
Design Demand Trend Acquisition Method Based on Short Text Mining of User Comments in Shopping Websites


Abstract
:1. Introduction
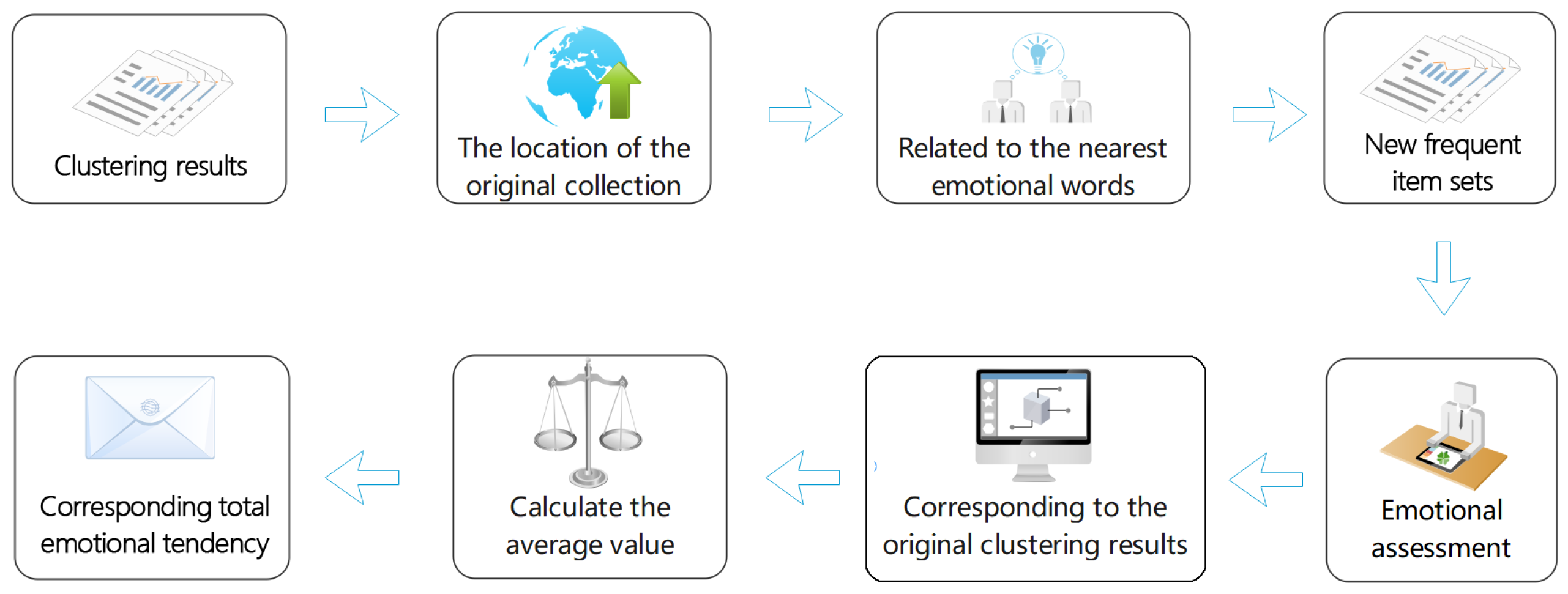
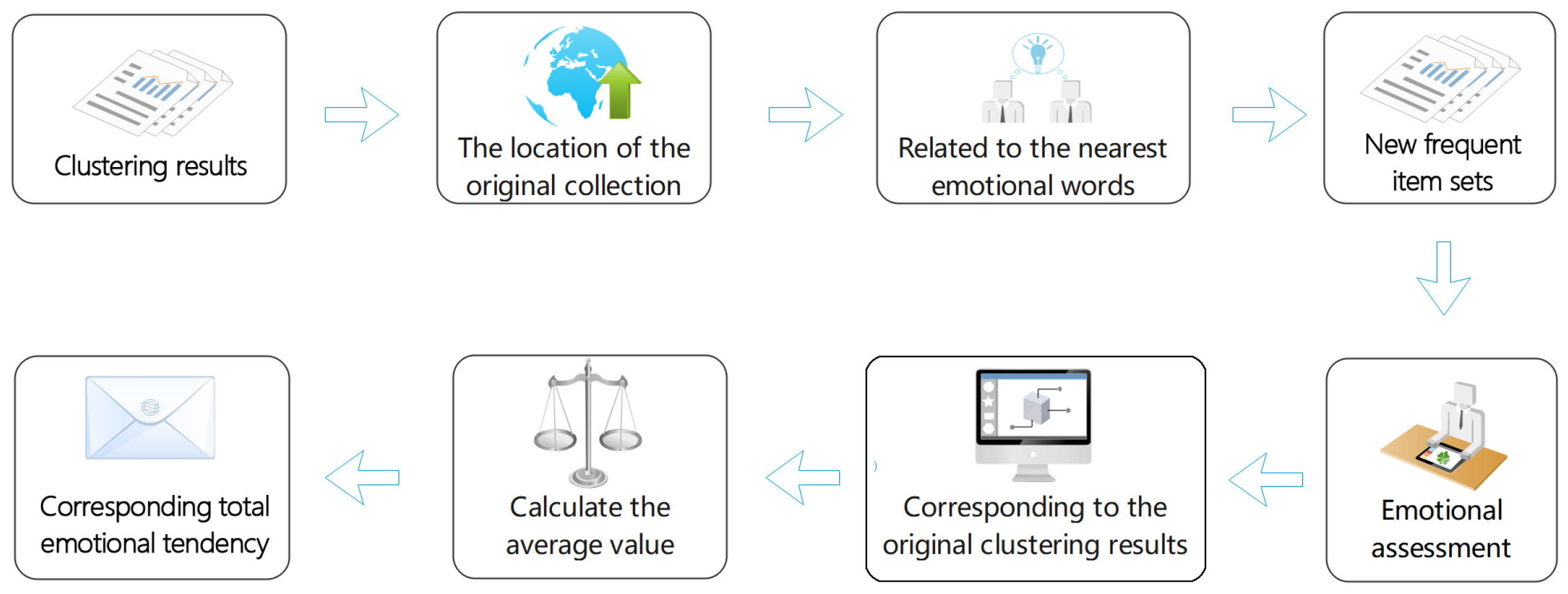
- After using the Jieba word segmentation tool (github.com/fxsjy/jieba) to segment Chinese text, we carried out a compact test and redundant pruning to deal with the large number of meaningless and repetitive words, and obtained a new frequent item set.
- Based on Sogou input method’s Chinese emotional word class library and PFE algorithm, the number of product features and sentiment tendency expressions were obtained so as to test the feature support again and then eliminate more meaningless “noun adjective” combinations. Based on the get-score block of EmotionAnalysis and the Adjective emotion level setting, we assessed the emotional orientation.
- We tried to solve the problems of quick comment, less information and ignoring the main body of the product by using a user-defined dictionary and the manual part of speech tagging. An experiment of designing and developing the element dictionary of oral online reviews was carried out because the complex item set lacks nouns or adjectives alone in the oral context of online reviews. Based on the experiments and the data obtained, this experiment attempted to put forward a specific quantitative definition of the network user demand degree and trend judgment of product design and development elements in order to make a general user demand and trend judgment.
- The data visualization interaction solution was designed based on certain visualization theory and logic, and the usability evaluation test was carried out to verify the effectiveness of the solution.
- A questionnaire was conducted on the user demand degree of laptop design elements, and extract design elements for mainstream laptops in the market. In addition to this, a method is proposed to quantify the users’ requirements, trend judgment when we design new goods.
- The experimental definition is proposed to be scientific through further mining experiments and data summary. We also designed the data visualization interaction based on the experimental data and evaluated the prototype by usability test.
2. Related Works
2.1. Data Mining Technology
2.2. Application of Data Mining
2.3. Data Visualization
3. Methodology
3.1. Research and Positioning of Laptop User Needs
3.2. Pre Experiment on Mining Short Comment Text of Shopping Website
3.2.1. User Comment Text Data Acquisition
3.2.2. Stop Word Filtering, Word Segmentation and Word Frequency Statistics
3.2.3. Compact and Redundancy Check
3.2.4. Product Feature–User Sentiment Combination Extraction
3.2.5. Establish a Dictionary of Design and Development Elements
3.2.6. Clustering Effect Experiment
3.2.7. Emotional Orientation Matching
3.3. User Demand and Trend Mining Experiment of Laptop’s Design Elements
3.4. Data Visualization Design of Laptop’s User Demands
- Visual presentation of demand attention ratio, demand hierarchy classification, and sample extraction time of laptop’s design elements according to the comprehensive computer database.
- Visual presentation of descending order of high-frequency words based on a whole computer database. Secondly, 10 users are selected to evaluate the scheme (this test includes four missions), and the availability of the visualization tool is judged according to the results.
3.5. Usability Test of Visualization Scheme
- The experimenters needed to compare and score the color sequence and composition (there are five levels: level 1 is very bad, level 2 is bad, level 3 is average, level 4 is like and level 5 is very like).
- The experimenters needed to complete the chart observation of the user demand degree of laptop design elements within 10 s, and answer which design element accounts for the largest proportion immediately and calculate the correct rate.
- The experimenters needed to complete the task of setting interception time on a MacBook provided by us as soon as possible, and record the complete time.
- The experimenters needed to sort the high frequency word experiment within 20 s. After that, they sorted five high-frequency words in the questionnaire and collect the statistics of the accuracy.
4. Case Study, Result and Discussion
4.1. Pre Experiment Result Analysis
4.2. User Demand and Trend Mining Experiment Result Analysis
4.3. Data Visualization Design of Laptop’s User Demands
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hirsch, S.; Novgorodov, S.; Guy, I.; Nus, A. Generating Tips from Product Reviews. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 8–12 March 2021; pp. 310–318. [Google Scholar]
- Daria, J.; Kuss, M.D.G. Online Social Networking and Addiction-A Review of the Psychological Literature. Int. J. Environ. Res. Public Health 2011, 8, 3528–3552. [Google Scholar]
- Mochurad, B.; Fedushko, S.; Grytsay, O.; Todoshchuk, A.; Kovalchuk, U. Web Analytics, Legal Framework and Estimation of Profitability of the Theater Website. CEUR Workshop Proc. 2021, 2824, 65–76. [Google Scholar]
- Cao, N.; Ji, S.; Chiu, D.K.; He, M.; Sun, X. A deceptive review detection framework: Combination of coarse and fine-grained features. Expert Syst. Appl. 2020, 156, 1–11. [Google Scholar] [CrossRef]
- Alattar, F.; Shaalan, K. Using Artificial Intelligence to Understand What Causes Sentiment Changes on Social Media. IEEE Access 2021, 9, 61756–61767. [Google Scholar] [CrossRef]
- Ishaq, A.; Umer, M.; Mushtaq, M.F.; Medaglia, C.; Siddiqui, H.U.R.; Mehmood, A.; Choi, G.S. Extensive hotel reviews classification using long short term memory. J. Ambient. Intell. Humaniz. Comput. 2020, 12, 9375–9385. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Kwak, D. Fuzzy Ontology and LSTM-Based Text Mining: A Transportation Network Monitoring System for Assisting Travel. Sensors 2019, 19, 234. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, S.; Huang, G.; Ofoghi, B.; Yearwood, J. Short text similarity measurement using context-aware weighted biterms. Neurocomputing 2020, 15, e5765. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, M.; Shen, C.; Huang, Z.; Gu, M. BTM and GloVe Similarity Linear Fusion-Based Short Text Clustering Algorithm for Microblog Hot Topic Discovery. IEEE Access 2020, 8, 32215–32225. [Google Scholar] [CrossRef]
- He, J.; Li, L.; Wang, Y.; Wu, X. Targeted aspects oriented topic modeling for short texts. Appl. Intell. 2020, 50, 2384–2399. [Google Scholar] [CrossRef]
- Selvaraj, S.; Choi, E. Swarm Intelligence Algorithms in Text Document Clustering with Various Benchmarks. Sensors 2021, 21, 3196. [Google Scholar] [CrossRef]
- Baccouche, A.; Ahmed, S.; Sierra-Sosa, D.; Elmaghraby, A. Malicious Text Identification: Deep Learning from Public Comments and Emails. Information 2020, 11, 312. [Google Scholar] [CrossRef]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural language processing: An introduction. J. Am. Med. Inform. Assoc. Jamia 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, C.J.; Payne, A.; Mork, J.G. The Unified Medical Language System SPECIALIST Lexicon and Lexical Tools: Development and applications. J. Am. Med. Inform. Assoc. 2020, 27, 1600–1605. [Google Scholar] [CrossRef] [PubMed]
- Cheng, X.; Kong, X.; Liao, L.; Li, B. A Combined Method for Usage of NLP Libraries Towards Analyzing Software Documents. In Proceedings of the International Conference on Advanced Information Systems Engineering, Grenoble, France, 8–12 June 2020; pp. 515–529. [Google Scholar]
- Chen, J.; Gong, Z.; Liu, W. A Dirichlet process biterm-based mixture model for short text stream clustering. Appl. Intell. 2020, 50, 1609–1619. [Google Scholar] [CrossRef]
- Franzmann, D.; Eichner, A.; Holten, R. How Mobile App Design Overhauls Can Be Disastrous in Terms of User Perception: The Case of Snapchat. ACM Trans. Soc. Comput. 2020, 3, 1–21. [Google Scholar] [CrossRef]
- Curiskis, S.A.; Drake, B.; Osborn, T.R.; Kennedy, P.J. An evaluation of document clustering and topic modelling in two online social networks: Twitter and Reddit. Inf. Process. Manag. 2019, 57, 102034. [Google Scholar] [CrossRef]
- Wandabwa, H.M.; Naeem, M.A.; Mirza, F.; Pears, R. Topical affinity in short text microblogs. Inf. Syst. 2021, 96, 1–17. [Google Scholar] [CrossRef]
- Chen, J.; Yu, J.; Zhao, S.; Zhang, Y. User’s Review Habits Enhanced Hierarchical Neural Network for Document-Level Sentiment Classification. Neural Process. Lett. 2021, 53, 2095–2111. [Google Scholar] [CrossRef]
- Hu, J.; Peng, J.; Zhang, W.; Qi, L.; Hu, M.; Zhang, H. An Intention Multiple-representation Model with Expanded Information. Comput. Speech Lang. 2021, 68, 1–12. [Google Scholar] [CrossRef]
- Abdulateef, S.; Khan, N.A.; Chen, B.; Shang, X. Multidocument Arabic Text Summarization Based on Clustering and Word2Vec to Reduce Redundancy. Information 2020, 11, 59. [Google Scholar] [CrossRef] [Green Version]
- Ozyurt, B.; Akcayol, M.A. A new topic modeling based approach for aspect extraction in aspect based sentiment analysis: SS-LDA. Expert Syst. Appl. 2020, 168, 114231. [Google Scholar] [CrossRef]
- Fidan, H.; Yuksel, M.E. A Novel Short Text Clustering Model Based on Grey System Theory. Arab. J. Sci. Eng. 2020, 45, 2865–2882. [Google Scholar] [CrossRef]
- Oussous, A.; Benjelloun, F.Z.; Lahcen, A.A.; Belfkih, S. ASA: A framework for Arabic sentiment Analysis. J. Inf. Sci. 2020, 46, 544–559. [Google Scholar] [CrossRef]
- De Oliveira Júnior, G.A.; de Oliveira Albuquerque, R.; Borges de Andrade, C.A.; de Sousa, R.T.; Sandoval Orozco, A.L.; García Villalba, L.J. Anonymous Real-Time Analytics Monitoring Solution for Decision Making Supported by Sentiment Analysis. Sensors 2020, 20, 4557. [Google Scholar] [CrossRef]
- Injadat, M.; Salo, F.; Nassif, A.B. Data mining techniques in social media: A survey. Neurocomputing 2016, 214, 654–670. [Google Scholar] [CrossRef]
- Gan, G.; Ng, M.K.P. K-means clustering with outlier removal. Pattern Recognit. Lett. 2017, 90, 8–14. [Google Scholar] [CrossRef]
- Zhu, F.; Patumcharoenpol, P.; Zhang, C.; Yang, Y.; Chan, J.; Meechai, A.; Vongsangnak, W.; Shen, B. Biomedical text mining and its applications in cancer research. J. Biomed. Inform. 2013, 46, 200–211. [Google Scholar] [CrossRef] [Green Version]
- MacCuish, J.D.; MacCuish, N.E. Clustering in Bioinformatics and Drug Discovery; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Yu, S.S.; Chu, S.W.; Wang, C.M.; Chan, Y.K.; Chang, T.C. Two improved k-means algorithms. Appl. Soft Comput. 2018, 68, 747–755. [Google Scholar] [CrossRef]
- Zhong, N.; Li, Y.; Wu, S.T. Effective pattern discovery for text mining. IEEE Trans. Knowl. Data Eng. 2010, 24, 30–44. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Zhang, Y.; Chen, Q.; Wang, H. Attitude of Chinese public towards municipal solid waste sorting policy: A text mining study. Sci. Total Environ. 2021, 756, 142674. [Google Scholar] [CrossRef] [PubMed]
- Rashid, J.; Shah, S.M.A.; Irtaza, A. Fuzzy topic modeling approach for text mining over short text. Inf. Process. Manag. 2019, 56, 102060. [Google Scholar] [CrossRef]
- He, P.; Luan, S. On-line data retrieval algorithm with restart strategy in wireless networks. J. Netw. 2014, 9, 3327. [Google Scholar] [CrossRef] [Green Version]
- Moro, S.; Rita, P.; Vala, B. Predicting social media performance metrics and evaluation of the impact on brand building: A data mining approach. J. Bus. Res. 2016, 69, 3341–3351. [Google Scholar] [CrossRef]
- Tuarob, S.; Tucker, C.S. Automated discovery of lead users and latent product features by mining large scale social media networks. J. Mech. Des. 2015, 137, 071402. [Google Scholar] [CrossRef]
- Süzen, N.; Gorban, A.N.; Levesley, J.; Mirkes, E.M. Automatic short answer grading and feedback using text mining methods. Procedia Comput. Sci. 2020, 169, 726–743. [Google Scholar] [CrossRef]
- Zheng, C.T.; Liu, C.; San Wong, H. Corpus-based topic diffusion for short text clustering. Neurocomputing 2018, 275, 2444–2458. [Google Scholar] [CrossRef]
- Greco, F.; Polli, A. Emotional Text Mining: Customer profiling in brand management. Int. J. Inf. Manag. 2020, 51, 101934. [Google Scholar] [CrossRef]
- Hyder, K.; Maravelias, C.D.; Kraan, M.; Radford, Z.; Prellezo, R. Marine recreational fisheries—Current state and future Opportunities. ICES J. Mar. Sci. 2020, 77, 2171–2180. [Google Scholar] [CrossRef]
- Yang, Y.P.; Chen, D.K.; Gu, R.; Gu, Y.F.; Yu, S.H. Consumers’ Kansei needs clustering method for product emotional design based on numerical design structure matrix and genetic algorithms. Comput. Intell. Neurosci. 2016, 2016, 5083213. [Google Scholar] [CrossRef] [Green Version]
- Pajo, S.; Vandevenne, D.; Duflou, J.R. Automated feature extraction from social media for systematic lead user identification. Technol. Anal. Strateg. Manag. 2017, 29, 642–654. [Google Scholar] [CrossRef] [Green Version]
- Moral, C.; de Antonio, A.; Ferre, X.; Ramirez, J. A proposed UML-based common model for information visualization systems. Multimed. Tools Appl. 2021, 80, 12541–12579. [Google Scholar] [CrossRef]
- Anne Parlina, K.R.; Murf, H. Theme Mapping and Bibliometrics Analysis of One Decade of Big Data Research in the Scopus Database. Information 2020, 11, 69. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Yamamoto, T.; Dobashi, Y. Multi-scale object retrieval via learning on graph from multimodal data. Neurocomputing 2016, 207, 684–692. [Google Scholar] [CrossRef]
- Layton, R. Learning Data Mining with Python; Packt Publishing Ltd: Birmingham, UK, 2015. [Google Scholar]
- Raschka, S.; Mirjalili, V. Python Machine Learning: Machine Learning and Deep Learning with Python. In Scikit-Learn, and TensorFlow, 2nd ed.; Packt: Birmingham, UK, 2017. [Google Scholar]
- Khwaldeh, A.; Tahat, A.; Marti, J.; Tahat, M. Atomic data mining numerical methods, source code SQlite with Python. Procedia-Soc. Behav. Sci. 2013, 73, 232–239. [Google Scholar] [CrossRef]
- Stančin, I.; Jović, A. An overview and comparison of free Python libraries for data mining and big data analysis. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 977–982. [Google Scholar]
- Nie, J. Analysis of the Application of Python in Big Data Mining and Analysis. J. Guangxi Univ. Natl. 2018, 24, 76–79. [Google Scholar]
- Kane, F. Hands-on Data Science and Python Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Vincent, O.; Makinde, A.; Salako, O.; Oluwafemi, O. A self-adaptive k-means classifier for business incentive in a fashion design environment. Appl. Comput. Inform. 2018, 14, 88–97. [Google Scholar] [CrossRef]
- Chen, W.; Yu, Z.; Xian, Y.; Wang, Z.; Wen, Y. Mining Keywords from Short Text Based on LDA-Based Hierarchical Semantic Graph Model. Int. J. Inf. Syst. Serv. Sect. (IJISSS) 2020, 12, 76–87. [Google Scholar] [CrossRef]
- Ceccarini, C.; Mirri, S.; Salomoni, P.; Prandi, C. On exploiting Data Visualization and IoT for Increasing Sustainability and Safety in a Smart Campus. Mob. Netw. Appl. 2021, 26, 2066–2075. [Google Scholar] [CrossRef]
- Keim, D.A. Information visualization and visual data mining. IEEE Trans. Vis. Comput. Graph. 2002, 8, 1–8. [Google Scholar] [CrossRef]
- Măzăreanu, V.P. Using geographical information systems as an information visualization tool. A case study. Ann. Alexandru Ioan Cuza Univ.-Econ. 2013, 60, 13–20. [Google Scholar] [CrossRef]
- Topal, K.; Ozsoyoglu, G. Emotional classification and visualization of movies based on their IMDb reviews. Inf. Discov. Deliv. 2017, 45, 149–158. [Google Scholar] [CrossRef]
- Kraak, M.J. Semiology of Graphics: Diagrams Networks Maps. Cartogr. J. 2011, 48, 153. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Equipment Attributes | Laptops’ Design Elements and It Proportion (%) | ||
|---|---|---|---|
| Pleasure | Keyboard (14.40%) | Touch screen or not (14.79%) | Sound effect (21.01%) |
| Attribute | Color (33.85%) | Material (34.63%) | After-sale service (44.74%) |
| Expected | Dissipate heat (54.47%) | Screen size (55.25%) | Endurance (55.64%) |
| Properties | Weight (62.65%) | Price (69.65%) | Screen resolution (72.37%) |
| Processing system (80.54%) | Apperance (84.05%) | ||
| Basic attributes | Brand (85.21%) | Memory (87.55%) | Processing performance (92.22%) |
| Number | Valid Text |
|---|---|
| 1 | The service attitude of express brother is very good |
| 2 | It’s good to buy this kind of thing for the first time |
| ... | ... |
| 480 | Daily work is very good |
| 481 | The computer is fast |
| Word | Frequency of Occurrence | Total Proportion |
|---|---|---|
| Fast | 671 | 50.04% |
| Good screen | 229 | 17.08% |
| Nice shape | 168 | 12.53% |
| Slow startup | 73 | 5.44% |
| Good service attitude | 66 | 4.92% |
| Fine color | 61 | 4.55% |
| A little heavy | 47 | 3.50% |
| Design Element | Dictionary | Design Element | Dictionary |
|---|---|---|---|
| Material | Feel, Touch, Metal, Plastic, Grade, High/Low grade | Keyboard | Keyboard, Type, Knock, Feel |
| Memory | Enough, Hard disk, Mechanical hard disk, SSD, Save | Touch screen | Touch |
| After-sale service | Exchange, Complain, Attitude, Contact time, Express speed | Sound effect | Sound effects, Sound quality |
| Appearance | Color, Style, Good-looking, Fashion, Grade, High/Low grade | Color | Style, Good-looking, Fashion |
| Screen resolution | Screen effects, Image quality, Clear, Fuzzy, Display, Shadow | Brand | Lenovo, China-made, Brand |
| Endurance time Weight | Battery, Power, Durable, Abiding, No power | Dissipate heat | Burn, Fan, Hot |
| Weight | Weight, Light, Overweight, Heavy, Convenient, Carry | Screen size | Size to fit |
| Processing system | System, Microsoft, Software, Win10, Win7 | Price | High/Low price, Cost performance, Expensive, Cheap |
| Processing performance | Fast/Low, Powerful, Starting-up, Lagging |
| Overlapping Words | Design Element | Corresponding Weight (Total Ratio: 1) |
|---|---|---|
| Style, Good-looking, Fashion, Grade, High/Low grade | Overall appearance | 0.6 |
| Style, Good-looking, Fashion, Grade, High/Low grade | Color | 0.2 |
| Feel, Grade | Material | 0.12 |
| Feel | Keyboard | 0.08 |
| Design Element | Average Score of Emotional Assessment (−0.3∼+0.3) | Design Element | Average Score of Emotional Assessment (−0.3∼+0.3) |
|---|---|---|---|
| Keyboard | +0.1267 | Weight | −0.2037 |
| Touch screen or not | 0 | Price | +0.2230 |
| Sound effect | +0.1142 | Screen resolution | −0.1875 |
| Color | +0.2133 | Processing system | +0.0244 |
| Material | +0.1426 | Appearance | +0.1587 |
| After-sale service | +0.1231 | Brand | +0.2662 |
| Dissipate heat | −0.0189 | Memory | +0.0055 |
| Screen size | +0.1877 | Processing performance | +0.0102 |
| Endurance time | −0.1998 |
| Element Attribute | Pleasure Attribute | Expected Properties | Basic Attributes |
|---|---|---|---|
| keyboard, touch screen | dissipate heat, screen | Brand, memory | |
| Design element | or not, sound effect, color, material, after-sale service | size, endurance time, weight, price, screen resolution, processing system, appearance | processing performance |
| Model of Laptop | Comprehensive Score S_(a) |
|---|---|
| ASUS A456UR7200 (14 inch) | −0.0739 |
| ThinkPad Yi 480 (14 inch) | +0.1639 |
| Xiaomi Air (13.3 inch) | +0.1346 |
| Surface Laptop | +0.1644 |
| Apple MacBook Pro 2017 (13.3 inch) | +0.1467 |
| Option 1 | Option 2 | |||||
|---|---|---|---|---|---|---|
| Task Number | Average Score | Average Time/s | Average Accuracy | Average Score | Average Time/s | Average Accuracy |
| 1 | 4.5 | – | – | 4.1 | – | – |
| 2 | – | – | 100% | – | – | 100% |
| 3 | – | 14.5 | – | – | 10.3 | – |
| 4 | – | – | 46% | – | – | 51% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, Z.; Yan, Z.; Yao, H.; Liang, S. Design Demand Trend Acquisition Method Based on Short Text Mining of User Comments in Shopping Websites. Information 2022, 13, 110. https://doi.org/10.3390/info13030110
Xiong Z, Yan Z, Yao H, Liang S. Design Demand Trend Acquisition Method Based on Short Text Mining of User Comments in Shopping Websites. Information. 2022; 13(3):110. https://doi.org/10.3390/info13030110
Chicago/Turabian StyleXiong, Zhiyong, Zhaoxiong Yan, Huanan Yao, and Shangsong Liang. 2022. "Design Demand Trend Acquisition Method Based on Short Text Mining of User Comments in Shopping Websites" Information 13, no. 3: 110. https://doi.org/10.3390/info13030110