
A Comprehensive Survey of Knowledge Graph-Based Recommender Systems: Technologies, Development, and Contributions


Abstract
:1. Introduction
- We explore traditional and more recent developments of filtering methods for a recommender system.
- We identify and analyze proposals related to knowledge graph-based recommender systems.
- We present the most relevant contributions by application domain.
- We outline future directions of research in the domain of recommender systems.
2. Filtering Approaches for Recommendation Systems
2.1. Collaborative Filtering
2.2. Content-Based Filtering
2.3. Demographic Filtering
2.4. Context Aware-Based Filtering
2.5. Knowledge-Based Filtering
2.6. Hybrid Filtering
3. Recommender Systems over Knowledge Graphs
3.1. Ontology-Based (OB) Recommendation
3.2. Linked Open Data (LOD)-Based Recommendation
3.3. Embedding-Based Recommendation
3.4. Path-Based Recommendation
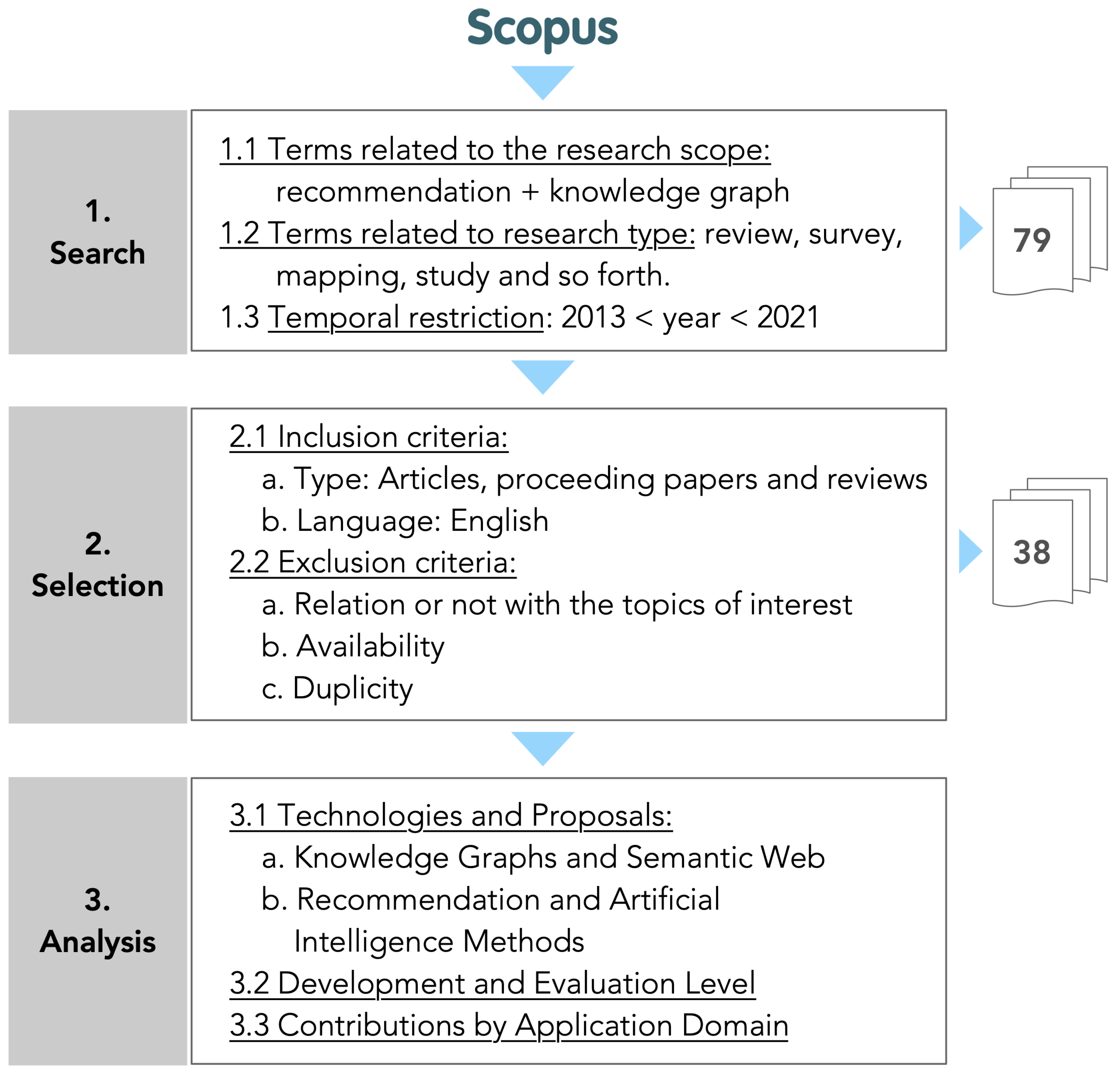
4. Methodology
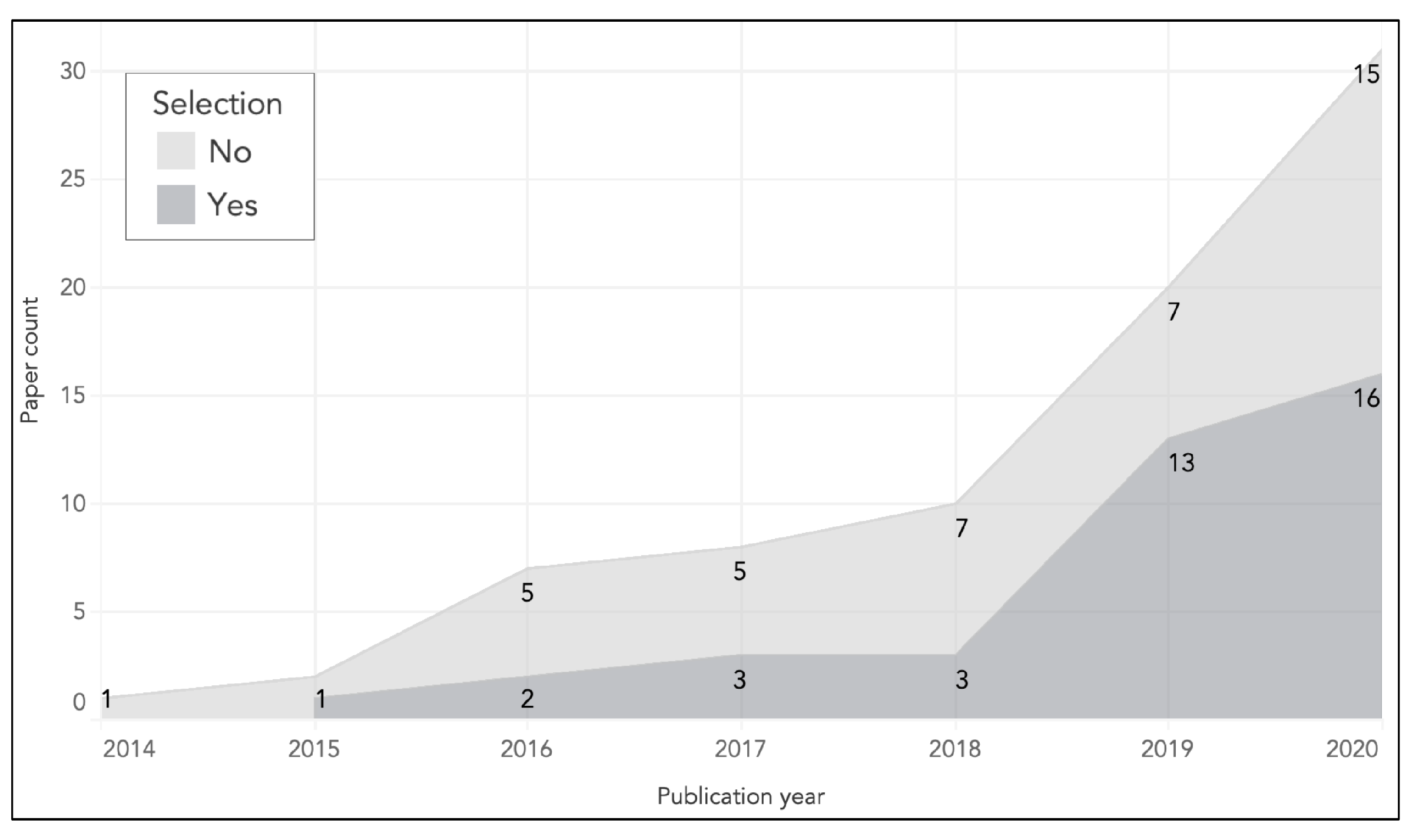
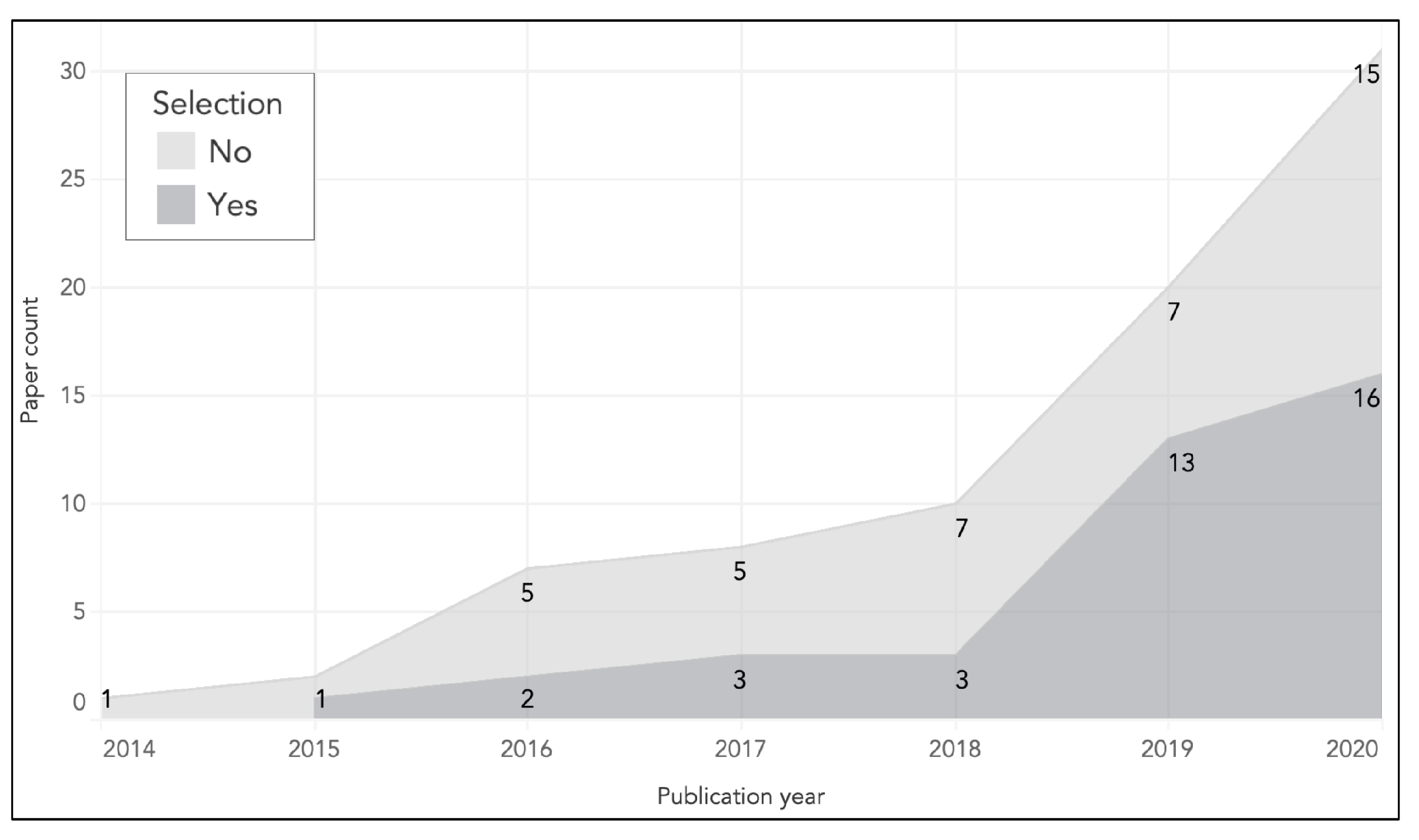
4.1. Search
| Listing 1. Search query. |
| ABS ( content AND filtering )) AND (ABS (" knowledge graph ")) |
| AND |
| (TITLE -ABS ( review ) OR TITLE -ABS( survey ) OR TITLE - ABS( state ?of?the ?art) |
| OR TITLE -ABS( SOTA ) OR TITLE -ABS( mapping ) OR TITLE ( study )) |
| AND |
| PUBYEAR > 2013 AND PUBYEAR < 2021 |
4.2. Selection
- Relation with the topic of interest. If the document did not describe a study or did not refer to the application of recommender systems in knowledge graphs, then it was excluded.
- Availability. If the document was not available online or if access to its complete content was not possible, then it was excluded.
- Duplicity. If there was more than one paper on the same topic and corresponding to the same authors, the most recently published paper was chosen.
4.3. Analysis
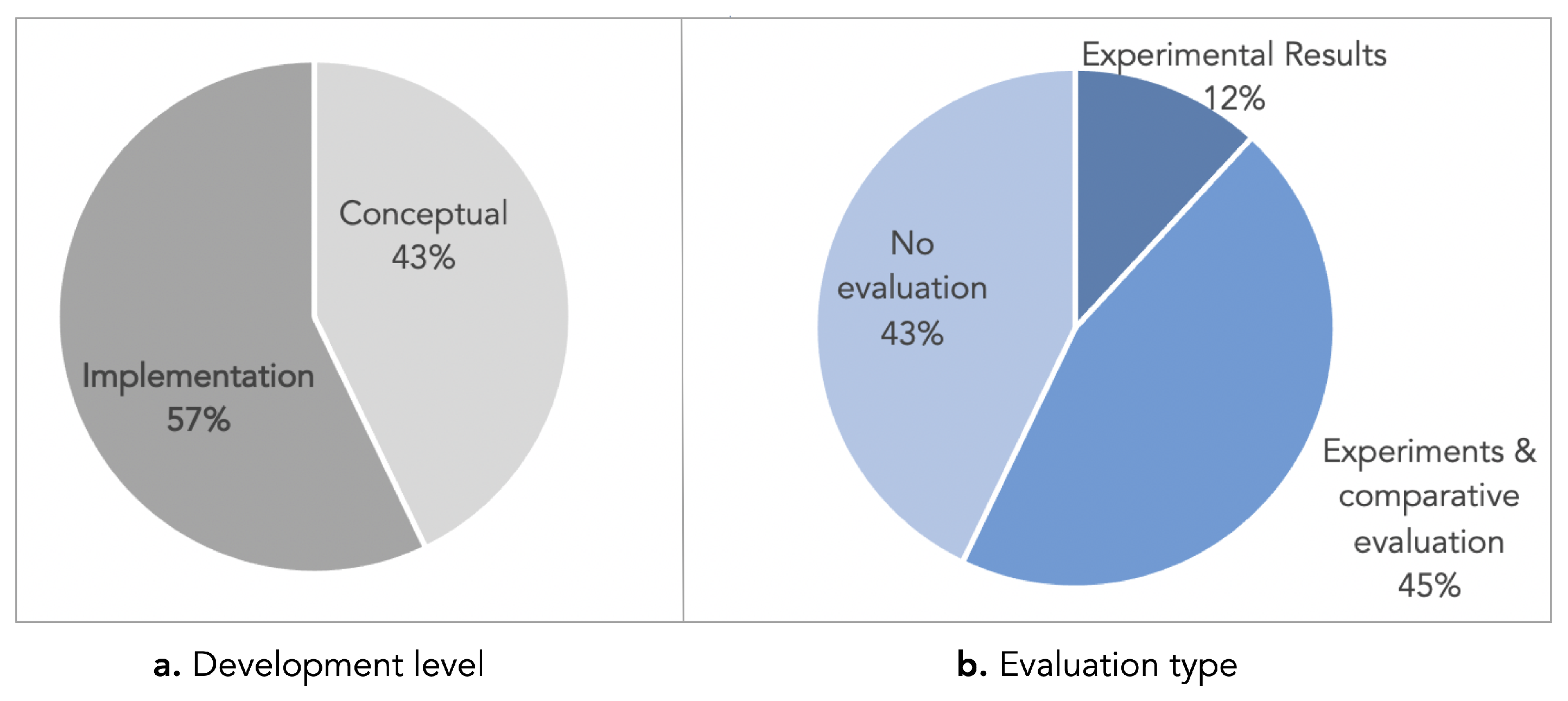
- Level of development. If the work presented a proposed high-level KG recommendation or if it referred to recommendations as a potential application of KGs, then the work was classified as conceptual. If the analyzed work presented a new recommendation method or if it presented the application of existing methods, then the work was classified as implementation.
- Type of evaluation. Regarding the type of evaluation carried out in each analyzed work, we considered three values: (1) experiments and comparative evaluation, if the authors performed experiments and compared their proposal with other baseline models, using performance metrics; (2) experimental results, if the proposal was evaluated using qualitative approaches or using exploratory experiments of the results; and (3) no evaluation, if no type of evaluation was found.
5. Results
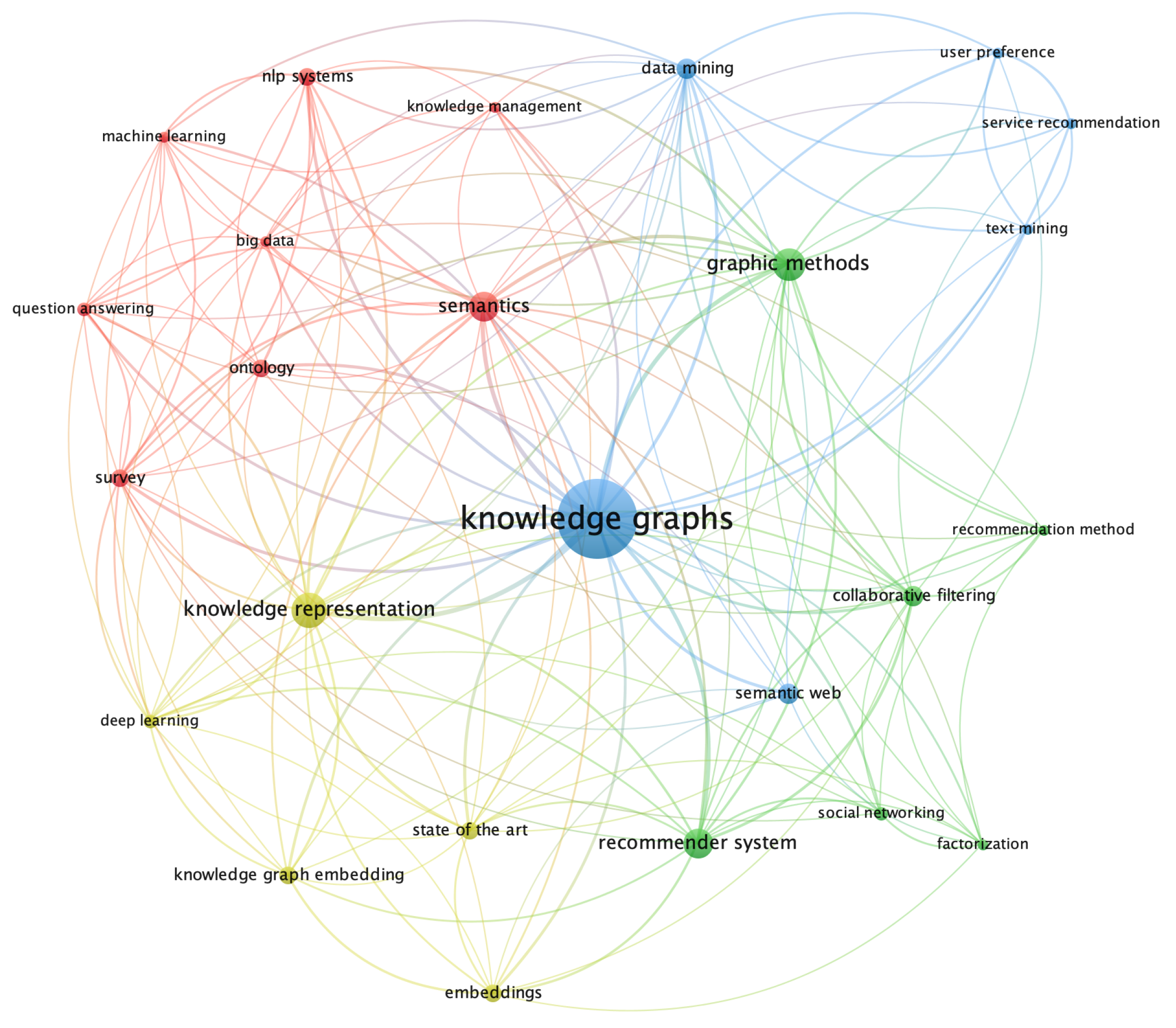
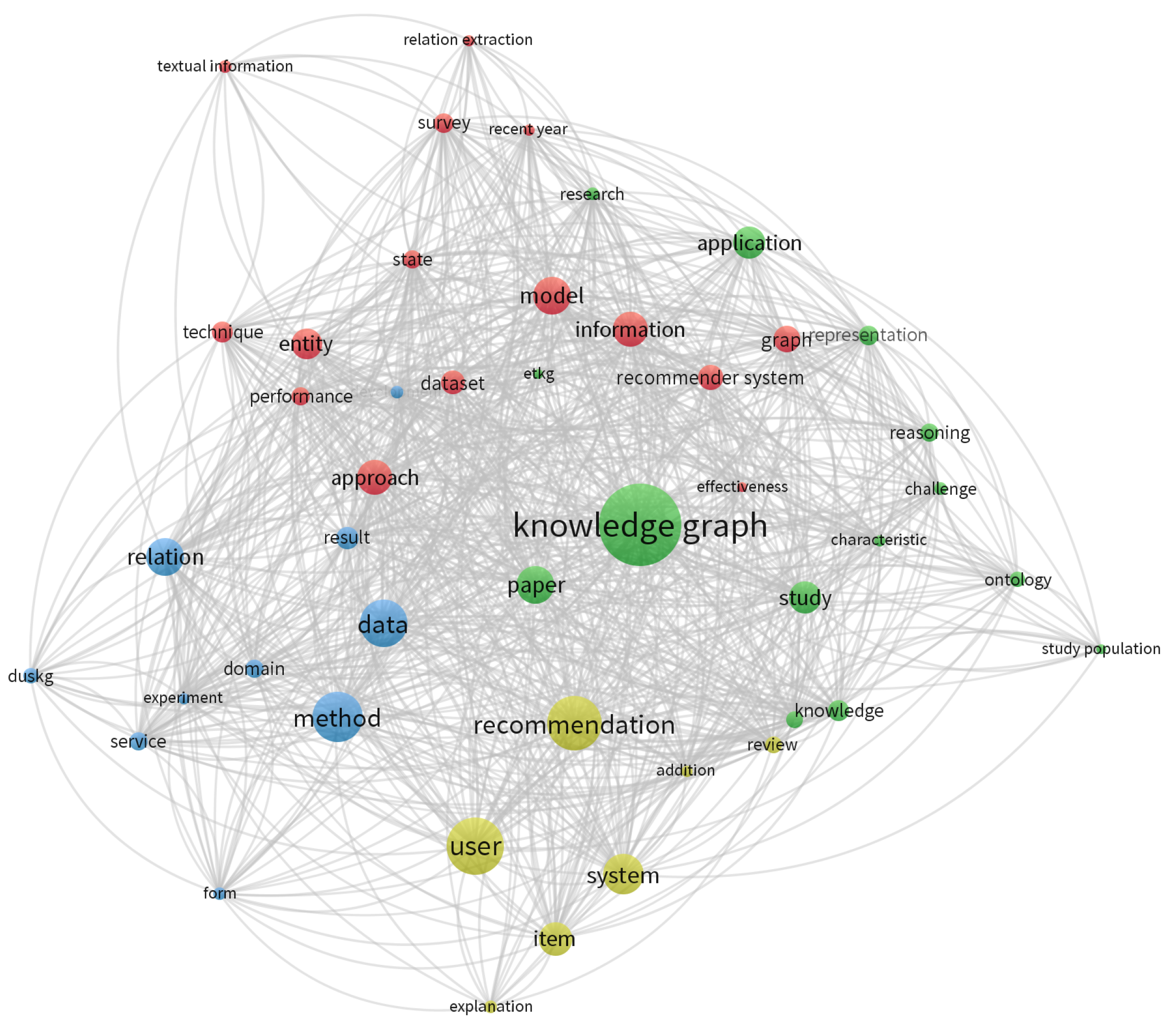
5.1. Technologies and Proposals
5.1.1. Knowledge Graphs and Semantic Web Technologies
5.1.2. Recommendation and Artificial Intelligence Methods
5.2. Development and Evaluation Levels
- Precision, recall, and F-measure are used when a recommender system must make decisions such as making or not making a recommendation. These measures are commonly used to evaluate the performance of recommender systems [88].
- Normalized Discounted Cumulative Gain (NDCG) allows for measuring the quality of the rank. NDCG is widely used to measure the effectiveness of recommendation algorithms [88].
- Mean Reciprocal Rank (MRR) measures whether the recommender system places the user’s relevant items at the top of the list [3].
- Novelty and Diversity. Novelty measures the ability of RS to recommend items that appear novel to the user [89]. Conversely, diversity measures the ability of the RS to recommend items that are not similar to those preferred by the user in the past or that is not limited to recommending popular items only [90,91].
5.3. Contributions by Application Domain
5.3.1. Education
5.3.2. Health
5.3.3. Lodging and Tourism
5.3.4. Entertainment
- Dynamic data. Fischer et al. [72] proposed a system that recommends entities by taking advantage of the temporal nature of search log data. This approach can significantly improve the quality of recommendations compared to certain static models of relevance; particularly, it improves the freshness measure.
- Explainable recommendation. According to [19], ranking items and entities in the KG can serve as an explanation for recommendations.
- Performance improvement. Zhang, Wang, and Luo [50] demonstrated that the model KGECF achieves stable performance on five different datasets. In this case, among the reasons why KGECF is more stable is because (1) it can learn user’s preference patterns more accurately and (2) the method used to embed the graph (RotatE) has very stable performance in modelling different types of relationships, such as one-to-many, many-to-one, and many-to-many relationships.
5.3.5. E-Commerce, Business, and Financial Sector
5.3.6. Cross-Domain
- Surveys that mention the recommendation term as (1) an application of KG [21,22], (2) KGE methods [65], (3) learning and reasoning on graph for recommendation (Wang2020c), (4) representation learning for dynamic graphs [63], (5) entity alignment [80], (6) relation extraction [73], (7) embedding mapping approaches [71], (8) knowledge base construction from unstructured text [67], and (9) extraction of semantic trees using KG [77].
- Survey on KG-based recommendation. In [6], KGE-based recommendation algorithms are presented. Additionally, the authors analyze the existing literature and compare five specific studies.
- Recommendation as secondary task. In [81], the authors present KG construction and the use of open source code to make recommendations. The graph is used to provide recommendations for language units.
- Recommendation as a central task. In [78], the model Knowledge-Aware Sequential Recommendation (KASR) is presented. KASR provides sequential recommendations, capturing both the sequence of interactive records and the semantic information in KG simultaneously. In this paper, the authors introduce the relation attention network to explicitly aggregate the high-order relevance in KG, and a unified knowledge-aware GRU directly plugs the significance into the modelling of interaction sequences. The authors have conducted experiments on three real-world datasets, and the results demonstrate that (1) knowledge-transfer based on relevant attributes helps to capture users’ preferences more accurately and (2) the relation attention network mines the rich semantic information in KG.
6. Future Directions
6.1. Interpretability of Recommendations
6.2. Explainable Recommendation
6.3. KG-Based Dynamic Recommendations
6.4. Learning with Knowledge Graphs
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CF | Collaborative Filtering |
| KG | Knowledge Graph |
| KGE | Knowledge Graph Embedding |
| LD | Linked Data |
| RS | Recommender System |
References
- Ricci, F.; Rokach, L.; Shapira, B.; Kantor, P.B. Recommender Systems Handbook; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Zhu, B.; Hurtado, R.; Bobadilla, J.; Ortega, F. An efficient recommender system method based on the numerical relevances and the non-numerical structures of the ratings. IEEE Access 2018, 6, 49935–49954. [Google Scholar] [CrossRef]
- Chen, R.; Hua, Q.; Chang, Y.S.; Wang, B.; Zhang, L.; Kong, X. A survey of collaborative filtering-based recommender systems: From traditional methods to hybrid methods based on social networks. IEEE Access 2018, 6, 64301–64320. [Google Scholar] [CrossRef]
- Walek, B.; Fojtik, V. A hybrid recommender system for recommending relevant movies using an expert system. Expert Syst. Appl. 2020, 158. [Google Scholar] [CrossRef]
- Jia, B.; Huang, X.; Jiao, S. Application of semantic similarity calculation based on knowledge graph for personalized study recommendation service. Kuram Uygulamada Egit. Bilim. 2018, 18, 2958–2966. [Google Scholar] [CrossRef]
- Liu, C.; Li, L.; Yao, X.; Tang, L. A Survey of Recommendation Algorithms Based on Knowledge Graph Embedding. In Proceedings of the 2019 IEEE International Conference on Computer Science and Educational Informatization (CSEI), Kunming, China, 16–19 August 2019; Institute of Electrical and Electronics Engineers Inc.: Interlaken, Switzerland, 2019. [Google Scholar]
- Manouselis, N.; Drachsler, H.; Vuorikari, R.; Hummel, H.; Koper, R. Recommender Systems in Technology Enhanced Learning. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P.B., Eds.; Springer: Boston, MA, USA, 2011; pp. 387–415. [Google Scholar] [CrossRef]
- Chicaiza, J.; Piedra, N.; Lopez-Vargas, J.; Tovar-Caro, E. Recommendation of Open Educational Resources. An Approach based on Linked Open Data. In Proceedings of the 2017 IEEE Global Engineering Education Conference (EDUCON), Athens, Greece, 25–28 April 2017; pp. 1316–1321. [Google Scholar] [CrossRef]
- Deng, Y.; Lu, D.; Huang, D.; Chung, C.J.; Lin, F. Knowledge Graph based Learning Guidance for Cybersecurity Hands-on Labs. In Proceedings of the ACM Conference on Global Computing Education, Chengdu, China, 17–19 May 2019; ACM: New York, NY, USA, 2018; Volume 19. [Google Scholar]
- Li, X.; Chen, Y.; Pettit, B.; De Rijke, M. Personalised reranking of paper recommendations using paper content and user behavior. ACM Trans. Inf. Syst. 2019, 37, 1–23. [Google Scholar] [CrossRef]
- Guo, Q.; Sun, Z.; Zhang, J.; Theng, Y.L. Modeling heterogeneous influences for point-of-interest recommendation in location-based social networks. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2019; Volume 11496, pp. 72–80. [Google Scholar] [CrossRef]
- Nilashi, M.; bin Ibrahim, O.; Ithnin, N.; Sarmin, N.H. A multi-criteria collaborative filtering recommender system for the tourism domain using Expectation Maximization (EM) and PCA—ANFIS. Electron. Commer. Res. Appl. 2015, 14, 542–562. [Google Scholar] [CrossRef]
- Santhoshi, C.; Thirupathi, V.; Chythanya, K.R.; Aluvala, S.; Sunil, G. A comprehensive study on efficient keyword-aware representative travel route recommendation. Int. J. Adv. Sci. Technol. 2020, 29, 1800–1810. [Google Scholar]
- Wang, H.; Wang, Z.; Hu, S.; Xu, X.; Chen, S.; Tu, Z. DUSKG: A fine-grained knowledge graph for effective personalized service recommendation. Future Gener. Comput. Syst. 2019, 100, 600–617. [Google Scholar] [CrossRef]
- Wu, J.; Zhu, X.; Zhang, C.; Hu, Z. Event-centric tourism knowledge graph—A case study of Hainan. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2020; Volume 12274, pp. 3–15. [Google Scholar] [CrossRef]
- Suzuki, T.; Oyama, S.; Kurihara, M. Explainable Recommendation Using Review Text and a Knowledge Graph. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; Institute of Electrical and Electronics Engineers Inc.: Interlaken, Switzerland, 2019; pp. 4638–4643. [Google Scholar] [CrossRef]
- Gim, J.; Lee, S.; Joo, W. A study of prescriptive analysis framework for human care services based on CKAN cloud. J. Sens. 2018, 2018. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Li, Y. An Auto Question Answering System for Tree Hole Rescue. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer Science and Business Media Deutschland GmbH: Norwell, MA, USA, 2020; Volume 12435, pp. 15–24. [Google Scholar] [CrossRef]
- Catherine, R.; Mazaitis, K.; Eskenazi, M.; Cohen, W. Explainable Entity-based Recommendations with Knowledge Graphs. In Proceedings of the 11th ACM Conference on Recommender Systems (RecSys 2017), Como, Italy, 27–31 August 2017; ACM: New York, NY, USA, 2017. [Google Scholar]
- Hu, S.; Tu, Z.; Wang, Z.; Xu, X. A POI-sensitive knowledge graph based service recommendation method. In Proceedings of the 2019 IEEE International Conference on Services Computing (SCC), Milan, Italy, 8–13 July 2019; Part of the 2019 IEEE World Congress on Services. IEEE: Piscataway, NJ, USA, 2019; pp. 197–201. [Google Scholar] [CrossRef]
- Zou, X. A Survey on Application of Knowledge Graph. In Proceedings of the 2020 4th International Conference on Control Engineering and Artificial Intelligence, CCEAI 2020, Singapore, 17–19 January 2020. Journal of Physics: Conference Series. [Google Scholar]
- Nigam, V.; Paul, S.; Agrawal, A.; Bansal, R. A review paper on the application of knowledge graph on various service providing platforms. In Proceedings of the 2020 10th International Conference on Cloud Computing, Data Science Engineering (Confluence), Noida, India, 29–31 January 2020; Institute of Electrical and Electronics Engineers Inc.: Interlaken, Switzerland, 2020; pp. 716–720. [Google Scholar] [CrossRef]
- Lu, F.; Cong, P.; Huang, X. Utilizing Textual Information in Knowledge Graph Embedding: A Survey of Methods and Applications. IEEE Access 2020, 8, 92072–92088. [Google Scholar] [CrossRef]
- Sun, Z.; Guo, Q.; Yang, J.; Fang, H.; Guo, G.; Zhang, J.; Burke, R. Research commentary on recommendations with side information: A survey and research directions. Electron. Commer. Res. Appl. 2019, 37. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; He, X.; Chua, T.S. Learning and reasoning on graph for recommendation. In Proceedings of the WSDM 2020: 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 890–893. [Google Scholar] [CrossRef] [Green Version]
- Rizun, M. Concept of recommender system for building an individual educational profile. In Proceedings of the Conference of 2019 Joint International Conference on Perspectives in Business Informatics Research Workshops and Doctoral Consortium, BIR-WS 2019, Katowice, Poland, 23–25 September 2019; CEUR Workshop Proceedings. CEUR-WS: Aachen, Germany, 2019; Volume 2443, pp. 165–176. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. IEEE Comput. Soc. 2009, 42, 42–49. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, Z.; Zheng, M.; He, X. Robust non-negative matrix factorization. Front. Electr. Electron. Eng. China 2011, 6, 192–200. [Google Scholar] [CrossRef]
- Zhou, X.; He, J.; Huang, G.; Zhang, Y. SVD-based incremental approaches for recommender systems. J. Comput. Syst. Sci. 2015, 81, 717–733. [Google Scholar] [CrossRef]
- Hernando, A.; Bobadilla, J.; Ortega, F. A non negative matrix factorization for collaborative filtering recommender systems based on a Bayesian probabilistic model. Knowl. Based Syst. 2016, 97, 188–202. [Google Scholar] [CrossRef]
- Wen, S.; Wang, C.; Li, H.; Wen, S. Naïve Bayes regression model and its application in collaborative filtering recommendation algorithm. Int. J. Internet Manuf. Serv. 2018, 5, 85–99. [Google Scholar] [CrossRef]
- Valdiviezo-Diaz, P.; Ortega, F.; Cobos, E.; Lara-Cabrera, R. A Collaborative Filtering Approach Based on Naïve Bayes Classifier. IEEE Access 2019, 7, 108581–108592. [Google Scholar] [CrossRef]
- Wasid, M.; Ali, R. An improved recommender system based on multi-criteria clustering approach. Procedia Comput. Sci. 2018, 131, 93–101. [Google Scholar] [CrossRef]
- Bobadilla, J.; Bojorque, R.; Hernando, A.; Hurtado, R. Recommender Systems Clustering using Bayesian non Negative Matrix Factorization. IEEE Access 2018, 3536, 1. [Google Scholar] [CrossRef]
- Ali, M.; Ali, R.; Khan, W.A.; Han, S.C.; Bang, J.; Hur, T.; Kim, D.; Lee, S.; Kang, B.H. A Data-Driven Knowledge Acquisition System: An End-to-End Knowledge Engineering Process for Generating Production Rules. IEEE Access 2018, 6, 15587–15607. [Google Scholar] [CrossRef]
- Fouss, F.; Pirotte, A.; Renders, J.M.; Saerens, M. Random-Walk Computation of Similarities between Nodes of a Graph with Application to Collaborative Recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19. [Google Scholar] [CrossRef]
- Sun, F.; Yu, M.; Zhang, X.; Chang, T.W. A vocabulary recommendation system based on knowledge graph for chinese language learning. In Proceedings of the IEEE 20th International Conference on Advanced Learning Technologies, ICALT 2020, Tartu, Estonia, 6–9 July 2020; Institute of Electrical and Electronics Engineers Inc.: Interlaken, Switzerland, 2020; pp. 210–212. [Google Scholar] [CrossRef]
- Tarus, J.K.; Niu, Z.; Mustafa, G. Knowledge-based recommendation: A review of ontology-based recommender systems for e-learning. Artif. Intell. Rev. 2018, 50, 21–48. [Google Scholar] [CrossRef]
- Bahramian, Z.; Ali Abbaspour, R.; Claramunt, C. A Cold Start Context-Aware Recommender System for Tour Planning Using Artificial Neural Network and Case Based Reasoning. Mob. Inf. Syst. 2017, 2017, 9364903. [Google Scholar] [CrossRef] [Green Version]
- Drachsler, H.; Hummel, H.; Koper, R. Recommendations for learners are different: Applying memory-based recommender system techniques to lifelong learning. In Proceedings of the 1st Workshop on Social Information Retrieval for Technology-Enhanced Learning & Exchange, Crete, Greece, 18 September 2007. [Google Scholar]
- Ricci, F.; Rokach, L.; Shapira, B. Recommender Systems Handbook; Springer: New York, NY, USA, 2015; Volume 32. [Google Scholar] [CrossRef]
- Blei, D.; Carin, L.; Dunson, D. Probabilistic topic models. IEEE Signal Process. Mag. 2010, 27, 55–65. [Google Scholar] [CrossRef] [Green Version]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities. Appl. Sci. 2020, 10, 7748. [Google Scholar] [CrossRef]
- Achmad, K.; Nugroho, L.; Djunaedi, A.; Widyawan. Context-aware based restaurant recommender system: A prescriptive analytics. J. Eng. Sci. Technol. 2019, 14, 2847–2864. [Google Scholar]
- Gasmi, I.; Anguel, F.; Seridi-Bouchelaghem, H.; Azizi, N. Context-aware based evolutionary collaborative filtering algorithm. Lect. Notes Netw. Syst. 2021, 156, 217–232. [Google Scholar] [CrossRef]
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender system application developments: A survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Colombo-Mendoza, L.O.; Valencia-García, R.; Rodríguez-González, A.; Alor-Hernández, G.; Samper-Zapater, J.J. RecomMetz: A context-aware knowledge-based mobile recommender system for movie showtimes. Expert Syst. Appl. 2015, 42, 1202–1222. [Google Scholar] [CrossRef]
- Burke, R. Hybrid Web Recommender Systems. In The Adaptive Web: Methods and Strategies of Web Personalization; Brusilovsky, P., Kobsa, A., Nejdl, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 377–408. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Wang, J.; Luo, J. Knowledge Graph Embedding Based Collaborative Filtering. IEEE Access 2020, 8, 134553–134562. [Google Scholar] [CrossRef]
- Singh, M.; Rishi, O. Event driven recommendation system for E-commerce using knowledge based collaborative filtering technique. Scalable Comput. 2020, 21, 369–378. [Google Scholar] [CrossRef]
- Kiran, R.; Kumar, P.; Bhasker, B. DNNRec: A novel deep learning based hybrid recommender system. Expert Syst. Appl. 2020, 144, 113054. [Google Scholar] [CrossRef]
- Khan, Z.; Niu, Z.; Nyamawe, A.; Haq, I. A Deep Hybrid Model for Recommendation by jointly leveraging ratings, reviews and metadata information. Eng. Appl. Artif. Intell. 2021, 97. [Google Scholar] [CrossRef]
- Peska, L. Hybrid recommendations by content-aligned Bayesian personalized ranking. New Rev. Hypermedia Multimed. 2018, 24, 88–109. [Google Scholar] [CrossRef]
- Ngaffo, A.; Ayeb, W.; Choukair, Z. A Bayesian Inference Based Hybrid Recommender System. IEEE Access 2020, 8, 101682–101701. [Google Scholar] [CrossRef]
- Bhaskaran, S.; Marappan, R.; Santhi, B. Design and analysis of a cluster-based intelligent hybrid recommendation system for e-learning applications. Mathematics 2021, 9, 197. [Google Scholar] [CrossRef]
- Sandeep Kumar, M.; Prabhu, J. A hybrid model collaborative movie recommendation system using K-means clustering with ant colony optimisation. Int. J. Internet Technol. Secur. Trans. 2020, 10, 337–354. [Google Scholar] [CrossRef]
- Wang, Q.; Long, M.; Yang, H. A Non-Negative Matrix-Factorization-Based Network Embedding Approach for Hybrid Recommender Systems. In Proceedings of the 2020 International Conference on Computing, Networks and Internet of Things, Sanya, China, 24–26 April 2020; CNIOT2020. Association for Computing Machinery: New York, NY, USA, 2020; pp. 105–110. [Google Scholar] [CrossRef]
- Zhou, J.; Wen, J.; Li, S.; Zhou, W. From Content Text Encoding Perspective: A Hybrid Deep Matrix Factorization Approach for Recommender System. In Proceedings of the International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef]
- Achary, N.; Patra, B. Graph Based Hybrid Approach for Long-Tail Item Recommendation in Collaborative Filtering. In ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2020; p. 426. [Google Scholar] [CrossRef]
- Li, J.; Xu, Z.; Tang, Y.; Zhao, B.; Tian, H. Deep hybrid knowledge graph embedding for top-n recommendation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2020; Volume 12432, pp. 59–70. [Google Scholar] [CrossRef]
- Musto, C.; Basile, P.; Semeraro, G. Hybrid Semantics-Aware Recommendations Exploiting Knowledge Graph Embeddings. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2019; Volume 11946, pp. 87–100. [Google Scholar] [CrossRef]
- Kazemi, S.; Goel, R.; Jain, K.; Kobyzev, I.; Sethi, A.; Forsyth, P.; Poupart, P. Representation learning for dynamic graphs: A survey. J. Mach. Learn. Res. 2020, 21, 1–73. [Google Scholar]
- Ameen, A. Knowledge based Recommendation System in Semantic Web—A Survey. Int. J. Comput. Appl. 2019, 182, 20–25. [Google Scholar] [CrossRef]
- Dai, Y.; Wang, S.; Xiong, N.N.; Guo, W. A survey on knowledge graph embedding: Approaches, applications and benchmarks. Electronics 2020, 9, 750. [Google Scholar] [CrossRef]
- Chari, S.; Qi, M.; Agu, N.N.; Seneviratne, O.; McCusker, J.P.; Bennett, K.P.; Das, A.K.; McGuinness, D.L. Making Study Populations Visible Through Knowledge Graphs. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2019; Volume 11779, pp. 53–68. [Google Scholar] [CrossRef] [Green Version]
- Ali, L.; Mathew, S. Knowledge Base Construction from Unstructured Text. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 569–574. [Google Scholar]
- Bi, Y.; Song, L.; Yao, M.; Wu, Z.; Wang, J.; Xiao, J. DCDIR: A Deep Cross-Domain Recommendation System for Cold Start Users in Insurance Domain. In Proceedings of the SIGIR 2020: 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; ACM, Inc.: New York, NY, USA, 2020; pp. 1661–1664. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Dong, X.; Li, T.; Ding, Z. An ontology enhanced user profiling algorithm based on application feedback. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; IEEE Computer Society: Washington, DC, USA, 2019; Volume 1, pp. 316–325. [Google Scholar] [CrossRef]
- Esteban, C.; Yang, Y.; Tresp, V. Embedding mapping approaches for tensor factorization and knowledge graph modelling. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2016; Volume 9678, pp. 199–213. [Google Scholar] [CrossRef]
- Fischer, L.; Blanco, R.; Mika, P.; Bernstein, A. Timely semantics: A study of a stream-based ranking system for entity relationships. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2015; Volume 9367, pp. 429–445. [Google Scholar] [CrossRef] [Green Version]
- Li, A.; Wang, X.; Wang, W.; Zhang, A.; Li, B. A survey of relation extraction of knowledge graphs. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2019; Volume 11809, pp. 52–66. [Google Scholar] [CrossRef]
- Oramas, S.; Ostuni, V.C.; Di Noia, T.; Serra, X.; Di Sciascio, E. Sound and music recommendation with knowledge graphs. ACM Trans. Intell. Syst. Technol. 2016, 8, 1–21. [Google Scholar] [CrossRef]
- Chari, S. Ontology-Enabled Analysis of Study Populations; ISWC Satellites 2019; CEUR: Luxembourg, 2019. [Google Scholar]
- Tomeo, P.; Fernández-Tobías, I.; Cantador, I.; Di Noia, T. Addressing the Cold Start with Positive-Only Feedback Through Semantic-Based Recommendations. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2017, 25, 57–78. [Google Scholar] [CrossRef] [Green Version]
- Tumpa, S.N.; Masroor Ali, M. Document Concept Hierarchy Generation by Extracting Semantic Tree Using Knowledge Graph. In Proceedings of the 2018 IEEE International WIE Conference on Electrical and Computer Engineering, WIECON-ECE 2018, Chonburi, Thailand, 14–16 December 2018; IEEE Inc.: Piscataway, NJ, USA, 2018; pp. 83–86. [Google Scholar] [CrossRef]
- Wang, Q.; Xiong, Y.; Zhu, Y.; Yu, P.S. KASR: Knowledge-Aware Sequential Recommendation. In Web and Big Data; Wang, X., Zhang, R., Lee, Y.K., Sun, L., Moon, Y.S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 493–508. [Google Scholar]
- Wu, J.; Lécué, F.; Gueret, C.; Hayes, J.; van de Moosdijk, S.; Gallagher, G.; McCanney, P.; Eichelberger, E. Personalizing actions in context for risk management using semantic web technologies. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2017; Volume 10588, pp. 367–383. [Google Scholar] [CrossRef]
- Zhao, X.; Zeng, W.; Tang, J.; Wang, W.; Suchanek, F. An Experimental Study of State-of-the-Art Entity Alignment Approaches. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Zhu, S.; Li, Y.; Shao, Y.; Wang, L. Building Semantic Dependency Knowledge Graph Based on HowNet. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2020; Volume 11831, pp. 525–534. [Google Scholar] [CrossRef]
- Qin, C.; Zhu, H.; Zhuang, F.; Guo, Q.; Zhang, Q.; Zhang, L.; Wang, C.; Chen, E.; Xiong, H. A survey on knowledge graph-based recommender systems. Sci. Sin. Inf. 2020, 50, 937–956. [Google Scholar] [CrossRef]
- Forouzandeh, S.; Berahmand, K.; Rostami, M. Presentation of a recommender system with ensemble learning and graph embedding: A case on MovieLens. Multimed. Tools Appl. 2020. [Google Scholar] [CrossRef]
- Zhou, K.; Zhao, W.X.; Bian, S.; Zhou, Y.; Wen, J.R.; Yu, J. Improving Conversational Recommender Systems via Knowledge Graph Based Semantic Fusion. In KDD ’20: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery I& Data Mining; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1006–1014. [Google Scholar] [CrossRef]
- Sarkar, R.; Goswami, K.; Arcan, M.; McCrae, J.P. Suggest me a movie for tonight: Leveraging Knowledge Graphs for Conversational Recommendation. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online), 8–13 December; International Committee on Computational Linguistics: Barcelona, Spain (Online), 2020; pp. 4179–4189. [Google Scholar] [CrossRef]
- Carrer-Neto, W.; Hernández-Alcaraz, M.L.; Valencia-García, R.; García-Sánchez, F. Social knowledge-based recommender system. Application to the movies domain. Expert Syst. Appl. 2012, 39, 10990–11000. [Google Scholar] [CrossRef] [Green Version]
- Teng, Y.; Shi, Y.; Tsai, J.; Shuai, H.; Tai, C.; Yang, D. Optimizing Social-Topic Engagement on Social Network and Knowledge Graph. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, M.; Liu, P. Performance Evaluation of Recommender Systems. Int. J. Perform. Eng. 2017, 13, 1246–1256. [Google Scholar] [CrossRef]
- Mendoza, M.; Torres, N. Evaluating content novelty in recommender systems. J. Intell. Inf. Syst. 2020, 54, 297–316. [Google Scholar] [CrossRef]
- Kunaver, M.; PoÅŸrl, T. Diversity in recommender systems: A survey. Knowl. Based Syst. 2017, 123, 154–162. [Google Scholar] [CrossRef]
- Díez, J.; Martínez-Rego, D.; Alonso-Betanzos, A.; Luaces, O.; Bahamonde, A. Optimizing novelty and diversity in recommendations. Prog. Artif. Intell. 2019, 8, 101–109. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Y.; Song, X.; Yang, B.; Jiang, C.; Luo, X. An Interpretable Recommendations Approach Based on User Preferences and Knowledge Graph. In Advances in Swarm Intelligence; Tan, Y., Shi, Y., Niu, B., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 326–337. [Google Scholar]
- Palumbo, E.; Monti, D.; Rizzo, G.; Troncy, R.; Baralis, E. entity2rec: Property-specific knowledge graph embeddings for item recommendation. Expert Syst. Appl. 2020, 151, 113235. [Google Scholar] [CrossRef]
- Lully, V.; Laublet, P.; Stankovic, M.; Radulovic, F. Enhancing explanations in recommender systems with knowledge graphs. Procedia Comput. Sci. 2018, 137, 211–222. [Google Scholar] [CrossRef]
- Xie, L.; Hu, Z.; Cai, X.; Zhang, W.; Chen, J. Explainable recommendation based on knowledge graph and multi-objective optimization. Complex Intell. Syst. 2021. [Google Scholar] [CrossRef]
- Nasiri, M.; Minaei, B.; Kiani, A. Dynamic Recommendation: Disease Prediction and Prevention Using Recommender System. Int. J. Basic Sci. Med. 2016, 1, 13–17. [Google Scholar] [CrossRef] [Green Version]
- Tareq, S.U.; Noor, M.H.; Bepery, C. Framework of dynamic recommendation system for e-shopping. Int. J. Inf. Technol. 2020, 12, 135–140. [Google Scholar] [CrossRef]
- Ma, J.; Chen, H.; Jiang, S.; Huang, Z. A dynamic recommendation approach in online social networks. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018; pp. 364–369. [Google Scholar] [CrossRef]
- Hamilton, W.L. Graph Representation Learning Hamilton; Morgan and Claypool Publishers: San Rafael, CA, USA, 2020; Volume 14, pp. 1–159. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. KGAT: Knowledge Graph Attention Network for Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’19), Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 950–958. [Google Scholar] [CrossRef] [Green Version]
- Kojima, R.; Ishida, S.; Ohta, M.; Iwata, H.; Honma, T.; Okuno, Y. kGCN: A graph-based deep learning framework for chemical structures. J. Cheminform. 2020, 12, 32. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Zhang, F.; Zhang, M.; Leskovec, J.; Zhao, M.; Li, W.; Wang, Z. Knowledge-Aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’19), Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 968–977. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | KG and LD | KGE | Ontology | Query Language | Reasoning & Inference | Data Technology |
|---|---|---|---|---|---|---|
| [5] | X | |||||
| [6] | X | |||||
| [9] | X | |||||
| [10] | X | |||||
| [11] | X | |||||
| [13] | X | X | ||||
| [14] | X | |||||
| [15] | X | X | X | X | ||
| [16] | X | |||||
| [17] | X | X | X | |||
| [18] | X | |||||
| [19] | X | |||||
| [20] | X | X | X | |||
| [21] | X | |||||
| [22] | X | |||||
| [23] | X | |||||
| [24] | X | |||||
| [25] | X | |||||
| [50] | X | X | ||||
| [51] | X | |||||
| [63] | X | X | X | |||
| [65] | X | |||||
| [66] | X | X | X | |||
| [67] | X | X | ||||
| [68] | X | |||||
| [69] | X | X | ||||
| [70] | X | X | X | |||
| [71] | X | |||||
| [72] | X | |||||
| [73] | X | |||||
| [74] | X | X | ||||
| [75] | X | X | ||||
| [76] | X | X | ||||
| [77] | X | X | ||||
| [78] | X | X | ||||
| [79] | X | X | X | X | ||
| [80] | X | X | ||||
| [81] | X | X | X | |||
| Total | 23 | 21 | 10 | 3 | 3 | 6 |
| Reference | Collaborative Filtering | Content Filtering | Context-Aware | Knowledge-Based |
|---|---|---|---|---|
| [5] | X | X | X | |
| [6] | ||||
| [9] | X | |||
| [10] | X | X | ||
| [11] | X | X | ||
| [13] | X | |||
| [14] | X | X | ||
| [15] | X | X | ||
| [16] | X | X | ||
| [17] | X | |||
| [18] | X | |||
| [19] | X | X | ||
| [20] | X | X | ||
| [21] | ||||
| [22] | ||||
| [23] | ||||
| [24] | X | x | ||
| [25] | X | |||
| [50] | X | X | ||
| [51] | X | |||
| [63] | ||||
| [65] | ||||
| [66] | X | |||
| [67] | ||||
| [68] | X | X | ||
| [69] | ||||
| [70] | X | X | ||
| [71] | X | |||
| [72] | X | X | ||
| [73] | ||||
| [74] | X | X | ||
| [75] | ||||
| [76] | X | X | ||
| [77] | X | |||
| [78] | X | |||
| [79] | X | |||
| [80] | ||||
| [81] | X |
| Domain | Recommended Item | Datasource | References |
|---|---|---|---|
| Education | Labs | Course data | [9] |
| Learning concepts | Educational resources | [5] | |
| Papers | ScienceDirect | [10] | |
| Health | Questions | Online Suicide Rescue Instruction | [18] |
| Treatments | Not specified | [66,75] | |
| User’s behavior | CKAN | [17] | |
| Lodging and Tourism | POIs | Hainan tourism | [15] |
| Social networks | [11] | ||
| POIs, restaurant services & travel routes | Yelp dataset | [11,13,14] | |
| Hotels | Tripadvisor | [16] | |
| Entertainment | Sound and music | Freesound.org | [74] |
| Last.fm | [50,74,78] | ||
| Songfacts.com | [74] | ||
| Facebook music | [76] | ||
| Images | [50] | ||
| Movies | Facebook movies | [76] | |
| IMDB | [19] | ||
| Movielens | [50,71,78] | ||
| Not specified | [24] | ||
| Books | Facebook books | [76] | |
| Not specified | Not specified | [69] | |
| E-Commerce, business and Financial | Business services | Yelp dataset | [20] |
| Insurance products | JGJISNF dataset | [68] | |
| Products | Retail e-Shop | [51] | |
| Toys | Amazon toys | [50] | |
| Books | Amazon books | [78] | |
| Music | Amazon music | [50] | |
| Financial actions | No specified | [79] | |
| Software apps | Apple App store | [70] | |
| Cross-domain | Entities/relationships | Search logs | [72] |
| DBP15K, DWY100K, SRPRS | [80] | ||
| Wikipedia, Bengali documents | [77] | ||
| Food industry | Amino Acid Dataset Freebase | [71] | |
| Language units | HowNet, Wikipedia & a newspaper | [81] | |
| Web resources | Not specified | [22] | |
| Not specified | Not specified | [6,21,25,63,65,67] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chicaiza, J.; Valdiviezo-Diaz, P. A Comprehensive Survey of Knowledge Graph-Based Recommender Systems: Technologies, Development, and Contributions. Information 2021, 12, 232. https://doi.org/10.3390/info12060232
Chicaiza J, Valdiviezo-Diaz P. A Comprehensive Survey of Knowledge Graph-Based Recommender Systems: Technologies, Development, and Contributions. Information. 2021; 12(6):232. https://doi.org/10.3390/info12060232
Chicago/Turabian StyleChicaiza, Janneth, and Priscila Valdiviezo-Diaz. 2021. "A Comprehensive Survey of Knowledge Graph-Based Recommender Systems: Technologies, Development, and Contributions" Information 12, no. 6: 232. https://doi.org/10.3390/info12060232
APA StyleChicaiza, J., & Valdiviezo-Diaz, P. (2021). A Comprehensive Survey of Knowledge Graph-Based Recommender Systems: Technologies, Development, and Contributions. Information, 12(6), 232. https://doi.org/10.3390/info12060232