
Automated Chicken Counting in Surveillance Camera Environments Based on the Point Supervision Algorithm: LC-DenseFCN


Abstract
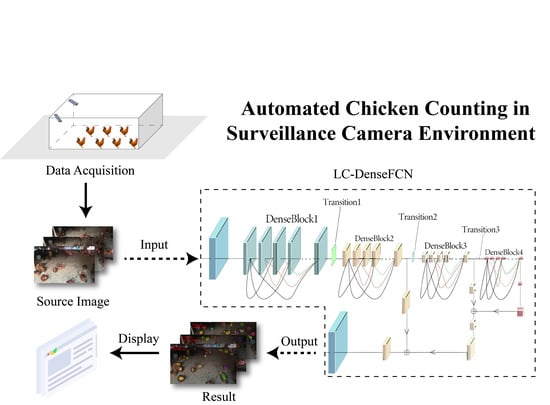
:
1. Introduction
- The motility of the flock makes it difficult to perform a complete count of the flock;
- The process is time consuming.
2. Related Work
2.1. DenseNet
2.2. FCN
2.3. Localization-Based Counting Algorithm
2.4. Object Detection Algorithms for Contrast Experiment
3. Materials and Methods
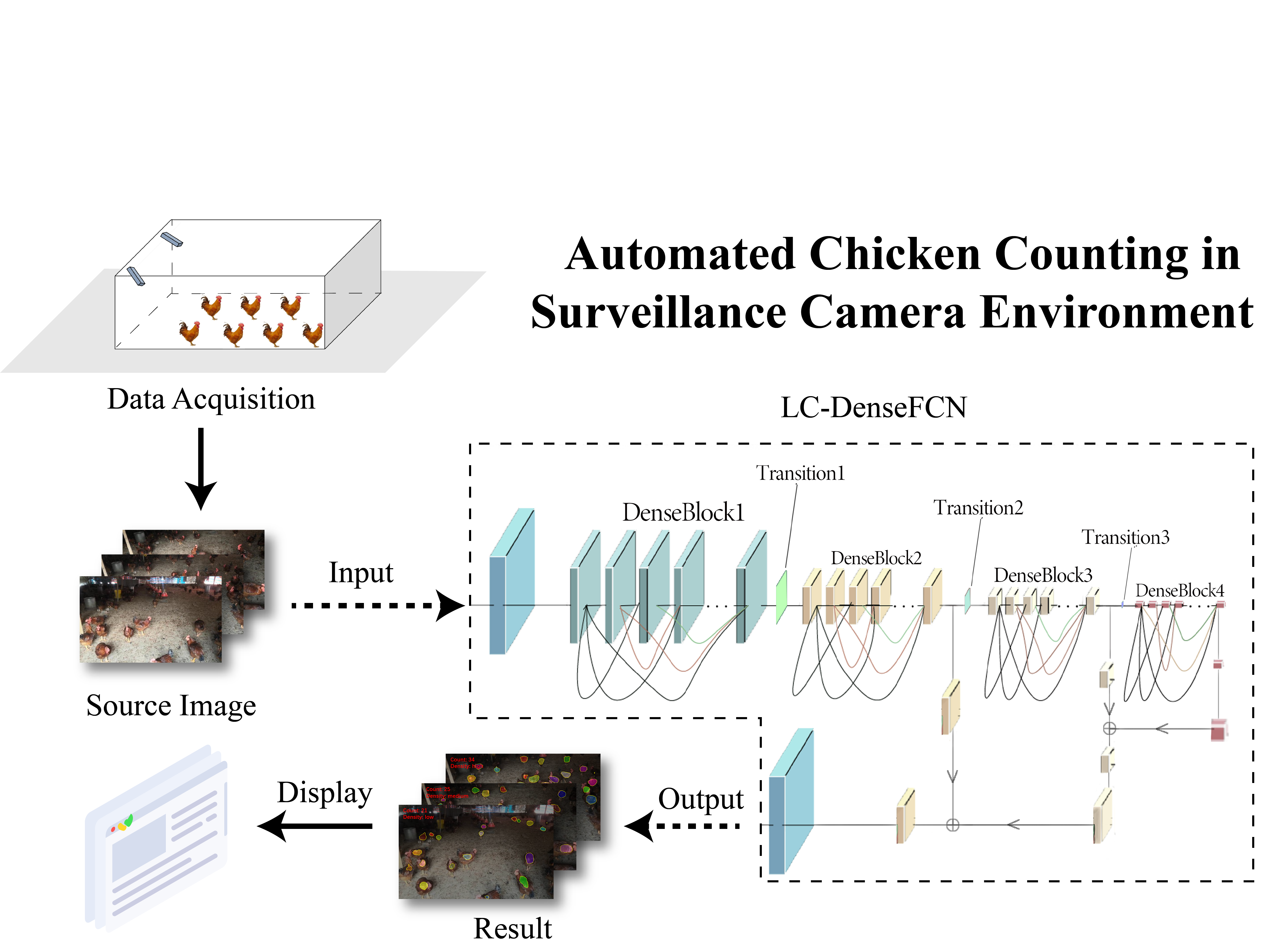
3.1. Overview of Our Framework
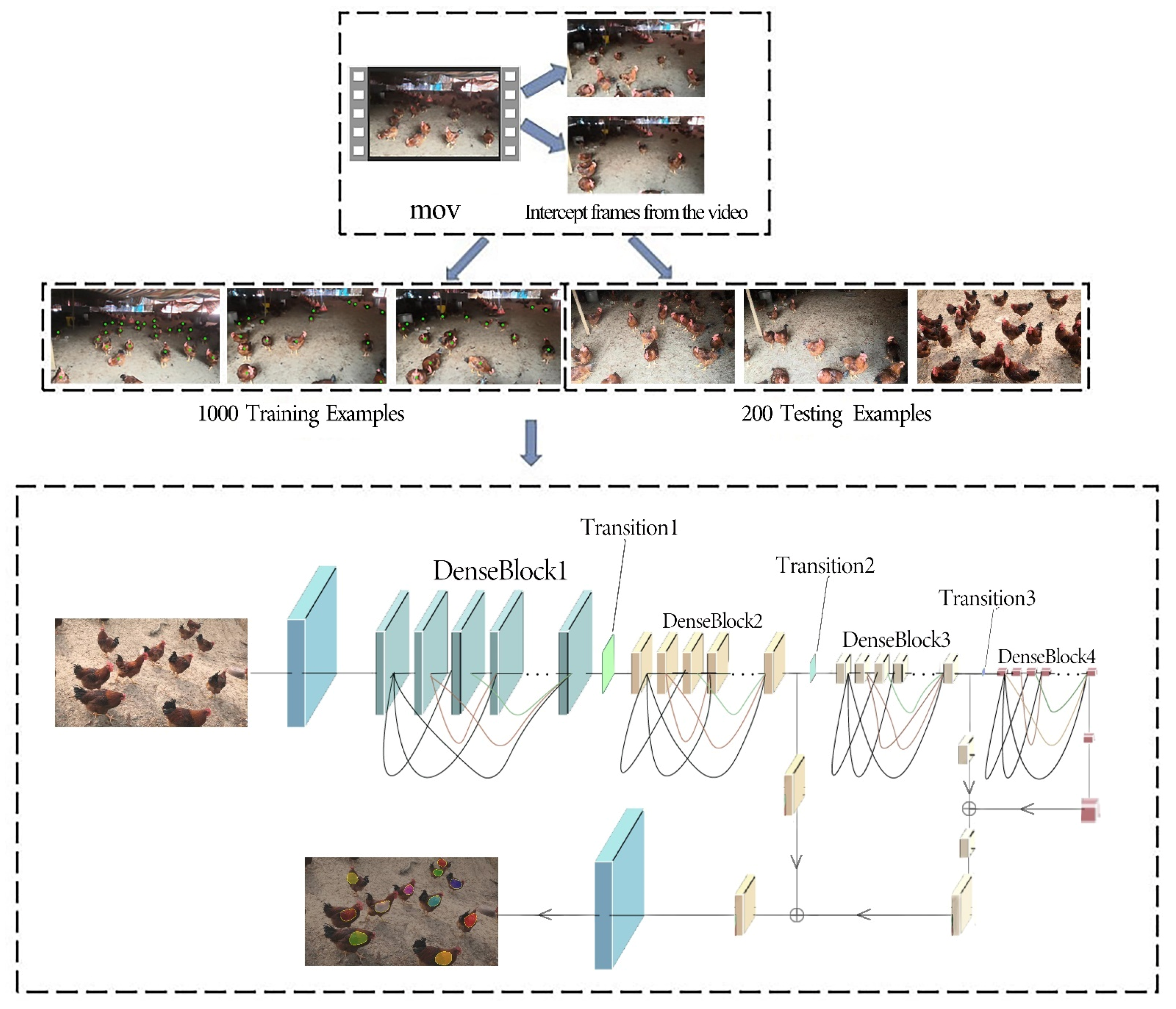
3.2. Dataset Preparation and Pre-Processing
3.3. The Detection and Counting Algorithm
3.3.1. Convolution
3.3.2. Deconvolution
3.3.3. Loss Function
- 1.
- Line split method.
- 2.
- Watershed split method.
3.4. Experimental Environment and Evaluation Protocol
4. Results
4.1. Performance Comparison of Segmentation Model under Different Backbones
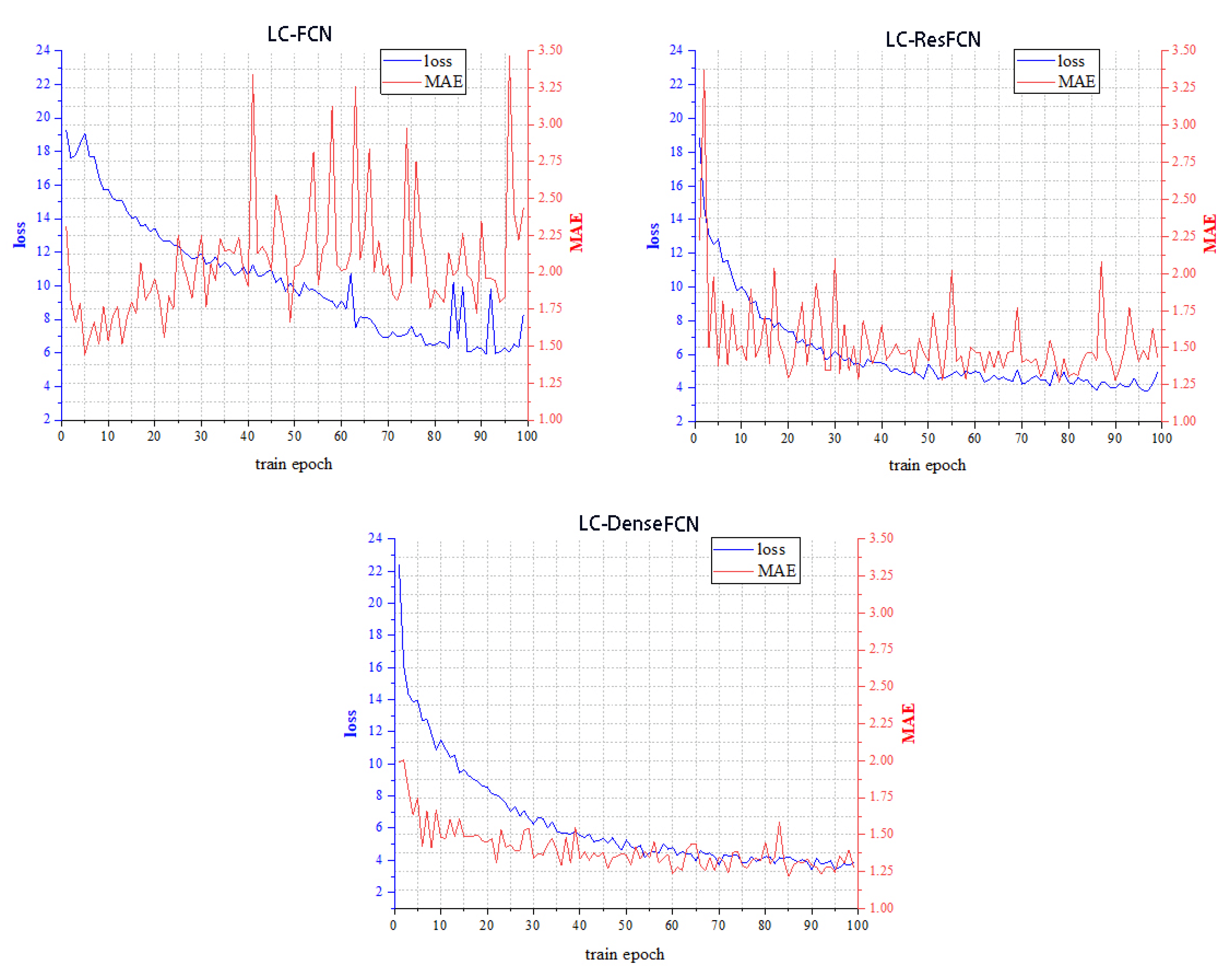
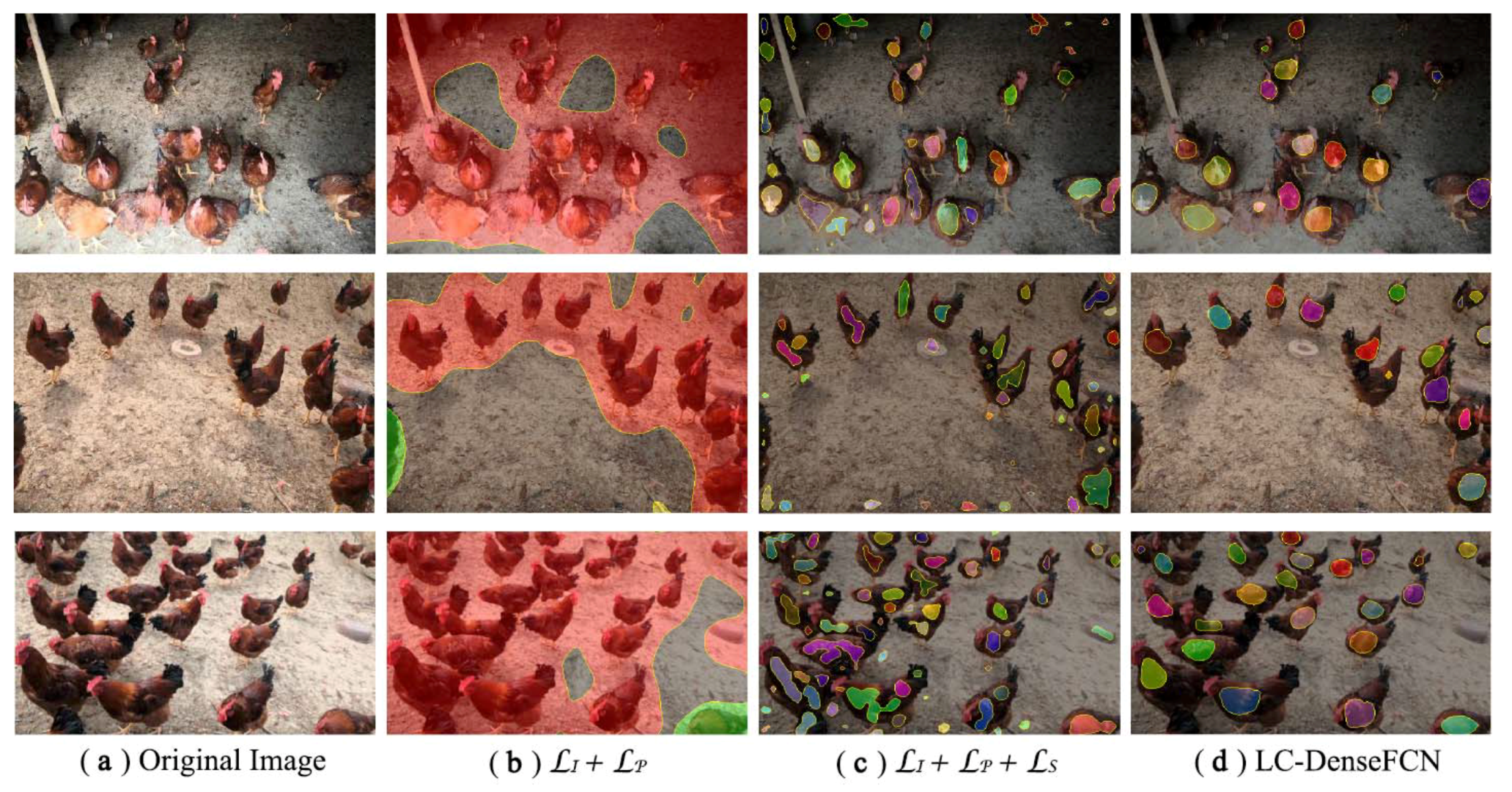
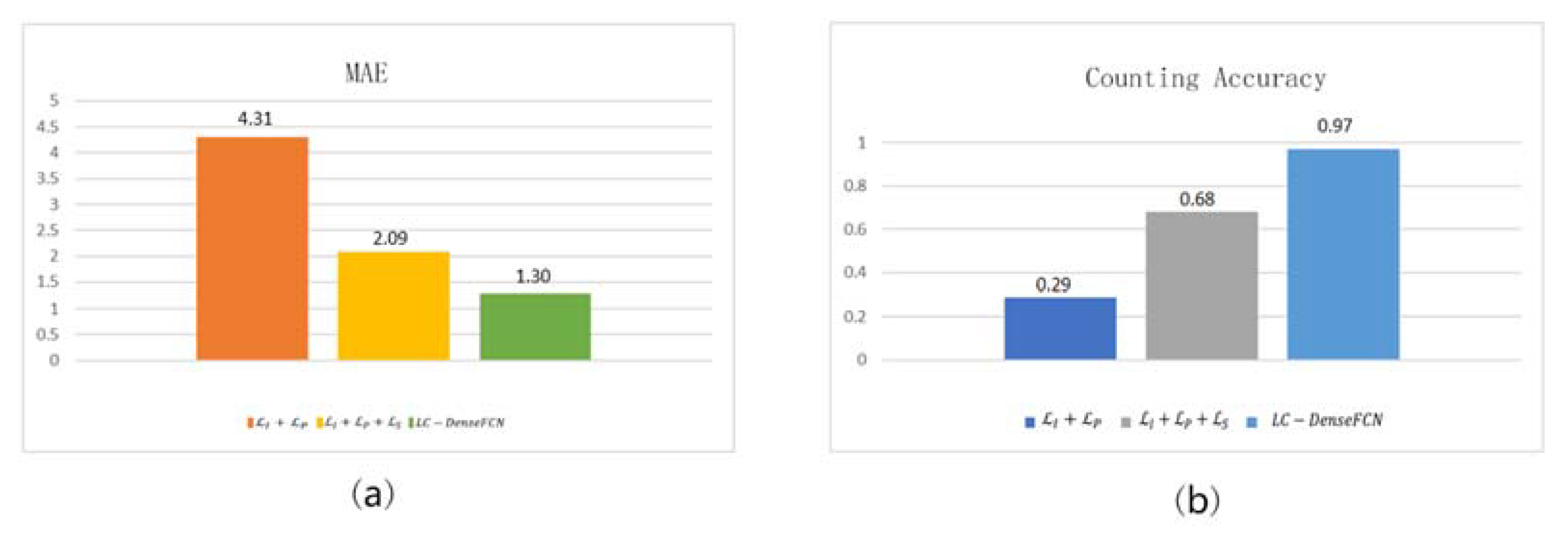
4.2. Loss Function Analysis
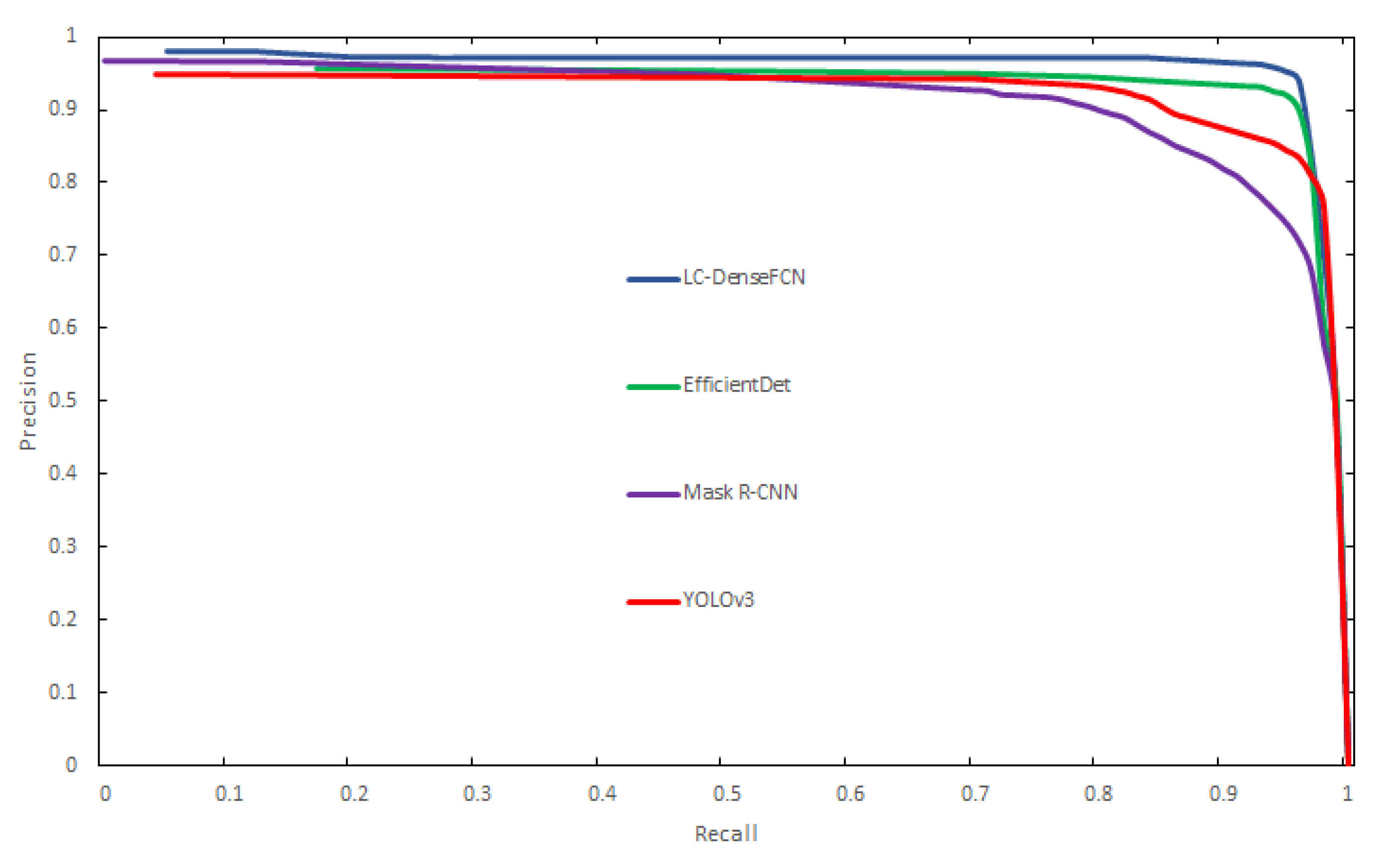
4.3. Comparison with State-of-the-Art Object Detection Algorithms
5. Discussion
- (1)
- In terms of processing accuracy, the source of detection was images collected by only two cameras on the chicken farm. Due to the fixed collection angle, the information of the overall environment could not be obtained; as a result, the information acquired was limited. Meanwhile, the movement characteristics of the chickens could also lead to a large error. In this regard, multiple cameras can be installed at different angles of the chicken farm, and the images collected by multiple cameras can be integrated to assess the overall situation of the chicken farm. Moreover, the overlapping situation of multiple chickens can be improved by installing cameras on top of the farm, which helps to effectively reduce counting errors. In general, although some individuals may have been missing in the test process, we finally achieved real-time monitoring of the number of chickens. The number of chickens should, theoretically, be in a dynamic range, and the final data can be obtained by statistical methods; thus, it will not have a significant impact on the overall accuracy;
- (2)
- In terms of processing speed, in order to meet a farmer’s need to obtain information on their chickens at any time, real-time processing of images collected by the camera is required. This is why we considered using the point supervision method. Compared to object detection methods, the point supervision method does not need to know the exact size of the object; therefore, the processing method is much simpler, and for counting tasks, the size of an object is of no practical use. The current semantic segmentation and instance segmentation methods were not considered due to their slow processing speed and the large amount of time spent on data annotation. The experimental results indicate that the LC-DenseFCN algorithm performs well; the detection speed was 9.27 FPS, which is sufficient for real-time detection.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Abbasi, A.Z.; Islam, N.; Shaikh, Z.A. A review of wireless sensors and networks’ applications in agriculture. Comput. Stand. Interfaces 2014, 36, 263–270. [Google Scholar]
- Ruiz-Garcia, L.; Lunadei, L.; Barreiro, P.; Robla, I. A Review of Wireless Sensor Technologies and Applications in Agriculture and Food Industry: State of the Art and Current Trends. Sensors 2009, 9, 4728–4750. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ning, W.; Zhang, N.; Wang, M. Wireless sensors in agriculture and food industry—Recent development and future perspective. Comput. Electron. Agric. 2006, 50, 1–14. [Google Scholar]
- Neethirajan, S.; Tuteja, S.K.; Huang, S.T.; Kelton, D. Recent advancement in biosensors technology for animal and livestock health management. Biosens. Bioelectron. 2017, 98, 398–407. [Google Scholar] [CrossRef] [PubMed]
- Handcock, R.N.; Swain, D.L.; Bishop-Hurley, G.J.; Patison, K.P.; Wark, T.; Valencia, P.; Corke, P.; O’Neill, C. Monitoring Animal Behaviour and Environmental Interactions Using Wireless Sensor Networks, GPS Collars and Satellite Remote Sensing. Sensors 2009, 9, 3586–3603. [Google Scholar] [CrossRef] [Green Version]
- Neethirajan, S. Recent advances in wearable sensors for animal health management. Sens. Bio-Sens. Res. 2017, 12, 15–29. [Google Scholar] [CrossRef] [Green Version]
- Frost, A.R.; Schofield, C.P.; Beaulah, S.A.; Mottram, T.T.; Lines, J.A.; Wathes, C.M. A review of livestock monitoring and the need for integrated systems. Comput. Electron. Agric. 1997, 17, 139–159. [Google Scholar] [CrossRef]
- Brown, K.H.; Hollingsworth, J. The Food Marketing Institute and the National Council of Chain Restaurants: Animal welfare and the retail food industry in the United States of America. Rev. Sci. Tech. 2005, 24, 655–663. [Google Scholar] [CrossRef]
- Tu, X.; Du, S.; Tang, L.; Xin, H.; Wood, B. A real-time automated system for monitoring individual feed intake and body weight of group housed turkeys. Comput. Electron. Agric. 2011, 75, 313–320. [Google Scholar] [CrossRef]
- Thaxton, J.P.; Dozier, W.A., III; Branton, S.L.; Morgan, G.W. Environment, Well-Being, and behavior Stocking Density and Physiological Adaptive Responses of Broilers. Poult. Sci. 2006. [Google Scholar] [CrossRef]
- Tong, H.B.; Lu, J.; Zou, J.M.; Wang, Q.; Shi, S.R. Effects of stocking density on growth performance, carcass yield, and immune status of a local chicken breed. Poult. Sci. 2012, 91, 667. [Google Scholar] [CrossRef]
- Dozier, W.A.; Thaxton, J.P.; Purswell, J.L.; Olanrewaju, H.A.; Roush, W.B. Stocking density effects on male broilers grown to 1.8 kilograms of body weight. Poult. Sci. 2006, 85, 344–351. [Google Scholar] [CrossRef]
- Yao, Y.; Yu, H.; Mu, J.; Li, J.; Pu, H. Estimation of the Gender Ratio of Chickens Based on Computer Vision: Dataset and Exploration. Entropy 2020, 22, 719. [Google Scholar] [CrossRef] [PubMed]
- Aydin, A. Using 3D vision camera system to automatically assess the level of inactivity in broiler chickens. Comput. Electron. Agric. 2017, 135, 4–10. [Google Scholar] [CrossRef]
- So-In, C.; Poolsanguan, S.; Rujirakul, K. A hybrid mobile environmental and population density management system for smart poultry farms. Comput. Electron. Agric. 2014, 109, 287–301. [Google Scholar] [CrossRef]
- Alahmari, S.S.; Goldgof, D.; Hall, L.; Phoulady, H.A.; Patel, R.H.; Mouton, P.R. Automated Cell Counts on Tissue Sections by Deep Learning and Unbiased Stereology. J. Chem. Neuroanat. 2019, 96, 94–101. [Google Scholar] [CrossRef]
- Xu, B.; Wang, W.; Falzon, G.; Kwan, P.; Schneider, D. Automated cattle counting using Mask R-CNN in quadcopter vision system. Comput. Electron. Agric. 2020, 171, 12. [Google Scholar] [CrossRef]
- Nguyen, H.; Maclagan, S.J.; Tu, D.N.; Nguyen, T.; Phung, D. Animal Recognition and Identification with Deep Convolutional Neural Networks for Automated Wildlife Monitoring. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 40–49. [Google Scholar]
- Tian, M.; Guo, H.; Chen, H.; Wang, Q.; Long, C.; Ma, Y. Automated pig counting using deep learning. Comput. Electron. Agric. 2019, 163, 104840. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Gong, C.; Chen, Y.; Yu, H. Applications of Deep Learning for Dense Scenes Analysis in Agriculture: A Review. Sensors 2020, 20, 1520. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Laradji, I.H.; Rostamzadeh, N.; Pinheiro, P.O.; Vazquez, D.; Schmidt, M. Where are the blobs: Counting by localization with point supervision. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 547–562. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Proceedings of the CVPR 2018: IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–22 June 2018. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. In You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. In YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Tan, M.; Le, Q. In Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Boyat, A.K.; Joshi, B.K. A Review Paper: Noise Models in Digital Image Processing. Signal Image Process. Int. J. 2015, 6, 63–75. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kuznetsova, A.A. Statistical Precision-Recall Curves for Object Detection Algorithms Performance Measurement. In Cyber-Physical Systems Modelling and Intelligent Control; Springer: Berlin/Heidelberg, Germany, 2021; pp. 335–348. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy (%) | Mean Absolute Error | Mean Square Error | Root-Mean-Square Error | Mean Relative Error | |
|---|---|---|---|---|---|
| LC-FCN | 91.40 | 1.60 | 5.14 | 2.27 | 0.86 |
| LC-ResFCN | 92.32 | 1.38 | 3.71 | 1.93 | 0.77 |
| LC-DenseFCN | 93.84 | 1.30 | 2.25 | 1.51 | 0.67 |
| Ground Truth | Detected | Counting Accuracy | Counting Error | Average Precision | Frames Per Second | |
|---|---|---|---|---|---|---|
| LC-DenseFCN | 4872 | 4748 | 0.97 | 0.03 | 0.94 | 9.27 |
| YOLOv3 | 4872 | 4396 | 0.90 | 0.10 | 0.89 | 5.11 |
| EfficientDet | 4872 | 4697 | 0.96 | 0.04 | 0.92 | 4.33 |
| Mask R-CNN | 4872 | 4213 | 0.86 | 0.14 | 0.86 | 2.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, L.; Xiao, Z.; Liao, X.; Yao, Y.; Wu, K.; Mu, J.; Li, J.; Pu, H. Automated Chicken Counting in Surveillance Camera Environments Based on the Point Supervision Algorithm: LC-DenseFCN. Agriculture 2021, 11, 493. https://doi.org/10.3390/agriculture11060493
Cao L, Xiao Z, Liao X, Yao Y, Wu K, Mu J, Li J, Pu H. Automated Chicken Counting in Surveillance Camera Environments Based on the Point Supervision Algorithm: LC-DenseFCN. Agriculture. 2021; 11(6):493. https://doi.org/10.3390/agriculture11060493
Chicago/Turabian StyleCao, Liangben, Zihan Xiao, Xianghui Liao, Yuanzhou Yao, Kangjie Wu, Jiong Mu, Jun Li, and Haibo Pu. 2021. "Automated Chicken Counting in Surveillance Camera Environments Based on the Point Supervision Algorithm: LC-DenseFCN" Agriculture 11, no. 6: 493. https://doi.org/10.3390/agriculture11060493
APA StyleCao, L., Xiao, Z., Liao, X., Yao, Y., Wu, K., Mu, J., Li, J., & Pu, H. (2021). Automated Chicken Counting in Surveillance Camera Environments Based on the Point Supervision Algorithm: LC-DenseFCN. Agriculture, 11(6), 493. https://doi.org/10.3390/agriculture11060493