
SGW-YOLOv8n: An Improved YOLOv8n-Based Model for Apple Detection and Segmentation in Complex Orchard Environments



Abstract
1. Introduction
2. Materials
2.1. Collection and Processing of Datasets
2.2. Hardware and System Environment
3. Methods
3.1. Network Model Based on Improved YOLOV8n—SGW-YOLOV8n
3.2. SPD-Conv Module and Its Composition
3.2.1. Overview of the SPD-Conv Module
3.2.2. Space-to-Depth Layer (SPD)
3.2.3. Non-Step Convolutional Layers
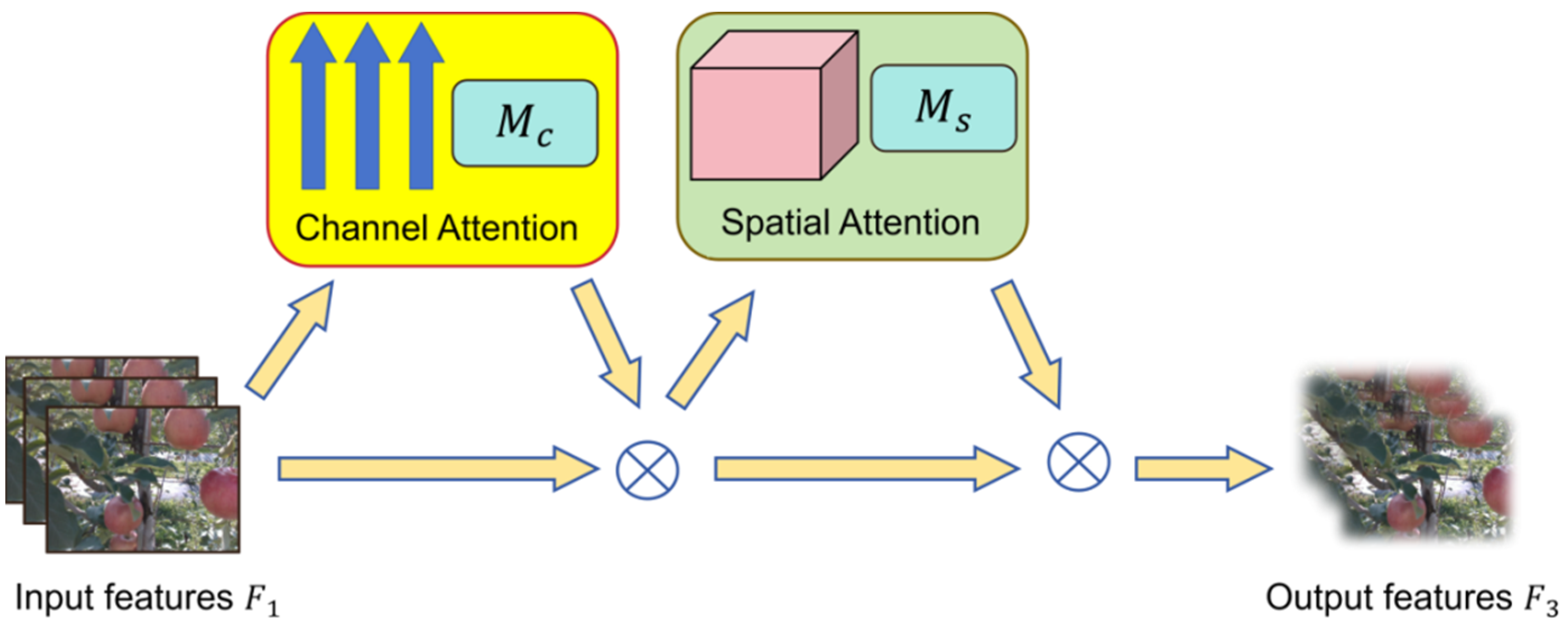
3.3. Global Attention Mechanism Module
3.3.1. Overview of Global Attention Mechanisms
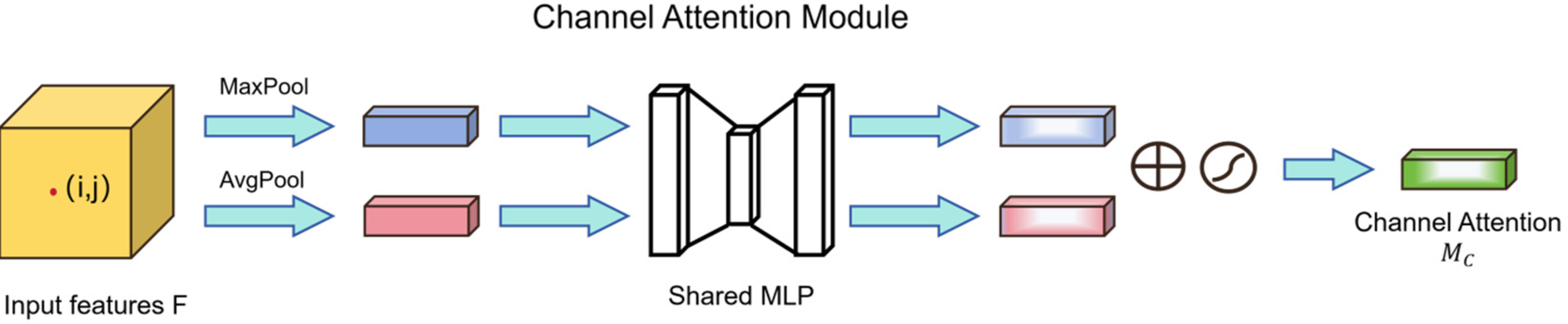
3.3.2. Channel Attention Mechanism
- Global information extraction
- 2.
- Channel weight generation
- 3.
- Weight adjustment
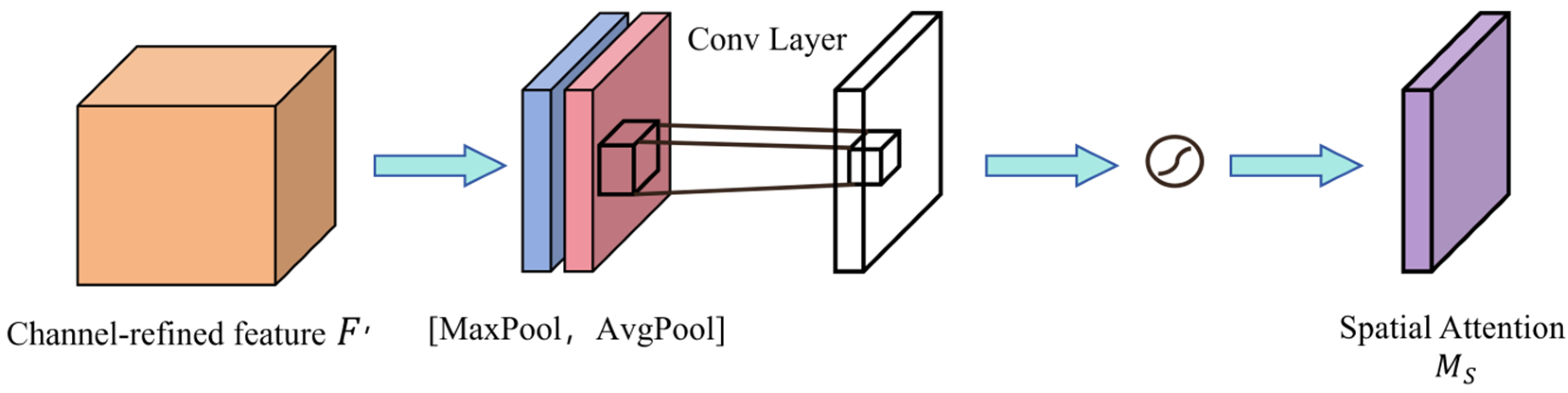
3.3.3. Spatial Attention Mechanism
- Feature map aggregation
- 2.
- Generate a spatial attention map
- 3.
- Weighting adjustment
3.4. Wise Intersection over Union (Wise-IoU) Loss Function Module
3.4.1. The Proposal of Wise-IoU and Its Core Mechanism
3.4.2. Schematic Diagram of Wise-IoU and Its Main Workflow
- Matching of anchor and target frames and calculation of loss function
- 2.
- Calculate the distance of the centre point.
- 3.
- Dynamic non-monotonic focusing mechanism
- 4.
- Loss function formula
3.5. Relevant Evaluation Indicators of YOLO Deep Learning Network Structure
4. Results
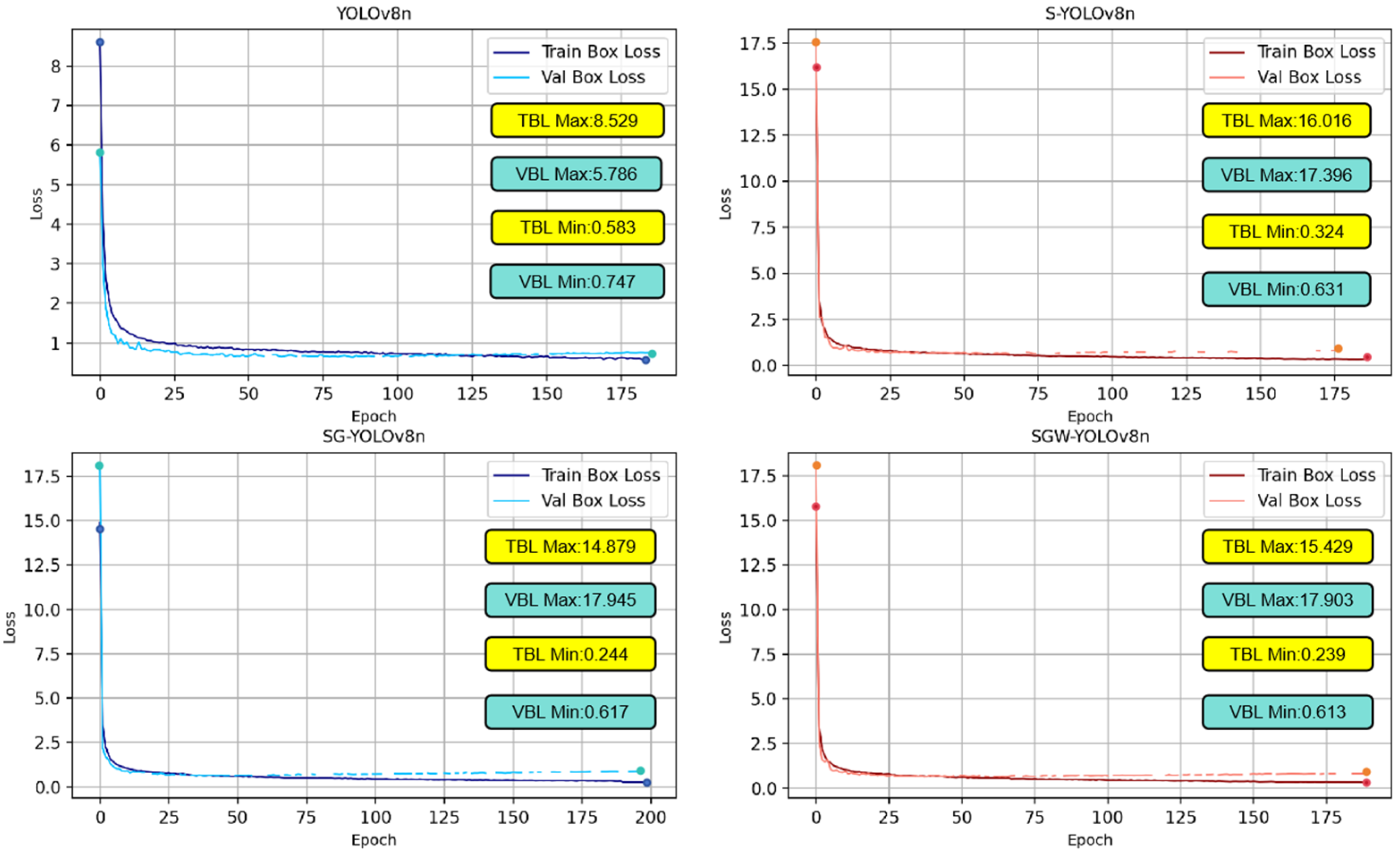
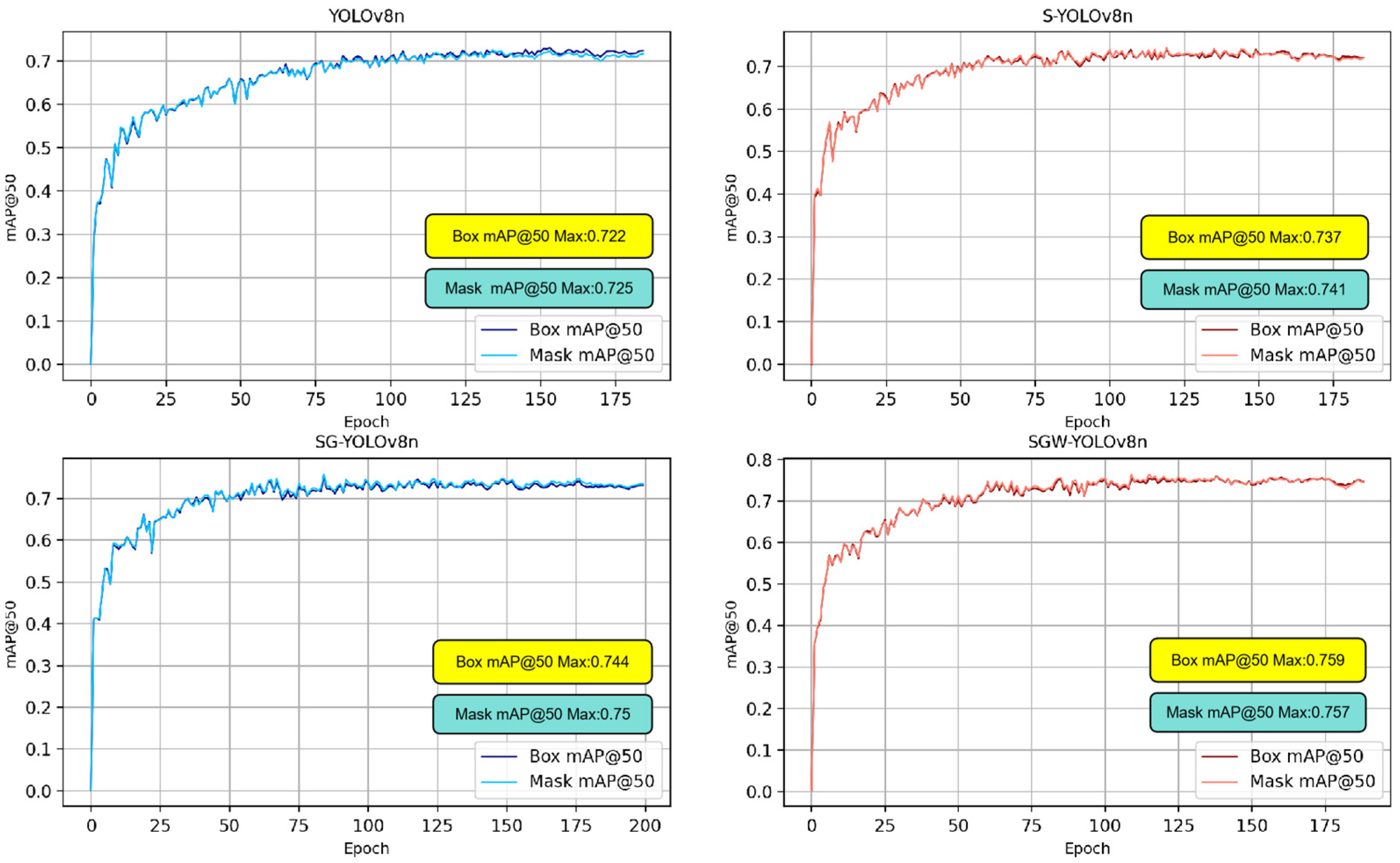
4.1. Ablation Experiment and Result Analysis
4.2. Comparison with Other Networks
4.3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Q.; Shi, F.; Abdullahi, N.M.; Shao, L.; Huo, X. An empirical study on spatial–temporal dynamics and influencing factors of apple production in China. PLoS ONE 2020, 15, e0240140. [Google Scholar] [CrossRef]
- Shi, L.; Shi, G.; Qiu, H. General review of intelligent agriculture development in China. China Agric. Econ. Rev. 2019, 11, 39–51. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Gené-Mola, J.; Sanz-Cortiella, R.; Rosell-Polo, J.R.; Morros, J.-R.; Ruiz-Hidalgo, J.; Vilaplana, V.; Gregorio, E. Fruit detection and 3D location using instance segmentation neural networks and structure-from-motion photogrammetry. Comput. Electron. Agric. 2020, 169, 105165. [Google Scholar] [CrossRef]
- Badgujar, C.M.; Poulose, A.; Gan, H. Agricultural object detection with You Look Only Once (YOLO) algorithm: A bibliometric and systematic literature review. arXiv 2024, arXiv:2401.10379. [Google Scholar] [CrossRef]
- Swathi, Y.; Challa, M. YOLOv8: Advancements and innovations in object detection. In International Conference on Smart Computing and Communication; Springer Nature: Singapore, 2024; pp. 1–13. [Google Scholar]
- Yang, S.; Wang, W.; Gao, S.; Deng, Z. Strawberry ripeness detection based on YOLOv8 algorithm fused with LW-Swin transformer. Comput. Electron. Agric. 2023, 215, 108360. [Google Scholar] [CrossRef]
- Qi, X.; Dong, J.; Lan, Y.; Zhu, H. Method for identifying litchi picking position based on YOLOv5 and PSPNet. Remote Sens. 2022, 14, 2004. [Google Scholar] [CrossRef]
- Zhang, L.; Luo, P.; Ding, S.; Li, T.; Qin, K.; Mu, J. The grading detection model for fingered citron slices (Citrus medica ‘fingered’) based on YOLOv8-FCS. Front. Plant Sci. 2024, 15, 1411178. [Google Scholar] [CrossRef]
- Wang, F.; Tang, Y.; Gong, Z.; Jiang, J.; Chen, Y.; Xu, Q.; Hu, P.; Zhu, H. A lightweight Yunnan Xiaomila detection and pose estimation based on improved YOLOv8. Front. Plant Sci. 2024, 15, 1421381. [Google Scholar] [CrossRef]
- Wang, X.; Liu, J. Vegetable disease detection using an improved YOLOv8 algorithm in the greenhouse plant environment. Sci. Rep. 2024, 14, 4261. [Google Scholar] [CrossRef]
- Zhou, S.; Zhou, H. Detection based on semantics and a detail infusion feature pyramid network and a coordinate adaptive spatial feature fusion mechanism remote sensing small object detector. Remote Sens. 2024, 16, 2416. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Zhang, C.; Kang, F.; Wang, Y. An improved apple object detection method based on lightweight YOLOv4 in complex backgrounds. Remote Sens. 2022, 14, 4150. [Google Scholar] [CrossRef]
- Ma, Z.; Dong, Y.; Xia, Y.; Xu, D.; Xu, F.; Chen, F. Wildlife real-time detection in complex forest scenes based on YOLOv5s deep learning network. Remote Sens. 2024, 16, 1350. [Google Scholar] [CrossRef]
- Yuan, H.; Huang, K.; Ren, C.; Xiong, Y.; Duan, J.; Yang, Z. Pomelo tree detection method based on attention mechanism and cross-layer feature fusion. Remote Sens. 2022, 14, 3902. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhou, J.; Yang, Y.; Liu, L.; Liu, F.; Kong, W. Rapid target detection of fruit trees using UAV imaging and improved light YOLOv4 algorithm. Remote Sens. 2022, 14, 4324. [Google Scholar] [CrossRef]
- Ni, J.; Zhu, S.; Tang, G.; Ke, C.; Wang, T. A small-object detection model based on improved YOLOv8s for UAV image scenarios. Remote Sens. 2024, 16, 2465. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhad, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; 2016; pp. 779–788. [Google Scholar]
- Howard, A.G. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Cv, A.; Adam, H. Deeplabv3+: Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV; Ferrari, V., Hebert, M., Sminchisescu, C., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. IEEE Conf. Comput. Vis. Pattern Recognit. 2017, 42, 1228–1242. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Bochkovskiy, A. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Sunkara, R.; Luo, T. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer Nature: Cham, Switzerland, 2022; pp. 443–459. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | SPD-CONV | GAM | Wise-IoU | Box F1 (%) | Mask F1 (%) | FPS | Weight Size (MB) | Box mAP@50(%) | Mask mAP@50(%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ① | ② | ③ | All | ① | ② | ③ | All | ||||||||
| Yolov8n | x | x | x | 70 | 70 | 48.96 | 6.44 | 92.9 | 63.3 | 60.5 | 72.2 | 92.7 | 63.7 | 61 | 72.5 |
| S-Yolov8n | √ | x | x | 72 | 72 | 45.72 | 50.5 | 93.6 | 63.7 | 63.9 | 73.7 | 93.3 | 64.3 | 64.8 | 74.1 |
| SG-Yolov8n | √ | √ | x | 72 | 72 | 42.18 | 52.6 | 93.5 | 66.6 | 63.2 | 74.4 | 93.5 | 67.9 | 636 | 75 |
| SGW-Yolov8n | √ | √ | √ | 74 | 74 | 44.37 | 52.3 | 93.2 | 67.7 | 66.8 | 75.9 | 93.1 | 68.1 | 66 | 75.7 |
| Model | Precision (%) | Recall (%) | F1 Score (%) | Box mAP@50 (%) | Mask mAP@50 (%) | FPS | Weigth Size (MB) |
|---|---|---|---|---|---|---|---|
| Yolov5 | 67.2 | 68.1 | 67.65 | 68.4 | 72.5 | 32.28 | 14.9 |
| Yolov6 | 69.3 | 66.2 | 67.71 | 67.9 | _ | 30.94 | 8.28 |
| Yolov7 | 66.8 | 63.5 | 65.11 | 64.8 | _ | 28.63 | 71.3 |
| Yolact | 44.8 | 45.7 | 45.25 | 45.1 | 54.4 | 23.44 | 413 |
| Mask R-CNN | 43.2 | 42.6 | 42.90 | 43.2 | 53.1 | 26.57 | 483 |
| SGW-Yolov8n | 78 | 78 | 74 | 75.9 | 75.7 | 44.37 | 52.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, T.; Miao, Z.; Huang, W.; Han, W.; Guo, Z.; Li, T. SGW-YOLOv8n: An Improved YOLOv8n-Based Model for Apple Detection and Segmentation in Complex Orchard Environments. Agriculture 2024, 14, 1958. https://doi.org/10.3390/agriculture14111958
Wu T, Miao Z, Huang W, Han W, Guo Z, Li T. SGW-YOLOv8n: An Improved YOLOv8n-Based Model for Apple Detection and Segmentation in Complex Orchard Environments. Agriculture. 2024; 14(11):1958. https://doi.org/10.3390/agriculture14111958
Chicago/Turabian StyleWu, Tao, Zhonghua Miao, Wenlei Huang, Wenkai Han, Zhengwei Guo, and Tao Li. 2024. "SGW-YOLOv8n: An Improved YOLOv8n-Based Model for Apple Detection and Segmentation in Complex Orchard Environments" Agriculture 14, no. 11: 1958. https://doi.org/10.3390/agriculture14111958
APA StyleWu, T., Miao, Z., Huang, W., Han, W., Guo, Z., & Li, T. (2024). SGW-YOLOv8n: An Improved YOLOv8n-Based Model for Apple Detection and Segmentation in Complex Orchard Environments. Agriculture, 14(11), 1958. https://doi.org/10.3390/agriculture14111958