
FPGA-Based Voice Encryption Equipment under the Analog Voice Communication Channel


Abstract
:1. Introduction
2. Materials and Methods
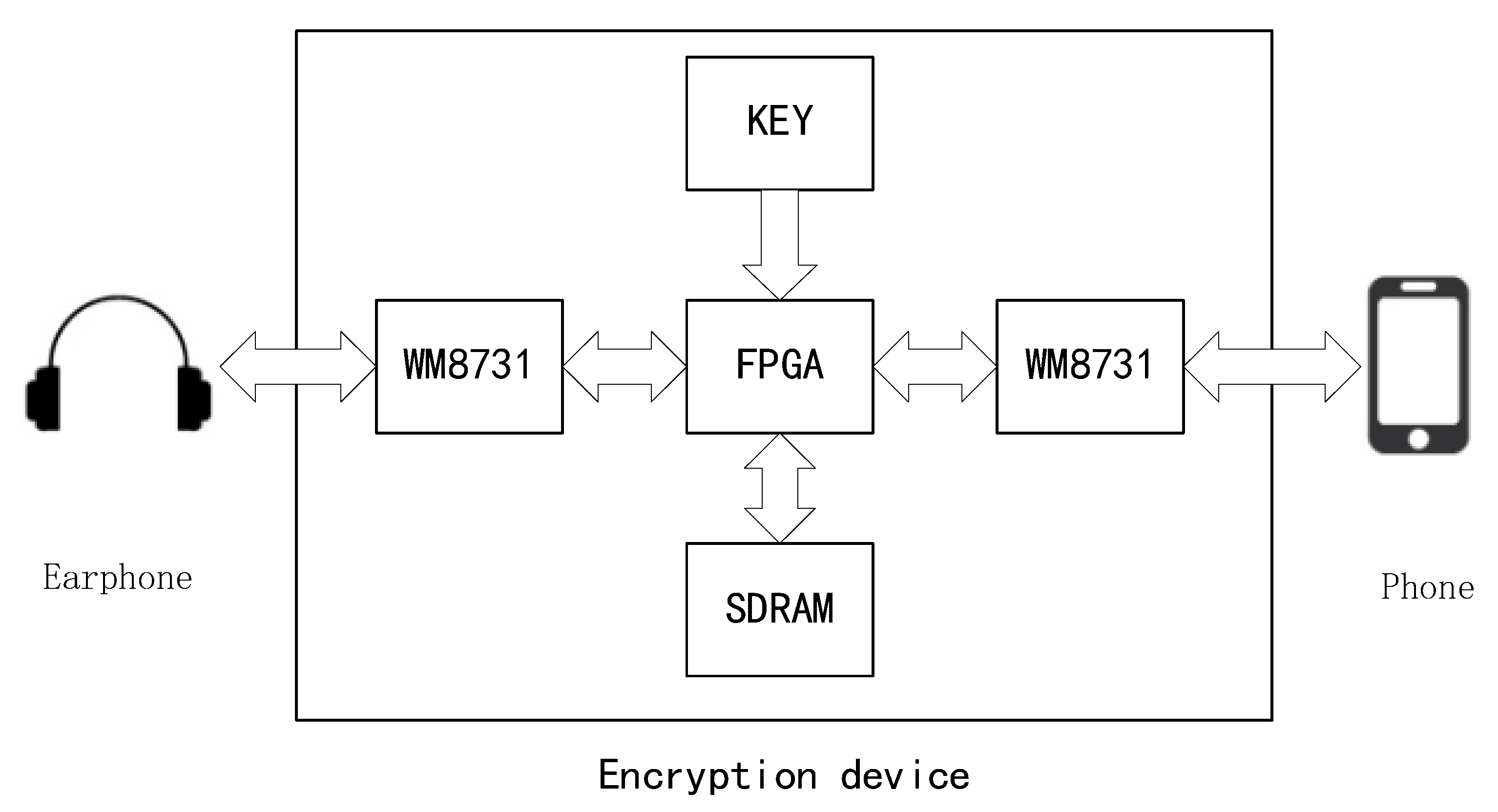
3. System Structure
3.1. Hardware Selection and Design
3.1.1. Audio Chip
3.1.2. FPGA Chip
3.1.3. PCB Design
3.2. Synchronization Algorithm
3.3. Encryption Algorithm
4. Test Results and Analysis
4.1. Time Delay Analysis
4.2. Voice Quality Test
4.3. Encryption Strength Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Park, S.; Cho, H.; Park, Y.; Choi, B.; Kim, D.; Yim, K. Security problems of 5G voice communication. In Proceedings of the 21st International Conference on Information Security Applications, WISA 2020, Jeju Island, Korea, 26–28 August 2020; pp. 403–415. [Google Scholar]
- Sadkhan, S.B.; Al-Sherbaz, A.; Mohammed, R.S. Chaos based Cryptography for Voice Encryption in Wireless Communication Literature Survey. In Proceedings of the 1st International Scientific Conference on Electrical, Communication, Computer, Power, and Control Engineering (ICECCPCE), Mosul, Iraq, 17–18 December 2013; pp. 191–197. [Google Scholar]
- Helenport, A.; Tait, B.L. Aspects of Voice Communications Fraud. In Proceedings of the 11th International Conference on Global Security, Safety, and Sustainability (ICGS3), London, UK, 18–20 January 2017; pp. 69–81. [Google Scholar]
- Chen, Y.; Hao, J.; Chen, J.; Zhang, Z. End-to-end speech encryption algorithm based on speech scrambling in frequency domain. In Proceedings of the 3rd International Conference on Cyberspace Technology, CCT 2015, Beijing, China, 17–18 October 2015. [Google Scholar]
- Sadkhan, S.B.; Salah, A. The trade-off between security and quality using permutation and substitution techniques in speech scrambling system. In Proceedings of the 2019 First International Conference of Computer and Applied Sciences (CAS), Baghdad, Iraq, 18–19 December 2019; pp. 244–249. [Google Scholar]
- Enache, F.; Deparateanu, D.; Oroian, T.; Popescu, F.; Vizitiu, I. Theoretical and practical implementation of scrambling algorithms for speech signals. In Proceedings of the 7th International Conference on Electronics, Computers and Artificial Intelligence, ECAI 2015, Bucharest, Romania, 25–27 June 2015; pp. S49–S52. [Google Scholar]
- Huang, H.H.; Liu, J.R.; Wang, Y.D. The Design Of Bluetooth Voice Source Wireless Real-time Voice Encryption System. In Proceedings of the 2016 3rd International Conference on Materials Engineering, Manufacturing Technology and Control, Taiyuan, China, 27–28 February 2016. [Google Scholar]
- Riyadi, M.A.; Pandapotan, N.; Khafid, M.R.A.; Prakoso, T. FPGA-based 128-bit Chaotic Encryption Method for Voice Communication. In Proceedings of the International Symposium on Electronics and Smart Devices (ISESD)-Smart Devices for Big Data Analytic and Machine Learning, Bandung, Indonesia, 23–24 October 2018; pp. 34–38. [Google Scholar]
- Zhang, Y.P.; Duan, F.; Liu, X. The Research of Applying Chaos Theory to Speech Communicating Encryption System. In Proceedings of the International Conference on Multimedia, Software Engineering and Computing, Wuhan, China, 26–27 November 2011; pp. 197–202. [Google Scholar]
- Abro, F.I.; Rauf, F.; Chowdhry, B.S.; Rajarajan, M. Towards Security of GSM Voice Communication. Wirel. Pers. Commun. 2019, 108, 1933–1955. [Google Scholar] [CrossRef]
- Islam, S.; Haq, I.U.; Saeed, A. Secure end-to-end SMS communication over GSM networks. In Proceedings of the 2015 12th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 13–17 January 2015; pp. 286–292. [Google Scholar]
- Rehman, M.U.; Adnan, M.; Batool, M.; Khan, L.A.; Masood, A. Effective Model for Real Time End to End Secure Communication Over GSM Voice Channel. Wirel. Pers. Commun. 2021, 119, 1643–1659. [Google Scholar] [CrossRef]
- Pal, P.; Sahana, B.C.; Ghosh, S.; Poray, J.; Mallick, A.K. Voice Password-Based Secured Communication Using RSA and ElGamal Algorithm. In Proceedings of the 5th International Conference on Advanced Computing and Intelligent Engineering, ICACIE 2020, Université des Mascareignes (UdM), Beau Bassin-Rose Hill, Mauritius, 25–27 June 2020; pp. 387–399. [Google Scholar]
- Zhong, W.; Wang, Y. Interfaces design of dual-channel audio codec based on FPGA. Int. J. Adv. Comput. Technol. 2011, 3, 460–466. [Google Scholar] [CrossRef]
- Yuan, H.; Xu, P. Designing of the digital voice recording system on SOPC. In Proceedings of the 2012 IEEE Fifth International Conference on Advanced Computational Intelligence (ICACI), Nanjing, China, 18–20 October 2012; pp. 1213–1215. [Google Scholar]
- Holmberg, W. Cost-Efficient Method Forlifetime Extension Ofinterconnectedcomputer-Based Systems. Available online: https://www.diva-portal.org/smash/get/diva2:1600354/FULLTEXT01.pdf (accessed on 2 November 2021).
- Ma, H.; Wang, Y.; Li, G. Implementation of audio data packet encryption synchronization circuit. In Proceedings of the 1st Euro-China Conference on Intelligent Data Analysis and Applications, ECC 2014, Shenzhen, China, 13–15 June 2014; pp. 321–329. [Google Scholar]
- Shaofeng, L.; Chaoping, G.; Lin, N.; Wanli, K.; Minjiao, Z. The Research of Encryption Algorithm for Voice Communication of Mobile Station. In Proceedings of the 2015 International Conference on Intelligent Transportation, Big Data and Smart City, Halong Bay, Vietnam, 19–20 December 2015; pp. 898–901. [Google Scholar]
- ElChabb, R.; Khattar, F.; Bassoul, G.; ElMurr, S.; Atallah, J.G. RT-VED: Real Time Voice Encryption/Decryption. In Proceedings of the International Colloquium on Computing, Communication, Control, and Management (CCCM 2010), Yangzhou, China, 20–22 August 2010; pp. 270–273. [Google Scholar]
- Sharma, P.; Sharma, R.K. Design and Implementation of Encryption Algorithm for Real Time Speech Signals. In Proceedings of the Conference on Advances in Signal Processing (CASP), Pune, India, 9–11 June 2016; pp. 237–241. [Google Scholar]
- Lwin, H.M.M.M.; Ishibashi, Y.; Mya, K.T. Influence of Voice Delay on Human Perception of Group Synchronization Error for Remote Learning: One-way Communication Case. In Proceedings of the 2020 IEEE Conference on Computer Applications, ICCA 2020, Yangon, Myanmar, 27–28 February 2020. [Google Scholar]
- Liu, X.; Chen, J.; He, X.; Li, W.; Zhang, G. A study of radio voice signal based on the time delay estimation. Int. J. Hybrid Inf. Technol. 2016, 9, 103–110. [Google Scholar] [CrossRef]
- Peng, Z.; Mo, K.; Zhu, X.; Chen, J.; Chen, Z.; Xu, Q.; Ma, X. Understanding user perceptions of robot’s delay, voice quality-speed trade-off and GUI during conversation. In Proceedings of the 2020 ACM CHI Conference on Human Factors in Computing Systems, CHI EA 2020, Honolulu, HI, USA, 25–30 April 2020. [Google Scholar]
- Lubkowski, P.; Polak, R.; Sierzputowski, R. The measurements of the secured voice communication quality in a broadband radio channel. In Proceedings of the Radioelectronic Systems Conference (RSC), Jachranka, Poland, 20–21 November 2019. [Google Scholar]
- Yihunie, F.; Abdelfattah, E. Simulation and Analysis of Quality of Service (QoS) of Voice over IP (VoIP) through Local Area Networks. In Proceedings of the 9th IEEE Annual Ubiquitous Computing, Electronics and Mobile Communication Conference, UEMCON 2018, New York, NY, USA, 8–10 November 2018; pp. 598–602. [Google Scholar]
- Cox, R.V.; Bock, D.E.; Bauer, K.B.; Johnston, J.D.; Synder, J.H. Analog Voice Privacy System. ATT Tech. J. 1987, 66, 119–131. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Frame Length | Number of Frames | Time Delay/ms |
|---|---|---|---|
| 1 | 600 | 4 | 50 |
| 2 | 600 | 8 | 100 |
| 3 | 1200 | 8 | 200 |
| 4 | 1200 | 16 | 400 |
| 5 | 2400 | 4 | 200 |
| 6 | 2400 | 8 | 400 |
| Tester ID | Voice Quality | Noise |
|---|---|---|
| A | 5 | None |
| B | 4 | Little |
| C | 4 | Little |
| D | 3 | Noisy |
| E | 4 | Little |
| Encryption Parameters | Range | Step Size |
|---|---|---|
| Encryption period | 0.1–1 s | None |
| Number of frames | 4–40 | 1 |
| Frame size | 200–2000 | 10 |
| Frame rearrangement | Determined by different arrangements | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, X.; Sun, G.; Zheng, B.; Nan, R. FPGA-Based Voice Encryption Equipment under the Analog Voice Communication Channel. Information 2021, 12, 456. https://doi.org/10.3390/info12110456
Ge X, Sun G, Zheng B, Nan R. FPGA-Based Voice Encryption Equipment under the Analog Voice Communication Channel. Information. 2021; 12(11):456. https://doi.org/10.3390/info12110456
Chicago/Turabian StyleGe, Xinyu, Guiling Sun, Bowen Zheng, and Ruili Nan. 2021. "FPGA-Based Voice Encryption Equipment under the Analog Voice Communication Channel" Information 12, no. 11: 456. https://doi.org/10.3390/info12110456
APA StyleGe, X., Sun, G., Zheng, B., & Nan, R. (2021). FPGA-Based Voice Encryption Equipment under the Analog Voice Communication Channel. Information, 12(11), 456. https://doi.org/10.3390/info12110456