
Joint Subtitle Extraction and Frame Inpainting for Videos with Burned-In Subtitles




Abstract
:1. Introduction
- The inverse conversion of the burned-in subtitle video to an independent subtitle file and subtitle-free video.
- A novel framework for burned-in subtitle video reconstruction based on deep learning.
- The first application of the state-of-the-art deep learning techniques for burned-in subtitle video reconstruction with significantly enhanced subtitle extraction and frame inpainting.
- A general pipeline can be applied in the reconstruction and re-editing of videos with subtitles, advertisements, logos, and other occlusions.
2. Related Work
2.1. Text Detection
2.2. Text Recognition
2.3. Image Inpainting
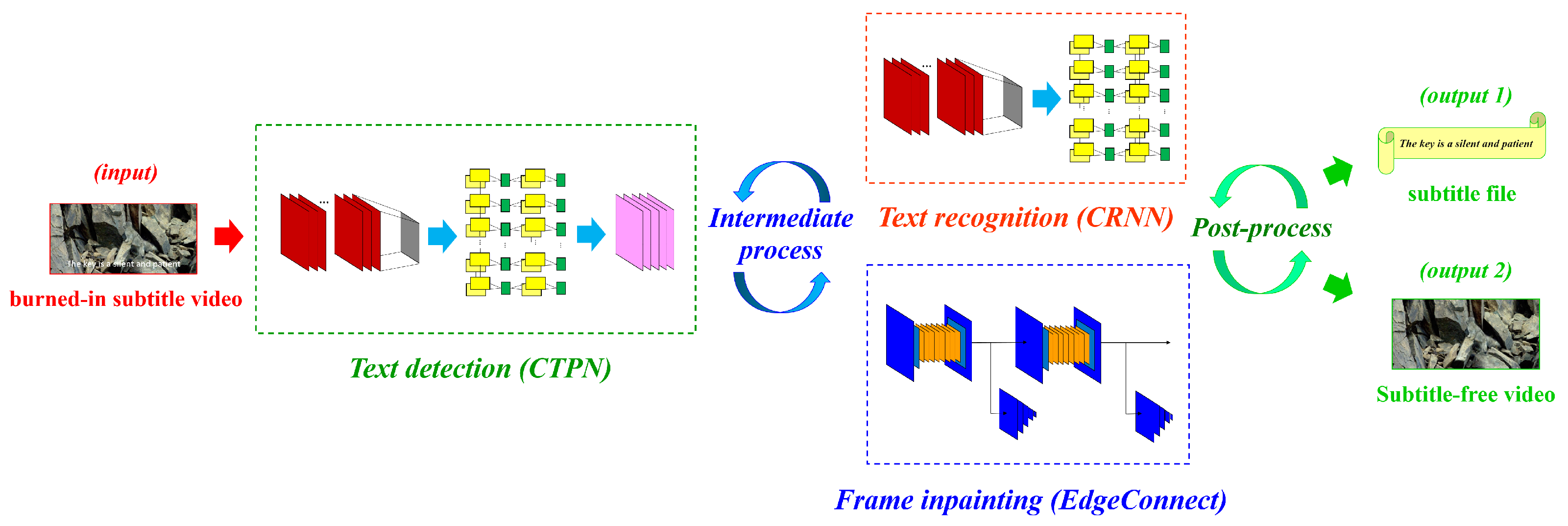
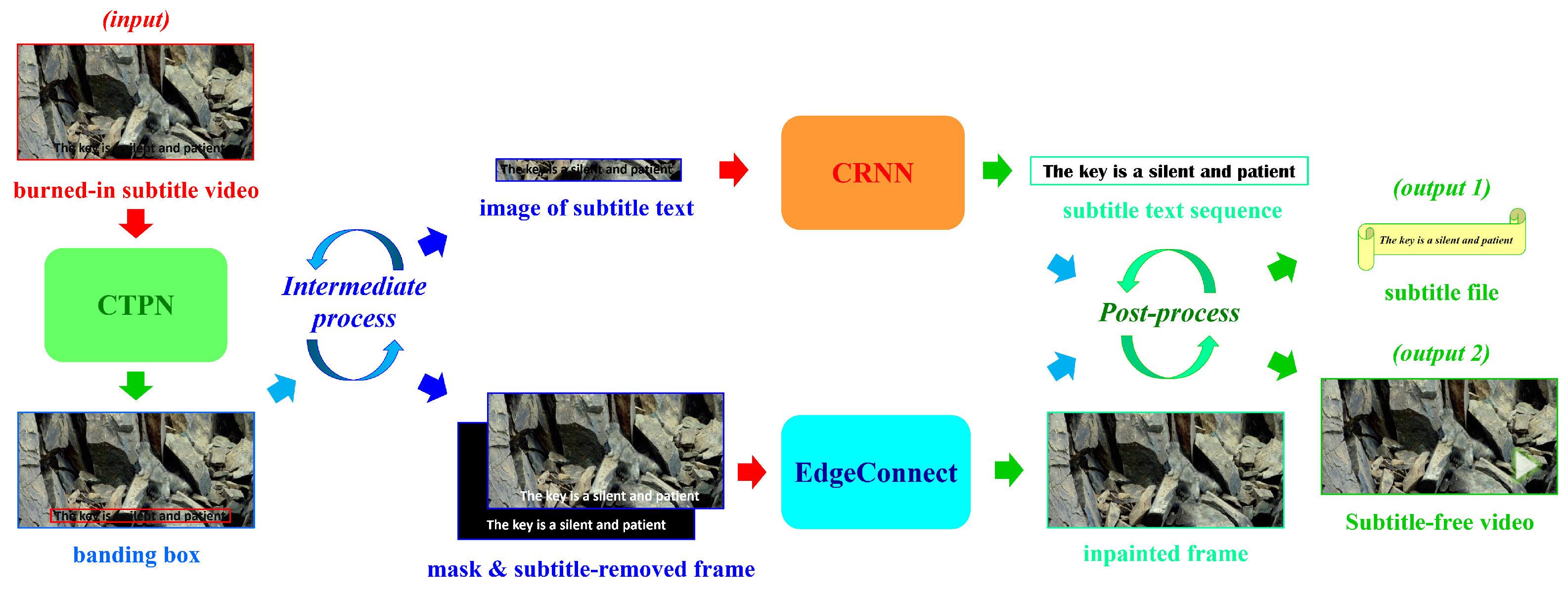
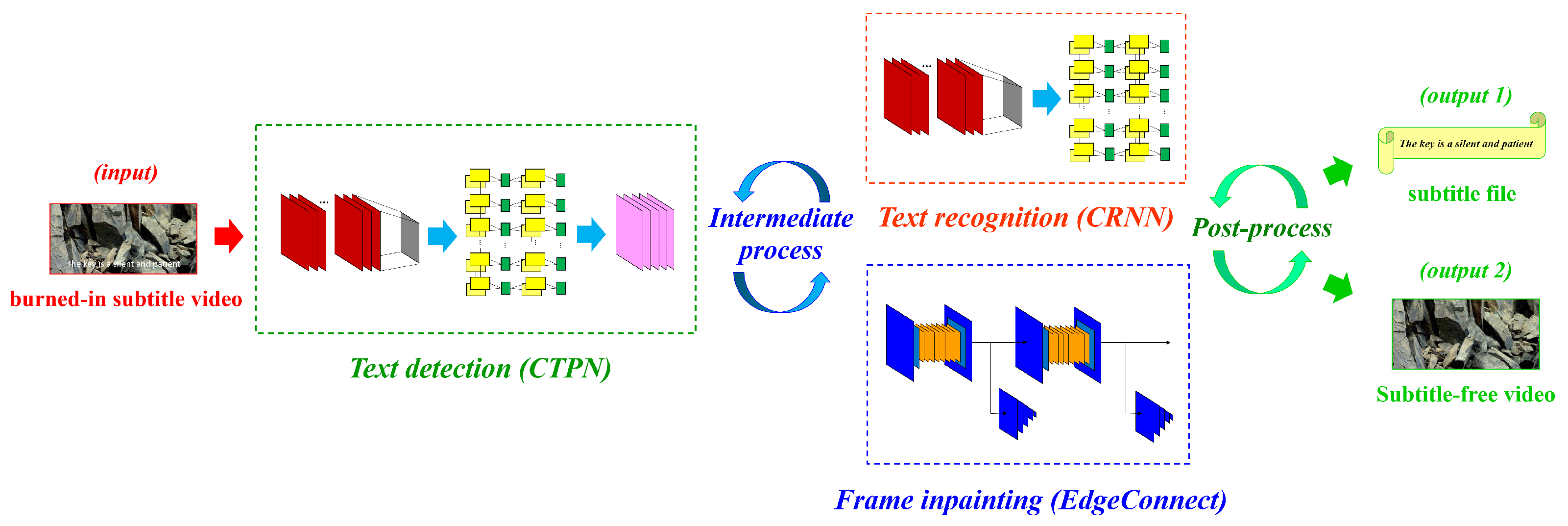
3. Method
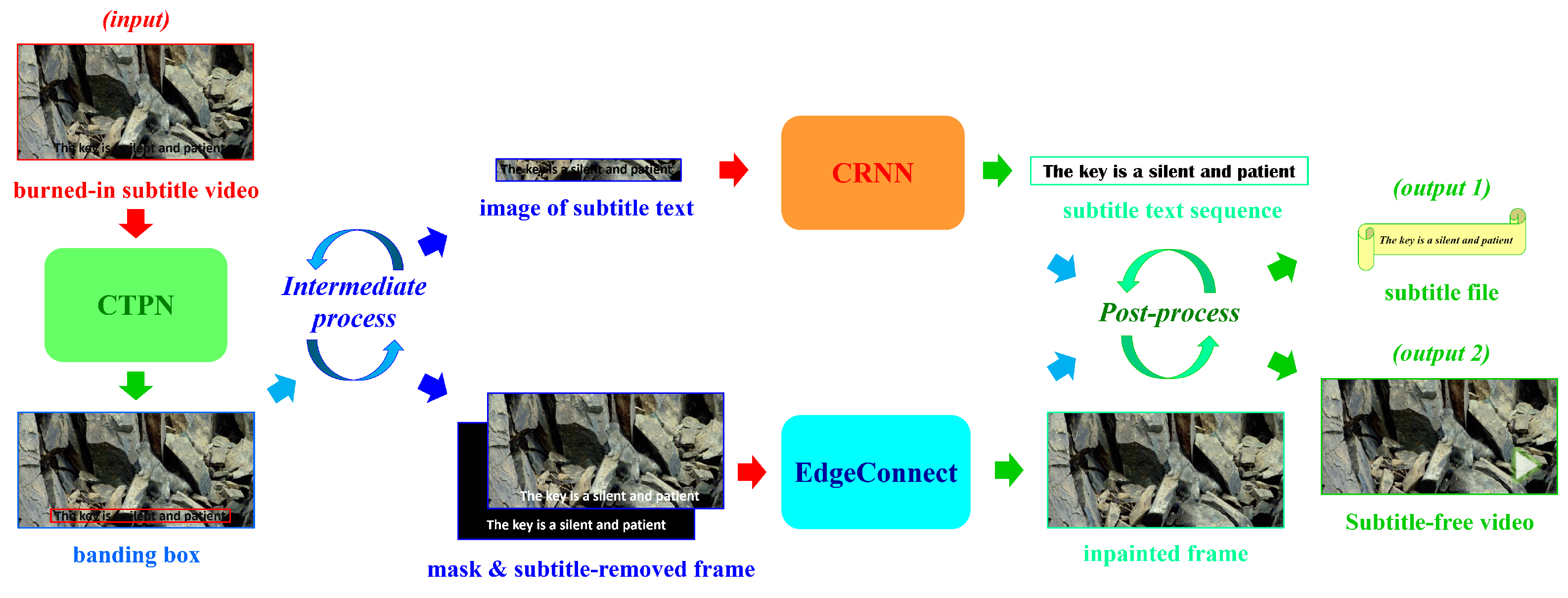
3.1. Text Detection
3.2. Text Recognition
3.3. Frame Inpainting
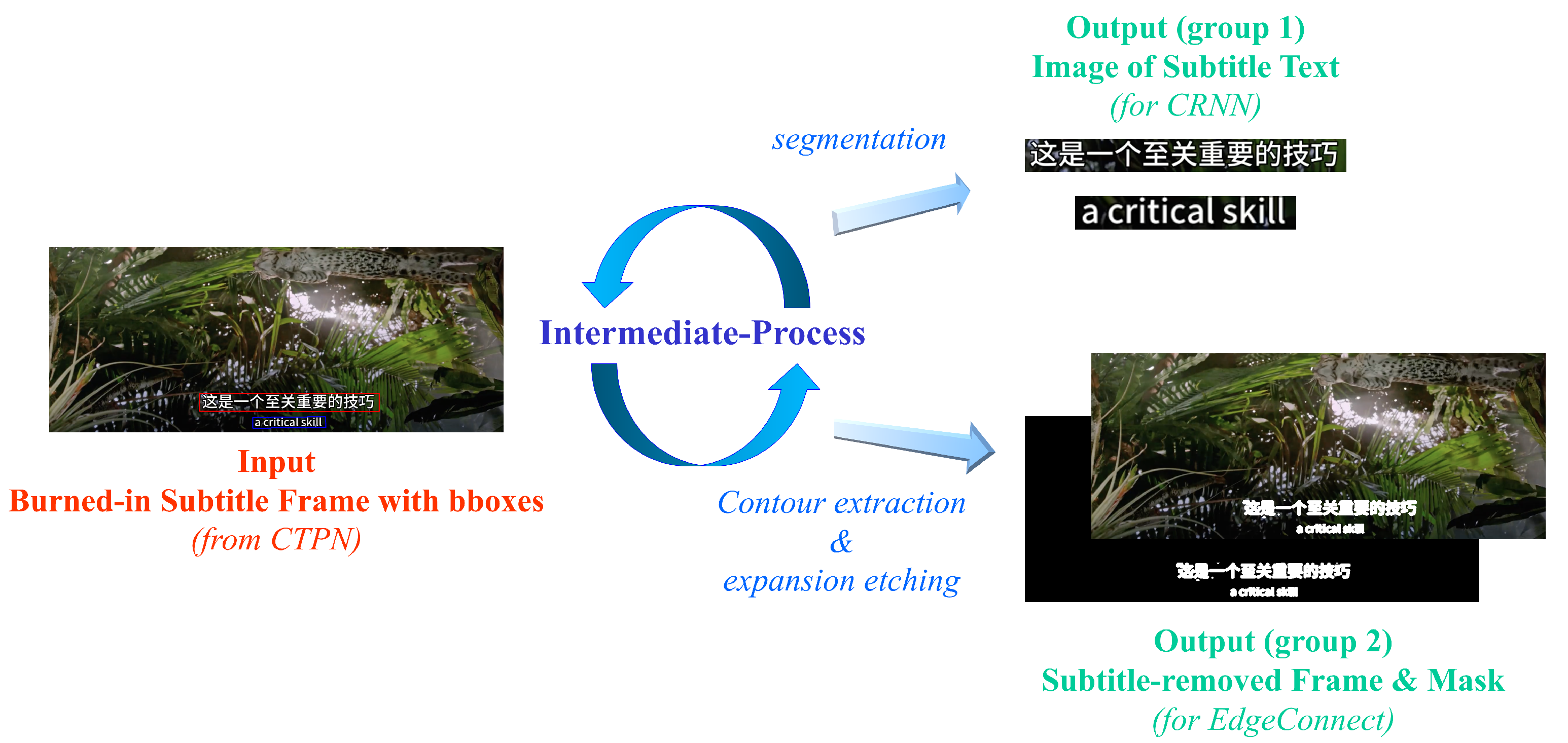
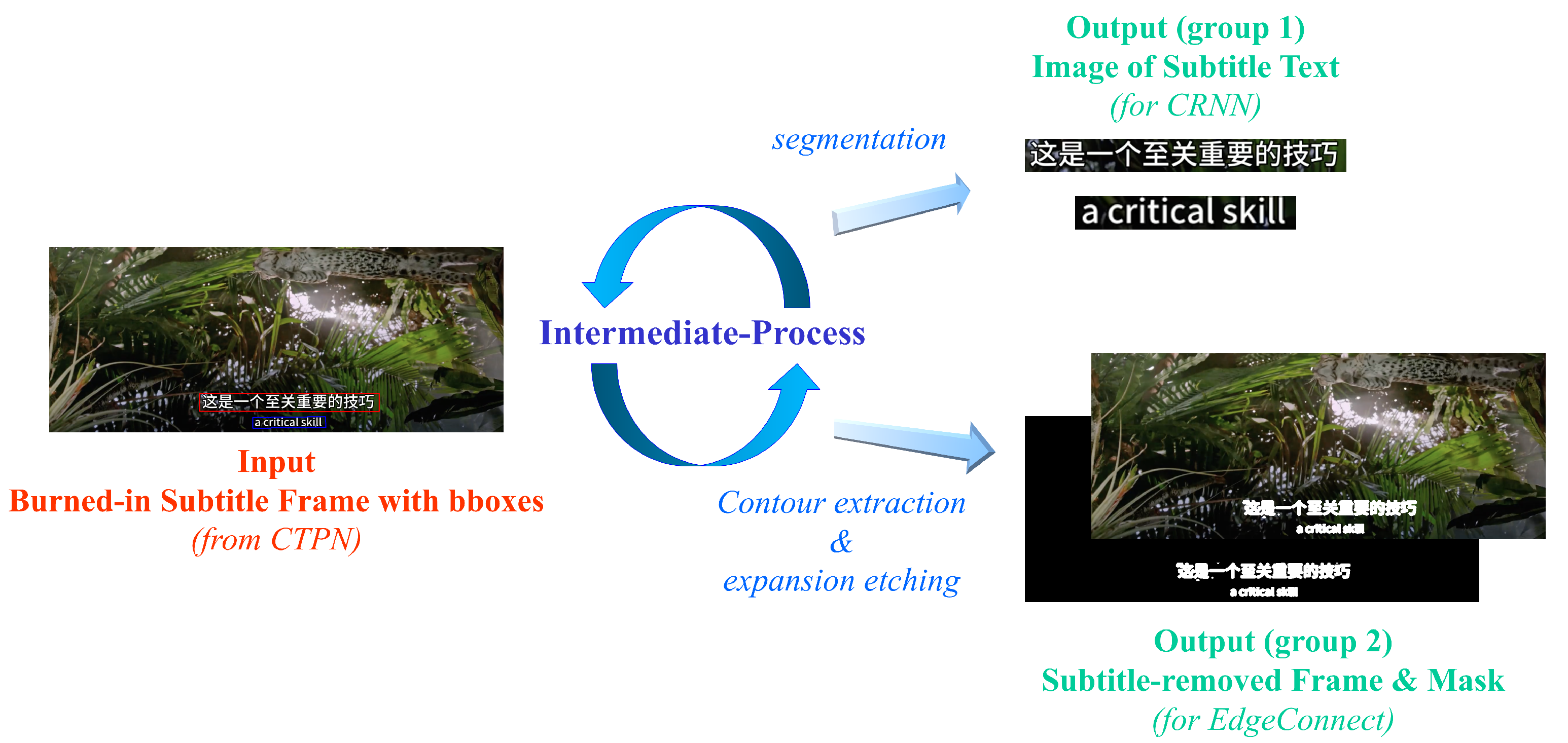
3.4. Intermediate-Process
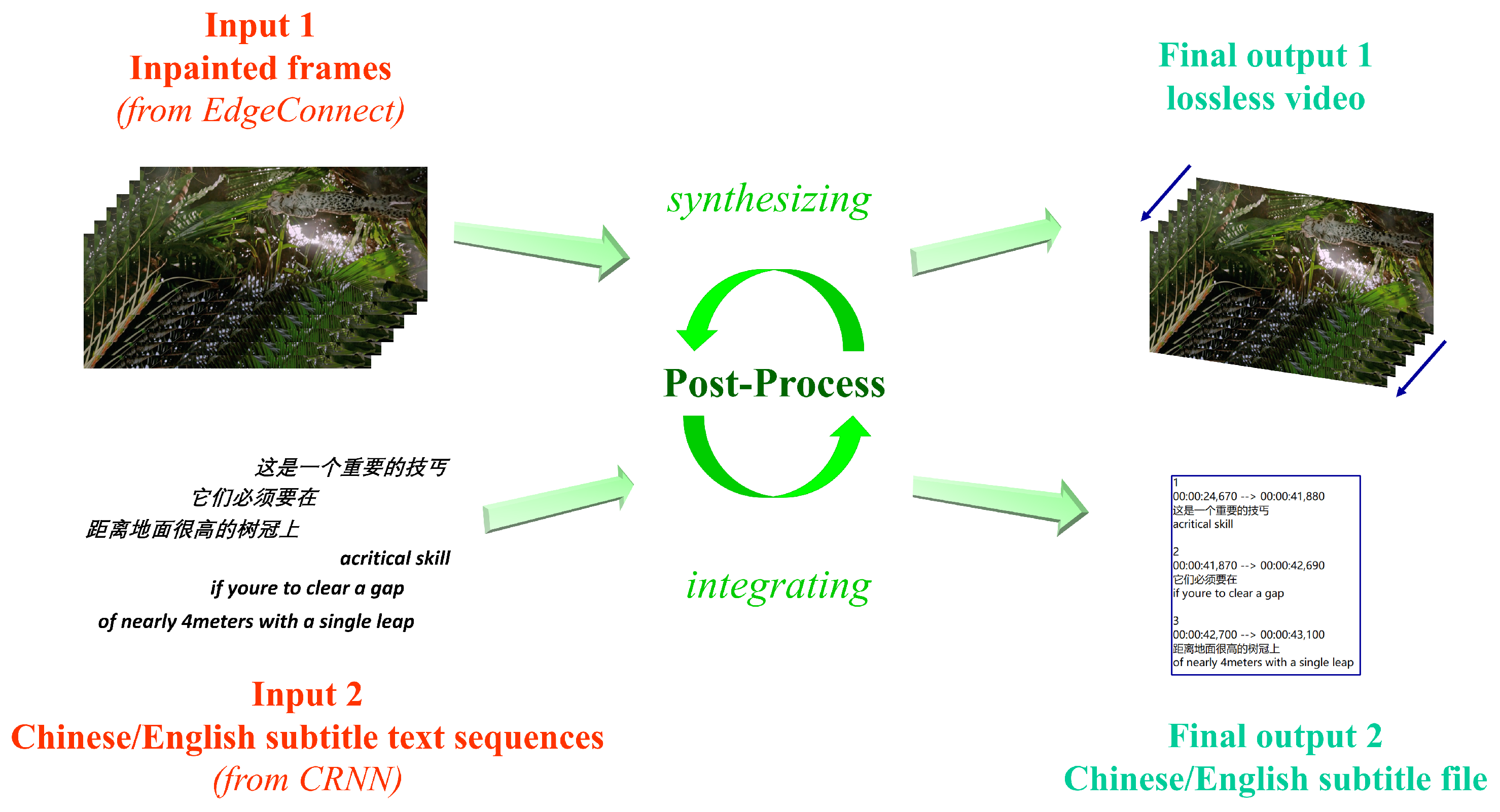
3.5. Post-Process
4. Results and Discussions
4.1. Text Detection
4.2. Intermediate-Process
4.3. Text Recognition
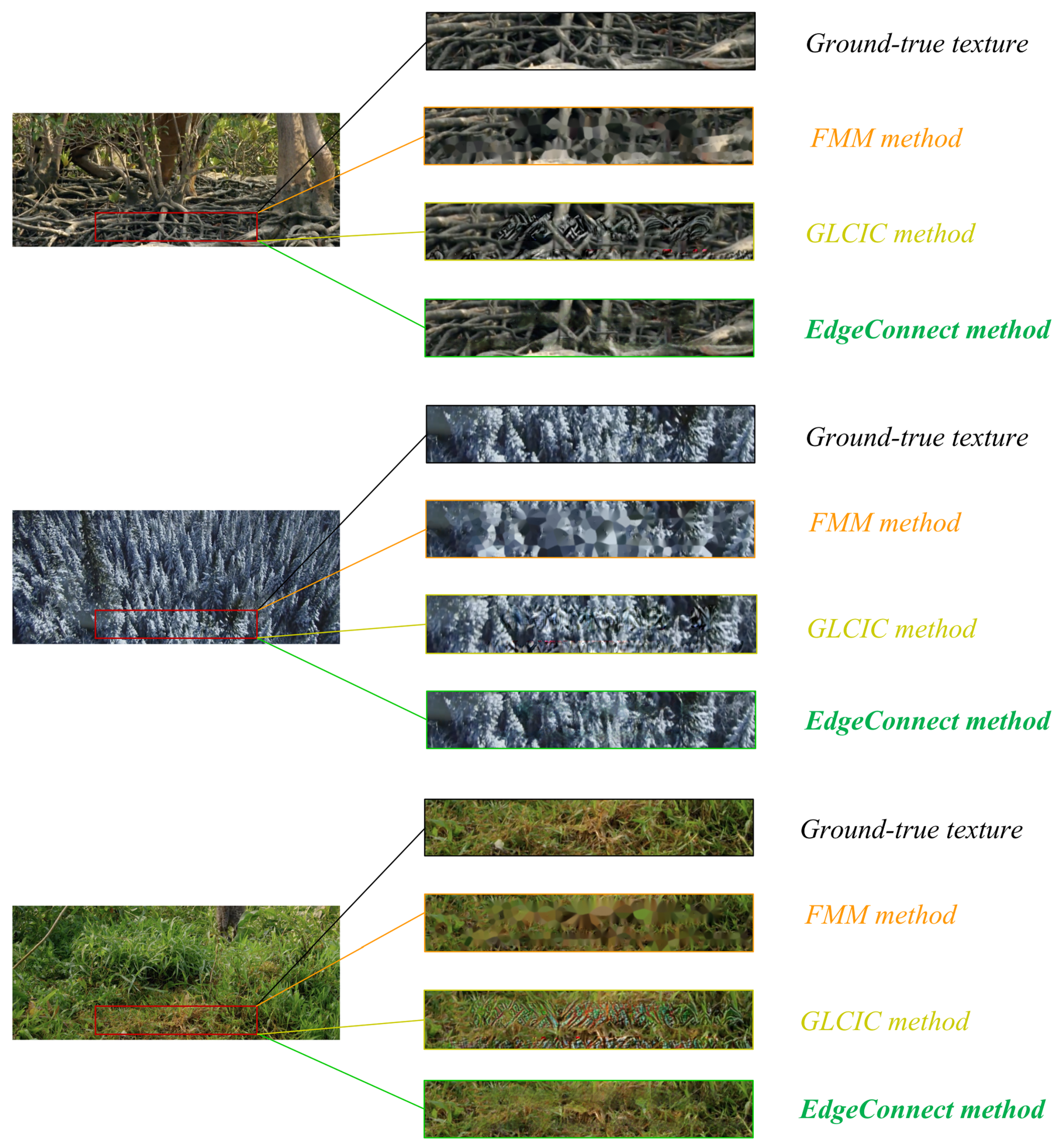
4.4. Frame Inpainting
4.5. Post-Process
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Configuration |
|---|---|
| Input | input raw image |
| Convolution | #maps:64, k:3 × 3, s:1, p:1 |
| Convolution | #maps:64, k:3 × 3, s:1, p:1 |
| MaxPooling | Window:2 × 2, s:2 |
| Convolution | #maps:128, k:3 × 3, s:1, p:1 |
| Convolution | #maps:128, k:3 × 3, s:1, p:1 |
| MaxPooling | Window:2 × 2, s:2 |
| Convolution | #maps:256, k:3 × 3, s:1, p:1 |
| Convolution | #maps:256, k:3 × 3, s:1, p:1 |
| Convolution | #maps:256, k:3 × 3, s:1, p:1 |
| MaxPooling | Window:2 × 2, s:2 |
| Convolution | #maps:512, k:3 × 3, s:1, p:1 |
| Convolution | #maps:512, k:3 × 3, s:1, p:1 |
| Convolution | #maps:512, k:3 × 3, s:1, p:1 |
| MaxPooling | Window:2 × 2, s:2 |
| Convolution | #maps:512, k:3 × 3, s:1, p:1 |
| Convolution | #maps:512, k:3 × 3, s:1, p:1 |
| Convolution | #maps:512, k:3 × 3, s:1, p:1 |
| Map-to-Sequence | #maps:512, k:3 × 3, s:1, p:1 |
| Bidirectional-LSTM | #hidden units:128 |
| Bidirectional-LSTM | #hidden units:128 |
| FullConnection | #dimension:512 |
| Output 1 | vertical coordinates |
| Output 2 | side-refinement |
| Output 3 | text/non-text scores |
| Type | Configuration |
|---|---|
| Input | input gray-scale image |
| Convolution | #maps:64, k:3 × 3, s:1, p:1 |
| MaxPooling | Window:2 × 2, s:2 |
| Convolution | #maps:128, k:3 × 3, s:1, p:1 |
| MaxPooling | Window:2 × 2, s:2 |
| Convolution | #maps:256, k:3 × 3, s:1, p:1 |
| Convolution | #maps:256, k:3 × 3, s:1, p:1 |
| MaxPooling | Window:1 × 2, s:2 |
| Convolution | #maps:512, k:3 × 3, s:1, p:1 |
| BatchNormalization | - |
| Convolution | #maps:512, k:3 × 3, s:1, p:1 |
| BatchNormalization | - |
| MaxPooling | Window:1 × 2, s:2 |
| Convolution | #maps:512, k:2 × 2, s:1, p:0 |
| Map-to-Sequence | - |
| Bidirectional-LSTM | #hidden units:256 |
| Bidirectional-LSTM | #hidden units:256 |
| Transcription | text sequence |
| EdgeGenerator | |
| Type | Configuration |
| Input | mask + edge + gray-scale map |
| Convolution | #in_channels:3, out_channels:64, k:7 × 7, p:0 |
| Convolution | #in_channels:64, out_channels:128, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:128, out_channels:256, k:4 × 4, s:2, p:1 |
| ResnetBlock×8 | #dimension:256, dilation = 2 |
| Convolution | #in_channels:256, out_channels:128, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:128, out_channels:64, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:64, out_channels:1, k:7 × 7, p:0 |
| EdgeDiscriminator | |
| Type | Configuration |
| Convolution | #in_channels:1, out_channels:64, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:64, out_channels:128, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:128, out_channels:256, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:256, out_channels:512, k:4 × 4, s:1, p:1 |
| Convolution | #in_channels:512, out_channels:1, k:4 × 4, s:1, p:1 |
| InpaintGenerator | |
| Type | Configuration |
| Input | edge map + RGB map |
| Convolution | #in_channels:4, out_channels:64, k:7 × 7, p:0 |
| Convolution | #in_channels:64, out_channels:128, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:128, out_channels:256, k:4 × 4, s:2, p:1 |
| ResnetBlock×8 | #dimension:256, dilation = 2 |
| Convolution | #in_channels:256, out_channels:128, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:128, out_channels:64, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:64, out_channels:3, k:7 × 7, p:0 |
| InpaintDiscriminator | |
| Type | Configuration |
| Convolution | #in_channels:3, out_channels:64, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:64, out_channels:128, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:128, out_channels:256, k:4 × 4, s:2, p:1 |
| Convolution | #in_channels:256, out_channels:512, k:4 × 4, s:1, p:1 |
| Convolution | #in_channels:512, out_channels:1, k:4 × 4, s:1, p:1 |
References
- Liqin, J.I.; Jiajun, W. Automatic Text Detection and Removal in Video Images. Chin. J. Image Graph. 2008, 13, 461–466. [Google Scholar]
- Xu, Y.; Shan, S.; Qiu, Z.; Jia, Z.; Shen, Z.; Wang, Y.; Shi, M.; Eric, I.; Chang, C. End-to-end subtitle detection and recognition for videos in East Asian languages via CNN ensemble. Signal Process. Image Commun. 2018, 60, 131–143. [Google Scholar] [CrossRef] [Green Version]
- Yan, H.; Xu, X. End-to-end video subtitle recognition via a deep Residual Neural Network. Pattern Recognit. Lett. 2020, 131, 368–375. [Google Scholar] [CrossRef]
- Favorskaya, M.N.; Zotin, A.G.; Damov, M.V. Intelligent inpainting system for texture reconstruction in videos with text removal. In Proceedings of the International Congress on Ultra Modern Telecommunications and Control Systems, Moscow, Russia, 18–20 August 2010; pp. 867–874. [Google Scholar]
- Khodadadi, M.; Behrad, A. Text localization, extraction and inpainting in color images. In Proceedings of the 20th Iranian Conference on Electrical Engineering (ICEE2012), Tehran, Iran, 15–17 May 2012; pp. 1035–1040. [Google Scholar]
- Jung, C.; Liu, Q.; Kim, J. A new approach for text segmentation using a stroke filter. Signal Process. 2008, 88, 1907–1916. [Google Scholar] [CrossRef]
- Zhang, D.Q.; Chang, S.F. Learning to detect scene text using a higher-order MRF with belief propagation. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; p. 101. [Google Scholar]
- Wolf, C.; Jolion, J.M.; Chassaing, F. Text localization, enhancement and binarization in multimedia documents. In Proceedings of the Object Recognition Supported by User Interaction for Service Robots, Quebec City, QC, Canada, 11–15 August 2002; Volume 2, pp. 1037–1040. [Google Scholar]
- Tian, Z.; Huang, W.; He, T.; He, P.; Qiao, Y. Detecting text in natural image with connectionist text proposal network. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 56–72. [Google Scholar]
- Esedoglu, S.; Shen, J. Digital inpainting based on the Mumford–Shah–Euler image model. Eur. J. Appl. Math. 2002, 13, 353–370. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.; Sun, X.; Wu, F.; Li, S.; Zhang, Y.Q. Image compression with edge-based inpainting. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1273–1287. [Google Scholar]
- Ballester, C.; Bertalmio, M.; Caselles, V.; Sapiro, G.; Verdera, J. Filling-in by joint interpolation of vector fields and gray levels. IEEE Trans. Image Process. 2001, 10, 1200–1211. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Darabi, S.; Shechtman, E.; Barnes, C.; Goldman, D.B.; Sen, P. Image melding: Combining inconsistent images using patch-based synthesis. Acm Trans. Graph. (TOG) 2012, 31, 1–10. [Google Scholar] [CrossRef]
- Huang, J.B.; Kang, S.B.; Ahuja, N.; Kopf, J. Image completion using planar structure guidance. Acm Trans. Graph. (TOG) 2014, 33, 1–10. [Google Scholar] [CrossRef]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. Edgeconnect: Generative image inpainting with adversarial edge learning. arXiv 2019, arXiv:1901.00212. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [Green Version]
- Favorskaya, M.N.; Damov, M.V.; Zotin, A.G. Intelligent method of texture reconstruction in video sequences based on neural networks. Int. J. Reason. Based Intell. Syst. 2013, 5, 223–236. [Google Scholar] [CrossRef]
- Vuong, T.L.; Le, D.M.; Le, T.T.; Le, T.H. Pre-rendered subtitles removal in video sequences using text detection and inpainting. In Proceedings of the International Conference on Electronics, Information and Communication, Danang, Vietnam, 27–30 January 2016; pp. 94–96. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Deep features for text spotting. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 512–528. [Google Scholar]
- Busta, M.; Neumann, L.; Matas, J. Fastext: Efficient unconstrained scene text detector. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1206–1214. [Google Scholar]
- Huang, W.; Qiao, Y.; Tang, X. Robust scene text detection with convolution neural network induced mser trees. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 497–511. [Google Scholar]
- Yin, X.C.; Yin, X.; Huang, K.; Hao, H.W. Robust text detection in natural scene images. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 970–983. [Google Scholar]
- Wang, T.; Wu, D.J.; Coates, A.; Ng, A.Y. End-to-end text recognition with convolutional neural networks. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba Science City, Japan, 11–15 November 2012; pp. 3304–3308. [Google Scholar]
- Bissacco, A.; Cummins, M.; Netzer, Y.; Neven, H. Photoocr: Reading text in uncontrolled conditions. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 785–792. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading text in the wild with convolutional neural networks. Int. J. Comput. Vis. 2016, 116, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A novel connectionist system for unconstrained handwriting recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 855–868. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Yeh, R.A.; Chen, C.; Yian Lim, T.; Schwing, A.G.; Hasegawa-Johnson, M.; Do, M.N. Semantic image inpainting with deep generative models. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5485–5493. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and Locally Consistent Image Completion. Acm Trans. Graph. 2017, 36, 107:1–107:14. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition. arXiv 2014, arXiv:1406.2227. [Google Scholar]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Telea, A. An image inpainting technique based on the fast marching method. J. Graph. Tools 2004, 9, 23–34. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. arXiv 2017, arXiv:1706.08500. [Google Scholar]





| Accuracy | ||
|---|---|---|
| Strategy | Chinese | English |
| Entire frame recognition | 70.5% | 72.1% |
| End-to-end recognition | 81.6% | 79.3% |
| Evaluation Metrics | ||||
|---|---|---|---|---|
| Method | PSNR | SSIM | NRMSE | FID |
| FMM | 28.804 | 0.945 | 0.110 | 0.280 |
| GLCIC | 29.241 | 0.960 | 0.099 | 0.142 |
| EdgeConnect | 34.129 | 0.975 | 0.059 | 0.035 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; He, Y.; Li, X.; Hu, X.; Hao, C.; Jiang, B. Joint Subtitle Extraction and Frame Inpainting for Videos with Burned-In Subtitles. Information 2021, 12, 233. https://doi.org/10.3390/info12060233
Xu H, He Y, Li X, Hu X, Hao C, Jiang B. Joint Subtitle Extraction and Frame Inpainting for Videos with Burned-In Subtitles. Information. 2021; 12(6):233. https://doi.org/10.3390/info12060233
Chicago/Turabian StyleXu, Haoran, Yanbai He, Xinya Li, Xiaoying Hu, Chuanyan Hao, and Bo Jiang. 2021. "Joint Subtitle Extraction and Frame Inpainting for Videos with Burned-In Subtitles" Information 12, no. 6: 233. https://doi.org/10.3390/info12060233
APA StyleXu, H., He, Y., Li, X., Hu, X., Hao, C., & Jiang, B. (2021). Joint Subtitle Extraction and Frame Inpainting for Videos with Burned-In Subtitles. Information, 12(6), 233. https://doi.org/10.3390/info12060233