1. Introduction
Coffee is the most traded tropical crop, with up to 25 million farming households contributing up to 80% of the worldwide output. Coffee production is concentrated in developing nations, where it accounts for a substantial portion of the export profits and is a primary source of revenue. It is one of the world’s most popular drinks and is among the most traded commodities [
1], where the market is continuously growing owing to increased demand in emerging economies and its substantial contribution to specialized and innovative products in developed countries. The diseases affecting coffee plants are a critical factor severely limiting coffee’s productivity. Biotic stresses, such as leaf miner, rust, phoma, and Cercospora, damage coffee plants and cause defoliation and a reduction in photosynthesis, thus reducing the production and quality of the product [
2]. Thus, identifying and measuring plant diseases is highly important in phytopathology. It is essential to understand both causal agents and the severity of the symptoms for effective pest and disease management [
3]. If not treated appropriately, these diseases can cause significant leaf damage and crop fatality [
4].
The Fourth Industrial Revolution (4IR) is the peak era of current industrial technology, where cyber–physical systems can be connected via deep learning, machine learning, artificial intelligence, and big data [
5]. The 4IR can also increase productivity and growth in various aspects. One of the sectors experiencing technological growth and development is agriculture, where technologies such as artificial intelligence, machine learning, and deep learning positively impact agriculture’s development and productivity [
6]. Smart agriculture is a new and evolving technology that integrates advanced strategies for increasing agricultural production while also increasing agricultural inputs in a sustainable and environmentally responsible manner. It is now possible to reduce errors and expenses to achieve ecologically and economically sustainable agriculture [
7]. Recently, several efforts have been made to use artificial intelligence (AI) to help farmers accurately recognize diseases and pests that damage agricultural production and to judge the severity of the symptoms.
AI attempts to provide computers with human-like intelligence by simulating human intelligence processes. It allows for analysis, learning, and problem solving while presenting new knowledge. AI has the potential to transform agriculture by allowing farmers to obtain better results with less work while providing numerous additional benefits [
8]. In recent years, AI research has experienced significant growth in machine learning applications, particularly a new class of models called deep learning. Notably, DL algorithms have demonstrated better performance in various domains than traditional machine learning methods [
9,
10]. DL models have significant relevance when promising outcomes are obtained. Many methods have been used in recent years to identify diseases in plants, and DL methods have proven to be quite efficient. Owing to the growing interest in DL in agriculture, numerous studies have been conducted, demonstrating that visual evaluation is reliable for plant disease detection [
11]. Researchers have been developing DL solutions for agriculture in recent years by classifying species and diseases using convolutional neural networks (CNN) [
12,
13]. CNNs are the most promising DL-based algorithms for automatically discriminating features and learning robustness. DL consists of several convolutional layers representing learning features based on data [
14].
However, DL has drawbacks, such as the necessity of large amounts of data for training the network. For example, the performance of the CNN deteriorates if the available dataset does not contain sufficient images. This critical drawback can be overcome via transfer learning. Transfer Learning has several advantages, one of which is that it does not require a large amount of data for training the network, as knowledge from previous similar learning tasks can be transferred to the current task. The control of crop losses is ensured by the rapid recognition of the disease’s cause, which enables the prompt selection of the best protective strategy. It also represents the initial and most crucial phase of disease prevention. Our motivation is to develop a system that can adequately classify coffee diseases. Early disease identification can result in more successful treatments and longer survival spans. Although transfer learning has been used in several disease detection methods [
15,
16,
17,
18,
19], researchers need to develop more disease detection methods in coffee plants using transfer learning.
Herein, relevant works on machine learning and deep learning for classifying and detecting plant diseases are reviewed. Marcos et al. [
20] focused on detecting rust in coffee leaves. This study used a genetic algorithm to compute an optimal convolution kernel mask that emphasizes fungal infections’ texture and color features. Gutte et al. [
21] used three phases for monocot and dicot diseases. First, they segmented the leaf using the k-mean clustering technique. Feature extraction was then performed to determine the shape, color, and texture. Finally, they used a support vector machine (SVM) to identify plant diseases. Abrham et al. [
22] classify coffee leaf disease into three major types of disease: Coffee Wilt Disease (CWD), Coffee Berry Disease (CBD), and Coffee Leaf Rust (CLR). First, the author used GLCM and color features for feature extraction; then, they used an artificial neural network (ANN), k-Nearest Neighbors (KNN), a Naïve and a hybrid self-organizing map (SOM), and a Radial basis function (RBF) for classifying the coffee plant leaf diseases.
Manso et al. [
23] proposed an application for detecting coffee leaf diseases in images captured using smartphones. Various types of backgrounds for images using the YCbCr (Luminance, Chrominance) and HSV (Hue, Saturation, Value) color spaces were analyzed throughout the segmentation process and compared with k-means clustering in the YCbCr color space. The iterative threshold algorithm is called the Otsu algorithm and calculates the damage caused by coffee plant diseases. Finally, for a classification in the segmentation of foliar damage, an ANN trained with a robust machine learning algorithm was used. According to the experts, the result obtained is auspicious, as it shows the feasibility and effectiveness of identifying and classifying foliar damage. Babu et al. [
24] developed a software model that effectively suggests corrective measures for disease or pest management in the agricultural field and achieves control solutions. They used five modules. First, they extracted the edge of a leaf to find the token value. Second, the module trained the neural network with the leaf and identified the error graph. Identifying and recognizing the leaf disease or pest species was carried out during the third and fourth modules. The last module attempted to match the identified disease or pest samples to examples in the database containing disease and pest image samples and suggest appropriate actions.
Marcos et al. [
25] proposed training a CNN for identifying rust infection. For an evaluation, they provided a set of images to an expert. The author compared the results, which showed that the method could recognize infection with high precision, as evidenced by the high dice coefficient. Dann et al. [
26] used the YOLOv3-MobileNetv2 model for detecting diseases in robusta coffee leaves. They develop a prototype that can capture the input images and then classify the disease into four classes: Cercospora, miner, phoma, and rust. Ramcharan et al. used a smartphone-based CNN model to identify cassava plant diseases with an accuracy rate of 80.6% [
27].
In [
28], transfer learning was used to classify ten diseases in four major crops that have received little attention. The data were transferred from a smartphone to a computer through a local area network (LAN), and the performances of six pre-trained CNNs, i.e., GoogLeNet, VGG19, DenseNet201, VGG-16, AlexNet, and ResNet101, were evaluated. GoogLeNet had the best validation accuracy at 97.3%. Real-time image classification was performed under the test conditions, and the prediction scores for each disease class were obtained. All models showed a reduction in accuracy, with VGG-16 achieving the highest accuracy at 90%. Esgario et al. [
29] used 1747 images of Arabica leaf and trained various deep convolutional models (VGG-16 and ResNet50) for classifying the degree of severity and biotic stress. The trained VGG-16 DCNN, which identified various biotic diseases, achieved a 95.47% accuracy, whereas ResNet50 validated each leaf condition efficiently with a 95.63% accuracy rate.
In the literature, although significant efforts have been made to develop various DL models to identify diseases in several crops, these models, unfortunately, are neither feasible nor effective for detecting coffee disease. Therefore, a reliable approach is needed to accurately identify various diseases in coffee plants. To satisfy this need, we propose a DL-based ensemble architecture in this paper, which yields efficient and accurate results.
Table 1 shows the detailed analyses of the state-of-the-art studies and our proposed model. In this paper, we, for the first time, develop fine-tuned and high-performing deep CNNs for coffee leaf disease detection (or classification) using transfer learning and conduct an extensive experimental optimization of the constructed CNNs. The main contributions of our work are as follows:
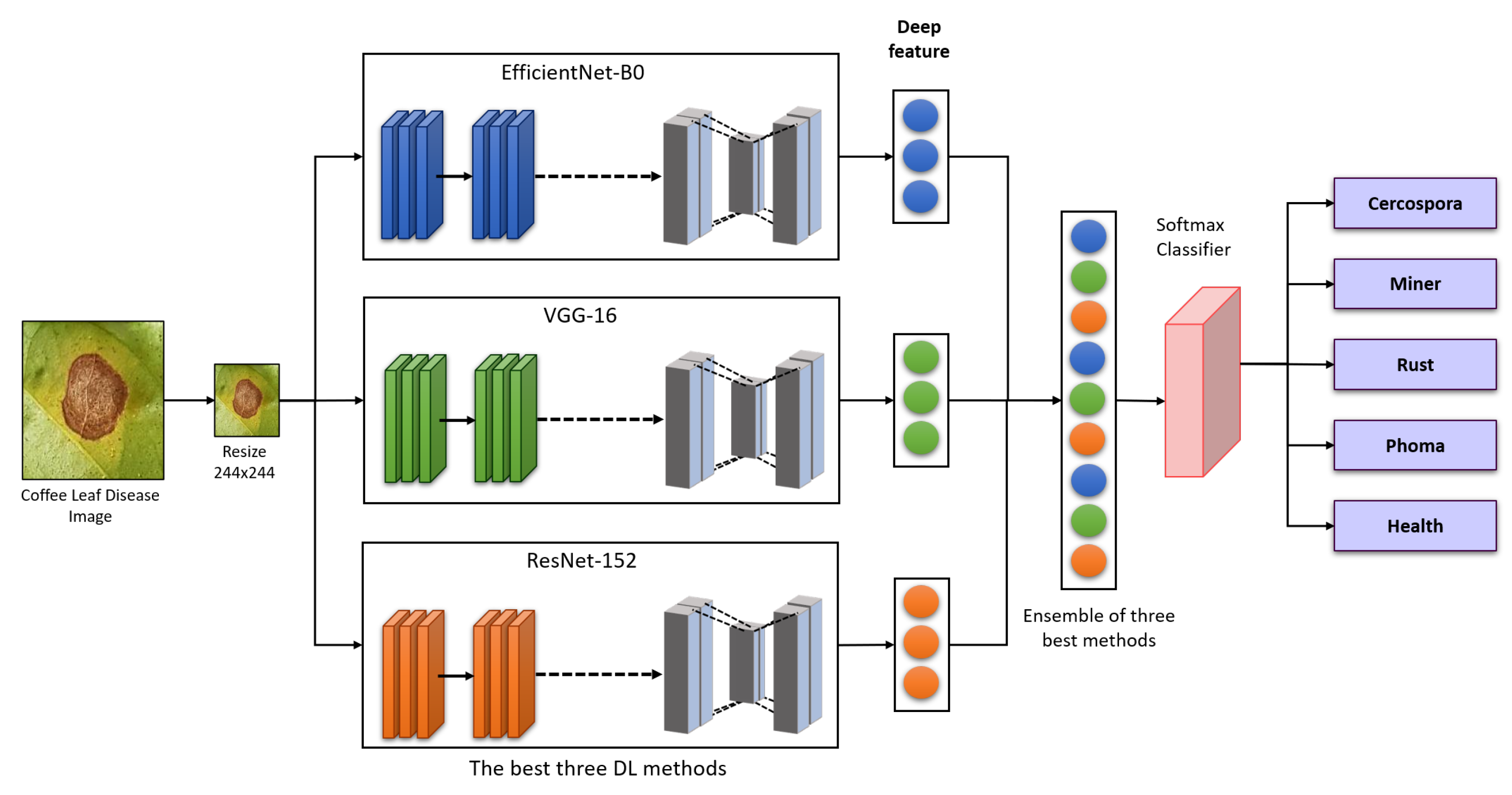
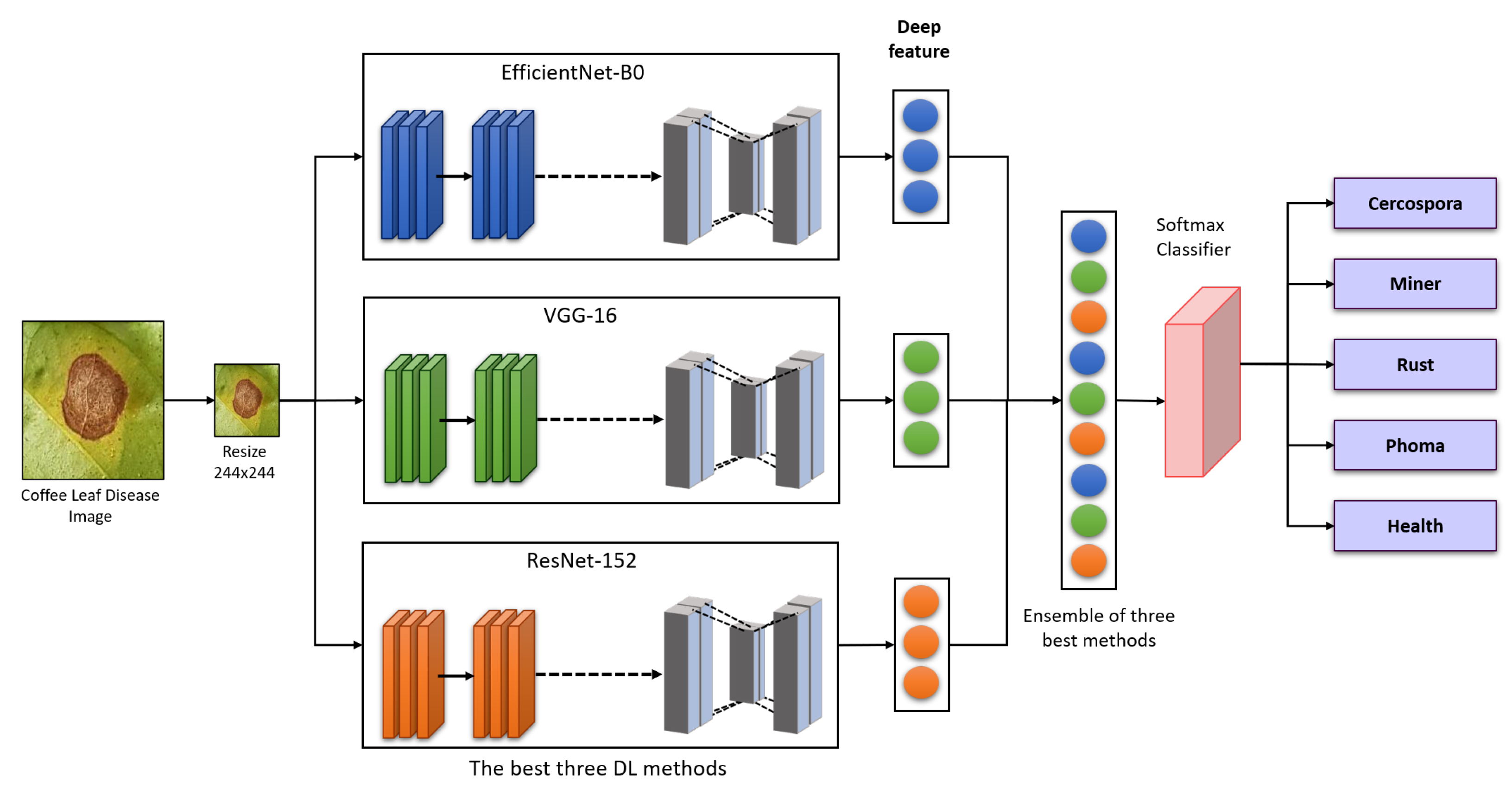
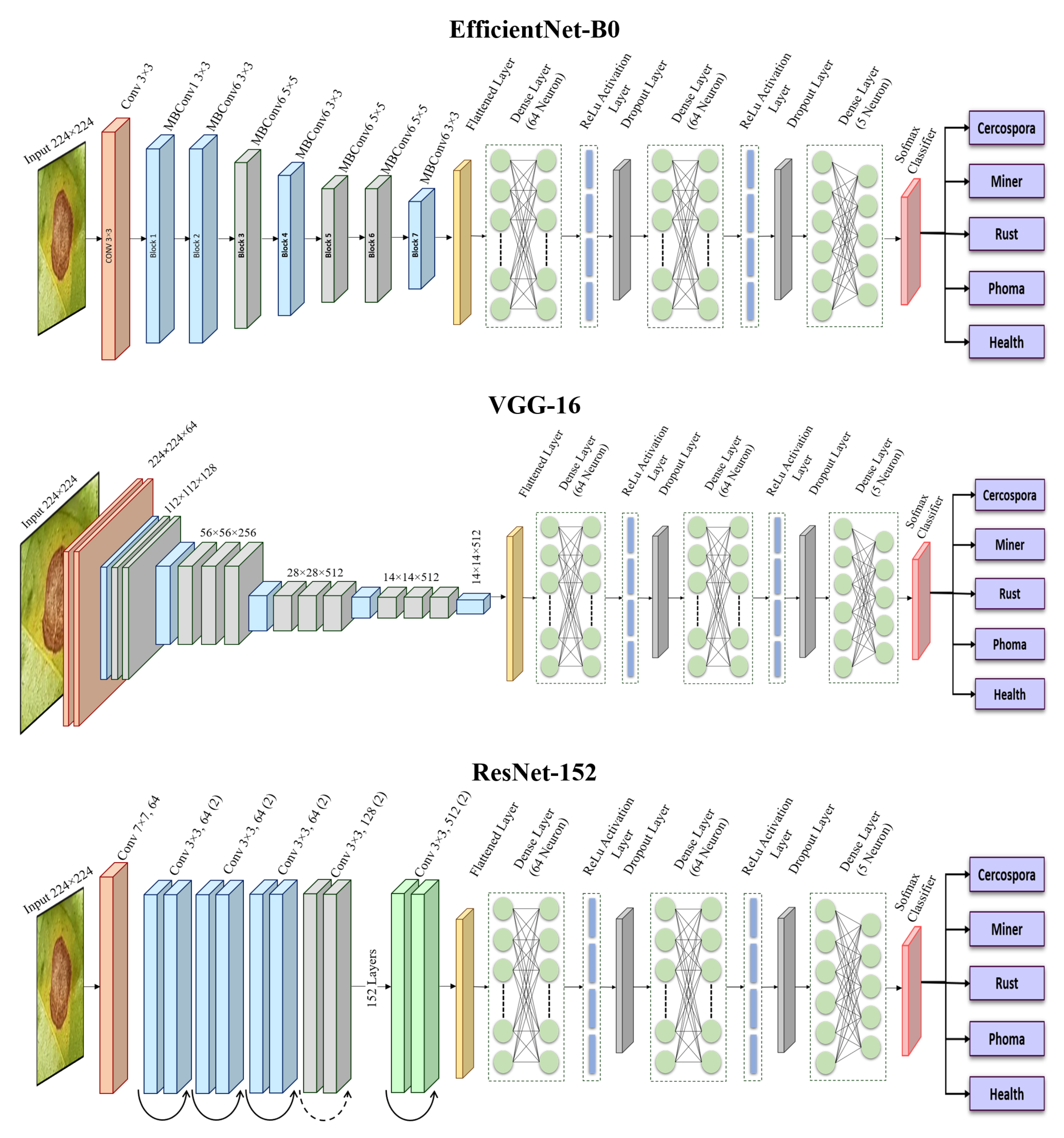
We develop a collaborative ensemble architecture to classify the diseases in coffee plants. The proposed strategy is based on re-training the pre-trained DL models using the coffee disease dataset and combining the weights of the three best-performing algorithms to make an ensemble architecture for better disease detection in coffee leaf.
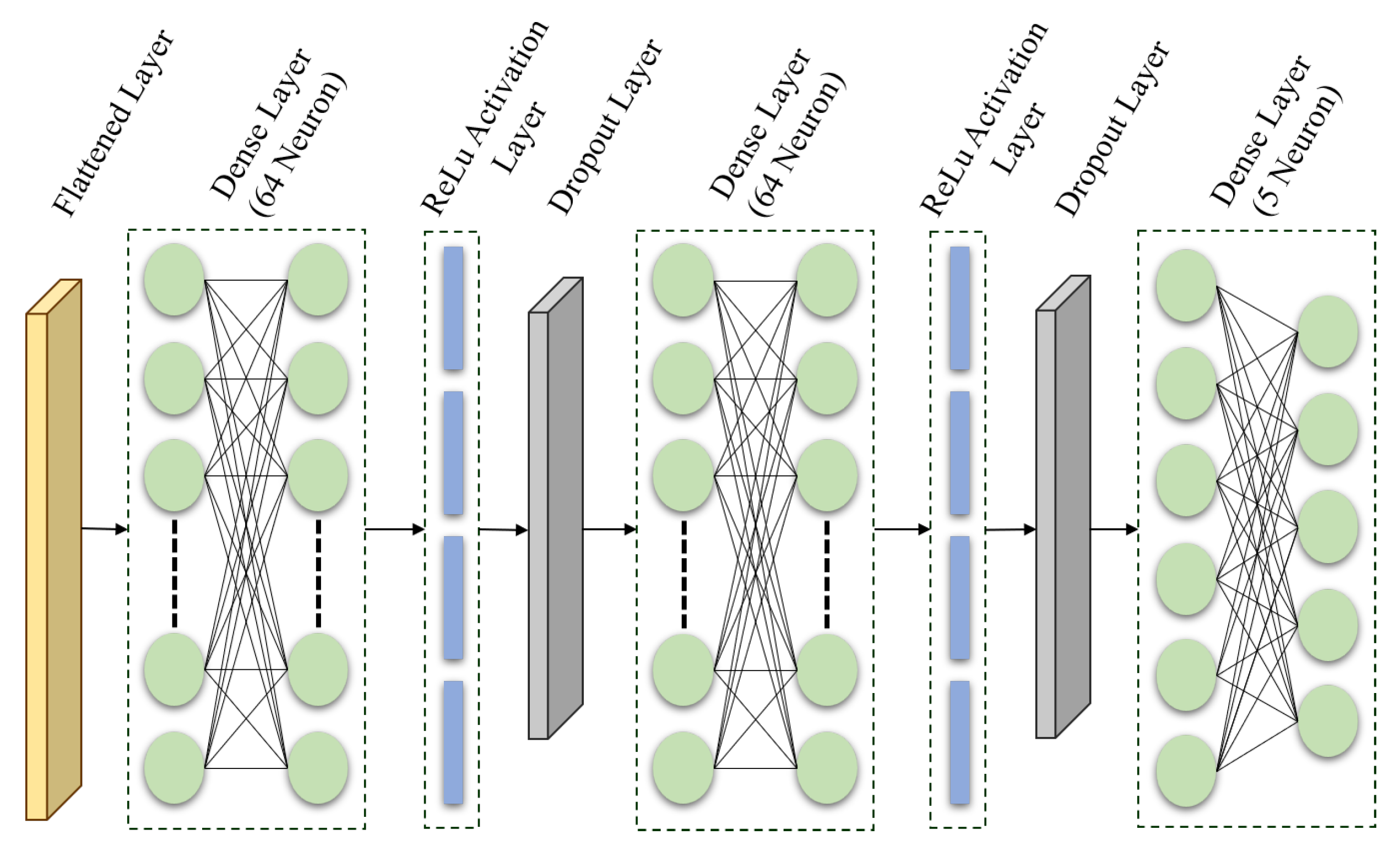
The pre-trained DL models utilized in this study are fine-tuned using our proposed layers, which can replace traditional disease detection in plants and improve overall classification accuracy.
A data pre-processing and data augmentation strategy is employed to improve the poor image quality of the training data and increase the diversity in input data to generate better outcomes on small datasets.
The effectiveness of the proposed architecture is assessed with several hyper-parameters such as activation functions, batch size, learning rate, and L2 regularizer, to increase classification accuracy. This ablation study demonstrates how our architecture outperforms the previous state-of-the-art studies in detecting coffee leaf diseases.
The remainder of this paper is organized as follows: In
Section 2, the materials and methods are described. The experimental results are described and compared with those of other recent iterative methods in
Section 3. Finally, future studies and conclusions are described in
Section 4.
3. Results and Discussion
A publicly accessible dataset is used to evaluate the performance of the proposed technique [
29]. We used the symptom dataset as the subset, and the dataset is categorized into five classes, where four classes are coffee leaf diseases (miner, phoma, Cercospora, rust,) and one class contains healthy leaves. This dataset yields a significant amount of heterogeneous agricultural data (containing 1300 images). This dataset is used in the training and testing process. For model development, we utilize EfficientNet-B0, ResNet-152, VGG-16, InceptionV3, Xception, MobileNetV2, DenseNet 201, InceptionResNetV2, and NasNetMobile with several data pre-processing and augmentation techniques to increase the size and diversity of the images. We employ an Adam optimizer in our optimization technique, which has been widely used in previous investigations, with an initial learning rate of 0.001 and a learning rate drop component of 0.1. For instance, the training learning rate dropped to 0.0001 (
) after 10 iterations, to 0.00001 (
) after 20 epochs, etc. For the other hyper-parameter used in this study, we used a mini-batch of 32 and the cross-entropy loss function. Simultaneously, we use Keras and TensorFlow APIs to develop fine-tuned baseline architectures. The proposed architectures are trained using 20% of the test data and 80% of the training data. The hyper-parameters included in this design plan show that the accuracy improved gradually as the number of epochs increased over a short period, stabilizing at a given amount.
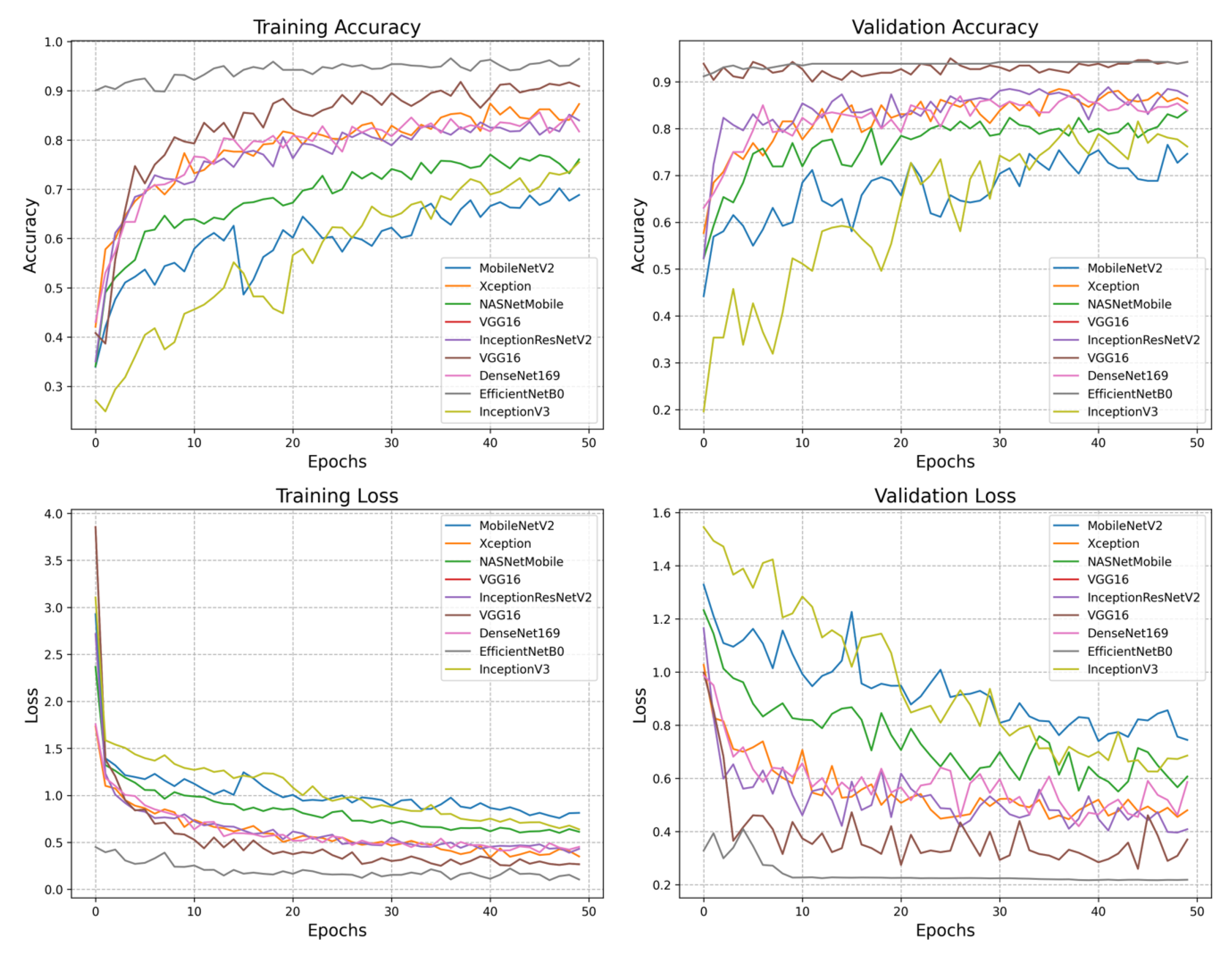
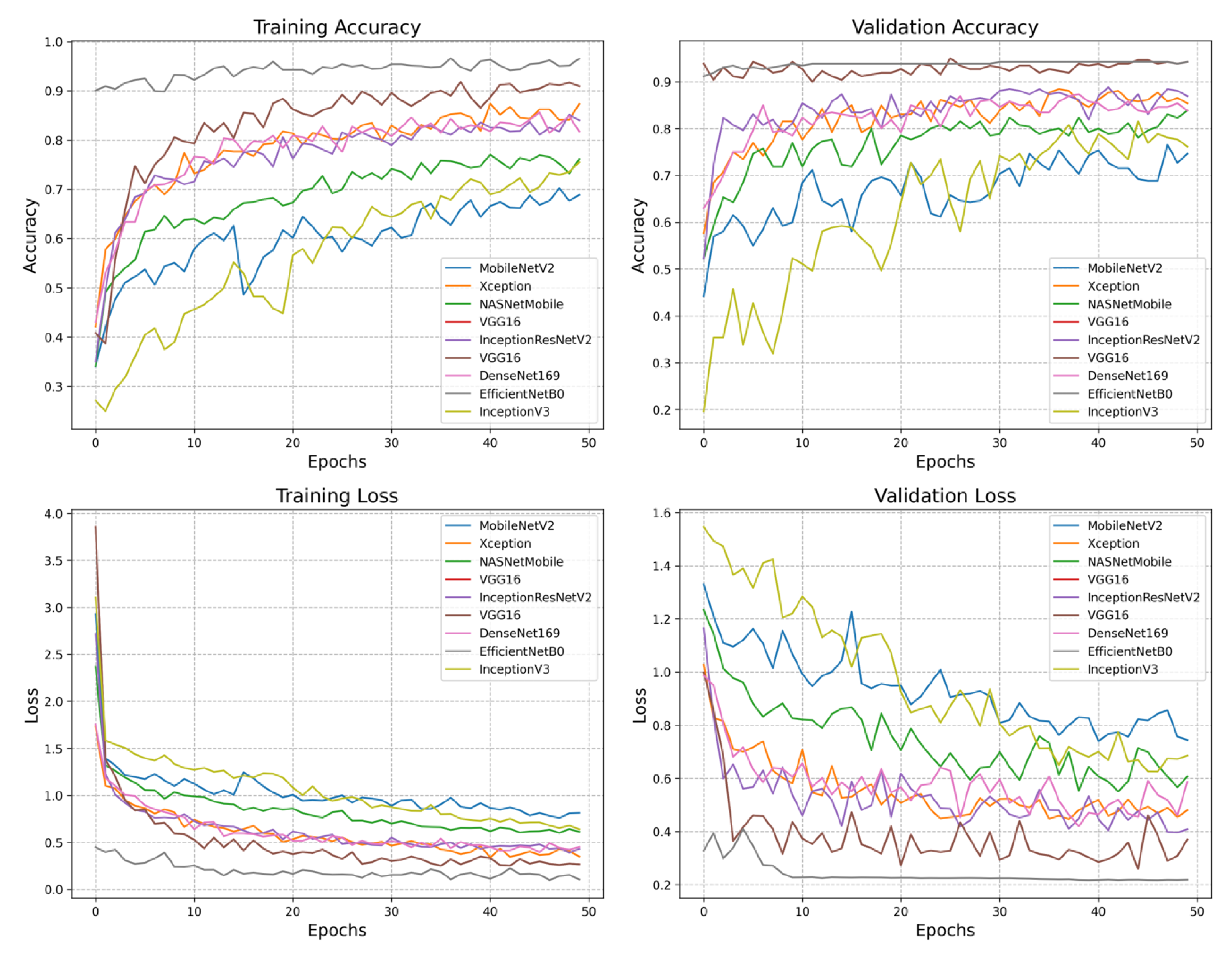
Figure 5 shows the graph of accuracy and loss in training and validation. In the training accuracy graph, EfficientNet-B0 and VGG-16 perform very well, achieving more than 90% accuracy. The last model is MobileNet-V2, achieving a less than 70% error rate. With a minimum loss, EfficientNet-B0 shows the highest validation accuracy of 95%. VGG-16 performed well on the coffee leaf dataset, achieving 94.2% validation accuracy. The ResNet-152 architecture achieves satisfactory performance with 93.8% validation accuracy, while MobileNet-V2 shows a low performance with 74.6% validation accuracy. Overall, EfficientNet-B0 performs very well, followed by VGG-16 in training and validation loss accuracy. Finally, MobileNet-V2 demonstrates poor performance in training and validation loss accuracy.
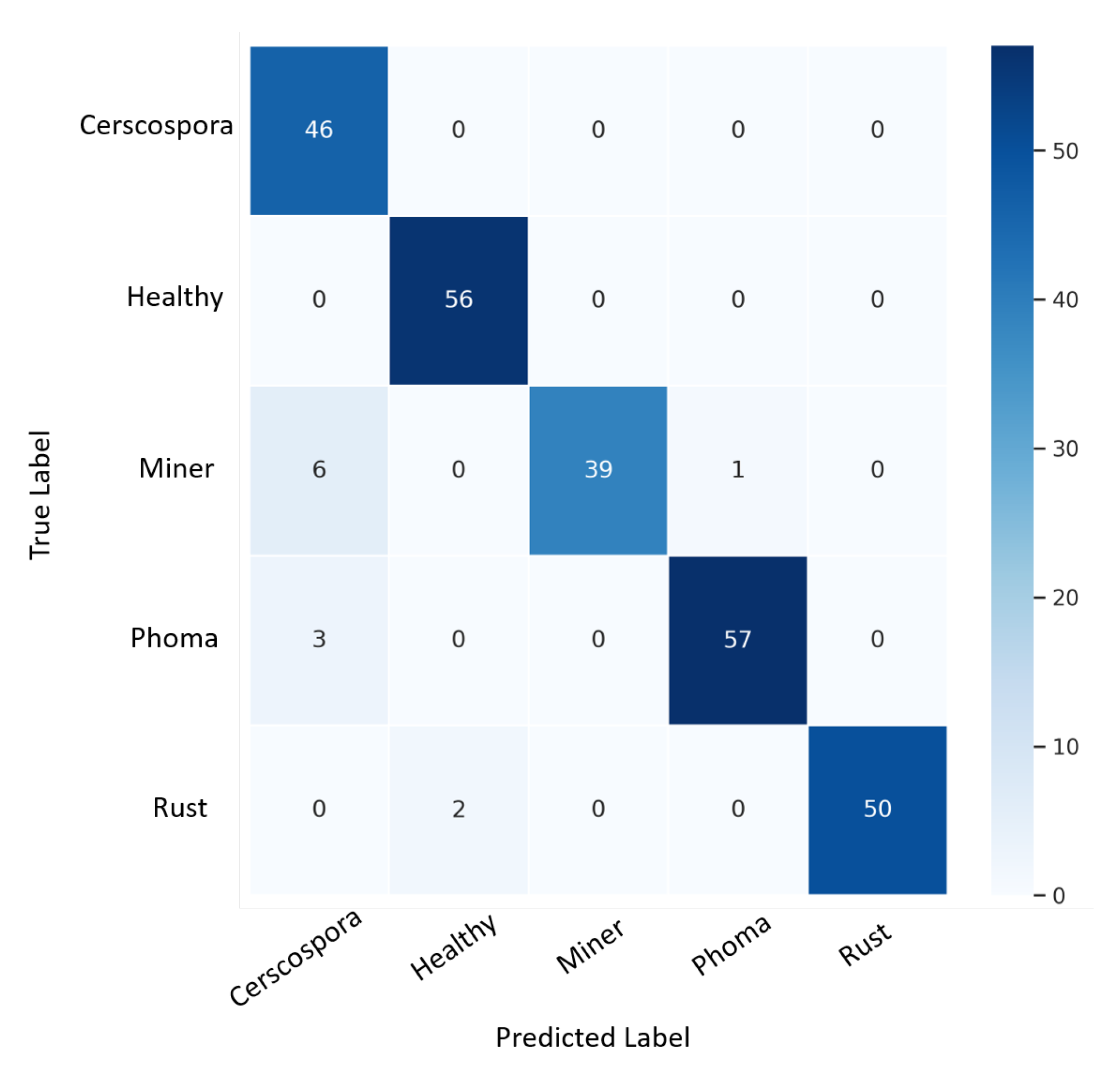
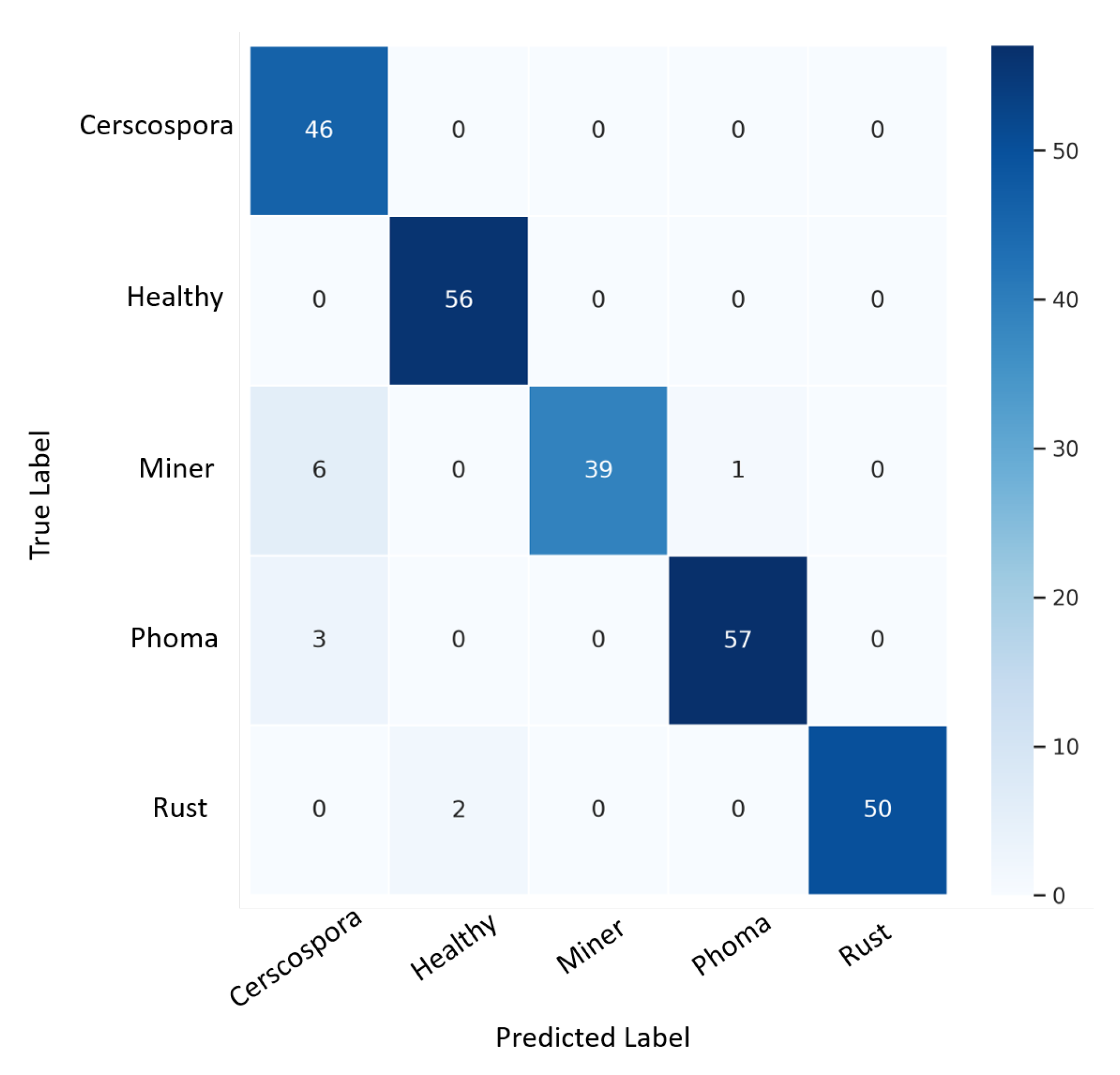
A total of 248 images were validated in their respective classes using confusion matrix techniques.
Table 6 presents the ensemble model’s and proposed model’s performance scores. The ensemble model achieves the highest state-of-the-art performance by achieving 97.3% in accuracy, 95.1% in F1-score, 98.9% in specificity, 95.2% in sensitivity, and 95.7% in precision. Next is the EfficientNet-B0 model, achieving 95% in accuracy, 94.9% in F1-score, 98.8% in specificity, 94.8% in sensitivity, and 95.2% in precision. VGG-16 follows, achieving 94.2% in accuracy, 94.1% in F1-score, 98.6% in specificity, 94% in sensitivity, and 94.4% in precision. Next is ResNet-152, achieving 93.8% in accuracy, 93.3% in F1-score, 98.5% in specificity, 93.2% in sensitivity, and 94% in precision. The MobileNet-V2 model achieves the lowest state-of-the-art performance by achieving 74.6% in accuracy, 73.5% in F1-score, 94.5% in specificity, 74.1% in sensitivity, and 76.8% in precision.
Figure 6 presents the confusion matrix obtained by the proposed ensemble architecture on the validation dataset.
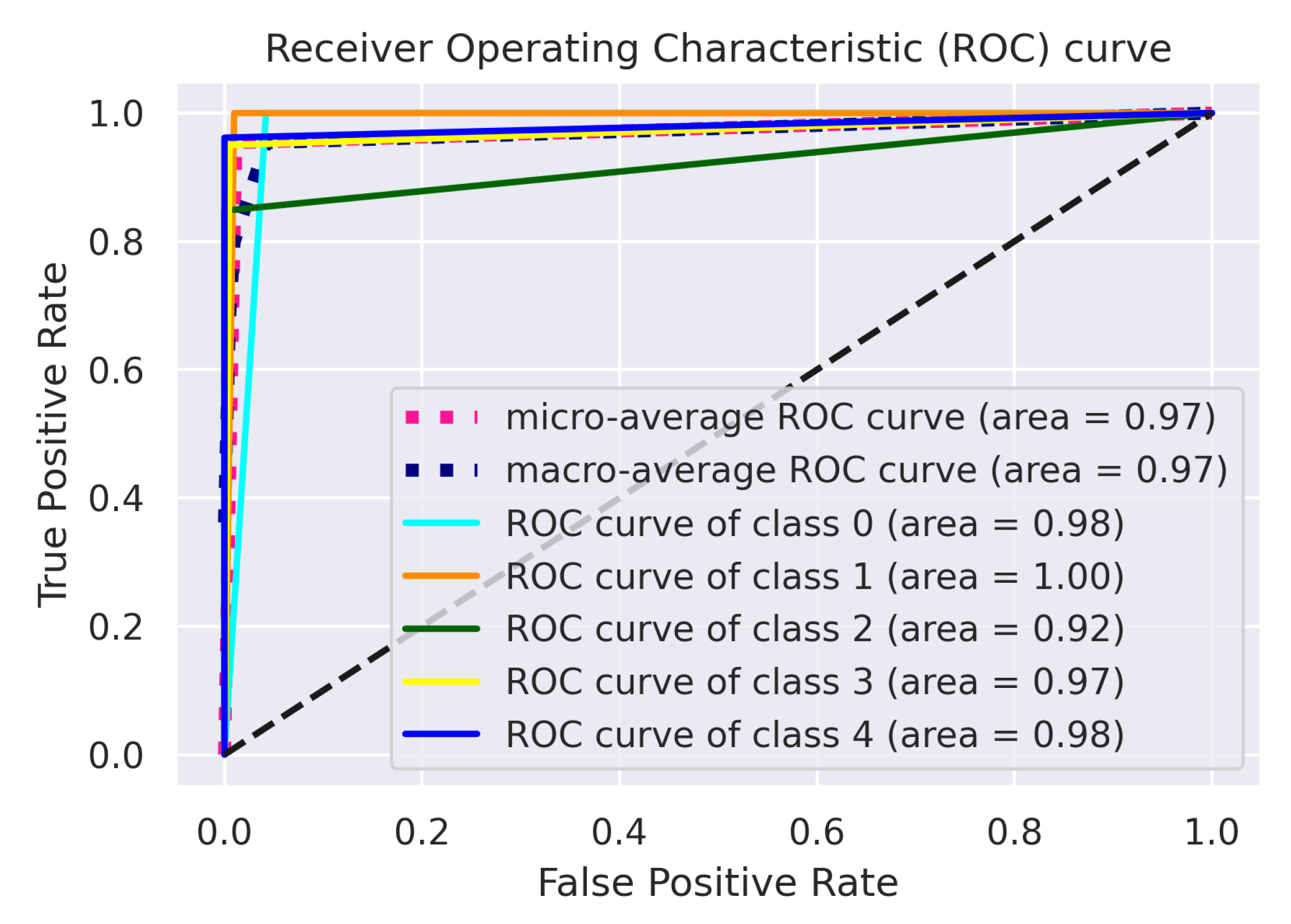
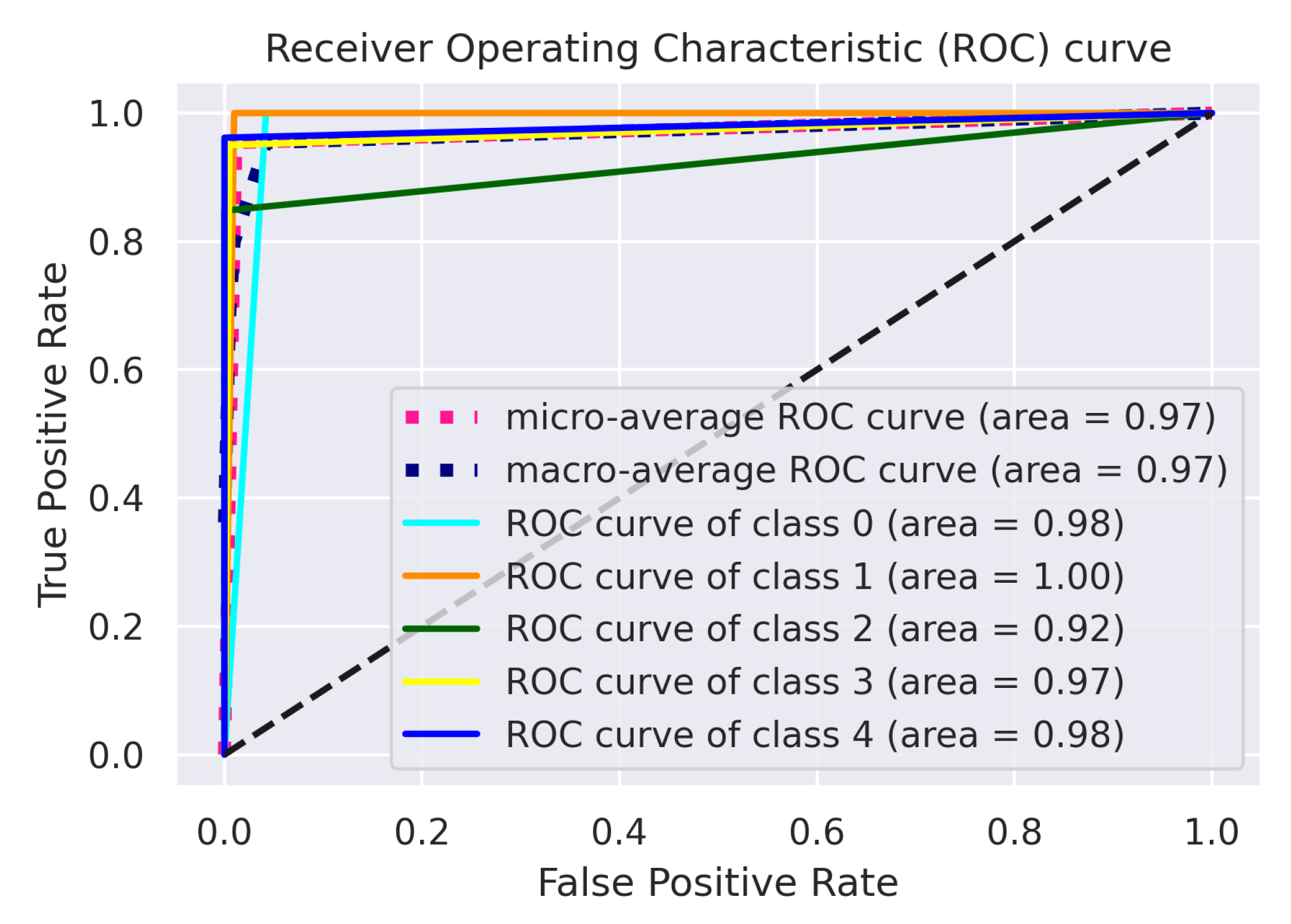
The area under the ROC graph is a measurable statistic for classification tasks with multiple threshold levels. An ROC curve is used for all potential thresholds to compare the true positive (sensitivity) against the false positive rate (1—specificity). The area under the curve (AUC) represents the degree of distinction. In contrast, the ROC is a probability graph. This indicates the effectiveness of the algorithm in discriminating between different classes. The model is more effective at differentiating between classes with diseased and healthy individuals with a higher AUC.
Figure 7 illustrates the graph of the ensemble model, which shows that the ensemble outperforms the other architectures by correctly classifying the five different classes.
Table 7 shows the ROC–AUC curve for the other fine-tuned models, where EfficientNet-B0 performs most satisfactorily by achieving a 0.97 macro-average score; the VGG-16 model trained with the coffee leaf disease dataset achieves a score of more than 0.96 for the macro-average score; ResNet-152 performs relatively well, achieving 0.96 macro- and micro-AUC scores; and MobileNet-V2 performs the worst among all the models by achieving a 0.84 macro-average score. Among all five classes, it scores lower for class 2 (miner), with only 0.86; the highest is class 3 (phoma), achieving 0.95 on average.
Table 8 shows the performance time of our proposed ensemble architecture and other fine-tuned models. This table shows that our proposed ensemble architecture is faster than other fine-tuned models, achieving 6.3 s in the training process.
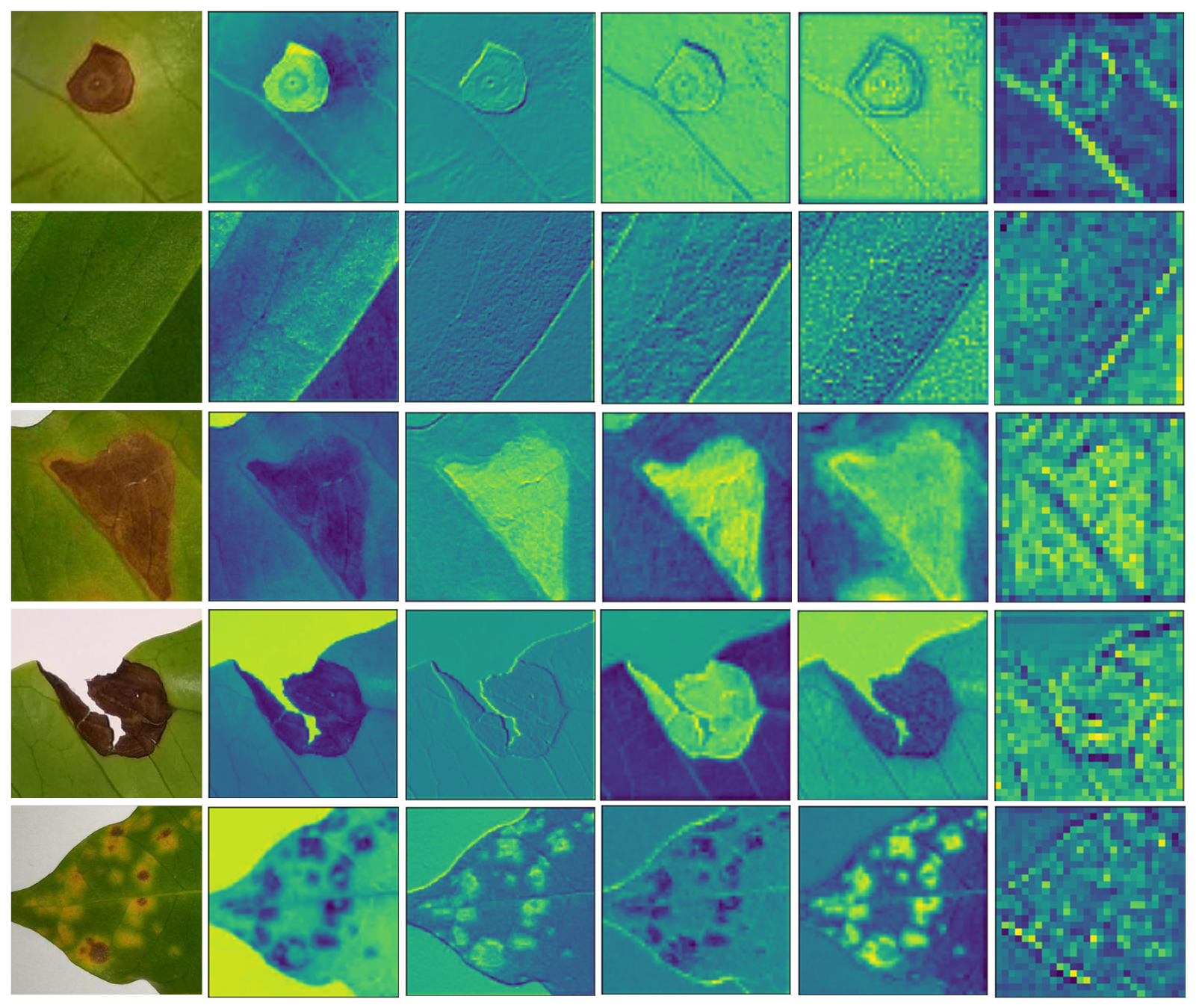
DL algorithms are very complex and are referred to as black boxes since any justification does not support the prognosis. The visual prediction presentation is essential for establishing confidence in AI-based intelligent systems.
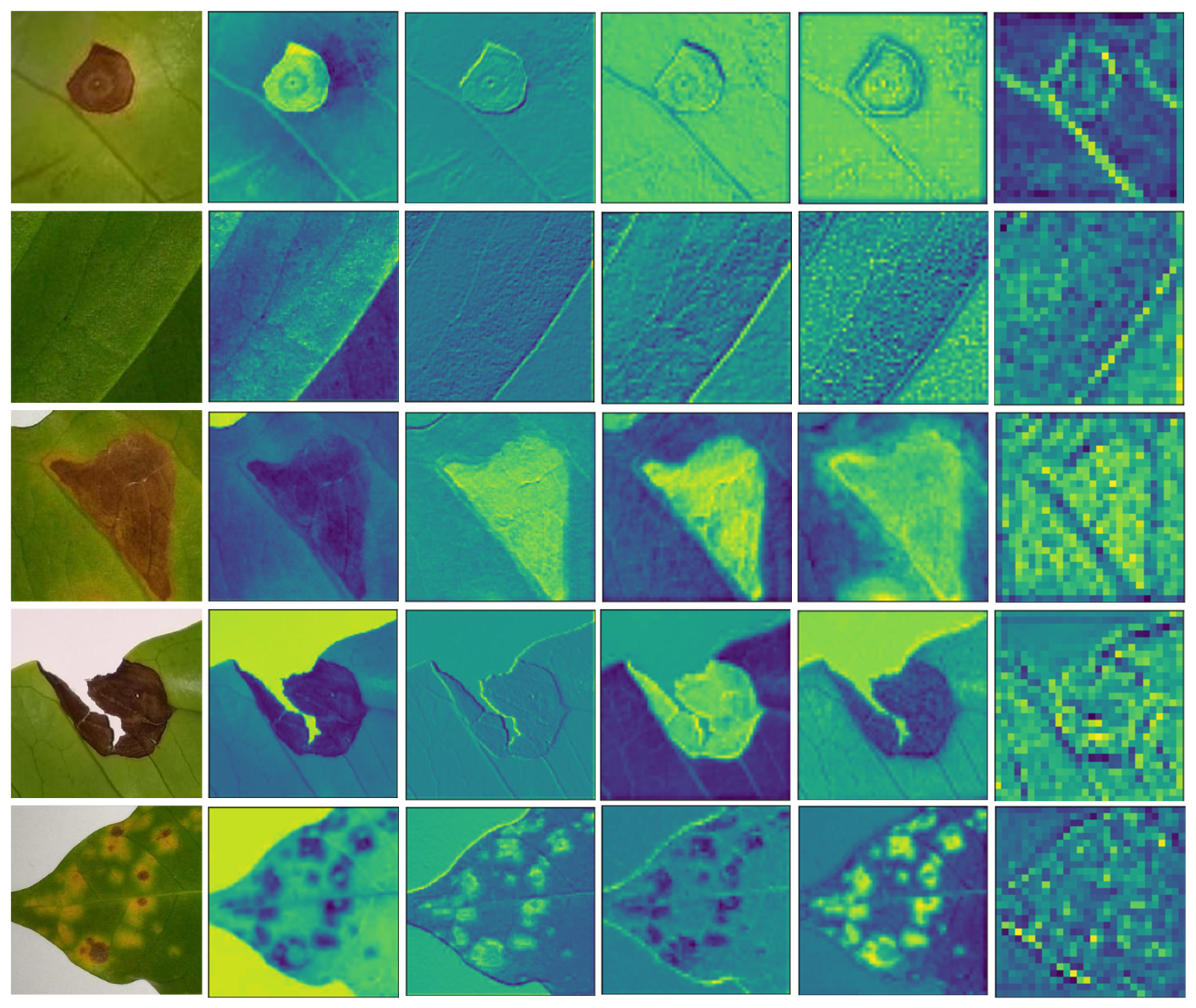
Figure 8 presents a visualization of images with feature maps extracted from the intermediate convolution layers of the ensemble model with different classes. Here, the model’s feature extraction capability as the convolutional network becomes deeper, from left to right, is presented. These feature maps show that the proposed network is effectively tuned to distinguish between diseases in coffee leaves. The first image is Cercospora, the second image is Healthy, the third image is miner, the fourth image is phoma, and the fifth image is rust. This section defines the size and number of features of the various fine-tuned CNN architectures used in this study. The CNNs and regular neural networks are identical. They consist of neurons with biases and weights that can be used for training. Each neuron processes a few impulses to conduct a dot product and may potentially perform non-linearity. In general, the parameters are weights that are learned through an activity. These include weighted vectors, which are modified during the backpropagation process and help the algorithm’s ability to anticipate outcomes.
Table 9 shows the parameter of the fine-tuned models used in this study. The best models that achieve higher accuracy are VGG-16 with 14 million parameters, EfficientNet-B0 with 4 million parameters, and ResNet-152 with 58 million parameters.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}