Abstract
Relation extraction is an important task with many applications in natural language processing, such as structured knowledge extraction, knowledge graph construction, and automatic question answering system construction. However, relatively little past work has focused on the construction of the corpus and extraction of Uyghur-named entity relations, resulting in a very limited availability of relation extraction research and a deficiency of annotated relation data. This issue is addressed in the present article by proposing a hybrid Uyghur-named entity relation extraction method that combines a conditional random field model for making suggestions regarding annotation based on extracted relations with a set of rules applied by human annotators to rapidly increase the size of the Uyghur corpus. We integrate our relation extraction method into an existing annotation tool, and, with the help of human correction, we implement Uyghur relation extraction and expand the existing corpus. The effectiveness of our proposed approach is demonstrated based on experimental results by using an existing Uyghur corpus, and our method achieves a maximum weighted average between precision and recall of 61.34%. The method we proposed achieves state-of-the-art results on entity and relation extraction tasks in Uyghur.
1. Introduction
Extracting entities and relations from unstructured texts is crucial for knowledge base construction in natural language processing (NLP) [1,2,3,4], intelligent question answering systems [5,6], and search engines. The development of knowledge graphs is particularly well-suited to this purpose due to their well-structured nature that typically comes in the form of three entries that are denoted as a head entity, a relation, and a tail entity (or h, r, and t). In particular, the automatic construction of knowledge graphs based on unstructured data has attracted significant interest. For example, projects such as DBPedia [7], YAGO [8], Kylin/KOG [9,10], and BabelNet [11] have focused on building knowledge graphs by using entities and relations that are extracted from unstructured data obtained from Wikipedia, which is one of the largest sources of multilingual language data on the internet. However, relation extraction requires sufficient annotated corpus data, particularly in supervised learning. Nonetheless, supervised relation extraction models [12,13] usually suffer from a lack of high-quality training data because the manual labeling of data is human labor-intensive and time-consuming. The above-discussed issue is particularly problematic for Uyghur because relatively little past work has focused on the construction of the corpus and has not included research about the extraction of Uyghur-named entity relations, resulting in the very limited availability of relation extraction research and a deficiency of annotated relation data. This lack of sufficient annotated corpus data is a significant challenge that has affected efforts toward the extraction of entities and relations from unstructured Uyghur texts. Moreover, relatively few annotated named Uyghur entity relation data are available on the internet. In addition, we note that the construction of knowledge graphs is quite language-dependent [14]. Currently, most knowledge graph systems are developed in the English language and then directly translated into the language of interest. However, this approach is often not feasible for Uyghur because the direct translation of English knowledge graphs into Uyghur is not always possible. As such, knowledge graphs must be directly constructed in Uyghur based on extracted relations to develop a reasonably sophisticated Uyghur knowledge base. However, Uyghur relation extraction is quite difficult compared to that of the English language because the Uyghur language is morphologically complex, and the difficulty of the task is further compounded by the limited availability of annotated data. These issues represent major limitations that affect the extraction of entities and relations in the Uyghur language. Uyghur is a type of morphologically-rich agglutinative language that is used by approximately 10 million people in the Xinjiang Uyghur autonomous region of China. Uyghur words are formed by a root followed by suffixes [14,15]; therefore, the size of the vocabulary is huge. Officially, Arabic and Latin scripts are used in Uyghur, while Latin scripts are also widely used on social networks and mobile communications.
The present work seeks to alleviate the above-discussed limitations by proposing a hybrid neural network and semi-automatic named-entity relation recognition method for making suggestions regarding annotation based on extracted relations with a set of rules applied by human annotators to expand the existing annotated Uyghur corpus more rapidly than by human annotation alone. We also focus on the issues raised during Uyghur knowledge graph construction and discuss the main challenges that must be addressed in this task. Finally, the effectiveness of our proposed approach is experimentally demonstrated.
2. Related Works
Entity relations are the key components that are required for building knowledge graphs, and numerous methods have been developed for relation recognition and extraction [16]. Conventional approaches consider entity recognition to be an antecedent step in a pipeline for relation extraction [17,18,19]. However, the dependence between the two tasks is typically ignored. The relation extraction task can be seen as a sequence labeling problem. As such, numerous methods have been based on sequence tagging. For example, research has been conducted to develop an entity relation descriptor based on a linear-chain Conditional Random Field (CRF) model, which has been demonstrated to reduce the space of possible label sequences and introduce long-range features [20,21,22,23]. Numerous sequence tagging approaches have been developed, including hidden Markov models (HMM), maximum entropy Markov models [10], CRF models [24], and neural network methods [25,26,27,28,29]. Among these, CRF models have been a commonly used in Natural Language Processing (NLP) applications in recent years. A CRF model combines maximum entropy with a hidden Markov model, which is a typical non-directional pattern model of discriminant probability. A CRF attempts to model the conditional probability of multiple variables after observing a given value. As such, the construction of a conditional probability model is the goal of a CRF [26]. Neural network-based methods have also become widely used in NLP applications. For example, the authors of [30] proposed a multichannel convolutional neural network (MCCNN) for automated biomedical relation extraction that obtained an average accuracy of 90.1%. However, the accuracy of named entity recognition affects the accuracy of relation extraction. This has recently been addressed by the joint extraction of named entities and relations [30,31,32]. For example, the authors of [33] proposed a novel tagging scheme and demonstrated that the sentence annotations could be applied to the joint extraction task based on different end-to-end models. The authors of [34] proposed a globally optimized neural model, and they achieved the best relation extraction performance for existing state-of-the-art methods on two standard benchmarks. The authors of [35] proposed attention-based bidirectional long short-term memory (BILSTM) with a conditional random field layer for document-level chemical Named Entity Recognition (NER). For NLP applications specific to the Uyghur language, a few studies have focused on corpus construction. Here, the authors of [14] proposed a method for constructing a Uyghur-named entity and relation corpus to expand the size of the existing corpus. The authors of [36] constructed a contemporary Uyghur grammatical information dictionary that provided extensive grammatical information and collocation features and is presently a primary resource for NLP research specific to the Uyghur language. The Uyghur Dependency Treebank was built from a public reading corpus [37,38], and also presently serves as an important tool for Uyghur linguistic studies. A standard scheme for tagging Uyghur sentences to construct a typical knowledge graph is illustrated in Table 1.

Table 1.
A standard Uyghur sentence tagging scheme.
It can be seen from Table 1 that “Alim Adilning” and “Aliye Ubul” are the first and second entities in the sentence, respectively. “Personal.Family” is a relation type.
3. Uyghur Relation Extraction Model
The present study adopts a hybrid neural network and CRF model to analyze the grammatical and semantic features of Uyghur-named entity relations. Experimental results have shown that a CRF model provides better extraction performance than neural network models when the amount of data is relatively small.
3.1. Task Definition
As mentioned above, the relation extraction task can be seen as a sequence labeling problem, and all Uyghur datasets applied to the hybrid neural network and CRF model must be labeled. The annotation for relation extraction from raw texts consists solely of relation extraction tags that recognize valid relations between entity pairs. The present work constructed feature sets of the different entity categories based on the characteristics of Uyghur-named entities and relations. These features include word-related features and dictionary features. Word-related features include Uyghur words, part-of-speech tagging, syllables, word lengths, and syllable lengths. We neglected the use of word stem characteristics because Uyghur word stemming is complicated, and no reasonably good stemming tools are presently available for Uyghur. Meanwhile, numerous dictionary features were adopted, such as common dictionaries, person name dictionaries, place name dictionaries, organization name dictionaries, and similarity dictionaries based on word vectors. Table 2 presents the annotation that were employed for each word in an example Uyghur sentence to facilitate relation extraction. Each sentence has a number of tags, where “O” represents “other” (which is independent of the extracted results), “S” represents a single word, “B” represents the first word of an entity, “I” represents the one middle word of the entity, and “E” represents the last word of the entity. The annotations adopted for an example Uyghur sentence to facilitate relation extraction are shown in Table 2.
Table 2.
Annotations adopted for an example Uyghur sentence to facilitate relation extraction.
3.2. Feature Template
The effect of combining different features on the named entity relations extraction process cannot be ignored. Therefore, the selection of feature templates plays an extremely important role in relation extraction. The processes of named entity relations recognition and extraction must both consider individual words and the context of each word (i.e., its surrounding words), and the CRF model must be designed to synthesize contextual information as well as external features. In this paper, we used CRF Sharp open source tools to build the CRF model for conducting Uyghur-named entity relation recognition, and a supervised corpus was employed to predict the relation type based on the CRF model. The template features adopted in the current work are listed in Table 3. Here, we adopted not only an atomic feature (unary feature) template but also a composite feature template that represents a combination of three features, while the other three features represents binary feature combinations. In addition, represents the first column of the corpus, which is a column of words, and F denotes other characteristic columns without words. In addition to the feature categories, the size of the feature window must also be considered when establishing a CRF model because the window contains the contextual information of a word. An overly large window will lead to information redundancy and reduce the training thickness of the model. Meanwhile, an overly small window size will provide insufficient information for model training, and the extraction performance of the model will suffer. In this paper, the final selected window size was 4 + 1.
Table 3.
The definitions of feature templates.
All sentences are treated as sequences in a CRF model, where each word in a sentence is a moment. In the process of relationship identification, a CRF model calculates the probability of applying particular tags to the moments of a sequence based on the acquired features and weights of each sequence, and these probabilities are then used as the input parameters of the conditional probability. The CRF model then normalizes the distribution of the entire state sequence. Furthermore, the selection of feature sets directly affects the performance of the model. Therefore, we built a candidate feature set of useful features to determine which feature had the strongest efficacy for predicting the entity relations.
The rows of a corpus selected by a feature are identified relative to a given position, while the selected columns of the corpus are identified according to an absolute position. Generally, m rows before and after a given row are selected, and n − 1 (where n is the total number of columns in the corpus) columns are selected. Each line in the template file is a feature template. The feature templates are represented as a token in the input data according to the statement %x[row, column], where row specifies the row offset to the current token and column specifies the position of the selected column. The initial position is 0. Unigram features have the letter U affixed to them, and bigram features are affixed with the letter B, as shown in Table 4.
Table 4.
Feature template table for example words.
3.3. Rules
The relation is different from the named entity. The task of Uyghur relation extraction has been simplified in the present work by assuming that the named entity was given. Therefore, only the relationships between the named entities represented in a sentence were tagged. However, the results obtained in this manner were not particularly useful for the subsequent task of human annotation. Thus, rules were adopted to denote the relation type after conducting relation extraction based on the CRF model. These rules were denoted according to the standard labeling shown in Table 5. Here, the rules for physical location relations were that the first parameter of this relationship had to be a person (PER), while the second parameter could be a facility (FAC), location (LOC), or a geographical, social, or political entity (GPE).
Table 5.
Input format of entity relationships.
As an example, the permissible parameter table for Physical.Located is given in Table 6 for the sentence “adil shangxeyde oquwatidu” (Adil is studying at Shanghai). These permissible parameters are shown in Table 6.
Table 6.
Permissible parameter table for an example sentence.
3.4. Hybrid Neural Network Model Training
Hybrid neural network models are based on convolutional neural networks (CNN) and long short-term memory (LSTM). In this paper, we propose a CRF model and hybrid neural network based on the semantic and morphological features in Uyghur. Both methods have their advantages and disadvantages.
The framework of the hybrid neural network is shown in Figure 1. The first layer is a bidirectional LSTM-encoding layer that is shared by the relation extraction and named entity extraction models. There are two modules after the encoding layer. One is the named entity recognition module and is linked to an LSTM-decoding layer, and the other feeds into a CNN layer to extract the relations. The basic layer contains word embedding, relation, the position of the entity and arg_type.
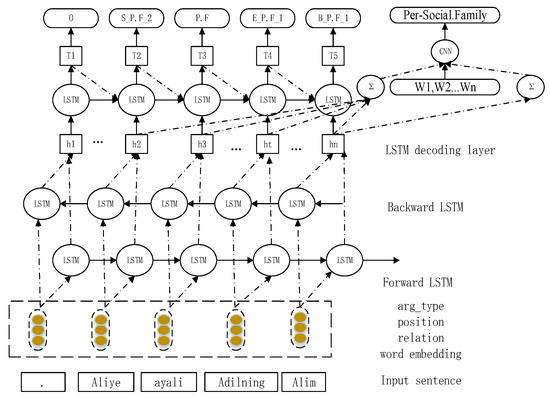
Figure 1.
The framework of the hybrid neural network for jointly extracting entities and relations.
3.4.1. Bidirectional LSTM-Encoding Layer
The bidirectional LSTM-encoding layer [39] contains a word embedding layer, a forward LSTM layer, a backward LSTM layer, and a concatenation layer. The word embedding layer converts the word with 1-hot representation to an embedding vector. A sequence of words is represented as , where is the dimensional word vector corresponding to the t-th word in the sentence with a length equal to the input sentence. After the word embedding layer, there are two parallel LSTM layers: the forward LSTM layer and the backward LSTM layer.
We express the detailed operation of LSTM in Equations (1)–(6). is the input gate that controls how much of the current input and previous output c will enter into the new cell. decides whether to erase or keep individual components of the memory. For each word , the forward layer encodes by considering the contextual information from words to .
In Equations (5)–(10), , , and are the input gate, forget gate, and output gate, respectively. b is the bias term, c is the cell memory, and represents the parameters. We concatenate to represent word t’s encoded information.
3.4.2. LSTM-Encoding Layer
We used an LSTM structure to produce the tag sequence, as given in Equations (11)–(19). When detecting the tag of word , the inputs of the decoding layer consist of obtained from the bidirectional LSTM layer, the former predicted tag embedding , the former cell value , and the former hidden vector in decoding layer .
In Equations (7)–(15), is the softmax matrix and is the total number of tags. The tag prediction vector is similar to tag embedding, and LSTM is capable of learning long-term dependencies. Thus, the decoding method can model tag interactions.
3.4.3. LSTM-Decoding Layer
When extracting entities’ semantic relations, we merge the encoding information of entities and then feed them into the CNN model.1.
where is the encoding information of entity and is word embedding. The CNN denotes the convolutional operations. In the convolutional layer, represents the i-th convolutional filter, represents the bias term, and filter slides through the input sequence to get the features . The sliding process can be represented as follows:
We apply the max-pooling operation to reserve the most prominent feature of filter and denote it as:
Finally, we set the Softmax layer with dropout to classify the relations based on relation features , which is defined as follows:
Here, is the Softmax matrix, is the total number of relation classes, the symbol denotes the element-wise multiplication operator, and is a binary mask vector that is drawn from b with probability .
3.5. CRF Model
A CRF model is defined as follows.
Set s as a node of V and E as an undirected graph of a set with no edges.
Each node in V corresponds to a random variable whose value range is a possible set of tags.
Each random variable satisfies Markov characteristics for an observed sequence for conditions as follows:
where W and V denote two adjacent nodes in graph G. Then, (X, Y) is a CRF.
The CRF model calculates the conditional probability of an output node value under the condition of given input nodes. For a chain with corresponding weights , the conditional probability of a state sequence obtained for a given sequence x is defined as follows:
Here, the denominator is a normalization factor that ensures that the sum of the probabilities of all possible state sequences is 1 for the given input , and that this holds for all values of . Additionally, the feature functions, which are located at n and n − 1, may be 0, 1, or any real number. In most cases, the characteristic function is a binary representation function, where the value is 1 when the characteristic condition is satisfied; otherwise, it is 0. Accordingly, the characteristic functions are defined as follows:
The final step is to search for the value , which represents the output with the highest probability.
Parameter settings: We used the CRF++ based NER as the baseline. The features used in CRF++ were unigrams and bigrams. The window size was set to 5, such that we considered two words ahead of and two words following the current word .
4. Experiments
The raw statistics pertaining to the initial annotated Uyghur language corpus and expanded corpus are listed in Table 7. Reference [14] was focused on the construction of the corpus of Uyghur-named entity relations, resulting in the very limited availability of relation extraction research and a deficiency of annotated relation data. There are 571 documents, 6173 sentences, and 4098 useful sentences.
Table 7.
Differences between original corpus and expanded corpus.
Problems:
- The corpus size was small.
- There were also many sentences that did not have any entities and relations.
- In this paper, the most basic corpus of Uyghur named entities and relations was constructed, and no study of the relation extraction research in Uyghur was undertaken.
Here, the 9103 sentences listed represent filtered sentences that were obtained from a total number of 17,765 sentences. This can address the first and second problems in the research of [14].
4.1. Dataset
As compared to the existing original corpus [14], our work expands the existing corpus size and improves its quality.
According to the conventions adopted in this work, an entity should be the name of a person (PER), location (LOC), organization (ORG), geographical entity (GPE), title (TTL), age (AGE), Uniform Resource Locater (URL), or facility (FAC).
The statistics of entities and their pertinence to these individual entity types are listed in Table 8 and Table 9, respectively. We note from Table 9 that the number of entities is extremely unbalanced, in that the number of GPEs is very large while the number of URLs is very small. In addition, the total number of non-duplicated named entities in the annotated corpus is 5610.
Table 8.
Entity statistics for the initial annotated corpus.
Table 9.
Coverage of entity types in the initial annotated corpus.
The statistics pertaining to relations for the total number of 9103 filtered sentences in the initial annotated corpus are listed in Table 10.
Table 10.
Overall relation statistics for the initial annotated corpus.
The actual numbers of individual relation types observed in the initial annotated corpus are listed in Table 11. An analysis of Table 11 indicates that the corpus includes five relation types, which are listed in Table 12, and 16 subtypes, which are listed in Table 13.
Table 11.
Numbers of individual relation types observed in the initial corpus.
Table 12.
Relation type statistics for the initial corpus.
Table 13.
Relation subtype statistics for the initial corpus.
An analysis of the tables indicates that most of the relation types are subsidiary. We also note from Table 13 that that the Part–Whole relation type includes the highest number of named entity relations, while the Gen–Aff relation type has the least.
4.2. Experimental Results
We first employed our proposed CRF model to conduct Uyghur relation extraction for 842 documents by using only word features Fwc. The performance results are listed in Table 14.
Table 14.
Relation extraction performance of the proposed CRF model when using only word features Fwc.
Secondly, we employed our proposed hybrid neural network and CRF models with added features X = {Fwc, Fsyllable, Farg_type, Frelation_type, Fposition}, Fposition, relation_type, arg_type, Fposition, relation_type, arg_type, wc, position+relation_type+arg_type, and Fposition, relation_type, arg_type, wc, position. The feature items that were selected for this paper are as follows: word feature/syllable/argument, type/relation, and type/position/syllable. The feature set was expressed as follows: X = {Fwc, Fsyllable, Farg_type, Frelation_type, Fposition}, where the five elements were defined as follows.
- Fwc: the word feature that represents the word itself.
- Fsyllable: the syllable that represents the suffix and prefix of the word.
- Farg_type: the argument type, i.e., whether it is a first or second argument.
- Frelation_type: the relation type that represents the relation between two entities.
- Fposition: the entity position feature that represents the position of the word contained in each entity.
The relation extraction results indicated that the features of the words are vital, but the syllable directly reduces the F1 score of the relation extraction results. The Hyper parameters of the hybrid neural network and performance results are listed in Table 15 and Table 16 respectively.
Table 15.
Hyper parameters of the hybrid neural network.
Table 16.
CRF model performed while using multiple feature comparisons with the neural network method on the task of relation extraction.
Finally, our proposed CRF model was applied to the same documents while using only Fwc to determine the relation extraction performance for each of the five primary relation types individually.
It can be seen from the above results that the traditional and neural network methods have their own advantages and disadvantages. The CRF model is better than the neural network in relation extraction with Uyghur features. The F1 value of the hybrid neural network with these features was only 48.7, which was higher than that of the pure hybrid neural network method. Though this present work was hindered by the lack of relation extraction corpora in the Uyghur language for conducting comparison experiments, we conducted comparative experiments with our own corpus and different methods.
4.3. Analysis and Discussion
Finally, the training data obtained the following results under the condition of adding features in five different categories. The performance results for the individual relation types are listed in Table 17.
Table 17.
Accuracy of relation extraction when using only word features Fwc for specific relation types.
We compared our method with different methods. The results in Table 17 are of particular interest in that they show the effect of the good relation extraction performance for Aff.Owner on the overall Uyghur relation extraction performance of the proposed method. The expanded corpus provides a higher quality basis for conducting Uyghur relation extraction research in NLP.
5. Conclusions
The present article addressed the many issues limiting Uyghur language research by proposing a hybrid neural network that combines a CRF model for making suggestions regarding annotation that is based on extracted relations with a set of rules applied by human annotators. Uyghur relation extraction was therefore implemented with the help of human correction to more rapidly expand the existing corpus than by human annotation alone. The relation extraction performance of our proposed approach was demonstrated by using an existing Uyghur corpus, and our method achieved a maximum F1 score of 61.34%.
In the future, we will explore how to better link these semantic features on the neural network. We also need to solve the problem of expanding the Uyghur relation extraction corpus and try to promote the recall value.
Author Contributions
A.H. and K.A. conceived and designed the experiments; A.H. performed the experiments; K.A. analyzed the data; T.Y. contributed materials; A.H. wrote the paper; T.Y. revised the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Grant Nos. 61762084, 61662077, and 61462083), the Opening Foundation of the Key Laboratory of Xinjiang Uyghur Autonomous Region of China (Grant No. 2018D04019), and the Scientific Research Program of the State Language Commission of China (Grant No. ZDI135-54).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Nogueira, C.; Santos, D.; Xiang, B.; Zhou, B. Classifying relations by ranking with convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 626–634. [Google Scholar]
- Han, X.; Liu, Z.; Sun, M. Neural knowledge acquisition via mutual attention between knowledge graph and text. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zeng, X.; Zeng, D.; He, S. Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 506–514. [Google Scholar]
- Luan, Y.; He, L.; Ostendorf, M.; Hajishirzi, H. Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3219–3232. [Google Scholar]
- Fader, A.; Zettlemoyer, L.; Etzioni, O. Open question answering over curated and extracted knowledge bases. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, San Diego, CA, USA, 24–27 August 2014; pp. 1156–1165. [Google Scholar]
- Xiang, Y.; Chen, Q.; Wang, X.; Qin, Y. Answer selection in community question answering via attentive neural networks. IEEE SPL 2017, 24, 505–509. [Google Scholar] [CrossRef]
- Lehmann, J.; Isele, R.M.; Jakob, A.J.; Bizer, C. DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web J. 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Zhou, P.; Shi, W.; Tian, J. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Xu, K.; Feng, Y.; Huang, S. Sematic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Proceeding, Lisbon, Portugal, 17–21 September 2015; pp. 536–540. [Google Scholar]
- Zeng, D.; Liu, K. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Proceeding, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z. Neural Relation Extraction with Selective Attention over Instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1083–1106. [Google Scholar]
- Xu, Y.; Mou, L.I. Classifying Relation via Long Short Term Memory Networks along Shortest Dependency Paths. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Proceeding, Lisbon, Portugal, 17–21 September 2015; pp. 1785–1794. [Google Scholar]
- Liu, Z.; Sun, M.; Lin, Y.; Xie, R. Knowledge representation learning: A review. J. Comput. Res. Dev. 2016, 53, 247–261. [Google Scholar] [CrossRef]
- Abiderexiti, K.; Maimaiti, M.; Yibulayin, T.; Wumaier, A. Annotation schemes for constructing Uyghur named entity relation corpus. In Proceedings of the 2016 International Conference on Asian Language Processing (IALP), Tainan, Taiwan, 21–23 November 2016; pp. 103–107. [Google Scholar]
- Parhat, S.; Ablimit, M.; Hamdulla, A. A Robust Morpheme Sequence and Convolutional Neural Network-Based Uyghur and Kazakh Short Text Classification. Information 2019, 10, 387. [Google Scholar] [CrossRef]
- Takanobu, R.; Zhang, T.; Liu, J. A Hierarchical Framework for Relation Extraction with Reinforcement Learning. arXiv 2018, arXiv:1811.03925. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Verspoor, K. End-to-End Neural Relation Extraction Using Deep Biaffine Attention. In Proceedings of the 41st European Conference on Information Retrieval (ECIR 2019), Cologne, Germany, 14–18 April 2019; pp. 1–9. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Li, Q.; Ji, H. Incremental joint extraction of entity mentions and relations. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 23–25 June 2014; pp. 402–412. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using LSTMs on sequences and tree structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1105–1116. [Google Scholar]
- Li, Z.; Yang, Z.; Shen, C. Integrating shortest dependency path and sentence sequence into a deep learning framework for relation extraction in clinical text. BMC Med. Inform. Decis. Mak. 2019, 19, 22. [Google Scholar] [CrossRef] [PubMed]
- Ren, X.; Wu, Z.; He, W.; Qu, M.; Voss, C.R.; Ji, H.; Abdelzaher, T.F.; Han, J. Cotype: Joint extraction of typed entities and relations with knowledge bases. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1015–1024. [Google Scholar]
- Liu, Z.; Xiong, C.; Sun, M. Entity-Duet Neural Ranking: Understanding the Role of Knowledge Graph Semantics in Neural Information Retrieval. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2395–2405. [Google Scholar]
- Xu, P.; Barbosa, D. Connecting Language and Knowledge with Heterogeneous Representations for Neural Relation Extraction. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 3–5 June 2019; pp. 3201–3206. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Fortezza da Basso, Florence, Italy, 28 July–2 August 2019; pp. 1441–1451. [Google Scholar]
- Graves, A.; Mohamed, A.-R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Yao, K.; Peng, B.; Zhang, Y.; Yu, D.; Zweig, G.; Shi, Y. Spoken language understanding using long short-term memory neural networks. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 189–194. [Google Scholar]
- Yao, K.; Peng, B.; Zweig, G.; Yu, D.; Li, X.; Gao, F. Recurrent conditional random field for language understanding. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4077–4081. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2—ACL-IJCNLP ‘09, Suntec, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Li, Y.; Jiang, J.; Chieu, H.L.; Chai, K.M.A. Extracting relation descriptors with conditional random fields. In Proceedings of the 5th International Joint Conference on Natural Language Processing, Chiang Mai, Thailand, 8–13 November 2011; pp. 392–400. [Google Scholar]
- Quan, C.; Hua, L.; Sun, X.; Bai, W. Multichannel convolutional neural network for biological relation extraction. Biomed Res. Int. 2016. [Google Scholar] [CrossRef] [PubMed]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint extraction of entities and relations based on a novel tagging scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1227–1236. [Google Scholar]
- Zhang, M.; Zhang, Y.; Fu, G. End-to-end neural relation extraction with global optimization. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 1730–1740. [Google Scholar]
- Luo, L.; Yang, Z.; Yang, P.; Zhang, Y.; Wang, L.; Lin, H.; Wang, J. An attention-based BiLSTM-CRF approach to document-level chemical named entity recognition. Bioinformatics 2017, 8, 1381–1388. [Google Scholar] [CrossRef] [PubMed]
- Wushouer, J.; Abulizi, W.; Abiderexiti, K.; Yibulayin, T.; Aili, M.; Maimaitimin, S. Building contemporary Uyghur grammatical information dictionary. In Worldwide Language Service Infrastructure. WLSI 2015; Murakami, Y., Lin, D., Eds.; Springer: Cham, Switzerland, 2016; pp. 137–144. [Google Scholar]
- Aili, M.; Xialifu, A.; Maihefureti, M.; Maimaitimin, S. Building Uyghur dependency treebank: Design principles, annotation schema and tools. In Worldwide Language Service Infrastructure. WLSI 2015. Lecture Notes in Computer Science; Murakami, Y., Lin, D., Eds.; Springer: Cham, Switzerland, 2016; pp. 124–136. [Google Scholar]
- Maimaiti, M.; Wumaier, A.; Abiderexiti, K.; Yibulayin, T. Bidirectional long short-term memory network with a conditional random field layer for Uyghur part-of-speech tagging. Information 2017, 8, 157. [Google Scholar] [CrossRef]
- Zheng, S.; Hao, Y.; Lu, D.; Bao, H.; Xu, J.; Hao, H.; Xu, B. Joint entity and relation extraction based on a hybrid neural network. Neurocomputing 2017, 257, 59–66. [Google Scholar] [CrossRef]

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).