
Prediction of Tea Varieties’ “Suitable for People” Relationship: Based on the InteractE-SE+GCN Model



Abstract
:1. Introduction
- We improved the initial InteractE model by combining it with SENet (the improved model is called InteractE-SE) and incorporated SENet after the feature layer of the InteractE model to enhance the capture of helpful information in the feature channel.
- We combined the above model with GCN to improve the InteractE model so that the GCN layer in the CompGCN model is used as an encoder and the SENet-incorporated InteractE model is used as a decoder (the improved model is called IntGCN), which strengthens the model’s ability to extract complex interaction information between entities and relationships. After several experiments, the improved model significantly improved the prediction metrics on public datasets (WN18RR, Kinship).
- We constructed a dataset containing 6698 records, including 330 types of tea and 29 types of relationships. Combining the improved model (IntGCN) with migration learning, we comprehensively used the knowledge and patterns the improved model learned in WN18RR to predict the “suitable for people” relationships in the tea dataset and complete the tea knowledge graph using the prediction results. This study thereby helps to explore the value potential of tea varieties and provides some references for tea research.
2. Materials and Methods
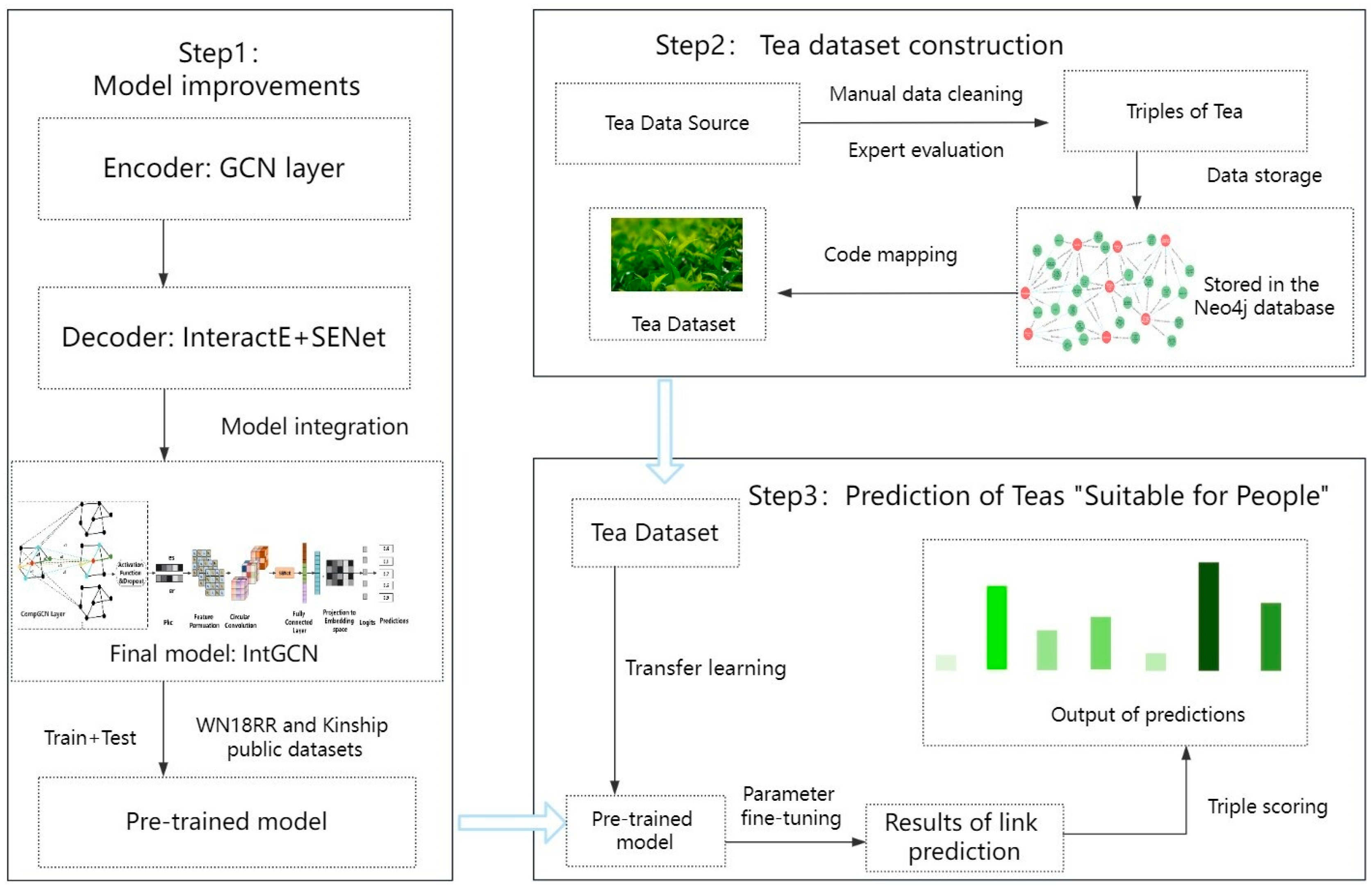
2.1. Research Process
2.2. Model Design
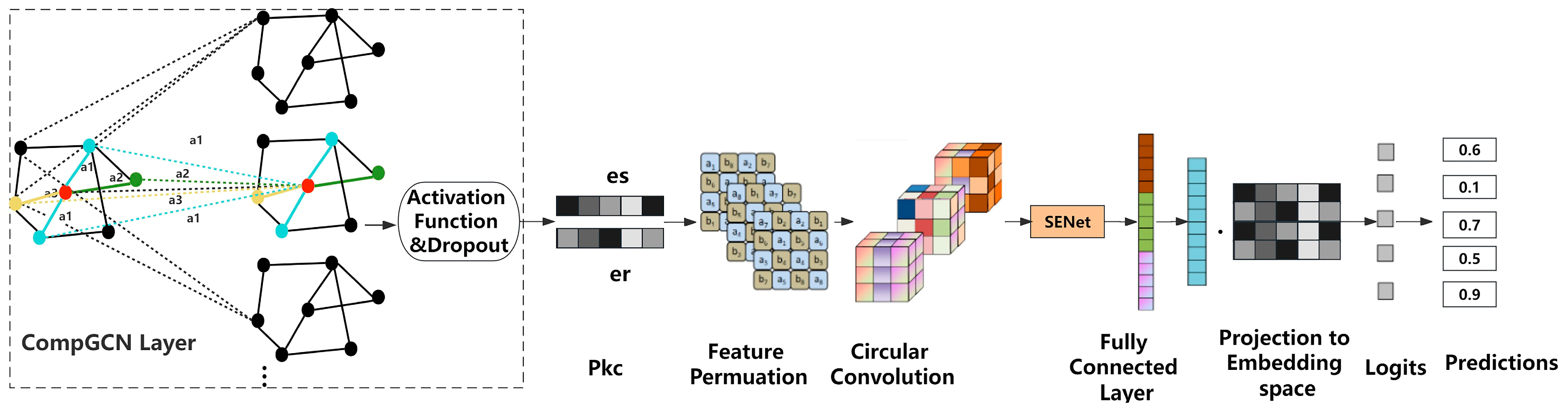
2.2.1. GCN Layer
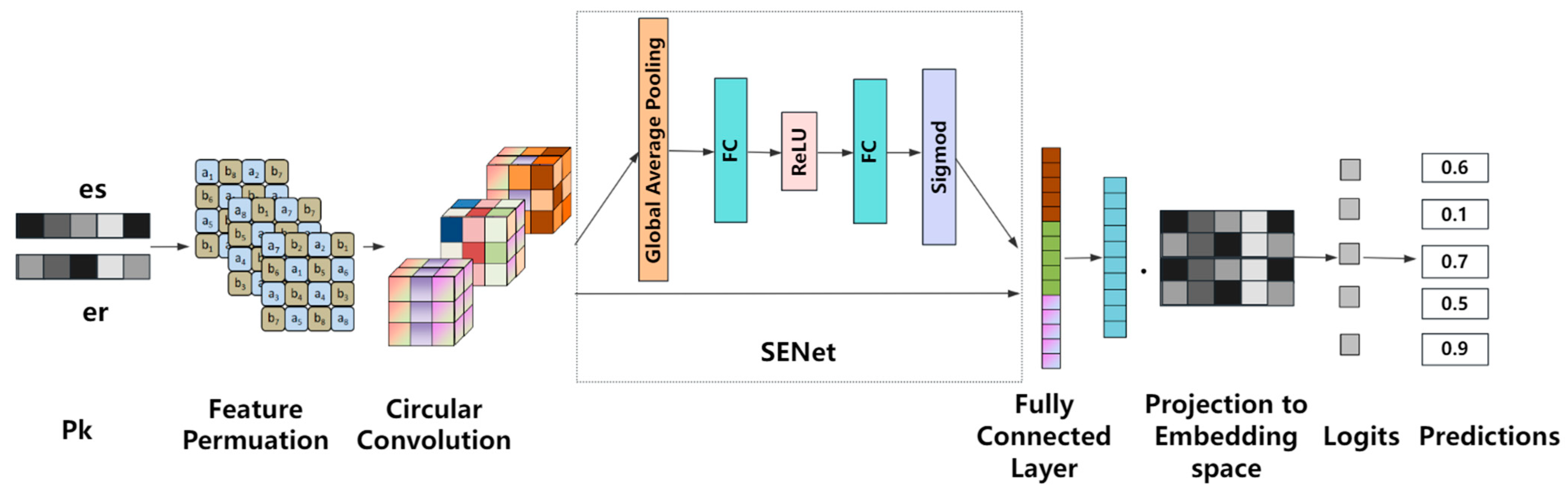
2.2.2. InteractE-SE
2.2.3. IntGCN
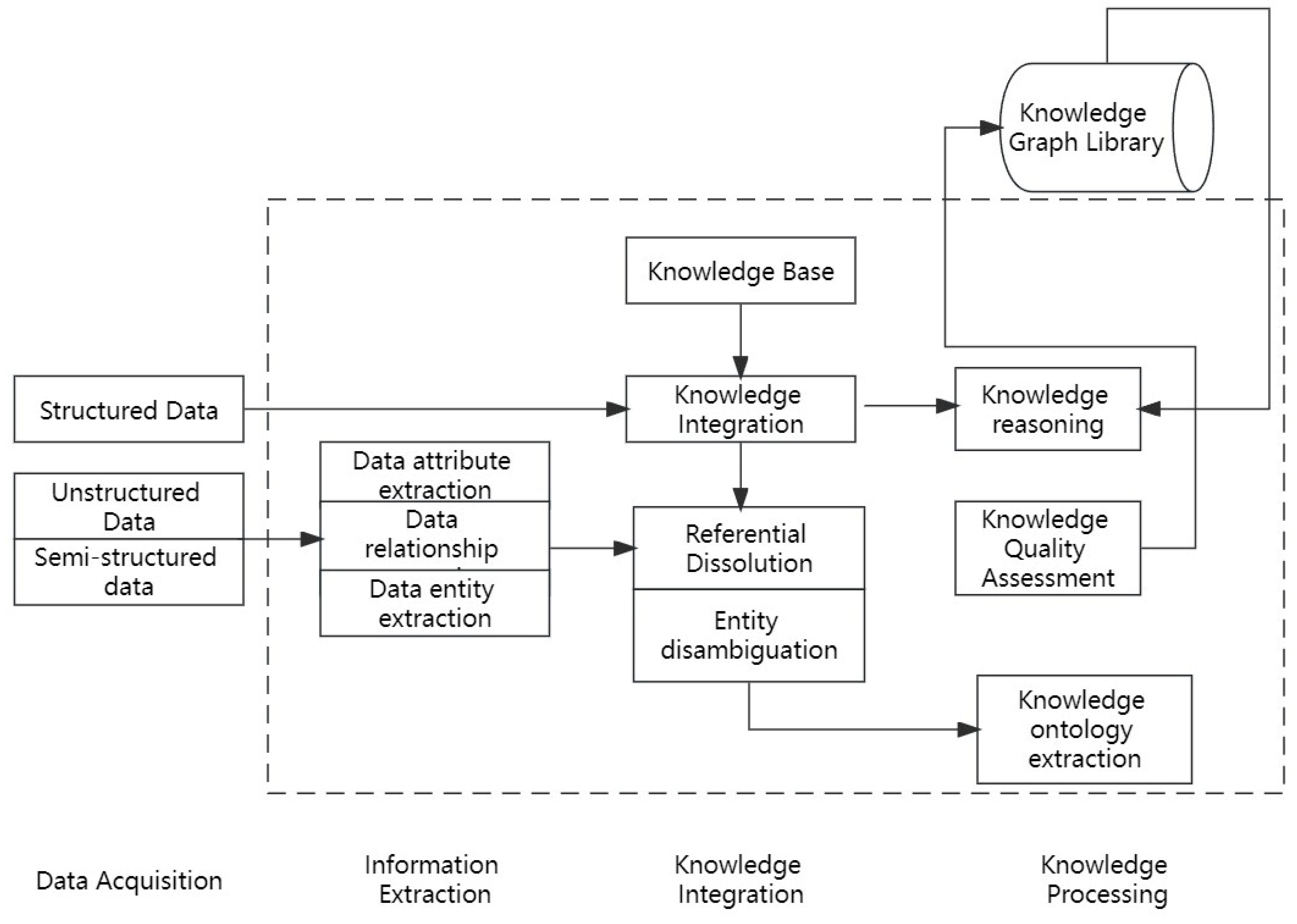
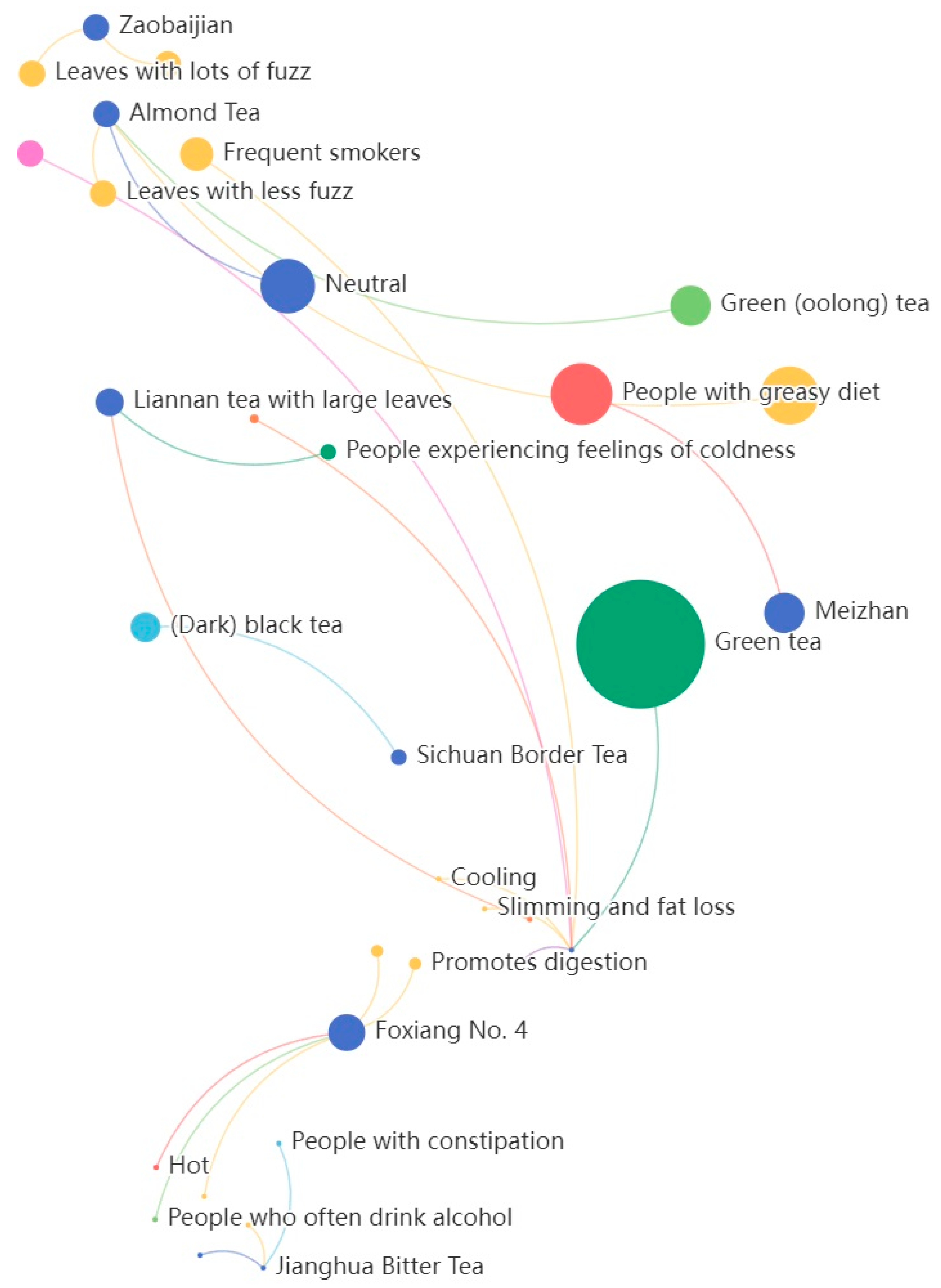
2.3. Constructing the Tea Knowledge Graph
2.4. Experimental Method Design
2.4.1. Dataset and Evaluation Metrics
2.4.2. Training Environment and Parameter Settings
2.4.3. Transfer Learning
3. Results
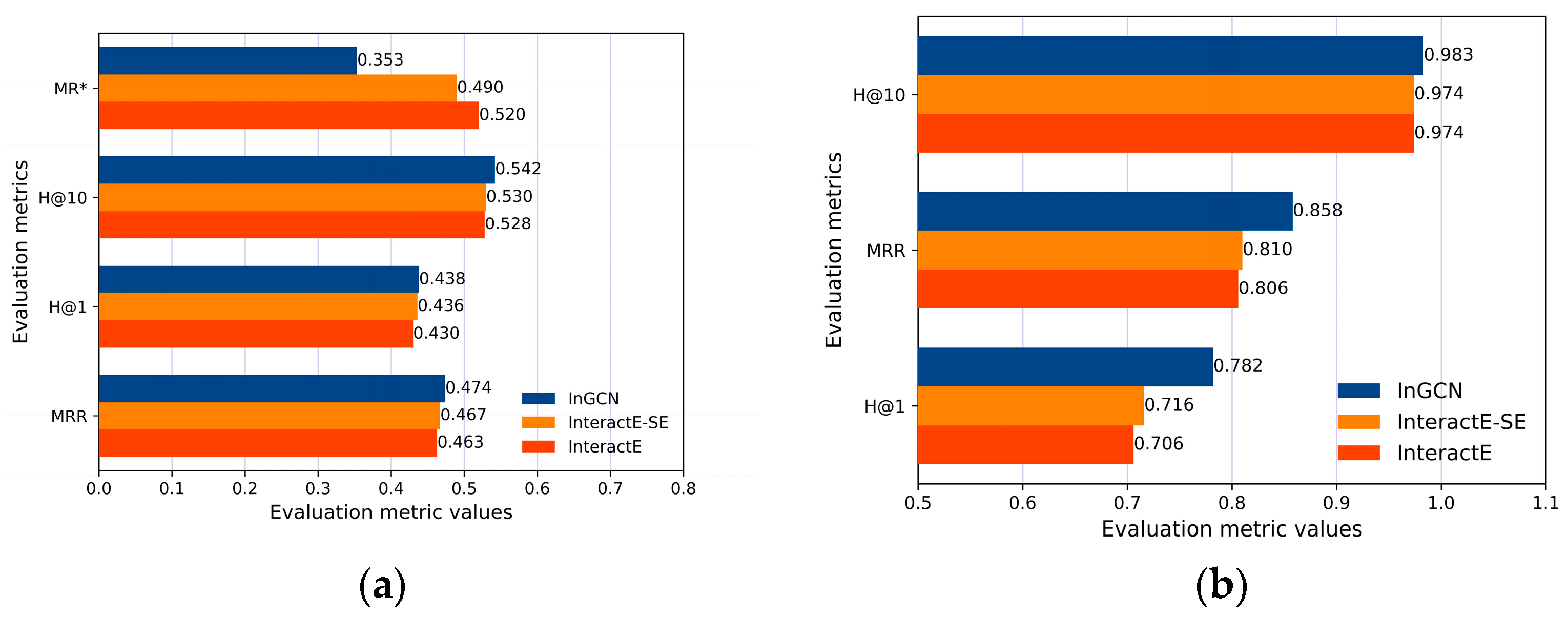
3.1. Evaluation of Public Datasets
3.1.1. Comparison of Link Prediction Performance
3.1.2. Ablation Evaluation
3.2. Evaluation of ID_Tea Dataset
3.2.1. Comparison of Link Prediction Performance
3.2.2. Ablation Evaluation
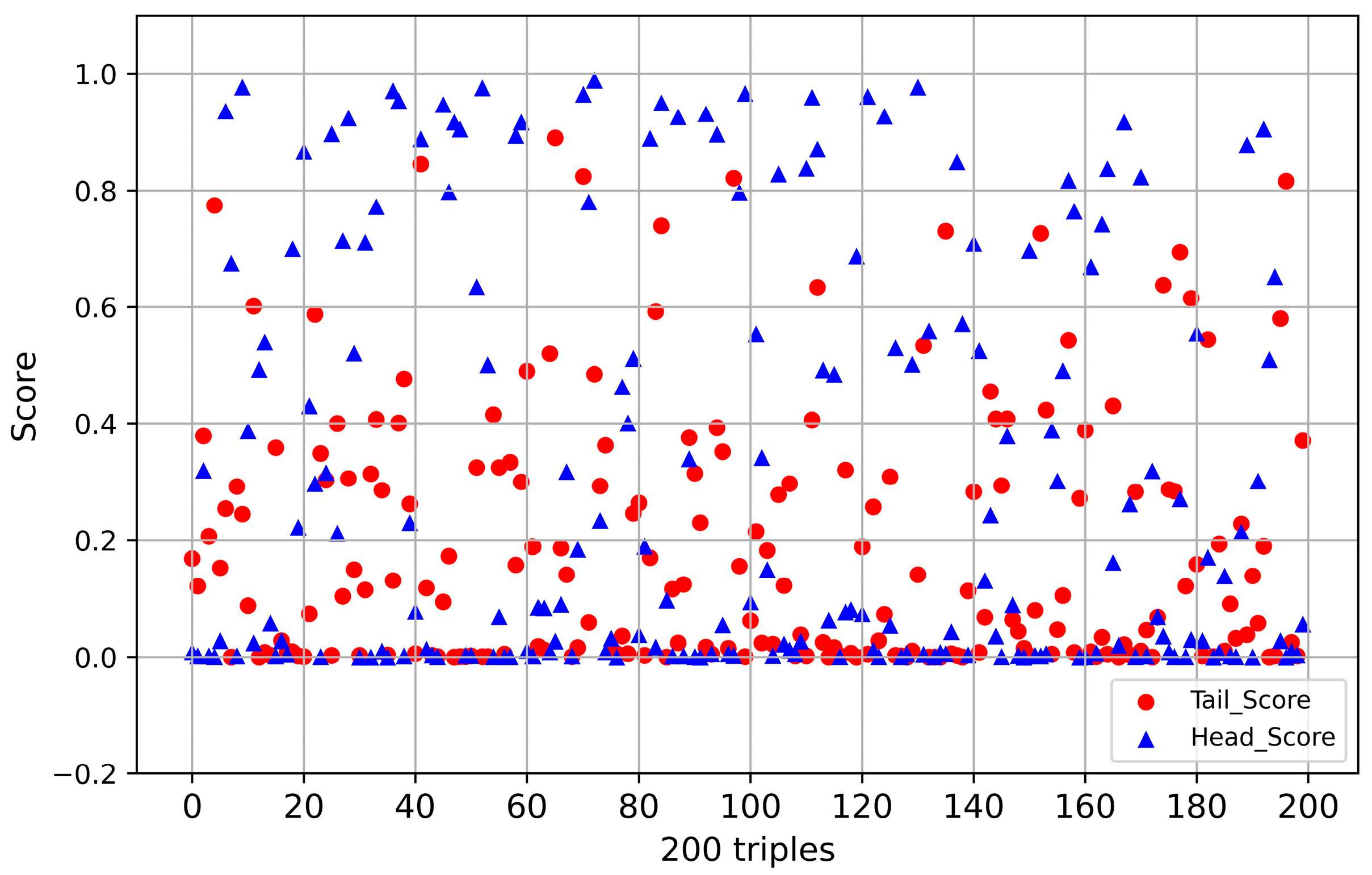
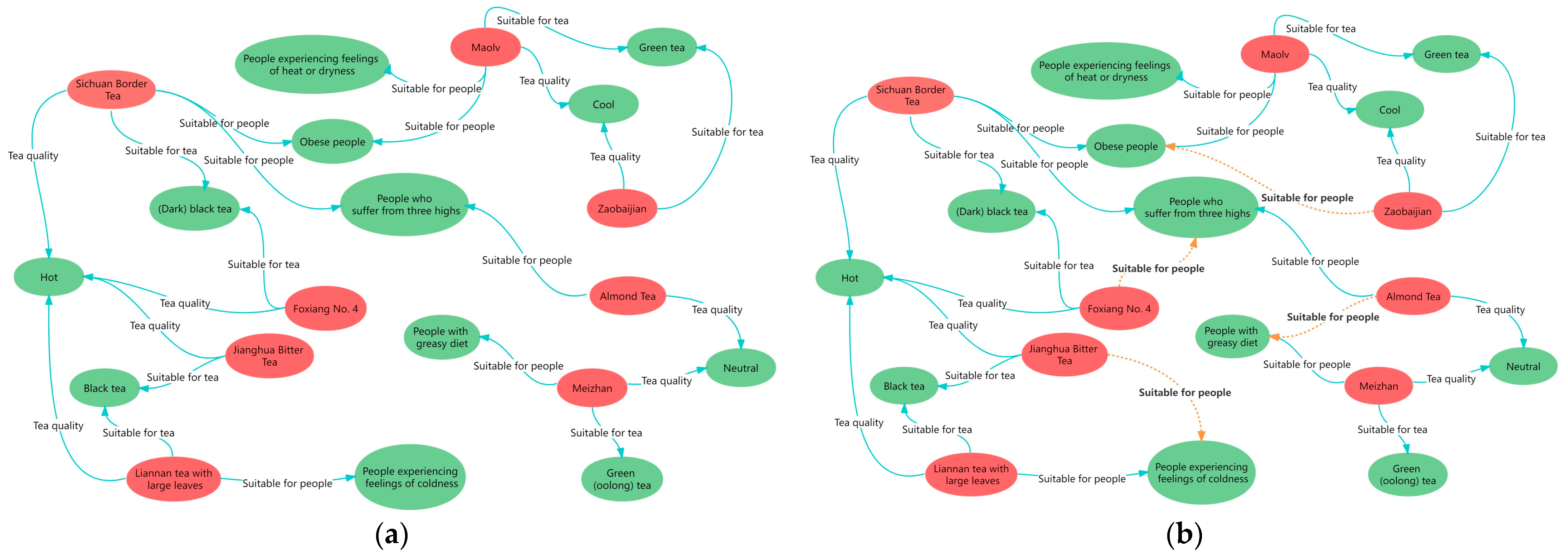
3.2.3. Relationship Prediction and Knowledge Graph Completion
4. Discussion
5. Conclusions
- Crop–soil adaptability prediction: By constructing knowledge graphs for crops and soils and leveraging link prediction algorithms, we can forecast the adaptability relationships between different crops and soils. This would aid farmers in selecting the most suitable crops for cultivation and optimising soil management strategies.
- Agricultural product quality assessment: By constructing knowledge graphs for agricultural products, link prediction algorithms can forecast these products’ quality characteristics and relevant attributes. For instance, they could predict fruit ripeness or the nutritional values of agricultural products, thereby assisting farmers and consumers in making informed decisions.
- Agricultural disease prediction: By constructing a knowledge graph that connects crops, diseases, and environmental conditions, it is possible to utilise link prediction algorithms to predict the probability of crops being affected by specific diseases. This approach can assist farmers in taking timely preventive measures and reducing damage to their crops caused by diseases. A well-designed and adequately implemented agricultural disease prediction system could significantly impact crop yields and the agricultural industry.
- Optimisation of agricultural supply chains: By constructing knowledge graphs for agricultural supply chains, link prediction algorithms can predict partner relationships, resource allocation, and the feasibility of transactions at various stages. This would optimise the agricultural supply chain’s operational efficiency and profit distribution.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shen, W.; Xiao, Y.; Ying, X.; Li, S.; Zhai, Y.; Shang, X.; Li, F.; Wang, X.; He, F.; Lin, J. Correction: Tea consumption and cognitive impairment: A cross-sectional study among Chinese elderly. PLoS ONE 2015, 10, e0140739. [Google Scholar] [CrossRef] [PubMed]
- Tang, G.-Y.; Meng, X.; Gan, R.-Y.; Zhao, C.-N.; Liu, Q.; Feng, Y.-B.; Li, S.; Wei, X.-L.; Atanasov, A.G.; Corke, H. Health functions and related molecular mechanisms of tea components: An update review. Int. J. Mol. Sci. 2019, 20, 6196. [Google Scholar] [CrossRef]
- Sae-Tan, S.; Grove, K.A.; Lambert, J.D. Weight control and prevention of metabolic syndrome by green tea. Pharmacol. Res. 2011, 64, 146–154. [Google Scholar] [CrossRef] [PubMed]
- Schönthal, A.H. Adverse effects of concentrated green tea extracts. Mol. Nutr. Food Res. 2011, 55, 874–885. [Google Scholar] [CrossRef] [PubMed]
- Pan, S.-Y.; Nie, Q.; Tai, H.-C.; Song, X.-L.; Tong, Y.-F.; Zhang, L.-J.-F.; Wu, X.-W.; Lin, Z.-H.; Zhang, Y.-Y.; Ye, D.-Y. Tea and tea drinking: China’s outstanding contributions to the mankind. Chin. Med. 2022, 17, 27. [Google Scholar] [CrossRef]
- Mahdavi-Roshan, M.; Salari, A.; Ghorbani, Z.; Ashouri, A. The effects of regular consumption of green or black tea beverage on blood pressure in those with elevated blood pressure or hypertension: A systematic review and meta-analysis. Complement. Ther. Med. 2020, 51, 102430. [Google Scholar] [CrossRef]
- Yan, W.; Ge, Z. Research on Winter Tea Application and Promotion Value. Mod. Econ. 2020, 11, 817–828. [Google Scholar] [CrossRef]
- Lee, J.; Kang, S. Consumer-driven usability test of mobile application for tea recommendation service. Appl. Sci. 2019, 9, 3961. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, W.; Shan, Z.; Zhang, C.; Dong, T.; Feng, Z.; Wang, C. Moisture contents and product quality prediction of Pu-erh tea in sun-drying process with image information and environmental parameters. Food Sci. Nutr. 2022, 10, 1021–1038. [Google Scholar] [CrossRef] [PubMed]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.d.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S. Knowledge graphs. ACM Comput. Surv. (CSUR) 2021, 54, 71. [Google Scholar] [CrossRef]
- Xiaoxue, L.; Xuesong, B.; Longhe, W.; Bingyuan, R.; Shuhan, L.; Lin, L. Review and trend analysis of knowledge graphs for crop pest and diseases. IEEE Access 2019, 7, 62251–62264. [Google Scholar] [CrossRef]
- Chen, Y.; Kuang, J.; Cheng, D.; Zheng, J.; Gao, M.; Zhou, A. AgriKG: An agricultural knowledge graph and its applications. In Proceedings of the Database Systems for Advanced Applications: DASFAA 2019 International Workshops: BDMS, BDQM, and GDMA, Chiang Mai, Thailand, 22–25 April 2019; pp. 533–537. [Google Scholar] [CrossRef]
- Rossi, A.; Barbosa, D.; Firmani, D.; Matinata, A.; Merialdo, P. Knowledge graph embedding for link prediction: A comparative analysis. ACM Trans. Knowl. Discov. Data (TKDD) 2021, 15, 1–49. [Google Scholar] [CrossRef]
- Wang, M.; Qiu, L.; Wang, X. A survey on knowledge graph embeddings for link prediction. Symmetry 2021, 13, 485. [Google Scholar] [CrossRef]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar] [CrossRef]
- Che, F.; Zhang, D.; Tao, J.; Niu, M.; Zhao, B. Parame: Regarding neural network parameters as relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2774–2781. [Google Scholar] [CrossRef]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Agrawal, N.; Talukdar, P. Interacte: Improving convolution-based knowledge graph embeddings by increasing feature interactions. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3009–3016. [Google Scholar] [CrossRef]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Greece, 3–7 June 2018; pp. 593–607. [Google Scholar] [CrossRef]
- Nathani, D.; Chauhan, J.; Sharma, C.; Kaul, M. Learning attention-based embeddings for relation prediction in knowledge graphs. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Zeb, A.; Saif, S.; Chen, J.; Haq, A.U.; Gong, Z.; Zhang, D. Complex graph convolutional network for link prediction in knowledge graphs. Expert Syst. Appl. 2022, 200, 116796. [Google Scholar] [CrossRef]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P. Composition-based multi-relational graph convolutional networks. arXiv 2019, arXiv:1911.0308. [Google Scholar]
- McCoy, K.; Gudapati, S.; He, L.; Horlander, E.; Kartchner, D.; Kulkarni, S.; Mehra, N.; Prakash, J.; Thenot, H.; Vanga, S.V. Biomedical text link prediction for drug discovery: A case study with COVID-19. Pharmaceutics 2021, 13, 794. [Google Scholar] [CrossRef] [PubMed]
- Huo, Z.; Huang, X.; Hu, X. Link prediction with personalized social influence. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar] [CrossRef]
- Nasiri, E.; Berahmand, K.; Samei, Z.; Li, Y. Impact of centrality measures on the common neighbors in link prediction for multiplex networks. Big Data 2022, 10, 138–150. [Google Scholar] [CrossRef] [PubMed]
- Shabaz, M.; Garg, U. Predicting future diseases based on existing health status using link prediction. World J. Eng. 2022, 19, 29–32. [Google Scholar] [CrossRef]
- Nasiri, E.; Berahmand, K.; Rostami, M.; Dabiri, M. A novel link prediction algorithm for protein-protein interaction networks by attributed graph embedding. Comput. Biol. Med. 2021, 137, 104772. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Ma, X. Knowledge graph construction and application in geosciences: A review. Comput. Geosci. 2022, 161, 105082. [Google Scholar] [CrossRef]
- Cheng, S.; Wang, T.; Guo, X.; Wang, Y. Knowledge Graph construction of Thangka icon characters based on Neo4j. In Proceedings of the 2020 International Conference on Intelligent Computing and Human-Computer Interaction (ICHCI), Sanya, China, 4–6 December 2020; pp. 218–221. [Google Scholar] [CrossRef]
- Lin, X.V.; Socher, R.; Xiong, C. Multi-hop knowledge graph reasoning with reward shaping. arXiv 2018, arXiv:1808.10568. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Yang, B.; Yih, W.-t.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 2071–2080. [Google Scholar]
- Shang, C.; Tang, Y.; Huang, J.; Bi, J.; He, X.; Zhou, B. End-to-end structure-aware convolutional networks for knowledge base completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 3060–3067. [Google Scholar] [CrossRef]
- Olcha, P.; Winiarska-Mieczan, A.; Kwiecień, M.; Nowakowski, Ł.; Miturski, A.; Semczuk, A.; Kiczorowska, B.; Gałczyński, K. Antioxidative, anti-inflammatory, anti-obesogenic, and antidiabetic properties of tea polyphenols—The positive impact of regular tea consumption as an element of prophylaxis and pharmacotherapy support in endometrial cancer. Int. J. Mol. Sci. 2022, 23, 6703. [Google Scholar] [CrossRef] [PubMed]
- Chen, P.; Li, C.; Chen, S.; Li, Z.; Zhang, H.; Zhao, C. Tea Cultivation Suitability Evaluation and Driving Force Analysis Based on AHP and Geodetector Results: A Case Study of Yingde in Guangdong, China. Remote Sens. 2022, 14, 2412. [Google Scholar] [CrossRef]
- Ye, J.; Wang, Y.; Kang, J.; Chen, Y.; Hong, L.; Li, M.; Jia, Y.; Wang, Y.; Jia, X.; Wu, Z. Effects of Long-Term Use of Organic Fertilizer with Different Dosages on Soil Improvement, Nitrogen Transformation, Tea Yield and Quality in Acidified Tea Plantations. Plants 2023, 12, 122. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.-Q.; Dong, S.-L.; Li, Z.-Y.; Lu, J.-L.; Ye, J.-H.; Tao, S.-K.; Hu, Y.-P.; Liang, Y.-R. Variation of Major Chemical Composition in Seed-Propagated Population of Wild Cocoa Tea Plant Camellia ptilophylla Chang. Foods 2023, 12, 123. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity 1 (Pictures and Tea Names) | Relations (Properties) | Entity 2 or Property Values |
|---|---|---|
 Maolv | Suitable for tea | Green tea |
| Tea quality | Cool | |
| Suitable for people | Obese people, people experiencing heat/dryness | |
| Value Effectiveness | Cooling, slows ageing, weight loss | |
| Propagation method | Asexual | |
| Germination time | Early life | |
| Characteristics | Leaves with lots of fuzz | |
 Foxiang No. 4 | Suitable for tea | (Dark) black tea |
| Tea quality | Hot | |
| Suitable for people | People who often drink alcohol | |
| Value Effectiveness | Slows ageing, promotes digestion, diuretic, relieves fatigue | |
| Characteristics | Leaves with lots of fuzz, high yield | |
| Place of origin | Yunnan Province | |
 Jianghua Bitter Tea | Suitable for tea | Black tea |
| Tea quality | Hot | |
| Place of origin | Jianghua Yao Autonomous County, Hunan Province | |
| Propagation method | Asexual | |
| Germination time | Mid-life | |
| Characteristics | High yield, leaves with lots of fuzz | |
| Value Effectiveness | Promotes digestion, diuretic, relieves fatigue | |
| Suitable for people | People with constipation | |
 Almond Tea | Suitable for tea | Green (oolong) tea |
| Tea quality | Neutral | |
| Place of origin | Jianghua Yao Autonomous County, Hunan Province | |
| Propagation method | Asexual | |
| Germination time | Late-life | |
| Characteristics | High yield, leaves with less fuzz | |
| Value Effectiveness | Slimming and fat loss, slows ageing | |
| Suitable for people | People who are easily fatigued | |
 Fuding Great White Tea | Suitable for tea | White tea |
| Tea quality | Cool | |
| Place of origin | Dutou Town, Fuding City, Fujian Province | |
| Propagation method | Asexual | |
| Germination time | Early birth | |
| Characteristics | High yield, cold resistant | |
| Value Effectiveness | Antidiarrhoeal, germicidal | |
| Suitable for people | People with poor immunity | |
 Junshanyinzhen | Suitable for tea | Yellow tea |
| Tea quality | Cool | |
| Place of origin | Dongting Lake, Yueyang, Hunan Province | |
| Category | Yellow tea | |
| Characteristics | Resembles silver needles | |
| Value Effectiveness | Cooling, relieves fatigue | |
| Suitable for people | People who often use computers |
| Dataset | Entities | Relations | Train | Validation | Test |
|---|---|---|---|---|---|
| WN18RR | 40943 | 11 | 86835 | 3034 | 3134 |
| Kinship | 104 | 25 | 8544 | 1068 | 1074 |
| ID_Tea | 1064 | 29 | 5368 | 665 | 665 |
| Hyperparameter | Values |
|---|---|
| Learning rate (lr) | {0.0001, 0.001, 0.005} |
| Batch size (batch) | {128, 256} |
| Convolutional kernel size (k) | {3, 5, 7, 9, 11} |
| Dimensional reduction setting for SENet (q) | {4,8,16} |
| Learning rate decay (d) | {1,0.95} |
| Model | Kinship | WN18RR | ||||||
|---|---|---|---|---|---|---|---|---|
| MRR | MR | H@10 | H@1 | MRR | MR | H@10 | H@1 | |
| TransE | 0.309 | 6.8 | 0.841 | 0.009 | 0.226 | 3384 | 0.501 | - |
| DistMult | 0.516 | 5.26 | 0.867 | 0.367 | 0.430 | 5110 | 0.490 | 0.390 |
| ComplEx | 0.823 | 2.48 | 0.971 | 0.733 | 0.440 | 5216 | 0.510 | 0.410 |
| R-GCN | 0.109 | 25.92 | 0.239 | 0.030 | - | - | - | - |
| KBGAN | 0.165 | - | 0.347 | - | 0.214 | - | 0.472 | - |
| ConvTransE | 0.824 | 2.53 | 0.972 | 0.734 | 0.460 | - | 0.520 | 0.430 |
| SACN | 0.759 | 3.25 | 0.951 | 0.643 | 0.470 | - | 0.540 | 0.430 |
| ConvE | 0.833 | 2.03 | 0.981 | 0.738 | 0.430 | 4187 | 0.520 | 0.400 |
| CompGCN | 0.840 | 2.10 | 0.982 | 0.753 | 0.469 | 3307 | 0.536 | 0.434 |
| InteractE | 0.806 | 2.32 | 0.974 | 0.706 | 0.463 | 5202 | 0.528 | 0.430 |
| Interact-SE | 0.810 | 2.31 | 0.974 | 0.716 | 0.467 | 4900 | 0.530 | 0.436 |
| IntGCN | 0.858 | 1.93 | 0.983 | 0.782 | 0.474 | 3533 | 0.542 | 0.438 |
| Model | GCN Layer | SENet | WN18RR | |||
|---|---|---|---|---|---|---|
| MRR | MR | H@10 | H@1 | |||
| InteractE | No | No | 0.463 | 5202 | 0.528 | 0.430 |
| No | Yes | 0.467 | 4900 | 0.530 | 0.436 | |
| Yes | No | 0.472 | 3266 | 0.540 | 0.437 | |
| Yes | Yes | 0.474 | 3533 | 0.542 | 0.438 | |
| Model | GCN Layer | SENet | Kinship | |||
|---|---|---|---|---|---|---|
| MRR | MR | H@10 | H@1 | |||
| InteractE | No | No | 0.806 | 2.32 | 0.974 | 0.706 |
| No | Yes | 0.810 | 2.31 | 0.974 | 0.716 | |
| Yes | No | 0.844 | 2.06 | 0.982 | 0.757 | |
| Yes | Yes | 0.858 | 1.93 | 0.983 | 0.782 | |
| Model | MRR (%) | H@1 (%) | H@3 (%) | H@10 (%) |
|---|---|---|---|---|
| ConvE | 56.4 | 47.6 | 61.4 | 72.9 |
| CompGCN | 60.2 | 53.4 | 63.3 | 72.7 |
| InteractE | 59.6 | 52.9 | 61.7 | 72.5 |
| InteractE-SE | 60.0 | 53.8 | 62.2 | 72.5 |
| IntGCN(noTransfer) | 61.3 | 54.3 | 64.9 | 74.2 |
| IntGCN | 61.6 | 54.4 | 65.8 | 75.0 |
| Model | GCN Layer | SENet | MRR (%) | H@1 (%) | H@3 (%) | H@10 (%) |
|---|---|---|---|---|---|---|
| InteractE | No | No | 59.6 | 52.9 | 61.7 | 72.5 |
| No | Yes | 60.0 | 53.8 | 62.2 | 72.5 | |
| Yes | No | 61.0 | 54.2 | 64.2 | 74.0 | |
| Yes | Yes | 61.3 | 54.3 | 64.9 | 74.2 |
| Prediction Triples | Scores |
|---|---|
| (Zaobaijian, suitable for people, obese people) | 0.952 |
| (Foxiang No. 4, suitable for people, people who suffer from three highs) | 0.977 |
| (Jianghua Bitter Tea, suitable for people, people experiencing feelings of coldness) | 0.965 |
| (Almond Tea, suitable for people, people with greasy diet) | 0.941 |
| (Foshou, suitable for people, people experiencing feelings of heat and dryness) | 0.709 |
| ··· | ··· |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Q.; Wu, Z.; Wang, M.; Tao, Y.; He, Y.; Marinello, F. Prediction of Tea Varieties’ “Suitable for People” Relationship: Based on the InteractE-SE+GCN Model. Agriculture 2023, 13, 1732. https://doi.org/10.3390/agriculture13091732
Huang Q, Wu Z, Wang M, Tao Y, He Y, Marinello F. Prediction of Tea Varieties’ “Suitable for People” Relationship: Based on the InteractE-SE+GCN Model. Agriculture. 2023; 13(9):1732. https://doi.org/10.3390/agriculture13091732
Chicago/Turabian StyleHuang, Qiang, Zongyuan Wu, Mantao Wang, Youzhi Tao, Yinghao He, and Francesco Marinello. 2023. "Prediction of Tea Varieties’ “Suitable for People” Relationship: Based on the InteractE-SE+GCN Model" Agriculture 13, no. 9: 1732. https://doi.org/10.3390/agriculture13091732
APA StyleHuang, Q., Wu, Z., Wang, M., Tao, Y., He, Y., & Marinello, F. (2023). Prediction of Tea Varieties’ “Suitable for People” Relationship: Based on the InteractE-SE+GCN Model. Agriculture, 13(9), 1732. https://doi.org/10.3390/agriculture13091732