
Topic Modeling for Amharic User Generated Texts



Abstract
:1. Introduction
- We provide annotated datasets of user generated content for supervised topic modeling in Amharic [15];
- We identify the most salient features (TF-IDF, LDA or combinations) to discriminate topics by machine learning models;
- We investigate the effect of stemming with TF-IDF word feature on identification of topics of Amharic texts;
- We test the effect of SMOTE with TF-IDF word grams features on the detection of the topics of Amharic user generated texts;
- We compare the performance of machine learning techniques on their identification of topics in Amharic user generated texts.
2. Literature Review
3. Materials and Methods
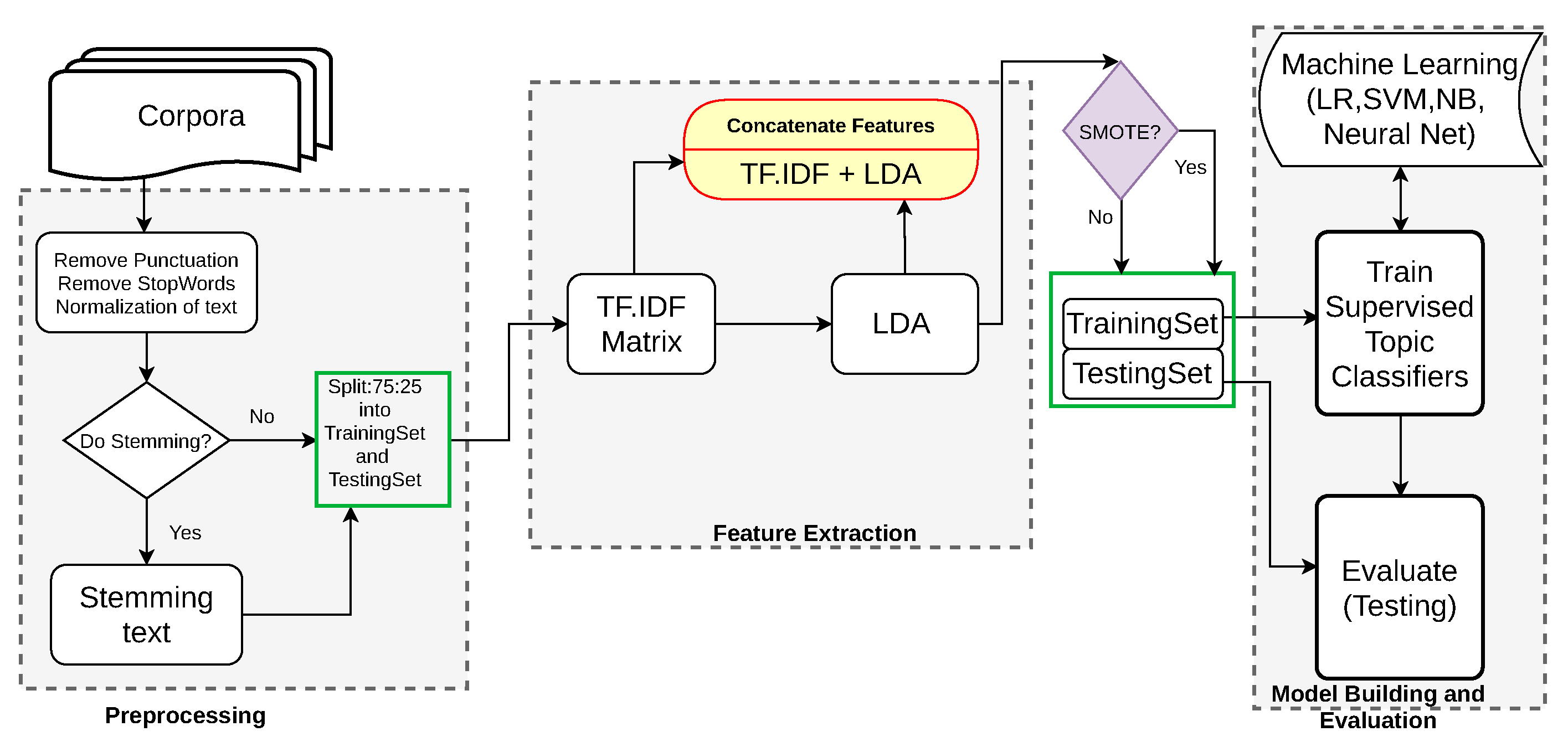
3.1. Supervised Topic Detection System
3.2. Evaluation Metrics
- (i) True Positive () is the number of samples in the positive class which are correctly detected by the model;
- (ii) True Negative () is the number of samples in the negative class which are correctly detected by the model;
- (iii) False Positive () (also called Type I Error) is the number of samples in the positive classes that are wrongly detected by the model;
- (iv) False Negative () (also called Type II Error) is the number of observations in the negative classes that are wrongly detected by the model.
- (i) Accuracy is the proportion of observations that are correctly predicted by the model, that is,
- (ii) Precision (P) is a measurement of the correctly predicted observations that are actually turned out to be positive class, that is,
- (iii) Recall (R) is a measurement of the proportion of actual positive observations, that are correctly predicted by the model, that is,
- (iv) F-score: is a measurement metrics which returns a balanced score of both recall and precision, that is,
4. Results and Discussions
4.1. Experimental Settings
4.2. Results
4.3. Quantitative Evaluation
4.4. Qualitative Evaluation
4.5. Error Analysis
5. Conclusions
- (1)
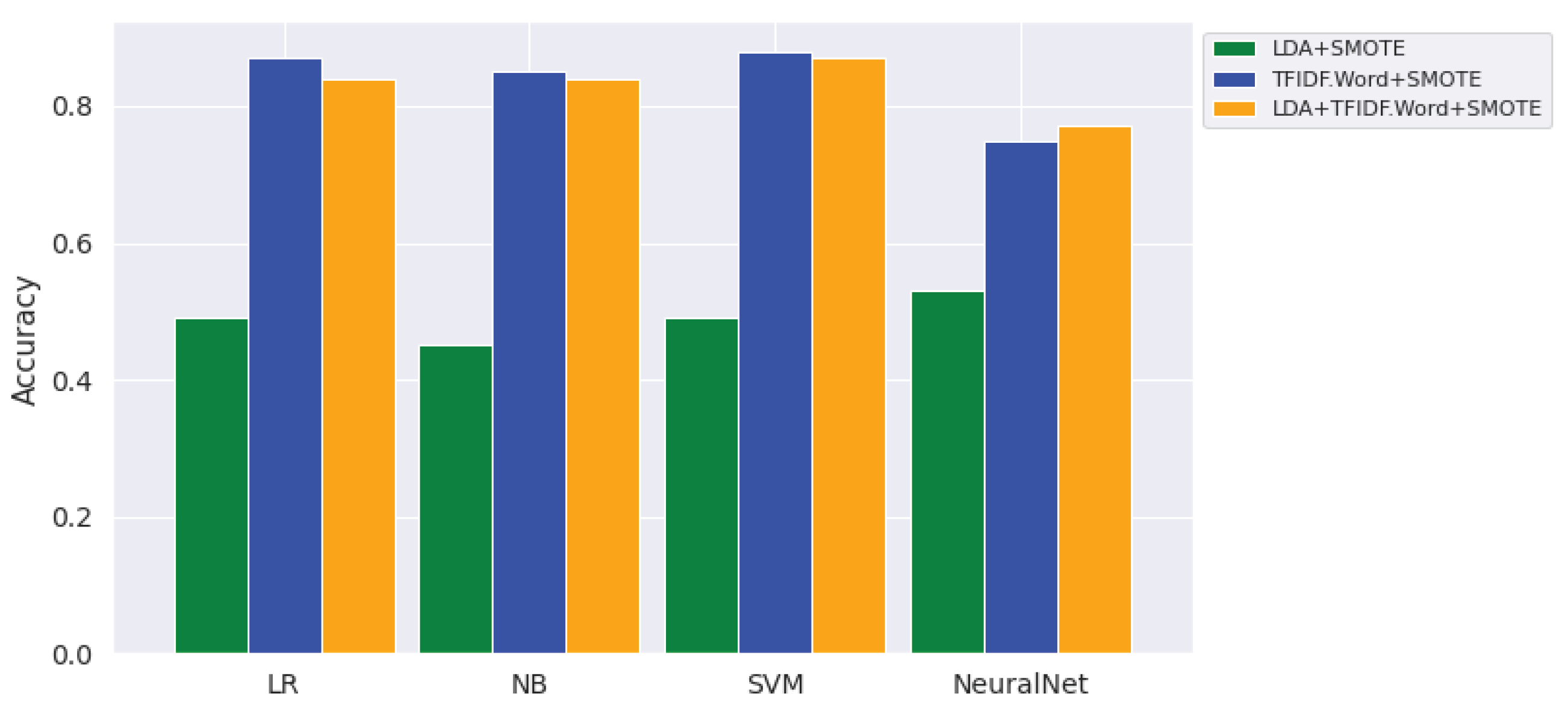
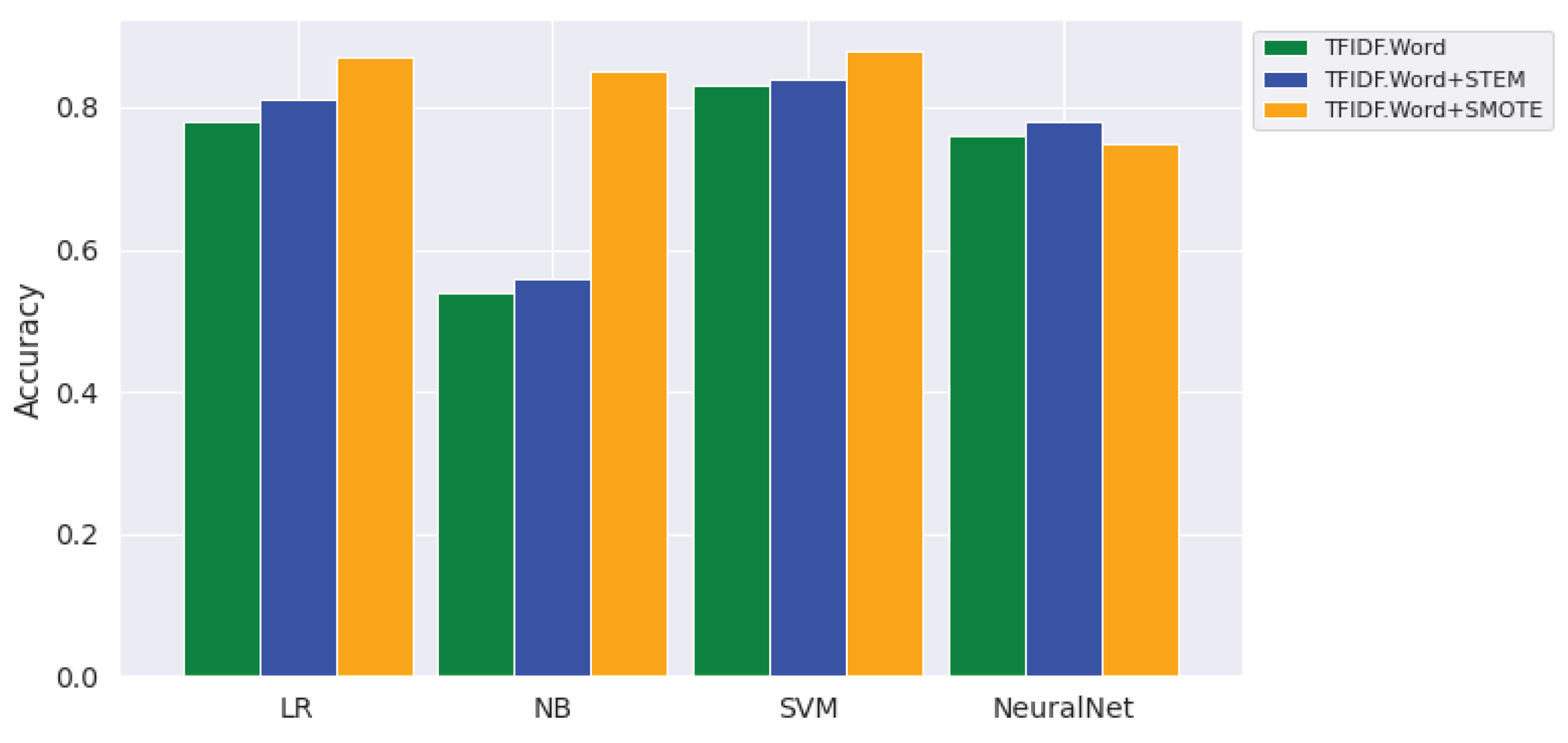
- Does LDA provide suitable feature set to discriminate Amharic user generated texts into a specific topic category? The answer to this research question is shown in Table 5 that LDA feature have the least importance in recognizing the topic of Amharic texts.
- (2)
- Do preprocessing operations, specifically stemmers, have a positive effect on topic modeling of Amharic user generated text? As is reported in Table 5, applying a stemmer to Amharic texts has a slightly improved performance of the topic classifiers compared with classifiers using features without the application of stemming. As stemming worked well in most languages [18,19,21], it could have worked well for Amharic topic classification. One of the reasons for having a poor performance of topic modeling classifiers might be the errors in the stemming algorithm itself. The other reason is that the stemmer might be a heavy stemmer, which might remove the semantic features of the input texts. In contrast, the findings can also be accepted as there is a study revealing that most of the English stemmers have also shown a negative performance of topic modeling in [20].
- (3)
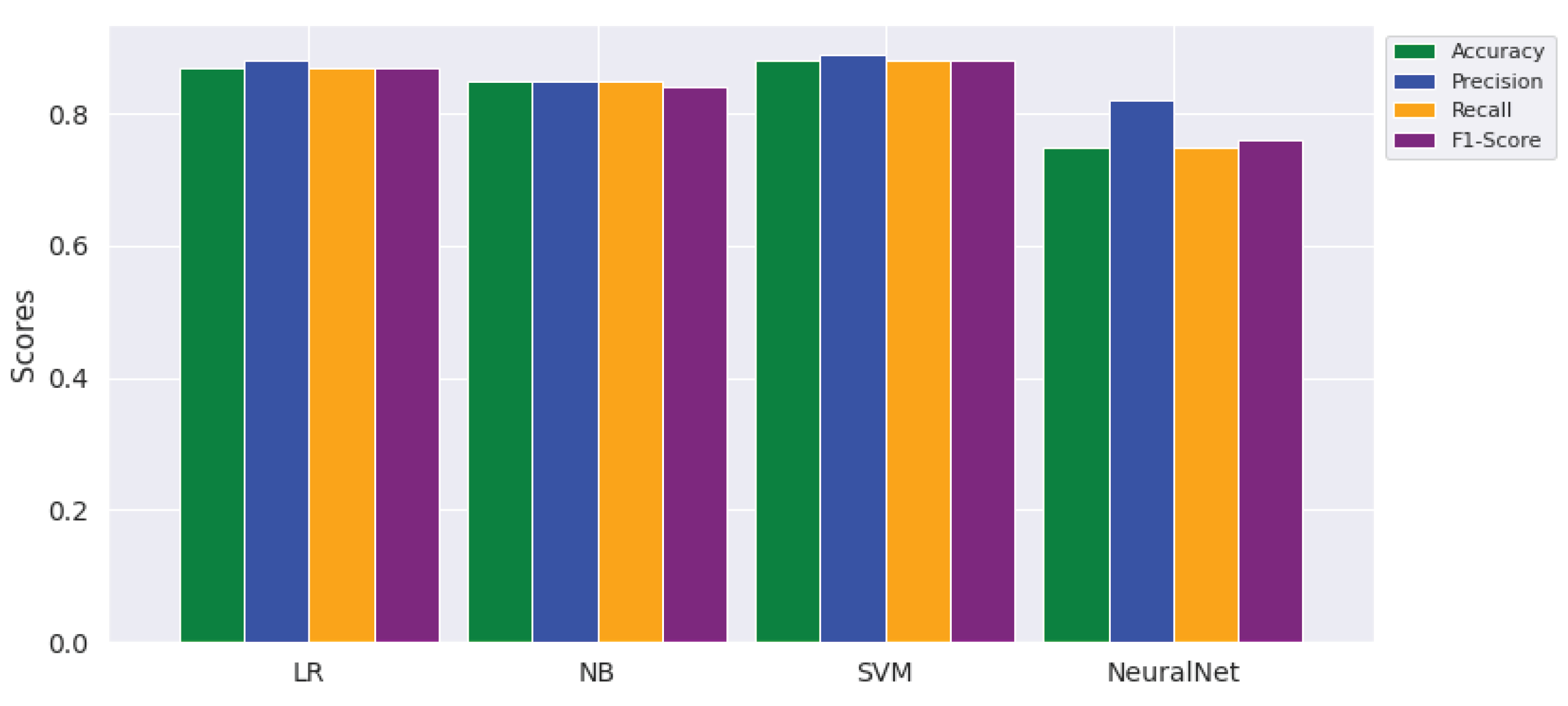
- To what extent does the supervised topic detection approach improve topic classification? The answer to this research question is presented in Table 5, that there is a large performance difference between the best topic detector (SVM with accuracy of 88%) and the worst topic detector (i.e., NB with accuracy of 40%), which is over a 48% improvement.
- (4)
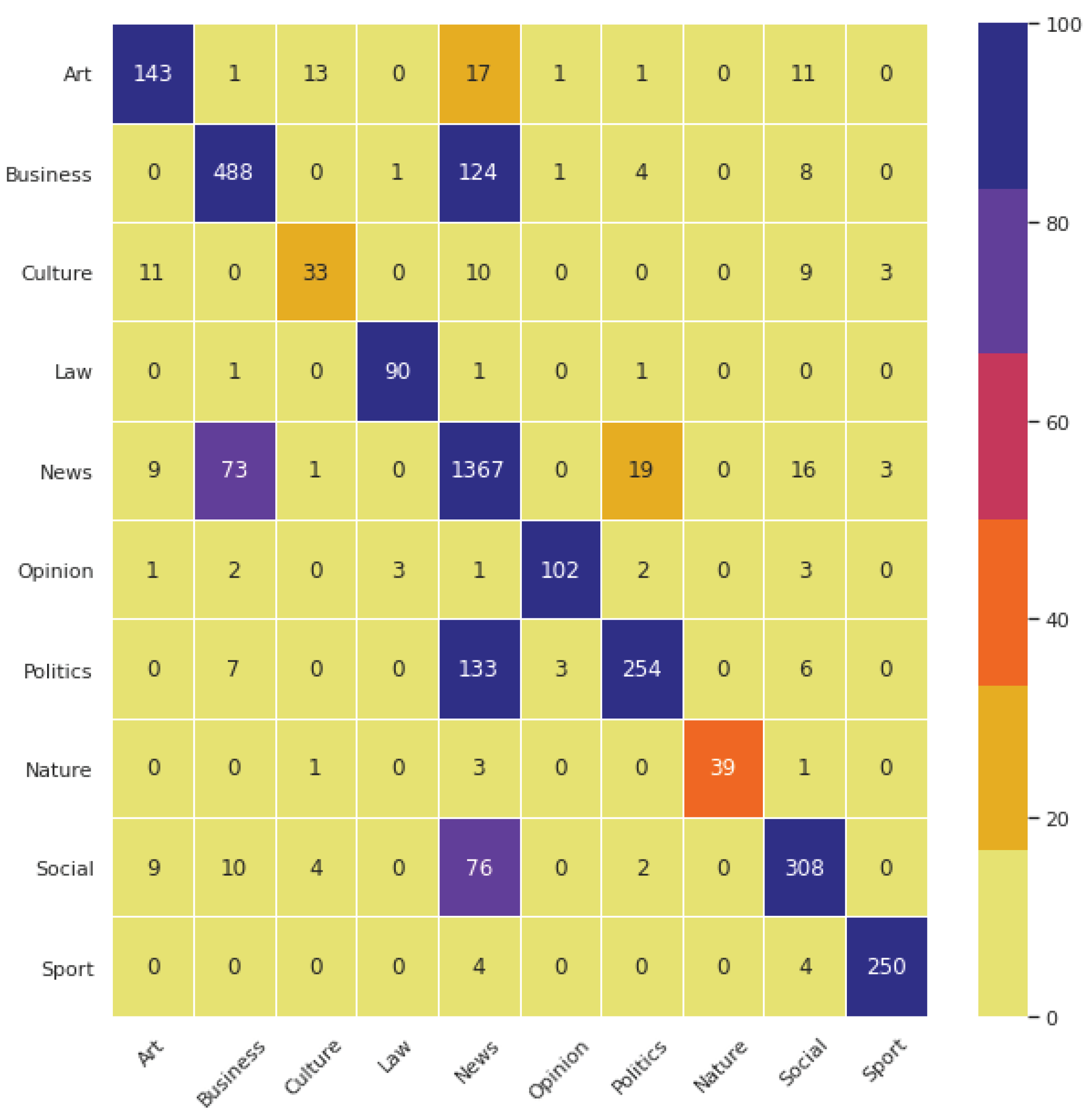
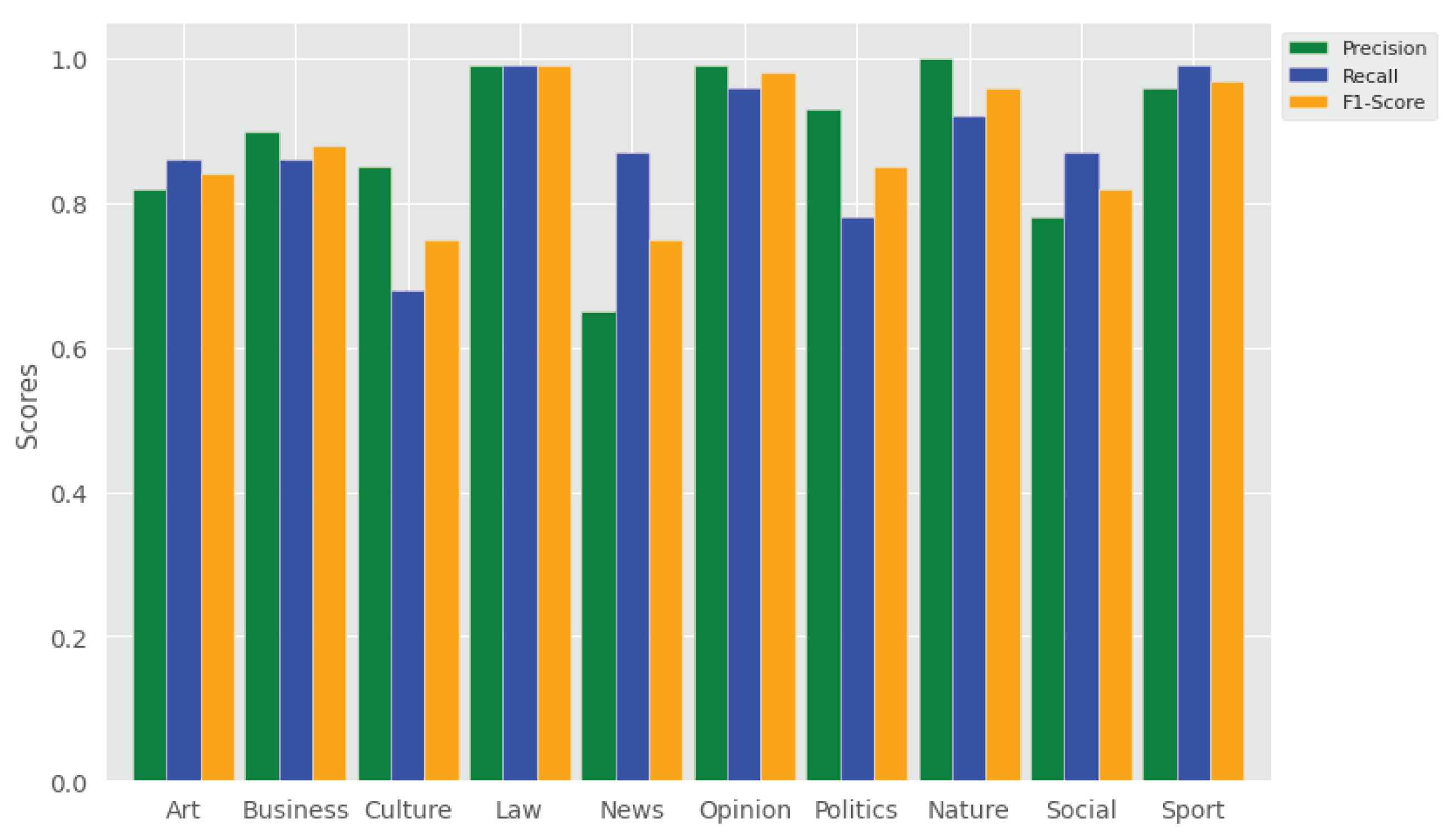
- To what extent are the topic categories accurately predicted by the trained model? The answer to this research question is shown and discussed through a qualitative evaluation of the topics learned by the models relying on the top important topic terms in the samples. The correctness of the topic terms generated by the trained model is validated and manually confirmed that it is really under that topic. This is reported in detail in the qualitative evaluation section, Section 4.4. Figure 7 also reports the performance of the topic classifiers across topic class categories. That is, the classifier performed poorly in the news category (i.e., precision 65%, recall 87%, F1 score 75%), whereas it performed the best in the law category (i.e., precision 99%, recall 99%, F1 score 99%).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SVM | Support Vector Machine |
| RF | Random Forest |
| NB | Naive Bayesian Classifier |
| LR | Logistic Regression |
| TF-IDF | Term Frequency Inverse Document Frequency |
| LDA | Latent Dirichlet Allocation |
| LSI | Latent Semantic Indexing |
| NN | Neural Network |
| KNN | K-Nearest Neighbor Classifier |
| pLSA | probabilistic Latent Semantic Analysis |
| SMOTE | Synthetic Minority Oversampling TEchnique |
References
- Shanmugam, R. Practical Text Analytics: Maximizing the Value of Text Data; Anandarajan, M., Hill, C., Nolan, T., Eds.; Springer Press: Cham, Switzerland; Taylor Francis: London, UK, 2019; ISBN 978-3-319-956663-3. [Google Scholar]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. Text Summarization Techniques: A Brief Survey. arXiv 2017, arXiv:1707.02268. Available online: https://arxiv.org/pdf/1707.02268.pdf (accessed on 9 September 2021). [CrossRef] [Green Version]
- Kowsari, K.; Jafari, M.K.; Heidarysafa, M.; Mendu, S.; Barnes, L.E.; Brown, D.E. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Shaukat, K.; Shaukat, U. Comment extraction using declarative crowdsourcing (CoEx Deco). In Proceedings of the 2016 International Conference on Computing, Electronic and Electrical Engineering (ICE Cube), Quetta, Pakistan, 11–12 April 2016; pp. 74–78. [Google Scholar]
- Claro, D.B.; Souza, M.; Castellã Xavier, C.; Oliveira, L. Multilingual Open Information Extraction: Challenges and Opportunities. Information 2019, 10, 228. [Google Scholar] [CrossRef] [Green Version]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment Analysis Algorithms and Applications: A Survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Alemneh, G.N.; Rauber, A.; Atnafu, S. Negation handling for Amharic sentiment classification. In Proceedings of the Fourth Widening Natural Language Processing Workshop, Seattle, WA, USA, 5 July 2020. [Google Scholar] [CrossRef]
- Augustyniak, Ł; Szymański, P.; Kajdanowicz, T.; Tuligłowicz, W. Comprehensive Study on Lexicon-based Ensemble Classification Sentiment Analysis. Entropy 2016, 18, 4. [Google Scholar] [CrossRef] [Green Version]
- Alemneh, G.N.; Rauber, A.; Atnafu, S. Dictionary Based Amharic Sentiment Lexicon Generation. In Proceedings of the International Conference on Information and Communication Technology for Development for Africa, Bahir Dar, Ethiopia, 28–30 May 2019; pp. 311–326. [Google Scholar] [CrossRef]
- Shaukat, K.; Hameed, I.A.; Luo, S.; Javed, I.; Iqbal, F.; Faisal, A.; Masood, R.; Usman, A.; Shaukat, U.; Hassan, R.; et al. Domain Specific Lexicon Generation through Sentiment Analysis. iJET 2020, 15, 9. [Google Scholar] [CrossRef]
- Tesfaye, S.G.; Kakeba, K. Automated Amharic Hate Speech Posts and Comments Detection Model Using Recurrent Neural Network; Research Square: Durham, NC, USA, 2020. [Google Scholar] [CrossRef]
- Vashistha, N.; Zubiaga, A. Online Multilingual Hate Speech Detection: Experimenting with Hindi and English Social Media. Information 2021, 12, 5. [Google Scholar] [CrossRef]
- Deboch, K. Short Amharic Text Clustering Using Topic Modeling. Master’s Thesis, Jimma University, Jimma, Ethiopia, 2020. [Google Scholar]
- Yirdaw, E.; Ejigu, D. Topic-based Amharic Text Summarization with Probabilistic Latent Semantic Analysis. In Proceedings of the International Conference on Management of Emergent Digital EcoSystems, Bangkok, Thailand, 26–29 October 2010; pp. 8–15. [Google Scholar]
- Neshir, G. Corpus for Amharic Topic Classification. 2021. Available online: https://zenodo.org/record/5504175#.YU3KV30RVPY (accessed on 9 September 2021). [CrossRef]
- Hofmann, M.; Chisholm, A. Text Mining and Visualization: Case Studies Using Open-Source Tools; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Gou, Z.; Huo, Z.; Liu, Y.; Yang, Y. A Method for Constructing Supervised Topic Model based on Term Frequency-Inverse Topic Frequency. Symmetry 2019, 11, 1486. [Google Scholar] [CrossRef] [Green Version]
- Alhaj, Y.; Xiang, J.; Zhao, D.; Al-Qaness, M.; Abd Elaziz, M.; Dahou, A. A Study of the Effects of Stemming Strategies on Arabic Document Classification. IEEE Access 2019, 7, 32664–32671. [Google Scholar] [CrossRef]
- Duwairi, R.; El-Orfali, M. A Study of The Effects of Preprocessing Strategies on Sentiment Analysis for Arabic Text. J. Inf. Sci. 2014, 40, 501–513. [Google Scholar] [CrossRef] [Green Version]
- Schofield, A.; Mimno, D. Comparing Apples to Apple: The Effects of Stemmers on Topic Models. Trans. Assoc. Comput. 2016, 4, 287–300. [Google Scholar] [CrossRef]
- Swapna, N.; Subhashini, P.; Rani, B. Impact of Stemming on Telugu Text Classification. Int. J. Recent Technol. 2019, 8, 2767–2769. [Google Scholar]
- Padurariu, C.; Breaban, M. Dealing with Data Imbalance in Text Classification. Procedia Comput. Sci. 2019, 159, 736–745. [Google Scholar] [CrossRef]
- Yan, B.; Han, G.; Sun, M.; Ye, S. A Novel Region Adaptive SMOTE Algorithm for Intrusion Detection on Imbalanced Problem. In Proceedings of the 2017 3rd IEEE International Conference On Computer And Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 1281–1286. [Google Scholar] [CrossRef]
- Gonzalez-Cuautle, D.; Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, L.; Portillo-Portillo, J.; Olivares-Mercado, J.; Perez-Meana, H.; Sandoval-Orozco, A. Synthetic Minority Oversampling Technique for Optimizing Classification Tasks in Botnet and Intrusion-Detection-System Datasets. Appl. Sci. 2020, 10, 794. [Google Scholar] [CrossRef] [Green Version]
- Alam, T.; Shaukat, K.; Hameed, I.; Luo, S.; Sarwar, M.; Shabbir, S.; Li, J.; Khushi, M. An Investigation of Credit Card Default Prediction in The Imbalanced Datasets. IEEE Access 2020, 8, 201173–201198. [Google Scholar] [CrossRef]
- Ah-Pine, J.; Soriano-Morales, E. A Study of Synthetic Oversampling for Twitter Imbalanced Sentiment Analysis. In Proceedings of the Workshop on Interactions Between Data Mining And Natural Language Processing (DMNLP 2016), Skopje, Macedonia, 22 September 2017. [Google Scholar]
- Neshir, G.; Rauber, A.; Atnafu, S. Meta-Learner for Amharic Sentiment Classification. Appl. Sci. 2021, 11, 8489. [Google Scholar] [CrossRef]
- Naili, M.; Chaibi, A.; Ghézala, H. Arabic Topic Identification Based on Empirical Studies of Topic Models; Revue Africaine De La Recherche En Informatique Et Mathématiques Appliquées (ARIMA): Trier, Germany, 2017; Volume 27. [Google Scholar]
- Anoop, V.; Asharaf, S.; Deepak, P. Unsupervised Concept Hierarchy Learning: A Topic Modeling Guided Approach. Procedia Comput. Sci. 2016, 89, 386–394. [Google Scholar] [CrossRef] [Green Version]
- Toubia, O.; Iyengar, G.; Bunnell, R.; Lemaire, A. Extracting Features of Entertainment Products: A Guided Latent Dirichlet Allocation Approach Informed by The Psychology of Media Consumption. J. Mark. Res. 2019, 56, 18–36. [Google Scholar] [CrossRef]
- Li, C.; Xing, J.; Sun, A.; Ma, Z. Effective Document Labeling with very few Seed Words: A Topic Model Approach. In Proceedings of the 25th Association of Computing Machinery (ACM) International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 85–94. [Google Scholar] [CrossRef]
- Jagarlamudi, J.; Daumé, H., III; Udupa, R. Incorporating Lexical Priors into Topic Models. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012; pp. 204–213. [Google Scholar]
- Kwon, H.; Ban, H.; Jun, J.; Kim, H. Topic Modeling and Sentiment Analysis of Online review for Airlines. Information 2021, 12, 78. [Google Scholar] [CrossRef]
- Tong, Z.; Zhang, H. A Text Mining Research-based on LDA Topic Modelling. In Proceedings of the International Conference on Computer Science, Engineering and Information Technology, Vienna, Austria, 21–22 May 2016; pp. 201–210. [Google Scholar]
- Liu, L.; Tang, L.; Dong, W.; Yao, S.; Zhou, W. An Overview of Topic Modeling and its Current Applications in Bioinformatics. Springerplus 2016, 5, 1–22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Foulds, J.; Smyth, P. Robust Evaluation of Topic Models. In Proceedings of the Neural Information Processing System (NIPS), Stateline, NV, USA, 5–10 December 2013. [Google Scholar]
- Korshunova, I.; Xiong, H.; Fedoryszak, M.; Theis, L. Discriminative topic modeling with logistic LDA. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 1–11. [Google Scholar]
- Ramage, D.; Hall, D.; Nallapati, R.; Manning, C. Labeled LDA: A Supervised Topic Model for Credit Attribution in Multi-labeled Corpora. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; pp. 248–256. [Google Scholar]
- Inkpen, D.; Razavi, A. Topic Classification using Latent Dirichlet Allocation at Multiple Levels. Int. J. Linguist. Comput. Appl. 2014, 5, 43–55. [Google Scholar]
- Jónsson, E.; Stolee, J. An Evaluation of Topic Modeling Techniques for Twitter. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Short Papers), Beijing, China, 26–31 July 2015; pp. 489–494. [Google Scholar]
- Chawla, N.; Bowyer, K.; Hall, L.; Kegelmeyer, W. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Alemayehu, N.; Willett, P. Stemming of Amharic Words for Information Retrieval. Lit. Linguist. Comput. 2002, 17, 1–17. [Google Scholar] [CrossRef]
- Likhitha, S.; Harish, B.; Kumar, H. A Detailed Survey on Topic Modeling for Document and Short Text Data. Int. J. Comput. Appl. 2019, 178, 1–9. [Google Scholar] [CrossRef]
- Brownlee, J. Master Machine Learning Algorithms: Discover How They Work and Implement Them from Scratch. Available online: https://bbooks.info/b/w/5a7f34e12f2f40dc87fbfda06a584ef681bc5300/master-machine-learning-algorithms-discover-how-they-work-and-implement-them-from-scratch.pdf (accessed on 3 June 2021).
- Llombart, O. Using Machine Learning Techniques for Sentiment Analysis. Available online: https://ddd.uab.cat/pub/tfg/2017/tfg_70824/machine-learning-techniques.pdf (accessed on 6 May 2021).
- Ho, R. Big Data Machine Learning: Patterns for Predictive Analytics. DZone Refcardz. Available online: https://www.bizreport.com/whitepapers/big_data_machine_learning_patterns.html (accessed on 5 June 2021).
- Scikit-Learn Machine Learning in Python. Available online: https://scikit-learn.org/stable/ (accessed on 2 June 2019).
- Yang, T.; Torget, A.; Mihalcea, R. Topic Modeling on Historical newspapers. In Proceedings of the 5th Association for Computational Linguistics (ACL)-Human Language Technologies (HLT) Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities, Portland, OR, USA, 24 June 2011; pp. 96–104. [Google Scholar]
- Resnik, P.; Armstrong, W.; Claudino, L.; Nguyen, T.; Nguyen, V.; Boyd-Graber, J. Beyond LDA: Exploring Supervised Topic Modeling for Depression-related Language in Twitter. In Proceedings of the 2nd Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, Colorado, CO, USA, 5 June 2015; pp. 99–107. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Year | Approach | Findings | Metrics | Languages | Limitations |
|---|---|---|---|---|---|---|
| [18] | 2019 | Supervised algorithms (SVM, NB and KNN) + Stemmers | ARLStem stemmer has improved performance of SVM for Arabic document classification with micro-F1 value of 94.64% over the other Arabic stemmers. | Micro-F1 score 94.64% | Arabic | The datasets used is imbalanced. i.e., entertainment (474 samples) vs. Middle East News(1462samples). |
| [19] | 2014 | Supervised Learning (SVM, NB and KNN) + Different Feature Strategies | The results show that stemming and light stemming combined with stopwords removal adversely affected the performance of the classification for the Movie dataset and slightly improved the classification for the Politics dataset | Accuracy 96.62% | Arabic | The built-in stemming algorithm in Rapidminer tool might have higher error rates which attributed to the less accuracy of experimental results, |
| [20] | 2016 | Topic Modeling | studied the effects of various stemmers of topic modeling and results has shown that stemming has not significant improvement of topic modeling. | - | English | Applying stemmers on keywords will reduce readability, to remedy this S stemmer or modified version of porter stemmer is recommended. |
| [21] | 2019 | KNN | Finding has shown an improvement of performance of text K-NN classifier while using different stemming approaches. | F1 score 82.89%, | Telugu | There is no procedures why KNN classifier is used over the other classifiers. |
| [40] | 2015 | Evaluation of topic modeling algorithms | Standard LDA has shown poor performance on short texts like in Twitter | - | English | Coherence of topics produced by the newly developed topic models are not judged by human experts |
| [28] | 2017 | Topic modeling of Arabic texts using LDA | Results shows that applying Arabic stemmers increase performance of topic identification Arabic | F1 Score 91.86%. | Arabic | Authors suggest to further study complete topic analysis based on topic models (LDA) and word embeddings. |
| [32] | 2012 | Seeded LDA | Guided LDA improved topic detection compared to model that use seed naive information | F1 score 81% | English | Allowing a seed word to be shared across multiple sets of seed words degrades the performance. |
| [33] | 2019 | Frequency based Topic detection and sentiment modeling | Topic based sentiment classification of Airline application review. | - | English | Since the limitations have not been fully resolved, future research may develop into a more feasible study if additional user information from the demographic site can be collected and utilized. |
| [17] | 2019 | supervised topic model | supervised topic model with TF-ITF outperformed the SOTA supervised topic models | Precision 53.76% | English | Better topic model will be obtained if using a variational autoencoder, which is a powerful technique for learning latent representations |
| [13] | 2020 | LDA + Word Embeddings | LDA with word embeddings with an accuracy of 97% using test set of six categories. | Accuracy of 97% | Amharic | Better feature enrichment extraction, preparation of datasets with more number of categories, and better design of LDA to cluster short texts are also recommended. |
| [14] | 2012 | PLSA + Keywords | Topic modeling using PLSA has shown encouraging result on Amharic topic summerization. | Precision/Recall 51.38% | Amharic | does not work for multiple document, query focused, update based summarization and PLSA does not consider term weightings, lack of large scale datasets for evaluation |
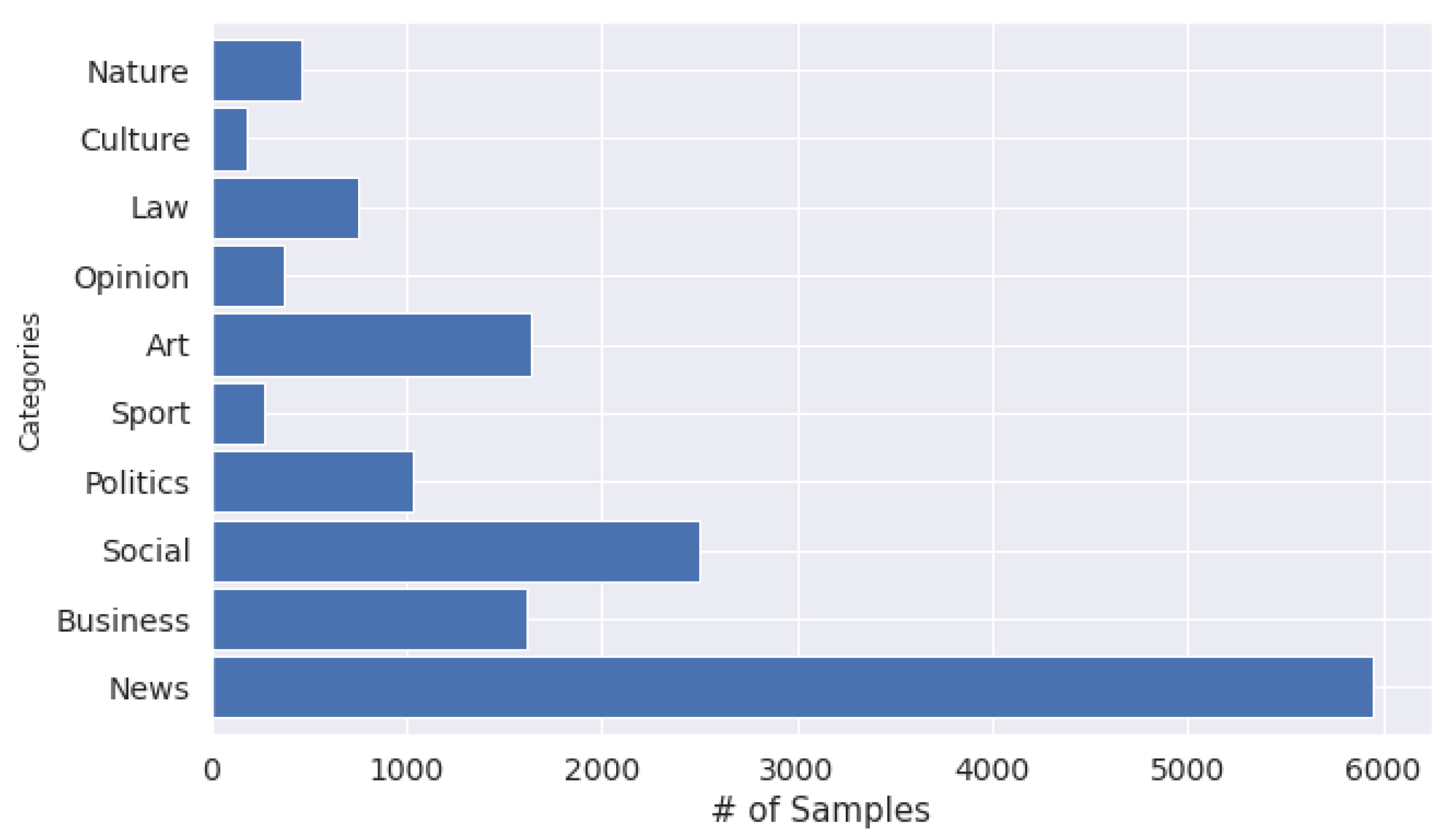
| Category | #Docs | Proportion | Avg. Length | Description of the Target |
|---|---|---|---|---|
| News | 5953 | 39.5% | 254 | Local and international news |
| Politics | 1611 | 10.6% | 593.5 | Election and other political issues |
| Business | 2502 | 16.5% | 449.4 | Financial, economical and other businesses |
| Sports | 1031 | 6.8% | 520.8 | States kinds of sports |
| Culture | 265 | 1.9% | 504.8 | States cultural events and values |
| Social | 1635 | 10.8% | 457.6 | Social activities in community |
| Laws | 371 | 2.5% | 1246.5 | States legal activities |
| Arts | 749 | 4.9% | 299.9 | States arts, music, film and entertainment |
| Nature | 176 | 1.2% | 198.6 | Related to natural resources and life |
| Opinion | 458 | 3.1% | 1197 | Comments on current issues |
| Actual Values | ||||
|---|---|---|---|---|
| Predicted Values | Positive | Negative | Total | |
| Positive | TP | FP | TP + FP | |
| Negative | FN | TN | FN + TN | |
| Total | TP + FN | FP + TN | TP + FP + FN + TN | |
| Algorithm | Hyper-Parameter | Type | Default Value | Selected Value |
|---|---|---|---|---|
| TF-IDFVectorizer | analyzer | discr | word | word |
| max_df | cont | 1 | None | |
| max_features | discr | None | None | |
| ngram_range | disc | (1,1) | (1,1) | |
| LR | C | cont | 1 | 1 |
| alpha | cont | None | None | |
| average | discr | None | None | |
| penalty | disc | l2 | l2 | |
| power_t | cont | None | None | |
| tol | cont | 0.0001 | 0.0001 | |
| NB | alpha | con | 1 | 1 |
| fit prior | cat | TRUE | TRUE | |
| SVM | C | con | 1 | 1 |
| coef0 | con | 0 | 0 | |
| degree | discr | 3 | 3 | |
| gamma | con | scale | scale | |
| kernel | disct | rbf | linear | |
| tol | con | 0.001 | 0.001 | |
| Neural Nets | hidden_layer_sizes | discr | - | (8,8,8) |
| activation | discr | - | ‘relu’ | |
| solver | discr | - | ‘adam’ | |
| max_iter | discr | - | 500 |
| Model | Metric | Exp I: WoS | Exp II: WS | Exp III: WSM | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LDA | TF-IDF | Combined | LDA | TF-IDF | Combined | LDA | TF-IDF | Combined | Train Time | Test Time | ||
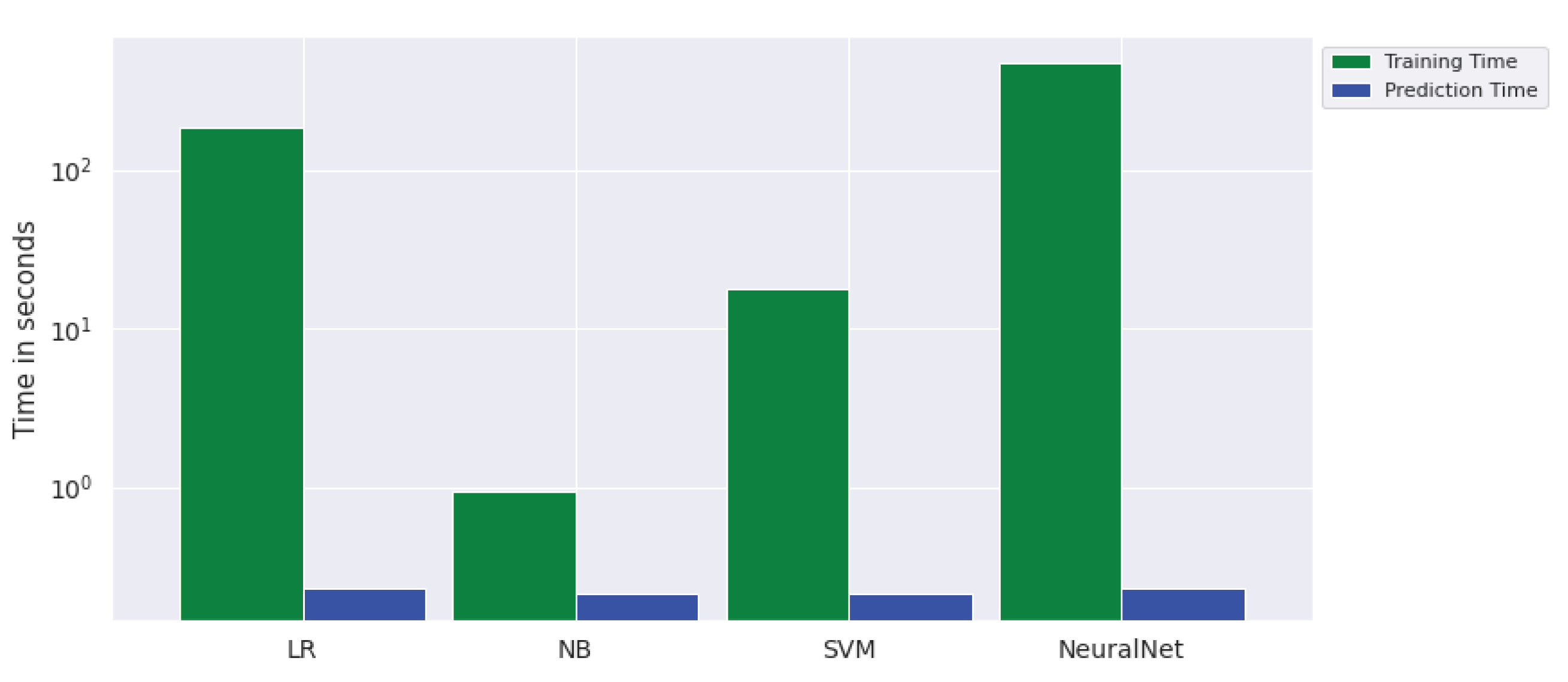
| LR | Accuracy | 0.41 | 0.78 | 0.78 | 0.40 | 0.81 | 0.81 | 0.49 | 0.87 | 0.84 | 184.11 s | 0.23 s |
| Precision | 0.25 | 0.88 | 0.88 | 0.11 | 0.86 | 0.86 | 0.53 | 0.88 | 0.86 | |||
| Recall | 0.13 | 0.67 | 0.67 | 0.10 | 0.75 | 0.75 | 0.49 | 0.87 | 0.84 | |||
| F1 | 0.11 | 0.74 | 0.74 | 0.06 | 0.80 | 0.80 | 0.46 | 0.87 | 0.84 | |||
| NB | Accuracy | 0.40 | 0.54 | 0.50 | 0.40 | 0.56 | 0.55 | 0.45 | 0.85 | 0.84 | 0.93 s | 0.21 s |
| Precision | 0.40 | 0.53 | 0.44 | 0.04 | 0.59 | 0.52 | 0.52 | 0.85 | 0.84 | |||
| Recall | 0.10 | 0.25 | 0.20 | 0.10 | 0.28 | 0.25 | 0.45 | 0.85 | 0.84 | |||
| F1 | 0.06 | 0.25 | 0.20 | 0.06 | 0.31 | 0.27 | 0.43 | 0.84 | 0.84 | |||
| SVMLin | Accuracy | 0.41 | 0.83 | 0.83 | 0.41 | 0.84 | 0.84 | 0.49 | 0.88 | 0.87 | 17.8 s | 0.21s |
| Precision | 0.24 | 0.87 | 0.87 | 0.09 | 0.86 | 0.86 | 0.52 | 0.89 | 0.88 | |||
| Recall | 0.12 | 0.81 | 0.81 | 0.12 | 0.82 | 0.82 | 0.49 | 0.88 | 0.87 | |||
| F1 | 0.09 | 0.83 | 0.83 | 0.09 | 0.84 | 0.84 | 0.45 | 0.88 | 0.87 | |||
| NeuralNet | Accuracy | 0.51 | 0.76 | 0.69 | 0.53 | 0.78 | 0.72 | 0.53 | 0.75 | 0.77 | 471.8 s | 0.23 s |
| Precision | 0.33 | 0.78 | 0.72 | 0.40 | 0.79 | 0.70 | 0.61 | 0.82 | 0.81 | |||
| Recall | 0.28 | 0.72 | 0.66 | 0.29 | 0.71 | 0.67 | 0.53 | 0.75 | 0.77 | |||
| F1 | 0.29 | 0.73 | 0.67 | 0.31 | 0.75 | 0.68 | 0.51 | 0.76 | 0.77 | |||
| Topic | Topic Words | Analysis of the Topic Words |
|---|---|---|
| ART | የሙዚቃ* ሙዚየም* አርቲስት* ሙዚቃ* ፊልም* ቴአትር* ጥበብ* ዐውደ* መጽሐፍ* ኮንሰርት*/music* museum* artist* music* film* theater* art* exhibit* book* Concert*/ | These words in Asterisks are about music, museum, Artists, film, theater, arts, books. These are all talking the topic arts |
| BUSINESS | ንግድና* ጠቅሰዋል ስለመሆኑ ስለመሆኑም ተጠቅሷል እንዲህ ባሻገር ያሉት አስታውቋል ተደርጎ/business*, mentioned, about, being, about, being mentioned, so beyond, existing, announced/ | Only one word is talking about the topic business. |
| CULTURE | ምኒልክ* አገላለጽ ብሔረሰብ* ዳግማዊ* የቅርስ* ምዕት ዘመን* ባህል* በዓል* ባህላዊ*/Menelik * statement* national *heritage* century* culture* festival* cultural*/ | These words in Asterisks is referring to the same theme or topic what is culture and history. |
| LAW | አድራሻቸው ሕጉ* ይሁን ይቻላል ጸሐፊውን* ግዴታ* ጽሑፍ* ሕግጋት* ወዘተ መርሆች*/address, the law* possible, author* duty* article* laws* etc., principles*/ | The words with Asterisks are under law/or justice domain. |
| NEWS | አንበርብር ባለፈው በማለት አስረድተዋል* መሆኑን ምንጮች* ገልጸዋል* አንበርብር የገለፁት* አስረድተዋል*/Anberber, explained* in the past, that, sources*, explained*, Anberber, explained*/ | The words in Asterisks are usually said by the journalists in media. |
| OPINIONS | ታዲያ እንገልጻለን* አድራሻቸው በኢሜይል አመለካከት* የጸሐፊውን ከአዘጋጁ ጽሑፉ የሚያንፀባርቅ* ይመስለኛል*/So, explain*, address, email, opinion*, author, author’s article, reflecting*, think*/ | The words in Asterisks reflects opinions. |
| POLITICS | አክሏል ጠቅላይ* ነበር ሪፖርተር የፖለቲካ* ያስረዳሉ አህመድ* ዓብይ* አድማ* የኢህአደግ*/remarked, PM*, was, reporter, political* explains, Ahmed* Abiy*, strike*, EPRDF*/ | The words in Asterisks are highly connected to politics domain |
| NATURE | ሸንቁጥ* ወንዶቹ* አጥቢዎች* ወፎች* ማንይንገረው ዛፍ* ጄደብሊው እንስሳ* ባለአከርካሪዎች* ዝርያዎች*/The squirrel*, the males*, the mammals*, the birds*, unspoken tree*, JW animal* vertebrae*, species*/ | The words in Asterisks are belongs to nature and life domain |
| SOCIAL | ስለዚህም ጉባኤ* የጤና* ገብረማርያም ትምህርት* በታደሰ ጤና* እንደሚሉት መልኩ በሽታ*/therefore, conference*, health*, G. mariam, education*, renewed, health*, the form of, disease*/ | The words in Asterisks are related to social activities such as meetings, education and health domain |
| SPORT | ውድድር* የስፖርት* ጨዋታ* ዋንጫ* ኦሊምፒክ* እግር* ሩጫ* ስፖርት* አትሌቶች* ኳስ*/competition*, sports*, game*, cup*, olympics*, foot*, running*, sports*, athletes*, football*/ | All words are terms connected to sports domain |
| Sample Text | Target Class | Predicted Class |
|---|---|---|
| በአስረኛው ዙር የኮንዶሚኒየም ቤቶች እጣ እድል ከደረሳቸው የአድስ አበባ ነዋሪዎች መካከል ፈጠነ ዋቅጅራ ይገኝበታል…/Among the residents of Addis Ababa who were lucky enough to win the tenth round of condominiums was Fetene Waqjira./ | Politics | News |
| የቢራ የጅምላ ዋጋ ተመን ምርቱን ከሚመረትበት ከተማ ውጭ እንዳይወጣ እያደረገው…ከማከፋፈያ ዋጋቸው በታች እንድሸጡ የሚያስታውቁ መሆኑም ችግር እንደፈጠረም ታውቋል…/It is also known that the wholesale price of beer is keeping the product out of the city where it is produced…/ | Business | News |
| ከአክሱም ከተማ በስተሰሜን ምስራቅ አቅጣጫ ኪሎ ሜትር ርቀት ጥንታዊቷ ይሀ ከተማ ትገኛለች መነሻችን ከነበረው አክሱም አድዋና አድግራት የሚወስደውን ዋና ጎዳና ጎን ትተን ኪሎ ሜትር ከተጓዝን…/This ancient city is located a few miles northeast of Axum…/ | Art | Culture |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neshir, G.; Rauber, A.; Atnafu, S. Topic Modeling for Amharic User Generated Texts. Information 2021, 12, 401. https://doi.org/10.3390/info12100401
Neshir G, Rauber A, Atnafu S. Topic Modeling for Amharic User Generated Texts. Information. 2021; 12(10):401. https://doi.org/10.3390/info12100401
Chicago/Turabian StyleNeshir, Girma, Andreas Rauber, and Solomon Atnafu. 2021. "Topic Modeling for Amharic User Generated Texts" Information 12, no. 10: 401. https://doi.org/10.3390/info12100401
APA StyleNeshir, G., Rauber, A., & Atnafu, S. (2021). Topic Modeling for Amharic User Generated Texts. Information, 12(10), 401. https://doi.org/10.3390/info12100401