Network Traffic Anomaly Detection via Deep Learning

 , ,
, ,
Abstract
:1. Introduction
- The design and development of an innovative network monitoring and analysis scheme based on the pfSense software;
- The construction and pre-processing of a novel network intrusion dataset composed of Suricata logs collected from the pfSense software;
- The design and exploitation of challenging Deep Learning (DL) schemes for semi-supervised network intrusion/anomaly detection.
2. Related Work and Background
2.1. Network Intrusion Detection Systems
2.2. Embedding
2.3. Long-Short Term Networks (LSTM)
2.4. Convolutional Neural Network
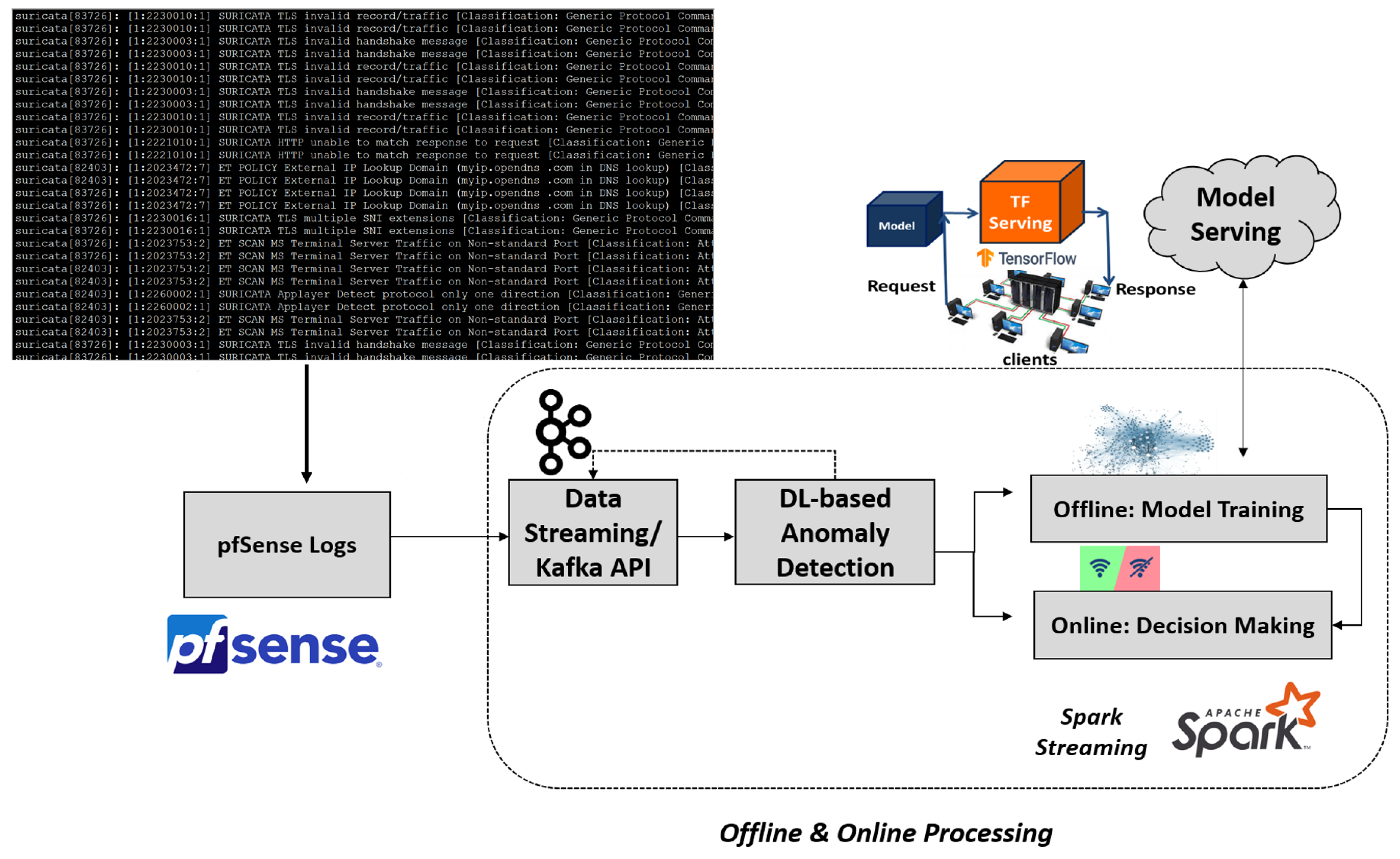
3. Proposed Formulation
- Offline: representing the model training process;
- Online: corresponding to the decision making and does not involve model re-training.
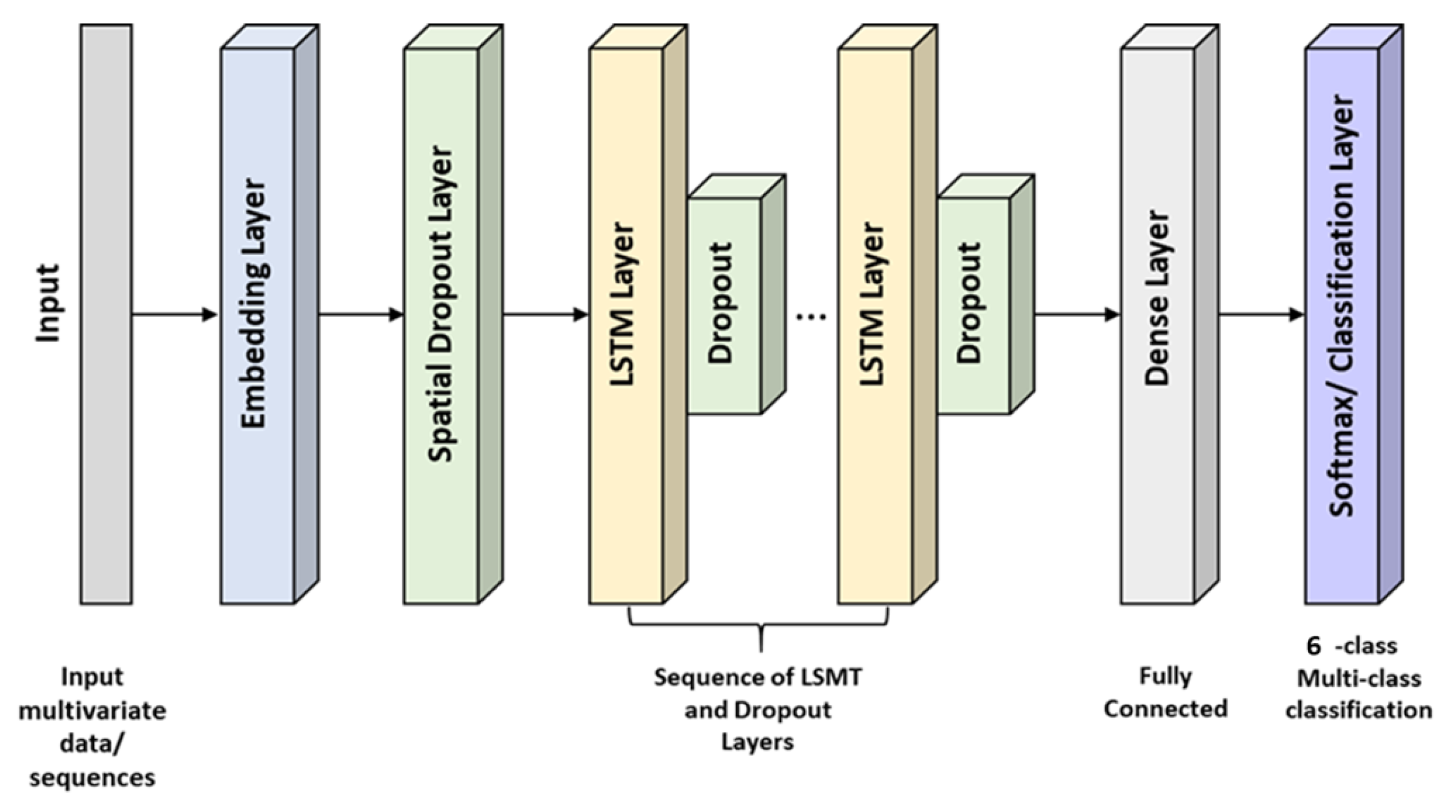
3.1. Long Short Term Memory (LSTM) Approach
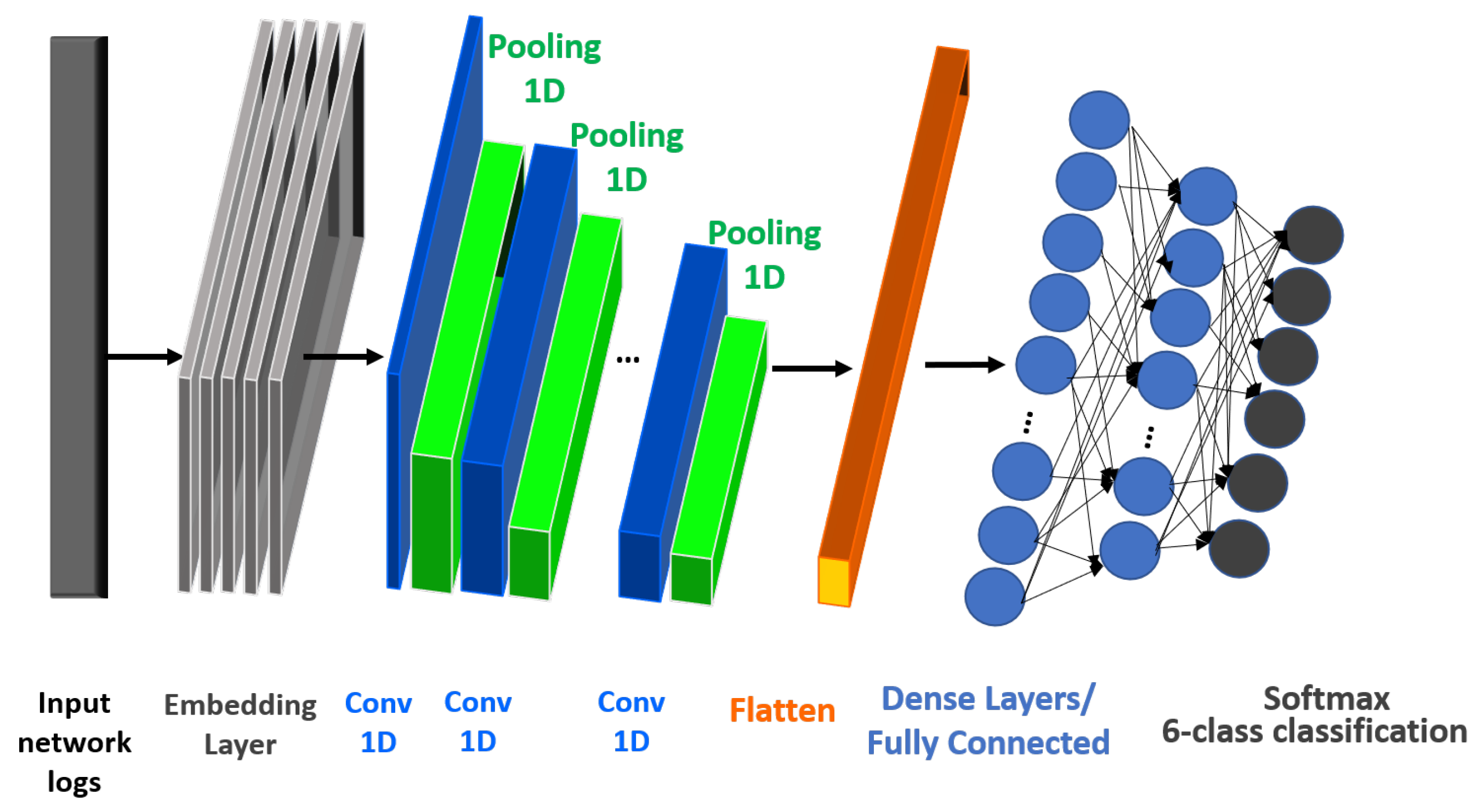
3.2. One Dimensional Convolutional Neural Network (CNN) Approach
4. Experimental Setup
4.1. pfSense Software
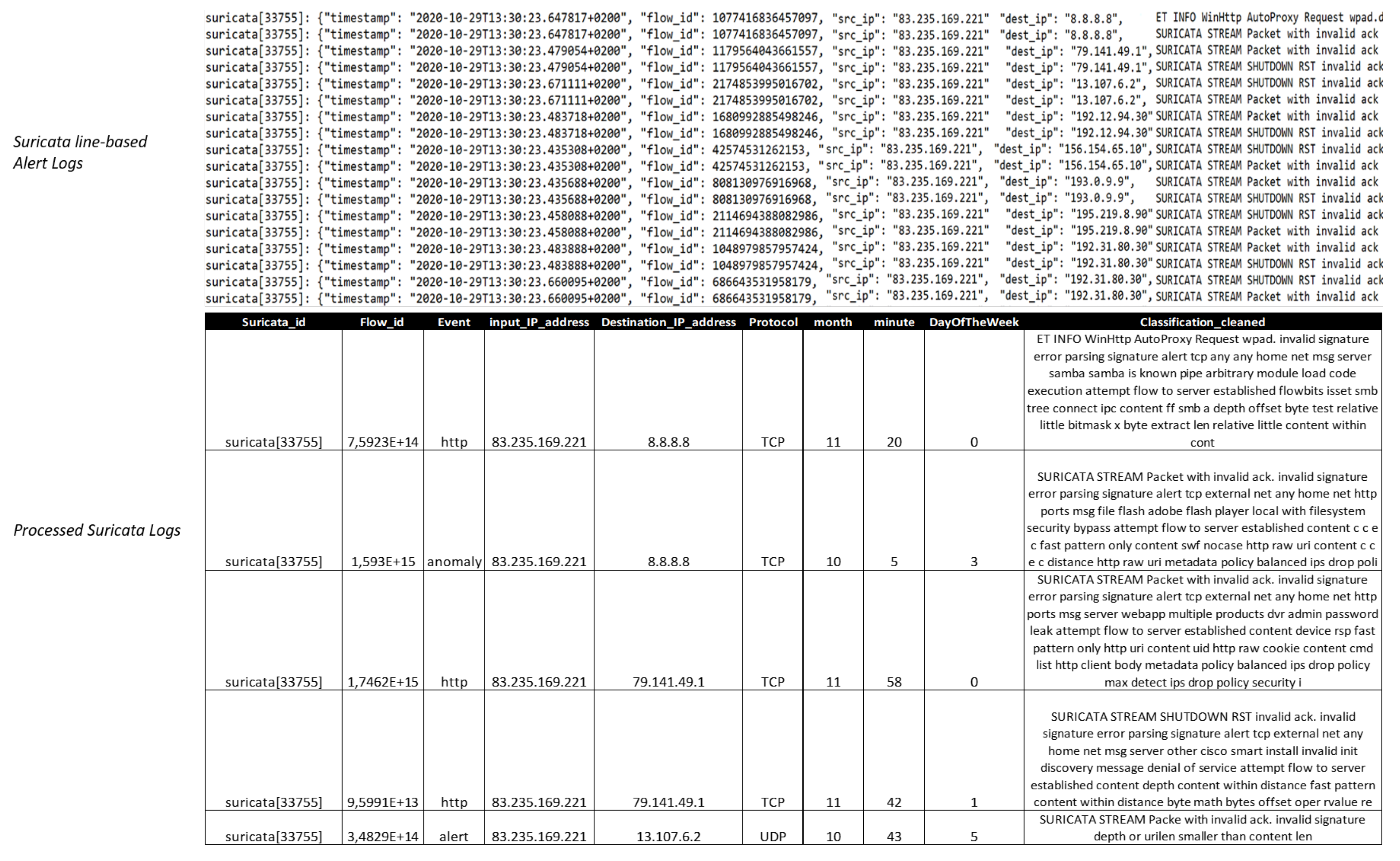
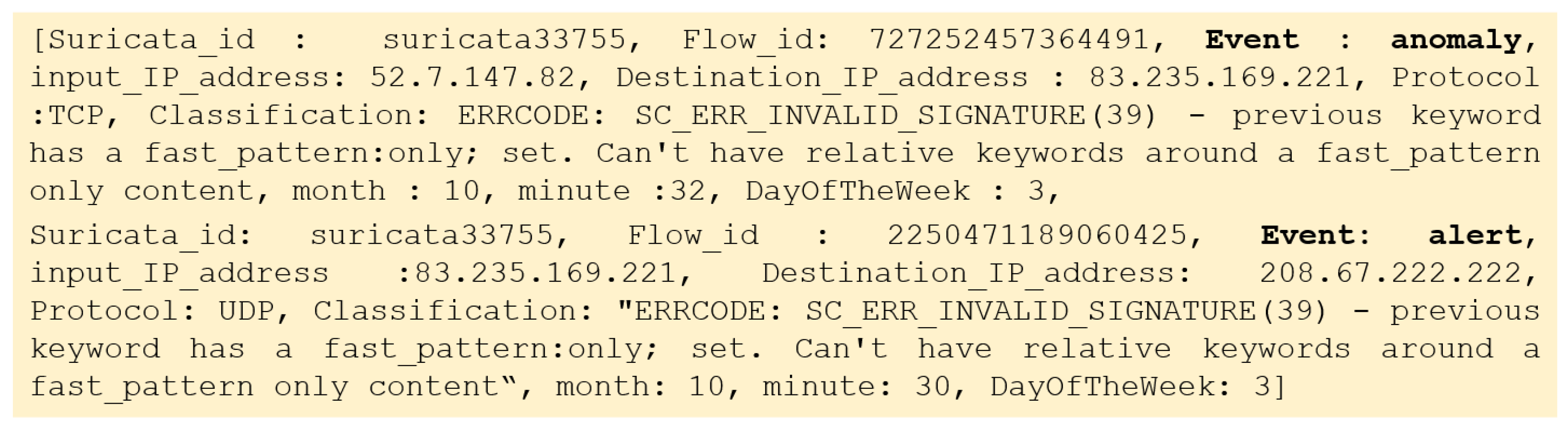
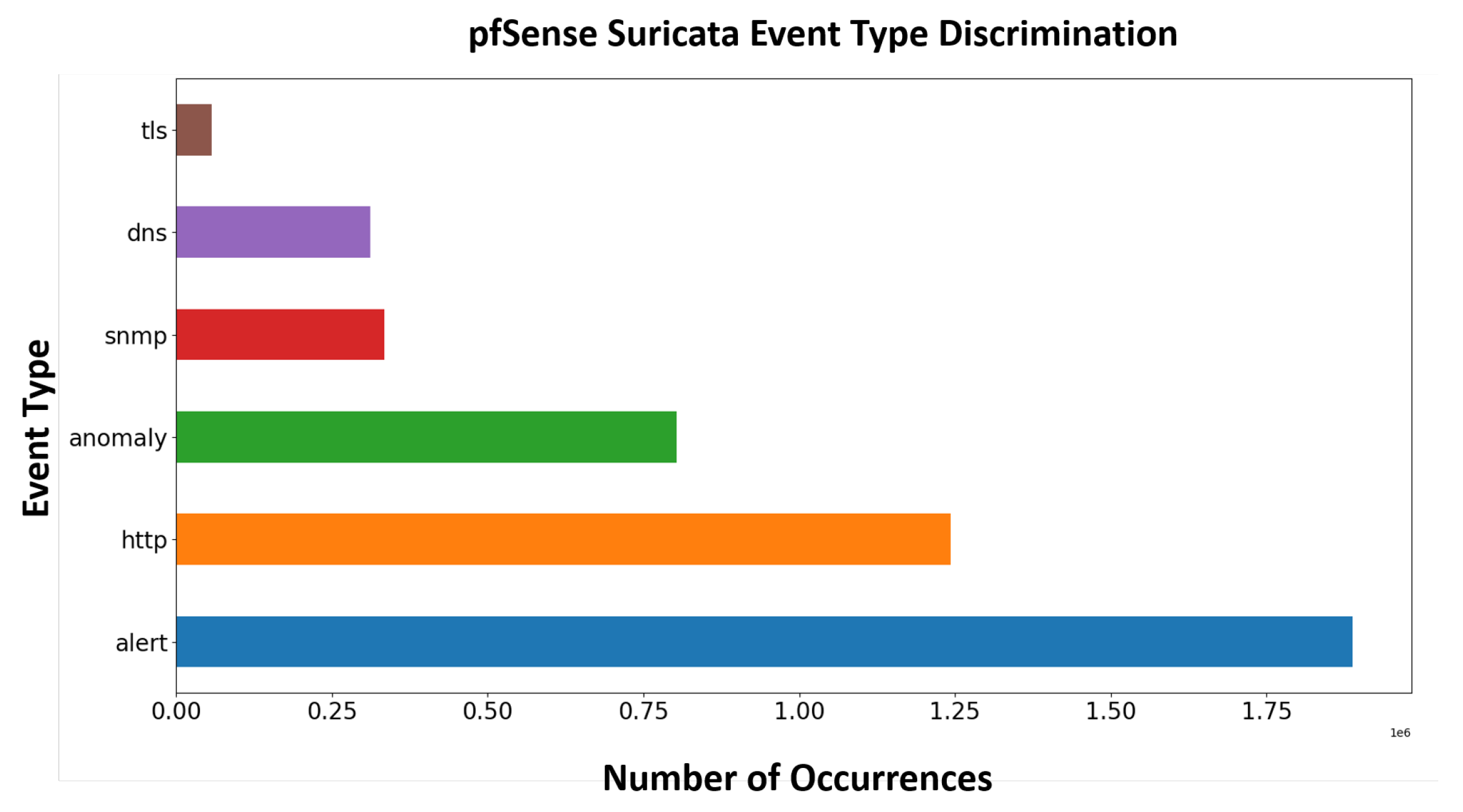
4.2. Dataset Description
4.3. Evaluation Metrics
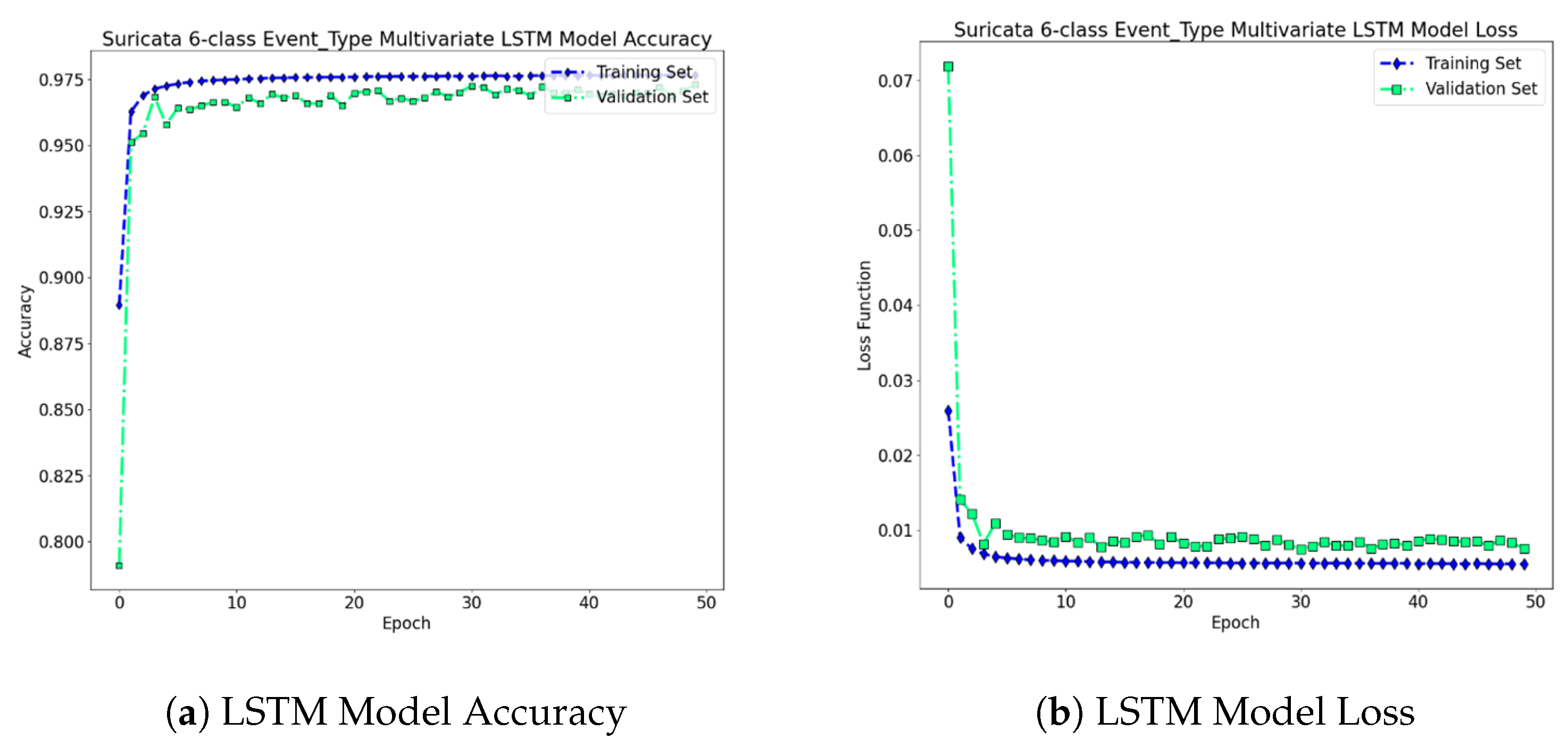
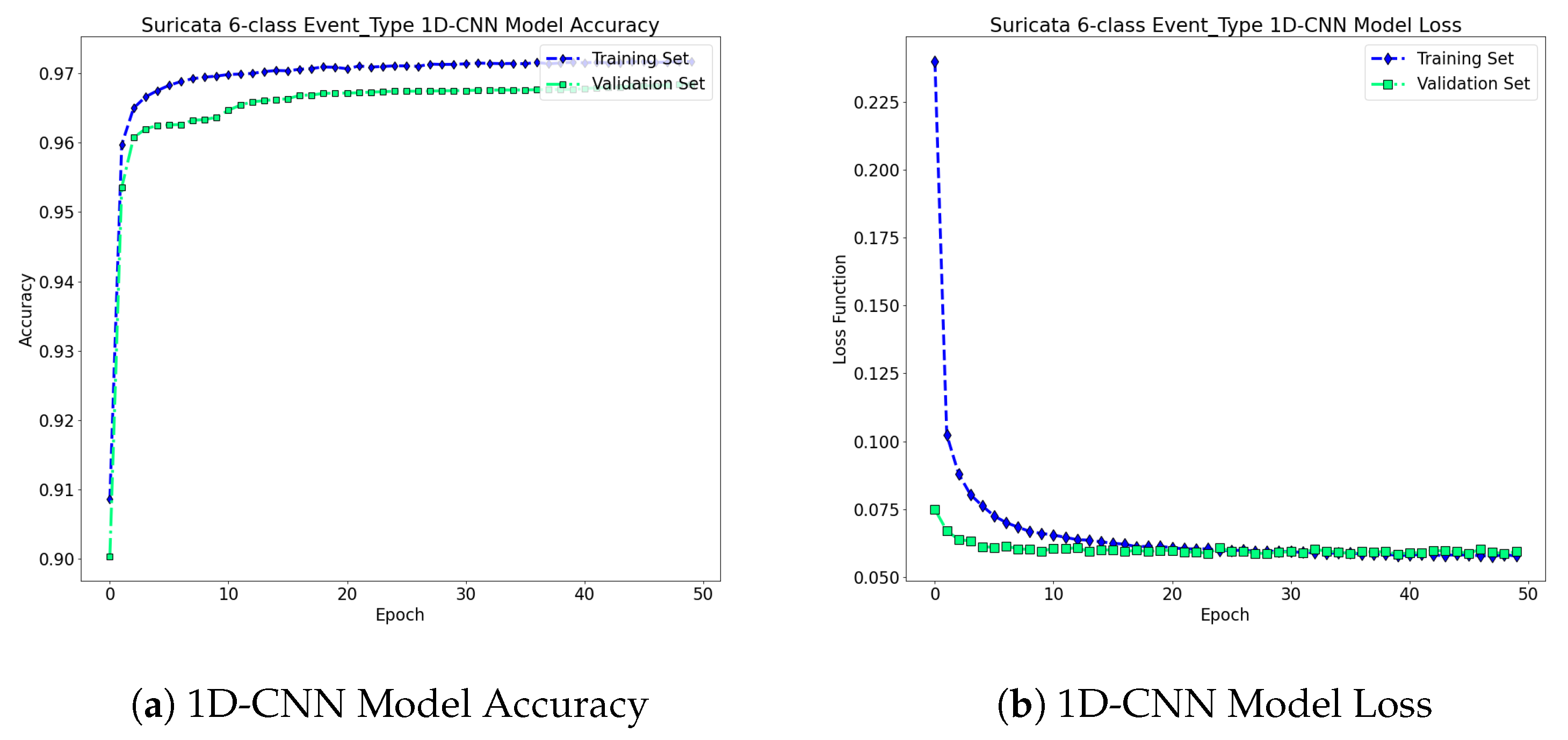
Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- pfSense-World’s Most Trusted Open Source Firewall. Available online: https://www.pfsense.org (accessed on 18 May 2021).
- pfSense-Documentation. Available online: https://docs.netgate.com/pfsense/en/latest/ (accessed on 18 May 2021).
- Apache Spark. Available online: https://spark.apache.org/docs/latest/streaming-programming-guide.html (accessed on 18 May 2021).
- Kim, D.S.; Nguyen, H.N.; Park, J.S. Genetic algorithm to improve SVM based network intrusion detection system. In Proceedings of the 19th International Conference on Advanced Information Networking and Applications (AINA’05) Volume 1 (AINA Papers), Taipei, Taiwan, 28–30 March 2005; Volume 2, pp. 155–158. [Google Scholar]
- Farnaaz, N.; Jabbar, M. Random forest modeling for network intrusion detection system. Procedia Comput. Sci. 2016, 89, 213–217. [Google Scholar] [CrossRef] [Green Version]
- Sekar, R.; Guang, Y.; Verma, S.; Shanbhag, T. A high-performance network intrusion detection system. In Proceedings of the 6th ACM Conference on Computer and Communications Security, Singapore, 2–4 November 1999; pp. 8–17. [Google Scholar]
- Sultana, N.; Chilamkurti, N.; Peng, W.; Alhadad, R. Survey on SDN based network intrusion detection system using machine learning approaches. Peer-Peer Netw. Appl. 2019, 12, 493–501. [Google Scholar] [CrossRef]
- Samrin, R.; Vasumathi, D. Review on anomaly based network intrusion detection system. In Proceedings of the 2017 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT), Mysuru, India, 15–16 December 2017; pp. 141–147. [Google Scholar] [CrossRef]
- Kruegel, C.; Toth, T. Using decision trees to improve signature-based intrusion detection. In International Workshop on Recent Advances in Intrusion Detection; Springer: Berlin/Heidelberg, Germany, 2003; pp. 173–191. [Google Scholar]
- Kumar, V.; Sangwan, O.P. Signature based intrusion detection system using SNORT. Int. J. Comput. Appl. Inf. Technol. 2012, 1, 35–41. [Google Scholar]
- Kwon, D.; Kim, H.; Kim, J.; Suh, S.C.; Kim, I.; Kim, K.J. A survey of deep learning-based network anomaly detection. Clust. Comput. 2019, 22, 949–961. [Google Scholar] [CrossRef]
- Omar, S.; Ngadi, A.; Jebur, H.H. Machine learning techniques for anomaly detection: An overview. Int. J. Comput. Appl. 2013, 79, 33–41. [Google Scholar] [CrossRef]
- Ioulianou, P.; Vasilakis, V.; Moscholios, I.; Logothetis, M. A signature-based intrusion detection system for the Internet of Things. In Proceedings of the Information and Communication Technology Forum (ICTF) 2018, Graz, Austria, 11–13 July 2018. [Google Scholar]
- Ioulianou, P.P.; Vassilakis, V.G. Denial-of-service attacks and countermeasures in the RPL-based Internet of Things. In Computer Security; Springer: Berlin/Heidelberg, Germany, 2019; pp. 374–390. [Google Scholar]
- Dharmapurikar, S.; Lockwood, J.W. Fast and scalable pattern matching for network intrusion detection systems. IEEE J. Sel. Areas Commun. 2006, 24, 1781–1792. [Google Scholar] [CrossRef]
- Mishra, P.; Varadharajan, V.; Tupakula, U.; Pilli, E.S. A detailed investigation and analysis of using machine learning techniques for intrusion detection. IEEE Commun. Surv. Tutor. 2018, 21, 686–728. [Google Scholar] [CrossRef]
- Buczak, A.L.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun. Surv. Tutor. 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Gupta, R.; Tanwar, S.; Tyagi, S.; Kumar, N. Machine learning models for secure data analytics: A taxonomy and threat model. Comput. Commun. 2020, 153, 406–440. [Google Scholar] [CrossRef]
- Görnitz, N.; Kloft, M.; Rieck, K.; Brefeld, U. Toward supervised anomaly detection. J. Artif. Intell. Res. 2013, 46, 235–262. [Google Scholar] [CrossRef]
- Yamanaka, Y.; Iwata, T.; Takahashi, H.; Yamada, M.; Kanai, S. Autoencoding Binary Classifiers for Supervised Anomaly Detection. In Pacific Rim International Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2019; pp. 647–659. [Google Scholar]
- Ma, J.; Sun, L.; Wang, H.; Zhang, Y.; Aickelin, U. Supervised anomaly detection in uncertain pseudoperiodic data streams. ACM Trans. Internet Technol. 2016, 16, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Ganomaly: Semi-supervised anomaly detection via adversarial training. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018; pp. 622–637. [Google Scholar]
- Ruff, L.; Vandermeulen, R.A.; Görnitz, N.; Binder, A.; Müller, E.; Müller, K.R.; Kloft, M. Deep Semi-Supervised Anomaly Detection. arXiv 2019, arXiv:1906.02694. [Google Scholar]
- Song, H.; Jiang, Z.; Men, A.; Yang, B. A hybrid semi-supervised anomaly detection model for high-dimensional data. Comput. Intell. Neurosci. 2017, 2017, 8501683. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahmad, S.; Lavin, A.; Purdy, S.; Agha, Z. Unsupervised real-time anomaly detection for streaming data. Neurocomputing 2017, 262, 134–147. [Google Scholar] [CrossRef]
- Filimonov, V.; Periorellis, P.; Starostin, D.; De Baynast, A.; Akchurin, E.; Klimov, A.; Minka, T.; Spengler, A. Unsupervised Anomaly Detection for Arbitrary Time Series. U.S. Patent 9,652,354, 16 May 2017. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Song, D.; Chen, Y.; Feng, X.; Lumezanu, C.; Cheng, W.; Ni, J.; Zong, B.; Chen, H.; Chawla, N.V. A deep neural network for unsupervised anomaly detection and diagnosis in multivariate time series data. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1409–1416. [Google Scholar]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A.v.d. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1705–1714. [Google Scholar]
- Ran, J.; Ji, Y.; Tang, B. A Semi-Supervised learning approach to IEEE 802.11 network anomaly detection. In Proceedings of the 2019 IEEE 89th Vehicular Technology Conference (VTC2019-Spring), Kuala Lumpur, Malaysia, 28 April–1 May 2019; pp. 1–5. [Google Scholar]
- Muniyandi, A.P.; Rajeswari, R.; Rajaram, R. Network anomaly detection by cascading k-Means clustering and C4.5 decision tree algorithm. Procedia Eng. 2012, 30, 174–182. [Google Scholar] [CrossRef] [Green Version]
- Aytekin, C.; Ni, X.; Cricri, F.; Aksu, E. Clustering and unsupervised anomaly detection with l 2 normalized deep auto-encoder representations. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–6. [Google Scholar]
- Papalexakis, E.E.; Beutel, A.; Steenkiste, P. Network anomaly detection using co-clustering. In Encyclopedia of Social Network Analysis and Mining; IEEE: New York, NY, USA, 2014; pp. 1054–1068. [Google Scholar]
- Ergen, T.; Kozat, S.S. Unsupervised anomaly detection with LSTM neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3127–3141. [Google Scholar] [CrossRef] [Green Version]
- Truong-Huu, T.; Dheenadhayalan, N.; Pratim Kundu, P.; Ramnath, V.; Liao, J.; Teo, S.G.; Praveen Kadiyala, S. An Empirical Study on Unsupervised Network Anomaly Detection using Generative Adversarial Networks. In Proceedings of the 1st ACM Workshop on Security and Privacy on Artificial Intelligence, Taipei Taiwan, 5 October 2020; pp. 20–29. [Google Scholar]
- Bertero, C.; Roy, M.; Sauvanaud, C.; Trédan, G. Experience report: Log mining using natural language processing and application to anomaly detection. In Proceedings of the 2017 IEEE 28th International Symposium on Software Reliability Engineering (ISSRE), Toulouse, France, 23–26 October 2017; pp. 351–360. [Google Scholar]
- Yu, J.; Reiter, E.; Hunter, J.; Mellish, C. Choosing the content of textual summaries of large time-series data sets. Nat. Lang. Eng. 2007, 13, 25. [Google Scholar] [CrossRef] [Green Version]
- Weston, J.; Ratle, F.; Mobahi, H.; Collobert, R. Deep learning via semi-supervised embedding. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 639–655. [Google Scholar]
- Lopez-Martin, M.; Carro, B.; Arribas, J.I.; Sanchez-Esguevillas, A. Network intrusion detection with a novel hierarchy of distances between embeddings of hash IP addresses. Knowl.-Based Syst. 2021, 219, 106887. [Google Scholar] [CrossRef]
- Yeh, C.K.; Wu, W.C.; Ko, W.J.; Wang, Y.C.F. Learning deep latent space for multi-label classification. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long short term memory networks for anomaly detection in time series. In Proceedings of the Presses universitaires de Louvain, Bruges, Belgium, 22–24 April 2015; p. 89. [Google Scholar]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Fotiadou, K.; Velivassaki, T.H.; Voulkidis, A.; Skias, D.; De Santis, C.; Zahariadis, T. Proactive Critical Energy Infrastructure Protection via Deep Feature Learning. Energies 2020, 13, 2622. [Google Scholar] [CrossRef]
- Muhuri, P.S.; Chatterjee, P.; Yuan, X.; Roy, K.; Esterline, A. Using a Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) to Classify Network Attacks. Information 2020, 11, 243. [Google Scholar] [CrossRef]
- Khan, M.A.; Karim, M.; Kim, Y. A scalable and hybrid intrusion detection system based on the convolutional-LSTM network. Symmetry 2019, 11, 583. [Google Scholar] [CrossRef] [Green Version]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. Cnn-rnn: A unified framework for multi-label image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2285–2294. [Google Scholar]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Kwon, D.; Natarajan, K.; Suh, S.C.; Kim, H.; Kim, J. An empirical study on network anomaly detection using convolutional neural networks. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; pp. 1595–1598. [Google Scholar]
- Naseer, S.; Saleem, Y.; Khalid, S.; Bashir, M.K.; Han, J.; Iqbal, M.M.; Han, K. Enhanced network anomaly detection based on deep neural networks. IEEE Access 2018, 6, 48231–48246. [Google Scholar] [CrossRef]
- Ma, C.; Du, X.; Cao, L. Analysis of multi-types of flow features based on hybrid neural network for improving network anomaly detection. IEEE Access 2019, 7, 148363–148380. [Google Scholar] [CrossRef]
- Eckle, K.; Schmidt-Hieber, J. A comparison of deep networks with ReLU activation function and linear spline-type methods. Neural Netw. 2019, 110, 232–242. [Google Scholar] [CrossRef]
- Fotiadou, K.; Velivassaki, T.H.; Voulkidis, A.; Railis, K.; Trakadas, P.; Zahariadis, T. Incidents Information Sharing Platform for Distributed Attack Detection. IEEE Open J. Commun. Soc. 2020, 1, 593–605. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Khalifelu, Z.A. Analysis and evaluation of unstructured data: Text mining versus natural language processing. In Proceedings of the 5th International Conference on Application of Information and Communication Technologies (AICT), Baku, Azerbaijan, 12–14 October 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Liang, X.; Wang, X.; Lei, Z.; Liao, S.; Li, S.Z. Soft-margin softmax for deep classification. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2017; pp. 413–421. [Google Scholar]
- Vogl, T.P.; Mangis, J.; Rigler, A.; Zink, W.; Alkon, D. Accelerating the convergence of the back-propagation method. Biol. Cybern. 1988, 59, 257–263. [Google Scholar] [CrossRef]
- Patel, K.C.; Sharma, D.P. A Review paper on pfsense—An Open source firewall introducing with different capabilities & customization. IJARIIE 2017, 3, 2395–4396. [Google Scholar]
- Suricata-Network Threat Detection Engine. Available online: https://suricata-ids.org/ (accessed on 18 May 2021).
- Hossin, M.; Sulaiman, M.N. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process. 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 3–8 December 2018; pp. 8778–8788. [Google Scholar]
- Sun, Y.; Kamel, M.S.; Wang, Y. Boosting for Learning Multiple Classes with Imbalanced Class Distribution. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; pp. 592–602. [Google Scholar] [CrossRef] [Green Version]
- Chaudhary, A.; Kolhe, S.; Kamal, R. An improved random forest classifier for multi-class classification. Inf. Process. Agric. 2016, 3, 215–222. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
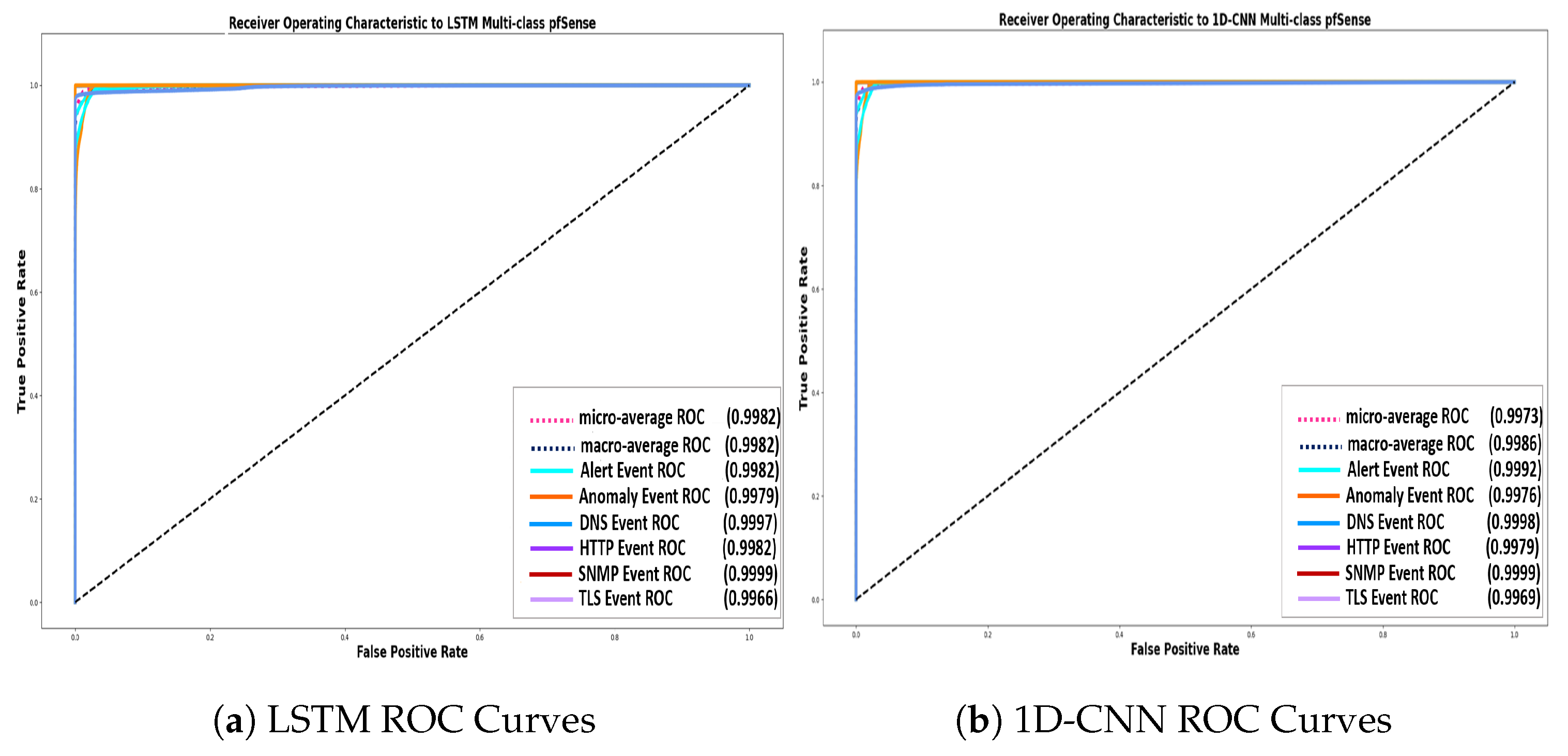{kind=link}
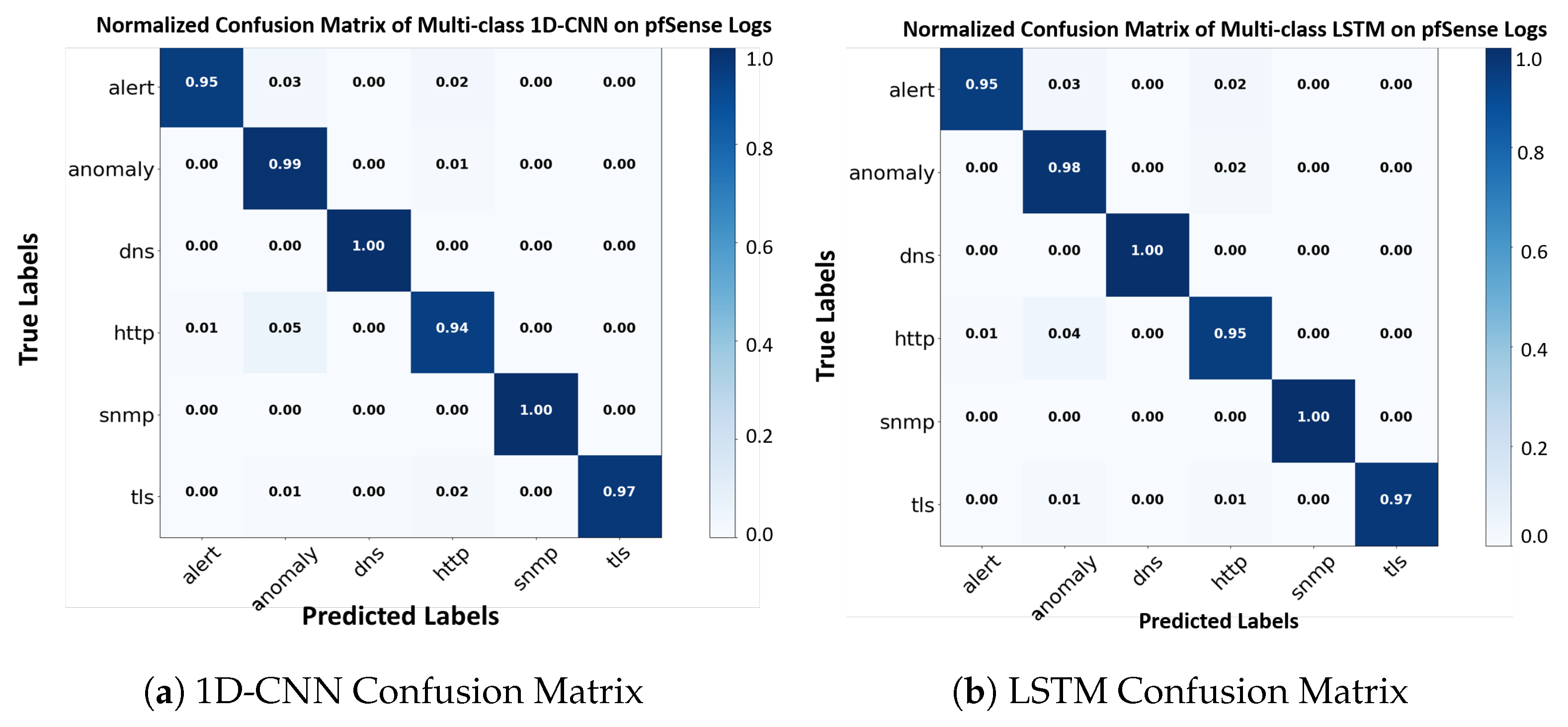{kind=link}
| Method | Random Forest | DNN | Proposed 1D-CNN | Proposed LSTM | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | Precision | Recall | F-1 Score | Precision | Recall | F-1 Score | Precision | Recall | F-1 Score | Precision | Recall | F-1 Score |
| Alert | 0.7996 | 0.8298 | 0.8844 | 0.8266 | 0.6687 | 0.7393 | 0.9862 | 0.9473 | 0.9663 | 0.9836 | 0.9492 | 0.9661 |
| Anomaly | 0.9908 | 0.8319 | 0.8154 | 0.7240 | 0.75087 | 0.7372 | 0.9168 | 0.9869 | 0.9506 | 0.9179 | 0.9751 | 0.9456 |
| DNS | 0.8400 | 0.9449 | 0.9673 | 0.9255 | 0.9113 | 0.9184 | 0.9980 | 0.9943 | 0.9961 | 0.9944 | 0.9979 | 0.9961 |
| HTTP | 0.9855 | 0.8772 | 0.8582 | 0.8026 | 0.6405 | 0.7124 | 0.9943 | 0.9980 | 0.9961 | 0.9454 | 0.9458 | 0.9456 |
| SNMP | 0.8971 | 0.9965 | 0.9910 | 0.9305 | 0.9830 | 0.9560 | 0.9994 | 0.9996 | 0.9995 | 0.9995 | 0.9996 | 0.9995 |
| TLS | 0.9316 | 0.9878 | 0.9646 | 0.7378 | 0.9710 | 0.8385 | 0.9995 | 0.9680 | 0.9835 | 0.9991 | 0.9682 | 0.9834 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fotiadou, K.; Velivassaki, T.-H.; Voulkidis, A.; Skias, D.; Tsekeridou, S.; Zahariadis, T. Network Traffic Anomaly Detection via Deep Learning. Information 2021, 12, 215. https://doi.org/10.3390/info12050215
Fotiadou K, Velivassaki T-H, Voulkidis A, Skias D, Tsekeridou S, Zahariadis T. Network Traffic Anomaly Detection via Deep Learning. Information. 2021; 12(5):215. https://doi.org/10.3390/info12050215
Chicago/Turabian StyleFotiadou, Konstantina, Terpsichori-Helen Velivassaki, Artemis Voulkidis, Dimitrios Skias, Sofia Tsekeridou, and Theodore Zahariadis. 2021. "Network Traffic Anomaly Detection via Deep Learning" Information 12, no. 5: 215. https://doi.org/10.3390/info12050215
APA StyleFotiadou, K., Velivassaki, T. -H., Voulkidis, A., Skias, D., Tsekeridou, S., & Zahariadis, T. (2021). Network Traffic Anomaly Detection via Deep Learning. Information, 12(5), 215. https://doi.org/10.3390/info12050215