1. Introduction
Presently, the social network market grows both in number of operators and in number of posts, exponentially. With millions of monthly active users, both on mobile devices and web browsers, Instagram represents a leading platform in this market. Launched in 2010, it has gradually gained a leading role among photo-sharing platforms, introducing several innovative features over times, including—not exhaustively—filters, stories, and an internal messaging system. Recently, these features have attracted not only ordinary users and photography enthusiasts, but also companies, organizations and global brands, thanks to the possibility that Instagram has offered to explore new business models and marketing strategies.
In such a context, approaches aimed to predict the popularity of social content are gaining increasing attention, not only from a commercial and industrial standpoint, but also from a scientific perspective. Indeed, thanks to the advancement of knowledge in the fields of data analysis and artificial intelligence, together with the development of new techniques based on Machine/Deep learning, Reinforcement Learning, Natural Language Processing (NLP), Data mining, Big Data, etc. [
1,
2,
3,
4,
5,
6,
7], it is now possible to provide advanced tools for companies and individuals, and promote the consolidation of these businesses in the social market. For this purpose, such tools and techniques usually aim to extract hidden information that may be exploited in several directions, spanning from targeted advertisements to political strategies.
Within this context, the present work proposes a novel approach for predicting the future popularity of Instagram posts. In particular, the existing literature often focuses on the prediction of the so-called engagement factor (i.e., the ratio between expected likes and number of followers of the account), thus addressing a regression problem. Conversely, this paper aims to determine whether, for the post to be published, the deviation from the average number of likes of recent posts will be positive or negative, therefore solving a binary classification task. More precisely, our method predicts the expected popularity class regardless of the selected media (image or video), which we assume as fixed by the user: vice versa, we analyze the metadata associated with the post (e.g., the caption, the chosen hashtags, the expected time and date of publication, the used emojis), as well as the additional information related to the account and the popularity of recent posts.
Therefore, the main contributions of this work are:
an original formulation of the problem to address, by defining it as a binary classification task, with the aim of determining whether the popularity of a future post will increase or decrease compared to the average popularity value of the past posts;
a novel approach based on feature engineering and machine-learning techniques for the prediction of the expected popularity class of posts on Instagram (although the approach is general and applicable to other social networks);
an experimental evaluation of the approach, comparing the results against a set of strong baselines, in different scenarios (obtained through an extensive exploration of the problem parameters);
a big data infrastructure that we have leveraged to run the proposed approach and that makes it scalable and flexible;
an analysis of the execution performance of the proposed algorithm, by considering a distributed cloud deployment, and by exploiting the aforementioned big data infrastructure.
The remainder of this paper is then organized as it follows. In
Section 2, we present some background notions related to the adopted machine-learning techniques, and a wide overview of the related work. Then, in
Section 3 we outline the problem to be addressed and describe it in a formal way.
Section 4 contains the procedure adopted for collecting the data and building the dataset, whereas in
Section 5 we describe in detail the proposed approach. Finally, in
Section 6 we illustrate the results of the experimental evaluation, and in
Section 7 we conclude the work, indicating some possible future developments.
4. Data Collection
In this section, we describe in detail the process adopted to build the dataset used for the study and testing of our approach.
Although some Instagram datasets already exist in the literature or are available on the web, we opted to build a new one from scratch. This choice was essentially driven by two reasons: (i) the social network sector is constantly evolving, and sees a steady emergence of new features, different recommendation policies, and explosive growth in content, therefore databases generated a few years earlier may not fully reflect the current situation; and, (ii) for the type of analysis to be performed, we needed a large dataset, with raw and genuine contents, and the widest possible set of features.
To build the dataset, we first collected a preliminary list of Instagram account identifiers, from which the full posts are extracted. The steps required for this process are depicted in
Figure 1: starting from the preliminary list of accounts, we exploited a browser extension (
https://instagramhelpertools.com/) for Google Chrome to export—for each of them—the full list of followers. Therefore, we iteratively extended the list of accounts, until a sufficiently large number of accounts was reached. Then, we leveraged our software module, developed in Python, to remove duplicates and filter accounts according to the following specifications: first, we selected
ordinary profiles only (i.e., those with less than 25,000 followers); second, we required that each selected account has at least 100 published posts; and, third, we discarded accounts with private visibility.
Once we completed this step, and we have then obtained the final list of accounts on which to build the dataset, we used our same Python module to interface with Instagram, through integration with an open-source crawler (
https://github.com/huaying/instagram-crawler). In this way, we proceeded to the extraction, on average, of the last 100 posts of each collected user; in particular, the list of complete posts of each account (along with some general profile information) has been separately stored on disk, organized in an appropriate directory as a
json file.
As already mentioned, although we also stored the URL of the visual content related to the post (i.e., the image or video) into the final
json document, this content is not taken into account by this work (it is stored for possible future purposes, see
Section 7), which instead aims to determine the popularity of a future post of Instagram according to the metadata chosen (caption, publication time, hashtags, etc.), thus assuming that the visual content itself is predetermined and not amendable. Hence, following this scheme, we collected the post and profile features described in
Table 1.
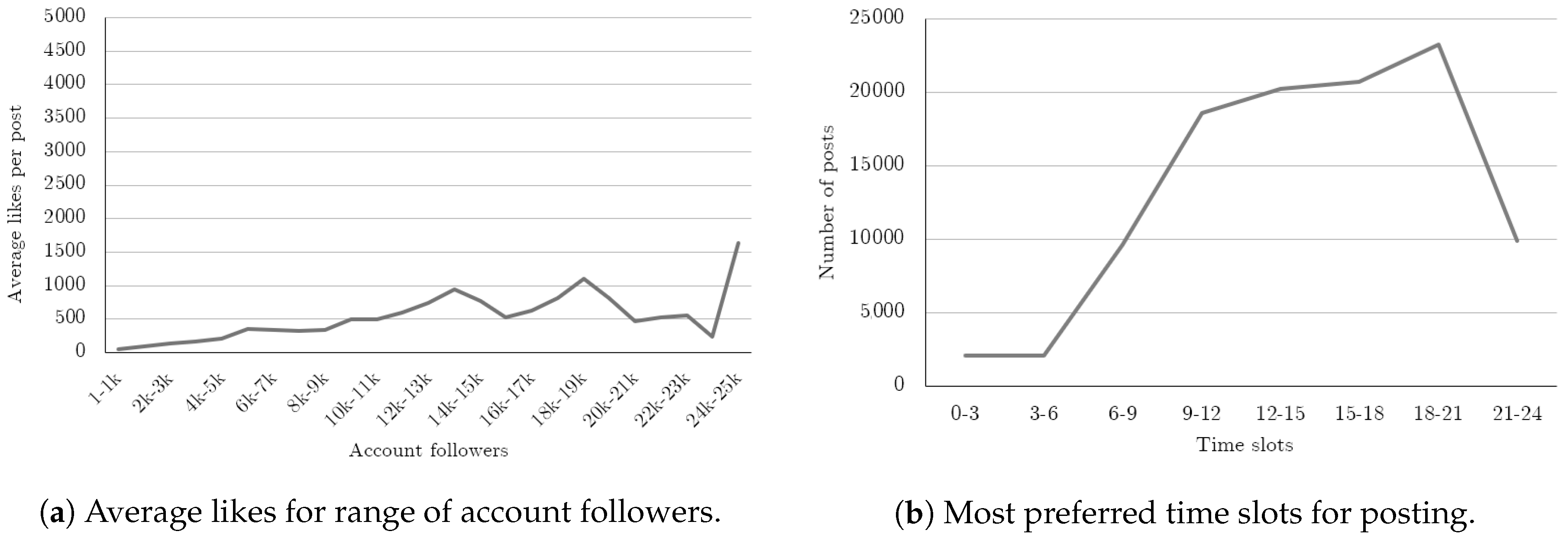
Overall, the final dataset we collected thus consists of 106,404 rows, for a total of 2545 different users. On average, each user has 2071 followers. Finally, in
Figure 2, we show some statistics related to the considered accounts: in particular, the sub-figure (a) shows that the average of achieved likes per post is, in proportion to the followers, higher for smaller accounts, whereas (b) outlines the typical publication times chosen by these accounts, in which the 18:00–21:00 time range appears to be the most popular one.
6. Experimental Evaluation
In what follows, we illustrate the experiments we carried out to validate the effectiveness of our method, performed by considering the dataset described in
Section 4.
6.5. Results
We now show the results of the experimental evaluation of our algorithm, in terms of the metrics described in
Section 6.4, and by comparing it with the baselines outlined above.
We performed a total of 12 experiments, by spanning different combinations of K (10, 30 and 50), i.e., the number of previous posts used to calculate the recent average of likes, and different values of (0, 0.05, 0.1 and 0.15), i.e., the minimum positive deviation from the average to classify the future post as popular. As an example, if we consider and , a post will be classified as popular, if its number of expected likes will be at least higher than the average likes of the last 30 posts of that user.
Specifically,
Table 5 shows the results for
and all the considered thresholds
. This is the worst-case scenario, since the prediction of the post popularity takes into account the average likes of the 10 most recent posts only, thus examining a short-term trend. Focusing on the competitors, we observe that the best baseline is the #4, although for
, the baseline 1 reaches slightly better results. In this context, our method (XGB-IP) gets the best overall performance for all the
thresholds (except for the F1-Score with
). Here, the most significant value is a 57.22% of balanced accuracy for
: in this case, we get a relative improvement of +8.59% compared to the best baseline, as well as a +7.46% compared to the Random Forest variant of our method. This gap decreases as
grows; for
, in fact, the performance is very similar to that of the competitors. A possible explanation for this behavior lies in the fact that posts that achieve a high increase in popularity compared to the account recent average are very unusual or characterized by deeper semantic peculiarities, and therefore difficult to predict by classification models that exploit the features of the proposed approach.
By moving to
(
Table 6), i.e., by increasing the number of recent posts considered, all methods considered get better results. However, our approach is confirmed as the best, with the exception—also in this case—of
(but with a result still comparable to that of baseline 4). The balanced accuracy for
is 61.19%, with a relative increase of +5.12% compared to baseline 4. We also note that for this configuration, even the variant based on Random Forest obtains a good result, but it worsens dramatically as
increases.
Finally, for , our method obtains the best overall result, with a balanced accuracy of 64.72% for (in relative terms, it means a +5.03% if compared to the best baseline, and a +3.9% if compared to the Random Forest variant), hence achieving a good predictivity.
Moreover, in this last setup, besides clearly overcoming all the competitors, the result of our method for
(i.e., the ability to predict whether the considered post will reach several likes more than 15% higher than the average of the last 50 published ones) has shown to be particularly significant. Indeed, as illustrated in
Table 7, for this difficult scenario, our XGB-IP method achieves a balanced accuracy of 62.68%, and an F1-score of 65.81%.
7. Conclusions and Future Work
In this work, we proposed an original definition of popularity for Instagram posts, by modeling it as a binary classification problem. Then, we designed a novel approach to predict such a popularity, combining feature engineering, supervised learning techniques and big data technologies.
Our method is developed to take advantage of the metadata associated with the post to be published (account data, scheduled date and time of publication, caption, etc.), regardless of the visual content proposed (video or image), and thus making it easily extensible to different social networks too. More in detail, compared to the previous literature work, our proposal introduces a new set of enriched features, with particular attention to the semantic content of the post caption, by analyzing, for instance, the sentiment score, the emojis and the popularity of the chosen hashtags. In addition, instead of simply predicting the number of expected likes, or the engagement factor, our method punctually identifies posts that are very likely to exceed (or not exceed) the average popularity of the account, providing a more suitable tool for practical use in social media management activities.
The validation of the method was performed considering two different implementations (one based on Gradient Boosting, and one based on Random Forest), against several strong baselines not based on machine-learning techniques. Notably, all the experiments were carried out on a newly built dataset of over 100,000 Instagram posts, adequately representative of common Italian and English accounts, as well as through the use of a distributed infrastructure based on AWS EC2 and Apache Spark.
The results showed that the implementation based on Gradient Boosting has a good effectiveness and is promising, reaching a balanced accuracy of 64.72%, in the real-world scenario, when considering and (i.e., when predicting that the future post will be popular if the expected likes are higher than the average of the last 50 published posts). However, the method proved to be successful in almost all the analyzed parameter thresholds, and almost always exceeded both the Random Forest-based variant and the considered baselines, in terms of balanced accuracy and F1-score. Additionally, for several thresholds, the relative improvement against the best competitor is between 4-8%. Moreover, the adoption of the distributed architecture for the training stage showed a reduction of up to 38% of the execution times, compared to a non-parallel approach, and thus making it possible to apply the method to much larger datasets, also related to different social networks and/or a greater number of features.
In light of these results, it is possible to outline some possible future research developments. First of all, the addition of new features that, for example, taking advantage of Natural Language Processing techniques already widely adopted in related research areas, allow the achievement of even higher accuracy through a deeper analysis of the caption text. Secondly, the analysis of classification tools different from those already considered, for example based on convolutional neural networks (CNNs), deep learning or deep reinforcement learning techniques, widely used presently and proven to be very powerful in analogous research contexts, which—in the presence of a very large amount of data—could lead to better performance. In addition, finally, the development of new tools that, using as input the results of our approach, can potentially help users and social media managers to optimize their contents, in order to achieve a good level of expected popularity for the new posts to be published.
Author Contributions
Conceptualization, S.C., A.S.P., D.R.R., R.S. and G.U.; data curation, S.C., A.S.P., D.R.R., R.S. and G.U.; formal analysis, S.C., A.S.P., D.R.R., R.S. and G.U.; methodology, S.C., A.S.P., D.R.R., R.S. and G.U.; resources, S.C., A.S.P., D.R.R., R.S. and G.U.; supervision, S.C.; validation, S.C., A.S.P., D.R.R., R.S. and G.U.; writing, original draft, A.S.P. and G.U.; writing, review and editing, S.C., A.S.P., D.R.R., R.S. and G.U. All authors have read and agreed to the published version of the manuscript.
Funding
This research is partially funded and supported by the Aut. Reg. of Sardinia cluster project "DoUtDes. Trasferimento di tecnologie e competenze di Business Intelligence alle aziende dei settori innovativi e tradizionali", CUP: F21B17000850005 (POR-FESR SARDEGNA 2014-2020).
Acknowledgments
The authors gratefully acknowledge Andrea Catania and Stefano R. Chessa for their useful suggestions and comments, which contribute to improve the final quality of this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Recupero, D.; Nuzzolese, A.; Consoli, S.; Presutti, V.; Peroni, S.; Mongiovi, M. Extracting knowledge from text using SHELDON, a semantic holistic framEwork for LinkeD ONtology data. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 235–238. [Google Scholar] [CrossRef]
- Consoli, S.; Recupero, D. Using FRED for named entity resolution, linking and typing for knowledge base population. Commun. Comput. Inf. Sci. 2015, 548, 40–50. [Google Scholar] [CrossRef]
- Dridi, A.; Reforgiato Recupero, D. Leveraging semantics for sentiment polarity detection in social media. Int. J. Mach. Learn. Cybern. 2019, 10, 2045–2055. [Google Scholar] [CrossRef]
- Carta, S.; Corriga, A.; Ferreira, A.; Podda, A.S.; Recupero, D.R. A multi-layer and multi-ensemble stock trader using deep learning and deep reinforcement learning. Appl. Intell. 2020, 1–17. [Google Scholar] [CrossRef]
- Barra, S.; Carta, S.M.; Corriga, A.; Podda, A.S.; Recupero, D.R. Deep learning and time series-to-image encoding for financial forecasting. IEEE/CAA J. Autom. Sin. 2020, 7, 683–692. [Google Scholar] [CrossRef]
- Carta, S.; Ferreira, A.; Podda, A.S.; Recupero, D.R.; Sanna, A. Multi-DQN: An Ensemble of Deep Q-Learning Agents for Stock Market Forecasting. Expert Syst. Appl. 2020, 164, 113820. [Google Scholar] [CrossRef]
- Presutti, V.; Consoli, S.; Nuzzolese, A.; Recupero, D.; Gangemi, A.; Bannour, I.; Zargayouna, H. Uncovering the semantics of Wikipedia pagelinks. In Knowledge Engineering and Knowledge Management; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8876, pp. 413–428. [Google Scholar] [CrossRef] [Green Version]
- Meena, K.S.; Suriya, S. A Survey on Supervised and Unsupervised Learning Techniques. In International Conference on Artificial Intelligence, Smart Grid and Smart City Applications; Springer: Berlin, Germany, 2019; pp. 627–644. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Tehrani, A.F.; Ahrens, D. Supervised regression clustering: A case study for fashion products. Int. J. Bus. Anal. (IJBAN) 2016, 3, 21–40. [Google Scholar] [CrossRef] [Green Version]
- Sen, P.C.; Hajra, M.; Ghosh, M. Supervised Classification Algorithms in Machine Learning: A Survey and Review. In Emerging Technology in Modelling and Graphics; Springer: Berlin, Germany, 2020; pp. 99–111. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Science & Business Media: Berlin, Germany, 2008. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Hecht-Nielsen, R. III.3-Theory of the Backpropagation Neural Network. In Neural Networks for Perception; Wechsler, H., Ed.; Academic Press: San Diego, CA, USA, 1992; pp. 65–93. [Google Scholar] [CrossRef]
- Grira, N.; Crucianu, M.; Boujemaa, N. Unsupervised and semi-supervised clustering: A brief survey. Rev. Mach. Learn. Tech. Process. Multimed. Content 2004, 1, 9–16. [Google Scholar]
- Cios, K.J.; Swiniarski, R.W.; Pedrycz, W.; Kurgan, L.A. Unsupervised learning: Association rules. In Data Mining; Springer: Boston, MA, USA, 2007; pp. 289–306. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Hegland, M. The apriori algorithm—A tutorial. In Mathematics and Computation in Imaging Science and Information Processing; World Scientific: Singapore, 2007; pp. 209–262. [Google Scholar]
- Pes, B. Ensemble feature selection for high-dimensional data: A stability analysis across multiple domains. Neural Comput. Appl. 2020, 32, 5951–5973. [Google Scholar] [CrossRef] [Green Version]
- Jena, P.C.; Kuhoo; Mishra, D.; Pani, S.K. A novel approach for regularization of ensemble learning in classification and regression analysis. Indian J. Public Health Res. Dev. 2018, 9, 1406–1411. [Google Scholar] [CrossRef]
- Gayberi, M.; Gunduz Oguducu, S. Popularity Prediction of Posts in Social Networks Based on User, Post and Image Features. In Proceedings of the 11th International Conference on Management of Digital EcoSystems, Limassol, Cyprus, 12–14 November 2019; pp. 9–15. [Google Scholar] [CrossRef]
- De, S.; Maity, A.; Goel, V.; Shitole, S.; Bhattacharya, A. Predicting the Popularity of Instagram Posts for a Lifestyle Magazine Using Deep Learning. In Proceedings of the 2017 2nd International Conference on Communication Systems, Computing and IT Applications (CSCITA), Mumbai, India, 7–8 April 2017. [Google Scholar] [CrossRef]
- Hong, L.; Dan, O.; Davison, B.D. Predicting popular messages in twitter. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 57–58. [Google Scholar]
- Bae, Y.; Lee, H. Sentiment analysis of twitter audiences: Measuring the positive or negative influence of popular twitterers. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 2521–2535. [Google Scholar] [CrossRef]
- Hoang, T.B.N.; Mothe, J. Predicting information diffusion on Twitter–Analysis of predictive features. J. Comput. Sci. 2018, 28, 257–264. [Google Scholar] [CrossRef] [Green Version]
- Rao, P.G.; Venkatesha, M.; Kanavalli, A.; Shenoy, P.D.; Venugopal, K. A micromodel to predict message propagation for twitter users. In Proceedings of the 2018 International Conference on Data Science and Engineering (ICDSE), Kochi, India, 7–9 August 2018; pp. 1–5. [Google Scholar]
- Naseri, M.; Zamani, H. Analyzing and predicting news popularity in an instant messaging service. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 1053–1056. [Google Scholar]
- Trzciński, T.; Rokita, P. Predicting popularity of online videos using support vector regression. IEEE Trans. Multimed. 2017, 19, 2561–2570. [Google Scholar] [CrossRef] [Green Version]
- Carta, S.; Medda, A.; Pili, A.; Reforgiato Recupero, D.; Saia, R. Forecasting E-Commerce Products Prices by Combining an Autoregressive Integrated Moving Average (ARIMA) Model and Google Trends Data. Future Internet 2019, 11, 5. [Google Scholar] [CrossRef] [Green Version]
- Peláez, J.I.; Martínez, E.A.; Vargas, L.G. Products and services valuation through unsolicited information from social media. Soft Comput. 2020, 24, 1775–1788. [Google Scholar] [CrossRef]
- Alduaiji, N.; Datta, A.; Li, J. Influence propagation model for clique-based community detection in social networks. IEEE Trans. Comput. Soc. Syst. 2018, 5, 563–575. [Google Scholar] [CrossRef]
- Boratto, L.; Carta, S. The rating prediction task in a group recommender system that automatically detects groups: Architectures, algorithms, and performance evaluation. J. Intell. Inf. Syst. 2015, 45, 221–245. [Google Scholar] [CrossRef]
- Carta, S.; Corriga, A.; Mulas, R.; Recupero, D.R.; Saia, R. A Supervised Multi-class Multi-label Word Embeddings Approach for Toxic Comment Classification. In Proceedings of the 11th International Conference on Knowledge Discovery and Information Retrieval, Vienna, Austria, 17–19 September 2019; pp. 105–112. [Google Scholar]
- Georgakopoulos, S.V.; Tasoulis, S.K.; Vrahatis, A.G.; Plagianakos, V.P. Convolutional neural networks for toxic comment classification. In Proceedings of the 10th Hellenic Conference on Artificial Intelligence, Patras, Greece, 9–12 July 2018; pp. 1–6. [Google Scholar]
- Saia, R.; Carta, S. Evaluating the benefits of using proactive transformed-domain-based techniques in fraud detection tasks. Future Gener. Comput. Syst. 2019, 93, 18–32. [Google Scholar] [CrossRef] [Green Version]
- Saia, R.; Carta, S. Evaluating Credit Card Transactions in the Frequency Domain for a Proactive Fraud Detection Approach. In Proceedings of the 14th International Conference on Security and Cryptography (SECRYPT 2017), Madrid, Spain, 26–28 July 2017; pp. 335–342. [Google Scholar]
- Saia, R.; Carta, S. A Frequency-domain-based Pattern Mining for Credit Card Fraud Detection. In Proceedings of the 2nd International Conference on Internet of Things, Big Data and Security (IoTBDS 2017), Porto, Portugal, 24–26 April 2017; pp. 386–391. [Google Scholar]
- Saia, R.; Carta, S. A fourier spectral pattern analysis to design credit scoring models. In Proceedings of the 1st International Conference on Internet of Things and Machine Learning, Liverpool, UK, 17–18 October 2017; pp. 1–10. [Google Scholar]
- Saia, R. A discrete wavelet transform approach to fraud detection. In International Conference on Network and System Security; Springer: Cham, Switzerland, 2017; pp. 464–474. [Google Scholar]
- Saia, R.; Carta, S.; Fenu, G. A wavelet-based data analysis to credit scoring. In Proceedings of the 2nd International Conference on Digital Signal Processing, Tokyo, Japan, 25–27 February 2018; pp. 176–180. [Google Scholar]
- Saia, R.; Carta, S. A Linear-dependence-based Approach to Design Proactive Credit Scoring Models. In Proceedings of the 8th International Conference on Knowledge Discovery and Information Retrieval, Porto, Portugal, 9–11 November 2016; pp. 111–120. [Google Scholar]
- Zhou, Y.; Wu, Z.; Zhou, Y.; Hu, M.; Yang, C.; Qin, J. Exploring Popularity Predictability of Online Videos With Fourier Transform. IEEE Access 2019, 7, 41823–41834. [Google Scholar] [CrossRef]
- Barbon, S., Jr.; Campos, G.F.C.; Tavares, G.M.; Igawa, R.A.; Proenca, M.L., Jr.; Guido, R.C. Detection of human, legitimate bot, and malicious bot in online social networks based on wavelets. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 1–17. [Google Scholar]
- Boratto, L.; Carta, S.; Fenu, G.; Saia, R. Semantics-aware content-based recommender systems: Design and architecture guidelines. Neurocomputing 2017, 254, 79–85. [Google Scholar] [CrossRef]
- Wu, L.; Ge, Y.; Liu, Q.; Chen, E.; Hong, R.; Du, J.; Wang, M. Modeling the evolution of users’ preferences and social links in social networking services. IEEE Trans. Knowl. Data Eng. 2017, 29, 1240–1253. [Google Scholar] [CrossRef]
- Rousidis, D.; Koukaras, P.; Tjortjis, C. Social media prediction: A literature review. Multimed. Tools Appl. 2020, 79, 6279–6311. [Google Scholar] [CrossRef]
- Reforgiato Recupero, D.; Cambria, E. ESWC 14 challenge on Concept-Level Sentiment Analysis. Commun. Comput. Inf. Sci. 2014, 475, 3–20. [Google Scholar] [CrossRef]
- Recupero, D.; Consoli, S.; Gangemi, A.; Nuzzolese, A.; Spampinato, D. A semantic web based core engine to efficiently perform sentiment analysis. In The Semantic Web: ESWC 2014 Satellite Events; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8798, pp. 245–248. [Google Scholar] [CrossRef]
- Recupero, D.; Dragoni, M.; Presutti, V. ESWC 15 challenge on concept-level sentiment analysis. Commun. Comput. Inf. Sci. 2015, 548, 211–222. [Google Scholar] [CrossRef]
- Xu, Q.S.; Liang, Y.Z. Monte Carlo cross validation. Chemom. Intell. Lab. Syst. 2001, 56, 1–11. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).

 ,
, 







{kind=link}
{kind=link}
{kind=link}