Istex: A Database of Twenty Million Scientific Papers with a Mining Tool Which Uses Named Entities


Abstract
:1. Introduction
1.1. Motivation
1.2. The Beginning of the Istex Project
1.3. The Current Situation of the Corpus of Acquired Document Resources
1.4. The Services Provided by the Istex Platform
- The PDF file;
- The publisher’s metadata;
- The standardized metadata in the MODS format;
- The XML display of the PDF in the TEI format;
- The document attachments (photos, graphs, etc.);
- The forms of enrichments.
1.5. Enrichment
2. Named Entity Recognition
2.1. Presentation
2.2. Unitex Software
- Insert, move or replace characters on the text processed;
- Compile rules and dictionaries as Finite-State Machines;
- Use variables instanced with a part of the text or with any characters;
- Work into a sequence of letters;
- Use regular expression;
- Build cascades of rules.
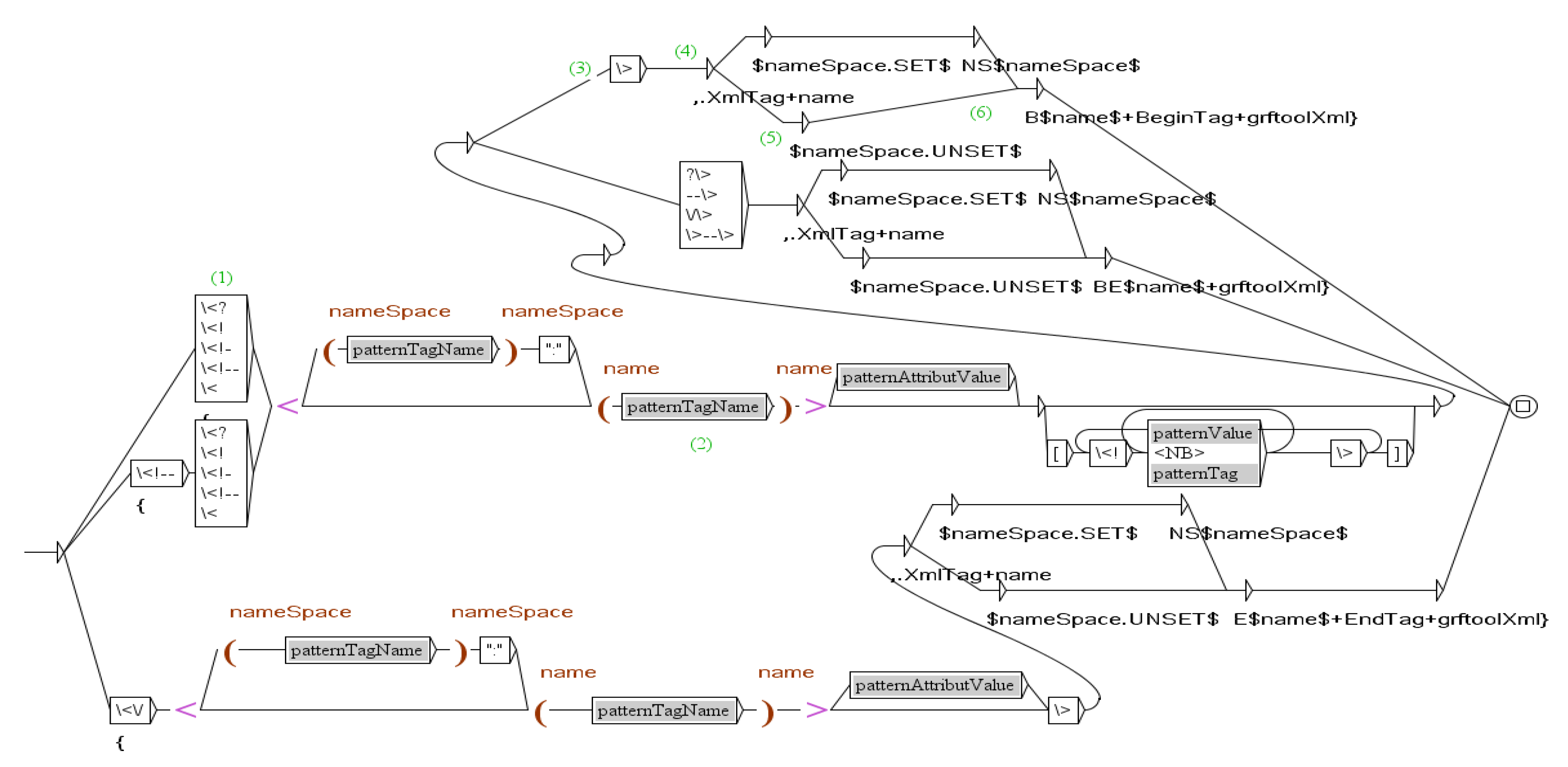
- (1):
- The first box recognizes "<" and merges "{" before "<publisher>";
- (2):
- The second box initialize the variable name with "publisher";
- (3):
- The third box recognizes ">";
- (4):
- The fourth box merges ",.XmlTag+name" after "<publisher>";
- (5):
- The fifth box tests if the variable nameSpace is instancied;
- (6):
- The sixth box concatenates "Bpublisher+BeginTag+grftoolXml}"to the precedent merging.
- {<publisher>,.XmlTag+nameBpublisher+BeginTag+grftoolXml}
- Springer-Verlag
- {</publisher>,.XmlTag+nameEpublisher+EndTag+grftoolXml}
2.3. NER with Unitex
- Preprocessing
- We research the beginning of the bibliography (i.e., the end of the text to analyze);
- We normalize the text (spaces, tabulations and line feeds; apostrophes, quotation marks, hyphens and ellipses);
- We tokenize the text (sequences of letters or single other characters);
- We apply dictionaries (common words, proper names and specific CasEN dictionaries).
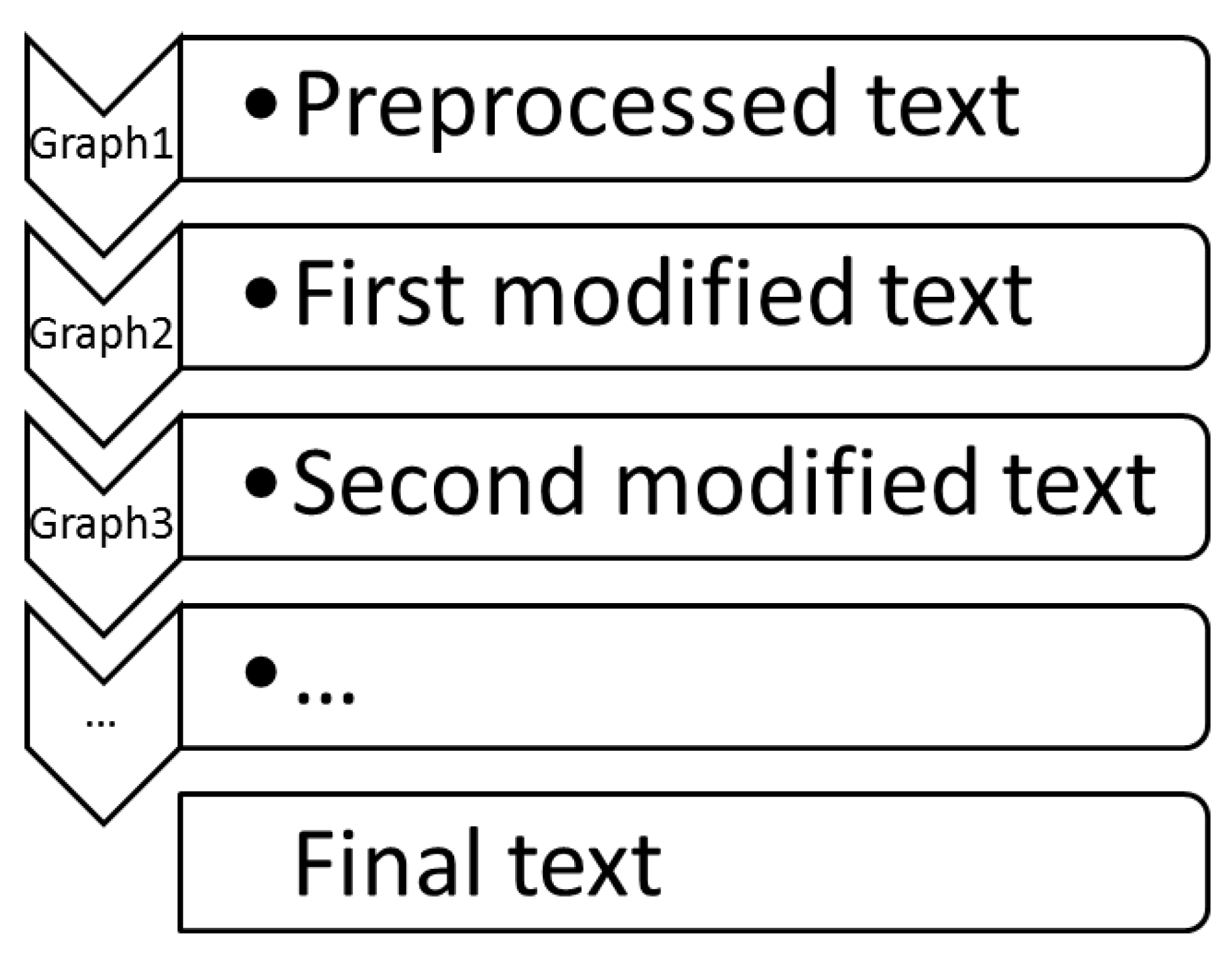
- Analysis: We apply the first subcascade in the defined order
- 10 tool graphs (XML tags, numbers, specific multiword units);
- Four amount graphs, 12 time graphs;
- Six person graphs, two product graphs, five organization graphs;
- Four location graphs, two event graphs, role graph, address graph;
- A reference graph, funder and provider graph (organizations with a specific role in the paper).
- Synthesis (the second subcascade)
- We transform the XML-CasSys file into a TEI file; (https://tei-c.org/)
- We customize it according to the target guide (Section 3.1).
- Counter (the third subcascade)
- We define the tags that we want to list and count;
- We build a standoff file (Section 3.2).
2.4. Evaluation
2.4.1. Evaluation Procedure
2.4.2. Results
3. NER Implementation at Inist
3.1. NER but for Which Entities?
- Names of persons: <persName>We thank Prof. <persName>Harry Green</persName> andDr <persName>Larissa Dobrzhinetskaya</persName> for assistance
- Administrative place names: <placeName>in northern <placeName>Sweden</placeName>
- Geographical place names: <geogName>located on the coast of the <geogName>Baltic Sea</geogName>,on the inlet to <geogName>Lake Malaren</geogName>
- Dates (year): <date>Friday, 14 May <date>1993</date>
- Names of organizations: <orgName>published by the <orgName>National Bank of Belgium</orgName>
- Funding organizations and funded projects: <orgName type= "funder">This work was supported by<orgName type="funder">INCO-DC grant IC18CT96-0116</orgName>from the <orgName>European Commission</orgName>
- Provider organizations of resources: <orgName type="provider">numerical simulations were run onthe <orgName type="provider">PARADOX-III cluster</orgName> hosted by [...]
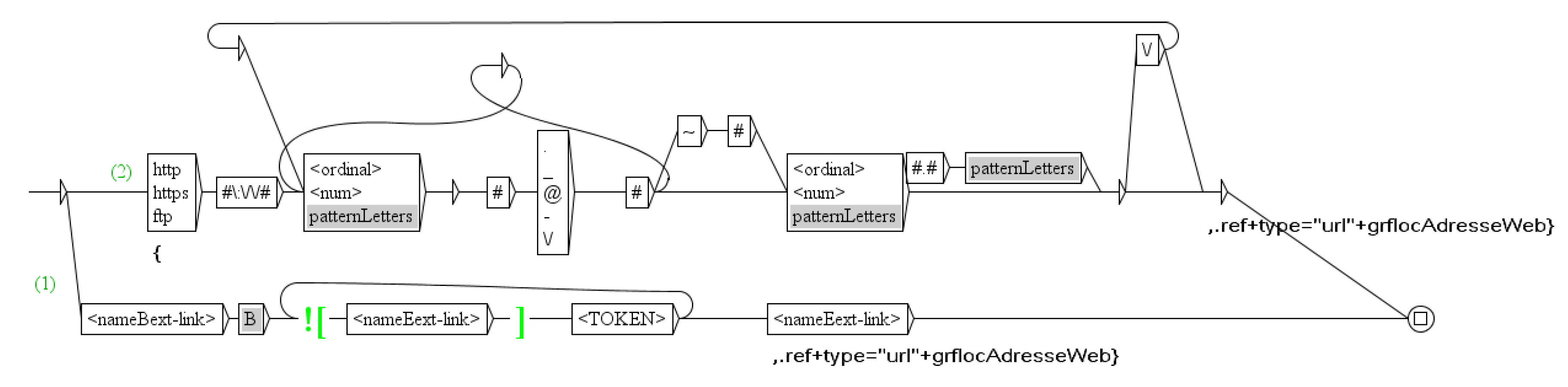
- URL: <ref type="url">a community web site <ref type="url">www.scruminresearch.org</ref>is being built.
- Pointers to bibliographic references: <ref type="bibl">proposed by <ref type="bibl">[Broyden12]</ref>
- Bibliographic references: <bibl>«the scene of our finitude, the place where we encounterthe limits of our subjectivity».<bibl>Diane Michelfelder et Richard Palmer, Dialogue and Déconstruction.The Gadamer-Derrida Encounter, Albany, Suny Press, 1989, p. XI</bibl>
3.2. The Use of a Standoff File
- A <teiHeader> containing a <fileDesc>, a <encodingDesc> and a <revisionDesc>;
- –
- The <fileDesc> (1) contains information about the type of enrichment achieved and the conditions for using the standoff data;
- –
- The <encodingDesc> (2) indicates the name of the application used to obtain the enrichment;
- –
- The <revisionDesc> (3) indicates the date of Unitex version change and the name of the new version;
- A series of <listAnnotation> (4), one for each type of named entity recognized; the <listAnnotation> contains an <annotationBlock> for each named entity belonging to this type;
- –
- An <annotationBlock> contains one named entity and information about this term; the <numeric value> indicates how often this named entity occurs in the document.
3.3. Unitex Implementation at Inist
- Step 1: Unitex compilation
- –
- Parameters
- ∗
- The Ubuntu version number to use (implicitly the gcc tool chain to use for the build process);
- ∗
- The Unitex version number to use (it should be noted here that the Unitex software itself was updated during the process to fix bugs or to improve things related to this experiment);
- ∗
- A zip files from Ergonotics containing an optimization add-on and a custom Unitex build script.
- –
- Output
- ∗
- A Docker image named unitex/compiled whose version number (tag in Docker lingo) is a number made up of the version number of Ubuntu and the version number of Unitex (e.g., unitex/compiled:14.04_2903).
- Step 2: Assembly of Unitex and CasEN
- –
- Parameters
- ∗
- The previously built unitex/compiled Docker Image to start from;
- ∗
- The CasEN artefact to use (the version number in this case is a date).
- –
- Output
- ∗
- A docker image named unitex/runable whose tag is a number made up of the unitex/compiled tag and the version number of the CasEN artefact (e.g., unitex/runable: 14_04_2903_20151201).
3.4. Named Entities Queries in the Istex Website
- The basic URL: https://api.istex.fr/document/?
- A mandatory parameter: q={query}
- Optional parameters:
- –
- output={list of fields to display}
- –
- size={maximum number of documents displayed}
- –
- from={number of the first document}
- A parameter separator: &
- https://api.istex.fr/document/?q=forestry&size=1
- {
- "total": 707274,
- "nextPageURI":
- "https://api.istex.fr/document/?q=forestry&size=1&defaultOperator=OR&from=1",
- "firstPageURI":
- "https://api.istex.fr/document/?q=forestry&size=1&defaultOperator=OR&from=0",
- "lastPageURI":
- "https://api.istex.fr/document/?q=forestry&size=1&defaultOperator=OR&from=9999",
- "hits": [
- {
- "arkIstex": "ark:/67375/56L-3RD0LK4K-P",
- "title": "Windsor-Forest. To the Right Honourable.
- George Lord Lansdown. By Mr. Pope.",
- "id": "10A93EC345EC7D19CBAE42E44ABD13CED8DACD0E",
- "score": 14.641167
- }
- ]
- }
- https://api.istex.fr/document/?q=(host.title:"Biofutur"+OR+host.issn:"0294-3506")
- +AND+host.publicationDate:1995+AND+author.name:"DODET"
- &output=title,author,host&size=100
- https://api.istex.fr/document/?q=namedEntities.unitex.persName:"chomsky"
- https://api.istex.fr/document/?q=namedEntities.unitex.persName:"chomsky"&size=588
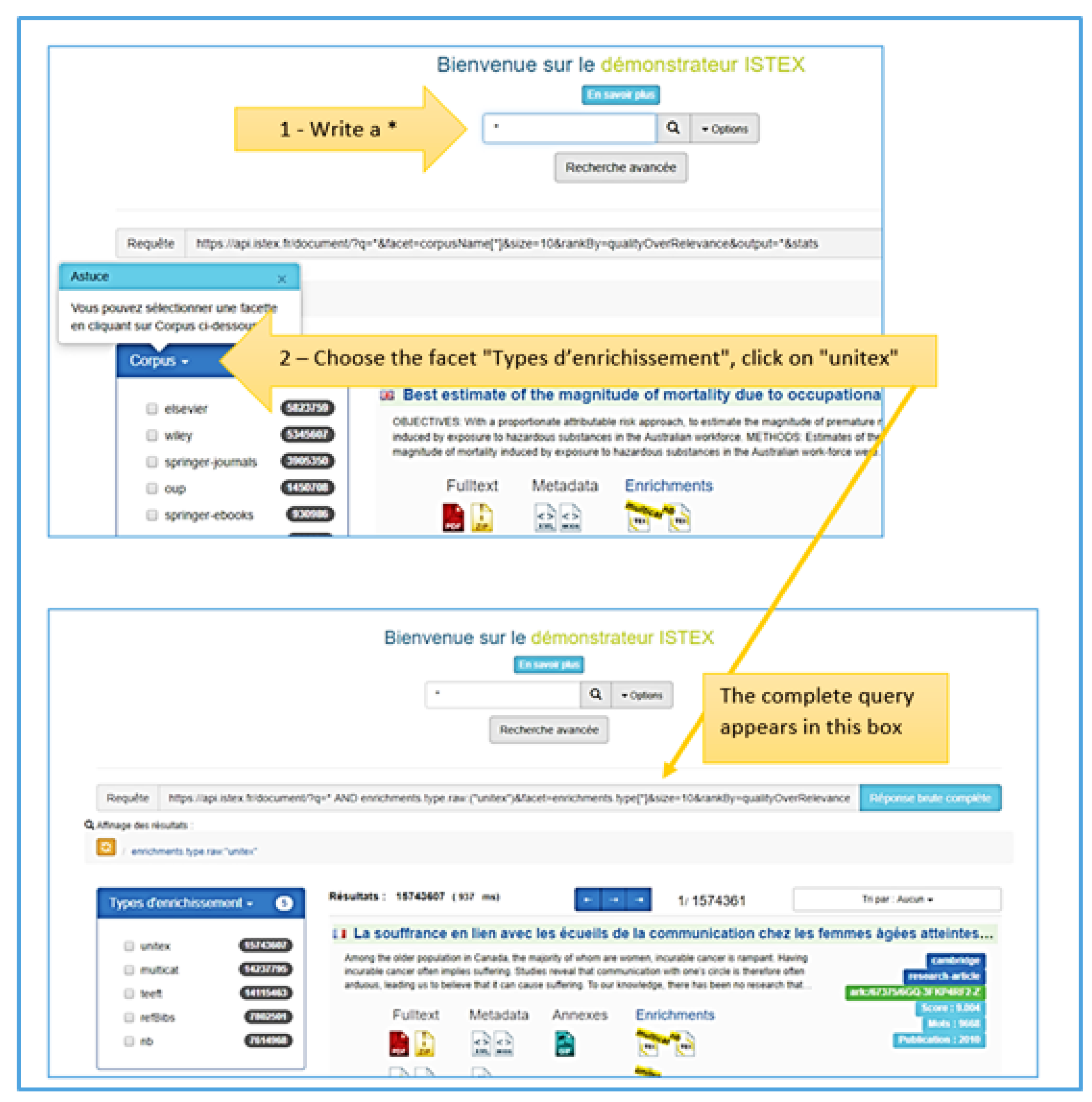
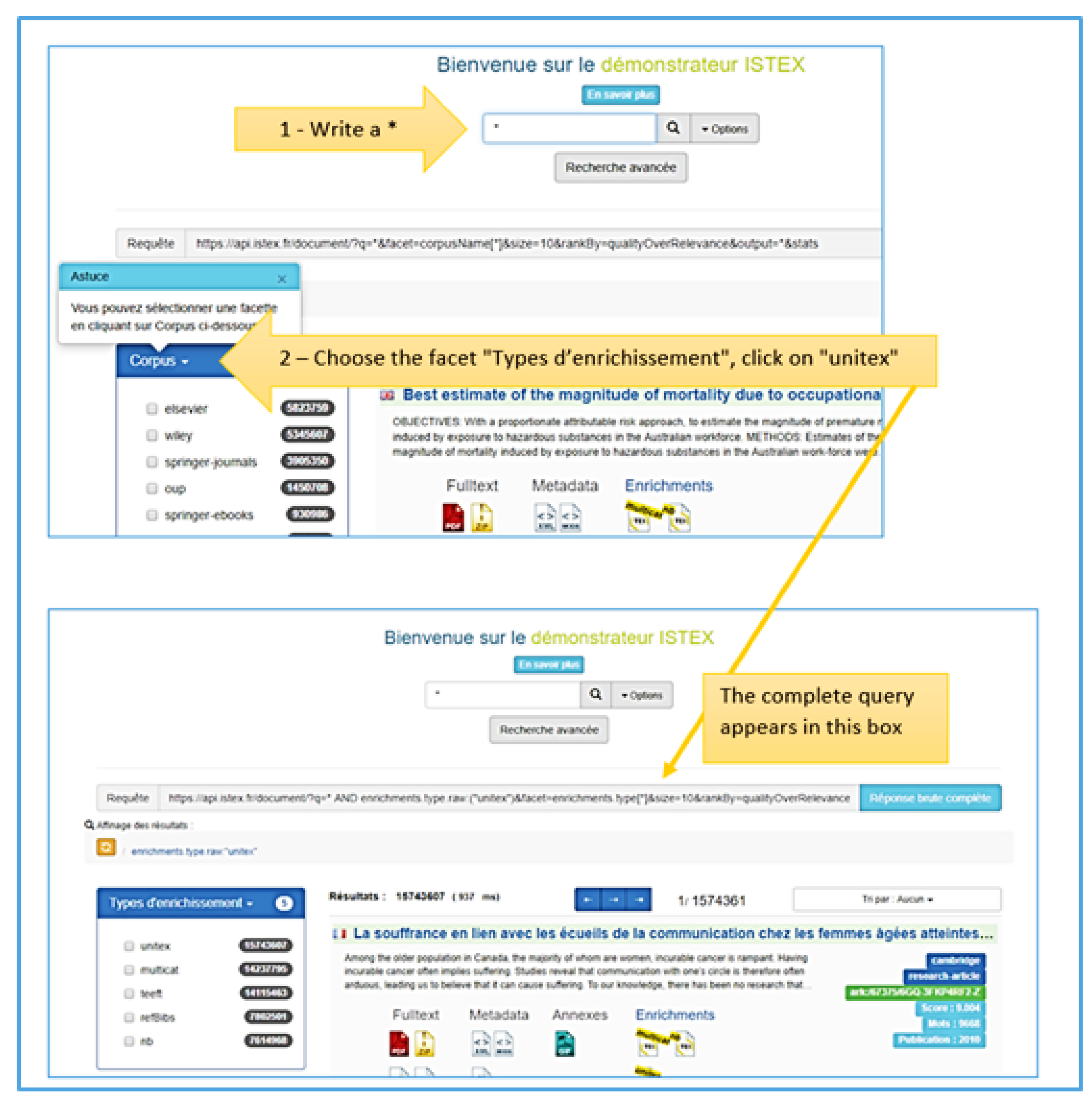
3.4.1. A More Complex Example of Query Concerning Unitex Enrichment
- https://api.istex.fr/document/?q=*%20AND%20enrichments.type.raw:(%22unitex%22)
- &facet=corpusName[*]&size=10&rankBy=qualityOverRelevance&output=*&stats
3.4.2. Replace Unitex Enrichment in the Complete TEI File of a Document
- https://api.istex.fr/document/697E812020AD421C96073D118759E7525A9E7DE2/enrichments/unitex
- https://api.istex.fr/document/697E812020AD421C96073D118759E7525A9E7DE2/enrichments/unitex?consolidate
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chinchor, N. Muc-7 Named Entity Task Definition. 1997. Available online: https://www-nlpir.nist.gov/related_projects/muc/proceedings/ne_task.html (accessed on 21 May 2019).
- Nadeau, N.; Sekine, S. A survey of named entity recognition and classification. In Named Entities: Recognitionandclassification and Use; Sekine, S., Ranchhod, E., Eds.; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2009; pp. 3–28. [Google Scholar]
- Yadav, V.; Bethard, S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning models. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2145–2158. [Google Scholar]
- Fort, K. Les ressources annotées, un enjeu pour l’analyse de contenu: Vers une méthodologie de l’annotation manuelle de corpus. Ph.D. Thesis, Université Paris-Nord-Paris XIII, Paris, France, 2012. [Google Scholar]
- Konkol, M.; Brychcín, T.; Konopík, M. Latent semantics in named entity recognition. Expert Syst. Appl. 2015, 42, 3470–3479. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Gillick, D.; Brunk, C.; Vinyals, O.; Subramanya, A. Multilingual Language Processing from Bytes. arXiv 2015, arXiv:1512.00103. [Google Scholar]
- Ritter, A.; Clark, S.; Etzioni, M.; Etzioni, O. Named entity recognition in tweets: An experimental study. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP ’11, Stroudsburg, PA, USA, 27–31 July 2011; pp. 1524–1534. [Google Scholar]
- Cano, A.; Rizzo, G.; Varga, A.; Rowe, M.; Stankovic, M.; Dadzie, A.S. Making sense of microposts. (#microposts2014) named entity extraction & linking challenge. In Proceedings of the 4th Workshop on Making Sense of Microposts, Co-Located with the 23rd International World Wide Web Conference (WWW 2014), Seoul, Korea, 7 April 2014; Volume 1141, pp. 54–60. [Google Scholar]
- Han, X.; Sun, L. A generative entity-mention model for linking entities with knowledge base. In Proceedings of the 49th ACL Meeting, Portland, OR, USA, 19–24 June 2011; pp. 945–954. [Google Scholar]
- Hachey, B.; Radford, W.; Nothman, J.; Honnibal, M.; Curran, J.R. Evaluating entity linking with Wikipedia. Artif. Intell. 2013, 194, 130–150. [Google Scholar] [CrossRef]
- Moncla, L.; Gaio, M.; Nogueras-Iso, J.; Mustière, S. Reconstruction of itineraries from annotated text with an informed spanning tree algorithm. Int. J. Geogr. Inf. Sci. (IJGIS) 2016, 30, 1137–1160. [Google Scholar] [CrossRef]
- MacDonald, D. Internal and external evidence in the identification and semantic categorisation of Proper Names. In Corpus Processing for Lexical Acquisition; Branimir, B., James, P., Eds.; The MIT Press: Cambridge, MA, USA, 1996. [Google Scholar]
- Ait-Mokhtar, S.; Chanod, J. Incremental Finite-State Parsing. In Proceedings of the 5th Applied Natural Language Processing Conference, ANLP 1997, Marriott Hotel, WA, USA, 31 March–3 April 1997; pp. 72–79. [Google Scholar]
- Hobbs, J.; Appelt, D.; Bear, J.; Israel, D.; Kameyama, M.; Stickel, M.; Tyson, M. A Cascaded Finite-State Transducer for Extracting Information from Natural-Language Text. In Finite State Devices for Natural Language Processing; MIT Press: Cambridge, MA, USA, 1996; pp. 383–406. [Google Scholar]
- Friburger, N.; Maurel, D. Finite-state transducer cascade to extract named entities in texts. Theor. Comput. Sci. 2004, 313, 94–104. [Google Scholar] [CrossRef]
- Abney, S. Parsing By Chunks. In Principle-Based Parsing; Springer: Berlin/Heidelberg, Germany, 1991; pp. 257–278. [Google Scholar]
- Abney, S. Partial Parsing via Finite-State Cascades. In Proceedings of the Workshop on Robust Parsing, 8th European Summer School in Logic, Language and Information, Prague, Czech Republic, 12–23 August 1996; pp. 8–15. [Google Scholar]
- Kokkinakis, D.; Kokkinakis, S.J. A Cascaded Finite-State Parser for Syntactic Analysis of Swedish. In Proceedings of the Ninth Conference of the European Chapter of the Association for Computational Linguistics, Bergen, Norway, 8–12 June 1999. [Google Scholar]
- Alegria, I.; Aranzabe, M.; Ezeiza, N.; Ezeiza, A.; Urizar, R. Using Finite State Technology in Natural Language Processing of Basque. In Implementation and Application of Automata; Watson, B.W., Wood, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 1–12. [Google Scholar]
- Makhoul, J.; Kubala, J.; Schwartz, R.; Weischedel, R. Performance measures for information extraction. In Proceedings of the DARPA Broadcast News Workshop, Herndon, VA, USA, 28 February–3 March 1999. [Google Scholar]
- Sanabria, C.A.R.D.J. Performance Evaluation of Container-based Virtualization for High Performance Computing Environments. arXiv 2017, arXiv:1709.10140. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| I = entities detected by mistake (insertion) | Slot Error Rate (SER): D + I + TE + 0.5 (T+E) / R |
| D = entities totally missed (suppression) | Recall: (S-I)/R |
| T = incorrect typing | Precision: (S-I)/S |
| E = incorrect boundary | Typing accuracy: (S-I-T-TE)/S |
| S = detected entities | Tagging accuracy: (S-I-E-TE)/S |
| R = real entities |
| D | I | T | E | TE | S | R |
|---|---|---|---|---|---|---|
| 1516 | 281 | 64 | 265 | 131 | 3296 | 5414 |
| SER | Recall | Precision | Typing | Tagging |
|---|---|---|---|---|
| Accuracy | Accuracy | |||
| 38.6% | 55.7% | 91.5% | 85.6% | 79.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maurel, D.; Morale, E.; Thouvenin, N.; Ringot, P.; Turri, A. Istex: A Database of Twenty Million Scientific Papers with a Mining Tool Which Uses Named Entities. Information 2019, 10, 178. https://doi.org/10.3390/info10050178
Maurel D, Morale E, Thouvenin N, Ringot P, Turri A. Istex: A Database of Twenty Million Scientific Papers with a Mining Tool Which Uses Named Entities. Information. 2019; 10(5):178. https://doi.org/10.3390/info10050178
Chicago/Turabian StyleMaurel, Denis, Enza Morale, Nicolas Thouvenin, Patrice Ringot, and Angel Turri. 2019. "Istex: A Database of Twenty Million Scientific Papers with a Mining Tool Which Uses Named Entities" Information 10, no. 5: 178. https://doi.org/10.3390/info10050178
APA StyleMaurel, D., Morale, E., Thouvenin, N., Ringot, P., & Turri, A. (2019). Istex: A Database of Twenty Million Scientific Papers with a Mining Tool Which Uses Named Entities. Information, 10(5), 178. https://doi.org/10.3390/info10050178