A Novel Approach for Web Service Recommendation Based on Advanced Trust Relationships


Abstract
:1. Introduction
2. Related Work
3. Formalization of Trust Relationship
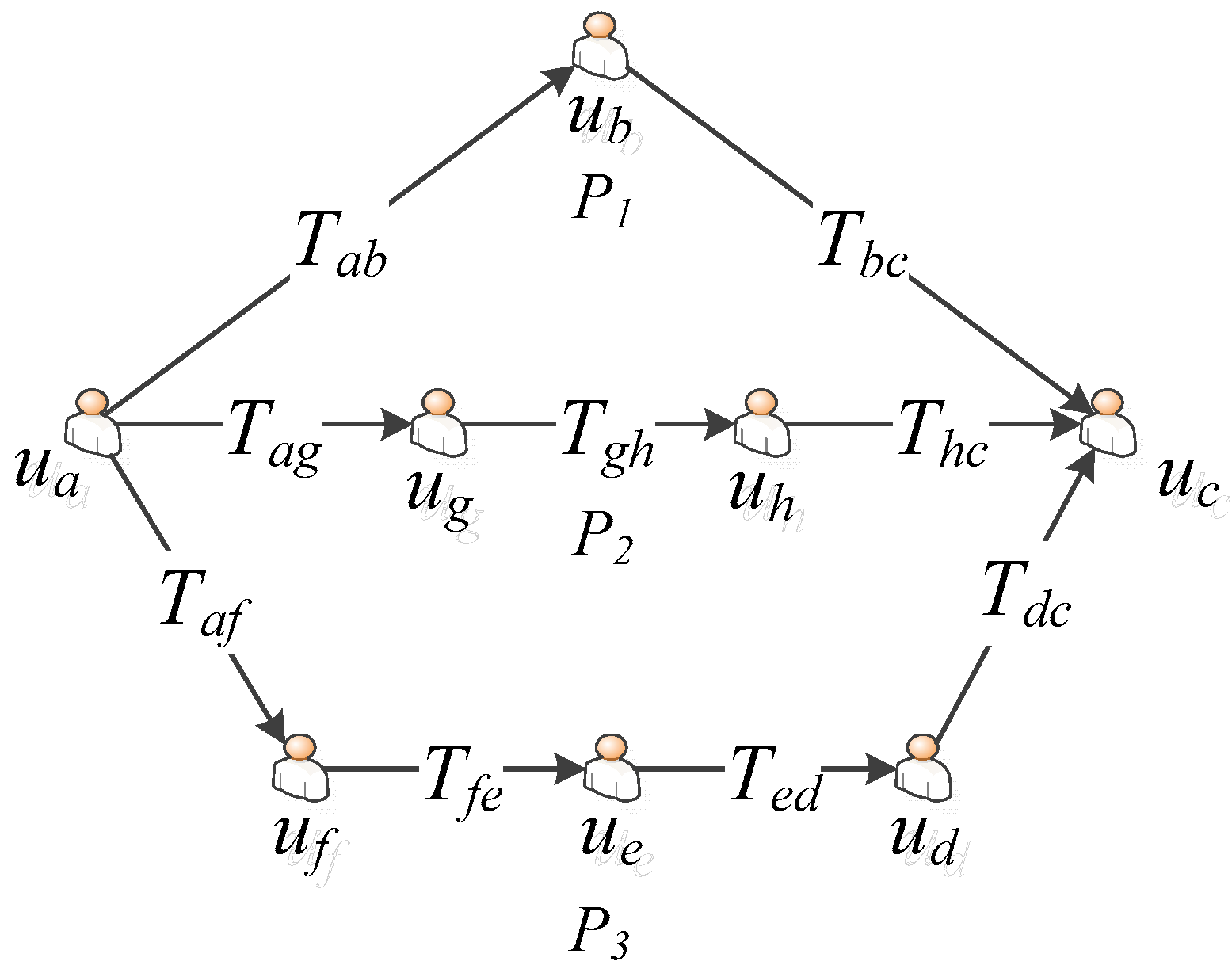
3.1. Definition of Trust Relationship
3.2. User Preference Similarity
3.3. Service Popularity
3.4. Dynamic Characteristics of Trust
4. Recommendation Mechanism
| Algorithm 1 SRATR Input: target user ua, the set of users U, the set of Web services S and the evaluation value matrix R Output: recommended services list La |
| 1. initialize the values of |TU|m, DT, P0 and k 2. La = and TUa = 3. for each user un∈U do 4. calculate Siman 5. calculate Yan 6. calculate Dan 7. if Dan ≥ DT do 8. add un to TUa 9. end if 10. end for 11. if |TUa| > |TU|m do 12. sort um in TUa according to Dam from the largest to the smallest 13. keep the top |TU|m users in TUa 14. end if 15. for each service si∈S do 16. calculate Pai 17. if Pai ≥ P0 do 18. add si to La 19. end if 20. end for 21. sort si in La according to Pai from the largest to the smallest 22. keep the top k services in La 23. return La |
5. Experiments and Analysis
5.1. Experimental Setup
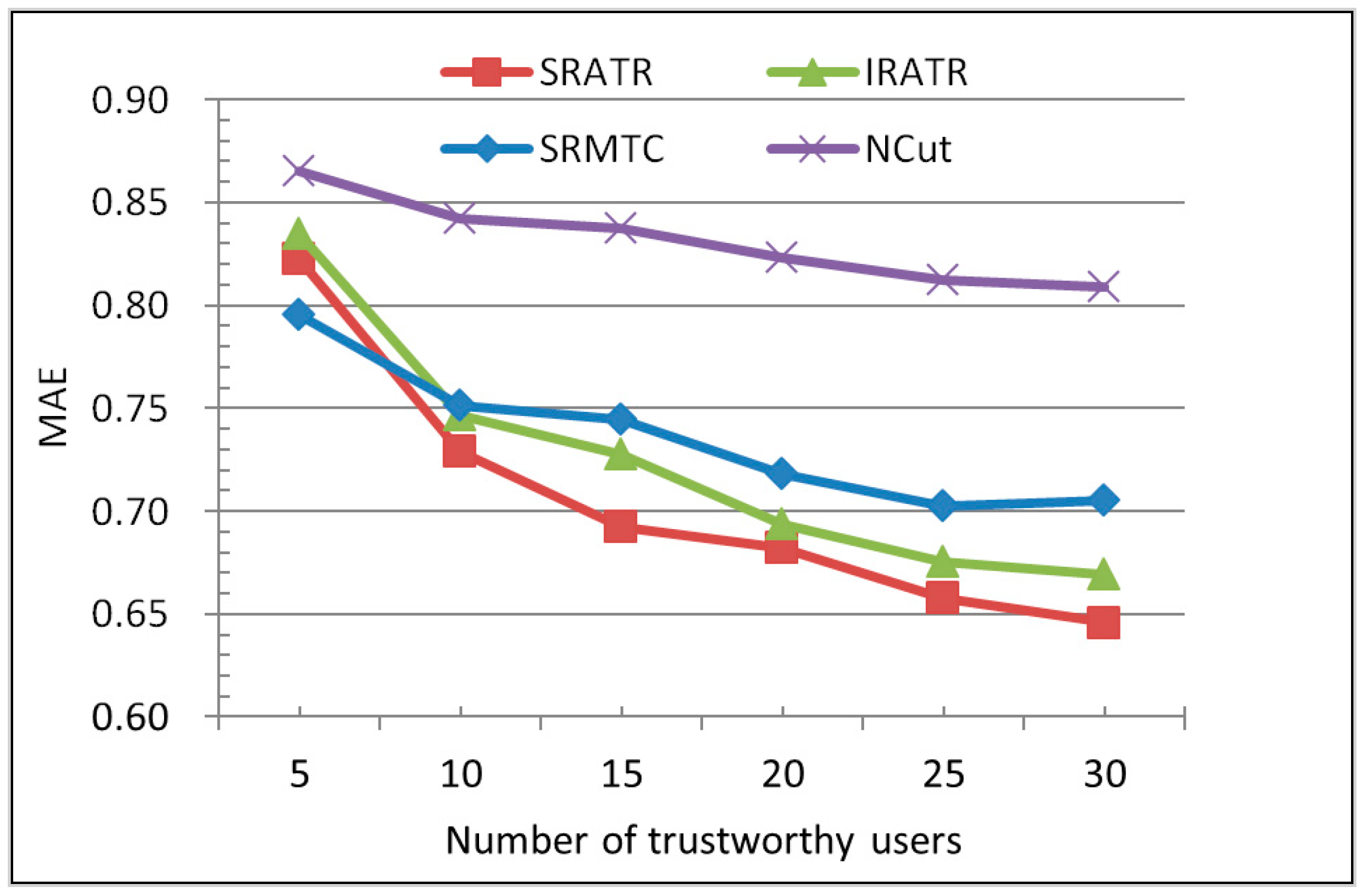
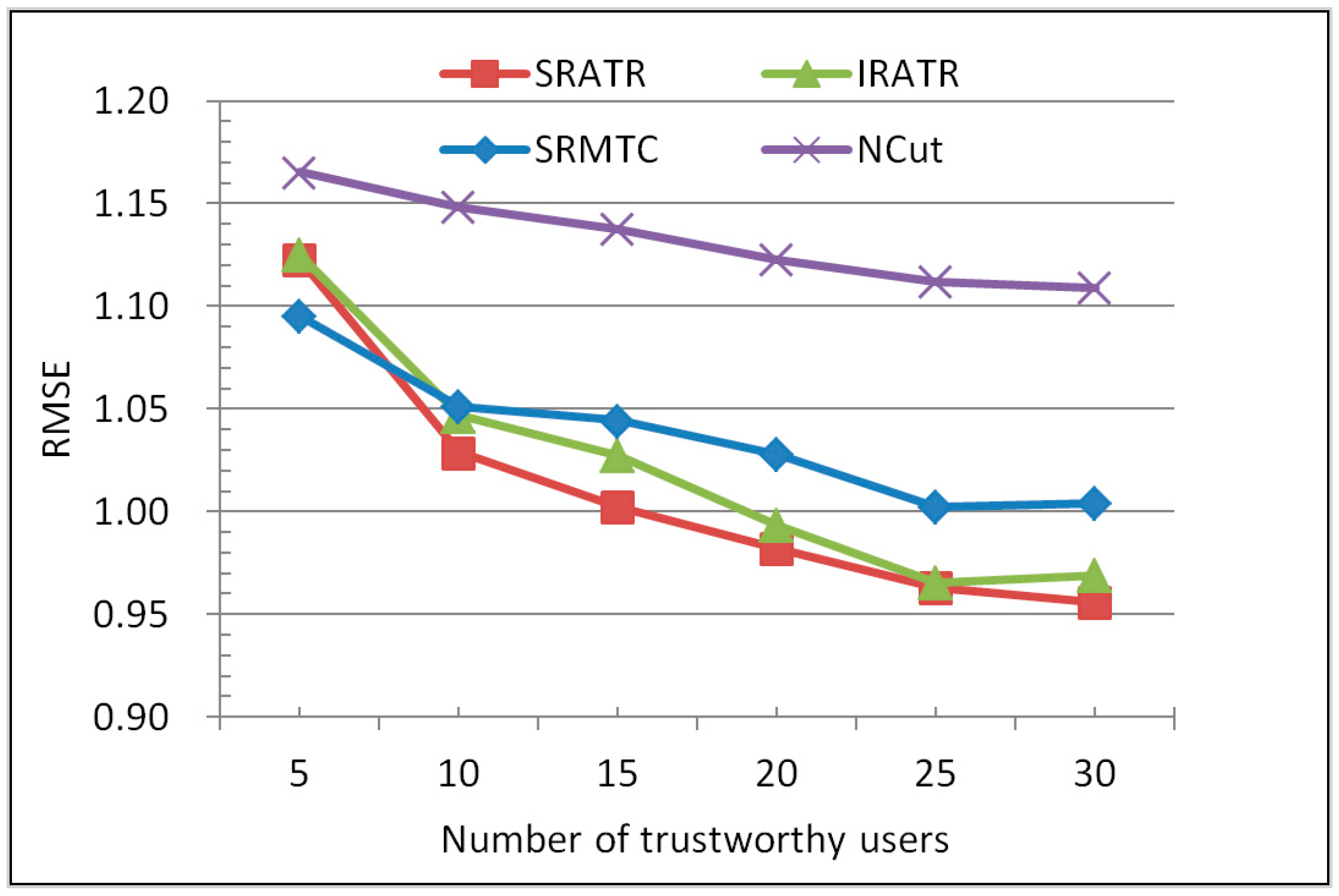
5.2. Comparison of Recommendation Quality
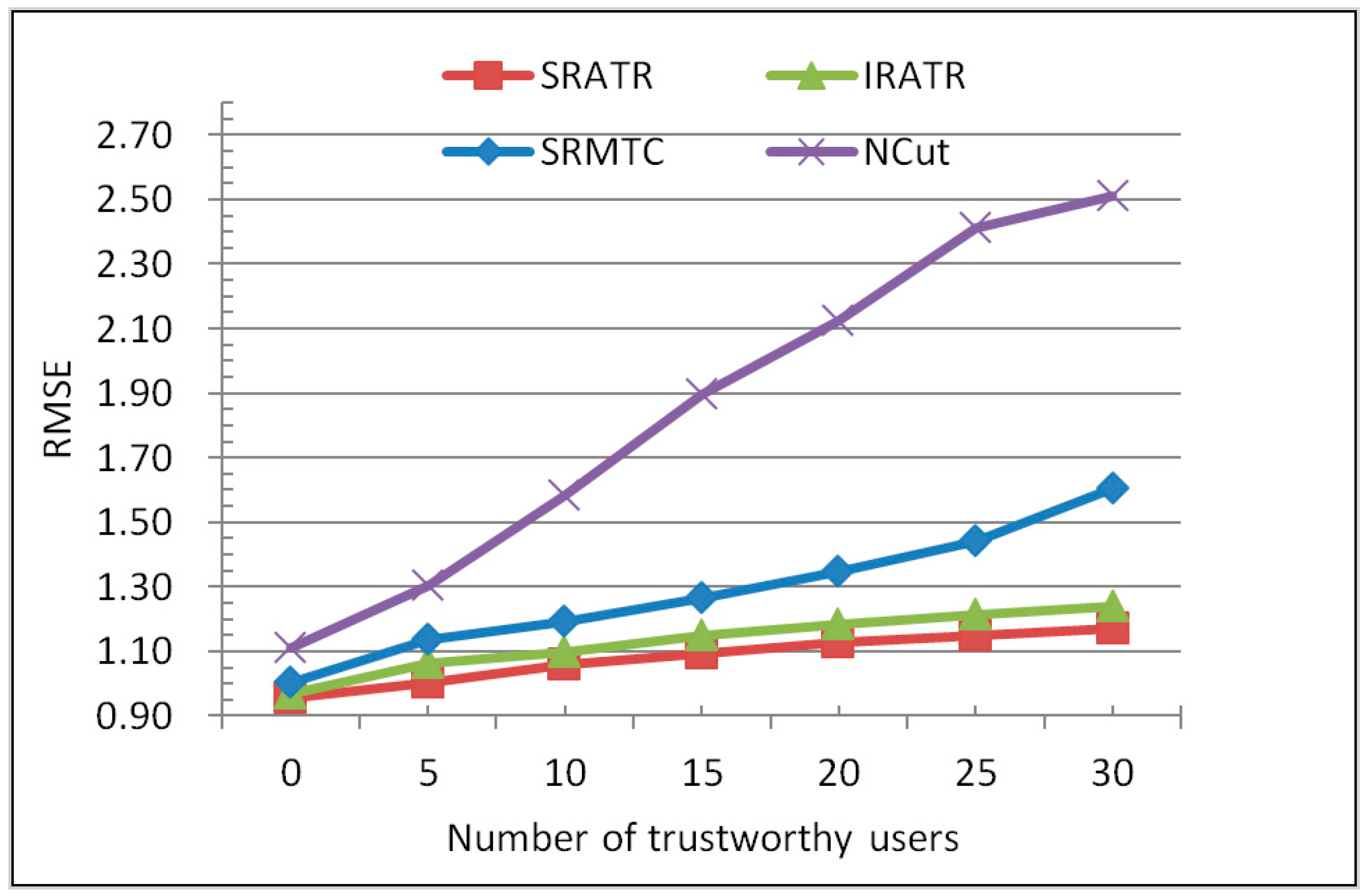
5.3. Comparison of Antifraud Ability
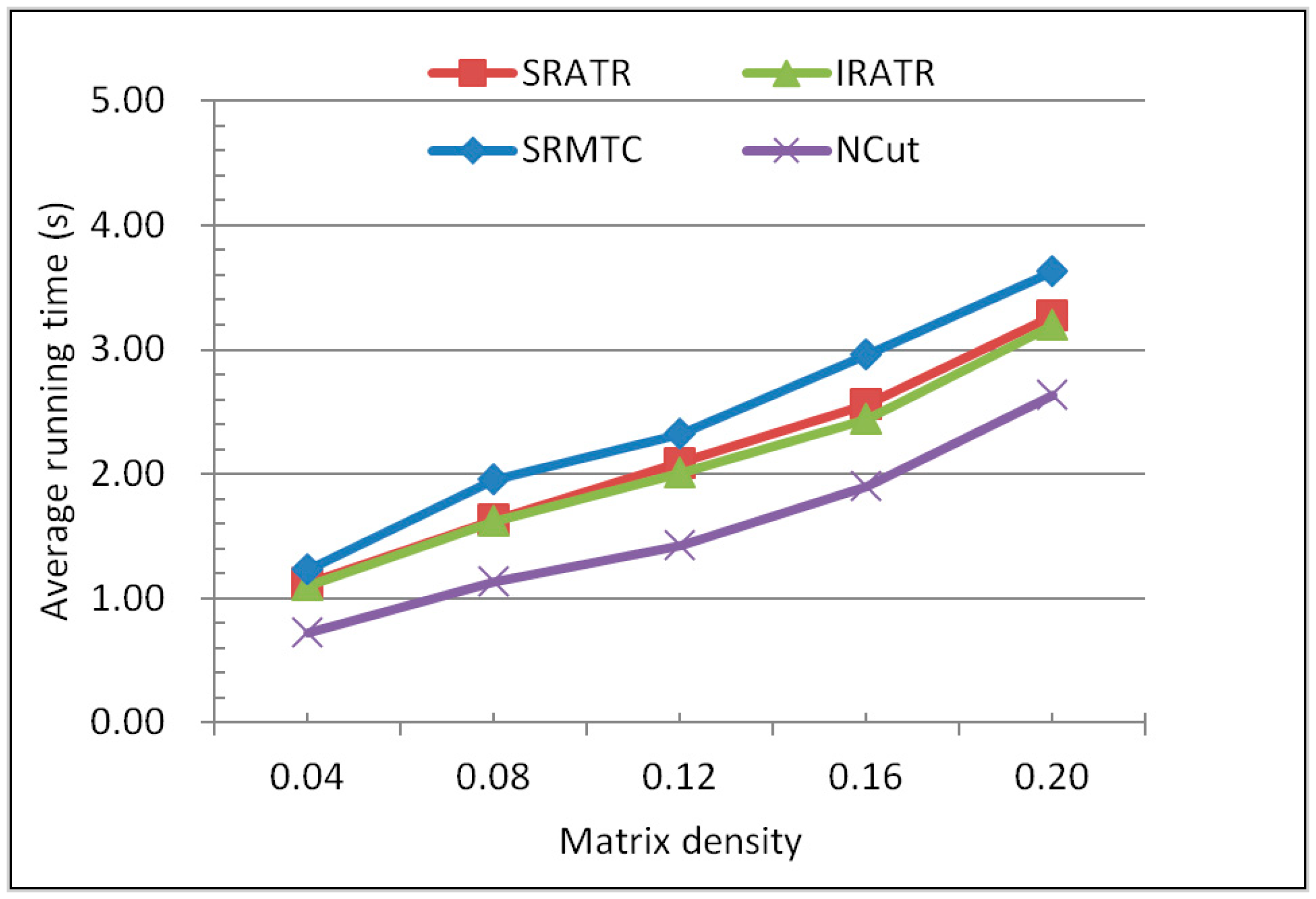
5.4. Comparison of Efficiency
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, Z.; Wang, J.; Zhang, N.; Li, Z.; He, W.; He, K. A topic-oriented clustering approach for domain services. J. Comput. Res. Dev. 2014, 51, 408–419. [Google Scholar]
- Pan, W.; Jiang, B.; Li, B.; Hu, B.; Song, B. Interactive service recommendation based on composition history. J. Comput. Res. Dev. 2018, 55, 613–628. [Google Scholar]
- Meng, X.; Liu, S.; Zhang, Y.; Hu, X. Research on social recommender systems. J. Softw. 2015, 26, 1356–1372. [Google Scholar]
- Wang, Y.; Yin, G.; Cai, Z.; Dong, Y.; Dong, H. A trust-based probabilistic recommendation model for social networks. J. Netw. Comput. Appl. 2015, 55, 59–67. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, J.; Yorke-Smith, N. A novel recommendation model regularized with user trust and item ratings. IEEE Trans. Knowl. Data Eng. 2016, 28, 1607–1620. [Google Scholar] [CrossRef]
- Azadjalal, M.M.; Moradi, P.; Abdollahpouri, A.; Jalili, M. A trust-aware recommendation method based on Pareto dominance and confidence concepts. Knowl. Based Syst. 2017, 116, 130–143. [Google Scholar] [CrossRef]
- Park, C.; Kim, D.; Oh, J.; Yu, H. Improving top-K recommendation with truster and trustee relationship in user trust network. Inf. Sci. 2016, 374, 100–114. [Google Scholar] [CrossRef]
- Aznoli, F.; Navimipour, N.J. Cloud services recommendation: Reviewing the recent advances and suggesting the future research directions. J. Netw. Comput. Appl. 2017, 77, 73–86. [Google Scholar] [CrossRef]
- Zhu, W.; Zhong, Y.; Xu, J. Trustworthy service recommendation method based on social trust. J. Chin. Comput. Syst. 2017, 38, 503–508. [Google Scholar]
- Kalaï, A.; Zayani, C.A.; Amous, I.; Abdelghani, W.; Sèdes, F. Social collaborative service recommendation approach based on user’s trust and domain-specific expertise. Future Gener. Comput. Syst. 2018, 80, 355–367. [Google Scholar] [CrossRef]
- Li, W.; Mo, J.; Xin, M.; Jin, Q. An optimized trust model integrated with linear features for cyber-enabled recommendation services. J. Parallel Distrib. Comput. 2018, 118, 81–88. [Google Scholar] [CrossRef]
- Su, K.; Xiao, B.; Liu, B.; Zhang, H.; Zhang, Z. TAP: A personalized trust-aware QoS prediction approach for web service recommendation. Knowl. Based Syst. 2017, 115, 55–65. [Google Scholar] [CrossRef]
- Fang, C.; Zhang, H.; Zhang, M.; Wang, J. Trust expansion and listwise learning-to-rank based service recommendation method. J. Commun. 2018, 39, 147–158. [Google Scholar]
- Nilashi, M.; Jannach, D.; Ibrahim, O.; Esfahani, M.D.; Ahmadi, H. Recommendation quality, transparency, and website quality for trust-building in recommendation agents. Electron. Commer. Res. Appl. 2016, 19, 70–84. [Google Scholar] [CrossRef]
- Liu, Y.; Liang, C.; Chiclana, F.; Wu, J. A trust induced recommendation mechanism for reaching consensus in group decision making. Knowl. Based Syst. 2017, 119, 221–231. [Google Scholar] [CrossRef]
- Tian, H.; Fan, H.; Du, W. Research on Web service discovery based on user community relations. J. Commun. 2015, 36, 28–36. [Google Scholar]
- Tian, H.; Liang, P. Improved recommendations based on trust relationships in social networks. Future Internet 2017, 9, 9. [Google Scholar] [CrossRef]
- Alejandro, B.; Parapar, J. Using graph partitioning techniques for neighbor selection in user-based collaborative filtering. In Proceedings of the Sixth ACM Conference on Recommender Systems, Dublin, Ireland, 9–13 September 2012; pp. 213–216. [Google Scholar]
- Wang, H.; Yang, W.; Wang, S.; Li, S. A service recommendation method based on trustworthy community. Chin. J. Comput. 2014, 37, 301–311. [Google Scholar]
- Zheng, Z.; Lyu, M. Collaborative reliability prediction for service-oriented systems. In Proceedings of the ACM/IEEE 32nd International Conference on Software Engineering (ICSE2010), Cape Town, South Africa, 2–8 May 2010; pp. 35–44. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Web Service ID | WSDL Address | Web Service Name | Provider Name | Location |
|---|---|---|---|---|
| 8451 | http://las.aei.polsl.pl/las2/las2.asmx?WSDL | Las2Service | polsl.pl | Poland |
| 8460 | http://streemo.pl/Portal/WebServices/SongService.asmx?WSDL | SongService | streemo.pl | Poland |
| 8953 | http://services.telekom.yu/WSResearch/registration.asmx?WSDL | Research | services.telekom.yu | Serbia and Montenegro |
| Client IP | Web Service ID | Response Time (ms) | Data Size | HTTP Code |
|---|---|---|---|---|
| 35.9.27.26 | 8451 | 2736 | 582 | 200 |
| 35.9.27.26 | 8460 | 804 | 14,419 | 200 |
| 35.9.27.26 | 8953 | 20,176 | 2624 | −1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, L.; Tian, H.; Liu, K. A Novel Approach for Web Service Recommendation Based on Advanced Trust Relationships. Information 2019, 10, 233. https://doi.org/10.3390/info10070233
Duan L, Tian H, Liu K. A Novel Approach for Web Service Recommendation Based on Advanced Trust Relationships. Information. 2019; 10(7):233. https://doi.org/10.3390/info10070233
Chicago/Turabian StyleDuan, Lijun, Hao Tian, and Kun Liu. 2019. "A Novel Approach for Web Service Recommendation Based on Advanced Trust Relationships" Information 10, no. 7: 233. https://doi.org/10.3390/info10070233
APA StyleDuan, L., Tian, H., & Liu, K. (2019). A Novel Approach for Web Service Recommendation Based on Advanced Trust Relationships. Information, 10(7), 233. https://doi.org/10.3390/info10070233