Abstract
In response to the limitations of meteorological conditions in global rice growing areas and the high cost of annotating samples, this paper combines the Vertical-Vertical (VV) polarization and Vertical-Horizontal (VH) polarization backscatter features extracted from Sentinel-1 synthetic aperture radar (SAR) images and the NDVI, NDWI, and NDSI spectral index features extracted from Sentinel-2 multispectral images. By leveraging the advantages of an optimized Semi-Supervised Generative Adversarial Network (optimized SSGAN) in combining supervised learning and semi-supervised learning, rice extraction can be achieved with fewer annotated image samples. Within the optimized SSGAN framework, we introduce a focal-adversarial loss function to enhance the learning process for challenging samples; the generator module employs the Deeplabv3+ architecture, utilizing a Wide-ResNet network as its backbone while incorporating dropout layers and dilated convolutions to improve the receptive field and operational efficiency. Experimental results indicate that the optimized SSGAN, particularly when utilizing a 3/4 labeled sample ratio, significantly improves rice extraction accuracy, leading to a 5.39% increase in Mean Intersection over Union (MIoU) and a 2.05% increase in Overall Accuracy (OA) compared to the highest accuracy achieved before optimization. Moreover, the integration of SAR and multispectral data results in an OA of 93.29% and an MIoU of 82.10%, surpassing the performance of single-source data. These findings provide valuable insights for the extraction of rice information in global rice-growing regions.
1. Introduction
As global food demand continues to rise, precise crop mapping has become increasingly vital for comprehending agricultural land utilization and monitoring crop development [1]. Rice, as one of the world’s important food crops, holds significant importance for both farmers and the agricultural sector. Planting rice usually involves agricultural irrigation stages, with continuous or periodic water layers covering the soil to control weeds and pests. Therefore, the temporal variation in water soil rice composition is a key factor in extracting rice crops. One of the main methods for rice extraction is phenological analysis based on optical or radar time series, which extracts rice through the main planting stages [2,3].
Optical remote sensing data possess extensive spectral information, which is frequently utilized for the extraction of rice crops [4]. Optical imagery can yield detailed spectral data pertinent to rice, enabling extraction through the analysis of temporal changes in spectral curves [5]. For instance, Rong Guang et al. [6] employed long time-series Sentinel-2 imagery to develop spectral index features corresponding to various growth stages of rice. They implemented a pixel-based composite method of climatic features (Eppf-CM) in conjunction with Support Vector Machine (SVM) classifiers, achieving an overall accuracy of 98%. The capture of optical images is affected by weather conditions and cloud cover. The better the weather conditions, the higher the quality of the satellite imagery produced. Clear weather and cloudless skies provide the best shooting conditions for clear, sharp image data. In dense clouds or bad weather, the quality of the image will be affected. At this time, the ground object in the image is covered by clouds, and the accurate reflectivity of the ground object cannot be obtained, which reduces the usability and accuracy of the image. Under optimal ground observation conditions, rice can be accurately extracted using time-series optical remote sensing images that correspond to the rice growth stages. However, a significant challenge arises as most rice cultivation areas are situated in subtropical and tropical regions, where the critical climatic periods for rice growth are often marked by adverse weather conditions that hinder optical observations, thereby complicating the acquisition of high-quality time-series optical images. Synthetic aperture radar (SAR) is an active microwave imaging sensor that emits broadband signals. By combining synthetic aperture technology, SAR can simultaneously obtain 2D high-resolution images in both range and azimuth directions. Compared to traditional optical remote sensing and hyperspectral remote sensing, SAR is not affected by weather, climate, or lighting conditions, providing all-weather and all-time imaging capabilities. It also has a certain degree of penetration, allowing the obtained images to reflect the microwave scattering characteristics of targets. SAR is an important technological means for humans to acquire information about terrestrial objects [7]. As rice plants develop, there is a notable increase in height from the transplanting stage, peaking at the spike stage. When rice plants enter the maturity stage, spike weight increases with the accumulation of biomass. In addition, rice stalks are bent, resulting in a slight decrease in plant height. These alterations in biophysical characteristics significantly influence the variations in SAR backscattering coefficients. Consequently, the determination of whether an area is cultivated with rice can be inferred from the analysis of SAR signals [8]. The temporal and spatial continuity of SAR data renders it highly applicable for rice extraction. For example, Zhan et al. [9] utilized time-series Sentinel-1 SAR images to extract rice by calculating the slope of the backscattering curve, focusing on the distinctive “V”-shaped features in the VH polarization backscattering curves before and after rice transplantation. This approach yielded an overall accuracy of 86%, even with a limited number of labeled samples.
Although SAR can provide images of the whole growth stage of rice, the combination of optical and SAR images has become a hotspot for rice extraction because it is susceptible to noise and does not have the rich spectral information of optical images, which can easily lead to the omission of small patches of paddy fields [10]. For instance, Gao et al. [11] utilized time-series Sentinel-1 SAR images in conjunction with Sentinel-2 optical images to train multiple random forest classifiers for rice extraction, achieving an overall accuracy exceeding 84% without the use of labeled samples. Similarly, Xu et al. [12] introduced a novel SPRI index for rice extraction, leveraging the NDVI and NDWI spectral indices derived from high-quality Sentinel-2 optical images, alongside Sentinel-1 SAR images. Their experiments, conducted across five research areas, yielded an overall accuracy surpassing 91%. Nonetheless, it is important to note that the characteristics of targets as represented by radar and optical data differ significantly. Consequently, establishing a cross-modal association of information with these varying characteristics remains a critical challenge in enhancing the accuracy of rice identification [13].
The advancement of deep learning technology offers a novel approach to crop mapping utilizing multi-source remote sensing imagery [14]. Leveraging extensive sample data, deep learning models are capable of autonomously extracting information-dense features from both optical and SAR time-series imagery, thereby facilitating the generation of precise rice distribution maps [15]. K.R. Thorp and D. Drajat [16] employed Sentinel-1 SAR and Sentinel-2 optical remote sensing images to delineate rice cultivation in Java Province, Indonesia, utilizing a recursive neural network (RNN) architecture integrated with Long Short-Term Memory (LSTM) nodes. Similarly, Wang et al. [17] utilized the same datasets and achieved commendable accuracy by developing a time series dataset that combined LSTM with Dynamic Time Warping (DTW) distance metrics.
The aforementioned studies using deep learning to collaborate SAR and optical images to extract rice information have made some progress, but most of the features are shallow features such as texture and geometric features extracted by convolutional layers or by hand, and lack the utilization of high-level semantic features of the images. Architectures like U-net [18] and Deeplabv3+ [19] utilize downsampling and upsampling approaches, enabling the learning of both high-level semantic features and low-level details in a memory-efficient manner. For instance, Sun et al. [20] employed the U-Net model to extract rice information from Sentinel-1 and Sentinel-2 images, achieving an overall accuracy of 92.2%. Nonetheless, supervised learning necessitates a substantial quantity of labeled samples to yield high-precision outcomes. In practice, constraints related to funding and time often result in an insufficient number of labeled samples. Consequently, this paper proposes addressing this issue through the application of semi-supervised learning. This approach can effectively exploit the information contained within unlabeled data, thereby enhancing the accuracy of clustering boundaries by increasing sample diversity [21,22,23]. Semi-Supervised Generative Adversarial Networks (SSGANs) [24] represent a widely adopted semi-supervised algorithm. Generative Adversarial Networks (GANs) [25] enhance image recognition capabilities through an adversarial learning strategy, which continues until the discriminator is unable to distinguish between genuine and counterfeit samples, ultimately improving the accuracy of image recognition. SSGAN incorporates a semantic segmentation network, which has been successfully implemented in supervised learning contexts, as a generative network within the GAN framework. This integration aims to enhance the adaptability and effectiveness of the segmentation network by combining the strengths of the GAN framework to facilitate semi-supervised segmentation functionality [26].
The SSGAN proposed by Hung et al. [24] employs the DeepLabv2 [27] segmentation network in place of a traditional generator, leveraging Atros Spatial Pyramid Pooling (ASPP) to capture features at different scales. However, this network does not fully utilize shallow features and predicts at a downsampling scale of 8 times, resulting in less-than-ideal boundary effects. To address this limitation, the present study incorporates the DeepLabv3+ segmentation network as a replacement for the generator. DeepLabv3+ utilizes an encoder–decoder architecture, which enhances the resolution of feature maps, thereby preserving more intricate details that contribute to improved accuracy in segmentation boundaries. Additionally, it retains a greater amount of shallow information, facilitating the integration of feature maps across different modules. To enhance the model’s applicability to multi-channel few-shot datasets, this research employs Wide-ResNet [28] as the backbone network for DeepLabv3+.
Furthermore, the SSGAN proposed by Hung et al. [24] modifies the discriminator from a traditional classification network to an end-to-end fully convolutional network. The discriminator recognizes the source of the pixel based on the contextual information in the corresponding receptive field-sized area around the pixel, thereby enabling it to learn the local structural information within the subgraph, and then train the whole subgraph set through a loop. The discriminator acquires knowledge of the feature distribution characteristics of the remote sensing image prior to cropping, which aids in maintaining label continuity throughout the remote sensing image. However, the corresponding adversarial loss manifests as a pixel-by-pixel cross-entropy summation between the generator’s output and the actual labels. Consequently, when the generator successfully segments the majority of the input image regions, a significant number of pixels that could potentially mislead the discriminator correspond to minimal loss values. This phenomenon results in a reduction in overall image loss, thereby complicating the discriminator’s ability to effectively guide the gradient updating direction of the segmentation network. To address this challenge, the present study introduces a novel focal-adversarial loss function, which dynamically adjusts the weight of the loss values associated with both difficult and easy samples within the overall adversarial loss. This adjustment enables the model to concentrate more on challenging samples, ensuring that the discriminator consistently exerts effective constraints on the gradient updating direction of the generator.
In summary, this paper proposes an optimized SSGAN rice extraction method based on time-series Sentinel-1 SAR images and Sentinel-2 multispectral images to achieve high-precision rice extraction while alleviating the demand for labeled samples to a greater extent. The generator module of the SSGAN model uses the DeepLabv3+ segmentation network; however, it utilizes the Wide-ResNet architecture as its backbone, rather than the Xception network, to improve the model’s adaptability to small multi-channel datasets. Furthermore, the paper presents an innovative focal-adversarial loss function designed to encourage the discriminator to consistently and effectively approximate the gradient updates of the generator network, thereby further refining the rice extraction outcomes.
2. Materials and Methods
This research focused on the central region of Chongming Island as the designated study area. The analysis utilized time-series Sentinel-1A synthetic aperture radar (SAR) images and Sentinel-2 multispectral images as primary data sources to derive time-series backscattering characteristics in both VV and VH polarizations, as well as to calculate spectral indices, including NDVI, NDWI, and NDSI. The optimized SSGAN method in this paper was used for the extraction of rice. By comparing the rice extraction results with different classification methods and datasets, this study explores the ability of sentinel data and the improved SSGAN to extract rice in cloudy and rainy areas, forming a rice extraction model for areas lacking available optical images during the critical growth period. The technical route is illustrated in Figure 1.
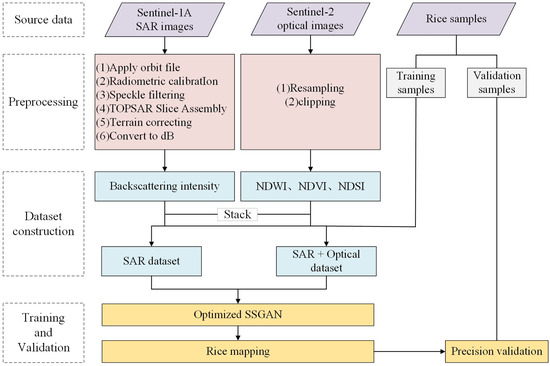
Figure 1.
Flow chart of the proposed method.
2.1. Study Area and Data
2.1.1. Study Area
The study area is situated in the central region of Chongming Island, China, as depicted in Figure 2. Chongming Island is positioned at the midpoint of China’s coastline along the western Pacific Ocean, with geographic coordinates ranging from 121°09′30″ to 121°54′00″ east longitude and 31°27′00″ to 31°51′15″ north latitude. It is located at the estuary of the Yangtze River, which is the largest river in China and is recognized as the largest estuarine alluvial island globally. Chongming Island is located in the subtropical zone, and the local flood season occurs from mid-June to late September and is characterized by high temperatures and heavy rainfall, making it difficult to obtain high-quality optical images.
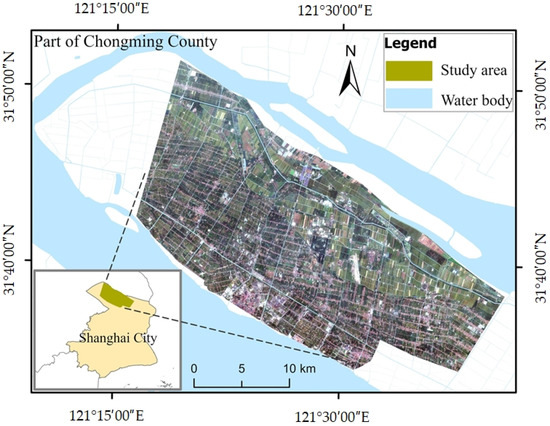
Figure 2.
Location of the study area and a true-color image map.
The cultivation of rice in the Chongming District of Shanghai encompasses several key stages: sowing and seedling development, transplanting, tillering and jointing, booting and heading, and finally, maturity and harvesting. Utilizing field sampling in conjunction with meteorological data sourced from the agricultural network of the China Meteorological Administration (CMA), a phenology for rice cultivation on Chongming Island has been established, as illustrated in Figure 3. The rice cultivated on Chongming Island is classified as single-season rice, characterized by a relatively extended growth period, typically spanning from mid-to-late May through to mid-to-late October. Consequently, all Sentinel-1A image data from May to November 2023 were selected for rice identification in this study.
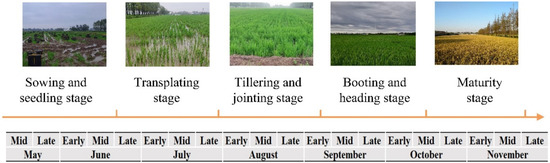
Figure 3.
The phenology of rice on Chongming Island.
2.1.2. Sentinel-1 SAR Data
The research employs Sentinel-1A synthetic aperture radar (SAR) data in Interferometric Wide (IW) mode at the Ground Range Detected (GRD) level. For the analysis, imagery collected between May 2023 and November 2023 was utilized, considering that the revisit interval for Sentinel-1 imagery is 12 days. This resulted in a total of 36 scenes and 18 phases of imagery, as detailed in Table 1.

Table 1.
Details of the Sentinel-1A images used.
The SAR images utilized in this study were obtained from the Alaska Satellite Facility (ASF) (https://search.asf.alaska.edu/, accessed on 21 December 2023). The preprocessing of these images was conducted using SNAPv9.0 software, which encompasses several key processes, including image mosaicing, orbit correction, radiometric calibration, speckle filtering, terrain correction, and conversion to decibels (dBs). Image mosaicing was performed using the TOPSAR Slice Assembly technique specifically developed for the mosaicing of SAR images, resulting in superior outcomes compared to conventional raster mosaicking methods. Speckle filtering was employed to eliminate noise from the radar data using the Refined Lee filtering method with a window size of 7 × 7. The conversion to dB serves three primary purposes: first, it normalizes the backscattering coefficient range to approximate a Gaussian distribution; second, it reduces the data storage requirements, as double-precision double-type data can be stored as float-type data; and third, it enhances the visualization and analysis of the radar data, which is initially presented in linear values that are not conducive to calculation due to their extensive range.
2.1.3. Sentinel-2 Multispectral Data
The research employed Sentinel-2 multispectral data at Level 2A, with images obtained from the European Space Agency (ESA) (https://dataspace.copernicus.eu/, accessed on 12 February 2024). A total of 18 high-quality images were selected for the study, encompassing the period from January 2023 to December 2023, which were organized into 9 distinct phases of imagery, as detailed in Table 2. From Table 2, it can be seen that due to the arrival of the flood season, there was a lot of cloud cover in the original image range on 28 May and 2 June. However, our study area was cloud-free, so these two images are usable. The cloud cover rate for images from July to September was over 90%, making it impossible to identify ground features from the images; thus, these images were not used.
Table 2.
Details of the Sentinel-2 images used.
The pre-processing of Sentinel-2 multispectral data was conducted using ENVI5.6. The Level 2A data have undergone radiometric calibration and atmospheric correction; therefore, this study primarily focuses on the processes of resampling, mosaicking, and cropping. The nearest neighbor method was used to resample the band data to 10 m, then the band data were combined to obtain the multi-band image data, and the optical image of the study area was obtained by mosaicking and combining with vector data cropping.
2.1.4. Rice Sample Data
The rice sample data utilized in this study were primarily obtained through field collection and high-resolution satellite imagery. Field samples were gathered on Chongming Island in late June, mid-September, and early December of 2023. Additionally, high-resolution images from the Jilin-1 Wide 01B satellite were employed to supplement these samples. The distribution of the rice samples is illustrated in Figure 4. Following the application of a sliding window cropping technique with a repetition rate of 0.2, the feature image data from the study area were segmented into deep learning image samples measuring 256 × 256 pixels. Ultimately, a total of 796 labeled image samples were generated after implementing data augmentation techniques, including horizontal flipping, vertical flipping, and mirror flipping.
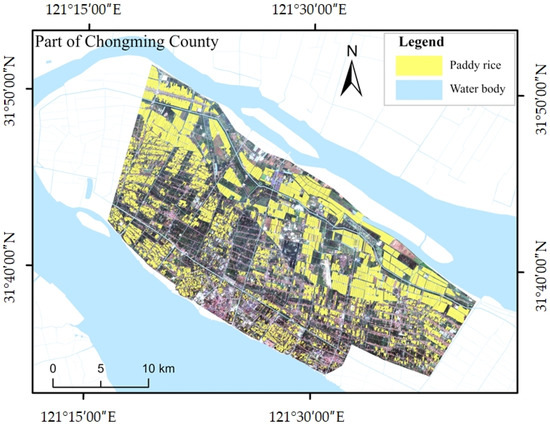
Figure 4.
A map of the distribution of rice samples.
2.2. Analysis of the Backscattering Characteristics of Rice
This research utilized the distribution statistics of ground object samples in the Chongming District to conduct a comparative analysis of the temporal trends in backscattering coefficients for various ground objects under both VV and VH polarizations.
Through field sampling and high-resolution image acquisition, eight distinct ground objects were identified: rice, reed, grassland, woodland, water, greenhouse, building, and other crops. The time-series backscattering curves for these eight ground objects were derived by calculating the mean values of all pixels corresponding to each date under both VV and VH polarizations (see Figure 5). The analysis of the backscattering curves indicates that the temporal variations in the VV and VH backscattering profiles of rice differ significantly from those of water bodies, construction sites, forests, grasslands, reeds, greenhouses, and other crops. Specifically, the time series backscattering curves for rice exhibit a wavy pattern characterized by two troughs and two peaks; however, the details of the VH and VV polarization responses differ. The VH polarization backscattering curve fluctuates between −19 and −16 dB, with troughs observed on 20 June and 12 September, and peaks on 27 May and 26 July. In contrast, the VV polarization backscattering curve varies between −13 and −8 dB, with troughs occurring on 8 June and 12 September, and peaks on 27 May and 14 July, respectively.
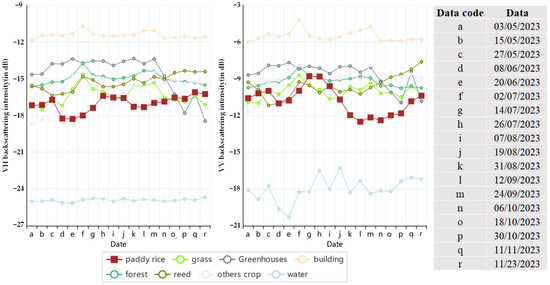
Figure 5.
Variation curves of backscatter values of VH and VV polarized features.
The mechanisms of backscattering in rice involve both surface and body scattering, which are influenced by various radar echoes [29]. Overall, the backscattering coefficient of rice is lower than that of other vegetation types, such as reeds and grasses, primarily due to the absorption characteristics of water bodies. During the mid-June period, which corresponds to the seedling and transplanting stages of rice growth, the scattering from the water in the paddy fields predominates, resulting in a backscattering value that is closely aligned with that of the water body, thus creating a trough in the data. As rice plants mature, there is a gradual increase in both leaf and stem density, leading to a predominance of canopy scattering combined with soil scattering. Consequently, the backscattering values exhibit an upward trend as the crop develops, peaking in mid-to-late July following the jointing stage. Post-jointing, there is a rapid increase in the number of rice plants, necessitating adequate water supply to support their growth. Insufficient water can lead to delayed heading or difficulties in flowering, as well as an increase in the occurrence of white spikes. Therefore, it is essential to irrigate the paddy fields after the jointing stage to maintain a thin layer of water. At this stage, the backscattering value of rice is influenced not only by canopy scattering but also significantly by the soil moisture content and its interaction with the rice plants. Following jointing, there is a marked decrease in the backscattering coefficient of rice, which begins to rise again around mid-September, coinciding with the heading and flowering phases. This increase is attributed to the need for soil aeration, which results in reduced soil moisture and subsequently leads to a gradual rise in the backscattering coefficient, thereby creating a characteristic wavy pattern in the backscattering data.
A comparative analysis of the change curves of backscattering intensity values for the two polarizations revealed that the disparity between the backscattering coefficients of rice and those of other features was more pronounced under the VH polarization than under the VV polarization. However, the magnitude of the change in backscattering coefficients was less significant under the VH polarization compared to that observed under the VV polarization.
2.3. Selection of Spectral Indices
In 2023, there were only nine periods of high-quality optical images that included the study area. These images encompass three distinct phases of the rice growth period: the seedling nursery period, which includes images from 28 May and 2 June, during which the soil moisture levels in the seedling rice fields are elevated, and the leaf area index is also notably high. Conversely, the unseeded rice fields exhibit a water layer covering the soil. The third time phase, captured on 15 October, corresponds to the rice maturity and harvesting period. At this time, a small portion of the rice fields has been harvested, leaving behind stubble and exposed soil, while the majority of the rice remains unharvested, with a high leaf area index still present. The other six phases are not within the rice growth period, but they also have certain indicative effects on rice extraction. Before planting rice, it is necessary to deeply plow, level, and finely break up the rice fields to ensure good drainage of the land in order to avoid flooding the rice. After the rice is harvested, there will be leftover rice stubble in the fields, as well as the re-tillage of mixed rice stubble, which will also have indicative effects on the spectral characteristics of the land. Consequently, the variations in the three components—water, soil, and vegetation—serve as significant indicators for the identification of rice.
Sentinel-2 imagery comprises 12 spectral bands, among which the red, near-infrared, and red-edge bands are particularly effective in capturing the distinct spectral signatures of vegetation and soil. These bands facilitate enhanced crop identification and monitoring of crop health [30,31]. Additionally, the green band and the near-infrared band are adept at delineating the unique spectral properties of aquatic environments. However, employing all bands of optical imagery as features may lead to information redundancy, diminishing the prominence of the feature information. Consequently, in alignment with the characteristics associated with the rice growth period, this study selected the NDWI, NDVI, and NDSI spectral indices as the primary features for the rice extraction analysis.
2.4. Optimized SSGAN Model
The SSGAN model has emerged as a significant component in the domain of computer vision in recent years, categorized into generative and non-generative semi-supervised learning approaches. Generative methods employ segmentation networks in place of discriminators, while non-generative methods utilize segmentation networks instead of generators. This study focuses on non-generative semi-supervised learning, applying the semi-supervised adversarial learning strategy proposed by Hung et al. [24], as illustrated in Figure 6. The fundamental concept of Generative Adversarial Networks (GANs) involves the use of two neural networks engaged in adversarial learning: a generator (G) and a discriminator (D). The generator is responsible for producing samples that closely resemble truth data, whereas the discriminator’s role is to ascertain whether the input samples are authentic or generated. These two networks engage in a competitive process to achieve a state of equilibrium, enabling the generator to produce high-quality fake samples while making it challenging for the discriminator to differentiate between genuine and fabricated samples. The SSGAN model incorporates fake samples generated by the generator along with truth samples during the classification process, increasing the diversity of the samples, which greatly helps improve the accuracy of object extraction tasks in multi-feature few-shot datasets.
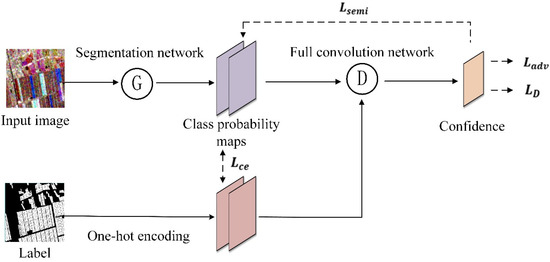
Figure 6.
Semi-supervised generation of adversarial learning strategies.
2.4.1. Loss Function
Figure 6 shows four distinct loss functions: discriminator losses , the cross-entropy loss of the partitioned true value , adversarial loss for deceiving discriminator , and semi-supervised losses based on confidence maps . Additionally, to facilitate the training of the generator segmentation network, a multitasking loss is employed. To represent these loss functions, we set as the input image, denotes the one-hot encoded true label, denotes the position of the pixel, denotes the generator, i.e., the segmentation network, and the output result is a category probability map of size , where denotes the number of categories and in this experiment. Consequently, refers to the predicted category probability map generated by the segmentation network. Furthermore, (∙) denotes the discriminator and the output result is a confidence map of size . Thus, indicates the prediction confidence of the discriminator on the output result of the generator, while reflects the prediction confidence of the discriminator on the truth labels. The variable indicates the source of input to the discriminator, whereas signifies that the input originates from the segmentation result and indicates that it is the input that is derived from the truth labels. The formulation of the loss function is presented as follows:
During the training phase, the generator segmentation network processes input images to produce predicted class probability maps. These maps are subsequently integrated with one-hot encoded label data and input into the discriminator network for assessment. The discriminator network generates a confidence map that serves as a binary classification probability map indicating whether a given pixel corresponds to an actual label or a pseudo-label generated by the network. The semi-supervised loss and the adversarial loss , aimed at deceiving the discriminator, are computed using the confidence map. These losses are then combined with the cross-entropy loss derived from the segmentation ground truth through a weighted summation to derive the multi-task loss . This loss is backpropagated to facilitate the training of the segmentation network, while is calculated from the confidence map to minimize the spatial cross-entropy loss for the training of the discriminator network. Notably, the process of employing the discriminator to regulate the gradient updates of the generator segmentation network relies solely on image data, thereby allowing the utilization of unlabeled samples for training the adversarial loss and enabling the implementation of semi-supervised learning.
The adversarial loss can be interpreted as a variant of cross-entropy, which involves the pixel-wise summation of the generator’s output and the actual labels. When the generator segmentation network demonstrates superior segmentation performance across the majority of the input image regions, a significant number of pixels that are particularly ambiguous for the discriminator yield lower loss values. This phenomenon results in a reduction of the overall image loss, thereby complicating the discriminator’s ability to effectively guide the gradient update direction of the generator segmentation network. To address this issue, we propose a focal adversarial loss , which adds an adjustment term and the equilibrium factor to the original adversarial loss , as expressed in the following formula:
The equilibrium factor primarily functions to balance the significance of positive and negative samples in the loss computation. An increase in indicates a greater emphasis on the loss associated with positive samples, while diminishing the importance of the loss related to negative samples. However, does not facilitate the differentiation between hard and easy samples. Consequently, we implement a dynamic adjustment of the loss contributions from both difficult and easy samples, based on the predictive confidence of the discriminator for the current samples, alongside the focusing factor . Samples with higher confidence are classified as easy samples, and the adjustment mechanism assigns them a lower weight, thereby reducing their contribution to the overall loss. Conversely, samples with lower confidence are identified as difficult samples, and the adjustment factor assigns them a higher weight, thereby increasing their contribution to the overall loss. This approach directs the network’s focus towards the learning of difficult samples. The parameter regulates the extent of attention allocated to the learning of difficult samples; a larger results in increased focus on these samples, making it particularly effective for addressing severe imbalances between positive and negative samples. By employing focal-adversarial loss, the model enhances its attention towards difficult and positive samples, effectively constraining the direction of gradient updates and thereby improving the model’s accuracy in rice extraction. Consequently, the segmentation loss function of the generator is expressed as follows:
2.4.2. Generator
In this research, we employ a modified version of Deeplabv3+ as the generator network. The salient characteristics of Deeplabv3+ include the Atrous Spatial Pyramid Pooling (ASPP) module and the encoder–decoder architecture. The ASPP module utilizes multi-sampling-rate dilation convolution, multi-receptive-field convolution, and pooling techniques on the input features to effectively capture multi-scale contextual information. Meanwhile, the encoder–decoder structure enhances the delineation of target boundaries by progressively restoring spatial information. Additionally, dilation convolution expands the receptive field while maintaining the dimensions of the feature map. However, the Xception backbone of DeepLabv3+ necessitates a substantial volume of training data to fully leverage its capabilities. In scenarios where training data is limited, there is a heightened risk of convergence challenges or performance deterioration, rendering it less suitable for few-shot datasets.
In addressing the aforementioned challenges, this paper presents an optimization of the DeepLabv3+ model. Firstly, the backbone network is substituted with the Wide-ResNet architecture. Compared to the Xception network, Wide-ResNet is posited to exhibit superior generalization capabilities due to its more straightforward structure, particularly when applied to smaller datasets. The Wide-ResNet enhances the network’s width by augmenting the number of channels within the convolutional layers, thereby improving the model’s receptive field [28]. This approach renders Wide-ResNet more efficient than traditional ResNet, which expands the receptive field through the stacking of residual blocks [31,32]. Furthermore, the standard 3 × 3 convolution utilized in the basic residual block and bottleneck layer of the final three modules of the Wide-ResNet network is replaced with 3 × 3 dilated convolution. Additionally, a dropout layer is incorporated within the residual block and bottleneck layer to randomly eliminate certain neurons and their corresponding weights, thereby mitigating the risk of overfitting. This strategy enhances the independence of the neurons within the network and significantly reduces the likelihood of overfitting, particularly given the high dimensionality of the features involved. The initial four modules retain the conventional structure of the basic residual block and bottleneck layer to ensure comprehensive feature learning from the dataset. Moreover, the order of batch normalization, activation, and convolution has been modified from convolution-batch normalization–activation to batch normalization–activation–convolution. This alteration has been demonstrated to yield faster processing times and improved outcomes. The structure of the improved generator network is illustrated in Figure 7. The architecture of the residual and bottleneck blocks employed in the generator backbone network is depicted in Figure 8.
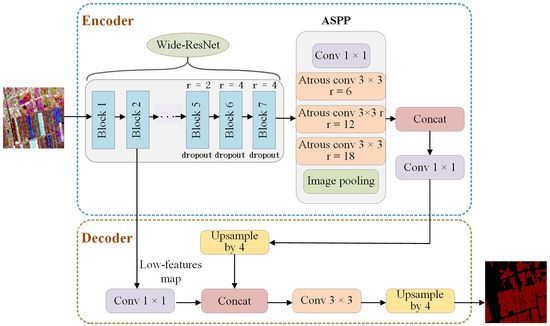
Figure 7.
Improved generator network structure diagram.
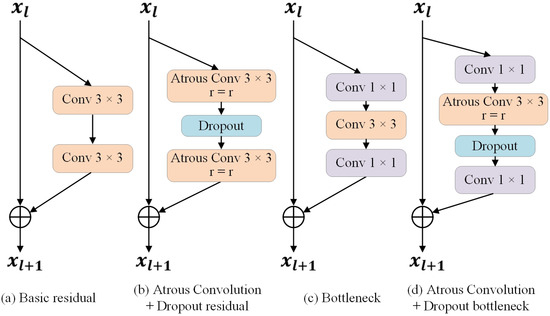
Figure 8.
Generator backbone network residual blocks and bottleneck layer structures. (a) Basic residual module; (b) Atrous Convolution + Dropout residual module; (c) Bottleneck module; (d) Atrous Convolution + Dropout bottleneck module.
2.4.3. Discriminator
This study employs a fully convolutional architecture as a discriminator network, which is designed to differentiate between the predicted probability map and the ground truth distribution while taking spatial resolution into account. The fully convolutional discriminator facilitates semi-supervised learning by identifying trusted regions within the predicted outcomes of unlabeled images, thus offering supplementary supervised signals. The structure of the discriminator is illustrated in Figure 9.

Figure 9.
Discriminator network structure.
2.5. Experimental Evaluation Metrics
In order to quantitatively evaluate the segmentation performance of different methods as network architectures, this paper uses Mean Intersection over Union (MIoU) and Overall Accuracy (OA) as criteria for assessing the results of rice extraction. Assuming that true positive (TP) and false positive (FP) represent the number of correctly and incorrectly classified rice samples, respectively, false negative (FN) and true negative (TN) represent the number of incorrectly and correctly classified non-rice samples, respectively.
OA is a simple accuracy metric that represents the proportion of correctly classified samples to the total number of samples. OA is commonly used to evaluate the overall performance of classification models, but it may not reflect the model’s specific performance across different categories. When the distribution of data categories is imbalanced, OA may not accurately assess the quality of the model, as it only considers the overall classification accuracy. The OA calculation formula is shown in Equation (8).
MIoU is the mean value of the pixel-level IoU (Intersection over Union). IoU measures the ratio of the intersection to the union between the predicted results and the true labels, while MIoU calculates the IoU value for each category and then takes the average, allowing for a more comprehensive assessment of the model’s performance across all categories. The advantage of MIoU is that it effectively measures the model’s performance for each category. The MIoU calculation formula is shown in Equation (9), where M represents the total number of categories.
3. Results
3.1. Experimental Conditions and Dataset
Experimental conditions: Windows operating system, NVIDIA RTX A4000 graphics card, Python compilation environment, Pytorch deep learning framework. To train the segmentation network, this paper uses the SGD optimizer, in which the momentum is 0.9, the weight decay coefficient is 0.0005, and the initial learning rate is set to 2.5 × 10−4. To train the discriminator, this paper uses the Adam optimizer, and the learning rate is 10−4.
Dataset: A total of 199 raw labeled samples, each measuring 256 × 256 pixels, were subjected to data augmentation techniques, including horizontal flipping, vertical flipping, and mirror flipping, resulting in an expanded dataset of 796 samples. This dataset was subsequently partitioned into a training set and a validation set, adhering to an 8:2 ratio, which comprised 636 samples for training and 160 samples for validation. Throughout the training phase, each feature combination was iterated upon 1000 times, utilizing a batch size of 12. The initial 300 iterations were conducted under a fully supervised training paradigm, exclusively employing labeled rice samples, with the primary objective of enabling the model to thoroughly learn the features of rice. Commencing from the 301st iteration, a semi-supervised training approach was implemented, wherein both labeled samples and fake samples were utilized concurrently. The proportion of labeled samples was set to one-quarter, three-quarters, and the full dataset, with a proportion of 1 indicating 1000 iterations of fully supervised training without including fake samples.
Experimental evaluation metrics: In order to quantitatively assess the rice extraction efficacy of various methodologies, this study employs Mean Intersection over Union (MIoU) and Overall Accuracy (OA) as the metrics for evaluating the outcomes of rice extraction.
3.2. Generator Performance Analysis
To assess the advanced capabilities of the segmentation network employed in the generator, we conduct a comparative analysis of the Deeplabv3+ segmentation network presented in this study against several other models, including U-net [18], Deeplabv2 [27], PSPNet [33], and SegNet [34]. In our training process, we employ consistent parameters and datasets across various models, utilizing one-quarter of the dataset, three-quarters of the dataset, and the entirety of the available training samples, respectively. This approach aims to demonstrate the enhanced adaptability of our optimized Deeplabv3+ model to multi-feature few-shot datasets. The input features consist of dual-polarized time-series SAR data and three spectral indices, resulting in a channel dimension of 63. As illustrated in Table 3, our optimized Deeplabv3+ model consistently outperforms the other four methods in rice extraction accuracy, irrespective of the training sample size. Notably, it maintains a stable and high level of accuracy even with a reduced number of samples, achieving an MIoU exceeding 80.5% and an OA surpassing 92.4%. These results substantiate the model’s suitability for a multi-feature few-shot dataset.
Table 3.
Performance analysis of generator segmentation network extraction for rice.
3.3. Hyperparameter Analysis
In this subsection, we examine the focusing factor and the equilibrium factor within the context of the proposed focal-adversarial loss function. A series of experiments were conducted using various parameter values to identify the most suitable configurations. In accordance with the existing literature [35], the parameter was assigned values of 1, 2, and 5, while the equilibrium factor was set to 0.25 and 0.75. The input features comprised dual-polarized time-series SAR backscattering values, as well as the NDWI, NDVI, and NDSI spectral indices. The labeled samples constituted one-quarter of the dataset, three-quarters of the dataset, and all the samples, respectively. As illustrated in Table 4, irrespective of the number of labeled samples, the accuracy of rice extraction was found to be greater when was set to 0.75 and was set to 2, in comparison to other parameter values. Furthermore, the highest accuracy in rice extraction was achieved when the proportion of labeled samples was three-quarters of the dataset, thereby affirming the superiority of the semi-supervised SSGAN method employed over the fully supervised approach. From these experimental findings, it can be inferred that the optimal value for is 0.75 and the optimal value for is 2 in the context of this rice extraction task.
Table 4.
Hyperparameter and value analysis.
3.4. Rice Extraction Results and Analysis
In accordance with the findings from the hyperparameter analysis presented in Section 3.3, we have established the values of and in the focal-adversarial loss function to be 0.75 and 2, respectively, for the purpose of conducting precision comparison experiments.
3.4.1. Comparative Analysis of the Accuracy of Various Feature Combinations
The features used in this paper include the 18-time-phase VH and VV polarized backscattering value data and the 9-time-phase NDWI, NDVI, and NDSI data. To assess the efficacy of the proposed dual-polarized SAR backscattering features in conjunction with the three spectral index features for the extraction of rice, various combinations of these features were incorporated into our enhanced SSGAN model for experimental analysis.
Table 5 presents the accuracy of rice extraction using various combinations of input features. In the table, a check mark (√) denotes the inclusion of a feature, while a cross (×) indicates its exclusion. The experimental results indicate that the extraction accuracy for rice achieved through our proposed combination ④, which integrates dual-polarized synthetic aperture radar (SAR) with spectral index features, is markedly superior to that obtained solely using SAR data. The highest extraction accuracy for rice occurs when the proportion of labeled samples is set at 3/4, yielding an MIoU value of 82.10% and an OA value of 93.29%. Compared to combination ①, there is an increase of 1.1% in the MIoU value and 0.44% in the OA value; relative to combination ②, the MIoU value rises by 1.05% and the OA value by 0.37%; and in comparison to combination ③, the MIoU and OA values increase by 1.1% and 0.44%, respectively. Furthermore, the accuracy of rice extraction using combination ③ demonstrates a significant enhancement over combinations ① and ②, with an average increase of approximately 0.75% in MIoU and 0.36% in OA. This improvement can be attributed to the greater disparity in backscattering coefficients between rice and other features under VH polarization compared to VV polarization. However, the variation in backscattering coefficients is more pronounced under VV polarization. Consequently, the simultaneous utilization of both VH and VV features results in higher extraction accuracy than when employing either feature independently. This leads to two key conclusions: first, that single-polarization SAR cannot fully leverage the information pertaining to rice features; and second, that the integration of SAR features and spectral index features, which are closely associated with rice growth, can further enhance the accuracy of rice extraction.
Table 5.
Comparison of the accuracy of different feature combinations for extracting rice.
3.4.2. Comparative Analysis of Accuracy Pre- and Post-SSGAN Optimization
To ascertain that each optimization made to the baseline SSGAN [24] model yielded beneficial outcomes, we employed a consistent input dataset and systematically conducted experiments on the identified improvement areas. These included modifying the adversarial loss function to focal-adversarial loss (+), optimizing the generator to utilize Deeplabv3+ (+Deeplabv3+), and subsequently adjusting the adversarial loss function to focal-adversarial loss , while also optimizing the generator to Deeplabv3+ (+ + Deeplabv3+). Furthermore, to evaluate the semi-supervised performance, we configured the number of labeled samples to represent one-quarter of the dataset, three-quarters of the dataset, and the full dataset, respectively. Utilizing all labeled samples corresponds to a scenario of supervised learning.
VH polarization feature dataset. Table 6 presents the accuracy achieved in rice extraction when employing an input feature that includes 18-time-phase VH polarization backscattering data. Furthermore, Figure 10 depicts the growth values in rice extraction accuracy at each improvement step in comparison to the baseline SSGAN.
Table 6.
Analysis of rice extraction accuracy for VH feature combinations.
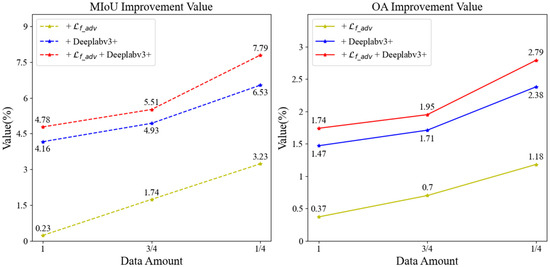
Figure 10.
VH polarization feature dataset accuracy enhancement values.
Table 6 illustrates that when rice is extracted using the baseline SSGAN model, the rice extraction accuracy is highest when using all labeled samples, with an MIoU value of 76.52% and an OA value of 91.03%. After we improve the SSGAN model (+ + Deeplabv3+), the rice extraction accuracy is highest when the labeled data account for three-quarters of the dataset, and it also has the highest accuracy in these four cases, with an MIoU value of 81.33% and an OA value of 92.79%. This represents an improvement of 4.81% in MIoU and 1.76% in OA compared to the highest accuracy achieved by the baseline SSGAN model, significantly enhancing rice extraction accuracy.
As illustrated in Figure 10, the analysis reveals that when using the entirety of the labeled data for supervised learning, the MIoU exhibits an enhancement of 0.23% and OA shows an improvement of 0.37% when the adversarial loss function is modified to the focal-adversarial loss function in comparison to the baseline SSGAN. Furthermore, substituting the generative network with the optimized DeepLabv3+ results in a 4.16% increase in MIoU and a 1.47% increase in OA. When both the adversarial loss function and the generative network are concurrently optimized, MIoU improves by 4.78% and OA by 1.74%. In scenarios where the proportion of labeled data is three-quarters of the dataset for the semi-supervised learning, the results indicate that changing the adversarial loss function to the focal-adversarial loss function yields a 1.74% improvement in MIoU and a 0.7% improvement in OA compared to the baseline SSGAN. Additionally, altering the generative network to the optimized DeepLabv3+ results in a 4.93% increase in MIoU and a 1.71% increase in OA. When both enhancements are applied simultaneously, MIoU increases by 5.51% and OA by 1.95%. In cases where the proportion of labeled data is reduced to 1/4 for semi-supervised learning, the findings indicate that modifying the adversarial loss function to the focal-adversarial loss function leads to a 3.23% improvement in MIoU and a 1.18% improvement in OA. Changing the generative network to the optimized DeepLabv3+ results in a 6.53% increase in MIoU and a 2.38% increase in OA. When both the adversarial loss function and the generative network are improved simultaneously, MIoU increases by 7.79% and OA by 2.79%. Overall, the data suggest that a smaller proportion of labeled data correlates with a greater enhancement in rice extraction accuracy, thereby highlighting the pronounced efficacy of the optimized SSGAN model in improving rice extraction accuracy.
VV polarization feature dataset. Table 7 presents the accuracy achieved in rice extraction when employing an input feature that includes 18-time-phase VV polarization backscattering data. Furthermore, Figure 11 depicts the growth values in rice extraction accuracy at each improvement step in comparison to the baseline SSGAN.
Table 7.
Analysis of the extraction accuracy of VV feature combinations for rice.
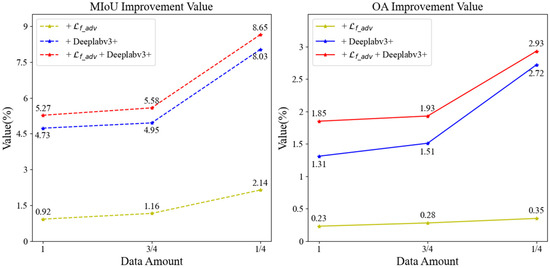
Figure 11.
VV polarization feature dataset accuracy enhancement values.
Table 7 illustrates that when rice is extracted using the baseline SSGAN model, the rice extraction accuracy is highest when utilizing all labeled samples, with an MIoU value of 75.50% and an OA value of 90.80%. After we improve the SSGAN model (+ + Deeplabv3+), the rice extraction accuracy is highest when the labeled data account for three-quarters of the dataset, and it also has the highest accuracy in these four cases, with an MIoU value of 80.81% and an OA value of 92.65%. This represents an improvement of 5.31% in MIoU and 1.85% in OA compared to the highest accuracy achieved by the baseline SSGAN model, significantly enhancing rice extraction accuracy.
As illustrated in Figure 11, the analysis reveals that when utilizing the entirety of the labeled data for supervised learning, the MIoU exhibits an enhancement of 0.92%, and the OA shows an improvement of 0.23% when the adversarial loss function is modified to the focal-adversarial loss function in comparison to the baseline SSGAN. Furthermore, substituting the generative network with the optimized DeepLabv3+ results in a 4.73% increase in MIoU and a 1.31% increase in OA. When both the adversarial loss function and the generative network are concurrently optimized, MIoU improves by 5.27% and OA by 1.85%. In scenarios where the proportion of labeled data is three-quarters of the dataset for semi-supervised learning, the results indicate that changing the adversarial loss function to the focal-adversarial loss function yields a 1.16% improvement in MIoU and a 0.28% improvement in OA compared to the baseline SSGAN. Additionally, altering the generative network to the optimized DeepLabv3+ results in a 4.95% increase in MIoU and a 1.51% increase in OA. When both enhancements are applied simultaneously, MIoU increases by 5.58% and OA by 1.93%. In cases where the proportion of labeled data is reduced to one-quarter of the dataset for semi-supervised learning, the findings indicate that modifying the adversarial loss function to the focal-adversarial loss function leads to a 2.14% improvement in MIoU and a 0.35% improvement in OA. Changing the generative network to the optimized DeepLabv3+ results in an 8.03% increase in MIoU and a 2.72% increase in OA. When both the adversarial loss function and the generative network are improved simultaneously, MIoU increases by 8.65% and OA by 2.93%. Overall, the data suggest that a smaller proportion of labeled data correlates with a greater enhancement in rice extraction accuracy, thereby highlighting the pronounced efficacy of the optimized SSGAN model in improving rice extraction accuracy.
VH + VV polarization feature dataset. Table 8 presents the accuracy achieved in rice extraction when employing an input feature that includes 18-time-phase VV and VH polarization backscattering data. Furthermore, Figure 12 depicts the growth values in rice extraction accuracy at each improvement step in comparison to the baseline SSGAN.
Table 8.
Analysis of rice extraction accuracy for VH + VV feature combination.
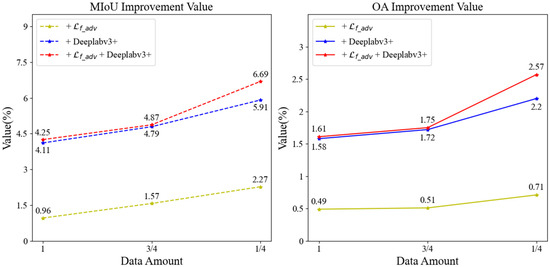
Figure 12.
VH + VV polarization feature dataset accuracy enhancement values.
Table 8 illustrates that when rice is extracted using the baseline SSGAN model, the rice extraction accuracy is highest when utilizing all labeled samples, with an MIoU value of 77.19% and anOA value of 91.34%. After we improve the SSGAN model (+ + Deeplabv3+), the rice extraction accuracy is highest when the labeled data account for three-quarters of the dataset, and it also has the highest accuracy in these four cases, with an MIoU value of 81.53% and an OA value of 92.97%. This represents an improvement of 4.34% in MIoU and 1.63% in OA compared to the highest accuracy achieved by the baseline SSGAN model, significantly enhancing rice extraction accuracy.
As illustrated in Figure 12, the analysis reveals that when utilizing the entirety of the labeled data for supervised learning, the MIoU exhibits an enhancement of 0.96% and the OA shows an improvement of 0.49% when the adversarial loss function is modified to the focal-adversarial loss function in comparison to the baseline SSGAN. Furthermore, substituting the generative network with the optimized DeepLabv3+ results in a 4.11% increase in MIoU and a 1.58% increase in OA. When both the adversarial loss function and the generative network are concurrently optimized, MIoU improves by 4.25% and OA by 1.61%. In scenarios where the proportion of labeled data is three-quarters of the dataset for semi-supervised learning, the results indicate that changing the adversarial loss function to the focal-adversarial loss function yields a 1.57% improvement in MIoU and a 0.51% improvement in OA compared to the baseline SSGAN. Additionally, altering the generative network to the optimized DeepLabv3+ results in a 4.79% increase in MIoU and a 1.72% increase in OA. When both enhancements are applied simultaneously, MIoU increases by 4.87% and OA by 1.75%. In cases where the proportion of labeled data is reduced to one-quarter of the dataset for semi-supervised learning, the findings indicate that modifying the adversarial loss function to the focal-adversarial loss function leads to a 2.27% improvement in MIoU and a 0.71% improvement in OA. Changing the generative network to the optimized DeepLabv3+ results in a 5.91% increase in MIoU and a 2.2% increase in OA. When both the adversarial loss function and the generative network are improved simultaneously, MIoU increases by 6.69% and OA by 2.57%. Overall, the data suggests that a smaller proportion of labeled data correlates with a greater enhancement in rice extraction accuracy, thereby highlighting the pronounced efficacy of the optimized SSGAN model in improving rice extraction accuracy.
VH polarization + VV polarization + NDVI + NDWI + NDSI feature dataset. Table 9 presents the accuracy achieved in rice extraction when employing an input feature that includes VV and VH polarization backscattering features, along with the spectral index features of NDWI, NDVI, and NDSI. Furthermore, Figure 13 demonstrates the incremental growth in rice extraction accuracy at each improvement step relative to the baseline SSGAN.
Table 9.
Analysis of rice extraction accuracy of VH + VV + NDWI + NDVI + NDSI feature combinations.
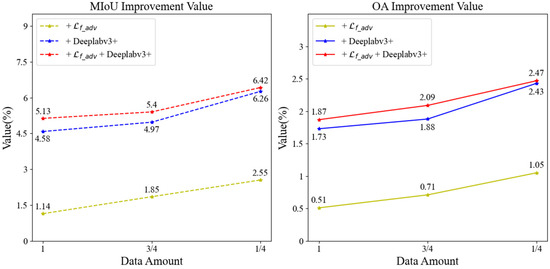
Figure 13.
VH polarization + VV polarization + NDVI + NDWI + NDSI feature dataset accuracy enhancement values.
Table 9 illustrates that when rice is extracted using the baseline SSGAN model, the rice extraction accuracy is highest when utilizing all the labeled samples, with an MIoU value of 76.71% and an OA value of 91.24%. After we improve the SSGAN model (+ + Deeplabv3+), the rice extraction accuracy is highest when the labeled data account for three-quarters of the dataset, and it also has the highest accuracy in these four cases, with an MIoU value of 82.10% and an OA value of 93.29%. This represents an improvement of 5.39% in MIoU and 2.05% in OA compared to the highest accuracy achieved by the baseline SSGAN model, significantly enhancing the rice extraction accuracy.
As illustrated in Figure 13, the analysis reveals that when utilizing the entirety of the labeled data for supervised learning, the MIoU exhibits an enhancement of 1.14% and OA shows an improvement of 0.51% when the adversarial loss function is modified to the focal-adversarial loss function in comparison to the baseline SSGAN. Furthermore, substituting the generative network with the optimized DeepLabv3+ results in a 4.58% increase in MIoU and a 1.73% increase in OA. When both the adversarial loss function and the generative network are concurrently optimized, MIoU improves by 5.13% and OA by 1.87%. In scenarios where the proportion of labeled data is three-quarters of the dataset for semi-supervised learning, the results indicate that changing the adversarial loss function to the focal-adversarial loss function yields a 1.85% improvement in MIoU and a 0.71% improvement in OA compared to the baseline SSGAN. Additionally, altering the generative network to the optimized DeepLabv3+ results in a 4.97% increase in MIoU and a 1.88% increase in OA. When both enhancements are applied simultaneously, MIoU increases by 5.4% and OA by 2.09%. In cases where the proportion of labeled data is reduced to one-quarter of the dataset for semi-supervised learning, the findings indicate that modifying the adversarial loss function to the focal-adversarial loss function leads to a 2.55% improvement in MIoU and a 1.05% improvement in OA. Changing the generative network to the optimized DeepLabv3+ results in a 6.26% increase in MIoU and a 2.43% increase in OA. When both the adversarial loss function and the generative network are improved simultaneously, MIoU increases by 6.42% and OA by 2.47%. Overall, the data suggests that a smaller proportion of labeled data correlates with a greater enhancement in rice extraction accuracy, thereby highlighting the pronounced efficacy of the optimized SSGAN model in improving rice extraction accuracy.
Through comparative analysis of the rice extraction performance of the SSGAN model across four datasets, three key conclusions can be drawn. First, the optimized SSGAN model consistently demonstrates superior rice extraction accuracy relative to the baseline SSGAN across all datasets. This enhancement in performance can be attributed to improvements in both the adversarial loss function and the generator, thereby affirming the intentional nature of the model’s advancements. Second, for the baseline SSGAN, the highest rice extraction accuracy is achieved when utilizing all the labeled samples. As the number of labeled samples decreases, the accuracy of rice extraction decreases. However, following the enhancements made to the generator and the adversarial loss function, the model attains its peak accuracy at a labeled data proportion of three-quarters of the dataset. This finding indicates that the modifications significantly bolster the semi-supervised capabilities of the model. The incorporation of unlabeled samples contributes to an increase in sample diversity, further validating the positive impact of our improvements to the baseline SSGAN. Third, a comparison of rice extraction accuracy reveals that as the proportion of labeled data diminishes, the magnitude of accuracy improvement with each enhancement step becomes more pronounced, highlighting the model’s enhanced capacity for accuracy improvement under conditions of limited labeled data.
In order to elucidate the enhancement effects of the SSGAN model and the efficacy of rice extraction, data pertaining to the fragmentation and concentration of rice plots were selected from the experimental results for visualization and analysis. The findings are presented in Figure 14. Ground-truth A denotes fragmented rice plots, while ground-truth B indicates concentrated rice plots. The figure illustrates that, in comparison to the baseline SSGAN, the modified SSGAN network demonstrates a marked improvement in boundary delineation and the accuracy of small plot localization. Furthermore, the results of rice extraction in concentrated rice plots exhibit greater precision. However, there is still noise, and the ability to identify rice in fragmented rice plots needs to be strengthened. Consequently, future efforts should focus on implementing more effective methodologies to optimize rice extraction outcomes.

Figure 14.
Comparative plots of rice extraction results.
4. Discussion
This study addresses the limitations of meteorological conditions in global rice planting areas and the high cost of labeling rice samples by proposing an optimized SSGAN rice extraction method based on time-series Sentinel imagery.
Traditional classifiers, including maximum likelihood classifiers and shallow machine learning algorithms such as Random Forest (RF) and Support Vector Machine (SVM), have established themselves as standard methodologies within the agricultural domain. However, advancements in technology and the proliferation of high-performance computing have led to a burgeoning interest in deep learning applications in remote sensing. Numerous researchers have investigated the benefits of utilizing Sentinel-1 synthetic aperture radar (SAR) data in conjunction with Sentinel-2 multispectral data, leveraging deep learning techniques for the extraction of rice data. One notable aspect is the substantial differences in the characteristics of targets as represented by radar and optical data. Deep learning facilitates cross-modal integration of heterogeneous information, enabling the automatic extraction of both shallow and deep features present in the imagery. This capability is further enhanced through the expansion of the receptive field or the integration of multiple scales, employing techniques such as dilated convolutions, pyramid pooling models, or the construction of networks designed to learn and amalgamate images captured at varying resolutions and by different sensors. Additionally, deep learning methodologies prioritize the extraction of contextual information, which can be effectively combined with spatial data through the use of skip connections, thereby maintaining the continuity of the images. Presently, rice extraction techniques predominantly rely on supervised learning approaches. While these methods demonstrate high accuracy in rice extraction, they necessitate a substantial volume of rice samples, and there is a lack of comprehensive discourse regarding the efficacy of these supervised learning techniques in scenarios characterized by limited sample sizes. Consequently, we advocate for the implementation of an optimized semi-supervised generative adversarial network for rice extraction, which aims to ensure the accuracy of the extraction process while utilizing a reduced number of samples.
We discovered that in situations with limited sample sizes, semi-supervised learning outperforms supervised learning regarding rice extraction capabilities. In Section 3.4.1, we discussed the impact of different feature combinations on the accuracy of rice extraction. The findings revealed that the highest accuracy was obtained using three-quarters of the labeled samples in a semi-supervised context, achieving an overall accuracy (OA) of 93.29% and a Mean Intersection over Union (MIoU) of 82.10%. Additionally, our enhancements to the SSGAN model made it more effective for multi-feature few-shot datasets. In Section 3.4.2, we discussed the impact of our improvements to the SSGAN model on rice extraction accuracy. The results indicated that compared to the baseline SSGAN, our optimized SSGAN model has stronger semi-supervised capabilities and better information mining ability for unlabeled samples. Furthermore, the fewer labeled samples there are, the greater the accuracy improvement of the optimized SSGAN, confirming that our optimized SSGAN model has advantages in the task of object extraction from few-shot datasets.
Similar to our research, many scholars have previously explored how to improve rice extraction accuracy as much as possible in cases where there are few or no labeled samples. For example, Gao et al. [11] did not use any labeled samples and utilized SAR and multispectral data to perform rice extraction by integrating multiple random forest classifiers; however, the overall accuracy of rice extraction was only 84%. Xu et al. [12] used a small number of labeled samples and employed NDVI and NDWI spectral indices along with SAR imagery data. They constructed a novel SPRI index based on the changes in water and vegetation components during the rice growth period to classify whether an area contains rice based on the index value. This method achieved an overall accuracy of 91% and had a lower demand for labeled samples. However, this method requires the availability of multispectral imagery during the critical growth period of rice, specifically during the jointing and heading stages, and the study area selected in this paper lacks high-quality optical imagery during that period, making this method unsuitable for rice extraction task in this study area. With the development of deep learning, rice extraction methods have gradually leaned towards deep learning, which can jointly utilize multispectral and SAR data across modalities to achieve high-accuracy rice extraction results. However, most current rice extraction research primarily focuses on supervised learning, including [16,17,20], which has a high demand for labeled samples that are difficult to obtain and are also costly. Therefore, the difference between this paper and earlier studies lies in the use of semi-supervised deep learning methods for rice extraction, which reduces the demand for samples while ensuring the accuracy of rice extraction.
While the method introduced in this paper effectively addresses the challenge of high demand for labeled samples and maintains accuracy in rice extraction compared to earlier studies, there are still opportunities for enhancement. As illustrated in Figure 14, our optimized SSGAN notably improved the clarity of boundaries and the precision of small plot location identification compared to its pre-optimization state; however, some noise remains. This noise is attributed to the nature of radar images, where the microwave reflection characteristics of the target are affected by variables such as frequency and polarization. In contrast, panchromatic optical remote sensing images generally offer high spatial resolution, enabling the capture of detailed contour information with distinct edges [36]. By combining SAR and panchromatic images, we can preserve the spatial structural details of the panchromatic image while also retaining the backscattering data from the SAR image, which can enhance subsequent image analysis and interpretation [37,38,39,40]. This approach could yield more useful information for rice extraction. Therefore, integrating SAR images with panchromatic images for rice extraction appears to be a viable strategy for mitigating the noise impact in SAR images on extraction outcomes; this will be the focus of our future research.
5. Conclusions
This study focuses on the extraction of rice information utilizing time-series Sentinel image data and the optimized SSGAN algorithm, taking into account the prevalent conditions of significant rainfall in global rice cultivation regions and substantial expenses associated with labeled samples.
Experimental findings indicate that by combining time series SAR data with spectral index features that are closely linked to rice growth, the accuracy of rice extraction can be significantly enhanced. Utilizing all features from both data sources results in an overall accuracy of 93.29% for the extracted rice planting areas, with an MIoU value of 82.10%, demonstrating a notable improvement in accuracy compared to using a single data source. Moreover, the optimized SSGAN model significantly improves the accuracy of rice extraction, particularly when labeled data comprises three-quarters of the dataset, resulting in the highest accuracy achieved. When compared to the baseline SSGAN’s best accuracy, the MIoU increased by 5.39% and the OA improved by 2.05%. These results suggest that the inclusion of a certain proportion of unlabeled samples in rice extraction tasks characterized by limited data can enhance sample diversity, bolster the model’s learning capabilities, and ultimately lead to improved extraction accuracy.
In forthcoming research endeavors, we will examine fusion techniques that integrate SAR images with panchromatic images to enhance the resolution of SAR imagery and mitigate noise levels. Additionally, we will persist in our exploration of methodologies for utilizing existing samples for feature selection, optimizing data sources, minimizing computational time, and achieving greater accuracy in results.
Author Contributions
Conceptualization, L.D. and Z.L.; methodology, L.D.; software, L.D.; validation, L.D.; formal analysis, L.D.; investigation, L.D. and F.Z.; resources, Q.W.; data curation, F.Z. and S.T.; writing—original draft preparation, L.D.; writing—review and editing, Z.L. and Q.W.; visualization, L.D.; supervision, Z.L.; project administration, Q.W.; funding acquisition, Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant number 42172118.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy and ethical restrictions.
Acknowledgments
This paper is supported by the National Natural Science Foundation of China under grant number 42172118. We would like to thank Sun Jing from Tongling University for providing valuable feedback on this article and for selflessly revising it. Lingling Du would like to thank Kai Yang for his patience, care, and support.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ranjan, A.K.; Parida, B.R. Predicting paddy yield at spatial scale using optical and Synthetic Aperture Radar (SAR) based satellite data in conjunction with field-based Crop Cutting Experiment (CCE) data. Int. J. Remote Sens. 2021, 42, 2046–2071. [Google Scholar] [CrossRef]
- Chen, J.; Yu, T.; Cherney, J.; Zhang, Z. Optimal Integration of Optical and SAR Data for Improving Alfalfa Yield and Quality Traits Prediction: New Insights into Satellite-Based Forage Crop Monitoring. Remote Sens. 2024, 16, 734. [Google Scholar] [CrossRef]
- Zhao, R.; Li, Y.; Ma, M. Mapping Paddy Rice with Satellite Remote Sensing: A Review. Sustainability 2021, 13, 503. [Google Scholar] [CrossRef]
- Tariq, A.; Yan, J.; Gagnon, A.; Khan, M.R.; Mumtaz, F. Mapping of cropland, cropping patterns and crop types by combining optical remote sensing images with decision tree classifier and random forest. Geo-Spat. Inf. Sci. 2022, 26, 302–320. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, H. Remote sensing extraction of paddy rice in Northeast China from GF-6 images by combining feature optimization and random forest. Natl. Remote Sens. Bull. 2023, 27, 2153–2164. [Google Scholar] [CrossRef]
- Ni, R.; Tian, J.; Li, X.; Yin, D.; Li, J.; Gong, H.; Zhang, J.; Zhu, L.; Wu, D. An enhanced pixel-based phenological feature for accurate paddy rice mapping with Sentinel-2 imagery in Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2021, 178, 282–296. [Google Scholar] [CrossRef]
- Dong, J.; Xiao, X. Evolution of regional to global paddy rice mapping methods: A review. ISPRS J. Photogramm. Remote Sens. 2016, 119, 214–227. [Google Scholar] [CrossRef]
- Wu, F.; Wang, C.; Zhang, H.; Zhang, B.; Tang, Y. Rice Crop Monitoring in South China With RADARSAT-2 Quad-Polarization SAR Data. IEEE Geosci. Remote Sens. Lett. 2011, 8, 196–200. [Google Scholar] [CrossRef]
- Zhan, P.; Zhu, W.; Li, N. An automated rice mapping method based on flooding signals in synthetic aperture radar time series. Remote Sens. Environ. 2021, 252, 112112. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Conrad, C. Crop type classification using a combination of optical and radar remote sensing data: A review. Int. J. Remote Sens. 2019, 40, 6553–6595. [Google Scholar] [CrossRef]
- Gao, Y.; Pan, Y.; Zhu, X.; Li, L.; Ren, S.; Zhao, C.; Zheng, X. FARM: A fully automated rice mapping framework combining Sentinel-1 SAR and Sentinel-2 multi-temporal imagery. Comput. Electron. Agric. 2023, 213, 108262. [Google Scholar] [CrossRef]
- Xu, S.; Zhu, X.; Chen, J.; Zhu, X.; Duan, M.; Qiu, B.; Wan, L.; Tan, X.; Xu, Y.N.; Cao, R. A robust index to extract paddy fields in cloudy regions from SAR time series. Remote Sens. Environ. 2023, 285, 113374. [Google Scholar] [CrossRef]
- Cai, Y.; Liu, Z.; Meng, X.; Wang, S.; Gao, H. Rice extraction from multi-source remote sensing images based on HRNet and self-attention mechanism. Trans. Chin. Soc. Agric. Eng. 2024, 40, 186–193. [Google Scholar]
- Alami Machichi, M.; Mansouri, L.E.; Imani, Y.; Bourja, O.; Lahlou, O.; Zennayi, Y.; Bourzeix, F.; Hanade Houmma, I.; Hadria, R. Crop mapping using supervised machine learning and deep learning: A systematic literature review. Int. J. Remote Sens. 2023, 44, 2717–2753. [Google Scholar] [CrossRef]
- Yang, L.; Huang, R.; Huang, J.; Lin, T.; Wang, L.; Mijiti, R.; Wei, P.; Tang, C.; Shao, J.; Li, Q.; et al. Semantic Segmentation Based on Temporal Features: Learning of Temporal-Spatial Information from Time-Series SAR Images for Paddy Rice Mapping. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Thorp, K.R.; Drajat, D. Deep machine learning with Sentinel satellite data to map paddy rice production stages across West Java, Indonesia. Remote Sens. Environ. 2021, 265, 112679. [Google Scholar] [CrossRef]
- Wang, M.; Wang, J.; Chen, L. Mapping Paddy Rice Using Weakly Supervised Long Short-Term Memory Network with Time Series Sentinel Optical and SAR Images. Agriculture 2020, 10, 483. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Sun, C.; Zhang, H.; Xu, L.; Ge, J.; Jiang, J.; Zuo, L.; Wang, C. Twenty-meter annual paddy rice area map for mainland Southeast Asia using Sentinel-1 synthetic-aperture-radar data. Earth Syst. Sci. Data 2023, 15, 1501–1520. [Google Scholar] [CrossRef]
- Xu, Y.; Zhou, J.; Zhang, Z. A new Bayesian semi-supervised active learning framework for large-scale crop mapping using Sentinel-2 imagery. ISPRS J. Photogramm. Remote Sens. 2024, 209, 17–34. [Google Scholar] [CrossRef]
- Liu, Y.X.; Zhang, B.; Wang, B. Semi-supervised semantic segmentation based on Generative Adversarial Networks for remote sensing images. J. Infrared Millim Waves 2020, 39, 473–482. [Google Scholar]
- Liu, B.; Yu, X.; Zhang, P.; Tan, X.; Yu, A.; Xue, Z. A semi-supervised convolutional neural network for hyperspectral image classification. Remote Sens. Lett. 2017, 8, 839–848. [Google Scholar] [CrossRef]
- Hung, W.C.; Tsai, Y.H.; Liou, Y.T.; Lin, Y.Y.; Yang, M.H. Adversarial Learning for Semi supervised Semantic Segmentation. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Sajun, A.R.; Zualkernan, I. Survey on Implementations of Generative Adversarial Networks for Semi-Supervised Learning. Appl. Sci. 2022, 12, 1718. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016. [Google Scholar]
- Wang, L.; Jin, H.; Wang, C.; Sun, R. Backscattering characteristics and texture information analysis of typical crops based on synthetic aperture radar: A case study of Nong’an County, Jilin Province. Chin. J. Eco-Agric. 2019, 27, 1385–1393. [Google Scholar]
- Li, X.; Chen, G.; Liu, J.; Chen, W.; Cheng, X.; Liao, Y. Effects of RapidEye imagery’s red-edge band and vegetation indices on land cover classification in an arid region. Chin. Geogr. Sci. 2017, 27, 827–835. [Google Scholar] [CrossRef]
- Alaeddine, H.; Jihene, M. Wide deep residual networks in networks. Multimed. Tools Appl. 2023, 82, 7889–7899. [Google Scholar] [CrossRef]
- Nakayama, Y.; Lu, H.; Li, Y.; Kim, H. Wide Residual Networks for Semantic Segmentation. In Proceedings of the 18th International Conference on Control, Automation and Systems (ICCAS), PyeongChang, Republic of Korea, 17–20 October 2018. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 30th Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 16th International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, Y.; Liu, G.; Liao, J. SAR and panchromatic image fusion algorithm based on empirical mode decomposition. Comput. Appl. Softw. 2016, 33, 177–180. [Google Scholar]
- Liu, W.; Yang, J.; Zhao, J.; Guo, F. A Dual-Domain Super-Resolution Image Fusion Method with SIRV and GALCA Model for PolSAR and Panchromatic Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Seo, D.K.; Eo, Y.D. A Learning-Based Image Fusion for High-Resolution SAR and Panchromatic Imagery. Appl. Sci. 2020, 10, 3298. [Google Scholar] [CrossRef]
- Li, S.T.; Li, C.Y.; Kang, X.D. Development status and future prospects of multi-source remote sensing image fusion. Natl. Remote Sens. Bull. 2021, 25, 148–166. [Google Scholar] [CrossRef]
- He, Y.; Liu, Y.; Tan, D.; Zhang, Y.; Zhang, C.; Sun, S.; Ding, Z.; Jiang, Q. Development Status and Prospect of Semantic Segmentation of Multi-source Remote Sensing Images. Mod. Radar 2024, 46, 16–24. [Google Scholar]
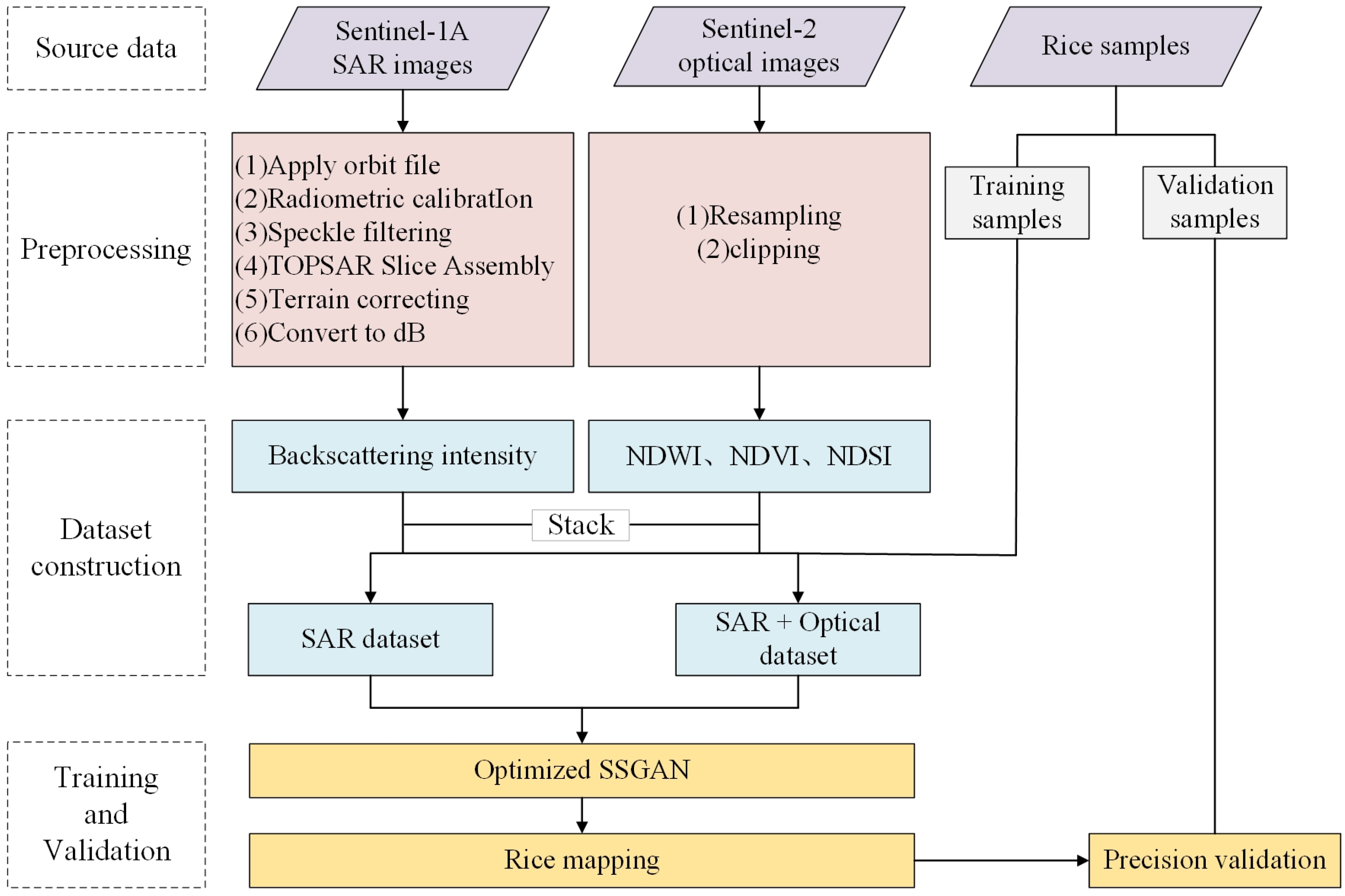
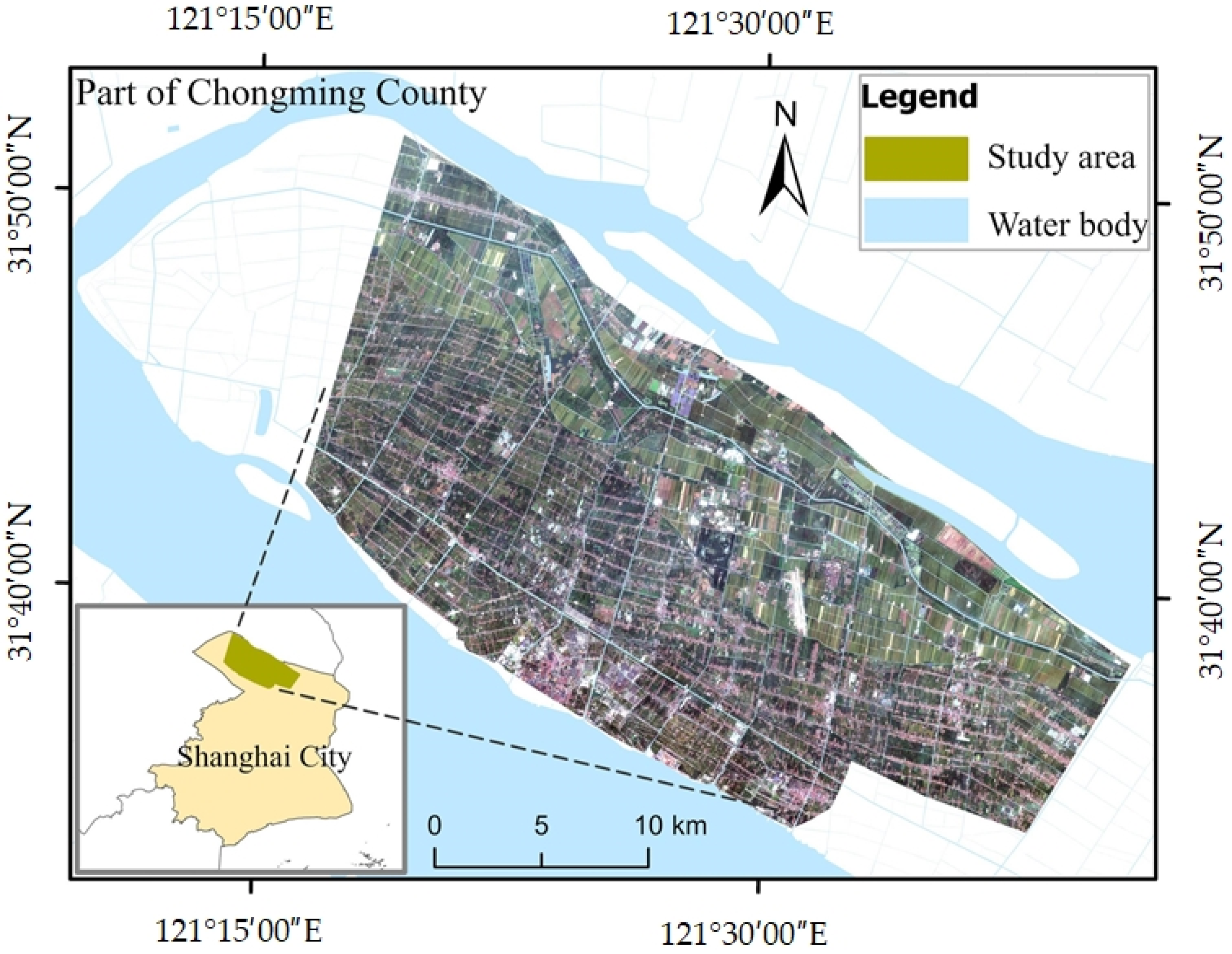
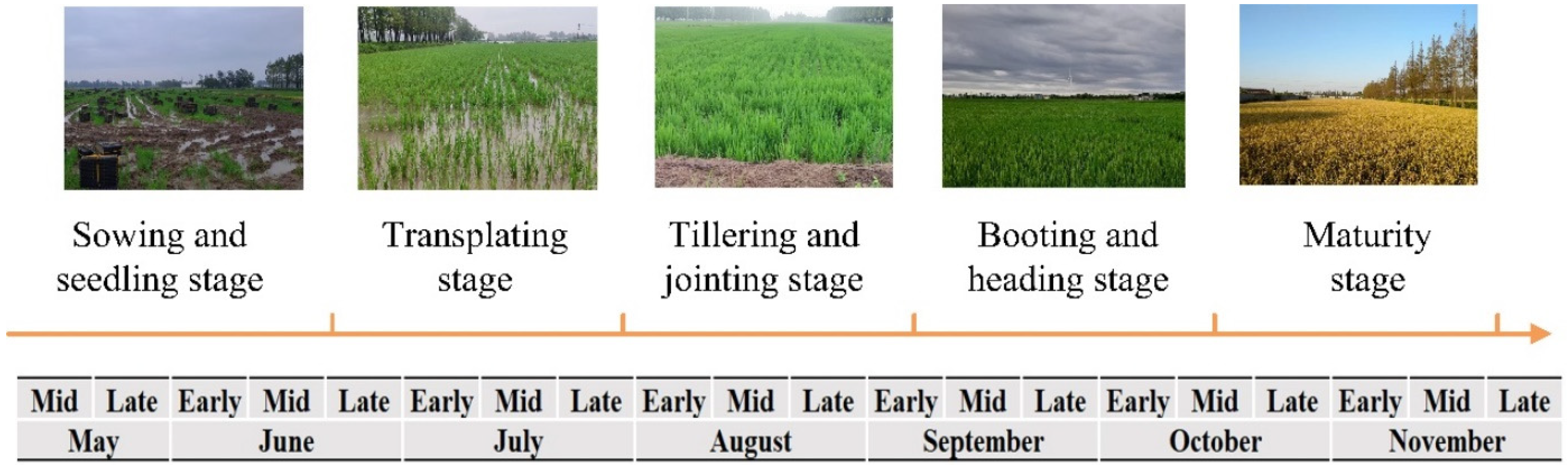
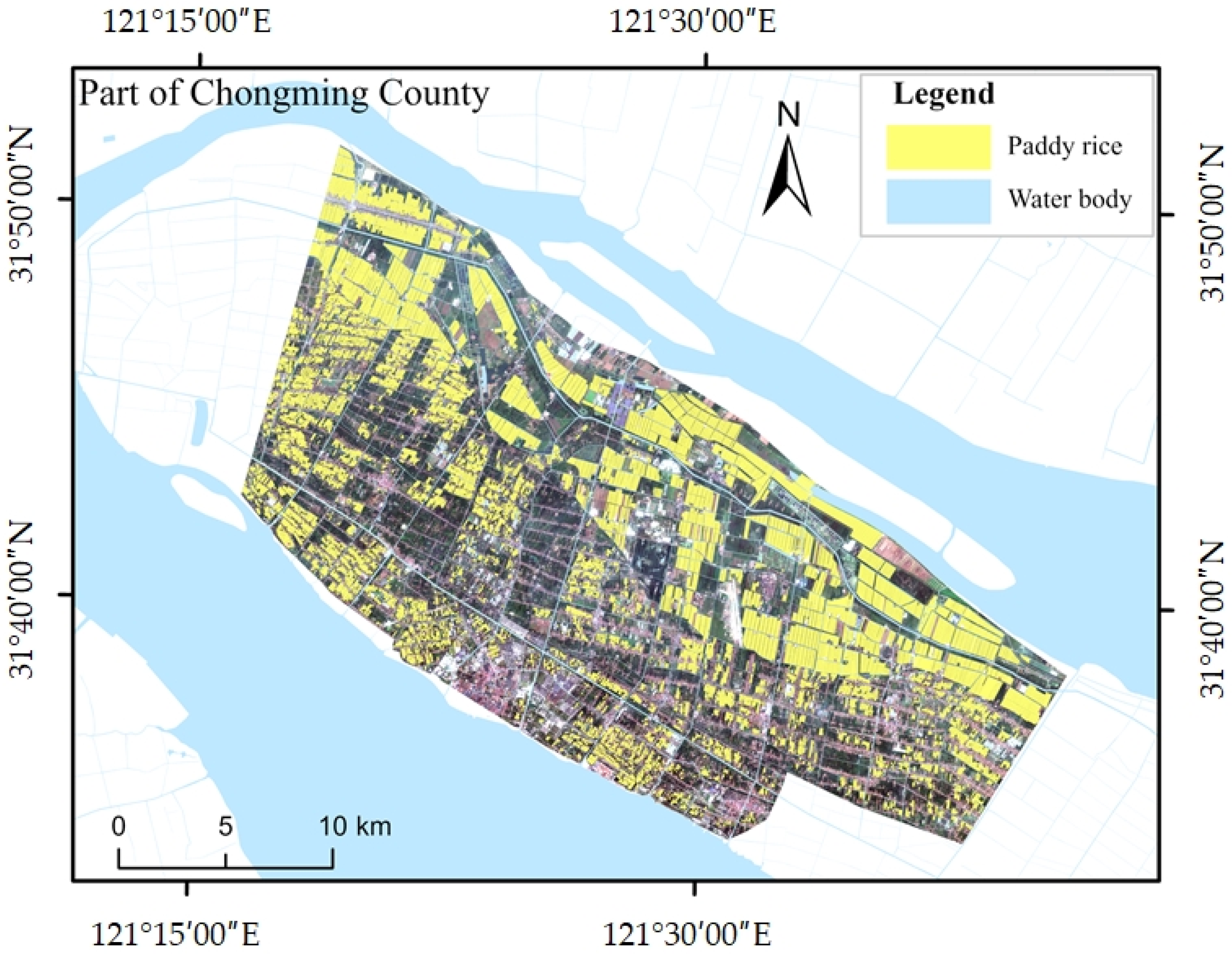
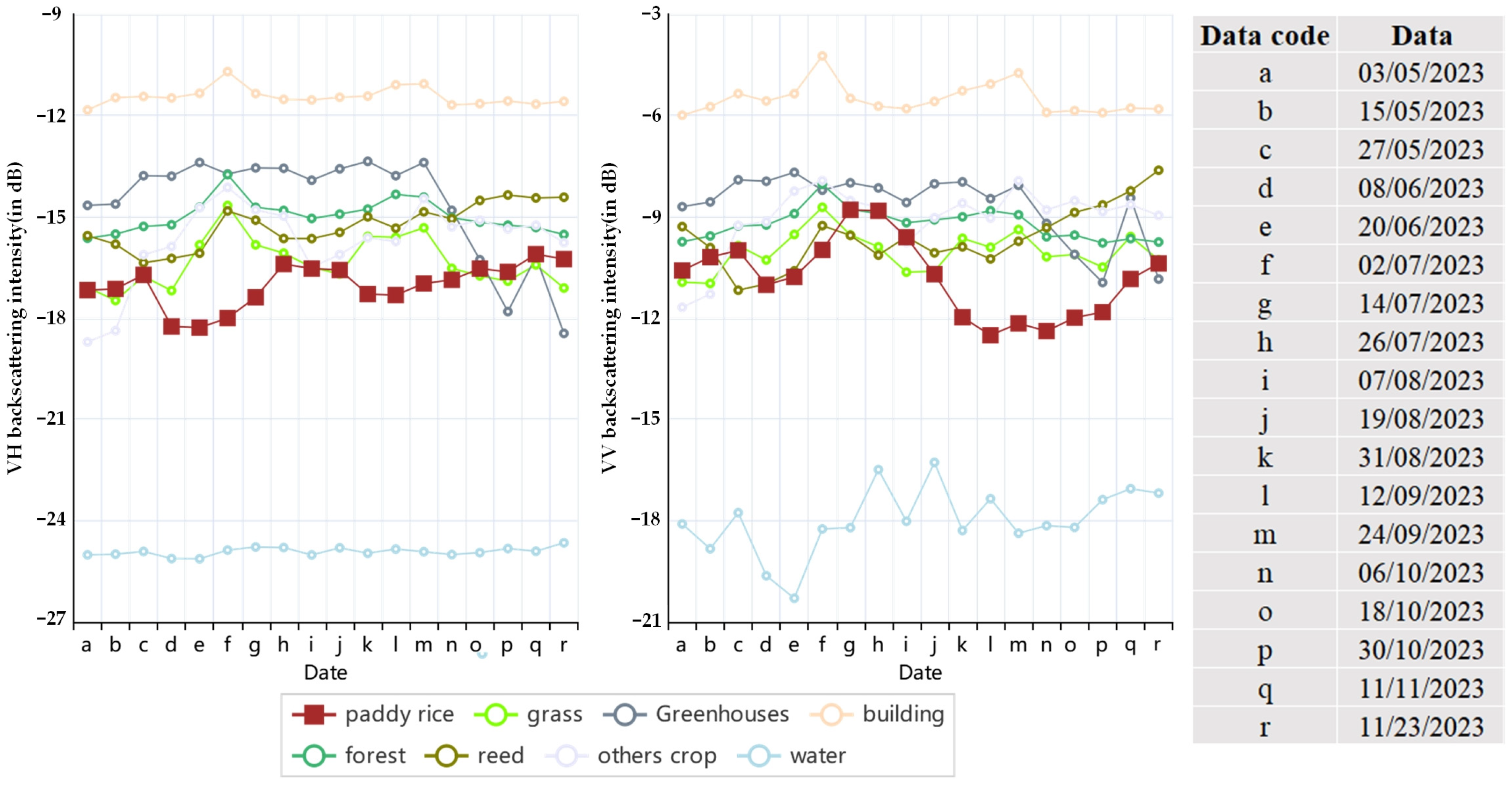
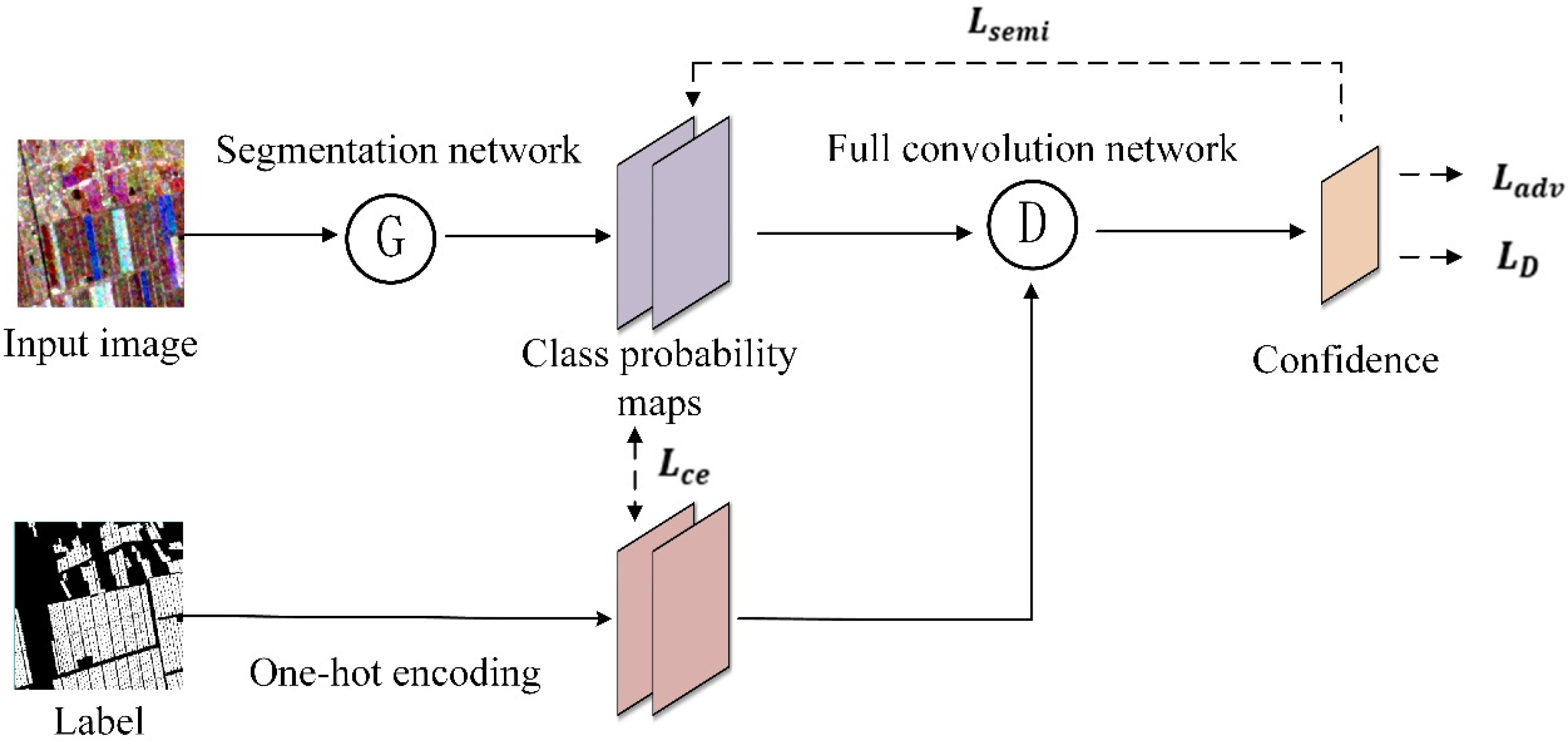
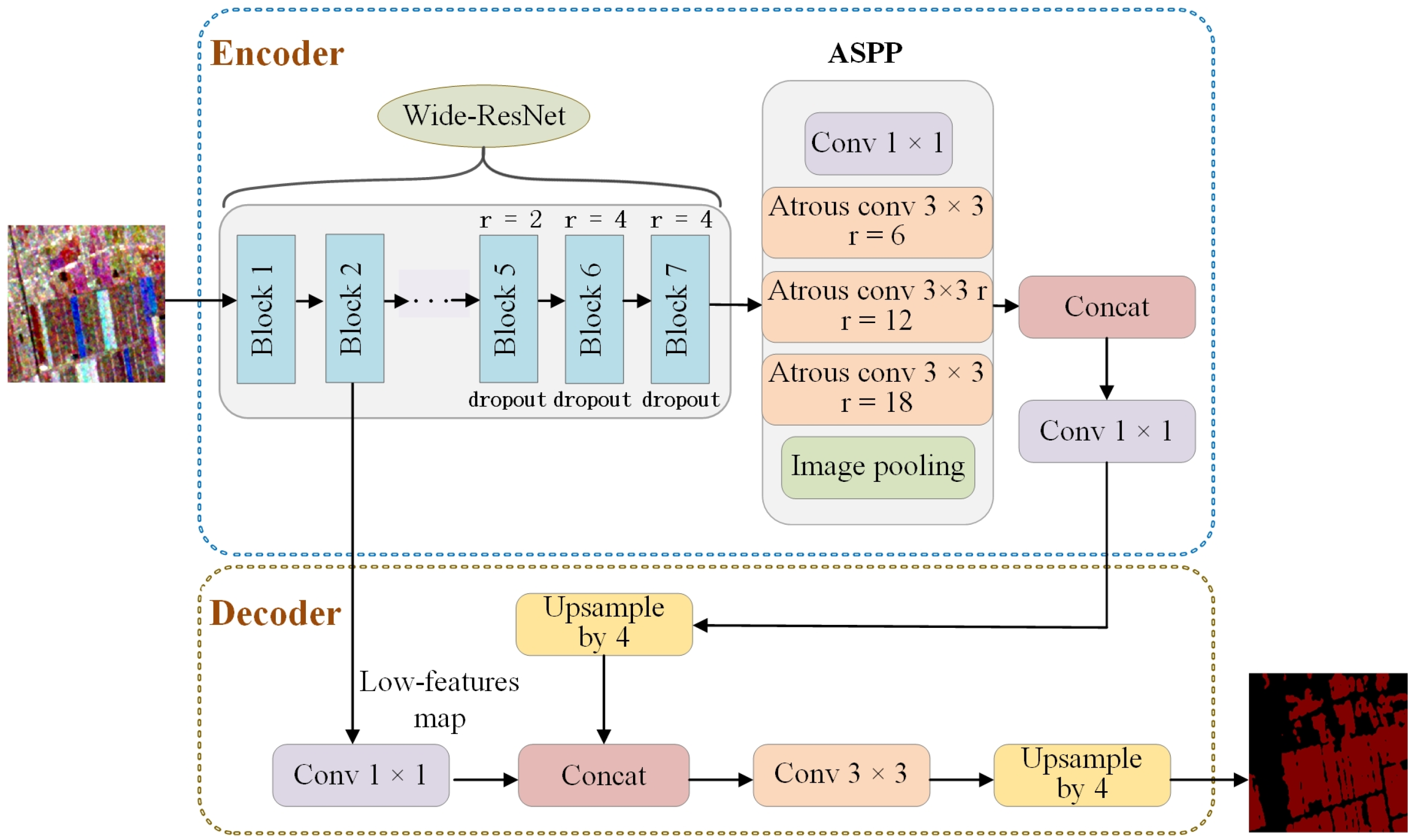
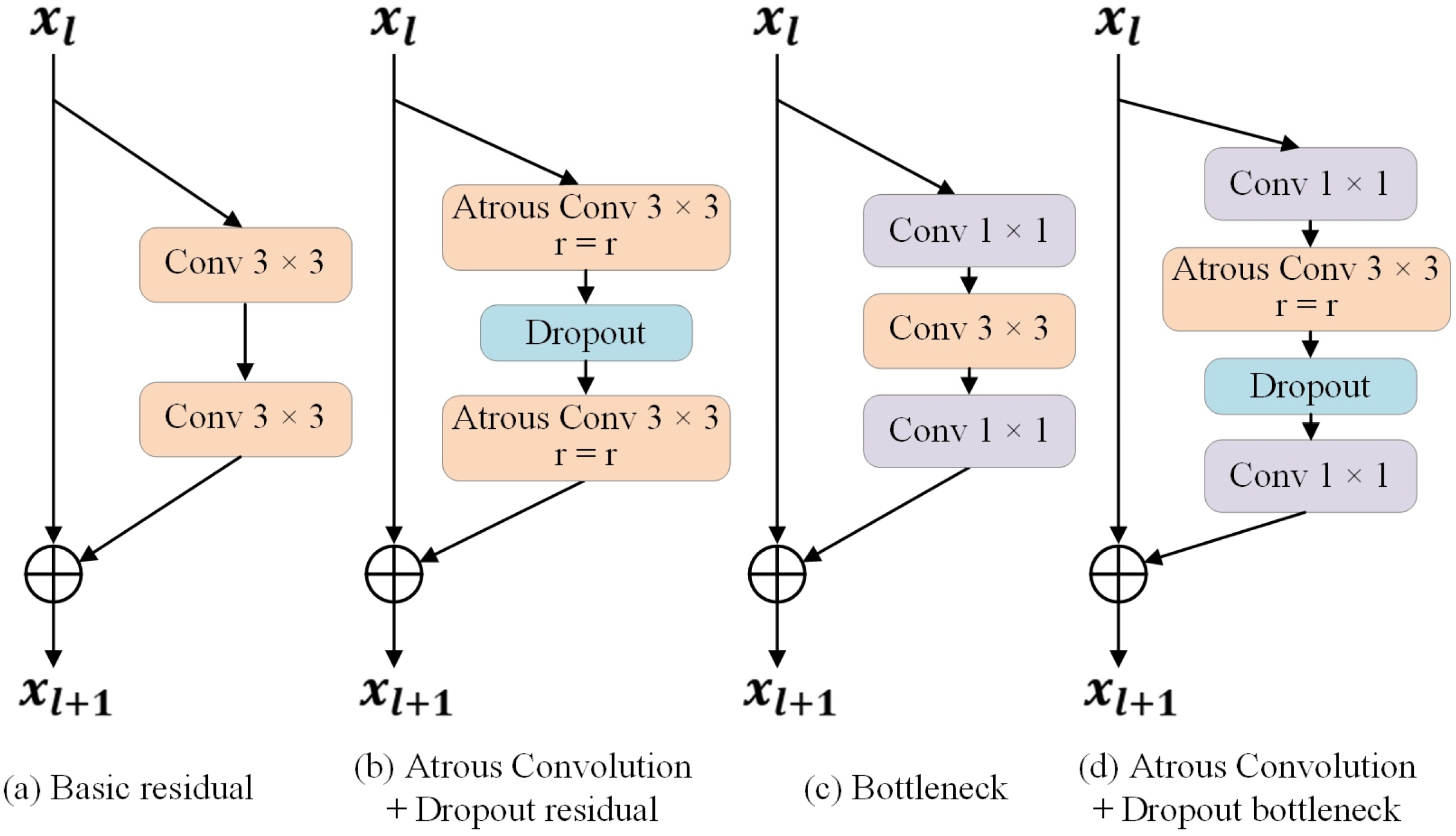

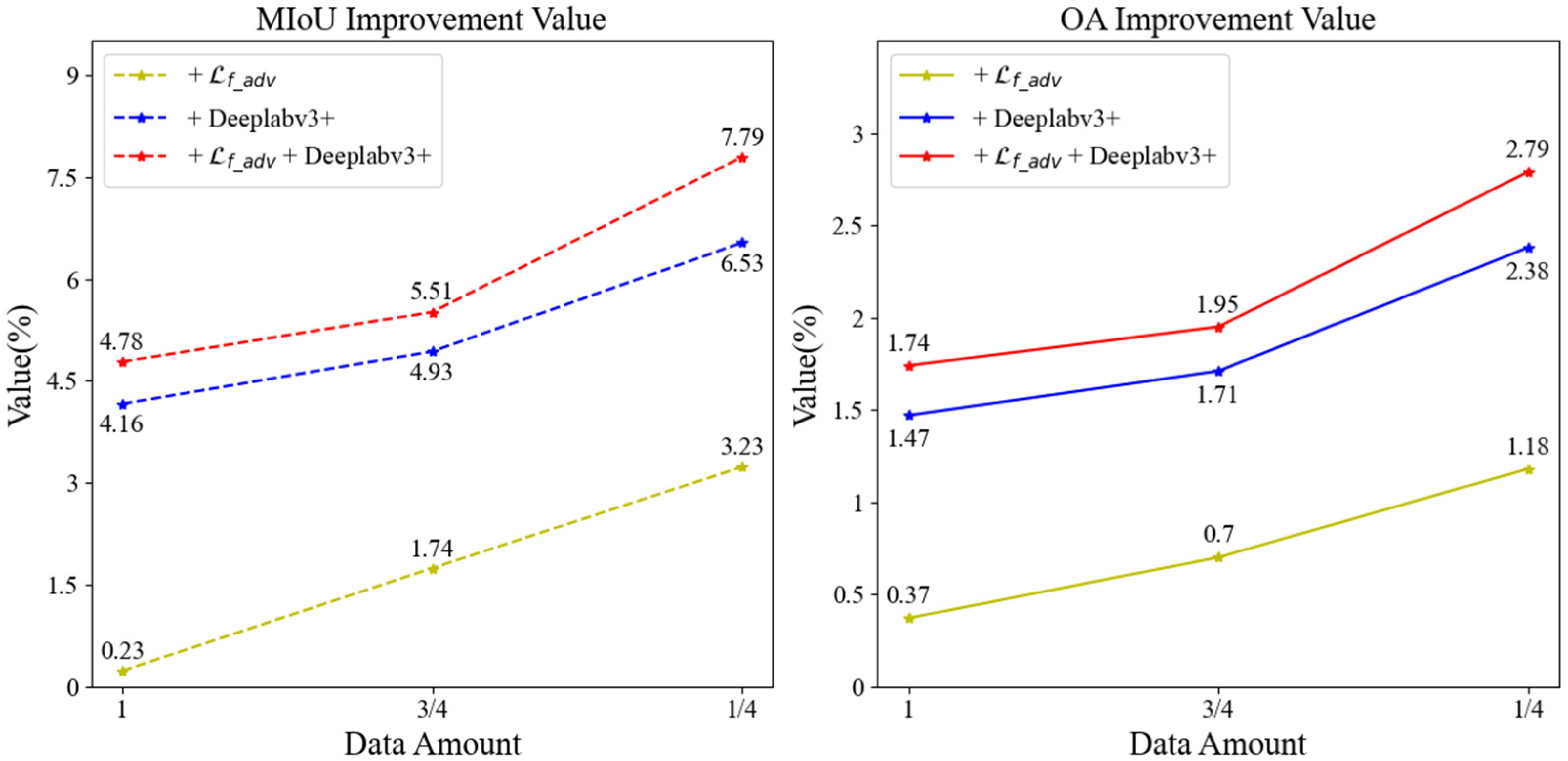
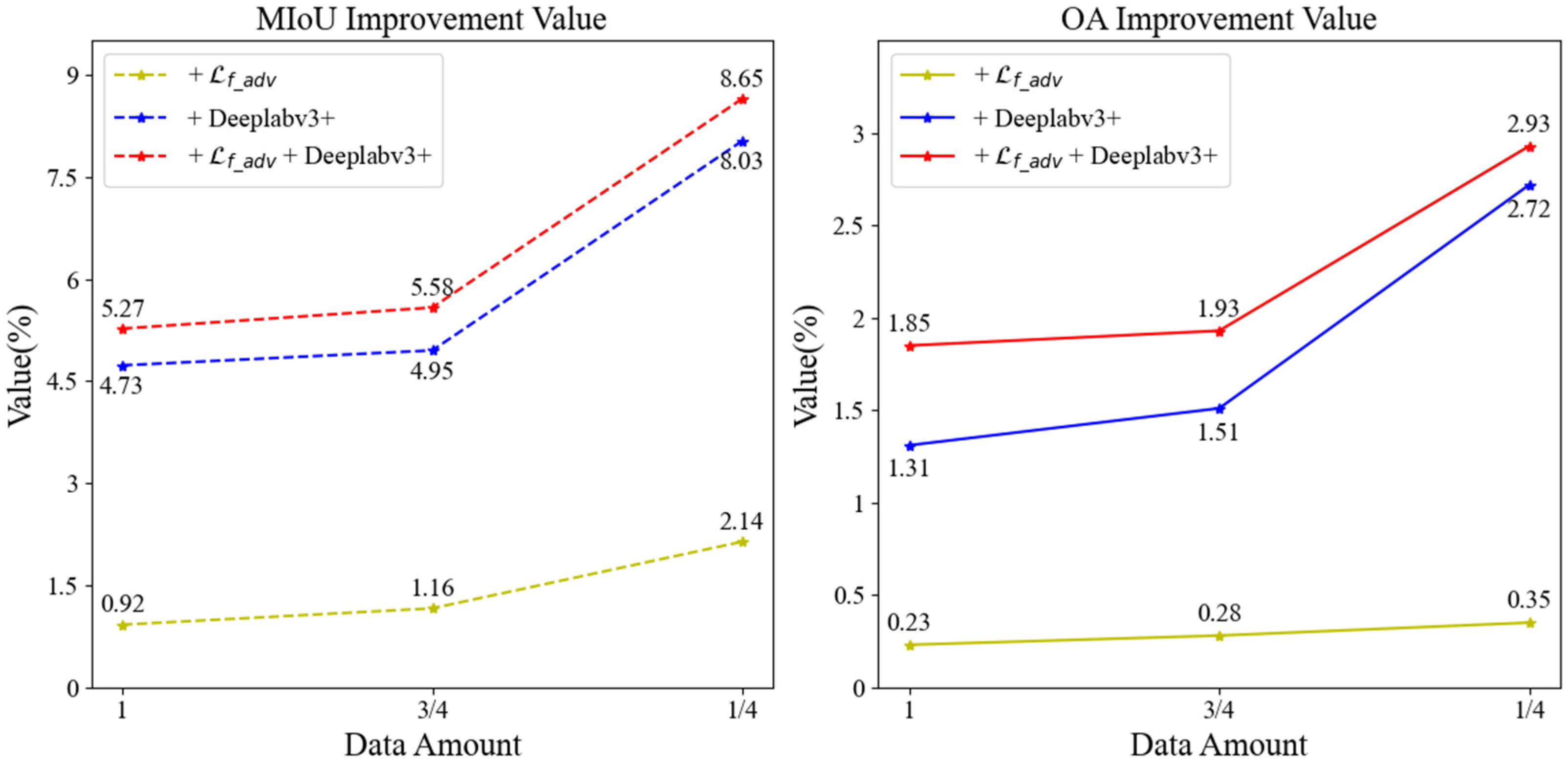
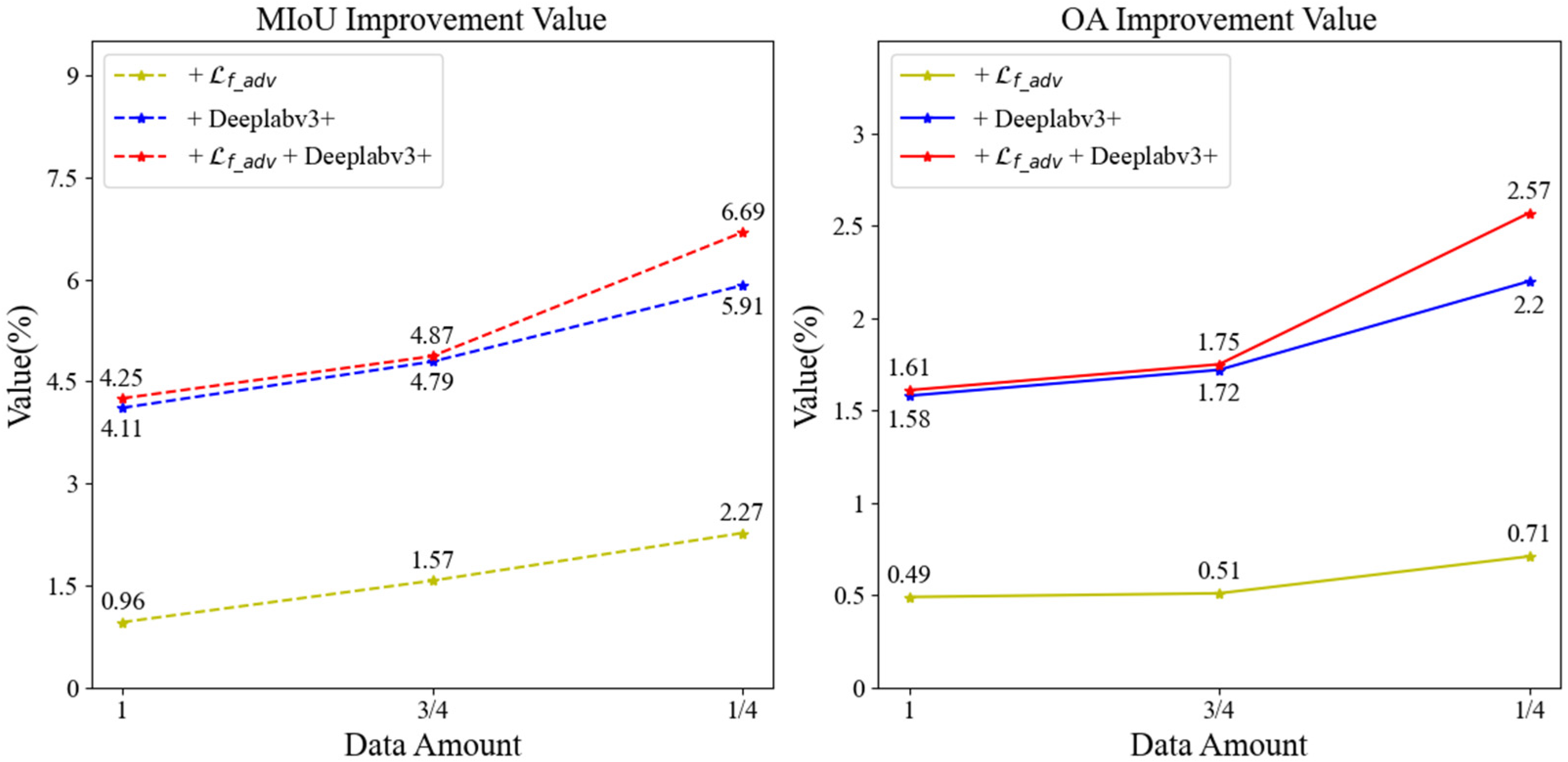
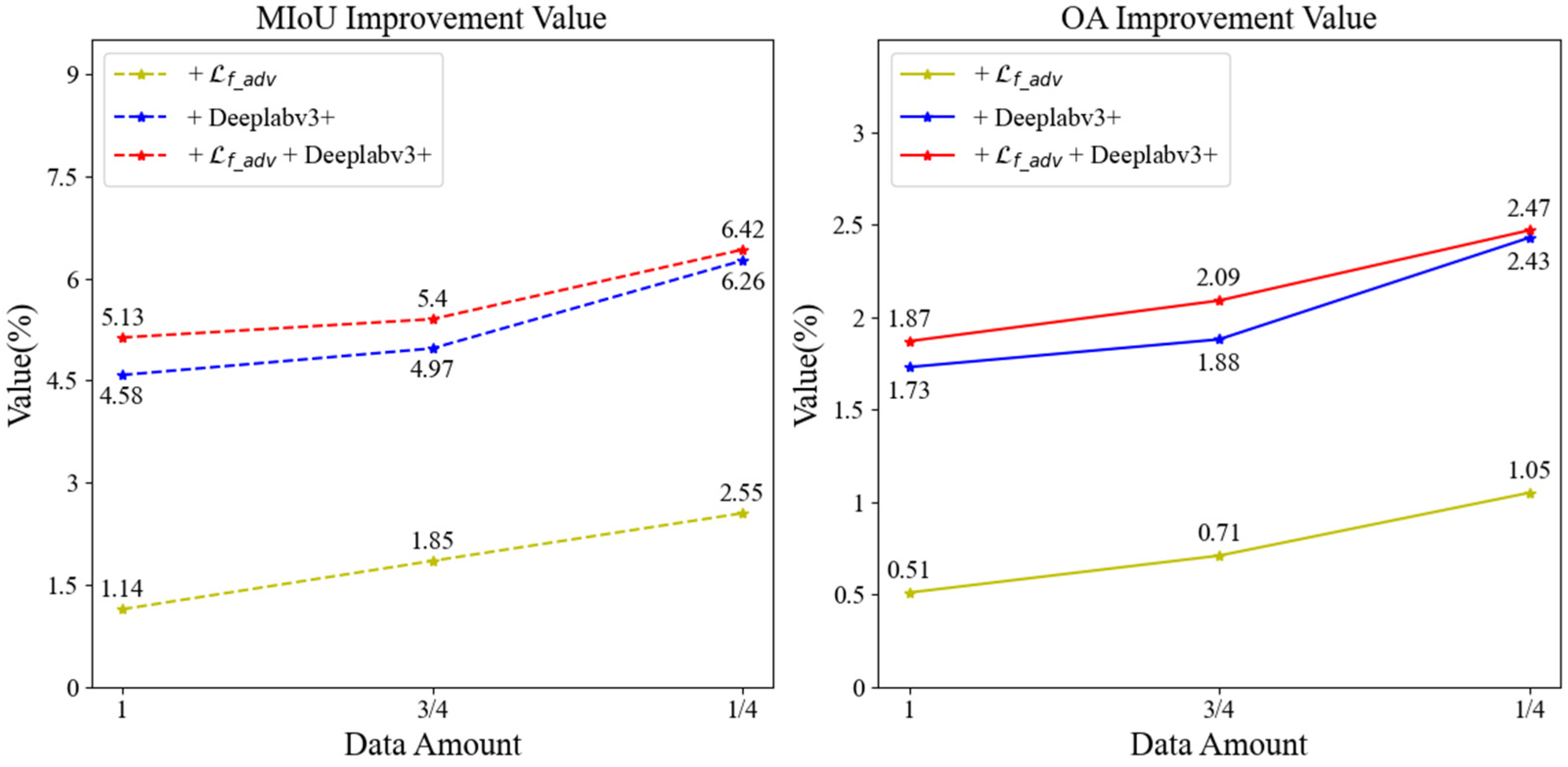

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).