1. Introduction
Knowledge bases (KB), such as YAGO [
1] and DBpedia [
2], which typically contain a set of concepts, instances, and relations, has become significantly important in both industry and academia [
3]. With the increasing of data size on the web, KB automatic construction approaches [
4] are proposed to extract knowledge from massive data efficiently. Due to the low-quality of raw data and the limitation of KB construction approaches, automatically constructed KBs are nagged by quality problems, which will cause serious accidents in applications. Thus, KB cleansing approaches are in great demand to increase the usability of KBs.
Many KB and database cleansing algorithms have been proposed in recent years such as building directed acyclic graph [
5] and applying other new knowledge. The main idea of the building directed acyclic graph method is to enumerate cycles and eliminate the relation with low trust because cycles are highly likely to contain incorrect relations. However, such approach focuses on the structure and level of the KB with the perspective of a graph, and does not have the ability to detect low frequency errors that are not included in a cycle. As a contrast, our method is good at dealing with low-frequency data. As for applying other new knowledge such as another KB or internet knowledge, it would take lots of time and each KB contains its unique relations that would be very different from the one that we are dealing with. A statistical regression method is a kind of mathematical method [
6]. It uses statistical technology for data integration. This method is mainly aimed at dealing with the linear relationship in the knowledge map. By dealing with the quantitative relationship between digital attributes, we can get the return method for the linear relationship. It is obvious that regression is only effective for finding linear relationships. However, this method can not get an effective solution to the nonlinear relationship. Therefore, this method is not very effective for most knowledge maps.
In summary, these algorithms focus on the structure of the knowledge graph and external knowledge without sufficient usage of the relations in the KB that need to be cleansed. When we think about concepts, we usually consider the relation of two concepts. For example, bird and fish are two conflicting concepts while bird and animal are two related concepts. Motivated by this, we attempt to adopt the relations between instances sets corresponding to the concepts for effective KB cleansing. Such approach brings the following technical challenges.
First, in a KB, the frequency of many relations is 1. For example, in Probase, 7M relations only emerge once. Thus, we can hardly derive error from frequency and have to seek frequency-independent error detection approaches. Second, current KBs are almost in large scale, which leads to inefficient data accessing during KB cleansing. It requires sophisticated data structures and algorithms for cleansing algorithms to achieve high performance. Third, with the existence of homonyms, even though a conflicting is discovered, it should be distinguished whether it is caused by incorrect triples or homonyms. Such distinguishing is crucial for cleansing strategy determination and in great demand.
Facing these challenges, we attempt to develop efficient KB cleansing algorithms in this paper. We observe that the relation between concept sets corresponding to conflicting concepts could be adopted for KB cleansing.
Considering the example for motivation, the concepts of bird and fish are conflicting, which means a creature could not be both a fish and a bird. Therefore, the incorrect triple (eagle, Isa, fish) in Probase is detected since eagle is in the intersection of the concept sets corresponding to fish and bird.
Based on this observation, we develop two error detection algorithms with different kinds of distance measures between concept sets from different aspects. For effectiveness issues, these algorithms adopt Hamming distance and Jaccard distance respectively to take advantage of more trustworthy relations and take full use of the total domain size. These two algorithms could allow us to take full use of the information provided in the Knowledge base itself. All of these algorithms are based on set distance computation. For efficiency issues, the optimization of set distance computation is easier than that of a large graph since complex structural information is not required to be collected and existing similarity join method for sets could be applied. To accelerate processing, we apply Simhash and Minhash LSH (Locality Sensitive Hashing for these algorithms, respectively.
For detecting incorrect triples, we develop a two-level repair mechanism for a more accurate result. For the easy cases, we repair the triples according to frequencies. When the frequency-based approach does not work, we develop the crowdsourcing-based repair approach to distinguish homonyms.
Furthermore, in the past, many different algorithms have been proposed for homonym extraction such as the simple lexical patterns [
7], statistical, and machine learning techniques [
8]. The usage of Isa relations are often used in induction of taxonomies. However, there are lots of errors in the automatically constructed KBs with low frequency findings in the corpus and web, and it is a big challenge to detect and repair them.
About the hash method, several hash methods have been largely used on detecting duplicate web pages and eliminating them from search results (AltaVista search engine) [
9], and they have also been applied in large-scale clustering problems, such as clustering documents by the similarity of their sets of words [
10]. These hash methods also give us a technique for quickly estimating how similar the two sets are. Therefore, we could apply these methods in our research.
Then, we talked about error detection. Many attempts have been proposed to detect and resolve conflicts in knowledge bases. Li et al. [
11] proposed the OWL-based method to detect several conflict types and resolve them in RDF knowledge base integration. Liang et al.proposed to enumerate cycles and eliminate the relation with low trustworthy score [
5]. However, these methods do not pay attention to the properties of concept. In our paper, we propose to use the set views according to the Knowledge base.
The contributions of this paper are summarized as follows:
First, we detect errors in KBs according to the relation between the concept sets. Such approach makes full usage of the Isa relationship between concepts and is easy to accelerate for set operations. Second, we develop three efficient KB error detection algorithms for various distances with acceleration strategies as well as the two-level repair algorithm. Such KB error detection and repairing algorithms achieve universal by diversification. Third, experimental results demonstrate that the proposed algorithms outperform existing approaches and could cleanse the KB efficiently and effectively.
This paper is organized as follows. In
Section 2, we discuss our distance-based model, containing corresponding concepts and calculation method of distance. In
Section 3, we show how we do error detection with our distance-based model. In
Section 4, we introduce our algorithm used for repairing. In
Section 5, we conduct experiments.
Section 6 and
Section 7 will be related work, discussion, and conclusions.
2. Distance-Based Models
Even though some KB error detection methods have been proposed, they fail to fully make use of the relations in KB. Major KB error detection approaches could be classified into two kinds.
One is the frequency-based approach [
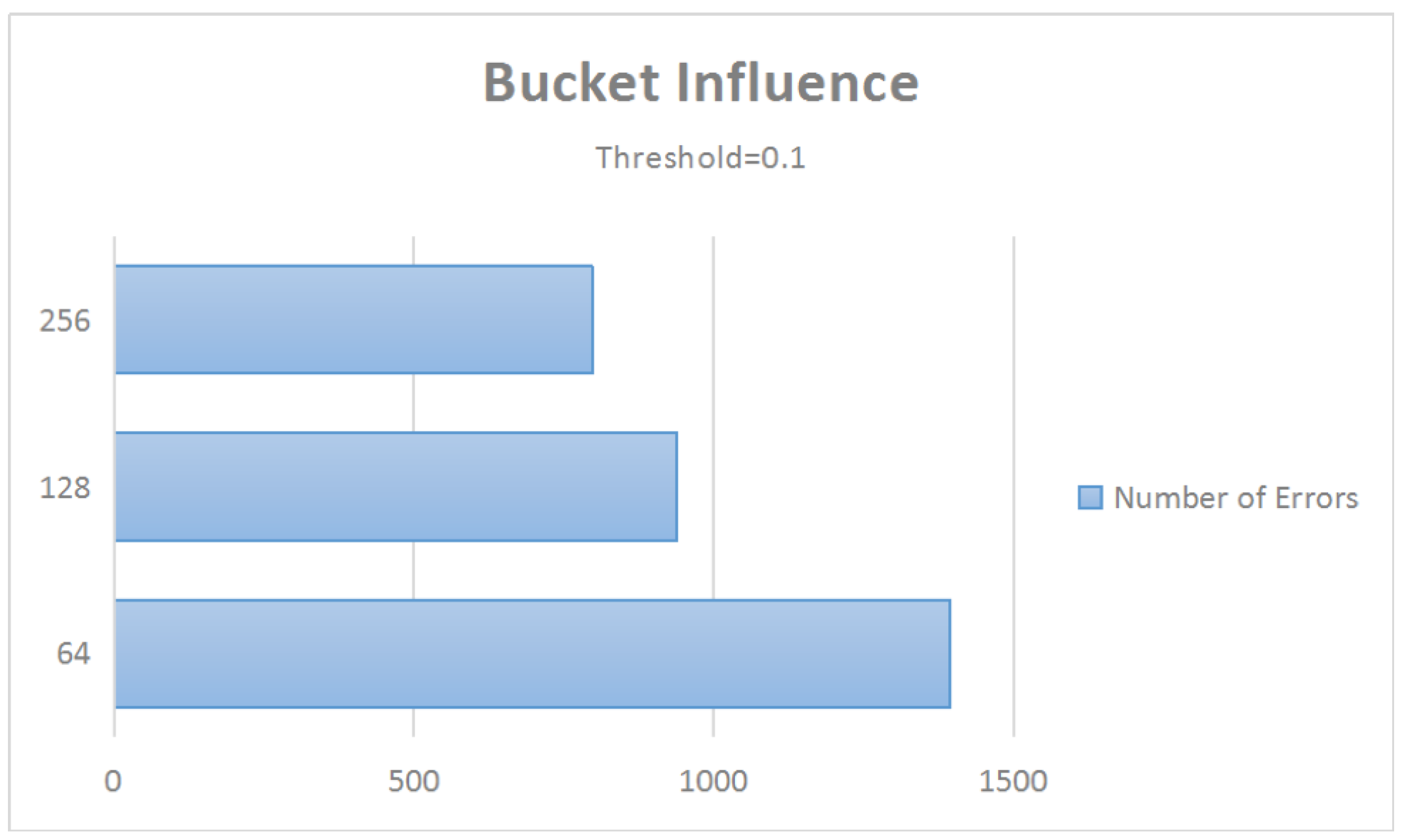
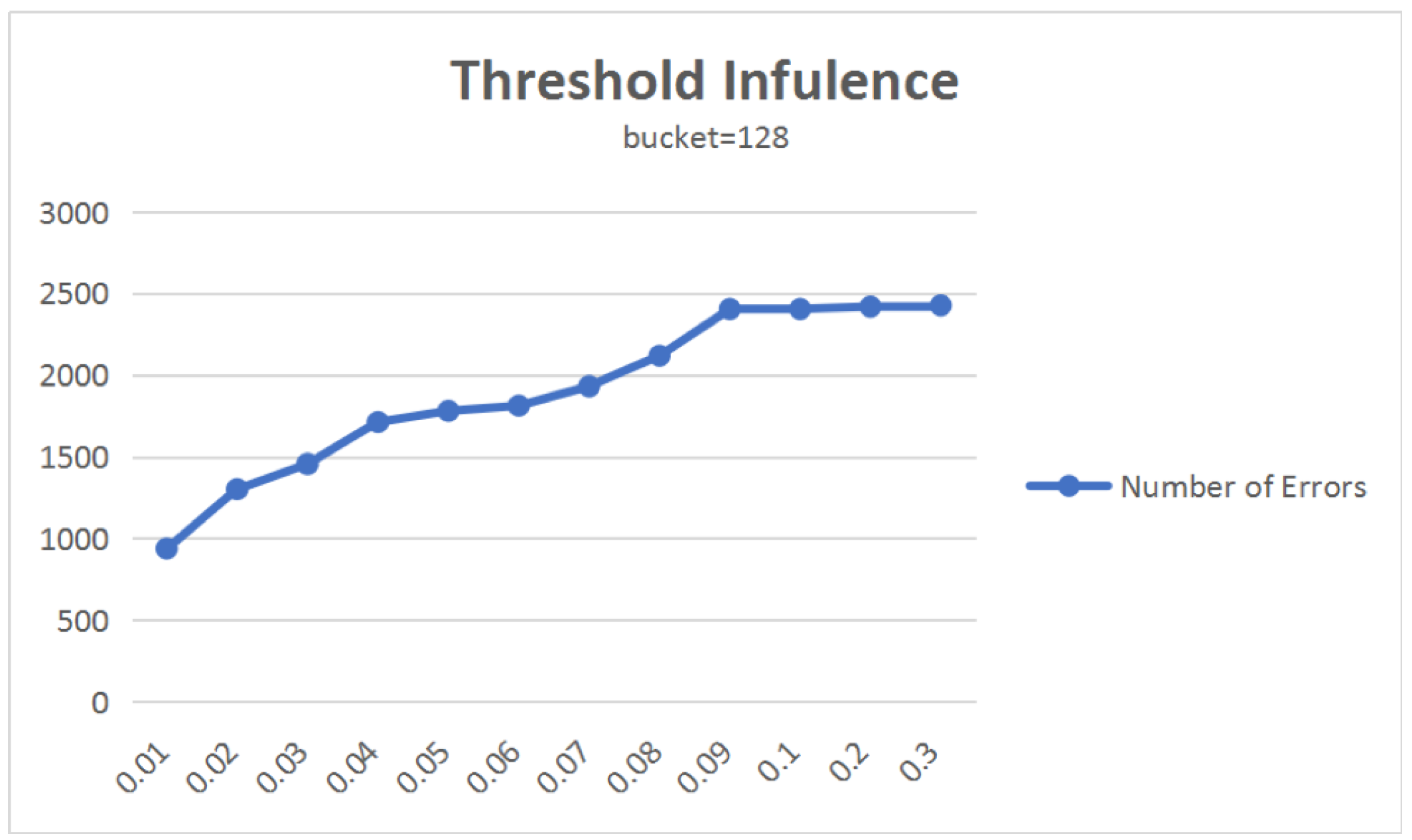
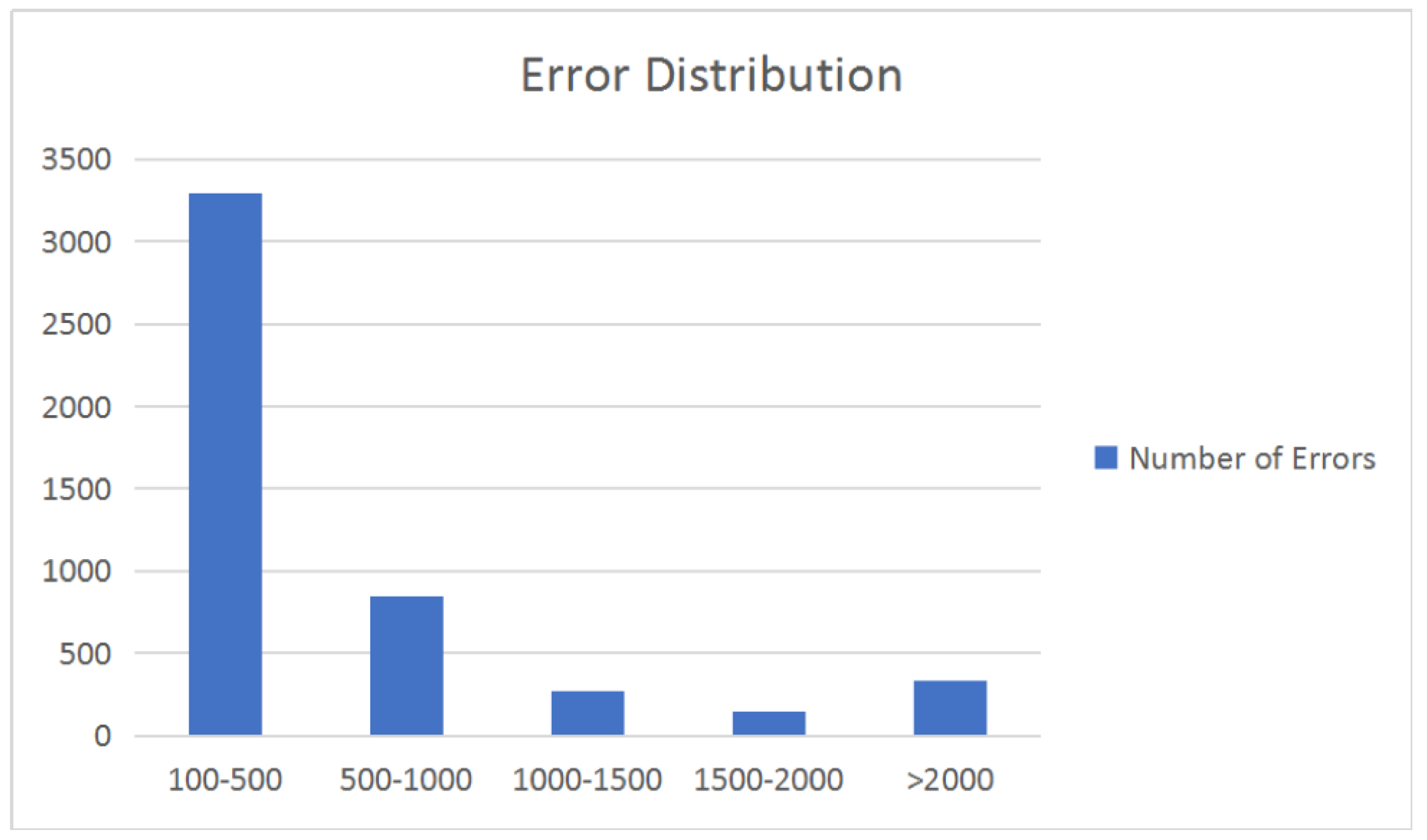
12]. The low frequency means that the relation is seldom noticed in the corpus or the web. Therefore, some approaches have been proposed to use frequency to determine whether a relation is correct or not. Clearly, many relations with low frequencies are correct. In Table (a), we list the percentage of frequencies in different range. We randomly selected 100 relations in the Probase [
5] to check the correctness, and the answer is given by human judgment. In addition, we list the correctness rate of these data with different frequencies in Table (b). From this experiment, just using frequency to determine whether a relation is wrong could be an unwise way to find errors and would achieve a low accuracy. We give specific example to show its limits.
Example 1. The frequencies of triples (snake, Isa, herb) and (fruit fly, Isa, creature) are both 1 in Probase. However, the latter is correct while the former is wrong. It shows that just using frequency fails to detect many errors.
The other is structure-based approaches [
5,
13,
14]. It has been observed that most cycles in a knowledge graph contain wrong Isa relations since a prefect knowledge base should be acyclic. Therefore, eliminating cycles could correct wrong Isa relationships. However, many wrong Isa relations are not contained in any cycle since the cycle is just a specific structure and many wrong errors do not happen to be in such specific structure.
Therefore, we attempt to find a more general approach for error detection. At first, we discuss the motivation of our distance-based approaches. Then, we discuss the definition of distances as well as their combinations.
2.1. Motivations
We observe that many errors are caused by misclassification of instances to concepts. Using the example stated before, fish and bird are two obvious conflicting concept sets because there is no such creature in the world is both a bird and a fish. If the same creature belongs to the concept of both fish and bird, at least one of these two Isa relations are wrong. According to this intuition, we detect errors using the intersection of conflicting sets.
We first define some related concepts.
Definition 1 (Concept Sets).Given a Knowledge base with Isa Relation, the weighted concept sets constructed based on this KB contains all the instances which have Isa relation with the concepts, and each instance is associated with a weight w(p).
For example, we use the instance stated before, fish is a concept in Probase, and we build a concept set called fish, which contains all the instances such as tuna, salmon and catfish. In addition, if we use the frequency as the weight w(p), the weight of these three are 1892, 3733, and 562.
Definition 2 (Conflicting Concept Sets).Given all the concept sets in a Knowledge base with Isa Relation. Consider two of these concept sets each, if these two concepts are incompatible in semantics, their corresponding concept sets are called conflicting concept sets.
For example, we could construct concept sets bird and fish from the knowledge base according to Definition 1. It is obvious that bird and fish are conflicting concept sets since they are incompatible in semantics.
We now show how to use the intersection of two Concept Sets to detect error. In the figure showed above, we present two kinds of relations of concept sets in the knowledge base.
Figure 1 shows two similar concept sets, which means each set has some similar properties with the other, while
Figure 2 shows two conflicting concept in semantics, which means the Conflicting Concept Sets stated before. It is obvious that the intersection of two Conflicting Sets contains errors of misclassification of instances. Therefore, computing the intersection of conflicting concept sets allows us to detect errors of low frequency with high accuracy. Clearly, the ideal intersection of two conflicting concept sets should be empty. On the other hand, if their intersection is not empty, errors have a highly probability to occur on the instance in their intersection. In this way, we perform error detection with set operations, which are pretty efficient. Additionally, this approach is not affected by the frequencies.
For a human, it is easy to distinguish conflicting concepts. However, the challenge is to find them automatically in massive knowledge bases. Inspired by the similarity measure for documents [
15], we attempt to use the distance between concept sets to determine conflicting sets. Intuitively, with the assumption that a KB is large enough to contain all instances of each concept, if two concept sets are very different in their instances, they are different in semantics correspondingly. Based on this intuition, we determine the conflicting concept sets according to the distance. Thus, the definition of distance is crucial to conflicting concept sets determination, and we will discuss it in the next subsection.
3. Detecting Algorithm
In the previous section, we show the approach of distance-based error detection. Due to the large scale of KBs, efficient and scalable algorithms are in demand. Thus, in this section, we develop efficient distance-based error detection algorithms.
Definition 3 (Signature).Transform the concept set into a stringwith some kind of hash function. Regard the stringas the signature of the concept set.
For efficiency issues, we adopt the hash method for the acceleration. That is, for each concept set S, we generate a signature . Thus, a set S is generated for all signatures. Then, a distance join operation, which is similar to the similarity join, is performed on S to generate the results.
For these three distances, we apply different hash functions and distance join strategies for efficiency issues.
Simhash Method for Hamming distance: Simhash is a fast algorithm for us to calculate Hamming distance in large scale data. However, one significant characteristic of this method is that it makes use of the weights of every instance, so the hash signature of each concept set is mainly depending on the larger weighted instance, and the smaller instance relation only acts as a very small influence; therefore, it is useful to distinguish the conflicting when the two concept sets are very different with each other, while Hamming distance could not distinguish when two concept sets have very different domain sizes.
Minhash LSH Method for Jaccard distance: Minhash LSH is also a very useful method in dealing with the document duplicate removal or web page comparing, and it is based on the Jaccard distance; the main advantages of Minhash LSH are that it could produce the Jaccard distance in a very short time; therefore, it is suitable for gigantic data size. However, as stated before, Jaccard distance faces two problems: the subset inclusion relations problem and the big set domain size influence.
Combination of Simhash Method and Minhash LSH Method: In order to find more conflicting concept sets with high accuracy, we propose to combine the Simhash Method and Minhash LSH Method stated above. The Simhash Method could make full use of the high frequency information according to each relation because higher frequency represents higher trustworthiness. Therefore, the Simhash Method could find conflicting concept sets which have very little of the same high frequency relations in both of the concept sets, but it does not consider the differences between domain size and the influence of low frequency relations. However, the Minhash LSH Method makes full use of domain size and regards each relation with the same importance without considering frequency. Therefore, both the Simhash Method and Minhash LSH Method could find conflicting concept sets with high accuracy, but each of them may ignore some kind of conflict while the other could detect just as stated above. In addition, we will discuss our two-level repair method in the next section.
Therefore, to make a better detection, we propose to use the Combination of Simhash Method and Minhash LSH Method for general Knowledge base. In addition, if we are detecting a Knowledge base without frequency, we propose to use the Minhash LSH Method.
4. Repairing Algorithm
After computing the conflicting concept sets, we could achieve our main purpose of KB cleansing by computing the intersection of conflicting concept sets. Our main purpose is to repair errors, and there are another two kinds of relations that can be detected in the intersection of conflicting concept sets. The following variables, L and B, are thresholds specially chosen. We’ll use them to judge which situation the word in intersection is in and then we decide what to do in the situation.
Definition 4 (Errors).Given all the relations in an intersection of two conflicting concept sets, if there is an instance P with large differences between two weights regarding two different concept sets, the larger weight is bigger than B, and the low weight is smaller than L, then the relationship R with the smaller weight according to instance P is the error.
For Examples, consider the intersection of bird and fish concept sets as we discussed before, and the frequency of turkey Isa bird in Probase is 211, which means that there are 211 sentences containing this Isa relation. In addition, the frequency of turkey Isa fish in Probase is 1. It is obvious that turkey belongs to bird not fish. Therefore, we could say that the relationship turkey Isa fish is an error.
Since the concept sets we are dealing with are conflicting with each other, for the second level of repairing, we could use the frequency in the KB as the weight to decide which relations should be deleted. At the same time, we could also apply different weights for cleansing according to different situations.
Definition 5 (Homonyms).Given all the relations in the intersection of two conflicting concept sets, if there is an instance P with both large weights, where the weights are both bigger than B, then the relations in both concept sets can be correct, and P is a homonym instance in both concept sets.
As we stated before, the relationships in the intersection of two conflicting concept sets can be both correct because one instance could have multiple meanings. However, in the experiment, we find that conflicting concept sets could have very little homonyms because the similarity degree of these two sets is significantly low. Therefore, we propose the idea to give these instances sub-attributions to identify them in the different relations and concepts.
Definition 6 (Suspicious relations).Given all the relations in the intersection of two conflicting concept sets, if there is an instance P with both very low weights regarding the both concept sets, where the weights are both lower than L, then the relations in both concept sets are suspicious.
We still consider the intersection of bird and fish conflicting concept sets, the frequency of maple Isa fish is 1, and the frequency of maple Isa bird is also 1. As humans, we could successfully judge these two relations to be both errors, but, if we look at the intersection of fish and herb, the frequency of health supplement Isa fish is 1, and the frequency of health supplement Isa herb is also 1. As humans, we view these two relations differently according to different people; therefore, it is hard to automatically distinguish these suspicious relations.
We notice that the suspicious instances are usually both seldom using relations or even wrong relations in the conflicting concept sets. In addition, it is even hard for human to raise up an agreement of right or wrong of these relations. Our cognition could provide very different conclusions. Therefore, there is no efficient automatically way to efficient classify these suspicious relations. In the experiment, we propose to build a suspicious knowledge base(SUSKB) and put these suspicious relations into SUSKB, and people could manually remove these relations in the SUSKB as they want.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}