
Detection of Cattle Key Parts Based on the Improved Yolov5 Algorithm
Abstract
1. Introduction
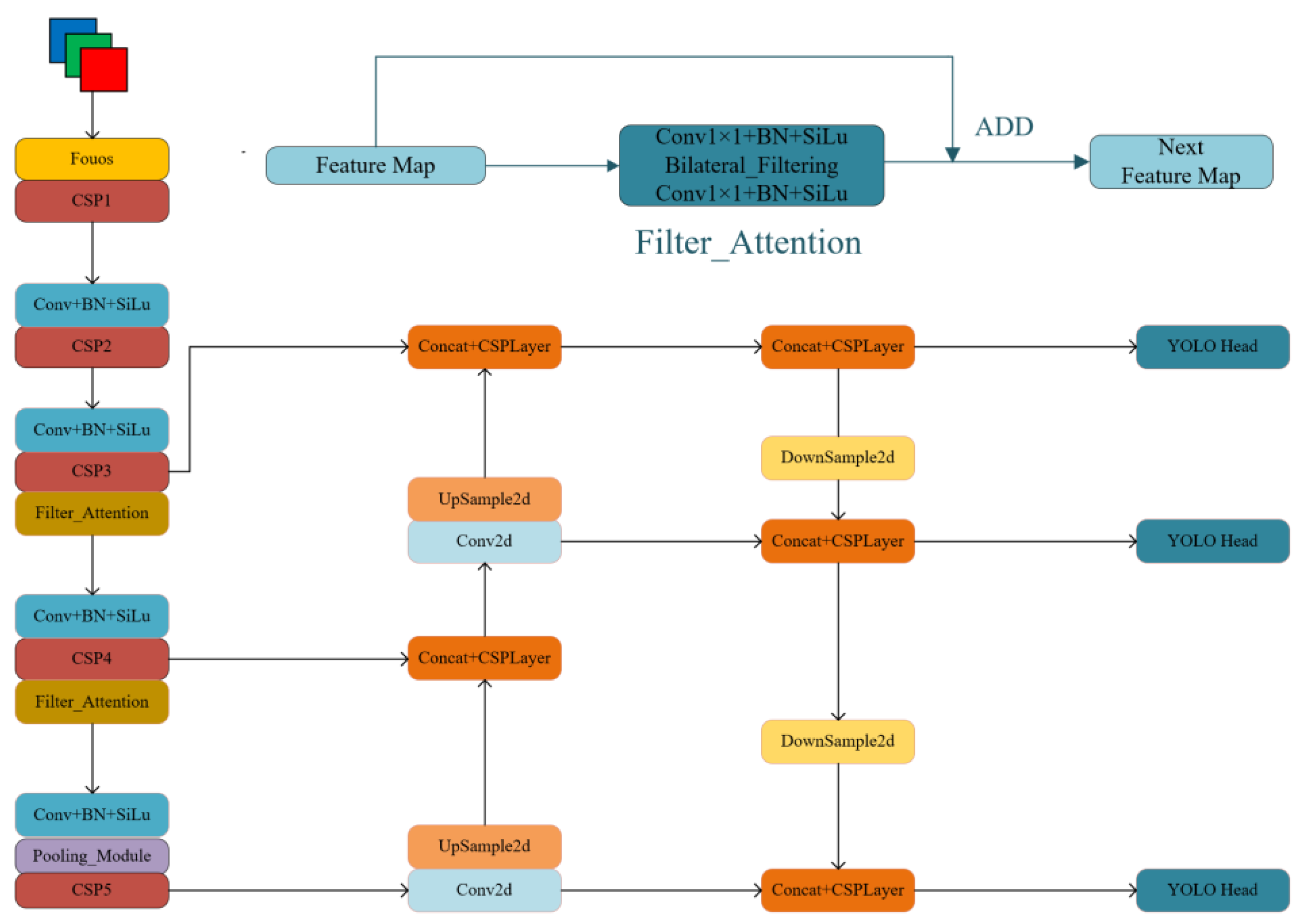
- The complex environment of the cattle livestock farms and the input image with Gaussian noise, as well particle noise in the training stage of the model, harm the detection effect. This paper designs the Filter_Attention mechanism, based on a bilateral filtering algorithm, to reduce the noise interference in the training stage.
- To solve the problem of image resolution loss associated with SPP structure, The SoftPooling algorithm is adopted to replace the SPP module. SoftPooling retains the defining activation features to the maximum extent. In Chapter 3, we designed ablation experiments to demonstrate that the method can improve the model’s sensitivity to small objects, especially for cattle head, legs, and tail.
- An anchor box has a significant influence on the results. This work used the k-means ++ algorithm to cluster corresponding labels of relevant data to obtain anchor boxes more suitable for detecting cattle key parts.
2. Materials and Methods
2.1. Data Sources
2.2. Prediction and Classification of Bounding Boxes
2.3. Backbone Feature Extraction Network
2.3.1. Filter_Attention Module
2.3.2. Pooling Layers
2.3.3. Optimized Design of the Anchor Box
- (a)
- Randomly selects K objects from N samples, each of which represents the initial mean or center of mass of a cluster
- (b)
- Assigns the remaining objects to the closest cluster based on their Euclidean distance to the mean of each cluster
- (c)
- It uses the mean of the samples in each cluster as the new center of mass. Next, steps (b) and (c) are repeated sequentially until the cluster means no longer change, and the cluster centers no longer change.
3. Experiments and Analyses
3.1. Experimental Platform Construction
3.2. Evaluation Indicators
3.3. Ablation Experiments
3.4. Comparative Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bai, Q.; Gao, R.; Zhao, C.; Li, Q.; Wang, R.; Li, S. Multi-scale behavior recognition method for dairy cows based on improved YOLOV5s network. Trans. Chin. Soc. Agric. Eng. 2022, 38, 163–172. [Google Scholar]
- Wang, R.; Gao, Z.; Li, Q.; Zhao, C.; Gao, R.; Zhang, H.; Li, S.; Feng, L. Detection Method of Cow Estrus Behavior in Natural Scenes Based on Improved YOLOv5. Agriculture 2022, 12, 1339. [Google Scholar] [CrossRef]
- Beggs, D.S.; Jongman, E.C.; Hemsworth, P.H.; Fisher, A.D. Lame cows on Australian dairy farms: A comparison of farmer-identified lameness and formal lameness scoring, and the position of lame cows within the milking order. J. Dairy Sci. 2019, 102, 1522–1529. [Google Scholar] [CrossRef] [PubMed]
- Duraiswami, N.R.; Bhalerao, S.; Watni, A.; Aher, C.N. Cattle Breed Detection and Categorization Using Image Processing and Machine Learning. In Proceedings of the 2022 International Conference on Advancements in Smart, Secure and Intelligent Computing (ASSIC), Bhubaneswar, India, 19–20 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Yılmaz, A.; Uzun, G.N.; Gürbüz, M.Z.; Kıvrak, O. Detection and Breed Classification of Cattle Using YOLO v4 Algorithm. In Proceedings of the 2021 International Conference on Innovations in Intelligent Systems and Applications (INISTA), Kocaeli, Turkey, 25–27 August 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Xu, B.; Wang, W.; Guo, L.; Chen, G.; Li, Y.; Cao, Z.; Wu, S. CattleFaceNet: A cattle face identification approach based on RetinaFace and ArcFace loss. Comput. Electron. Agric. 2022, 193, 106675. [Google Scholar] [CrossRef]
- Neethirajan, S. Happy Cow or Thinking Pig? WUR Wolf—Facial Coding Platform for Measuring Emotions in Farm Animals. AI 2021, 2, 342–354. [Google Scholar] [CrossRef]
- Kang, X.; Zhang, X.D.; Liu, G. Accurate detection of lameness in dairy cattle with computer vision: A new and individualized detection strategy based on the analysis of the supporting phase. J. Dairy Sci. 2020, 103, 10628–10638. [Google Scholar] [CrossRef]
- Gardenier, J.; Underwood, J.; Clark, C. Object Detection for Cattle Gait Tracking. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2206–2213. [Google Scholar] [CrossRef]
- Song, X.; Bokkers, E.; van Mourik, S.; Koerkamp, P.G.; van der Tol, P. Automated body condition scoring of dairy cows using 3-dimensional feature extraction from multiple body regions. J. Dairy Sci. 2019, 102, 4294–4308. [Google Scholar] [CrossRef]
- Tzanidakis, C.; Tzamaloukas, O.; Simitzis, P.; Panagakis, P. Precision Livestock Farming Applications (PLF) for Grazing Animals. Agriculture 2023, 13, 288. [Google Scholar] [CrossRef]
- Huang, X.; Li, X.; Hu, Z. Cow tail detection method for body condition score using faster R-CNN. In Proceedings of the IEEE International Conference on Unmanned Systems and Artificial Intelligence (ICUSAI), Xi’an, China, 22–24 November 2019; pp. 347–351. [Google Scholar]
- Smith, D.; Little, B.; Greenwood, P.I.; Valencia, P.; Rahman, A.; Ingham, A.; Bishop-Hurley, G.; Shahriar, M.S.; Hellicar, A. A study of sensor derived features in cattle behaviour classification models. In Proceedings of the 2015 IEEE SENSORS, Busan, Republic of Korea, 1–4 November 2015; IEEE: New York, NY, USA, 2015; pp. 1–4. [Google Scholar]
- Wang, K.; Wu, P.; Cui, H.; Xuan, C.; Su, H. Identification and classification for sheep foraging behavior based on acoustic signal and deep learning. Comput. Electron. Agric. 2021, 187, 106275. [Google Scholar] [CrossRef]
- Zhao, K.X.; He, D.J. Target detection method for moving cows based on background subtraction. Int. J. Agric. Biol. Eng. 2015, 8, 42–49. [Google Scholar]
- Li, G.; He, D.; Zhao, K.; Lei, Y. Decomposing of Cows’ Body Parts based on Skeleton Feature. J. Agric. Sci. Technol. 2017, 19, 87–94. [Google Scholar] [CrossRef]
- Shao, W.; Kawakami, R.; Yoshihashi, R.; You, S.; Kawase, H.; Naemura, T. Cattle detection and counting in UAV images based on convolutional neural networks. Int. J. Remote Sens. 2020, 41, 31–52. [Google Scholar] [CrossRef]
- Jiang, B.; Wu, Q.; Yin, X.; Wu, D.; Song, H.; He, D. FLYOLOv3 deep learning for key parts of dairy cow body detection. Comput. Electron. Agric. 2019, 166, 104982. [Google Scholar] [CrossRef]
- Shen, W.; Hu, H.; Dai, B.; Wei, X.; Sun, J.; Jiang, L.; Sun, Y. Individual identification of dairy cows based on convolutional neural networks. Multimed. Tools Appl. 2020, 79, 14711–14724. [Google Scholar] [CrossRef]
- Huang, X.; Hu, Z.; Qiao, Y.; Sukkarieh, S. Deep Learning-Based Cow Tail Detection and Tracking for Precision Livestock Farming. IEEE/ASME Trans. Mechatron. 2022. early access. [Google Scholar] [CrossRef]
- Qiao, Y.; Guo, Y.; He, D. Cattle body detection based on YOLOv5-ASFF for precision livestock farming. Comput. Electron. Agric. 2023, 204, 107579. [Google Scholar] [CrossRef]
- Xiao, J.; Liu, G.; Wang, K.; Si, Y. Cow identification in free-stall barns based on an improved Mask R-CNN and an SVM. Comput. Electron. Agric. 2022, 194, 106738. [Google Scholar] [CrossRef]
- Weng, Z.; Meng, F.; Liu, S.; Zhang, Y.; Zheng, Z.; Gong, C. Cattle face recognition based on a Two-Branch convolutional neural network. Comput. Electron. Agric. 2022, 196, 106871. [Google Scholar] [CrossRef]
- Xu, B.; Wang, W.; Guo, L.; Chen, G.; Wang, Y.; Zhang, W.; Li, Y. Evaluation of Deep Learning for Automatic Multi-View Face Detection in Cattle. Agriculture 2021, 11, 1062. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Zhang, Y.; Zhou, W.; Wang, Y.; Xu, L. A real-time recognition method of static gesture based on DSSD. Multimed. Tools Appl. 2020, 79, 17445–17461. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Singh, S.; Krishnan, S. Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks. arXiv 2019, arXiv:1911.09737. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar] [CrossRef]
- Stergiou, A.; Poppe, R.; Kalliatakis, G. Refining activation downsampling with SoftPool. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10337–10346. [Google Scholar] [CrossRef]
- Xiao, D.Q.; Lin, S.C.; Liu, Y.F.; Yang, Q.M.; Wu, H.L. Group-housed pigs and their body parts detection with Cascade Faster R-CNN. Int. J. Agric. Biol. Eng. 2022, 15, 203–209. [Google Scholar] [CrossRef]
- Ocepek, M.; Žnidar, A.; Lavrič, M.; Škorjanc, D.; Andersen, I.L. DigiPig: First Developments of an Automated Monitoring System for Body, Head and Tail Detection in Intensive Pig Farming. Agriculture 2022, 12, 2. [Google Scholar] [CrossRef]
- Wang, C.; Wang, J.; Du, Q.; Yang, X. Dog Breed Classification Based on Deep Learning. In Proceedings of the 2020 13th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 12–13 December 2020; pp. 209–212. [Google Scholar] [CrossRef]
- Wu, Y.; Guo, H.; Li, Z.; Ma, Q.; Zhao, Y.; Pezzuolo, A. Body Condition Score for Dairy Cows Method Based on Vision Transformer. In Proceedings of the 2021 IEEE International Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), Trento-Bolzano, Italy, 3–5 November 2021; pp. 37–41. [Google Scholar] [CrossRef]
- Zhao, K.X.; Shelley, A.N.; Lau, D.L.; Dolecheck, K.A.; Bewley, J.M. Automatic body condition scoring system for dairy cows based on depth-image analysis. Int. J. Agric. Biol. Eng. 2020, 13, 45–54. [Google Scholar] [CrossRef]
- Marsot, M.; Mei, J.; Shan, X.; Ye, L.; Feng, P.; Yan, X.; Li, C.; Zhao, Y. An adaptive pig face recognition approach using Convolutional Neural Networks. Comput. Electron. Agric. 2020, 173, 105386. [Google Scholar] [CrossRef]
- Fuentes, A.; Yoon, S.; Park, J.; Park, D.S. Deep learning-based hierarchical cattle behavior recognition with spatio-temporal information. Comput. Electron. Agric. 2020, 177, 105627. [Google Scholar] [CrossRef]
- Hu, H.; Dai, B.; Shen, W.; Wei, X.; Sun, J.; Li, R.; Zhang, Y. Cow identification based on fusion of deep parts features. Biosyst. Eng. 2020, 192, 245–256. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | AP | F1 | mAP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Cow | Head | Leg | Tail | Cow | Head | Leg | Tail | ||
| Yolov5 | 93.02 | 94.36 | 86.02 | 70.19 | 0.87 | 0.91 | 0.80 | 0.56 | 85.90 |
| Yolov5a | 94.02 | 93.80 | 87.21 | 72.34 | 0.88 | 0.90 | 0.81 | 0.67 | 86.86 |
| Yolov5b | 95.17 | 96.09 | 88.06 | 77.10 | 0.91 | 0.91 | 0.81 | 0.72 | 89.10 |
| Yolov5c | 95.91 | 95.99 | 89.08 | 80.73 | 0.92 | 0.91 | 0.81 | 0.71 | 90.23 |
| Ours | 95.13 | 95.75 | 88.12 | 83.96 | 0.90 | 0.92 | 0.85 | 0.78 | 90.74 |
| Algorithm | Parts | AP | F1 | Recall | Precision | mAP |
|---|---|---|---|---|---|---|
| SSD-VGG16 | Cow | 92.88 | 0.86 | 89.72 | 82.55 | 77.35 |
| Haed | 94.34 | 0.90 | 90.09 | 89.32 | ||
| Leg | 78.50 | 0.70 | 59.31 | 86.12 | ||
| Tail | 43.68 | 0.08 | 4.29 | 100 | ||
| Effcientdet-ResNet50 | Cow | 94.56 | 0.91 | 90.51 | 91.60 | 71.72 |
| Head | 92.04 | 0.90 | 88.79 | 90.75 | ||
| Leg | 74.12 | 0.57 | 41.91 | 89.53 | ||
| Tail | 26.17 | 0.13 | 7.14 | 100 | ||
| Faster-R-CNN-ResNet50 | Cow | 92.04 | 0.82 | 96.05 | 71.47 | 81.45 |
| Head | 92.90 | 0.87 | 92.67 | 82.69 | ||
| Leg | 79.87 | 0.69 | 85.05 | 58.12 | ||
| Tail | 61.01 | 0.61 | 70.00 | 54.44 | ||
| CenterNet-ResNet50 | Cow | 93.60 | 0.90 | 87.75 | 92.50 | 85.35 |
| Head | 93.52 | 0.92 | 90.52 | 94.17 | ||
| Leg | 81.29 | 0.79 | 73.28 | 86.67 | ||
| Tail | 72.98 | 0.68 | 54.29 | 90.48 | ||
| Ours | Cow | 95.13 | 0.92 | 92.09 | 88.26 | 90.74 |
| Head | 95.75 | 0.92 | 89.66 | 94.12 | ||
| Leg | 88.12 | 0.85 | 79.66 | 90.53 | ||
| Tail | 83.96 | 0.78 | 67.14 | 92.16 |
| References | Precision% | AP% | Detection Parts/Species |
|---|---|---|---|
| [18] | - | 90.91; 99.45; 90.83 | Head + Trunk + Leg/cow |
| [19] | - | 80.51; 97.44; 86.67 | Head + Trunk + Leg/cow |
| [47] | - | 72.88; 93.98; 84.86 | Head + Trunk + Leg/cow |
| [40] | - | 92.5; 90.5; 96.5 | Head + Back + Tail/pig |
| [41] | 96; 66; 76 | - | Pig + Head + Tail/pig |
| Ours | 94.12; 88.26; 90.53 | 95.13; 95.75; 88.12 | Head + Trunk + Leg/cattle |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, D.; He, Z.; Fan, H.; Sun, K. Detection of Cattle Key Parts Based on the Improved Yolov5 Algorithm. Agriculture 2023, 13, 1110. https://doi.org/10.3390/agriculture13061110
Shao D, He Z, Fan H, Sun K. Detection of Cattle Key Parts Based on the Improved Yolov5 Algorithm. Agriculture. 2023; 13(6):1110. https://doi.org/10.3390/agriculture13061110
Chicago/Turabian StyleShao, Dangguo, Zihan He, Hongbo Fan, and Kun Sun. 2023. "Detection of Cattle Key Parts Based on the Improved Yolov5 Algorithm" Agriculture 13, no. 6: 1110. https://doi.org/10.3390/agriculture13061110
APA StyleShao, D., He, Z., Fan, H., & Sun, K. (2023). Detection of Cattle Key Parts Based on the Improved Yolov5 Algorithm. Agriculture, 13(6), 1110. https://doi.org/10.3390/agriculture13061110