
Collective and Informal Learning in the ViewpointS Interactive Medium

 , , ,
, , ,
Abstract
:1. Introduction
- We immerge each member of the community inside the medium where s/he plays a double role: (i) the role of knowledge resource together with his/her own context of documents and topics and (ii) the role of agent interconnecting knowledge resources.
- We equip the medium with a topology based on a metric distance, in such that “knowledge trails” and “knowledge maps” emerge from the flow of interactions and guide the discovery of useful knowledge resources.
- We set a perspective mechanism allowing each user to tune his/her serendipity, for instance, by privileging or discarding his/her personal trails in the medium, or by privileging subjective versus factual connections among all the connections weaved by the community between all the knowledge resources.
- Finally, we rely on the topology of the medium for building indicators measuring the proximities between the community members and the knowledge resources.
2. State of the Art
- How does informal learning occur in communities sharing a medium?
- How can members of a community discover useful and unexpected resources for knowledge acquisition?
- Can the medium itself enhance the recommending process?
- What are the means for assessing informal learning?
2.1. How Does Informal Learning Occur in Communities Sharing a Medium?
2.2. How Can Members of a Community Discover Useful and Unexpected Resources for Knowledge Acquisition?
2.3. Can the Medium Itself Enhance the Recommending Process?
2.4. What Are the Means for Assessing Informal Learning?
- We consider a community of users where new knowledge resources may enter in a continuous flow and start by putting each user inside the medium where s/he plays a double role: (i) the role of knowledge resource together with his/her own context of documents and topics and (ii) the role of agent interconnecting knowledge resources. Doing so, we set the conditions for collaborative context-aware recommendation.
- We then equip the medium with a topology and a metrics, in such a way that metric knowledge maps reflecting the community structure emerge and guide the discovery of useful knowledge resources.
- We set a perspective mechanism allowing each user to tune his/her serendipity, for instance, by privileging or discarding his/her personal trails in the medium, or by privileging subjective versus factual connections.
- Finally, we rely on the topology of the medium for building indicators measuring the proximities between the community members and the knowledge resources, based on the recording of the individual interactions.
3. Materials and Methods
3.1. The Approach
3.2. The ViewpointS Model
- Human agent;
- Guest: a human agent who has a login and a password for interacting with the medium, meaning that the person has been invited to participate to collective learning;
- Document: any digital object (text, image, video, …) with a content that might support a knowledge acquisition process; a document is accessible through a local url or a web url;
- Topic: a linguistic expression used for describing the needs and queries of the members as well as the contents offered by the documents. In some way, the evolving set of all topics is the language of the community. It should be noted that this language is not administered; instead, it is continuously enriched by spontaneous contributions;
- Topic hub: a resource aimed at gathering similar topics;
- Event: a resource featuring anything ranging from a quick conversation, to a project or a business. Events aim at gathering guests (participating in the event) as well as documents (related to the event) or topics (related to the event).
- Factual: when the connection reflects a fact that can be proven true by its emitter, e.g., a factual connection between a guest and a document s/he authors or between a guest and an event s/he participates in;
- Subjective: when the connection reflects the beliefs or emotions or opinions of its emitter, e.g., when the guest A likes the resource B, or when the guest A believes that B is relevant with respect to C;
- Extractive: this type will be implemented later when artificial agents will automatically generate viewpoints;
- Normative: when a topic is semantically close to a topic hub according to the belief of the emitter;
- Serendip: these viewpoints are automatic traces summarizing the trails leading to “happy encounters” by the guests. If, for example, a guest searches around resource 1, finds resource 2, and reacts positively to it, then searches around resource 3, two serendip viewpoints “belonging to this guest” are automatically created: one linking resource 1 to resource 2, the other linking resource 2 to resource 3.
3.3. The ViewpointS Web Application
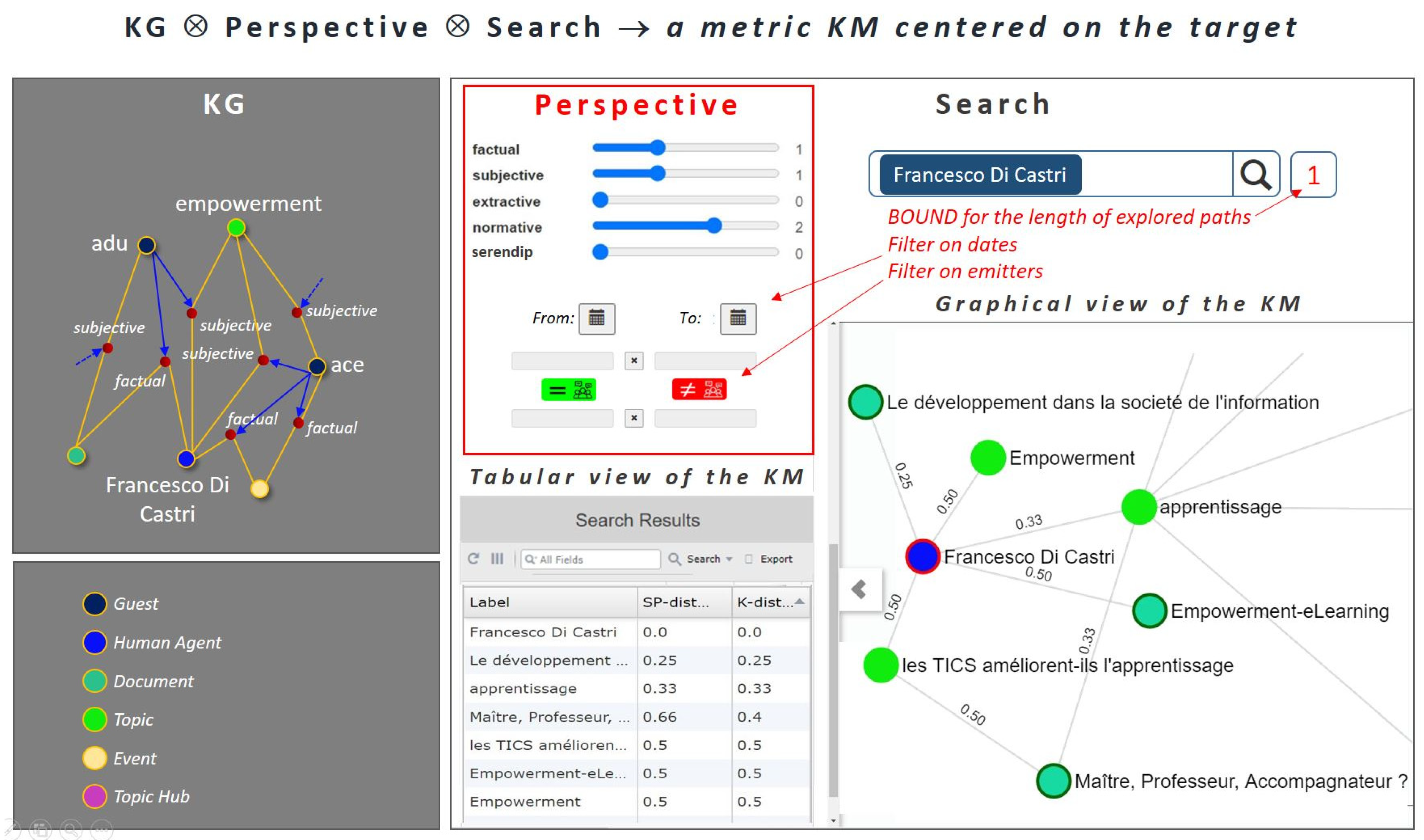
- Tuning the 5 sliders in order to attribute relative weights to the respective viewpoints’ types; these weights will be computed when aggregating the viewpoints into the links labelled with distances that appear in the graphical view;
- Selecting a temporal range, if needed;
- Filtering the viewpoints by emitters, if needed; the green button is used for restraining the emitters to a group; the red button is used for excluding a group of emitters.
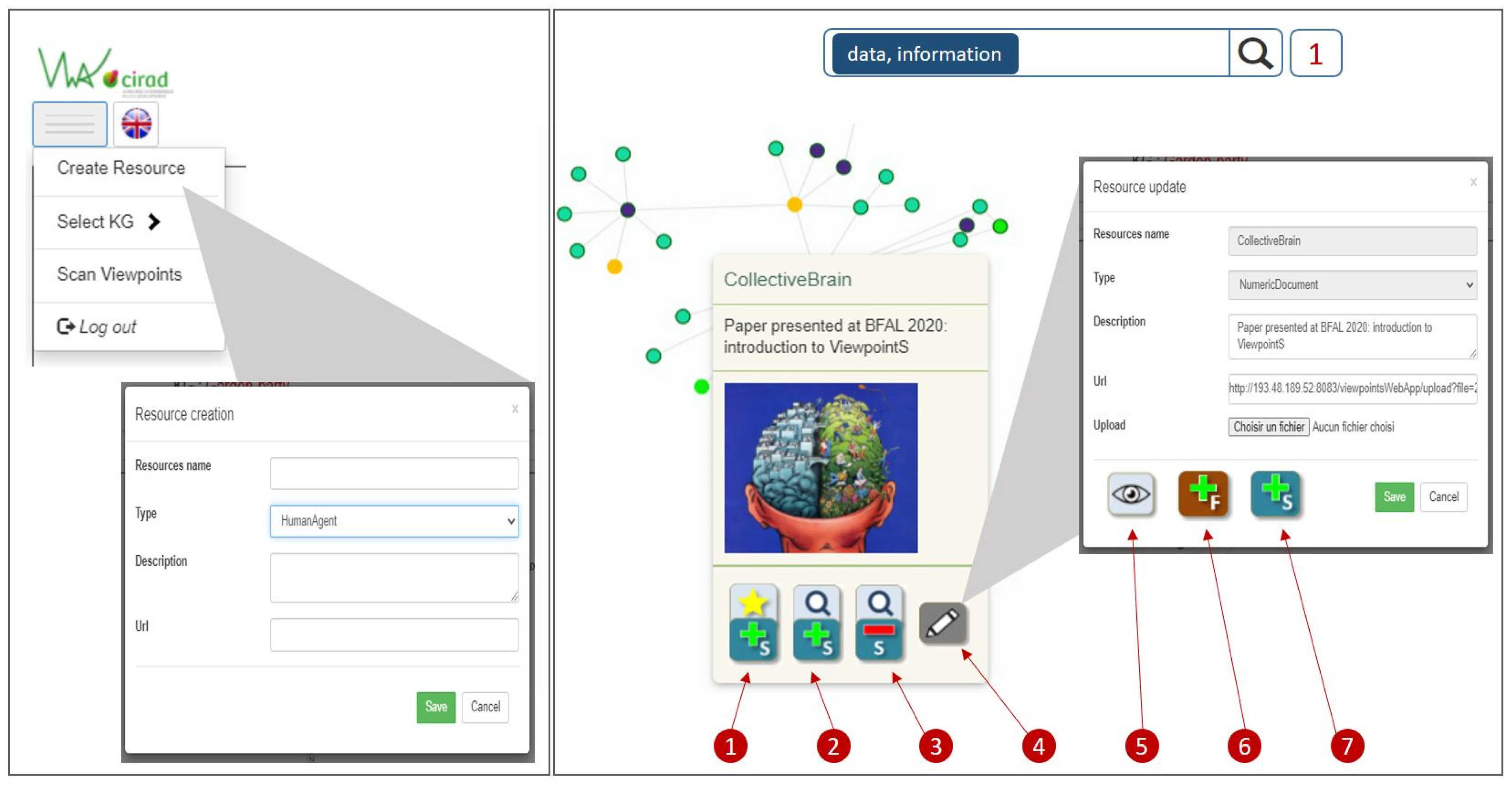
- Button 1 will generate a positive subjective viewpoint between the emitter (guest) and the resource “CollectiveBrain”.
- Button 2 will generate a positive subjective viewpoint between the target of the search (here: “data, information”) and the resource “CollectiveBrain”; this connection means that the emitter believes that the document “CollectiveBrain” is relevant with respect to the search “data, information”.
- Button 3 will generate a negative subjective viewpoint between the target of the search (here: “data, information”) and the resource “CollectiveBrain”; this connection means that the emitter believes the document “CollectiveBrain” to be irrelevant with respect to the search “data, information”.
- Button 4 will open a “Resource update” interface for updating the description and url, under the condition that the guest was the creator of the resource.
- Button 5 will allow the update of the preview image under the condition that the guest was the creator of the resource.
- Button 6 will allow the guest to connect the current resource to another resource via a factual viewpoint.
- Button 7 will allow the guest to connect the current resource to another resource via a subjective viewpoint.
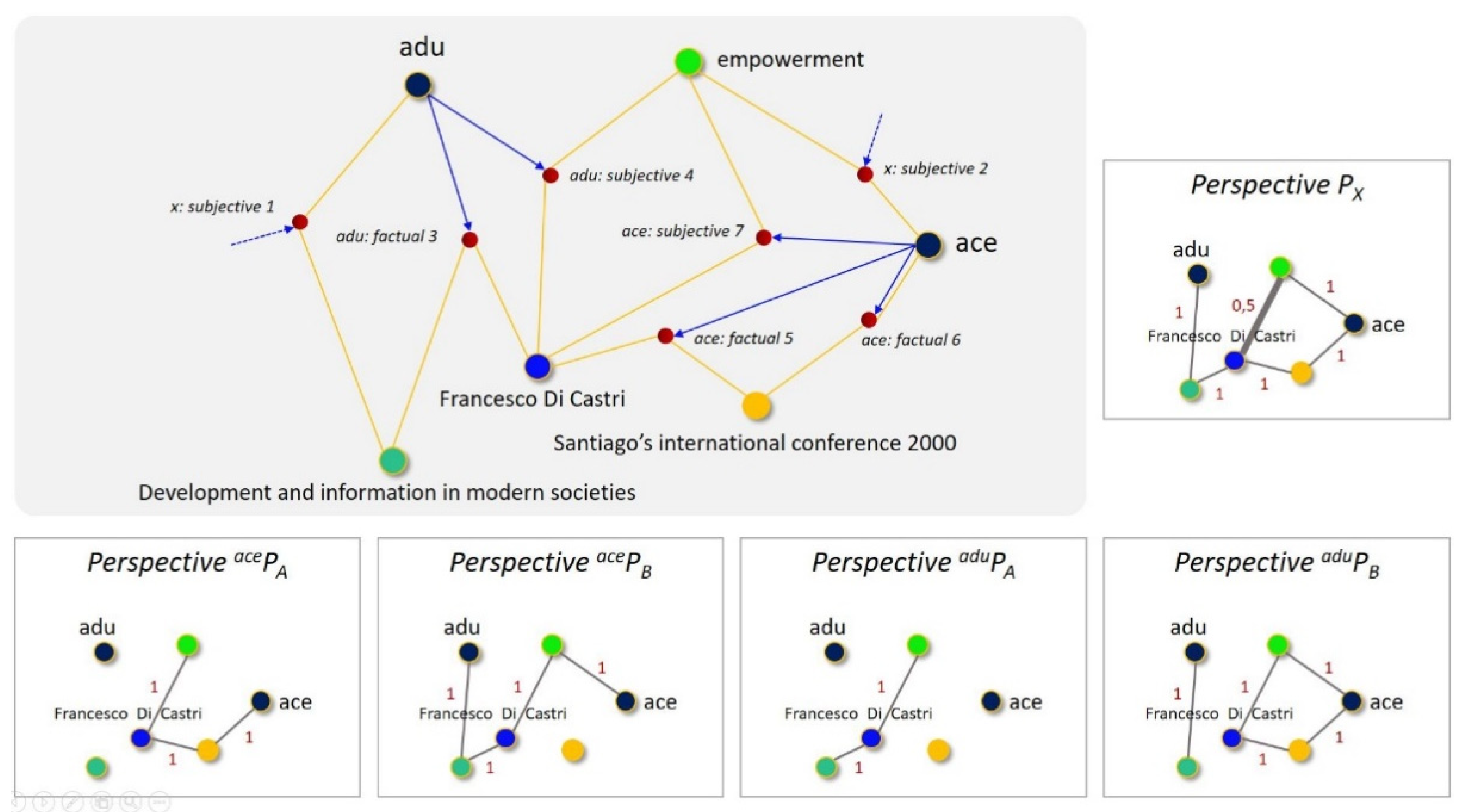
- Two guests “adu” and “ace” and a third human agent “Francesco Di Castri”;
- One event “Santiago …”;
- One document “Development …” and one topic “empowerment”;
- Seven numbered viewpoints denoted by their emitter and type: n°1 and n°2 emitted by “x”, n°3 and n°4 emitted by “adu” (3, 4) and n°5, 6, 7 emitted by “ace”.
3.4. The Garden-Party Experiment
- The dynamics of the community;
- The final structure of the medium;
- The mutual influence between the collective and the individual in terms of exploration and knowledge acquisition.
- To feel concerned by the issue of “learning from each other”; to be curious about what others would contribute;
- Not to be “allergic” to the Web;
- To have a “priority topic”, i.e., a topic of interest for which they would have at least one good document (image, text, audio, video, slide show, etc.) to share;
- To accept to dedicate to the experiment approximately half an hour a week for six weeks, at freely chosen pace times, without any reward.
- The 30 confirmed guests;
- The nine topic hubs defined by the authors;
- The priority topics brought in by the guests;
- Subjective viewpoints between each guest and her/his priority topic;
- Normative viewpoints between each priority topic and the appropriate topic hub(s);
- A set of events reflecting the real-life connections between the guests;
- Factual viewpoints reflecting the participation of guests to events.
- Strategy #1: Human first. Choose the following perspective: [“normative” slider = 0; other sliders = 1]. Search for the topic “group photo”, select a resource guest, double-click for search, and explore his/her neighborhood.
- Strategy #2: Topic first. Choose the following perspective: [“normative” slider = 2; other sliders = 1]. Start from one of the nine topic hubs, select one, and explore its neighborhood.
- Strategy #3: Any resource. Choose the following perspective: [all sliders = 1]. Start typing a word that inspires you in the search bar, wait for auto-completion to display a resource (if any), click on search, and explore its immediate neighborhood.
- Strategy #4: Most recent. Use the “scan viewpoints” feature while ordering from the most recent to the oldest one and memorize a resource of interest. Choose the following perspective: [all sliders = 1]. Explore the immediate neighborhood of the resource of interest.
3.5. The Data Collection and Measures
- Two guests “adu” and “ace” and a third human agent “Francesco Di Castri”;
- One event “Santiago …”;
- One document “Development …” and one topic “empowerment”;
- Seven viewpoints denoted “emitter: type & number”: two emitted by “x” (1, 2), two emitted by “adu” (3, 4), and three emitted by “ace” (5, 6, 7).
4. Results
4.1. Analyzing the Dynamics of the Community
- Nine topic hubs;
- Sixty-three topics (the priority topics chosen by the guests);
- Twenty-nine events;
- Fifty-five human agents (expected guests), among which 30 guests participated up to the end.
- Three hundred and seventy-four input documents;
- Two hundred and seventeen input topics, which yielded a total of 280 topics;
- Thirty-seven input human agents (authors of documents or referees for topics), which yielded a total of 92 human agents (30 guests + 25 too-busy + 37 people outside the experiment).
- Five thousand two hundred and ninety-five viewpoints of type serendip;
- Two thousand six hundred and two viewpoints of type subjective;
- Nine hundred and thirty-one viewpoints of type factual.
4.2. Analyzing the Final Structure of the Medium
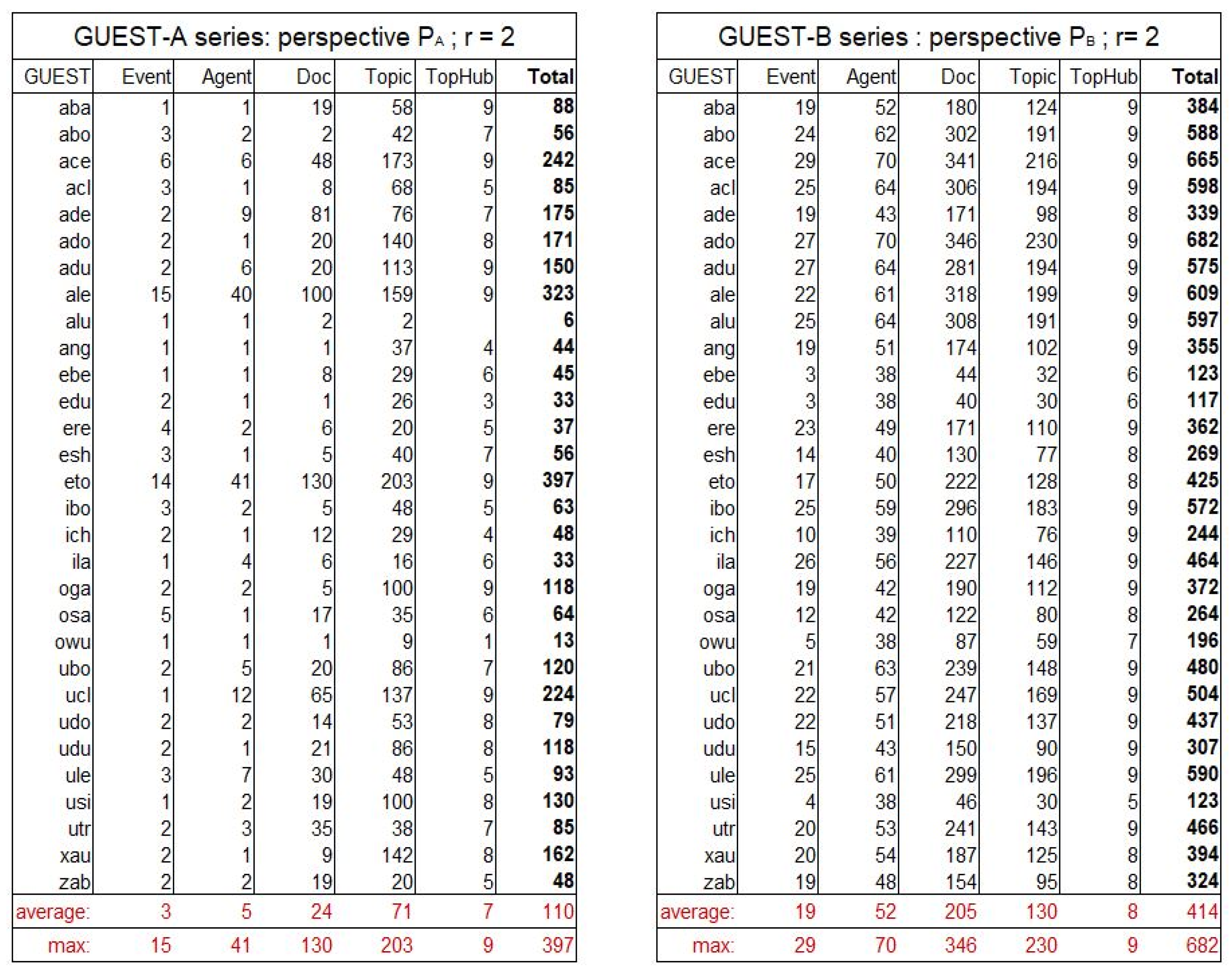
4.2.1. Overview of the Extracted Data
4.2.2. Distribution of the Documents and Topics with Respect to the Topic Hubs
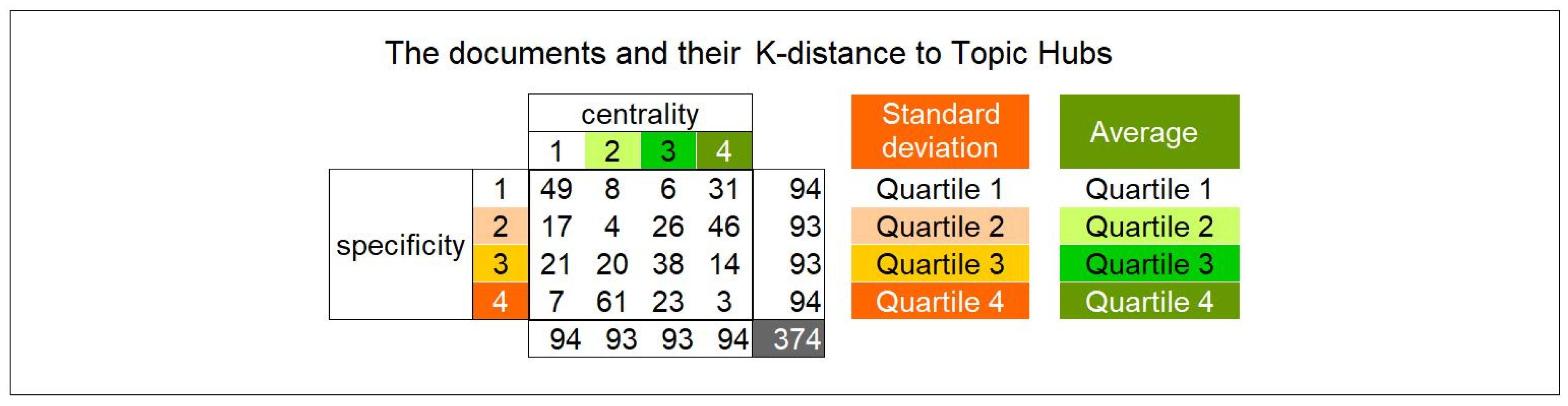
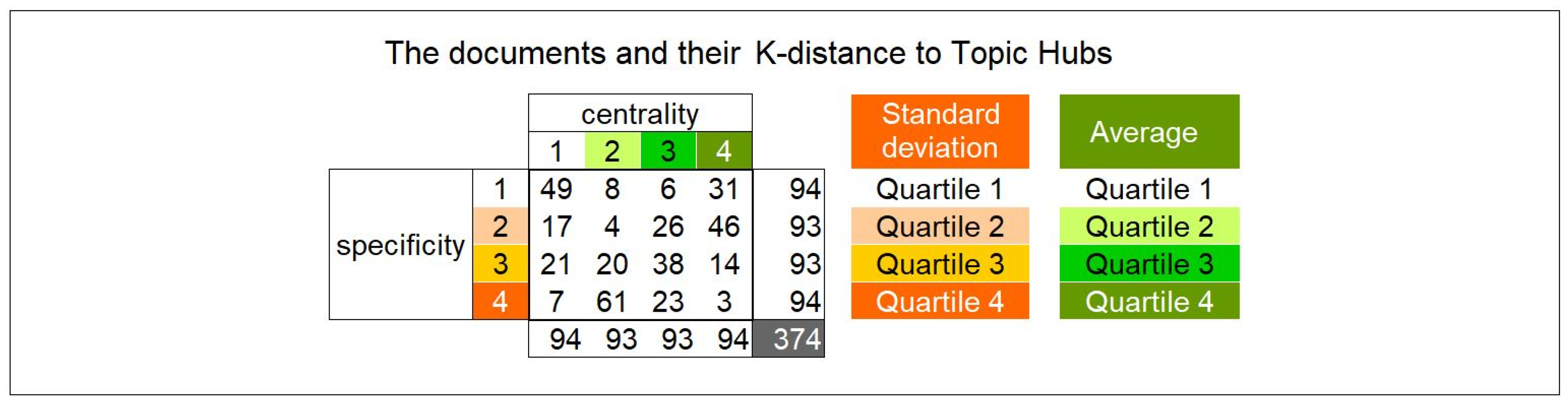
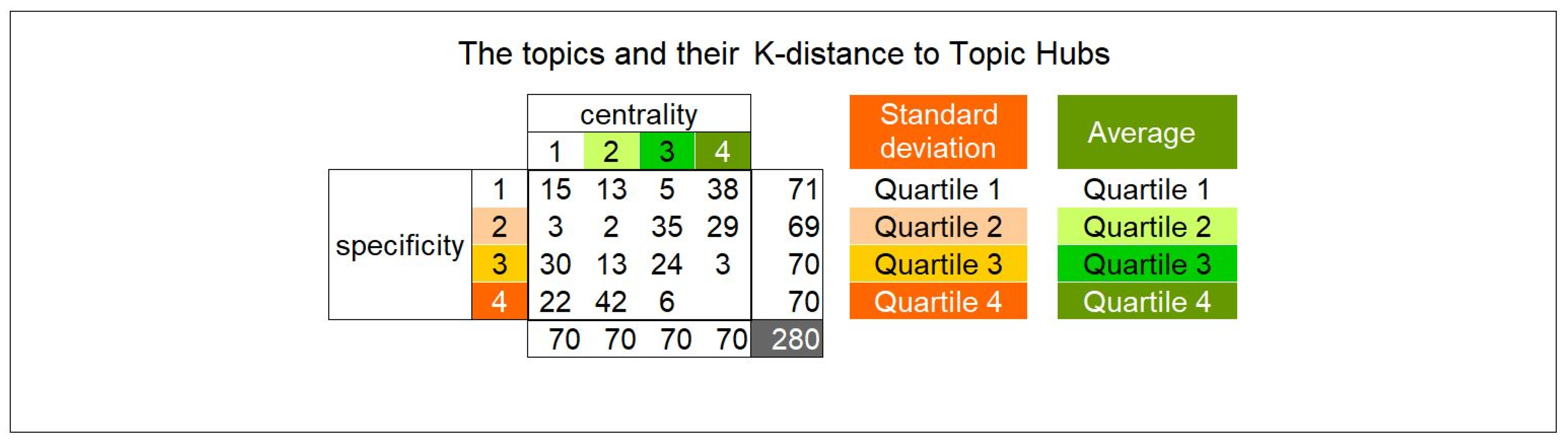
- Collection of the K-distances between all documents and the nine topic hubs.
- Computation, for each document “x” of the average A(x) and the standard deviation Sd(x) of the nine K-distances to the topic hubs. Absent distances (greater than the radius) have been discarded in the average. The “standard deviation of the population” formula has been used.
- Computation of the respective quartiles for A(x) and Sd(x) along the 374 documents.
- Classification of each document from 1 to 4 according to its A-quartile: “1” means high average, “4” means low average, in such a way that this ranking is an indicator of the “centrality” of the document. A “central” document is close to all the topic hubs and, therefore, has a low average distance and, therefore, is ranked 4.
- Classification of each document from 1 to 4 according to its Sd-quartile: “1” means low standard deviation, “4” means high standard deviation, in such a way that this ranking is an indicator of the “specificity” of the document. A “specific” document has a high standard deviation among distances and, therefore, is ranked 4.
- Computation of the distribution of the 374 documents according to this 4*4 classification; the result is illustrated in Figure 9.
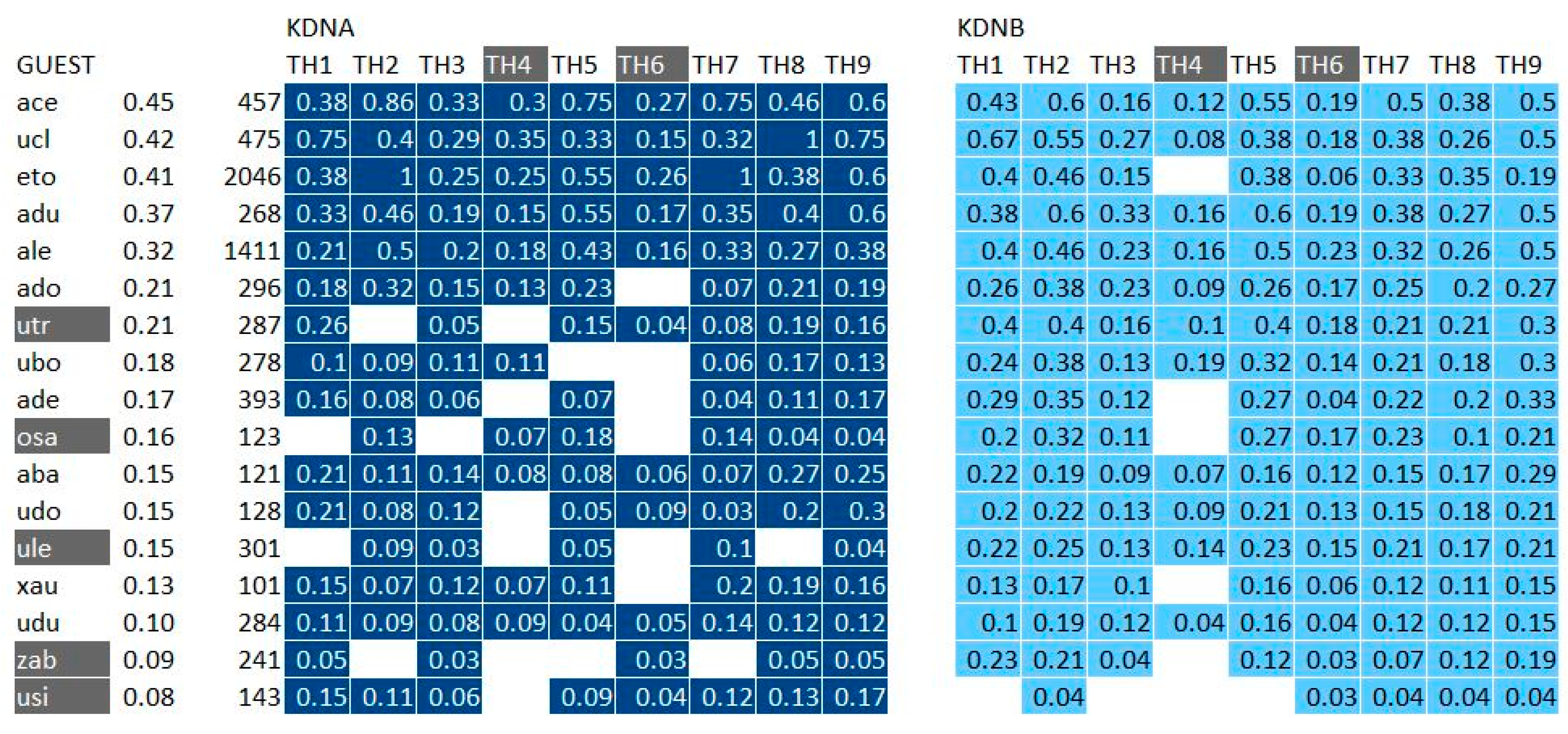
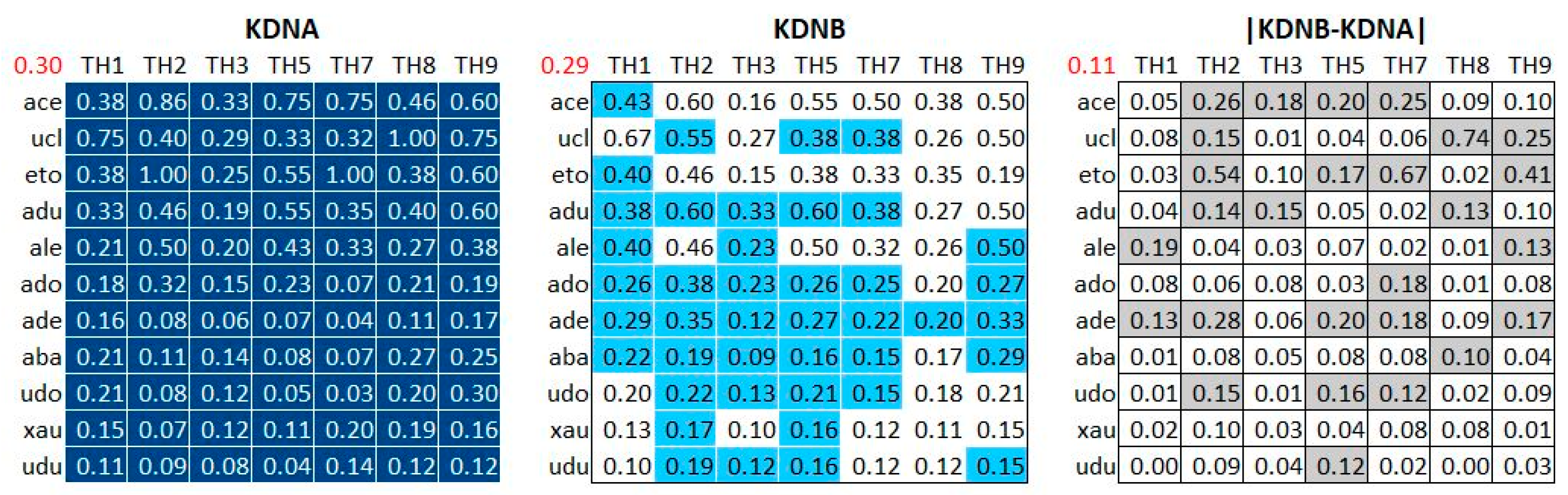
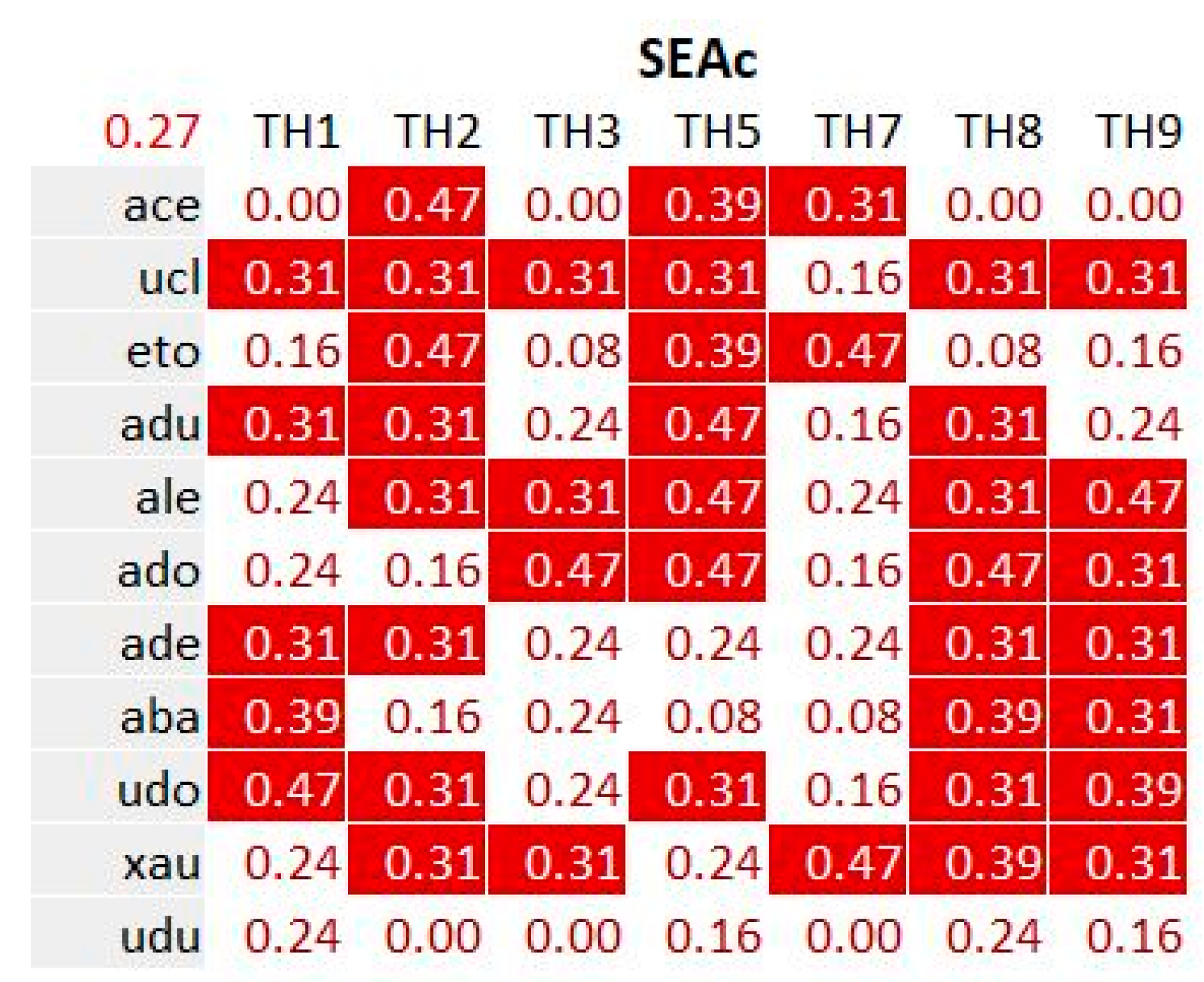
4.2.3. Positions of the Guests Relatively to the Topic Hubs
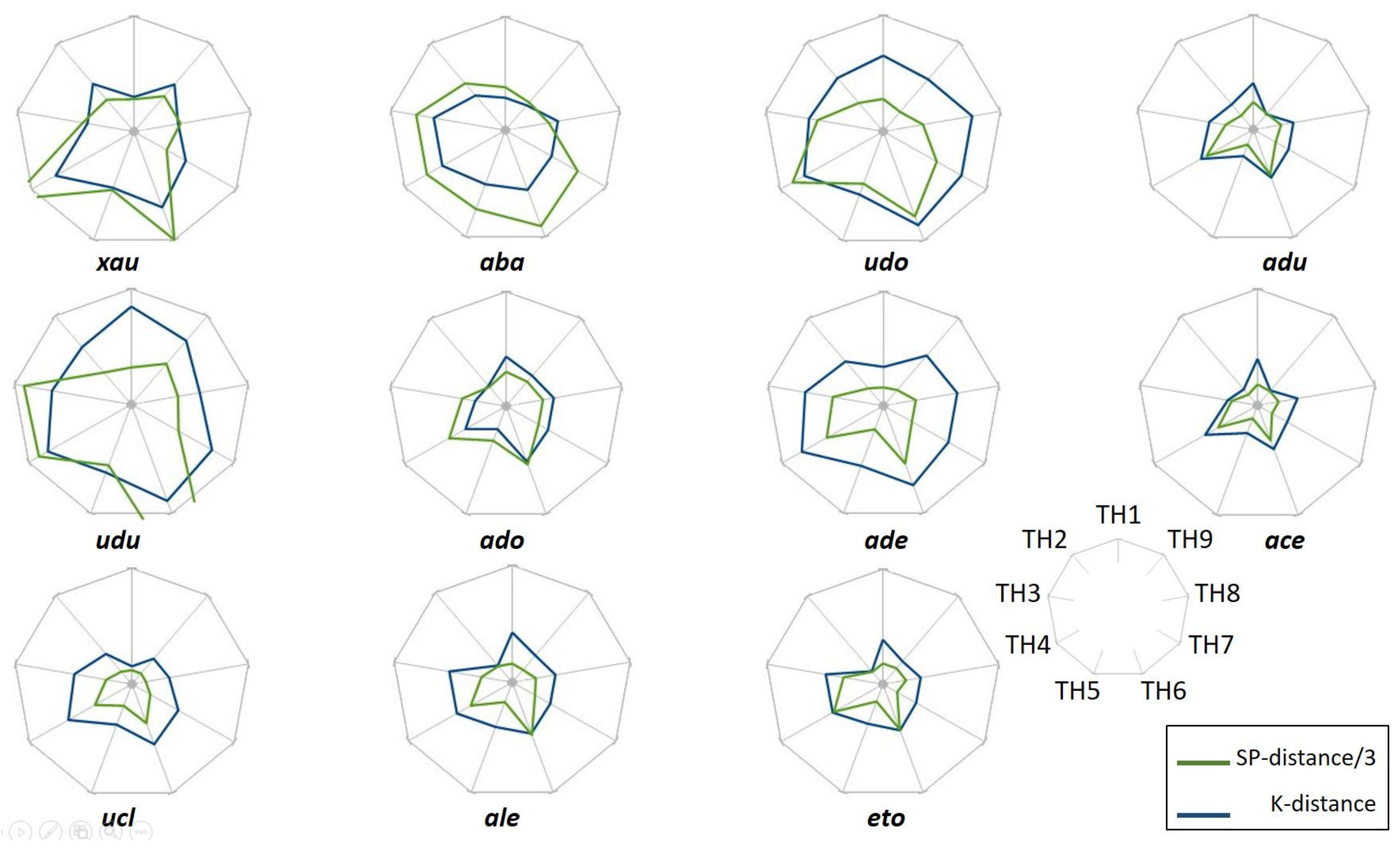
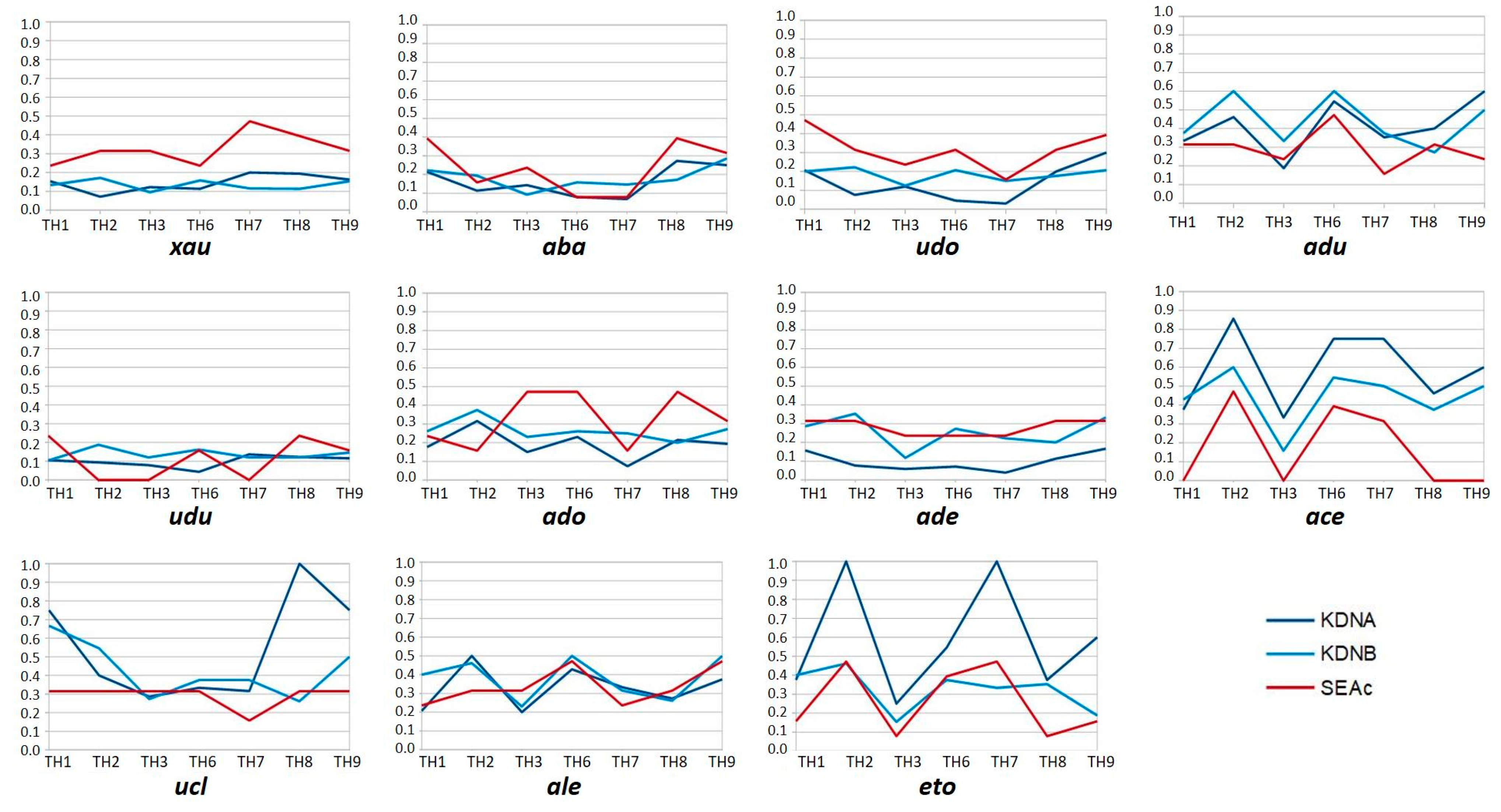
4.3. Analyzing the Medium-Enhanced Serendipity by Exploiting the Stereoscopic Knowledge Maps
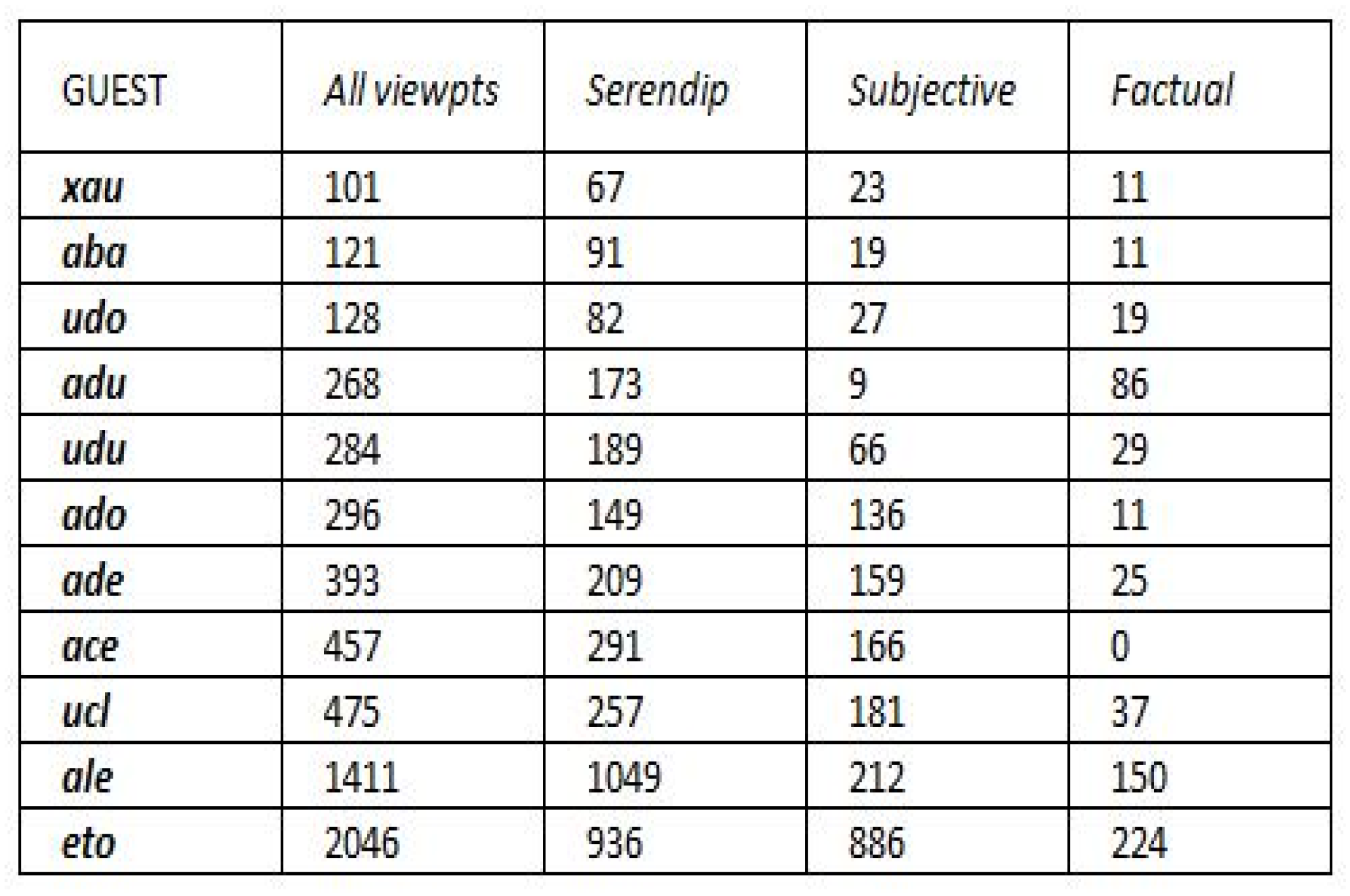
4.3.1. Overview of the Extracted Data and Selection of a Sample
4.3.2. Discussing the Possibility of a Diachronic Analysis of the Interactions with the Medium
4.3.3. Mutual Influence between the Individual and the Collective
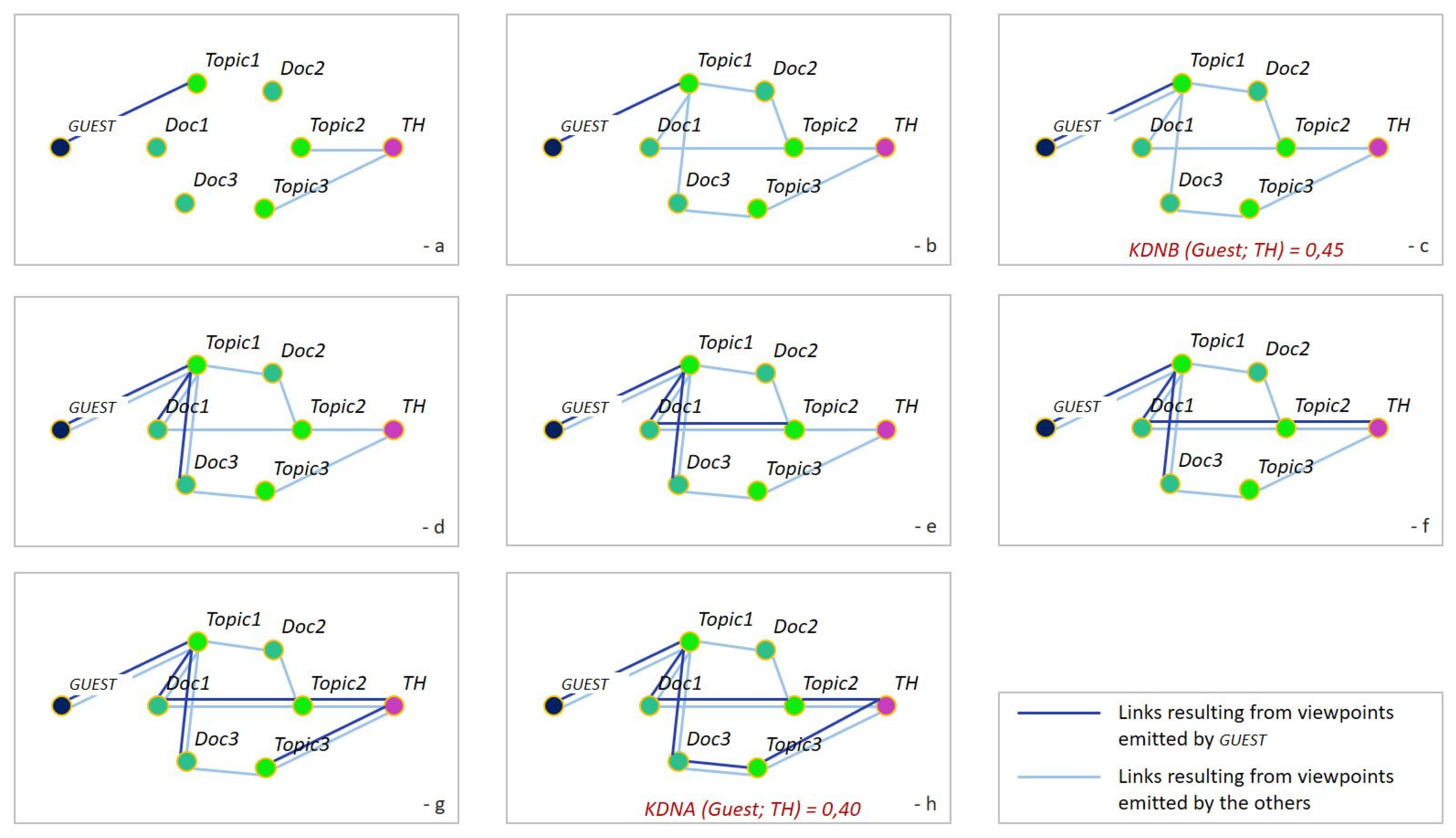
An Imaginary Case
- Initial state: guest has connected himself (dark blue link) to his/her priority topic: Topic1. Other guests have input their own respective priority topics: Topic2 and Topic3, and connected them to th.
- Some other guests input Doc1, Doc2, and Doc3 and connect these documents (light blue links) to topics by viewpoints of type subjective (see Section 2.2).
- One other guest searches on Topic1, finds guest then searches on guest; this results in a new viewpoint (light blue link) of type serendip between guest and Topic1. guest is now connected to th via viewpoints emitted by others (light blue links). We may, therefore, compute KDNB (guest; th) = 0.45.
- guest searches on Topic1, finds Doc1 and Doc3, reads them, and agrees they are relevant with respect to Topic1; this results in new subjective connections (dark blue links) between Topic1 and these documents.
- guest searches on Doc1, finds Topic2, and searches on Topic2; this results in a new serendip connection between Doc1 and Topic2.
- When searching on Topic2, guest finds th and then searches on th; this results in a new serendip connection between Topic2 and th.
- When searching on th, guest finds Topic3 and then searches on Topic3; this results in a new serendip connection between th and Topic3.
- When searching on Topic3, guest meets Doc3 for the second time; he/she agrees that Doc3 is also relevant with respect to Topic3. This results in a new subjective connection between Topic3 and Doc3. Finally, guest is connected to th via viewpoints emitted by himself (dark blue). We may, therefore, compute KDNA (guest; th) = 0.40.
Exploiting the Stereoscopic Maps
Cross Analysis of KDNA, KDNB and SEAc
5. Discussion
- Did informal learning occur among the guests of the Garden-party?
- Did the guests discover useful and unexpected resources for knowledge acquisition?
- Does the ViewpointS medium enhance the recommending process?
- Do the ViewpointS metrics allow a form of assessment for informal learning?
5.1. May We Consider the Guests of the Garden-party as the Members of a Community?
5.2. Did the Guests Discover Useful and Unexpected Resources for Knowledge Acquisition?
- Five thousand two hundred and ninety-five viewpoints of type serendip, acknowledging interesting encounters (these viewpoints are automatically generated as soon as a guest undertakes a search or reacts positively to a finding);
- Two thousand six hundred and two viewpoints of type subjective, acknowledging either emotional or rational reactions of their emitters to what they have encountered;
- Nine hundred and thirty-one viewpoints of type factual, acknowledging new logical links weaved by their emitters between the resources of the corpus.
5.3. Does the ViewpointS Medium Enhance the Recommending Process?
5.4. Do the ViewpointS Metrics Allow a Form of Assessment for Informal Learning?
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nyce, J.M.; Kahn, P. (Eds.) From Memex to Hypertext: Vannevar Bush and the Mind’s Machine; Academic Press Professional, Inc.: Cambridge, MA, USA, 1991; ISBN 978-0-12-523270-8. [Google Scholar]
- Engelbart, D.C.; Engelbart, C. Bootstrapping Organizations into the 21st Century: A Strategic Framework, Bootstrap Institute, December 1991 (AUGMENT 132803). Available online: https://www.dougengelbart.org/content/view/115/000/ (accessed on 10 January 2021).
- Di Castri, F. Access to information and e-learning for local empowerment: The requisite for human development and environmental protection. In Towards the Learning Grid: Advances in Human Learning Services; Frontiers in Artificial Intelligence and Applications; Ritrovato, P., Allison, C., Cerri, S.A., Dimitrakos, T., Gaeta, M., Salerno, S., Eds.; IOS Press: Amsterdam The Netherlands, 2005; Volume 127, pp. 12–21. [Google Scholar]
- Scardamalia, M. Can schools enter a Knowledge Society? In Educational Technology and the Impact on Teaching and Learning; Selinger, M., Wynn, J., Eds.; RM: Abingdon, UK, 2000; pp. 5–10. [Google Scholar]
- De Cindio, F.; Peraboni, C.; Cerri, S.A. Network Communities. In Encyclopedia of the Sciences of Learning; Seel, N.M., Ed.; Springer: Boston, MA, USA, 2012. [Google Scholar]
- Schneider, M.; Stern, E. L’apprentissage dans une perspective cognitive. In Comment Apprend-On? La Recherche au Service de la Pratique; Dumont, H., Istance, D., Benavides, F., Eds.; Éditions OCDE: Paris, France, 2010; pp. 73–95. [Google Scholar]
- Breuker, J.; Cerri, S.A. Learning as a Side Effect. In Encyclopedia of the Sciences of Learning; Seel, N.M., Ed.; Springer: Boston, MA, USA, 2012. [Google Scholar]
- Van Andel, P. Anatomy of the unsought finding. Serendipity: Origin, history, domains, traditions, appearances, patterns and programmability. Br. J. Philos. Sci. 1994, 45, 631–648. [Google Scholar] [CrossRef]
- Herlocker, L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating Collaborative Filtering Recommender Systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Kotkov, D.; Konstan, J.A.; Zhao, Q.; Veijalainen, J. Investi-gating Serendipity in Recommender Systems Based on Real User Feedback. In Proceedings of the SAC 2018: Symposium on Applied Computing, Pau, France, 9–13 April 2018. [Google Scholar]
- Adamic, L.; Zhang, J.; Bakshy, E.; Ackerman, M. Knowledge sharing and Yahoo Answers: Everyone knows something. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 665–674. [Google Scholar]
- Toms, E. Serendipitous Information Retrieval. Proceedings of DELOS Workshop: Information Seeking, Searching and Querying in Digital Libraries. 2000. Available online: https://delosnetwork.com/workshops/ (accessed on 13 February 2021).
- Lops, P.; de Gemmis, M.; Semeraro, G. Content-based Recommender Systems: State of the Art and Trends. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P., Eds.; Springer: Boston, MA, USA, 2011. [Google Scholar]
- Yeung, C.M.A.; Gibbins, N.; Shadbolt, N. A Study of User Profile Generation from Folksonomies. In Proceedings of the Workshop on Social Web and Knowledge Management, Social Web 2008 Workshop at WWW2008, Beijing, China, 20–24 April 2008. [Google Scholar]
- Verbert, K.; Manouselis, N.; Ochoa, X.; Wolpers, M.; Drachsler, H.; Bosnic, I.; Duval, E. Context-aware recommender systems for learning: A survey and future challenges. IEEE Trans. Learn Technol. 2012, 5, 318–335. [Google Scholar] [CrossRef]
- Moreno, J.L. Who Shall Survive? A New Approach to the Problem of Human Interrelations; Nervous and Mental Disease Monograph Series; Nervous and Mental Disease Publishing Co.: Washington, DC, USA, 1934. [Google Scholar] [CrossRef]
- Csauthors.net. Available online: https://www.csauthors.net/distance (accessed on 13 February 2021).
- Klerkx, J.; Duval, E. Visualising Social Bookmarks. Soc. Inf. Retr. Technol. Enhanc. Learn 2009, 10, 2. [Google Scholar]
- Jivet, J.; Scheffel, M.; Specht, M.; Drachsler, H.Y. License to Evaluate: Preparing Learning Analytics Dashboards for Educational Practice. In Proceedings of the LAK’18: International Conference on Learning Analytics and Knowledge, Sydney, Australia, 7–9 March 2018; ACM: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Jaffé, A.; Trajtenberg, M. Flows of knowledge from universities and federal laboratories: Modeling the flow of patent citations over time and across institutional and geographic boundaries. Proc. Natl. Acad. Sci. USA 1996, 93, 12671–12677. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Troussas, C.; Krouska, A.; Sgouropoulou, C. A Novel Teaching Strategy through Adaptive Learning Activities for Computer Programming. IEEE Trans. Educ. 2020. [Google Scholar] [CrossRef]
- Coudel, E.; Rey-Valette, H.; Tonneau, J.P. Which competencies and learning facilitate the involvement of local actors in territorial governance? The example of a Fatmer University in Brazil. Int. J. Sustain. Dev. 2008, 11, 206–225. [Google Scholar] [CrossRef]
- Vygotsky, L.S. Mind in society. In The Development of Higher Psychological Functions; Cole, M., John-Steiner, V., Scribner, S., Souberman, E., Eds.; Harvard University Press: Cambridge, MA, USA, 1978. [Google Scholar]
- Muthukrishna, M.; Henrich, J. Innovation in the Collective Brain. Philos. Trans. R. Soc. B 2016, 371. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lemoisson, P.; Surroca, G.; Jonquet, C.; Cerri, S.A. ViewpointS: Capturing formal data and informal contributions into an adaptive knowledge graph. Int. J. Knowl. Learn. 2018, 12, 119–145. [Google Scholar] [CrossRef] [Green Version]
- Lemoisson, P.; Cerri, S.A.; Rakotondrahaja, C.; Andriamialison, A.S.P.; Sankar, H. VWA: ViewpointS Web Application to Assess Collective Knowledge Building. In Proceedings of the 11th International Conference on Computational Collective Intelligence (ICCCI), Hendaye, France, 4–6 September 2019; pp. 3–15. [Google Scholar]
- Lemoisson, P.; Cerri, S.A. ViewpointS: Towards a Collective Brain. In Proceedings of the ICCCI: International Conference on Computational Collective Intelligence, Bristol, UK, 5–7 September 2018; pp. 3–12. [Google Scholar]
- Edelman, G.M.; Tononi, G. A Universe of Consciousness: How Matter Becomes Imagination; Basic Books: New York, NY, USA, 2000. [Google Scholar]
- Dunning, D. Chapter five—The Dunning–Kruger Effect: On Being Ig-norant of One’s Own Ignorance. Adv. Exp. Soc. Psychol. 2011, 44, 247–296. [Google Scholar] [CrossRef]
- Cerri, S.A.; Lemoisson, P. Sovereignty by personalization of information search: How collective wisdom may influence my knowledge. In Intelligent Tutoring Systems 2021; Springer: Berlin/Heidelberg, Germany, 2021; in press. [Google Scholar]
- Cerri, S.A.; Lemoisson, P. Serendipitous Learning Fostered by Brain State Assessment and Collective Wisdom. In Proceedings of the 2nd International Conference on Brain Function Assessment in Learning (BFAL), Heraklion, Greece, 9–11 October 2020. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TH1 | Food, sports, sexuality, health, body life |
| TH2 | Learning |
| TH3 | Arts, cultures, views about the world |
| TH4 | Scientific knowledge and media coverage |
| TH5 | Data, information, collective intelligence, action |
| TH6 | Emotions, feelings and opinions, values, conscience |
| TH7 | Governance, intervention approaches, public action |
| TH8 | The humans on the planet, yesterday, today, and tomorrow |
| TH9 | Philosophy, religions, wisdoms, daily life |
| The series of complete maps | The th-x series of maps exploit the trails of the 30 guests. Each th-x map results from a request exploring the neighborhood of one topic hub, with radius = 1.5, under the perspective PX [all sliders = 1; all viewpoints]. |
| The series of stereoscopic maps | The guest-a series of maps exclusively exploit the targeted guests’ trails; they reflect the intensity of interaction by the guest with all the resources present in his/her neighborhood. Each guest-a map results from a request exploring the neighborhood of one guest, with radius = 2, under the perspective guestPA [all sliders = 1; only the viewpoints emitted by the guest]. The guest-b series of maps exclude the targeted guests’ trails and exploit the other guests’ trails; they reflect the intensity of interaction by the others with the resources present in the guests’ neighborhood. Each guest-b request map results from a request exploring the neighborhood of one guest, with radius = 2, under the perspective guestPB [all sliders = 1; all viewpoints except the viewpoints emitted by the guest]. |
| SEAa | Based on the self-evaluated proximities between each guest and each topic hub; computes the difference of self-evaluated proximities between the beginning and end of the experiment. Uses a linear scale [no = 0|rather no = 3|rather yes = 6|yes = 9] Normalized by the maximum absolute value of all self-evaluations. |
| SEAc | Based on the self-evaluated proximities between each guest and each topic hub; computes the average self-evaluated proximity between the beginning and end of the experiment. Uses a linear scale [no = 0|rather no = 3|rather yes = 6|yes = 9] Normalized by the maximum absolute value of all self-evaluations. |
| KDNA | Computes the k-proximity (inverse of the k-distance) between resources when using the perspective PA (the guests’ trails). Normalized by the maximum value obtained when computing KDNA and KDNB. |
| KDNB | Computes the k-proximity (inverse of the k-distance) between resources when using the perspective PB (the other guests’ trails). Normalized by the maximum value obtained when computing KDNA and KDNB. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lemoisson, P.; Cerri, S.A.; Douzal, V.; Dugénie, P.; Tonneau, J.-P. Collective and Informal Learning in the ViewpointS Interactive Medium. Information 2021, 12, 183. https://doi.org/10.3390/info12050183
Lemoisson P, Cerri SA, Douzal V, Dugénie P, Tonneau J-P. Collective and Informal Learning in the ViewpointS Interactive Medium. Information. 2021; 12(5):183. https://doi.org/10.3390/info12050183
Chicago/Turabian StyleLemoisson, Philippe, Stefano A. Cerri, Vincent Douzal, Pascal Dugénie, and Jean-Philippe Tonneau. 2021. "Collective and Informal Learning in the ViewpointS Interactive Medium" Information 12, no. 5: 183. https://doi.org/10.3390/info12050183
APA StyleLemoisson, P., Cerri, S. A., Douzal, V., Dugénie, P., & Tonneau, J.-P. (2021). Collective and Informal Learning in the ViewpointS Interactive Medium. Information, 12(5), 183. https://doi.org/10.3390/info12050183