

Segmentation Method of Zanthoxylum bungeanum Cluster Based on Improved Mask R-CNN

Abstract
1. Introduction
- (1)
- The Swin-Transformer network was utilized as the backbone feature extraction network, expanding the model’s receptive field and improving its feature extraction ability.
- (2)
- The SK attention mechanism was utilized to fuse detailed information from the low-level feature map of FPN into the mask branch to supplement image detail features and improve the segmentation accuracy.
- (3)
- The DIOU loss function was applied to replace the original bounding box loss function SmoothL1, enhancing the model’s convergence speed and accuracy.
2. Materials and Methods
2.1. Image Acquisition and Augmentation
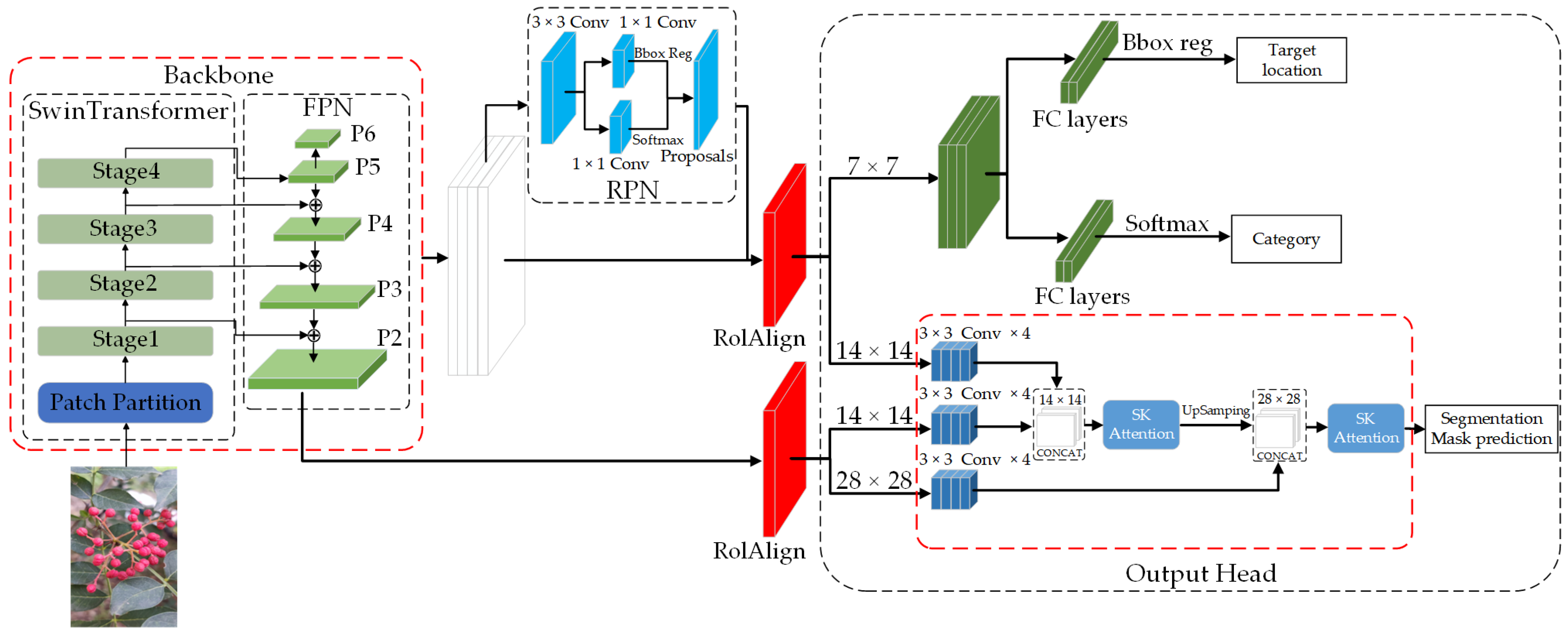
2.2. Overview of the Baseline Mask R-CNN Model
- (1)
- The backbone first employs the feature extraction network of ResNet50 to extract feature maps C1–C5 of different scales. Then, the feature pyramid network (FPN) performs feature fusion on these feature maps, generating fused feature maps P2–P6. P2, the low-level feature map of FPN, has the highest resolution and contains rich detailed information. However, the high-level feature maps with lower resolutions mainly contain semantic information.
- (2)
- The feature maps are input into the RPN, where anchor boxes are generated to extract regions that may contain target information, generating proposal boxes of varying sizes.
- (3)
- ROIAlign adjusts the proposal boxes of various sizes generated by the RPN to uniform sizes (7 × 7, 14 × 14).
- (4)
- The feature maps of uniform size are input into the output head, comprising two branches: an object detection branch and a mask segmentation branch. The object detection branch employs Fully Connected (FC) layers to detect and localize the objects, while the mask segmentation branch applies the Fully Convolutional Network (FCN) to segment the targeted objects.
2.3. Improved Mask R-CNN Model
2.3.1. Swin-Transformer Feature Extraction Network
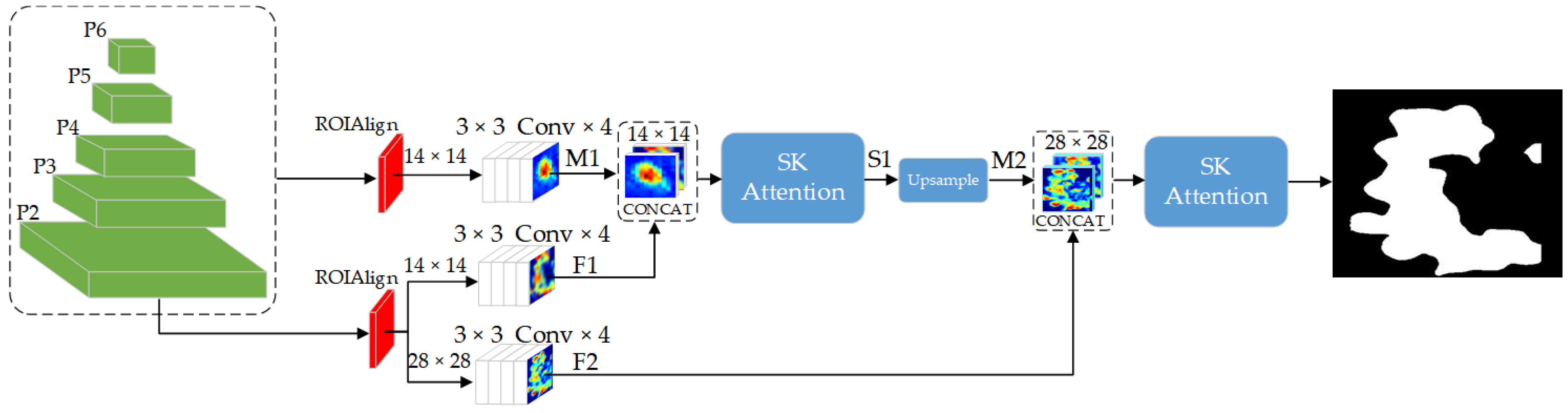
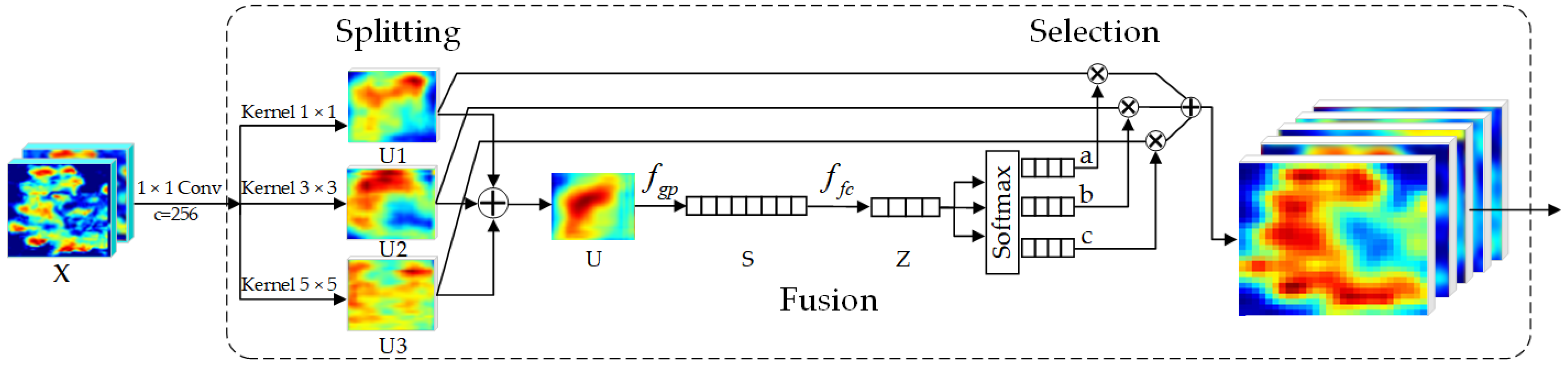
2.3.2. Mask Branch Improvement
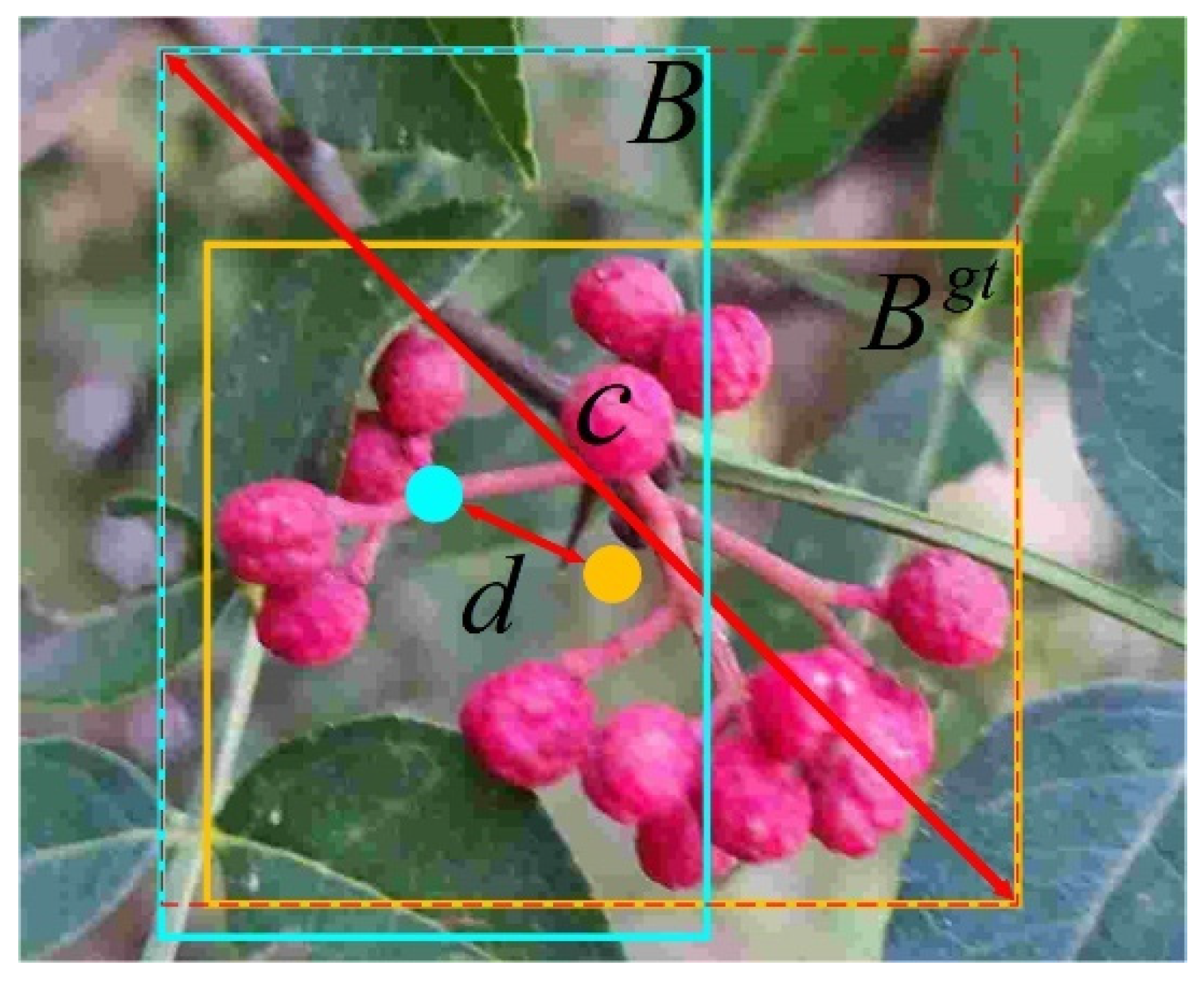
2.3.3. Loss Function
2.4. Experimental Setup
2.5. Model Evaluation
3. Results and Discussion
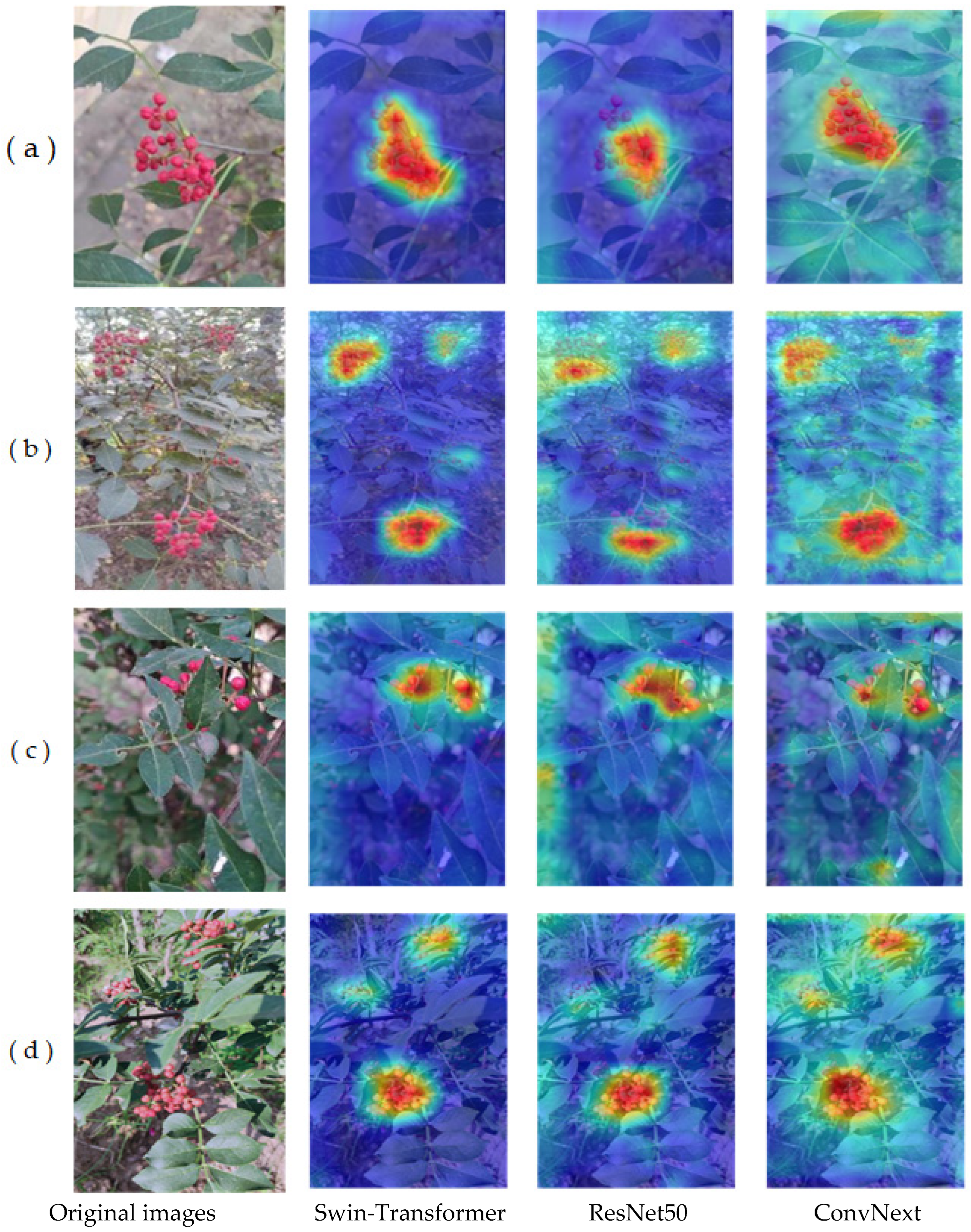
3.1. The Effect of Different Backbone Feature Extraction Networks
3.2. The Effect of Different Attention Mechanisms for Mask Branch Improvement
3.3. The Effect of Different Loss Functions
3.4. Ablation Experiment
3.5. Comparison Experiments of Different Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ke, J.; Wang, Y.; Luo, T.; Yu, L.; Wang, X.; Ma, Y.; Lei, Z.; Zhang, Z. Study on the effect of different bitter masking inhibitors on the bitter masking of Zanthoxylum bungeanum Maxim. Int. J. Gastron. Food Sci. 2024, 35, 100894. [Google Scholar] [CrossRef]
- Liang, W.; Yang, H.; Lei, H.; Xiang, Z.; Duan, Y.; Xin, H.; Han, T.; Su, J. Phytochemistry and health functions of Zanthoxylum bungeanum Maxim and Zanthoxylum schinifolium Sieb. et zucc as pharma-foods: A systematic review. Trends Food Sci. Tech. 2024, 143, 104225. [Google Scholar] [CrossRef]
- Liu, A.; Wei, Q.; Cui, X.; Wang, Q.; Han, G.; Gao, S. Current situation and research progress on fruit picking of Zanthoxylum bungeanum Maxim. J. Chin. Agric. Mech. 2019, 40, 85–87. [Google Scholar]
- Matsui, T.; Sugimori, H.; Koseki, S.; Kento, K. Automated detection of internal fruit rot in hass avocado via deep learning-based semantic segmentation of X-ray images. Postharvest Biol. Tec. 2023, 203, 112390. [Google Scholar] [CrossRef]
- Wang, C.; Tang, Y.; Zou, X.; Weiming, S.; Feng, W. A robust fruit image segmentation algorithm against varying illumination for vision system of fruit harvesting robot. Optik 2017, 131, 626–631. [Google Scholar] [CrossRef]
- Xiang, R.; Ying, Y.; Jiang, H. Development of real-time recognition and localization methods for fruits and vegetables in field. Trans. Chin. Soc. Agric. Mech. 2013, 44, 208–223. [Google Scholar]
- Hu, T.; Wang, W.; Gu, J.; Xia, Z.; Zhang, J.; Wang, B. Research on Apple Object Detection and Localization Method Based on Improved YOLOX and RGB-D Images. Agronomy 2023, 13, 1816. [Google Scholar] [CrossRef]
- Payne, A.B.; Walsh, K.B.; Subedi, P.P.; Jarvis, D. Estimation of mango crop yield using image analysis—Segmentation method. Comput. Electron. Agric. 2013, 91, 57–64. [Google Scholar] [CrossRef]
- Lv, J.; Wang, F.; Xu, L.; Ma, Z.; Yang, B. A segmentation method of bagged green apple image. Sci. Hortic. 2019, 246, 411–417. [Google Scholar] [CrossRef]
- Malik, M.H.; Zhang, T.; Li, H.; Zhang, M.; Shabbir, S.; Ahmed, S. Mature tomato fruit detection algorithm based on improved HSV and watershed algorithm. IFAC-Pap. 2018, 51, 431–436. [Google Scholar] [CrossRef]
- Song, L.; Shu, T.; Zhou, D.; Ahmed, S. Application of Canny edge detection based on ultra-fuzzy set in Zanthoxylum bungeanum Maxim images. J. Chongqing Technol. Bus. Univ. 2016, 33, 38–42. [Google Scholar]
- Qi, R.; Chen, M.; Yang, Z.; Ding, M. Image segmentation of Sichuan pepper based on HSV model and improved OTSU algorithm. J. Chin. Agric. Mech. 2019, 40, 155–160. [Google Scholar]
- Wan, F.; Bai, M.; He, Z.; Huang, X. Identification of Chinese prickly ash under the natural scenes. J. Chin. Agric. Mech. 2016, 37, 115–119. [Google Scholar]
- Huang, P.; Zheng, Q.; Liang, C. Overview of Image Segmentation Methods. J. Wuhan Univ. 2020, 66, 519–531. [Google Scholar]
- Luo, Z.; Yang, W.; Yuan, Y.; Gou, R.; Li, X. Semantic segmentation of agricultural images: A survey. Inf. Process. Agric. 2024, 11, 172–186. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, F.; Zou, X.; Meng, H.; Zhang, Y.; Luo, X. Method for locating picking points of grape clusters using multi-object recognition. Trans. Chin. Soc. Agric. Eng. 2023, 39, 166–177. [Google Scholar]
- Zhong, Z.; Xiong, J.; Zheng, Z.; Liu, B.; Liao, S.; Huo, Z.; Yang, Z. A method for litchi picking points calculation in natural environment based on main fruit bearing branch detection. Comput. Electron. Agric. 2021, 189, 106398. [Google Scholar] [CrossRef]
- Zhuang, O.; Wang, Z.; Wu, L.; Li, K.; Wang, C. Image segmentation method of plug seedlings based on improved SOL0v2. J. Nanjing Agric. Univ. 2023, 46, 200–209. [Google Scholar]
- Liu, W.; Ye, T.; Li, X. Tomato Leaf Disease Detection Method Based on Improved SOLO v2. Trans. Chin. Soc. Agric. Mech. 2021, 52, 213–220. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Pérez-Borrero, I.; Marín-Santos, D.; Gegúndez-Arias, M.E.; Cortés-Ancos, E. A fast and accurate deep learning method for strawberry instance segmentation. Comput. Electron. Agric. 2020, 178, 105736. [Google Scholar] [CrossRef]
- Jia, W.; Tian, Y.; Luo, R.; Zhang, Z.; Lian, J.; Zheng, Y. Detection and segmentation of overlapped fruits based on optimized mask R-CNN application in apple harvesting robot. Comput. Electron. Agric. 2020, 172, 105380. [Google Scholar] [CrossRef]
- Long, J.; Zhao, C.; Lin, S.; Guo, W.; Wen, C.; Zhang, Y. Segmentation method of the tomato fruits with different maturities under greenhouse environment based on improved Mask R-CNN. Trans. Chin. Soc. Agric. Eng. 2021, 37, 100–108. [Google Scholar]
- Liang, X.; Zhang, X.; Wang, Y. Recognition method for the pruning points of tomato lateral branches using improved Mask R-CNN. Trans. Chin. Soc. Agric. Eng. 2022, 38, 112–120. [Google Scholar]
- Bai, Z.; Lv, Y.; Zhu, Y.; Ma, Y.; Duan, E. Dead duck recognition algorithm based on improved Mask R-CNN. Trans. Chin. Soc. Agric. Mech. 2024, 1–10. Available online: https://link.cnki.net/urlid/11.1964.S.20240511.0922.002 (accessed on 1 September 2024).
- Zhang, G.; Lu, X.; Tan, J.; Li, J.; Zhang, Z.; Li, Q.; Hu, X. RefineMask: Towards high-quality instance segmentation with fine-grained features. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops, Nashville, TN, USA, 11–17 October 2021; pp. 6856–6857. [Google Scholar]
- Wang, X.; Wu, Z.; Fang, C. TeaPoseNet: A deep neural network for tea leaf pose recognition. Comput. Electron. Agric. 2024, 225, 109278. [Google Scholar] [CrossRef]
- Shi, J.; Bai, Y.; Zhou, J.; Zhang, B. Multi-Crop Navigation Line Extraction Based on Improved YOLO-v8 and Threshold-DBSCAN under Complex Agricultural Environments. Agriculture 2024, 14, 45. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Wang, W.; Zhao, R. Fine-grained instance segmentation of clothing images based on improved Mask R-CNN. Wool Text. J. 2023, 51, 88–94. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Zi, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and better learning for bounding box regression. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Wang, H.; Li, Y.; Dang, L.M.; Moon, H. An efficient attention module for instance segmentation network in pest monitoring. Comput. Electron. Agric. 2022, 195, 106853. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extraction Networks | (%) | (%) | Parameters (M) | Time (s/Image) |
|---|---|---|---|---|
| The baseline Mask R-CNN (ResNet50) | 78.2 | 72.6 | 43.97 | 0.137 |
| ConvNext | 81.3 | 73.8 | 47.67 | 0.139 |
| Swin-Transformer | 82.6 | 75.2 | 47.37 | 0.138 |
| Attention Mechanisms | (%) | (%) | Parameters (M) | Time (s/Image) |
|---|---|---|---|---|
| The baseline Mask R-CNN | 78.2 | 72.6 | 43.97 | 0.137 |
| SK | 82.2 | 74.9 | 48.58 | 0.187 |
| CA | 79.8 | 73.6 | 47.22 | 0.184 |
| CBAM | 79.4 | 73.5 | 47.65 | 0.185 |
| Loss Functions | (%) | (%) | Parameters (M) | Time (s/Image) |
|---|---|---|---|---|
| The baseline Mask R-CNN (SmoothL1) | 78.2 | 72.6 | 43.97 | 0.137 |
| SIOU | 80.6 | 72.4 | 43.97 | 0.137 |
| GIOU | 80.6 | 71.6 | 43.97 | 0.137 |
| CIOU | 80.3 | 71.5 | 43.97 | 0.137 |
| DIOU | 81.4 | 73.0 | 43.97 | 0.137 |
| Group | Swin- Transformer | Mask Branch Improvement | DIOU | (%) | (%) | Parameters (M) | Time (s/Image) |
|---|---|---|---|---|---|---|---|
| 1 | × | × | × | 78.2 | 72.6 | 43.97 | 0.137 |
| 2 | √ | × | × | 82.6 | 75.2 | 47.37 | 0.138 |
| 3 | × | √ | × | 82.2 | 74.9 | 48.58 | 0.187 |
| 4 | × | × | √ | 81.4 | 73.0 | 43.97 | 0.137 |
| 5 | √ | √ | √ | 84.0 | 77.2 | 50.32 | 0.189 |
| Models | (%) | (%) | Parameters (M) | Time (s/Image) |
|---|---|---|---|---|
| YOLACT | 81.0 | 71.3 | 34.73 | 0.127 |
| Mask Scoring R-CNN | 82.7 | 73.5 | 60.31 | 0.137 |
| SOLOv2 | - | 68.4 | 46.54 | 0.186 |
| Improved Mask R-CNN | 84.0 | 77.2 | 50.32 | 0.189 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Wang, S.; Wang, C.; Wang, L.; Zhang, Y.; Song, H. Segmentation Method of Zanthoxylum bungeanum Cluster Based on Improved Mask R-CNN. Agriculture 2024, 14, 1585. https://doi.org/10.3390/agriculture14091585
Zhang Z, Wang S, Wang C, Wang L, Zhang Y, Song H. Segmentation Method of Zanthoxylum bungeanum Cluster Based on Improved Mask R-CNN. Agriculture. 2024; 14(9):1585. https://doi.org/10.3390/agriculture14091585
Chicago/Turabian StyleZhang, Zhiyong, Shuo Wang, Chen Wang, Li Wang, Yanqing Zhang, and Haiyan Song. 2024. "Segmentation Method of Zanthoxylum bungeanum Cluster Based on Improved Mask R-CNN" Agriculture 14, no. 9: 1585. https://doi.org/10.3390/agriculture14091585
APA StyleZhang, Z., Wang, S., Wang, C., Wang, L., Zhang, Y., & Song, H. (2024). Segmentation Method of Zanthoxylum bungeanum Cluster Based on Improved Mask R-CNN. Agriculture, 14(9), 1585. https://doi.org/10.3390/agriculture14091585