



A Cooperative Scheduling Based on Deep Reinforcement Learning for Multi-Agricultural Machines in Emergencies


Abstract
:1. Introduction
- We transform the emergency agricultural machinery scheduling problem into a class of AMTSPTW problems, taking into account the asymmetry of field transfer time and time windows.
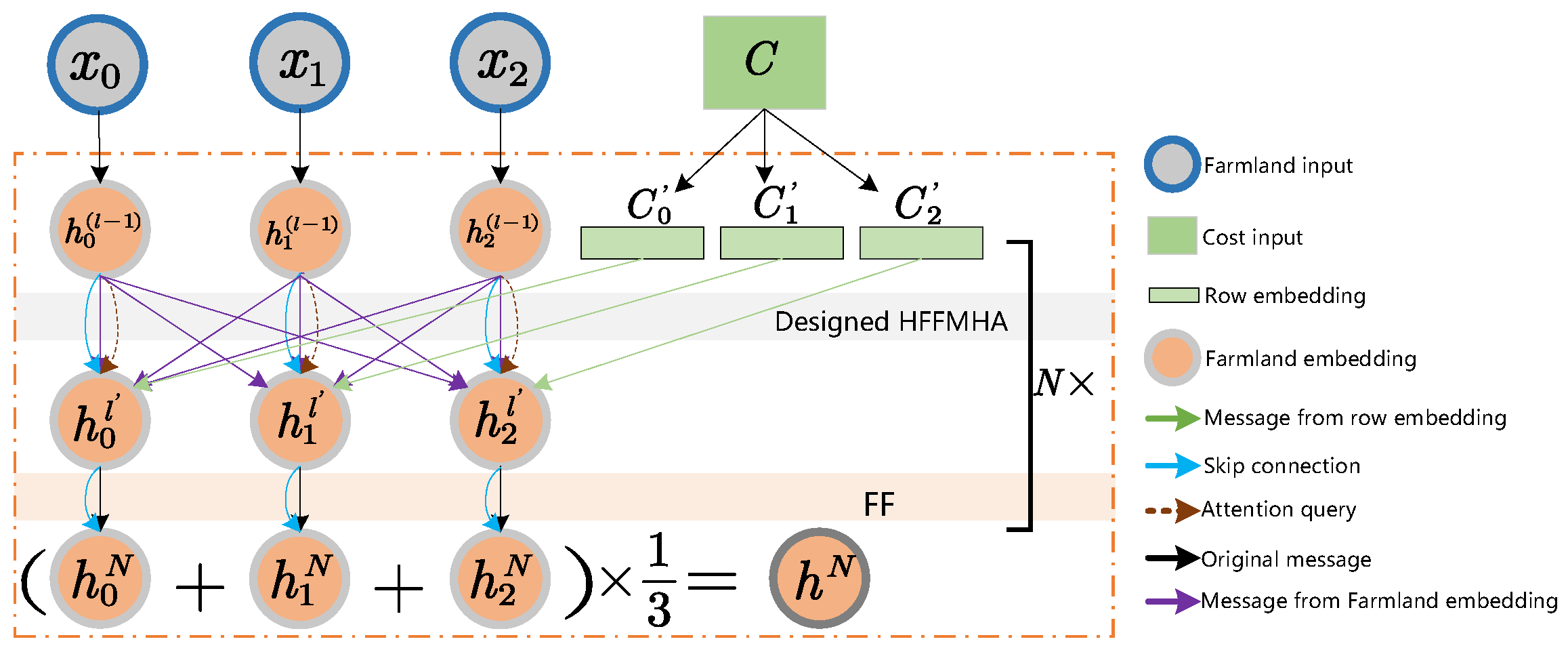
- We propose a DRL framework for end-to-end solving of the AMTSPTW problem. The framework employs an encoder-decoder structure. We propose a heterogeneous feature fusion attention mechanism in the encoder that allows the policy network to integrate time windows and path features for decision-making.
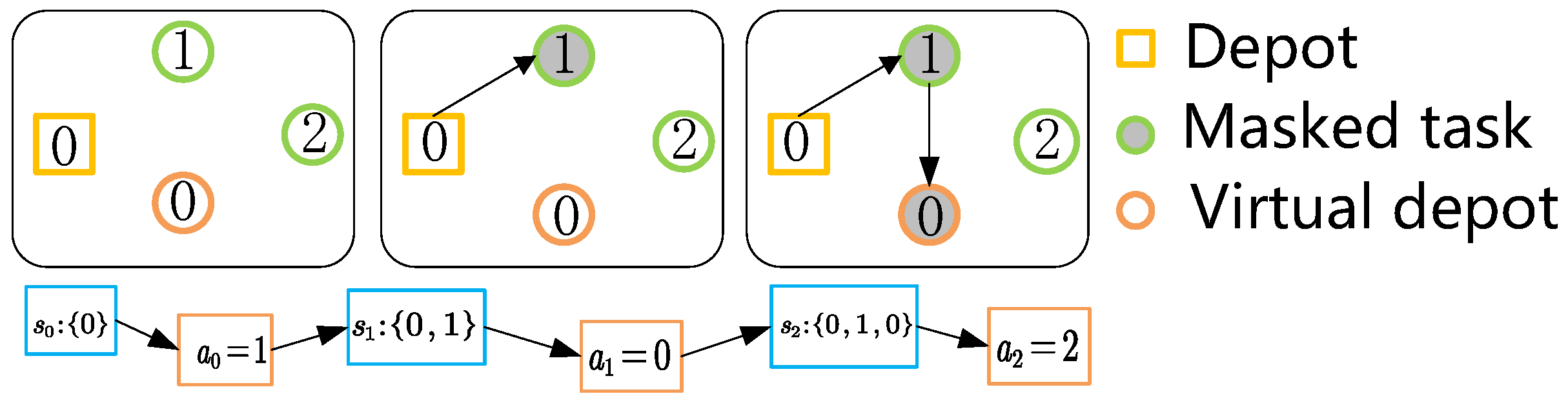
- In the decoder, we add virtual depots to assign farmlands to each agricultural machinery. We design a path segmentation mask mechanism to enable the policy to utilize the virtual depots and mask mechanism to partition the solutions efficiently.
2. Problem Description
- The location of the agricultural machinery depot, the farmlands, and their entry and exit points are known and fixed.
- The number of agricultural machines is known, and they have the same parameters. The influence of machinery lifespan on power is ignored.
- The transfer time of agricultural machinery from one farmland to another farmland is known, and the time windows for each farmland are also known.
- Agricultural machinery departs from the depot. Each farmland can only be served by one agricultural machine once, and the machine needs to return to the depot after completing its farmlands.
- There are no capacity restrictions for the agricultural machinery. It is assumed that they can complete all their tasks, such as leveling machines, ploughs, and so on.
3. Materials and Methods
3.1. Formulation of MDP
3.2. Policy Network
3.2.1. Encoder
3.2.2. Decoder
3.3. Training Method
4. Results
4.1. Experimental Environment
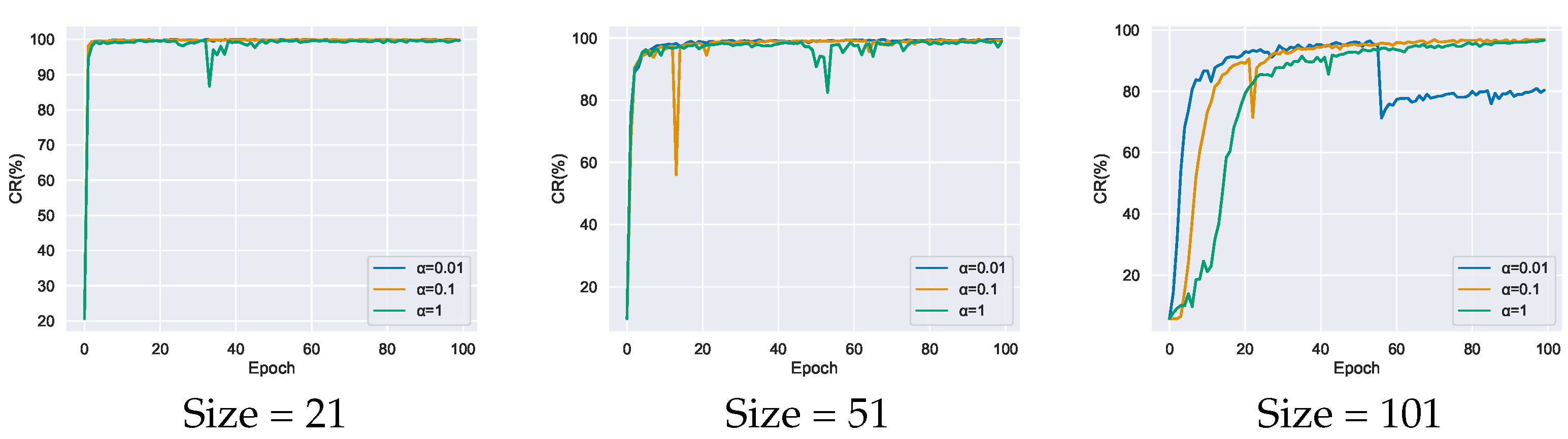
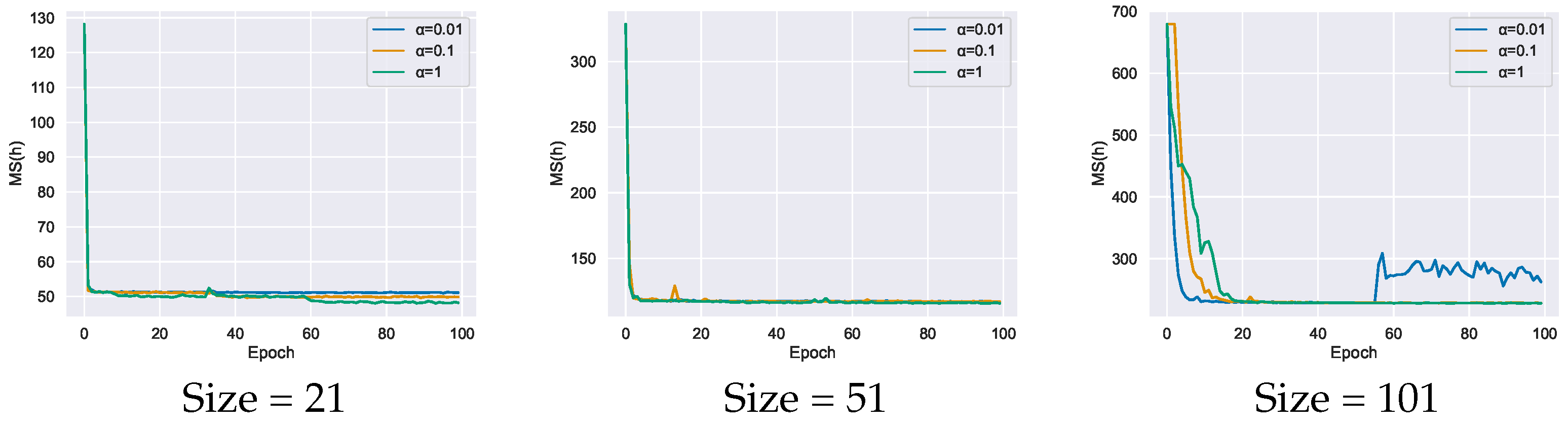
4.2. Parameter Analysis
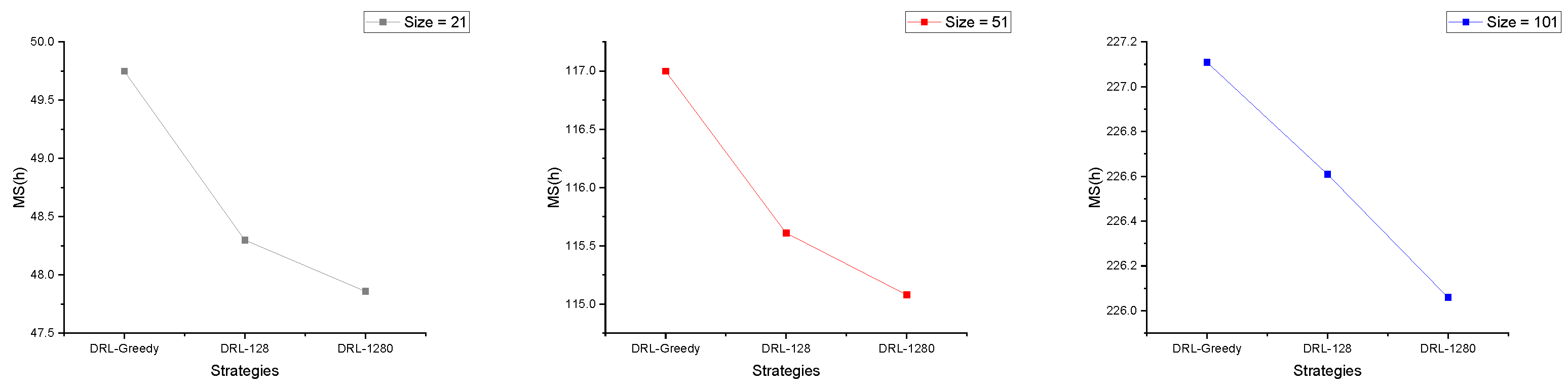
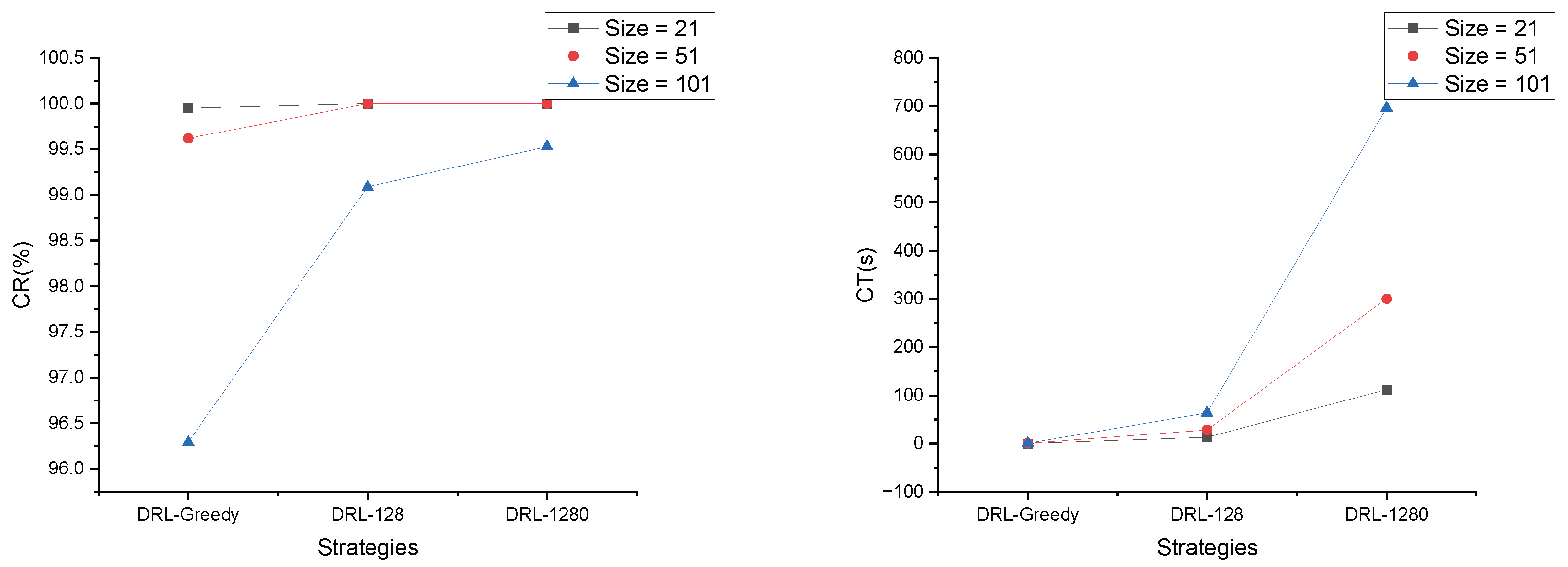
4.3. Strategy Analysis
- Greedy strategy, we consistently select the farmland with the greatest probability for each decoding action.
- Sampling, sampling through the probability distribution generated by the decoder, generates ℜ solutions for each instance and selects the best solution, where ℜ is set to 128 and 1280, called DRL-128 and DRL-1280, respectively.
4.4. Comparision Analysis
4.5. Generalization Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, H.; Cuan, X.; Chen, Z.; Zhang, L.; Chen, H. A Multiregional Agricultural Machinery Scheduling Method Based on Hybrid Particle Swarm Optimization Algorithm. Agriculture 2023, 13, 1042. [Google Scholar] [CrossRef]
- Zhou, K.; Leck Jensen, A.; Sørensen, C.; Busato, P.; Bothtis, D. Agricultural Operations Planning in Fields with Multiple Obstacle Areas. Comput. Electron. Agric. 2014, 109, 12–22. [Google Scholar] [CrossRef]
- Burger, M.; Huiskamp, M.; Keviczky, T. Complete Field Coverage as a Multi-Vehicle Routing Problem. IFAC Proc. Vol. 2013, 46, 97–102. [Google Scholar] [CrossRef]
- Jensen, M.F.; Bochtis, D.; Sørensen, C.G. Coverage Planning for Capacitated Field Operations, part II: Optimisation. Biosyst. Eng. 2015, 139, 149–164. [Google Scholar] [CrossRef]
- Seyyedhasani, H.; Dvorak, J.S. Using the Vehicle Routing Problem to Reduce Field Completion Times with Multiple Machines. Comput. Electron. Agric. 2017, 134, 142–150. [Google Scholar] [CrossRef]
- Basnet, C.B.; Foulds, L.R.; Wilson, J.M. Scheduling Contractors’ Farm-to-Farm Crop Harvesting Operations. Int. Trans. Oper. Res. 2006, 13, 1–15. [Google Scholar] [CrossRef]
- Guan, S.; Nakamura, M.; Shikanai, T.; Okazaki, T. Resource Assignment and Scheduling Based on a Two-phase Metaheuristic for Cropping System. Comput. Electron. Agric. 2009, 66, 181–190. [Google Scholar] [CrossRef]
- Pitakaso, R.; Sethanan, K. Adaptive Large Neighborhood Search for Scheduling Sugarcane inbound Logistics Equipment and Machinery Under a Sharing Infield Resource System. Comput. Electron. Agric. 2019, 158, 313–325. [Google Scholar] [CrossRef]
- Zuniga Vazquez, D.A.; Fan, N.; Teegerstrom, T.; Seavert, C.; Summers, H.M.; Sproul, E.; Quinn, J.C. Optimal Production Planning and Machinery Scheduling for Semi-arid Farms. Comput. Electron. Agric. 2021, 187, 106288. [Google Scholar] [CrossRef]
- Chen, C.; Hu, J.; Zhang, Q.; Zhang, M.; Li, Y.; Nan, F.; Cao, G. Research on the Scheduling of Tractors in the Major Epidemic to Ensure Spring Ploughing. Math. Probl. Eng. 2021, 2021, 3534210. [Google Scholar]
- Cao, R.; Li, S.; Ji, Y.; Zhang, Z.; Xu, H.; Zhang, M.; Li, M.; Li, H. Task Assignment of Multiple Agricultural Machinery Cooperation Based on Improved Ant Colony Algorithm. Comput. Electron. Agric. 2021, 182, 105993. [Google Scholar] [CrossRef]
- Wang, Y.J.; Huang, G.Q. A Two-step Framework for Dispatching Shared Agricultural Machinery with Time Windows. Comput. Electron. Agric. 2022, 192, 106607. [Google Scholar] [CrossRef]
- He, F.; Yang, J.; Li, M. Vehicle Scheduling Under Stochastic Trip Times: An Approximate Dynamic Programming Approach. Transp. Res. Part Emerg. Technol. 2018, 96, 144–159. [Google Scholar] [CrossRef]
- Watanabe, A.; Tamura, R.; Takano, Y.; Miyashiro, R. Branch-and-bound Algorithm for Optimal Sparse Canonical Correlation Analysis. Expert Syst. Appl. 2023, 217, 119530. [Google Scholar] [CrossRef]
- Li, J.; Sun, Q.; Zhou, M.; Dai, X. A New Multiple Traveling Salesman Problem and Its Genetic Algorithm-Based Solution. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 627–632. [Google Scholar]
- Sajede, A.; Mohammad, T.; Majid, F. An Integrated Production and Transportation Scheduling Problem with Order Acceptance and Resource Allocation Decisions. Appl. Soft Comput. 2021, 112, 107770. [Google Scholar]
- Liu, C.; Zhang, Y. Research on MTSP Problem Based on Simulated Annealing. In Proceedings of the 1st International Conference on Information Science and Systems, Jeju, Republic of Korea, 27–29 April 2018; pp. 283–285. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 2, Cambridge, MA, USA, 7–12 December 2015; pp. 2692–2700. [Google Scholar]
- Bello, I.; Pham, H.; Le, Q.V.; Norouzi, M.; Bengio, S. Neural Combinatorial Optimization with Reinforcement Learning. In Proceedings of the 5th International Conference on Learning Representations, Workshop Track Proceedings, Toulon, France, 24–26 April 2017. [Google Scholar]
- Nazari, M.; Oroojlooy, A.; Snyder, L.; Takac, M. Reinforcement Learning for Solving the Vehicle Routing Problem. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; p. 31. [Google Scholar]
- Kool, W.; van Hoof, H.; Welling, M. Attention, Learn to Solve Routing Problems! In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019.
- Zhao, J.; Mao, M.; Zhao, X.; Zou, J. A Hybrid of Deep Reinforcement Learning and Local Search for the Vehicle Routing Problems. IEEE Trans. Intell. Transp. Syst. 2021, 22, 7208–7218. [Google Scholar] [CrossRef]
- Hu, Y.; Yao, Y.; Lee, W.S. A Reinforcement Learning Approach for Optimizing Multiple Traveling Salesman Problems over Graphs. Knowl. Based Syst. 2020, 204, 106244. [Google Scholar] [CrossRef]
- Zhang, R.; Prokhorchuk, A.; Dauwels, J. Deep Reinforcement Learning for Traveling Salesman Problem with Time Windows and Rejections. In Proceedings of the 2020 International Joint Conference on Neural Networks, Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Zhang, R.; Zhang, C.; Cao, Z.; Song, W.; Tan, P.S.; Zhang, J.; Wen, B.; Dauwels, J. Learning to Solve Multiple-TSP With Time Window and Rejections via Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2023, 24, 1325–1336. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Baker, E.K. Technical Note—An Exact Algorithm for the Time-Constrained Traveling Salesman Problem. Oper. Res. 1983, 31, 938–945. [Google Scholar] [CrossRef]
- Gao, J.; Li, Y.; Xu, Y.; Lv, S. A Two-Objective ILP Model of OP-MATSP for the Multi-Robot Task Assignment in an Intelligent Warehouse. Appl. Sci. 2022, 12, 4843. [Google Scholar] [CrossRef]
- Braekers, K.; Caris, A.; Janssens, G.K. Bi-Objective Optimization of Drayage Operations in the Service Area of Intermodal Terminals. Transp. Res. Part Logist. Transp. Rev. 2014, 65, 50–69. [Google Scholar]
- Li, J.; Xin, L.; Cao, Z.; Lim, A.; Song, W.; Zhang, J. Heterogeneous Attentions for Solving Pickup and Delivery Problem via Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2306–2315. [Google Scholar] [CrossRef]
- Oberlin, P.; Rathinam, S.; Darbha, S. A Transformation for A Multiple Depot, Multiple Traveling Salesman Problem. In Proceedings of the 2009 Conference on American Control Conference, St. Louis, MO, USA, 10–12 June 2009; pp. 2636–2641. [Google Scholar]
- Williams, R.J. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Kwon, Y.D.; Choo, J.; Kim, B.; Yoon, I.; Gwon, Y.; Min, S. POMO: Policy Optimization with Multiple Optima for Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21188–21198. [Google Scholar]
- Deudon, M.; Cournut, P.; Lacoste, A.; Adulyasak, Y.; Rousseau, L.M. Learning Heuristics for the TSP by Policy Gradient. In Proceedings of the Integration of Constraint Programming, Artificial Intelligence, and Operations Research, Cham, Switzerland, 28–31 May 2018; pp. 170–181. [Google Scholar]
- Wei, J.; He, Y.; Zhu, Z.; Zhu, L. An Novel Shortest Path Algorithm Based on Spatial Relations. In Proceedings of the 2020 4th International Conference on Electronic Information Technology and Computer Engineering, Xiamen, China, 6–8 November 2021; pp. 1024–1028. [Google Scholar]
- He, P.; Hao, J.K. Hybrid Search with Neighborhood Reduction for The Multiple Traveling Salesman Problem. Comput. Oper. Res. 2022, 142, 105726. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Measurement | Size = 21 | Size = 51 | Size = 101 |
|---|---|---|---|---|
| GA | CR (%) | 95.47% | 36.99% | 22.04% |
| MS (h) | 52.39 | 155.13 | 306.87 | |
| CT (s) | ≥2000 | ≥2000 | ≥2000 | |
| SA | CR (%) | 94.84% | 72.34% | 44.40% |
| MS (h) | 53.51 | 134.21 | 287.05 | |
| CT (s) | 602.71 | 1163.58 | ≥2000 | |
| TS | CR (%) | 99.98% | 99.70% | 97.13% |
| MS (h) | 50.812 | 116.57 | 226.53 | |
| CT (s) | 156.29 | 722.24 | ≥2000 | |
| AM-1280 | CR (%) | 100.00% | 65.68% | 50.03% |
| MS (h) | 47.48 | 130.21 | 258.06 | |
| CT (s) | 90.59 | 204.85 | 461.14 | |
| DRL-1280 | CR (%) | 100.00% | 100% | 99.50% |
| MS (m) | 47.77 | 115.14 | 225.97 | |
| CT (s) | 97.28 | 221.25 | 534.48 |
| Method | Measurement | Size = 31 | Size = 71 | Size = 121 |
|---|---|---|---|---|
| GA | CR(%) | 72.81% | 28.96% | 18.75% |
| MS (h) | 83.29 | 215.08 | 370.35 | |
| CT (s) | ≥2000 | ≥2000 | ≥2000 | |
| SA | CR (%) | 88.40% | 58.73% | 37.97% |
| MS (h) | 78.86 | 195.26 | 351.95 | |
| CT (s) | 790.00 | 1538.21 | ≥2000 | |
| TS | CR (%) | 99.98% | 98.79% | 95.88% |
| MS (h) | 72.89 | 161.11 | 270.93 | |
| CT (s) | 332.67 | 1166.87 | ≥2000 | |
| AM-1280 | CR (%) | 99.23% | 49.58% | 42.34% |
| MS (h) | 72.40 | 192.09 | 318.69 | |
| CT (s) | 130.87 | 272.84 | 614.41 | |
| DRL-1280 | CR (%) | 99.94% | 98.36% | 97.54% |
| MS (h) | 71.27 | 161.02 | 271.14 | |
| CT (s) | 140.10 | 333.36 | 718.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, W.; Wang, J.; Yang, W. A Cooperative Scheduling Based on Deep Reinforcement Learning for Multi-Agricultural Machines in Emergencies. Agriculture 2024, 14, 772. https://doi.org/10.3390/agriculture14050772
Pan W, Wang J, Yang W. A Cooperative Scheduling Based on Deep Reinforcement Learning for Multi-Agricultural Machines in Emergencies. Agriculture. 2024; 14(5):772. https://doi.org/10.3390/agriculture14050772
Chicago/Turabian StylePan, Weicheng, Jia Wang, and Wenzhong Yang. 2024. "A Cooperative Scheduling Based on Deep Reinforcement Learning for Multi-Agricultural Machines in Emergencies" Agriculture 14, no. 5: 772. https://doi.org/10.3390/agriculture14050772
APA StylePan, W., Wang, J., & Yang, W. (2024). A Cooperative Scheduling Based on Deep Reinforcement Learning for Multi-Agricultural Machines in Emergencies. Agriculture, 14(5), 772. https://doi.org/10.3390/agriculture14050772