1. Introduction
The walnut, scientifically known as Juglans regia, is a type of nut tree belonging to the Juglandaceae. Walnuts are rich in protein, unsaturated fatty acids, vitamins, and other minerals beneficial to human health [
1]. Currently, there are 21 species of walnuts distributed across the West Indies, Southern Europe, Asia, Central America, North America, and western South America [
2]. Among them, China is the world’s largest walnut producer, accounting for over half of the global walnut production. The main walnut-producing regions in China include Yunnan Province (880,000 tons), Xinjiang Uygur Autonomous Region (440,000 tons), Sichuan Province (300,000 tons), Shaanxi Province (200,000 tons), and others [
3]. Taking Yunnan Province, the largest walnut-producing region, as an example, the primary variety is the Deep-ridged walnut, a unique variety in southwestern China. When Deep-ridged walnuts mature in autumn, their shells harden, change color, and the kernels complete their development. Farmers harvest them during the walnut’s ripe period to ensure optimal taste and flavor. However, the ripe period of walnuts is short, and ripe walnuts are prone to oxidation and spoilage. Additionally, overripe walnut kernels tend to stick tightly to the shell, which increases the difficulty of processing after harvesting. Currently, there are two main challenges in walnut production management: firstly, the primary method of walnut harvesting is manual, resulting in very low efficiency and causing many walnuts to overripe and rot on the trees. Secondly, most walnut trees in Yunnan are planted in hilly areas with complex terrain and uneven distribution, making manual counting of walnut fruits extremely difficult.
In recent years, agricultural digitization has continuously improved, promoting the rational utilization of modern production technologies and traditional agricultural production elements, which plays a crucial role in adjusting agricultural production methods and achieving precision agriculture [
4,
5]. Agricultural digitization refers to the use of advanced technologies such as big data [
6], machine learning [
7,
8], the Internet of Things [
9], and deep learning [
10,
11,
12] in the agricultural production process. Shantam Shorewala et al. [
13] proposed a semi-supervised decision method to identify the density and distribution of weeds from color images to locate weeds in fields. Validation results demonstrate that the method generalizes well to different plant species, achieving a maximum recall of 0.99 and a maximum accuracy of 82.13%. Cheng et al. used a deep residual network to detect pests in fields with complex backgrounds. Experimental results showed that the accuracy of this method was higher than support vector machines and backpropagation neural networks and higher than the recognition accuracy of traditional convolutional neural networks (CNNs). However, the network structure complexity of ResNet is relatively high, requiring more computation [
14]. Behroozi-Khazaei et al. combined artificial neural networks (ANN) with genetic algorithms (GA) to segment grape clusters similar in color to the background and leaves. Although the improved algorithm can automatically detect grape clusters in images and effectively predict yields, it remains challenging to successfully detect when there is little color difference between grape clusters and leaves [
15]. Juan Ignacio Arribas et al. segmented RGB images to separate sunflower leaves from the background and then used a Generalized Sensory Perceptron (GSP) neural network architecture combined with a Posterior Probability Model Selection (PPMS) algorithm to classify sunflower leaves and weeds. However, classification accuracy may be affected when lighting conditions are complex [
16]. In summary, algorithms still face challenges such as high computational complexity. Additionally, when background and object features are too similar, models may struggle to meet expectations for crop detection.
With the development of deep learning, object detection algorithms have been widely applied in various fields including remote sensing [
17,
18], urban data analysis [
19], agricultural production [
20], embedded development [
21] and multispectral image detection [
22]. Object detection mainly includes two-stage and one-stage algorithms. Two-stage algorithms include R-CNN [
23], Fast-RCNN [
24], Faster-RCNN [
25], Mask R-CNN [
26], etc. These algorithms classify objects based on pre-generated candidate regions, and their detection accuracy is usually higher. However, due to the multi-stage processing required by two-stage algorithms, their complexity is relatively high, and real-time performance is poor, requiring higher hardware requirements. In order to optimize the cumbersome detection process of two-stage algorithms, one-stage detection algorithms have been proposed. Joseph Redmon et al. proposed a one-stage object detection algorithm called YOLO (You Only Look Once), which promoted the development of real-time object detection [
27]. Subsequently, many researchers proposed improved one-stage detection algorithms, such as SSD [
28], CenterNet [
29], YOLOv3 [
30], YOLOv7 [
31], etc. Chen et al. proposed an improved YOLOv4 model for detecting and counting bayberry trees in images captured by UAVs. Experimental results show that the improved model achieves higher recall while ensuring accuracy [
32]. Hao et al. improved the YOLOv3 algorithm for detecting green walnuts. This algorithm utilizes Mixup data augmentation and introduces the lightweight convolutional network MobileNet-v3. In the experiment for detecting green walnuts, the model size is 88.6 MB, and the accuracy reaches 93.3% [
33]. Zhong et al. conducted research on walnut recognition in natural environments. They improved the YOLOX algorithm using the Swin Transformer multi-feature fusion module. The improved model achieved an AP50 of 96.72% in natural environments, with a model parameter of 20.55 M [
34]. In Li et al.’s study, by improving the feature fusion structure of the YOLOX model, the model’s ability to interact with local information in UAV remote sensing images is enhanced, achieving stronger small object detection capabilities [
35].
Considering the significant challenge of manually counting walnut fruits in hilly areas and recognizing the superiority of the YOLOv8s algorithm in object detection, we proposed the w-YOLO algorithm to address walnut fruit object detection in hilly terrain and under complex lighting conditions.
The contributions of our work can be summarized in the following points:
We utilized UAVs to collect remote-sensing images of walnut trees and established a representative dataset of small walnut targets. The dataset consists of 2490 images with a resolution of 640 × 640, containing a total of 12,138 walnut targets. This work fills the gap in walnut datasets and provides valuable data for walnut target detection and recognition under complex lighting conditions.
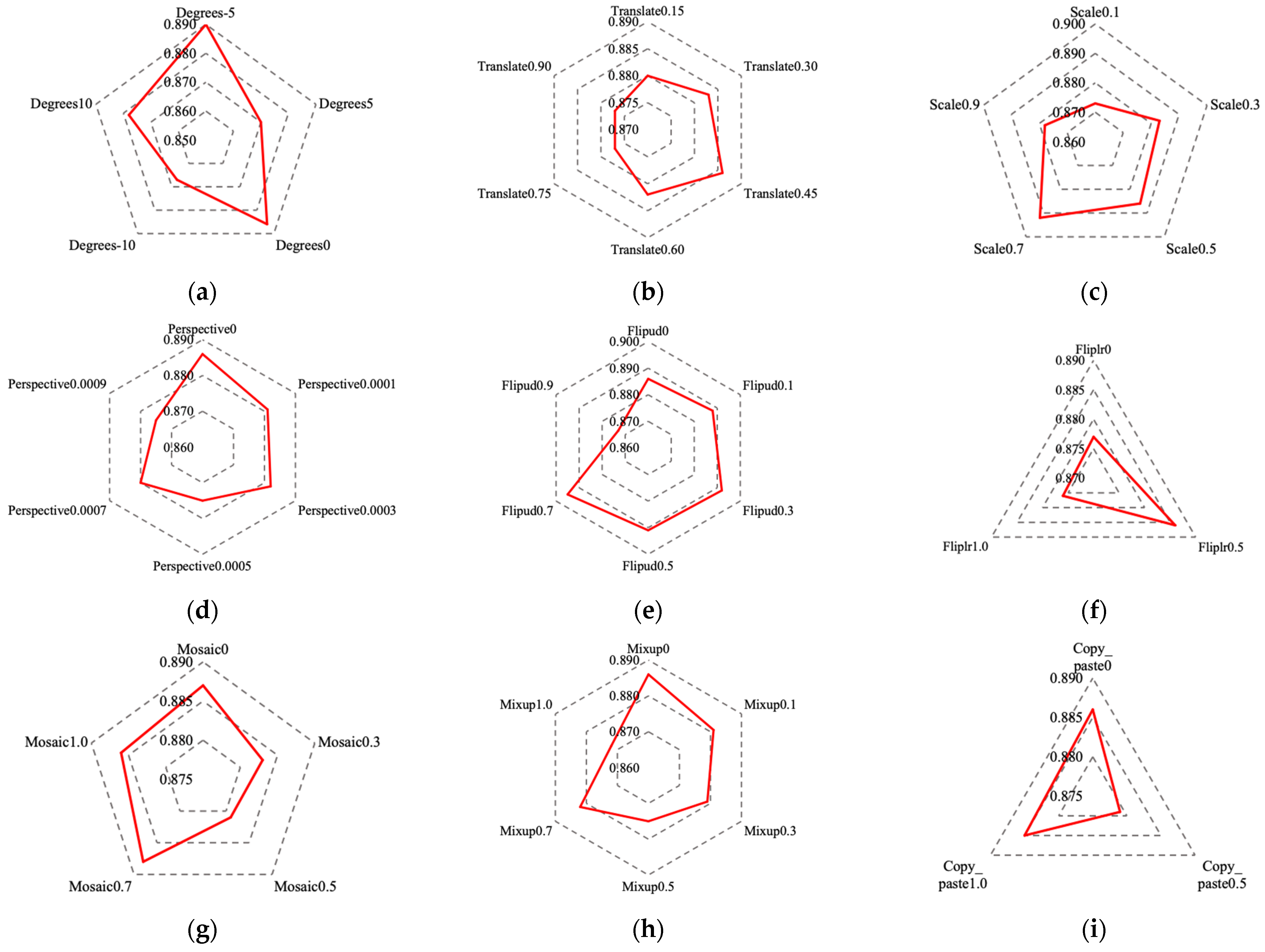
We made improvements to the YOLOv8s model and designed a w-YOLO model, which includes a lightweight feature extraction network, a better-performing feature fusion network, and a new detection layer. These improvements aim to reduce the model’s parameter count, and decrease the size of the model’s weight files for deployment on edge computing devices. At the same time, it enhances the model’s ability to capture walnut object features, making the model more suitable for walnut detection and recognition under different lighting conditions.
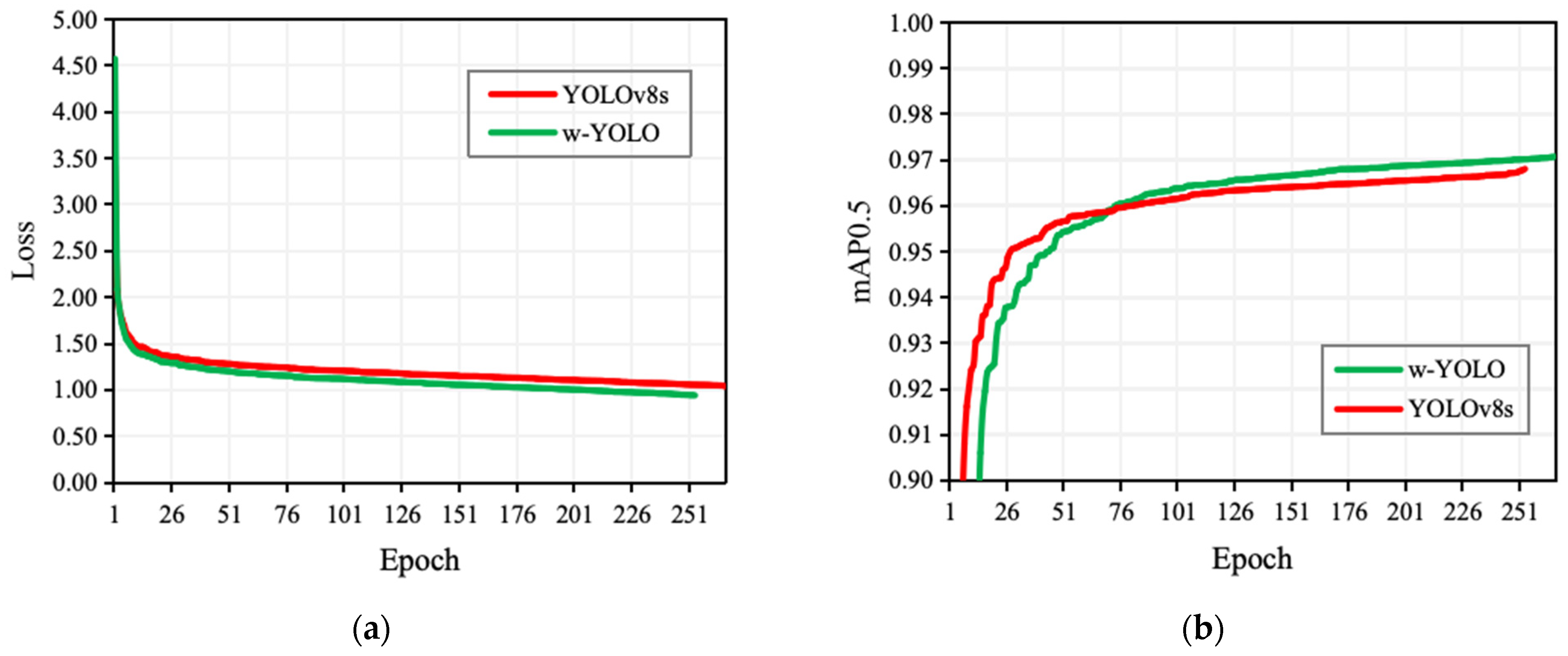
The w-YOLO model we designed achieved the recognition of small walnut targets under complex lighting conditions. It significantly improves walnut detection accuracy, with a mAP0.5 of 97% and an F1-score of 92%. The parameter count decreased by 52.3%, and the model’s weight file size reduced by 50.7%. Its detection performance surpasses the baseline YOLOv8s and other mainstream object detection models, providing valuable references for walnut detection and management under complex lighting conditions.
The remaining structure of the paper is as follows. In
Section 2, we provide an overview of our dataset and introduce the design details of the w-YOLO model. In
Section 3, we conduct a series of experiments and analyze the results.
Section 4 delves into a detailed discussion of some factors influencing the w-YOLO model. Finally, in the
Section 5, we present our conclusions.
5. Conclusions
In walnut agriculture production, yield prediction is a crucial step, and traditional manual counting methods face significant challenges in hilly areas. Given the advantages of deep learning models and low-altitude remote sensing technology in agricultural production, in this study, we constructed a walnut small object dataset using high-resolution aerial images captured by UAVs, addressing the problem of data scarcity in this research field. The dataset consists of 2490 images, totaling 12,138 walnut targets. In hilly areas, the complex lighting conditions experienced by walnut fruits during UAV data collection to some extent affect the accuracy of the model. Therefore, based on the YOLOv8s model, we made a series of improvements to obtain w-YOLO, including the utilization of FasterNet, C2f-Faster, and BiFPN to simplify the model’s feature extraction and fusion networks, reducing parameters by 6.37 M and shrinking the weight file size to 9.8 MB. Additionally, we employed a DyHead detection layer with attention mechanisms and redesigned a detection head combination more suitable for walnut object identification. In the walnut recognition task in complex lighting conditions of UAV remote sensing images, w-YOLO achieved a mAP0.5 of 97%, an increase of 0.4% compared to YOLOv8s, with parameters and weight file size reduced by 52.3% and 50.7%, respectively. It is worth noting that our study focuses on model lightweight and enabling w-YOLO to adapt to walnut fruit detection under different lighting conditions. The detection performance of w-YOLO under backlighting was significantly improved compared to the original model, but there are still instances of missed detections, making walnut identification under backlighting conditions challenging. Furthermore, w-YOLO has shown excellent detection results under facing and side lighting. We believe that the lightweight w-YOLO can provide valuable assistance for walnut production management and support the development of edge hardware devices for walnut detection.
However, we recognize that there is still significant room for improvement in the robustness of walnut recognition models. Therefore, our walnut dataset still needs to be further expanded, such as adding walnut data in different occlusion scenarios and multispectral walnut image data. In future research, we will also conduct radar-based three-dimensional modeling of walnut forests and calculate vegetation indices to provide more valuable resources for walnut agriculture production research.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}