
Analysis of Unsatisfying User Experiences and Unmet Psychological Needs for Virtual Reality Exergames Using Deep Learning Approach


Abstract
:1. Introduction
- RQ1: How are the unmet psychological needs in virtual reality exergames reflected in online reviews? Which design elements of virtual reality exergames lead to that when we consider the extracted keywords?
- RQ2: Are there any differences between the results of consumer online review analysis and experimental results? If so, why do these differences occur?
2. Background
2.1. Evaluation of User Experience from Psychological Needs
2.2. Virtual Reality Exergames
2.3. Sentiment Analysis for Online Consumer Reviews
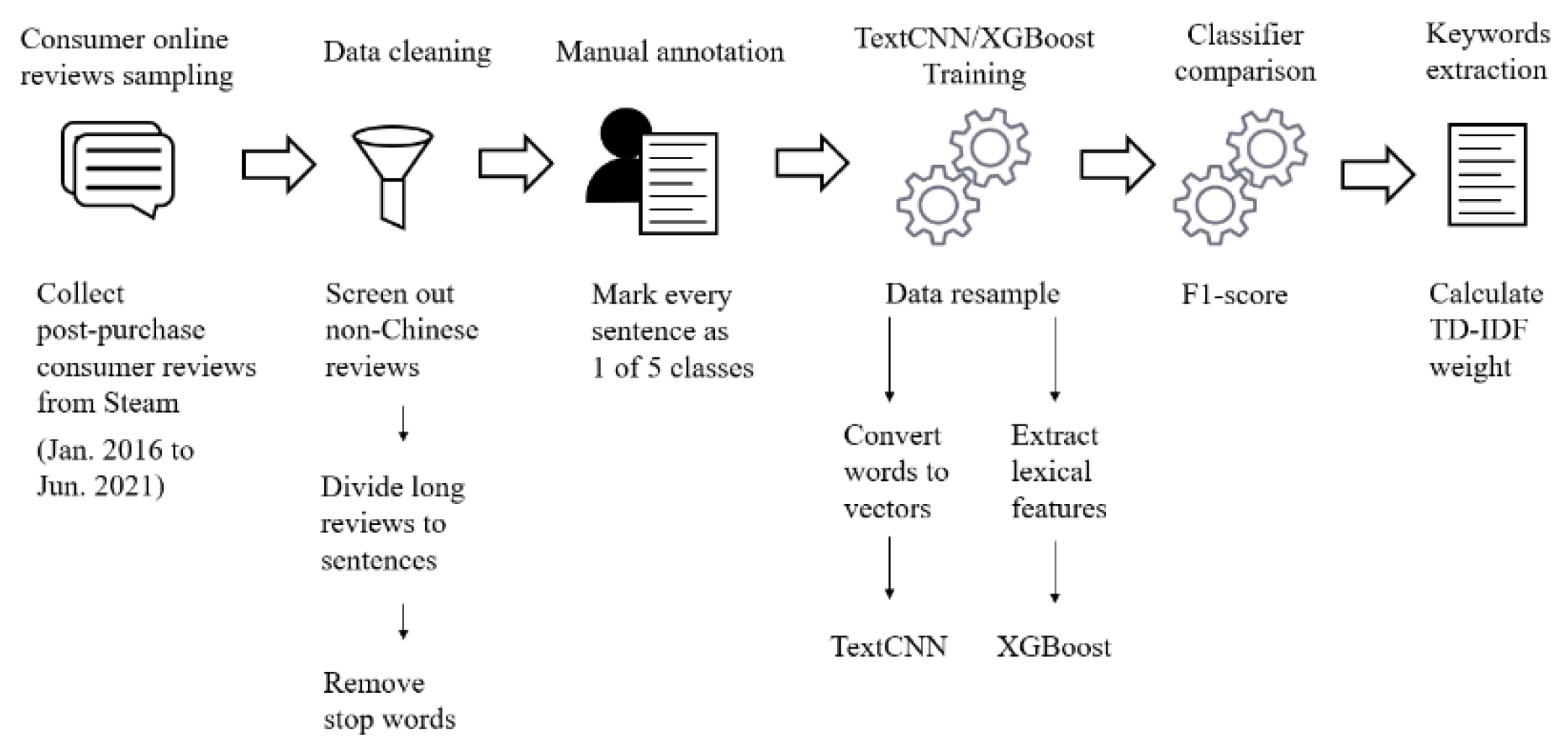
3. Materials and Methods
3.1. Data Sampling and Cleaning
3.2. Manual Annotation
3.3. Classifiers
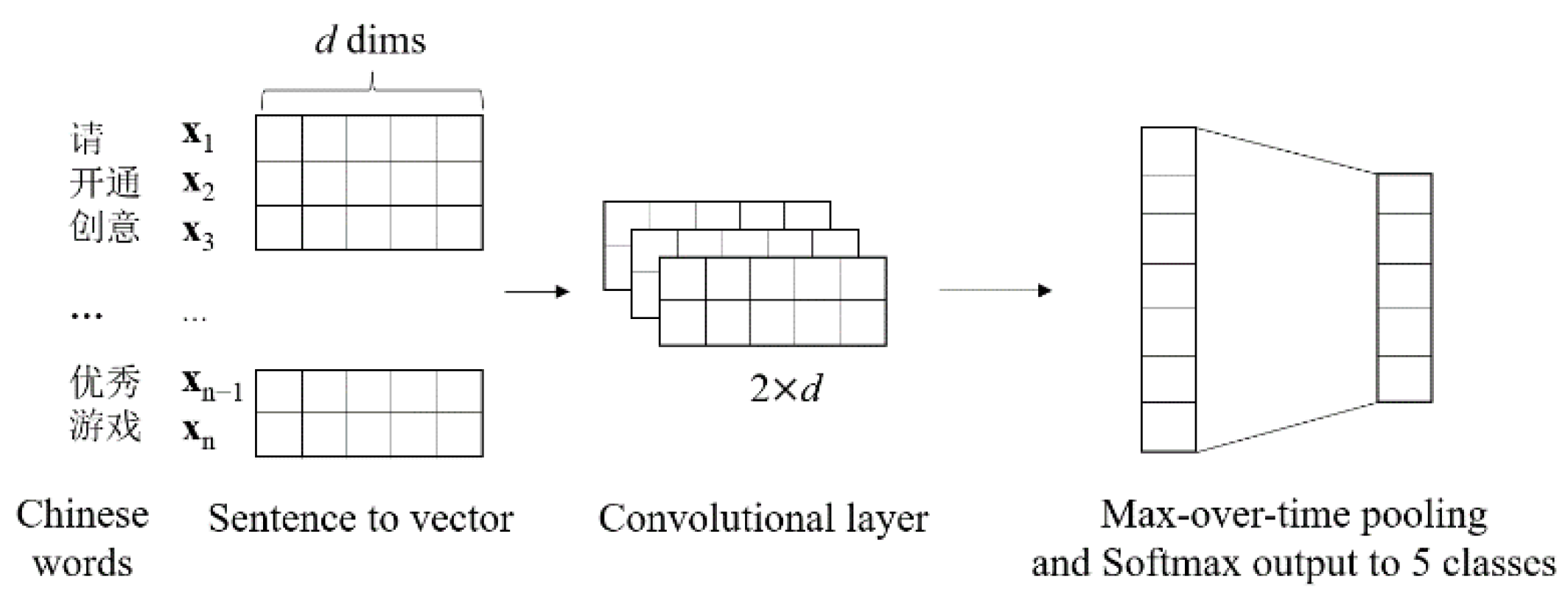
3.3.1. TextCNN
3.3.2. XGBoost
3.4. Classifiers Evaluation
3.5. Keywords Extraction by TF-IDF
4. Results
4.1. Classifier Performance and Selection
4.2. Keywords Extraction Results
5. Discussion
5.1. Research Findings
5.2. Limitations and Directions for Future Research
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
A.1. The Annotation Guideline
Definitions
- Unsatisfying experiences: users feel upset, hostile, ashamed, distressed, irritable, scared, or guilty when or after playing the virtual reality exergame. These emotions can be perceived in online reviews.
- Autonomy: users’ sense of control over their own choices using the product.
- Competence: users’ sense of knowledge and skills required to achieve a goal, or feeling capable, effective in users’ actions.
- Relatedness: users’ sense of community and psychological connection with others. Annotation examples are shown in Table A1.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Label | Examples |
|---|---|---|
| Not relevant to unsatisfying experiences | 0 | Good game/this is my first review/worthy to buy. |
| Unsatisfying experiences not relevant to psychological needs | 1 | The game is running on SteamVR, but not on my HMD/have bugs and cannot contact to developers/why my license expired? |
| Unsatisfying experiences with unmet autonomy needs | 2 | Few favorite songs, and not open to custom music editing/we need mods! |
| Unsatisfying experiences with unmet competence needs | 3 | After repeatedly squatting and standing up for a period of time, players will soon feel the pain in their legs, resulting in the failure of the game. |
| Unsatisfying experiences with unmet relatedness needs | 4 | Hope you can release multi-player mode in the future/no one in online game. |
References
- SteamVR Logged 104m Sessions and 1.7m New VR Users in 2020. Available online: https://www.vrfocus.com/2021/01/steamvr-logged-104m-sessions-and-1-7m-new-vr-users-in-2020 (accessed on 15 January 2021).
- Ergonomic Requirements for Office Work with Visual Display Terminals (VDTs)—Part 11: Guidance on Usability. Available online: https://www.iso.org/obp/ui/#iso:std:iso:9241:-11:ed-1:v1:en (accessed on 13 September 2021).
- Partala, T.; Kallinen, A. Understanding the most satisfying and unsatisfying user experiences: Emotions, psychological needs, and context. Interact. Comput. 2012, 24, 25–34. [Google Scholar] [CrossRef] [Green Version]
- Partala, T.; Saari, T. Understanding the most influential user experiences in successful and unsuccessful technology adoptions. Comput. Hum. Behav. 2015, 53, 381–395. [Google Scholar] [CrossRef]
- de Saenz-Urturi, Z.; Zapirain, B.G.; Zorrilla, A.M. Elderly user experience to improve a Kinect-based game playability. Behav. Inf. Technol. 2015, 34, 1040–1051. [Google Scholar] [CrossRef]
- Deci, E.; Ryan, R.M. The “What” and “Why” of Goal Pursuits: Human Needs and the Self-Determination of Behavior. Psychol. Inq. 2000, 11, 227–268. [Google Scholar] [CrossRef]
- Ijaz, K.; Ahmadpour, N.; Wang, Y.; Calvo, R.A. Player Experience of Needs Satisfaction (PENS) in an immersive virtual reality exercise platform describes motivation and enjoyment. Int. J. Hum. Comput. Interact. 2020, 36, 1195–1204. [Google Scholar] [CrossRef]
- Tsai, T.-H.; Chang, Y.-S.; Chang, H.-T.; Lin, Y.-W. Running on a social exercise platform: Applying self-determination theory to increase motivation to participate in a sporting event. Comput. Hum. Behav. 2020, 114, 106523. [Google Scholar] [CrossRef]
- Faric, N.; Potts, H.W.W.; Hon, A.; Smith, L.; Newby, K.; Steptoe, A.; Fisher, A. What Players of Virtual Reality Exercise Games Want: Thematic Analysis of Web-Based Reviews. J. Med. Internet Res. 2019, 21, e13833. [Google Scholar] [CrossRef]
- McMichael, L.; Faric, N.; Newby, K.; Potts, H.W.W.; Hon, A.; Smith, L.; Steptoe, A.; Fisher, A. Parents of adolescents perspectives of physical activity, gaming and virtual reality: Qualitative study. JMIR Serious Games 2020, 8, e14920. [Google Scholar] [CrossRef] [PubMed]
- Hassenzahl, M.; Diefenbach, S.; Göritz, A. Needs, affect, and interactive products—Facets of user experience. Interact. Comput. 2010, 22, 353–362. [Google Scholar] [CrossRef]
- Hassenzahl, M.; Tractinsky, N. User experience—A research agenda. Behav. Inf. Technol. 2006, 25, 91–97. [Google Scholar] [CrossRef]
- Ryan, R.M.; Deci, E.L. Self-determination theory and the facilitation of intrinsic motivation, social development, and well-being. Am. Psychol. 2000, 55, 68–78. [Google Scholar] [CrossRef]
- Reis, H.T.; Sheldon, K.M.; Gable, S.L.; Roscoe, J.; Ryan, R.M. Daily Well-Being: The Role of Autonomy, Competence, and Relatedness. Pers. Soc. Psychol. Bull. 2000, 26, 419–435. [Google Scholar] [CrossRef]
- Tan, C.T.; Leong, T.W.; Shen, S.; Dubravs, C.; Si, C. Exploring Gameplay Experiences on the Oculus Rift. In Proceedings of the 2015 Annual Symposium on Computer-Human Interaction in Play, London, UK, 5–7 October 2015; pp. 253–263. [Google Scholar]
- Jennett, C.; Cox, A.L.; Cairns, P.; Dhoparee, S.; Epps, A.; Tijs, T.; Walton, A. Measuring and defining the experience of immersion in games. Int. J. Hum. Comput. Stud. 2008, 66, 641–661. [Google Scholar] [CrossRef]
- Ilves, M.; Gizatdinova, Y.; Surakka, V.; Vankka, E. Head movement and facial expressions as game input. Entertain. Comput. 2014, 5, 147–156. [Google Scholar] [CrossRef]
- Lee, H.T.; Kim, Y.S. The effect of sports VR training for improving human body composition. EURASIP J. Image Video Process. 2018, 2018, 148. [Google Scholar] [CrossRef]
- Michalski, S.C.; Szpak, A.; Saredakis, D.; Ross, T.; Billinghurst, M.; Loetscher, T. Getting your game on: Using virtual reality to improve real table tennis skills. PLoS ONE 2019, 14, e0222351. [Google Scholar] [CrossRef] [PubMed]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning–based text classification: A comprehensive review. ACM Comput. Surv. 2021, 54, 62. [Google Scholar] [CrossRef]
- Cambria, E. Affective Computing and Sentiment Analysis. In IEEE Intelligent Systems; IEEE: Piscataway, NJ, USA, 2016; Volume 31, pp. 102–107. [Google Scholar] [CrossRef]
- Shaver, P.; Schwartz, J.; Kirson, D.; O’Connor, C. Emotion knowledge: Further exploration of a prototype approach. J. Pers. Soc. Psychol. 1987, 52, 1061–1086. [Google Scholar] [CrossRef]
- Watson, D.; Tellegen, A.; Clark, L. Development and validation of brief measures of positive and negative affect: The PANAS scales. J. Pers. Soc. Psychol. 1988, 54, 1063–1070. [Google Scholar] [CrossRef]
- Plutchik, R. The nature of emotions human emotions have deep evolutionary roots, a fact that may explain their complexity and provide tools for clinical practice. Am. Sci. 2001, 89, 344–350. [Google Scholar] [CrossRef]
- Cambria, E.; Livingstone, A.; Hussain, A. The Hourglass of Emotions. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 144–157. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Li, W.; Shao, W.; Ji, S.; Cambria, E. BiERU: Bidirectional emotional recurrent unit for conversational sentiment analysis. Neurocomputing 2022, 467, 73–82. [Google Scholar] [CrossRef]
- Peng, H.; Ma, Y.; Poria, S.; Li, Y.; Cambria, E. Phonetic-enriched text representation for Chinese sentiment analysis with reinforcement learning. Inf. Fusion 2021, 70, 88–99. [Google Scholar] [CrossRef]
- Lin, E.; Chen, Q.; Qi, X. Deep reinforcement learning for imbalanced classification. Appl. Intell. 2020, 50, 2488–2502. [Google Scholar] [CrossRef] [Green Version]
- Ofek, N.; Poria, S.; Rokach, L.; Cambria, E.; Hussain, A.; Shabtai, A. Unsupervised Commonsense Knowledge Enrichment for Domain-Specific Sentiment Analysis. Cogn. Comput. 2016, 8, 467–477. [Google Scholar] [CrossRef]
- Eler, D.M.; Grosa, D.; Pola, I.; Garcia, R.; Correia, R.; Teixeira, J. Analysis of Document Pre-Processing Effects in Text and Opinion Mining. Information 2018, 9, 100. [Google Scholar] [CrossRef] [Green Version]
- Lo, T.W.; He, B.; Ounis, I. Automatically building a stopword list for an information retrieval system. J. Digit. Inf. Manag. 2005, 3, 3–8. [Google Scholar]
- Che, W.; Li, Z.; Liu, T. LTP: A Chinese Language Technology Platform. In Proceedings of the Coling 2010: Demonstrations, Beijing, China, 23–27 August 2010; pp. 13–16. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Wang, Y.; Dang, Y.; Xu, Z. Mining automobile quality problems based on the characteristics of forum data. Chin. J. Manage. Sci. 2021, 29, 201–212. [Google Scholar]
- Wang, J.; Zhao, Z.; Liu, Y.; Guo, Y. Research on the Role of Influencing Factors on Hotel Customer Satisfaction Based on BP Neural Network and Text Mining. Information 2021, 12, 99. [Google Scholar] [CrossRef]
- Beat Saber CEO Talks Hacks, Mods and Getting Artists Paid. Available online: https://uploadvr.com/gdc-beat-saber-ceo-mods/ (accessed on 25 March 2019).


| Category | Label | Examples |
|---|---|---|
| Not relevant to unsatisfying experience | 0 | This is my first review. |
| Unsatisfying experience not relevant to psychological needs | 1 | Have bugs and cannot contact to developers. |
| Unsatisfying experience with unmet autonomy needs | 2 | Few favorite songs, and not open to custom music editing. |
| Unsatisfying experience with unmet competence needs | 3 | After repeatedly squatting and standing up for a period of time, players will soon feel the pain in their legs, resulting in the failure of the game. |
| Unsatisfying experience with unmet relatedness needs | 4 | Hope you can release multi-player mode in the future. |
| Parameters | Value | Description |
|---|---|---|
| in_channels | 1 | Number of information input channels of convolution layer. |
| out_channels | 9 | Number of information output channels of convolution layer. |
| kernel_size | 2 × 128 | Size of convolution layer kernel. |
| stride | 1 | Steps per move. |
| batch_size | 512 | Number of samples used for each training. |
| learning_rate | 0.001 | The learning speed of the model. |
| dropout | 0.5 | The probability of abandoning the activation of neurons (to avoid over fitting). |
| Parameters | Value | Description |
|---|---|---|
| objective | multi:softmax | Multiclass classification using the softmax objective. |
| gamma | 0.1 | Minimum loss reduction required to make a further partition on a leaf node of the tree. |
| max_depth | 6 | Maximum depth of a tree. |
| learning_rate (eta) | 0.1 | Step size shrinkage used in update to prevents overfitting. |
| subsample | 0.5 | Subsample ratio of the training instance. Setting it to 0.5 means that XGBoost randomly collected half of the data instances to grow trees and this will prevent overfitting. |
| min_child_weight | 1 | Minimum sum of instance weight needed in a child. |
| Micro-F1 Score (%) in Each Cross-Validation | 1st | 2nd | 3rd | 4th | 5th | |
|---|---|---|---|---|---|---|
| textCNN | 91.90 | 87.99 | 89.94 | 86.03 | 94.13 | 90.00 |
| XGBoost | 82.85 | 81.11 | 84.37 | 82.49 | 82.63 | 82.69 |
| Class 1: Unsatisfying Experience without Unmet Psychological Needs | Class 2: Unmet Autonomy Needs | Class 3: Unmet Competence Needs | Class 4: Unmet Relatedness Needs | ||||
|---|---|---|---|---|---|---|---|
| Word | TF-IDF | Word | TF-IDF | Word | TF-IDF | Word | TF-IDF |
| game | 1.6613 | game | 0.9641 | game | 0.8371 | on-line cooperation | 1.2314 |
| experience | 0.1874 | song | 0.3099 | feeling | 0.1546 | game | 0.8912 |
| controller | 0.1445 | workshop | 0.1806 | experience | 0.1527 | mode | 0.6977 |
| player | 0.1388 | player | 0.1643 | player | 0.1440 | experience | 0.2457 |
| feeling | 0.1264 | controller | 0.1451 | hour | 0.1377 | skin | 0.2148 |
| frame | 0.1092 | music | 0.1381 | arm | 0.1291 | official | 0.1744 |
| problem | 0.0944 | experience | 0.1278 | frame | 0.0979 | foreigner | 0.1720 |
| hot-air balloon | 0.0912 | mode | 0.1272 | sensation | 0.0848 | human and computer | 0.1705 |
| gameplay | 0.0872 | official | 0.1264 | music | 0.0832 | social activity | 0.1547 |
| interface | 0.0857 | music game | 0.0841 | mode | 0.0826 | function | 0.1367 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Yan, Q.; Zhou, S.; Ma, L.; Wang, S. Analysis of Unsatisfying User Experiences and Unmet Psychological Needs for Virtual Reality Exergames Using Deep Learning Approach. Information 2021, 12, 486. https://doi.org/10.3390/info12110486
Zhang X, Yan Q, Zhou S, Ma L, Wang S. Analysis of Unsatisfying User Experiences and Unmet Psychological Needs for Virtual Reality Exergames Using Deep Learning Approach. Information. 2021; 12(11):486. https://doi.org/10.3390/info12110486
Chicago/Turabian StyleZhang, Xiaoyan, Qiang Yan, Simin Zhou, Linye Ma, and Siran Wang. 2021. "Analysis of Unsatisfying User Experiences and Unmet Psychological Needs for Virtual Reality Exergames Using Deep Learning Approach" Information 12, no. 11: 486. https://doi.org/10.3390/info12110486