provided significant clinical benefits despite the risk of false positives [58].
4.14. False Positives and Clinical Benefits
High sensitivity in AI models often leads to increased false positives, but this tradeoff can be beneficial in clinical settings, where early detection is critical. In a study on cancer detection using AI models, thresholds were adjusted for each of seven protein tumor markers, significantly reducing false positives and increasing specificity from 56.9% to 92.9% [59]. Similarly, in breast cancer diagnostics, AI models improved diagnostic accuracy and reduced unnecessary biopsies by up to 20% by setting clinically relevant risk thresholds [60].
4.15. Clinical Decision Support Systems
Sensitivity adjustments in clinical decision support systems have shown to be effective in the early detection of acute conditions. For instance, a clinical decision support system optimized for the early detection of acute kidney injury demonstrated that higher sensitivity settings could ensure early detection, though it might lead to alert fatigue among physicians because of increased false positive alerts [61].
These studies collectively support the hypothesis that sensitivity and threshold adjustments are critical in optimizing AI model performance, particularly in medical applications, where early detection and intervention are vital.
4.16. Internal Coherence and Algorithm Calibration
The internal coherence of the AI models in aligning their severity classifications with treatment recommendations is another critical factor. Models showing high internal coherence, like ChatGPT 4 and Copilot, indicate well-calibrated algorithms that can reliably map severity levels to appropriate treatments. In contrast, models like PMC-LLaMA 13B, which showed significant divergence in their recommendations, might require further calibration to improve their clinical reliability.
The hypothesis that internal coherence and algorithm calibration significantly impact the performances of AI models in severity classifications and treatment recommendations is supported by several studies.
The significance of the internal coherence and calibration in enhancing AI model performance is evident across various domains. A study on IT incident risk prediction demonstrated that a transformer model, calibrated for multiple severity levels, achieved an impressive AUC score of 98%, outperforming other machine-learning and deep-learning models [62]. This finding underscores the critical role of calibration in achieving accurate and reliable predictions.
Similar benefits of well-calibrated algorithms were observed in a hybrid ensemble machine-learning model developed for severity risk assessment and post-COVID prediction [63]. By ensuring accurate severity classifications and treatment recommendations, the calibrated model enhanced clinical decision-making processes.
Furthermore, in a study on automated myocardial scar quantification, an AI-based approach demonstrated comparable prognostic values to manual quantification when calibrated for clinical reliability [64]. This highlights the importance of calibration in maintaining clinical accuracy and consistency.
The impact of the calibration extends for predicting the severity of traffic crash injuries, as demonstrated in a study utilizing an ordinal classification machine-learning approach [65]. The calibrated models significantly outperformed their uncalibrated counterparts in predicting the crash injury severity, reinforcing the need for well-calibrated algorithms to achieve accurate outcomes.
These studies collectively emphasize the crucial roles of the internal coherence and calibration in optimizing AI model performance across various domains, including IT incident risk assessment, clinical decision-making, medical image analysis, and traffic safety prediction.
However, it is important to acknowledge that most of these models are proprietary and maintained solely by the developing companies. This limits external control over fine-tuning these critical aspects, making it challenging to tailor them to specific preferences or use cases.
However, retrieval-augmented generation (RAG) techniques offer a potential solution by enabling models to prioritize and utilize custom knowledge bases, thereby enhancing their relevance and accuracy for specific domains or tasks. Additionally, customizable models, like OpenAI’s Custom GPTs and Google’s Gems, provide opportunities for greater control and personalization, allowing users to adapt these models to better align with their unique requirements and preferences.
4.17. Implications for Clinical Practice
The findings of our study have several implications for the integration of AI in clinical practice, particularly in the management of scoliosis as follows:
- Adoption of High-Performing Models: Models like ChatGPT 4, Copilot, and PopAi, which demonstrated high alignment with reference standards, could be adopted more readily in clinical settings. Their reliability and consistency make them suitable for aiding healthcare professionals in diagnostic and therapeutic decision-making processes;
- Need for Continuous Model Evaluation and Calibration: Continuous evaluation and recalibration of AI models are essential to maintain their clinical relevance and accuracy. Models like PMC-LLaMA 13B, which showed lower performance, need ongoing refinement, incorporating more diverse and representative training data to enhance their predictive capabilities;
- Tailoring AI to Specific Clinical Needs: Different clinical scenarios might require different AI capabilities. For instance, models with lower thresholds for detecting mild scoliosis could be preferred in preventive care settings, while those with stricter thresholds might be more suitable for specialized surgical planning;
- Ethical Considerations and Bias Mitigation: Ensuring that AI models do not propagate biases present in their training data is crucial. Diverse and representative training datasets, coupled with robust ethical guidelines, are necessary to develop AI systems that provide equitable and unbiased healthcare recommendations.
In summary, this study underscores the potential and challenges for using AI models in the classification and management of scoliosis. Although certain models have demonstrated exceptional performance, consistent with clinical standards, others require further development and calibration. The continuous advancement of AI technology, driven by comprehensive training data and precise algorithm design, holds promise for significantly enhancing clinical decision-making and patient care in scoliosis management.
The study by Huo et al. (2024) provides intriguing insights into the effectiveness of LLM-linked chatbots in the surgical management of gastroesophageal reflux disease (GERD), comparing the performances of ChatGPT 3.5, ChatGPT 4, Copilot, Google Bard, and Perplexity AI against SAGES guidelines. Google Bard demonstrated the highest alignment with these guidelines, achieving 85.7% accuracy for adult surgeons, 80.0% for adult patients, 100.0% for pediatric surgeons, and 50.0% for pediatric patients. Comparatively, other studies in different medical contexts, such as chronic disease management and diagnostics, also show variable LLM performances, with specialized models, like ChatGPT 4, often outperforming their predecessors. This study highlights that although models like Google Bard perform well, the efficacy of LLMs can vary significantly based on the clinical context and specificity of their training. This underscores the need for ongoing refinement and training of LLMs with evidence-based health information to enhance their accuracy and usefulness in clinical practice, ensuring their maximum potential is realized in healthcare settings [66].
The variability in recommendations provided by LLMs poses significant limitations on their applications to medical data classification, as demonstrated by the study on hearing diagnoses using ChatGPT 3.5 and 4. That study evaluated the accuracy and repeatability of those models in answering objective hearing test questions over multiple days. Despite ChatGPT 4 showing a higher accuracy (65–69%) compared to that of ChatGPT 3.5 (48–49%), both models exhibited notable variabilities in their responses. Within a single day, the agreement percentage was higher for ChatGPT 4 (87–88%) than for ChatGPT 3.5 (76–79%), and similar trends were observed across different days. However, the inconsistencies in the response repeatability, as evidenced by Cohen’s kappa values, cast doubt on the reliability of these models for professional medical applications. This underscores a critical challenge in using LLMs for medical data, where consistent and accurate recommendations are paramount. Further refinement and more rigorous training with specialized datasets are essential to mitigate these limitations and enhance the reliability of LLMs in clinical settings [67].
4.18. Limitations
Our research project encountered several limitations that could have influenced the results and interpretations as follows:
Dependence on Descriptive Accuracy: The accuracy and effectiveness of the AI models in classifying scoliosis and suggesting therapeutic measures rely substantially on the precision and detail of the radiological descriptions provided. Any inconsistencies, omissions, or subjective interpretations in these descriptions could significantly impact the AI’s performance;
Limitations of Textual Data: Unlike direct image analysis, using textual descriptions may limit the AI’s ability to detect nuanced visual cues that could be crucial for accurate diagnosis and classification. This method may omit subtle details that are typically assessed visually by a trained specialist;
Complexity in Therapeutic Suggestions: Suggesting appropriate therapeutic interventions based purely on textual descriptions without direct visual assessment may limit the depth of the AI’s recommendations. This could be particularly challenging when dealing with complex cases, where multiple factors influence the treatment decision;
Regulatory and Ethical Considerations: The deployment of AI systems in medical settings involves regulatory approvals that ensure the safety and efficacy of the technology. Ethical considerations, such as patient consent and the potential for AI to make erroneous recommendations, also need to be addressed comprehensively;
Comparison with Dedicated Medical Models: Although this study compares OSAIMs with a dedicated medical model (PMC-LLaMA 13B), differences in training datasets, model architectures, and tuning might affect the fairness of the comparison. Dedicated models are often optimized for specific tasks and might have access to proprietary datasets that are not available for OSAIMs;
Scalability and Hardware Requirements: Implementing AI solutions in clinical practice can be limited by the need for substantial computational resources. The models evaluated, particularly the more complex ones, like PMC-LLaMA 13B, require high-end GPUs and specific software environments, which may not be readily available in all clinical settings.
These limitations highlight important considerations for the use of AI in interpreting radiological descriptions and underscore the necessity for the rigorous validation and continuous improvement of AI systems in clinical settings.
5. Conclusions
Our study underscores the diverse capabilities of AI models in scoliosis classification and therapeutic recommendation. Although models such as ChatGPT 4, Copilot, and PopAi demonstrated high alignment with clinical standards because of extensive and diverse training data, others, like PMC-LLaMA 13B, showed significant deviations, particularly in expanding the range for moderate scoliosis, which could delay therapeutic interventions. This variability highlights the importance of continuous evaluation and recalibration, emphasizing the need for incorporating more diverse and representative training datasets. Advanced transformer architectures used in models like ChatGPT 4 and Copilot play a crucial role in their superior performances, enabling them to capture complex patterns and relationships in data more effectively than simpler models. However, all the models exhibited challenges in maintaining consistency with established medical standards in their responses, indicating the need for improved autonomy in decision-making based on medical knowledge. Ethical considerations, bias mitigation, and the scalability of AI solutions are also critical, as the deployment of AI in clinical settings involves regulatory approvals and ensuring equitable and unbiased healthcare recommendations. These findings point to the necessity of the rigorous validation and continuous improvement of AI systems to enhance their clinical reliability and relevance, ensuring they can effectively support healthcare professionals in diagnostic and therapeutic decision-making processes.
Author Contributions
Conceptualization, A.F., R.F. and A.Z.-F.; methodology, A.F., R.F., A.Z.-F. and B.P.; investigation, A.F., B.P., A.Z.-F. and R.F.; data curation, A.F. and B.P.; writing—original draft preparation, A.F., A.Z.-F., B.P. and R.F.; writing—review and editing, A.F., A.Z.-F., R.F., B.P., E.N. and K.Z.; supervision, B.P., K.Z. and E.N.; funding acquisition, A.F., A.Z.-F., E.N., K.Z. and B.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data are contained within the article.
Acknowledgments
Many thanks are extended to Agnieszka Strzała for linguistic proofreading and to Robert Fabijan for the substantive support in the field of AI and for assistance in designing the presented study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Uppalapati, V.K.; Nag, D.S. A Comparative Analysis of AI Models in Complex Medical Decision-Making Scenarios: Evaluating ChatGPT, Claude AI, Bard, and Perplexity. Cureus 2024, 16, e52485. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Huang, C.; Wang, D.; Li, K.; Han, X.; Chen, X.; Li, Z. Artificial Intelligence in Scoliosis: Current Applications and Future Directions. J. Clin. Med. 2023, 12, 7382. [Google Scholar] [CrossRef] [PubMed]
- Zong, H.; Li, J.; Wu, E.; Wu, R.; Lu, J.; Shen, B. Performance of ChatGPT on Chinese national medical licensing examinations: A five-year examination evaluation study for physicians, pharmacists and nurses. BMC Med. Educ. 2024, 24, 143. [Google Scholar] [CrossRef]
- Saravia-Rojas, M.Á.; Camarena-Fonseca, A.R.; León-Manco, R.; Geng-Vivanco, R. Artificial intelligence: ChatGPT as a disruptive didactic strategy in dental education. J. Dent. Educ. 2024, 88, 872–876. [Google Scholar] [CrossRef]
- Pradhan, F.; Fiedler, A.; Samson, K.; Olivera-Martinez, M.; Manatsathit, W.; Peeraphatdit, T. Artificial intelligence compared with human-derived patient educational materials on cirrhosis. Hepatol. Commun. 2024, 8, e0367. [Google Scholar] [CrossRef] [PubMed]
- Masalkhi, M.; Ong, J.; Waisberg, E.; Lee, A.G. Google DeepMind’s gemini AI versus ChatGPT: A comparative analysis in ophthalmology. Eye 2024, 38, 1412–1417. [Google Scholar] [CrossRef] [PubMed]
- Maniaci, A.; Fakhry, N.; Chiesa-Estomba, C.; Lechien, J.R.; Lavalle, S. Synergizing ChatGPT and general AI for enhanced medical diagnostic processes in head and neck imaging. Eur. Arch. Otorhinolaryngol. 2024, 281, 3297–3298. [Google Scholar] [CrossRef] [PubMed]
- Morreel, S.; Verhoeven, V.; Mathysen, D. Microsoft Bing outperforms five other generative artificial intelligence chatbots in the Antwerp University multiple choice medical license exam. PLoS Digit Health 2024, 3, e0000349. [Google Scholar] [CrossRef]
- Zakka, C.; Shad, R.; Chaurasia, A.; Dalal, A.R.; Kim, J.L.; Moor, M.; Fong, R.; Phillips, C.; Alexander, K.; Ashley, E.; et al. Almanac—Retrieval-Augmented Language Models for Clinical Medicine. NEJM AI 2024, 1. [Google Scholar] [CrossRef]
- Aiumtrakul, N.; Thongprayoon, C.; Arayangkool, C.; Vo, K.B.; Wannaphut, C.; Suppadungsuk, S.; Krisanapan, P.; Garcia Valencia, O.A.; Qureshi, F.; Miao, J.; et al. Personalized Medicine in Urolithiasis: AI Chatbot-Assisted Dietary Management of Oxalate for Kidney Stone Prevention. J. Pers. Med. 2024, 14, 107. [Google Scholar] [CrossRef]
- Kassab, J.; Hadi El Hajjar, A.; Wardrop, R.M., 3rd; Brateanu, A. Accuracy of Online Artificial Intelligence Models in Primary Care Settings. Am. J. Prev. Med. 2024, 66, 1054–1059. [Google Scholar] [CrossRef]
- Noda, R.; Izaki, Y.; Kitano, F.; Komatsu, J.; Ichikawa, D.; Shibagaki, Y. Performance of ChatGPT and Bard in self-assessment questions for nephrology board renewal. Clin. Exp. Nephrol. 2024, 28, 465–469. [Google Scholar] [CrossRef] [PubMed]
- Abdullahi, T.; Singh, R.; Eickhoff, C. Learning to Make Rare and Complex Diagnoses with Generative AI Assistance: Qualitative Study of Popular Large Language Models. JMIR Med. Educ. 2024, 10, e51391. [Google Scholar] [CrossRef] [PubMed]
- Google Gemini AI. The Future of Artificial Intelligence. Available online: https://digitalfloats.com/google-gemini-the-future-of-440artificial-intelligence/ (accessed on 10 April 2024).
- Gemini. Available online: https://gemini.google.com/advanced?utm_source=deepmind&utm_medium=owned&utm_cam-442paign=gdmsite_learn (accessed on 10 April 2024).
- You Chat: What Is You Chat? Available online: https://about.you.com/introducing-youchat-the-ai-search-assistant-that-lives-in-your-search-engine-eff7badcd655/ (accessed on 10 April 2024).
- Albagieh, H.; Alzeer, Z.O.; Alasmari, O.N.; Alkadhi, A.A.; Naitah, A.N.; Almasaad, K.F.; Alshahrani, T.S.; Alshahrani, K.S.; Almahmoud, M.I. Comparing Artificial Intelligence and Senior Residents in Oral Lesion Diagnosis: A Comparative Study. Cureus 2024, 16, e51584. [Google Scholar] [CrossRef]
- Constitutional AI: Harmlessness from AI Feedback. Available online: https://www.anthropic.com/news/constitutional-ai-harmlessness-from-ai-feedback (accessed on 10 April 2024).
- Rokhshad, R.; Zhang, P.; Mohammad-Rahimi, H.; Pitchika, V.; Entezari, N.; Schwendicke, F. Accuracy and consistency of chatbots versus clinicians for answering pediatric dentistry questions: A pilot study. J. Dent. 2024, 144, 104938. [Google Scholar] [CrossRef] [PubMed]
- Elyoseph, Z.; Levkovich, I. Comparing the Perspectives of Generative AI, Mental Health Experts, and the General Public on Schizophrenia Recovery: Case Vignette Study. JMIR Ment. Health 2024, 11, e53043. [Google Scholar] [CrossRef]
- Wright, B.M.; Bodnar, M.S.; Moore, A.D.; Maseda, M.C.; Kucharik, M.P.; Diaz, C.C.; Schmidt, C.M.; Mir, H.R. Is ChatGPT a trusted source of information for total hip and knee arthroplasty patients? Bone Jt. Open 2024, 5, 139–146. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Lin, W.; Zhang, X.; Zhang, Y.; Xie, W.; Wang, Y. PMC-LLaMA: Toward building open-source language models for medicine. J. Am. Med. Inform. Assoc. 2024, ocae045. [Google Scholar] [CrossRef]
- Hopkins, B.S.; Nguyen, V.N.; Dallas, J.; Texakalidis, P.; Yang, M.; Renn, A.; Guerra, G.; Kashif, Z.; Cheok, S.; Zada, G.; et al. ChatGPT versus the neurosurgical written boards: A comparative analysis of artificial intelligence/machine learning performance on neurosurgical board-style questions. J. Neurosurg. 2023, 139, 904–911. [Google Scholar] [CrossRef]
- Yang, S.; Chang, M.C. The assessment of the validity, safety, and utility of ChatGPT for patients with herniated lumbar disc: A preliminary study. Medicine 2024, 103, e38445. [Google Scholar] [CrossRef]
- Roman, A.; Al-Sharif, L.; Al Gharyani, M. The Expanding Role of ChatGPT (Chat-Generative Pre-Trained Transformer) in Neurosurgery: A Systematic Review of Literature and Conceptual Framework. Cureus 2023, 15, e43502. [Google Scholar] [CrossRef] [PubMed]
- Maharathi, S.; Iyengar, R.; Chandrasekhar, P. Biomechanically designed Curve Specific Corrective Exercise for Adolescent Idiopathic Scoliosis gives significant outcomes in an Adult: A case report. Front. Rehabil. Sci. 2023, 4, 1127222. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; He, Y.; Deng, Z.S.; Yan, A. Improvement of automated image stitching system for DR X-ray images. Comput. Biol. Med. 2016, 71, 108–114. [Google Scholar] [CrossRef] [PubMed]
- Hwang, Y.S.; Lai, P.L.; Tsai, H.Y.; Kung, Y.C.; Lin, Y.Y.; He, R.J.; Wu, C.T. Radiation dose for pediatric scoliosis patients undergoing whole spine radiography: Effect of the radiographic length in an auto-stitching digital radiography system. Eur. J. Radiol. 2018, 108, 99–106. [Google Scholar] [CrossRef] [PubMed]
- Hey, H.W.D.; Ramos, M.R.D.; Lau, E.T.; Tan, J.H.J.; Tay, H.W.; Liu, G.; Wong, H.K. Risk Factors Predicting C-Versus S-shaped Sagittal Spine Profiles in Natural, Relaxed Sitting: An Important Aspect in Spinal Realignment Surgery. Spine 2020, 45, 1704–1712. [Google Scholar] [CrossRef] [PubMed]
- Horng, M.H.; Kuok, C.P.; Fu, M.J.; Lin, C.J.; Sun, Y.N. Cobb Angle Measurement of Spine from X-Ray Images Using Convolutional Neural Network. Comput. Math. Methods Med. 2019, 2019, 6357171. [Google Scholar] [CrossRef] [PubMed]
- Patient Examination AO Surgery Reference. Available online: https://surgeryreference.aofoundation.org/spine/deformities/adolescent-idiopathic-scoliosis/further-reading/patient-examination (accessed on 10 April 2024).
- Fabijan, A.; Polis, B.; Fabijan, R.; Zakrzewski, K.; Nowosławska, E.; Zawadzka-Fabijan, A. Artificial Intelligence in Scoliosis Classification: An Investigation of Language-Based Models. J. Pers. Med. 2023, 13, 1695. [Google Scholar] [CrossRef] [PubMed]
- Fabijan, A.; Fabijan, R.; Zawadzka-Fabijan, A.; Nowosławska, E.; Zakrzewski, K.; Polis, B. Evaluating Scoliosis Severity Based on Posturographic X-ray Images Using a Contrastive Language–Image Pretraining Model. Diagnostics 2023, 13, 2142. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar] [CrossRef]
- Llama-Precise Parameters Guidelines. Available online: https://github.com/oobabooga/text-generation-webui/wiki/03-%E2%80%90-Parameters-Tab (accessed on 10 April 2024).
- PMC-LLaMA Prompt Schema. Available online: https://github.com/chaoyi-wu/pmc-llama (accessed on 10 April 2024).
- Conger, A.J. Integration and generalization of kappas for multiple raters. Psychol. Bull. 1980, 88, 322–328. [Google Scholar] [CrossRef]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378–382. [Google Scholar] [CrossRef]
- Fleiss, J.L.; Levin, B.; Paik, M.C. Statistical Methods for Rates and Proportions, 3rd ed.; John Wiley & Sons: New York, NY, USA, 2003; ISBN 978-0-471-52629-2. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 2 April 2024).
- Gamer, M.; Lemon, J.; Singh, P. irr: Various Coefficients of Interrater Reliability and Agreement, R Package Version 0.84.1, irr. 2019. Available online: https://CRAN.R-project.org/package=irr (accessed on 10 April 2024).
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Sarkar, D. lattice: Multivariate Data Visualization with R; Springer: New York, NY, USA, 2008; ISBN 978-0-387-75968-5. [Google Scholar]
- Makowski, D.; Lüdecke, D.; Patil, I.; Thériault, R.; Ben-Shachar, M.; Wiernik, B. Automated Results Reporting as a Practical Tool to Improve Reproducibility and Methodological Best Practices Adoption. CRAN. 2023. Available online: https://easystats.github.io/report/ (accessed on 10 April 2024).
- Sjoberg, D.; Whiting, K.; Curry, M.; Lavery, J.; Larmarange, J. Reproducible Summary Tables with the gtsummary Package. R J. 2021, 13, 570–580. [Google Scholar] [CrossRef]
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016; ISBN 978-3-319-24277-4. [Google Scholar]
- Chung, H.; Park, C.; Kang, W.S.; Lee, J. Gender Bias in Artificial Intelligence: Severity Prediction at an Early Stage of COVID-19. Front. Physiol. 2021, 12, 778720. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Sun, J.; Zhou, X. Comparison of ResNet-50 and vision transformer models for trash classification. In Proceedings of the Third International Conference on Artificial Intelligence and Computer Engineering (ICAICE 2022), Wuhan, China, 11–13 November 2022; Volume 12610. [Google Scholar]
- He, Z.; Lin, M.; Xu, Z.; Yao, Z.; Chen, H.; Alhudhaif, A.; Alenezi, F. Deconv-transformer (DecT): A histopathological image classification model for breast cancer based on color deconvolution and transformer architecture. Inf. Sci. 2022, 608, 1093–1112. [Google Scholar] [CrossRef]
- Nuobu, G. Transformer model: Explainability and prospectiveness. Appl. Comput. Eng. 2023, 20, 88–99. [Google Scholar] [CrossRef]
- Kanca, E.; Ayas, S.; Kablan, E.B.; Ekinci, M. Performance Comparison of Vision Transformer-Based Models in Medical Image Classification. In Proceedings of the 2023 31st Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkiye, 5–8 July 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Niu, X.; Bai, B.; Deng, L.; Han, W. Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory. arXiv 2024, arXiv:2405.08707v1. [Google Scholar] [CrossRef]
- Gholami, S.; Omar, M. Do Generative Large Language Models need billions of parameters? arXiv 2023, arXiv:2309.06589v1, 6589v1. [Google Scholar] [CrossRef]
- Pursnani, V.; Sermet, Y.; Demir, I. Performance of ChatGPT on the US Fundamentals of Engineering Exam: Comprehensive Assessment of Proficiency and Potential Implications for Professional Environmental Engineering Practice. Comput. Educ. Artif. Intell. 2023, 5, 100183. [Google Scholar] [CrossRef]
- Heston, T.F.; Khun, C. Prompt Engineering in Medical Education. Int. Med. Educ. 2023, 2, 198–205. [Google Scholar] [CrossRef]
- Chen, L.; Tophel, A.; Hettiyadura, U.; Kodikara, J. An Investigation into the Utility of Large Language Models in Geotechnical Education and Problem Solving. Geotechnics 2024, 4, 470–498. [Google Scholar] [CrossRef]
- Murugan, M.; Yuan, B.; Venner, E.; Ballantyne, C.M.; Robinson, K.M.; Coons, J.C.; Wang, L.; Empey, P.E.; Gibbs, R.A. Empowering Personalized Pharmacogenomics with Generative AI Solutions. J. Am. Med. Inform. Assoc. 2024, 31, 1356–1366. [Google Scholar] [CrossRef] [PubMed]
- Feijen, M.; Egorova, A.D.; Beeres, S.L.M.A.; Treskes, R.W. Early Detection of Fluid Retention in Patients with Advanced Heart Failure: A Review of a Novel Multisensory Algorithm, HeartLogicTM. Sensors 2021, 21, 1361. [Google Scholar] [CrossRef] [PubMed]
- Luan, Y.; Zhong, G.; Li, S.; Wu, W.; Liu, X.; Zhu, D.; Feng, Y.; Zhang, Y.; Duan, C.; Mao, M. A panel of seven protein tumour markers for effective and affordable multi-cancer early detection by artificial intelligence: A large-scale and multicentre case-control study. EClinicalMedicine 2023, 61, 102041. [Google Scholar] [CrossRef] [PubMed]
- Witowski, J.; Heacock, L.; Reig, B.; Kang, S.K.; Lewin, A.; Pysarenko, K.; Patel, S.; Samreen, N.; Rudnicki, W.; Łuczyńska, E.; et al. Improving breast cancer diagnostics with deep learning for MRI. Sci. Transl. Med. 2022, 14, eabo4802. [Google Scholar] [CrossRef]
- Handler, S.M.; Kane-Gill, S.L.; Kellum, J.A. Optimal and early detection of acute kidney injury requires effective clinical decision support systems. Nephrol. Dial. Transplant. 2014, 29, 1802–1803. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, S.; Singh, M.; Doherty, B.; Ramlan, E.; Harkin, K.; Coyle, D. Multiple Severity-Level Classifications for IT Incident Risk Prediction. In Proceedings of the 2022 9th International Conference on Soft Computing & Machine Intelligence (ISCMI), Toronto, ON, Canada, 26–27 November 2022; pp. 270–274. [Google Scholar] [CrossRef]
- Shakhovska, N.; Yakovyna, V.; Chopyak, V. A new hybrid ensemble machine-learning model for severity risk assessment and post-COVID prediction system. Math. Biosci. Eng. 2022, 19, 6102–6123. [Google Scholar] [CrossRef]
- Lange, T.; Stiermaier, T.; Backhaus, S.; Boom, P.; Kutty, S.; Bigalke, B.; Hasenfuß, G.; Thiele, H.; Eitel, I.; Schuster, A. Abstract 15535: Automated Artificial Intelligence-based Myocardial Scar Quantification for Risk Assessment Following Myocardial Infarction. Circulation 2020, 142 (Suppl. S3), A15535. [Google Scholar] [CrossRef]
- Zhu, S.; Wang, K.; Li, C. Crash Injury Severity Prediction Using an Ordinal Classification Machine Learning Approach. Int. J. Environ. Res. Public Health 2021, 18, 11564. [Google Scholar] [CrossRef]
- Huo, B.; Calabrese, E.; Sylla, P.; Kumar, S.; Ignacio, R.C.; Oviedo, R.; Hassan, I.; Slater, B.J.; Kaiser, A.; Walsh, D.S.; et al. The performance of artificial intelligence large language model-linked chatbots in surgical decision-making for gastroesophageal reflux disease. Surg. Endosc. 2024, 38, 2320–2330. [Google Scholar] [CrossRef] [PubMed]
- Kochanek, K.; Skarzynski, H.; Jedrzejczak, W.W. Accuracy and Repeatability of ChatGPT Based on a Set of Multiple-Choice Questions on Objective Tests of Hearing. Cureus 2024, 16, e59857. [Google Scholar] [CrossRef] [PubMed]
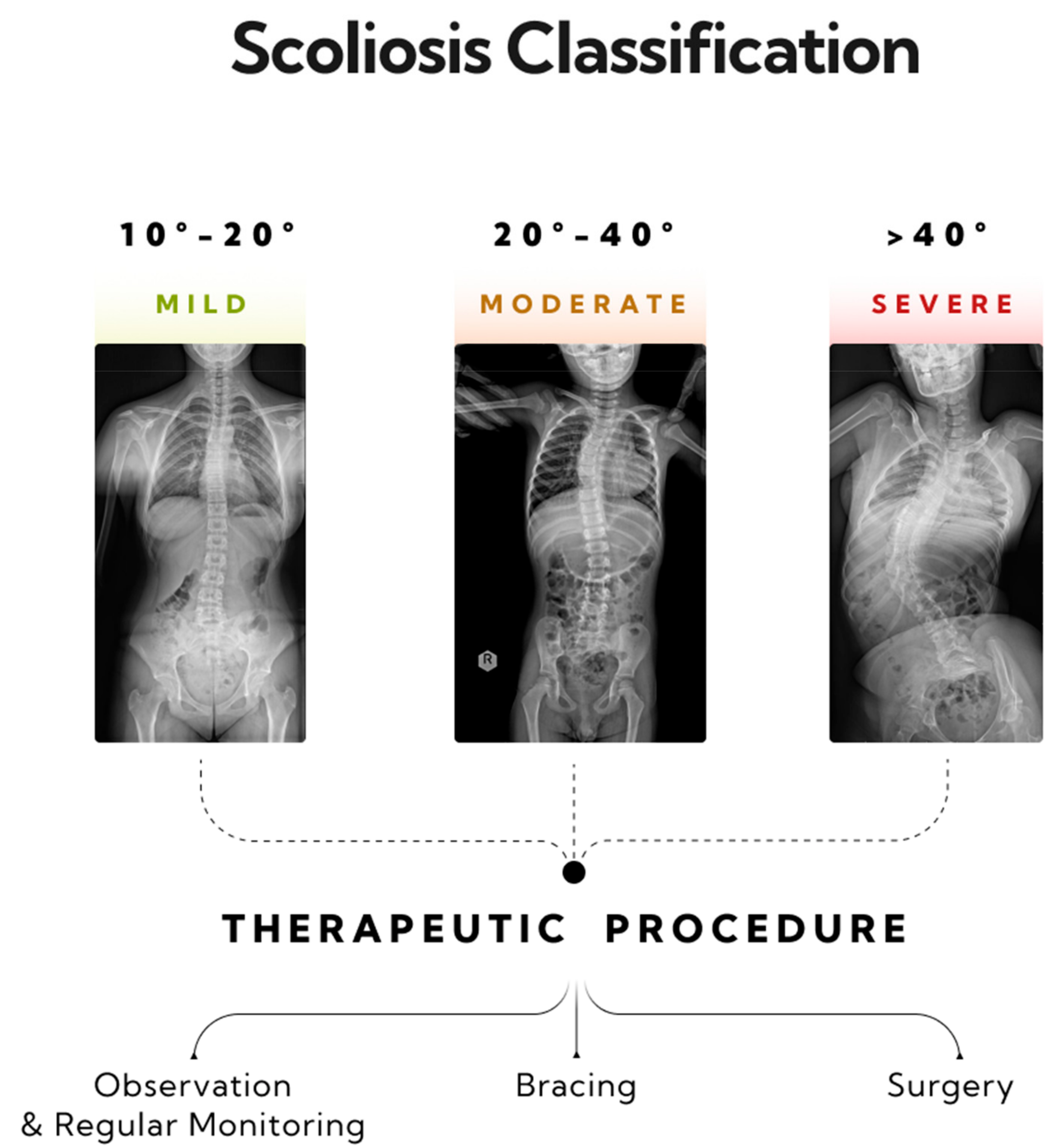
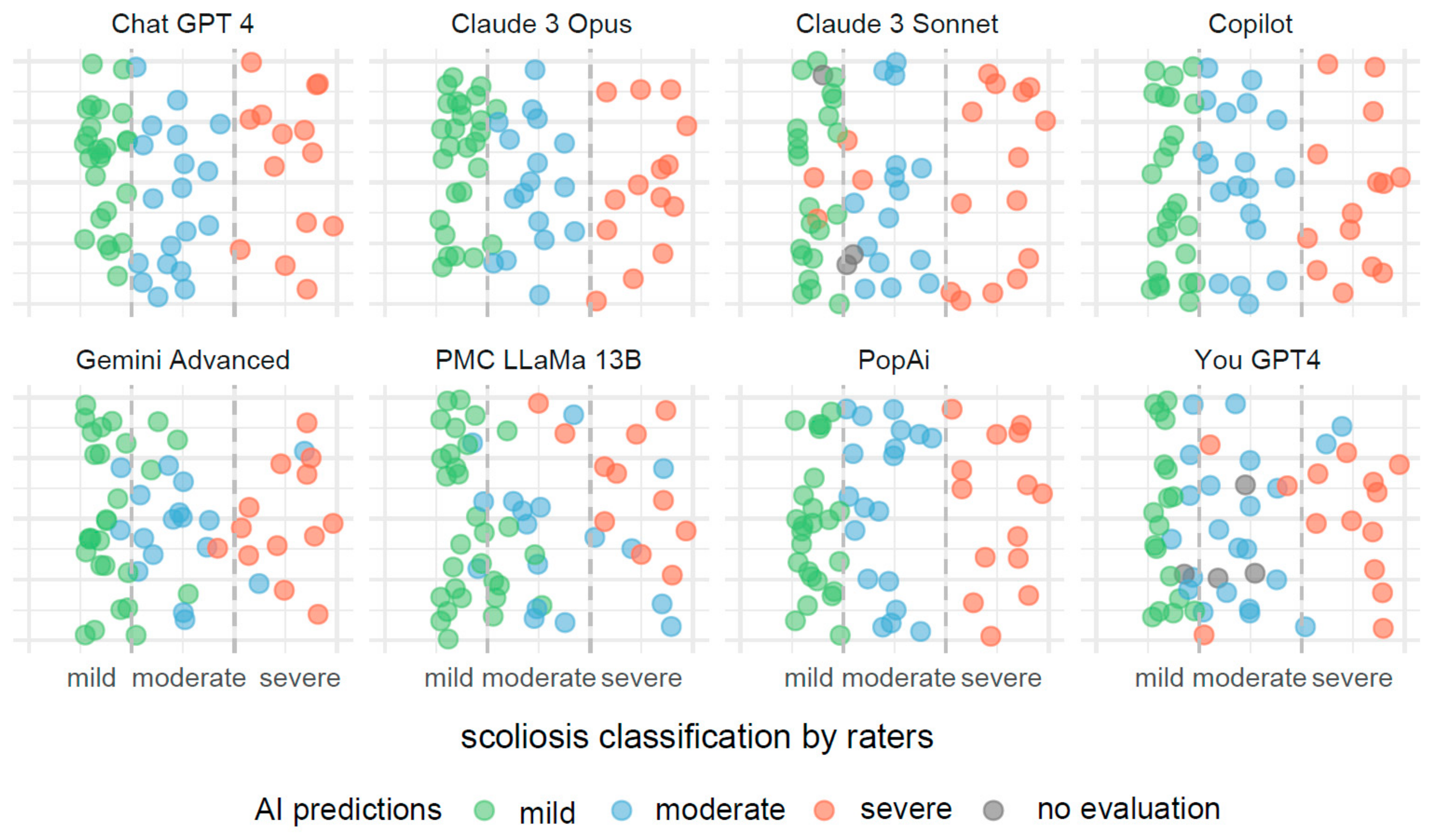
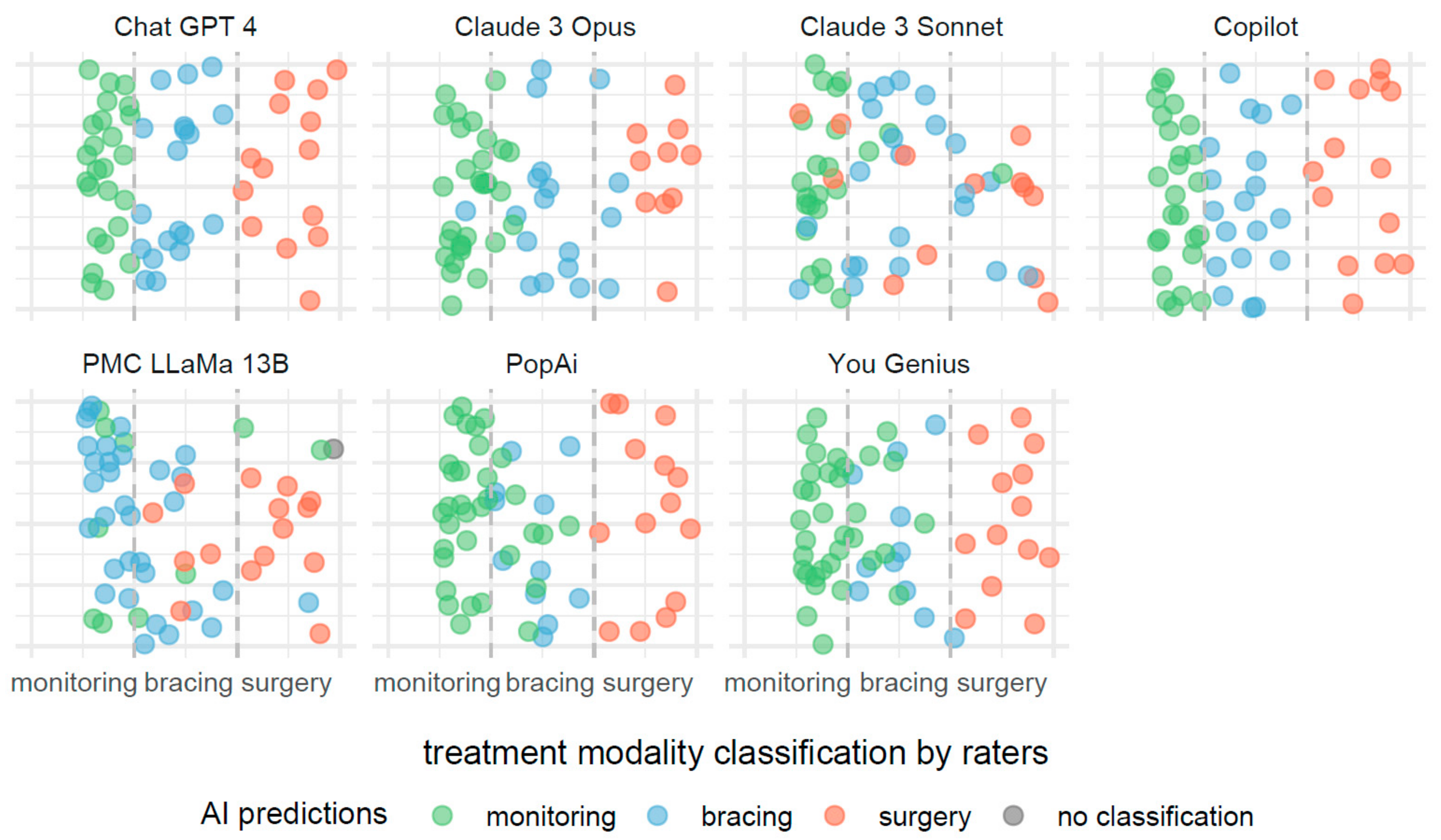
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).