
LettuceNet: A Novel Deep Learning Approach for Efficient Lettuce Localization and Counting
 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
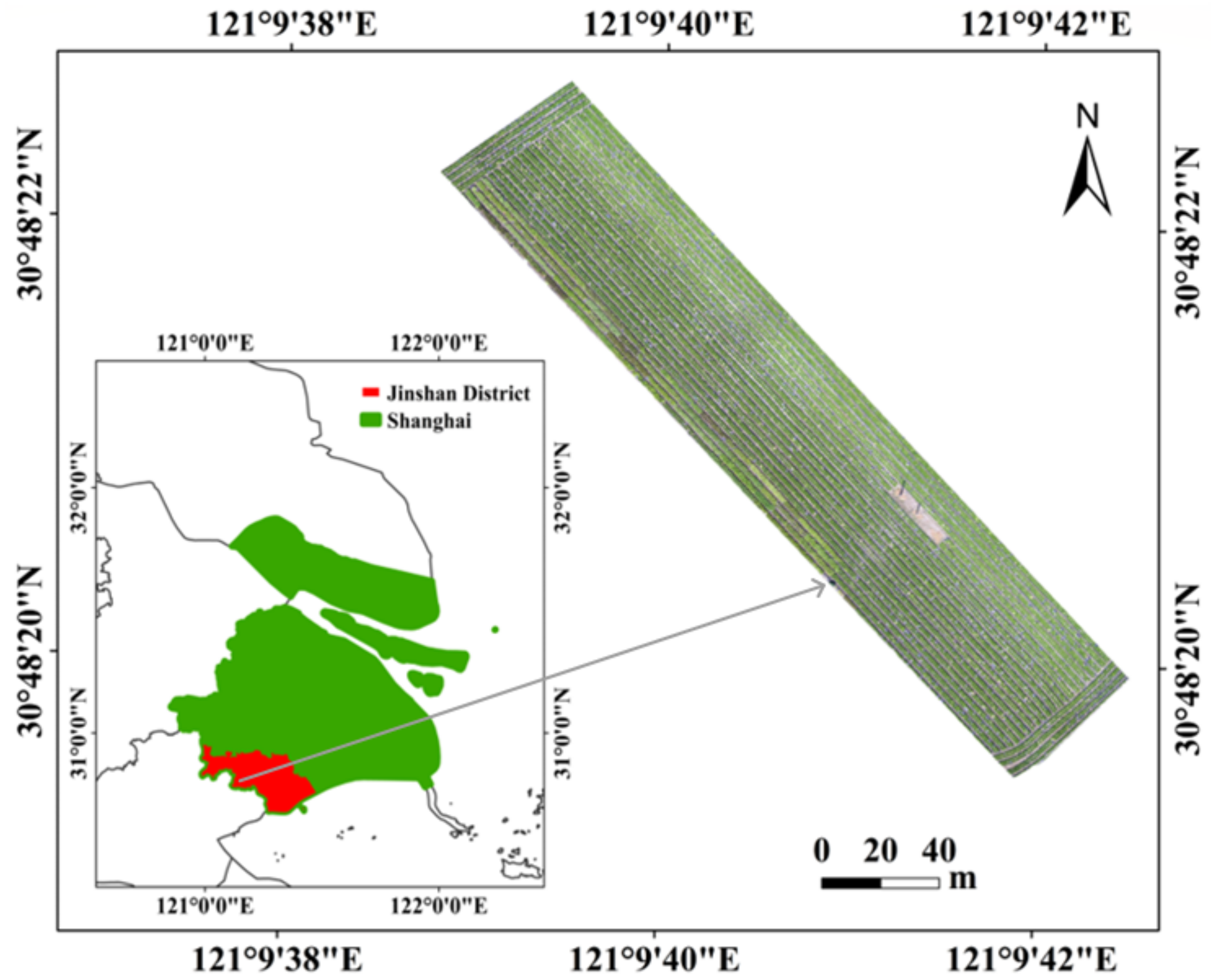
2.1. UAV-Based Lettuce RGB Images Acquisition
2.2. Lettuce Dataset Construction and Preprocessing
2.3. LettuceNet Structure
2.3.1. FEM
2.3.2. MFFM
2.3.3. DM
2.3.4. LCM
2.3.5. Loss Functions
2.4. Implementation Details and Accuracy Rating
3. Results
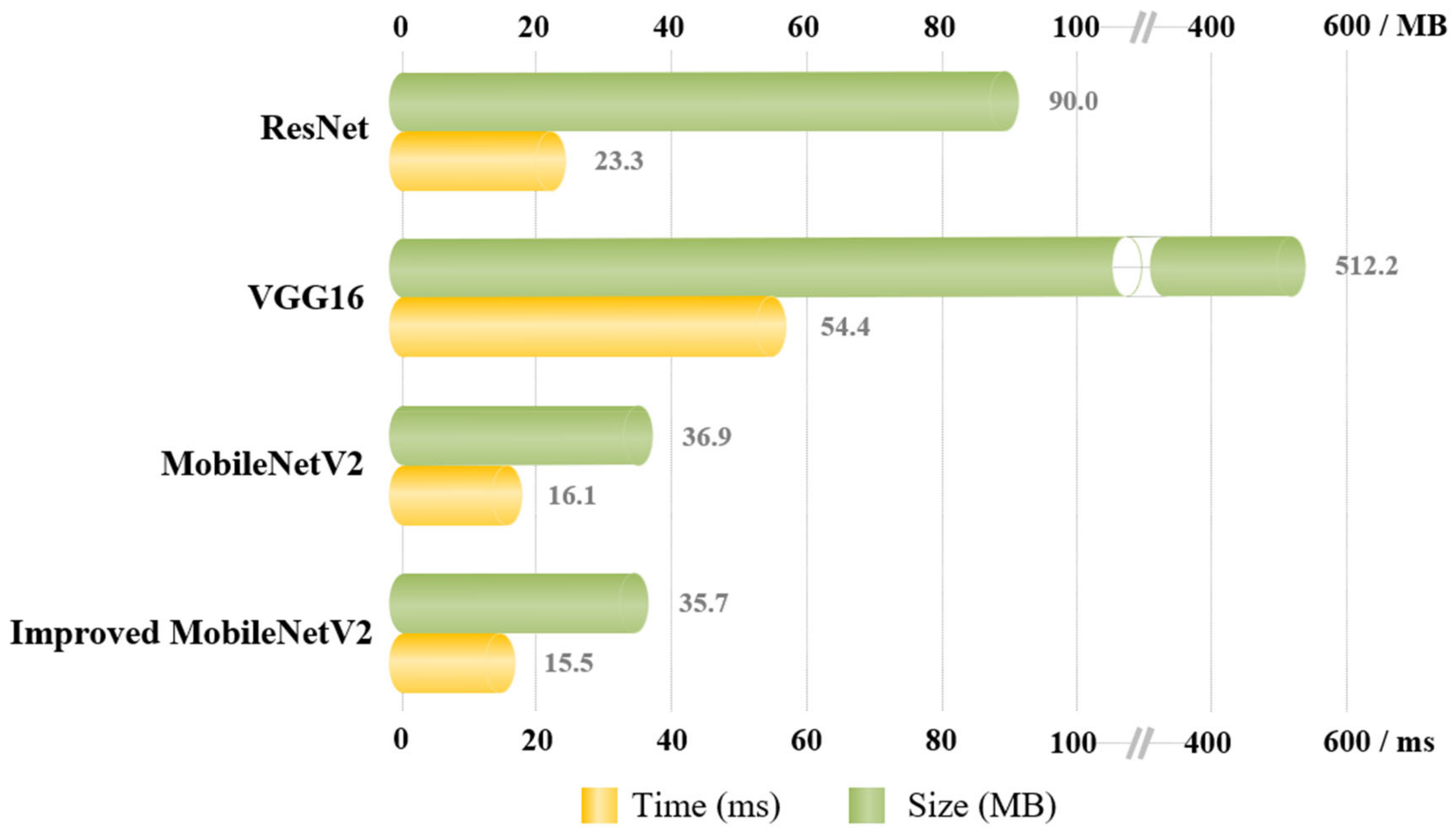
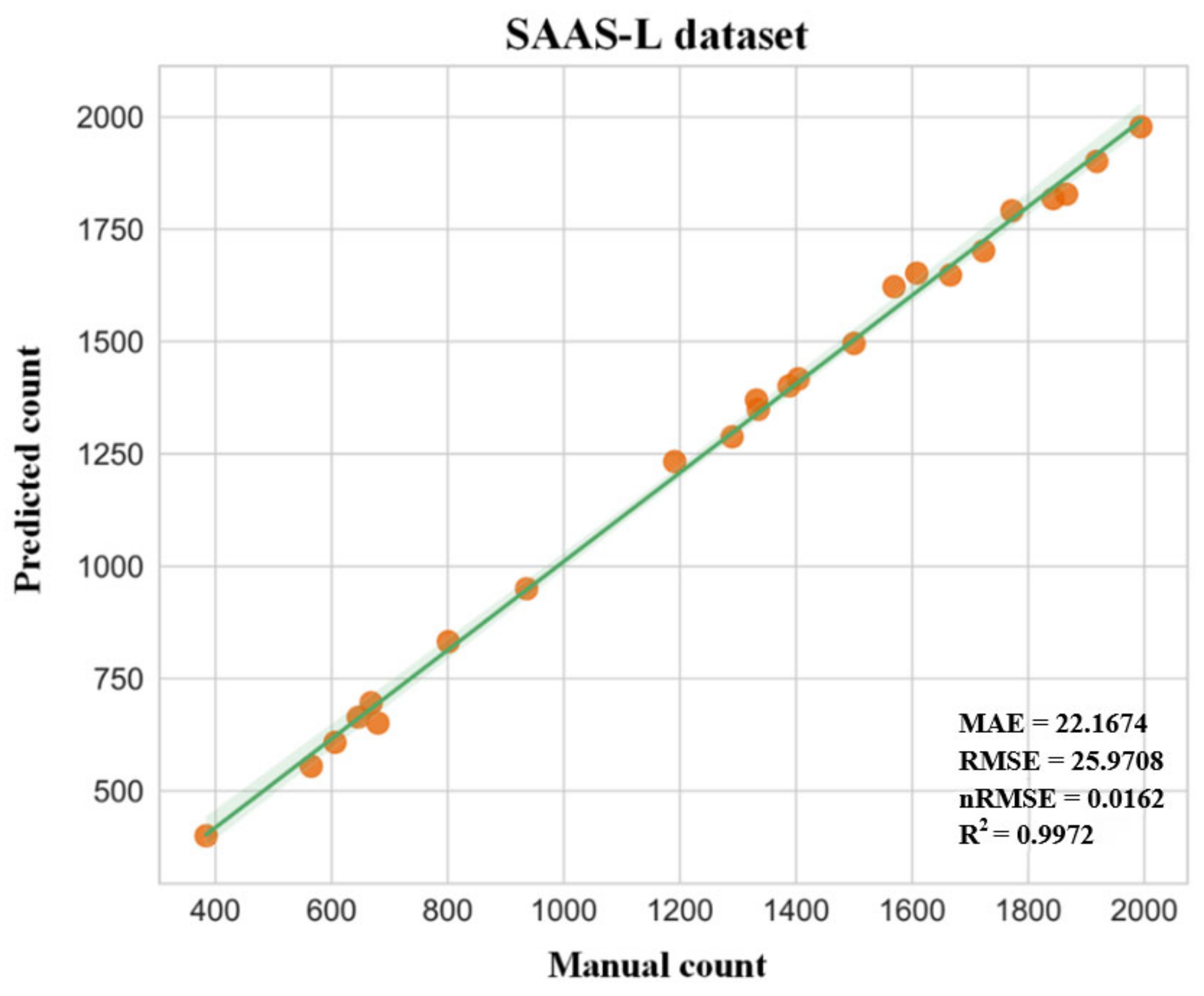
3.1. Evaluation of the Accuracy and Efficiency of LettuceNet Counting
3.2. Localization Evaluation of LettuceNet
3.3. Comparison of LettuceNet with Existing Similar Methods
3.4. Generalizability Evaluation of LettuceNet
3.5. Boundary Effects Evaluation of LettuceNet
4. Discussion
4.1. Advantages of LettuceNet
4.2. Future Improvements for LettuceNet
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, J.; Li, P.; Wang, J. Effects of Light Intensity and Temperature on the Photosynthesis Characteristics and Yield of Lettuce. Horticulturae 2022, 8, 178. [Google Scholar] [CrossRef]
- de Oliveira, E.Q.; Neto, F.B.; de Negreiros, M.Z.; Júnior, A.P.B.; de Freitas, K.K.C.; da Silveira, L.M.; de Lima, J.S. Produção e valor agroeconômico no consórcio entre cultivares de coentro e de alface. Hortic. Bras. 2005, 23, 285–289. [Google Scholar] [CrossRef]
- Khoroshevsky, F.; Khoroshevsky, S.; Bar-Hillel, A. Parts-per-Object Count in Agricultural Images: Solving Phenotyping Problems via a Single Deep Neural Network. Remote Sens. 2021, 13, 2496. [Google Scholar] [CrossRef]
- Wu, J.; Yang, G.; Yang, X.; Xu, B.; Han, L.; Zhu, Y. Automatic Counting of in situ Rice Seedlings from UAV Images Based on a Deep Fully Convolutional Neural Network. Remote Sens. 2019, 11, 691. [Google Scholar] [CrossRef]
- Bai, X.; Liu, P.; Cao, Z.; Lu, H.; Xiong, H.; Yang, A.; Cai, Z.; Wang, J.; Yao, J. Rice Plant Counting, Locating, and Sizing Method Based on High-Throughput UAV RGB Images. Plant Phenom. 2023, 5, 20. [Google Scholar] [CrossRef]
- Li, Y.; Bao, Z.; Qi, J. Seedling maize counting method in complex backgrounds based on YOLOV5 and Kalman filter tracking algorithm. Front. Plant Sci. 2022, 13, 1030962. [Google Scholar] [CrossRef] [PubMed]
- Feng, A.; Zhou, J.; Vories, E.; Sudduth, K.A. Evaluation of cotton emergence using UAV-based imagery and deep learning. Comput. Electron. Agric. 2020, 177, 105711. [Google Scholar] [CrossRef]
- Machefer, M.; Lemarchand, F.; Bonnefond, V.; Hitchins, A.; Sidiropoulos, P. Mask R-CNN Refitting Strategy for Plant Counting and Sizing in UAV Imagery. Remote Sens. 2020, 12, 3015. [Google Scholar] [CrossRef]
- Bauer, A.; Bostrom, A.G.; Ball, J.; Applegate, C.; Cheng, T.; Laycock, S.; Rojas, S.M.; Kirwan, J.; Zhou, J. Combining computer vision and deep learning to enable ultra-scale aerial phenotyping and precision agriculture: A case study of lettuce production. Hortic. Res. 2019, 6, 70. [Google Scholar] [CrossRef]
- Petti, D.; Li, C.Y. Weakly-supervised learning to automatically count cotton flowers from aerial imagery. Comput. Electron. Agric. 2022, 194, 106734. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2:Inverted Residuals and Linear Bottlenecks. In Proceedings of the 31st IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for Semantic Segmentation in Street Scenes. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Wu, Y.; He, K.; He, K. Group Normalization. arXiv 2018, arXiv:1803.08494. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net:Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv 2015, arXiv:1511.00561. [Google Scholar] [CrossRef] [PubMed]
- Wu, K.; Otoo, E.; Shoshani, A. Optimizing connected component labeling algorithms. In Image Processing, Medical Imaging; SPIE: Bellingham, WA, USA, 2005; Available online: https://ui.adsabs.harvard.edu/abs/2005SPIE.5747.1965W/abstract (accessed on 12 November 2022).
- Li, Z.; Li, Y.; Yang, Y.; Guo, R.; Yang, J.; Yue, J.; Wang, Y. A high-precision detection method of hydroponic lettuce seedlings status based on improved Faster RCNN. Comput. Electron. Agric. 2021, 182, 106054. [Google Scholar] [CrossRef]
- Ghosal, S.; Zheng, B.; Chapman, S.C.; Potgieter, A.B.; Jordan, D.R.; Wang, X.; Singh, A.K.; Singh, A.; Hirafuji, M.; Ninomiya, S.; et al. A Weakly Supervised Deep Learning Framework for Sorghum Head Detection and Counting. Plant Phenom. 2019, 2019, 1525874. [Google Scholar] [CrossRef] [PubMed]
- Afonso, M.; Fonteijn, H.; Fiorentin, F.S.; Lensink, D.; Mooij, M.; Faber, N.; Polder, G.; Wehrens, R. Tomato Fruit Detection and Counting in Greenhouses Using Deep Learning. Front. Plant Sci. 2020, 11, 571299. [Google Scholar] [CrossRef] [PubMed]
- Laradji, I.H.; Rostamzadeh, N.; Pinheiro, P.O.; Vazquez, D.; Schmidt, M. Where Are the Blobs: Counting by Localization with Point Supervision. Comput. Vis.—ECCV 2018, 2018, 560–576. [Google Scholar] [CrossRef]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Fei-Fei, L. What’s the Point: Semantic Segmentation with Point Supervision. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef]
- Beucher, S.; Meyer, F. The morphological approach to segmentation: The watershed transformation. In Mathematical Morphology in Image Processing; CRC Press: Boca Raton, FL, USA, 2018; Volume 34, pp. 433–481. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE-Computer-Society Conference on Computer Vision and Pattern Recognition Workshops, Miami Beach, FL, USA, 20–25 June 2009. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale Aggregation Network for Accurate and Efficient Crowd Counting. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Xiong, H.; Cao, Z.; Lu, H.; Madec, S.; Liu, L.; Shen, C. TasselNetv2: In-field counting of wheat spikes with context-augmented local regression networks. Plant Methods 2019, 15, 150. [Google Scholar] [CrossRef]
- Liang, D.; Xu, W.; Zhu, Y.; Zhou, Y. Focal Inverse Distance Transform Maps for Crowd Localization. IEEE Trans. Multimed. 2022, 25, 6040–6052. [Google Scholar] [CrossRef]
- Lan, Y.; Huang, K.; Yang, C.; Lei, L.; Ye, J.; Zhang, J.; Zeng, W.; Zhang, Y.; Deng, J. Real-time identification of rice weeds by UAV low-altitude remote sensing based on improved semantic segmentation model. Remote Sens. 2021, 13, 4370. [Google Scholar] [CrossRef]
- He, S.; Zou, H.; Wang, Y.; Li, B.; Cao, X.; Jing, N. Learning Remote Sensing Object Detection with Single Point Supervision. IEEE Trans. Geosci. Remote Sens. 2024, 62, 3343806. [Google Scholar] [CrossRef]
- Shi, Z.; Mettes, P.; Snoek, C.G.M. Focus for Free in Density-Based Counting. Int. J. Comput. Vis. 2024, 1–18. [Google Scholar] [CrossRef]
- Xie, Z.; Ke, Z.; Chen, K.; Wang, Y.; Tang, Y.; Wang, W. A Lightweight Deep Learning Semantic Segmentation Model for Optical-Image-Based Post-Harvest Fruit Ripeness Analysis of Sugar Apples. Agriculture 2024, 14, 591. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, X.; Sun, Y.; Liu, Y.; Wang, L.; Liu, M. Sh-DeepLabv3+: An Improved Semantic Segmentation Lightweight Network for Corn Straw Cover Form Plot Classification. Agriculture 2024, 14, 628. [Google Scholar] [CrossRef]
- Xiao, F.; Wang, H.; Xu, Y.; Shi, Z. A Lightweight Detection Method for Blueberry Fruit Maturity Based on an Improved YOLOv5 Algorithm. Agriculture 2024, 14, 36. [Google Scholar] [CrossRef]
- Chen, P.; Dai, J.; Zhang, G.; Hou, W.; Mu, Z.; Cao, Y. Diagnosis of Cotton Nitrogen Nutrient Levels Using Ensemble MobileNetV2FC, ResNet101FC, and DenseNet121FC. Agriculture 2024, 14, 525. [Google Scholar] [CrossRef]
- Qiao, Y.; Liu, H.; Meng, Z.; Chen, J.; Ma, L. Method for the automatic recognition of cropland headland images based on deep learning. Int. J. Agric. Biol. Eng. 2023, 16, 216–224. [Google Scholar] [CrossRef]
- Öcal, A.; Koyuncu, H. An in-depth study to fine-tune the hyperparameters of pre-trained transfer learning models with state-of-the-art optimization methods: Osteoarthritis severity classification with optimized architectures. Swarm Evol. Comput. 2024, 89, 101640. [Google Scholar] [CrossRef]
- Sonmez, M.E.; Sabanci, K.; Aydin, N. Convolutional neural network-support vector machine-based approach for identification of wheat hybrids. Eur. Food Res. Technol. 2024, 250, 1353–1362. [Google Scholar] [CrossRef]
- Wang, Y.; Kong, X.; Guo, K.; Zhao, C.; Zhao, J. Intelligent Extraction of Terracing Using the ASPP ArrU-Net Deep Learning Model for Soil and Water Conservation on the Loess Plateau. Agriculture 2023, 13, 1283. [Google Scholar] [CrossRef]
- Laradji, I.H.; Saleh, A.; Rodriguez, P.; Nowrouzezahrai, D.; Azghadi, M.R.; Vazquez, D. Weakly supervised underwater fish segmentation using affinity LCFCN. Sci. Rep. 2021, 11, 17379. [Google Scholar] [CrossRef] [PubMed]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458v1. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643v1. [Google Scholar]
- Wang, Q.; Li, C.; Huang, L.; Chen, L.; Zheng, Q.; Liu, L. Research on Rapeseed Seedling Counting Based on an Improved Density Estimation Method. Agriculture 2024, 14, 783. [Google Scholar] [CrossRef]
- Xu, X.; Gao, Y.; Fu, C.; Qiu, J.; Zhang, W. Research on the Corn Stover Image Segmentation Method via an Unmanned Aerial Vehicle (UAV) and Improved U-Net Network. Agriculture 2024, 14, 217. [Google Scholar] [CrossRef]
- Yang, T.; Zhu, S.; Zhang, W.; Zhao, Y.; Song, X.; Yang, G.; Yao, Z.; Wu, W.; Liu, T.; Sun, C.; et al. Unmanned Aerial Vehicle-Scale Weed Segmentation Method Based on Image Analysis Technology for Enhanced Accuracy of Maize Seedling Counting. Agriculture 2024, 14, 175. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Venue, Year | MAE | RMSE | nRMSE | R2 |
|---|---|---|---|---|---|
| ResNet50 | CVPR, 2009 | 8.5391 | 12.7231 | 0.0877 | 0.9328 |
| VGG16 | ICLR, 2015 | 10.9140 | 18.8136 | 0.1297 | 0.8531 |
| MobileNetV2 | CVPR, 2018 | 7.7042 | 11.2965 | 0.0780 | 0.9469 |
| Improved MobileNetV2 | This study | 2.4486 | 4.0247 | 0.0276 | 0.9933 |
| Backbone | Normalization Method | MAE | RMSE | nRMSE | R2 |
|---|---|---|---|---|---|
| ResNet50 | BN | 8.5391 | 12.7231 | 0.0877 | 0.9328 |
| VGG16 | BN | 10.9140 | 18.8136 | 0.1297 | 0.8531 |
| MobileNetV2 | BN | 7.7042 | 11.2956 | 0.0780 | 0.9469 |
| ResNet50 | GN | 2.7196 | 4.0846 | 0.0282 | 0.9930 |
| VGG16 | GN | 3.9307 | 6.1983 | 0.0427 | 0.9841 |
| Improved MobileNetV2 | GN | 2.4486 | 4.0247 | 0.0276 | 0.9933 |
| Backbone | F-Score | Increase Rate over Improved MobileNetV2 |
|---|---|---|
| ResNet50 | 0.8943 | −8.68% |
| VGG16 | 0.8227 | −15.93% |
| MobileNetV2 | 0.9156 | −6.44% |
| Improved MobileNetV2 | 0.9791 | \ |
| Method | Venue, Year | MAE | RMSE | nRMSE | R2 |
|---|---|---|---|---|---|
| MCNN | CVPR, 2016 | 21.6751 | 24.3227 | 0.1742 | 0.3569 |
| CSRNet | CVPR, 2018 | 11.6435 | 14.8340 | 0.1065 | 0.8502 |
| SANet | ECCV, 2018 | 10.2312 | 13.8073 | 0.1016 | 0.8769 |
| TasselNetV2 | PLME, 2019 | 19.5449 | 20.1694 | 0.1568 | 0.4132 |
| FIDTM | Arxiv, 2021 | 17.8176 | 18.4937 | 0.1421 | 0.5765 |
| LettuceNet | This study | 2.4486 | 4.0247 | 0.0276 | 0.9933 |
| Method | Venue, Year | MAE | RMSE | nRMSE | R2 |
|---|---|---|---|---|---|
| MCNN | CVPR, 2016 | 13.4583 | 14.7319 | 0.2096 | 0.7262 |
| CSRNet | CVPR, 2018 | 6.9403 | 8.4934 | 0.1347 | 0.8868 |
| SANet | ECCV, 2018 | 12.0519 | 14.0147 | 0.1972 | 0.7419 |
| TasselNetV2 | PLME, 2019 | 5.1772 | 6.1824 | 0.0982 | 0.9357 |
| FIDTM | Arxiv, 2021 | 10.1745 | 11.6043 | 0.1872 | 0.7876 |
| LettuceNet | This study | 5.8173 | 7.6048 | 0.1070 | 0.9057 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruan, A.; Xu, M.; Ban, S.; Wei, S.; Tian, M.; Yang, H.; Hu, A.; Hu, D.; Li, L. LettuceNet: A Novel Deep Learning Approach for Efficient Lettuce Localization and Counting. Agriculture 2024, 14, 1412. https://doi.org/10.3390/agriculture14081412
Ruan A, Xu M, Ban S, Wei S, Tian M, Yang H, Hu A, Hu D, Li L. LettuceNet: A Novel Deep Learning Approach for Efficient Lettuce Localization and Counting. Agriculture. 2024; 14(8):1412. https://doi.org/10.3390/agriculture14081412
Chicago/Turabian StyleRuan, Aowei, Mengyuan Xu, Songtao Ban, Shiwei Wei, Minglu Tian, Haoxuan Yang, Annan Hu, Dong Hu, and Linyi Li. 2024. "LettuceNet: A Novel Deep Learning Approach for Efficient Lettuce Localization and Counting" Agriculture 14, no. 8: 1412. https://doi.org/10.3390/agriculture14081412