
Impresso Inspect and Compare. Visual Comparison of Semantically Enriched Historical Newspaper Articles


Abstract
:1. Introduction
Related Work
2. Materials and Methods
2.1. Interface Design
2.2. Computational Complexity
3. Results
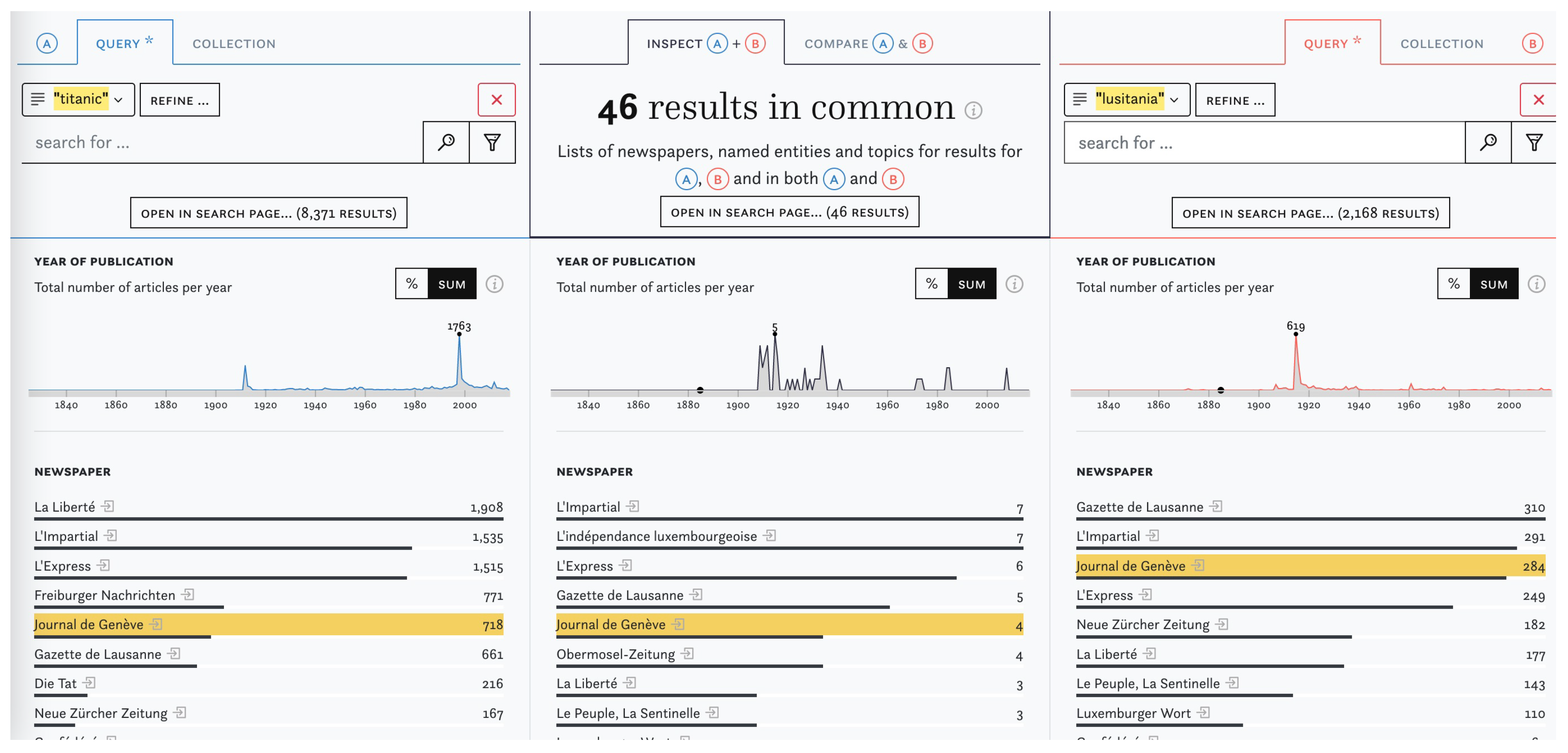
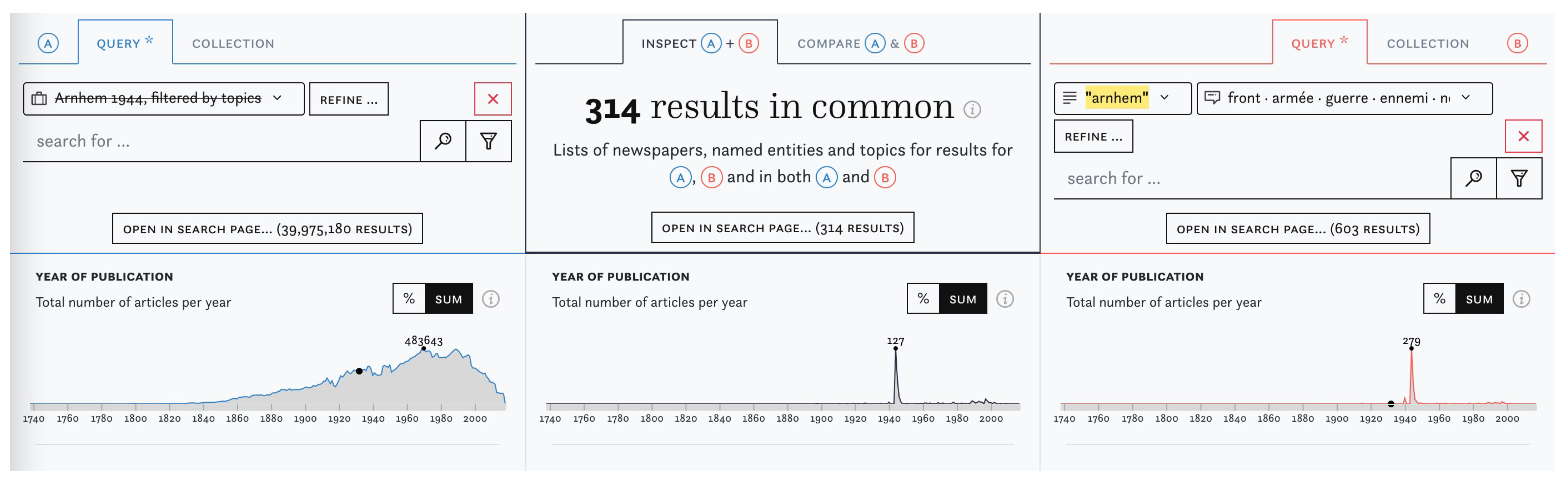
3.1. Improving Search Queries
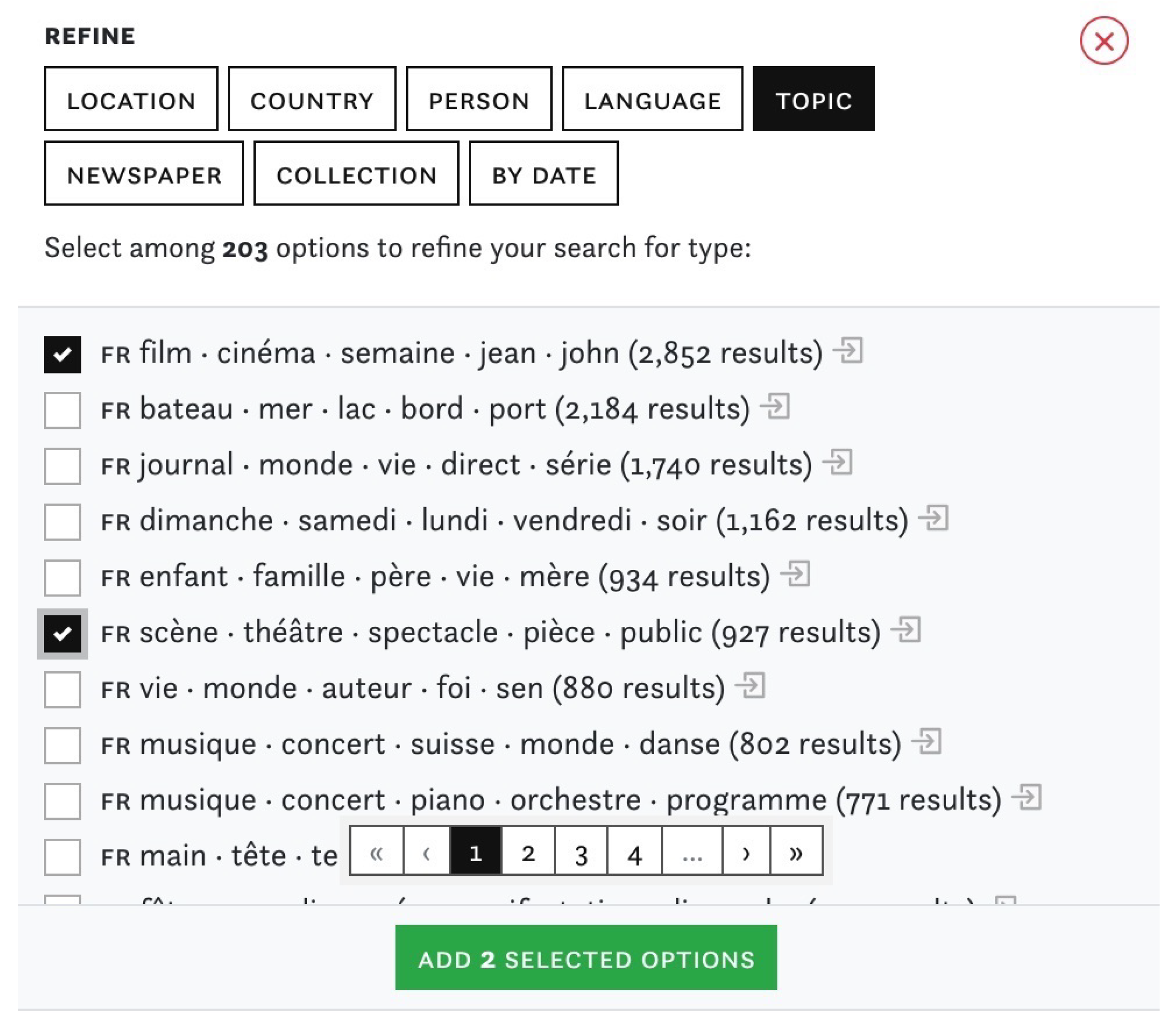
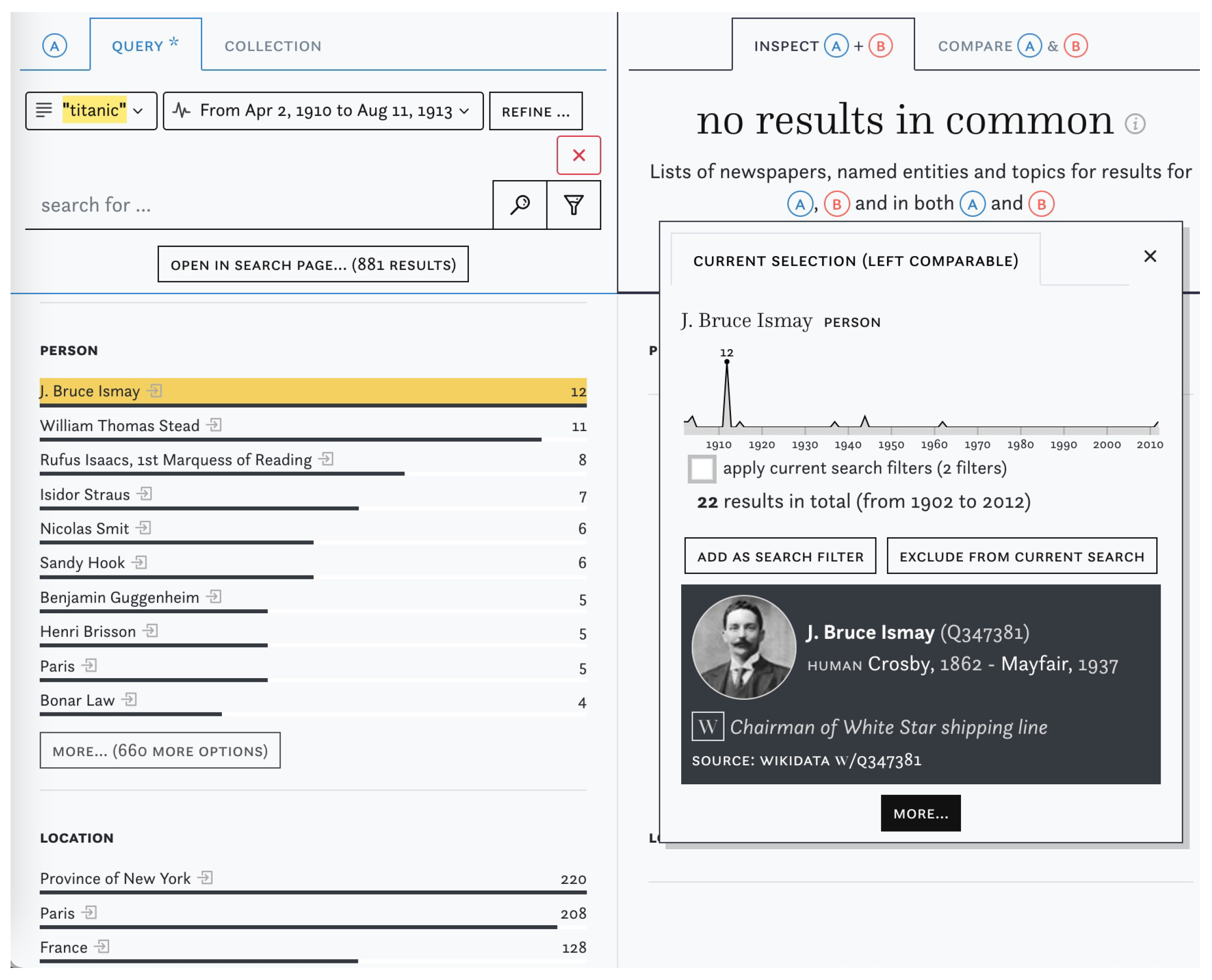
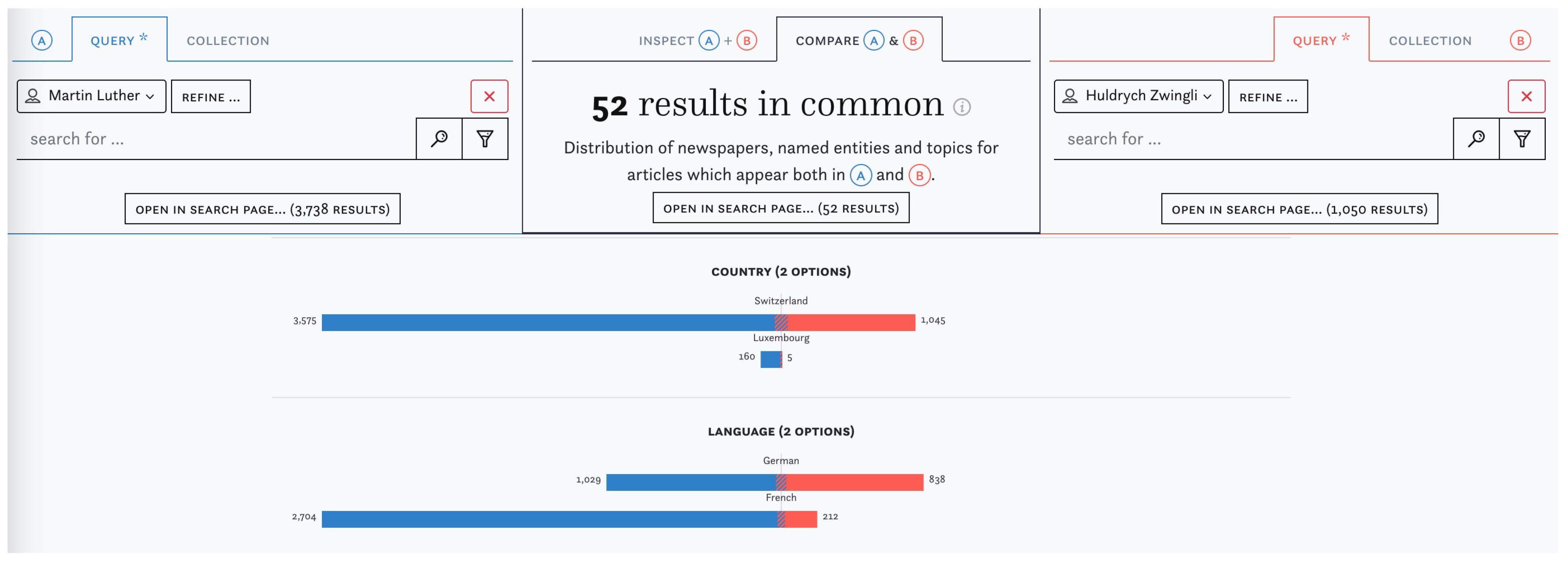
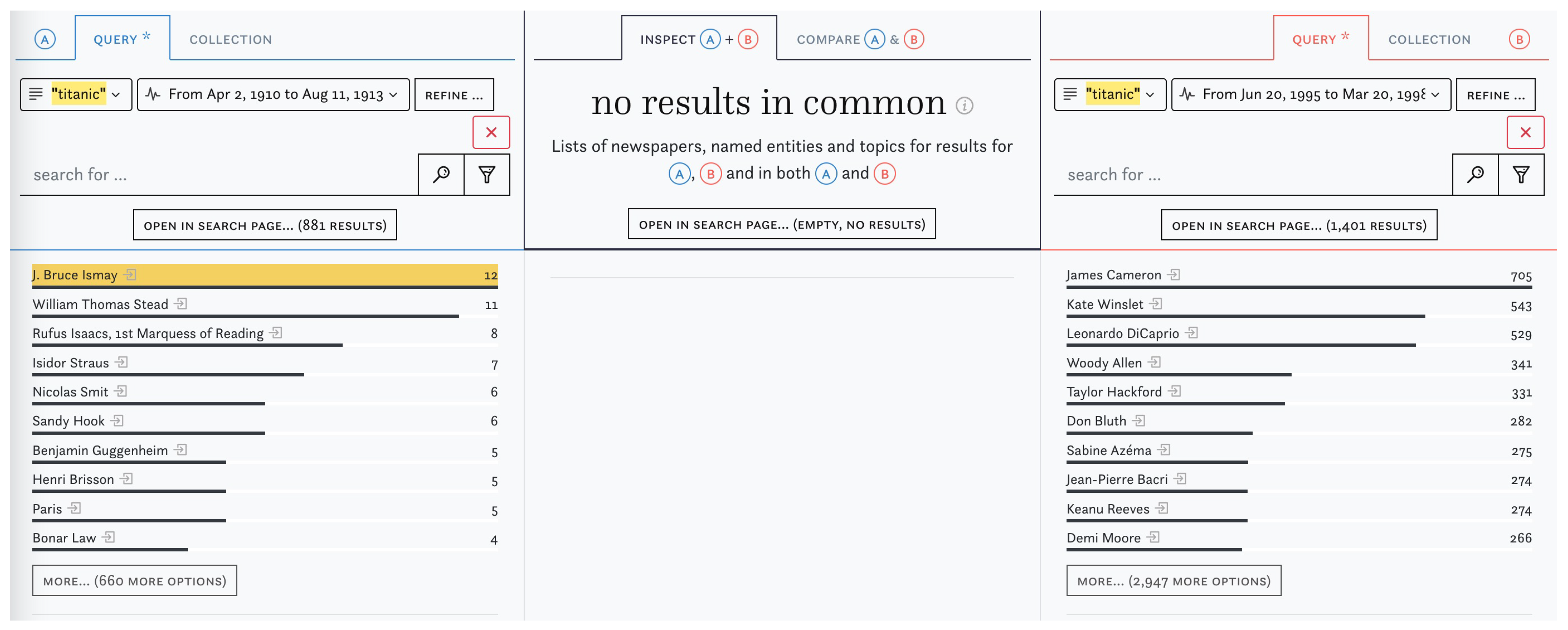
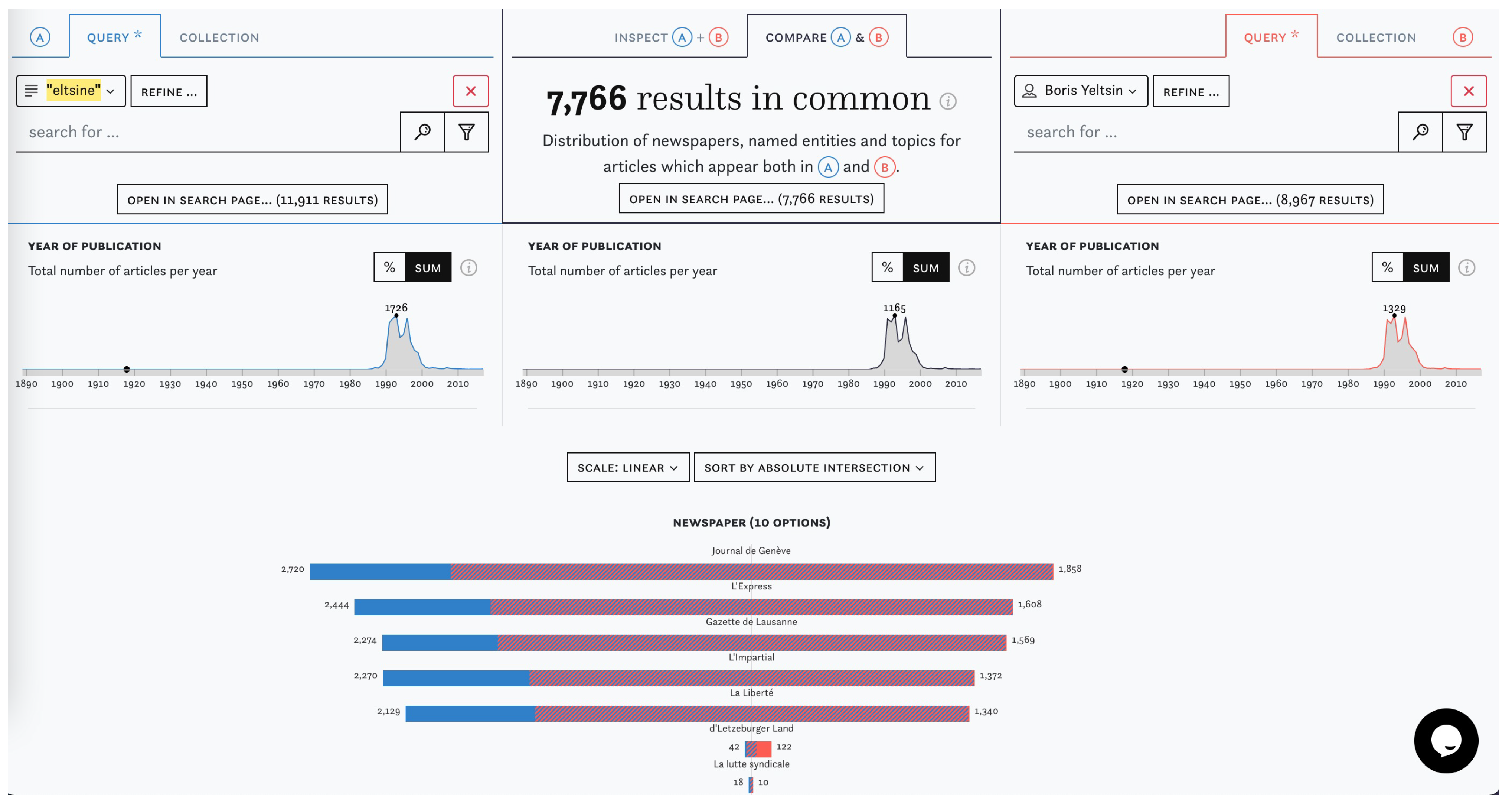
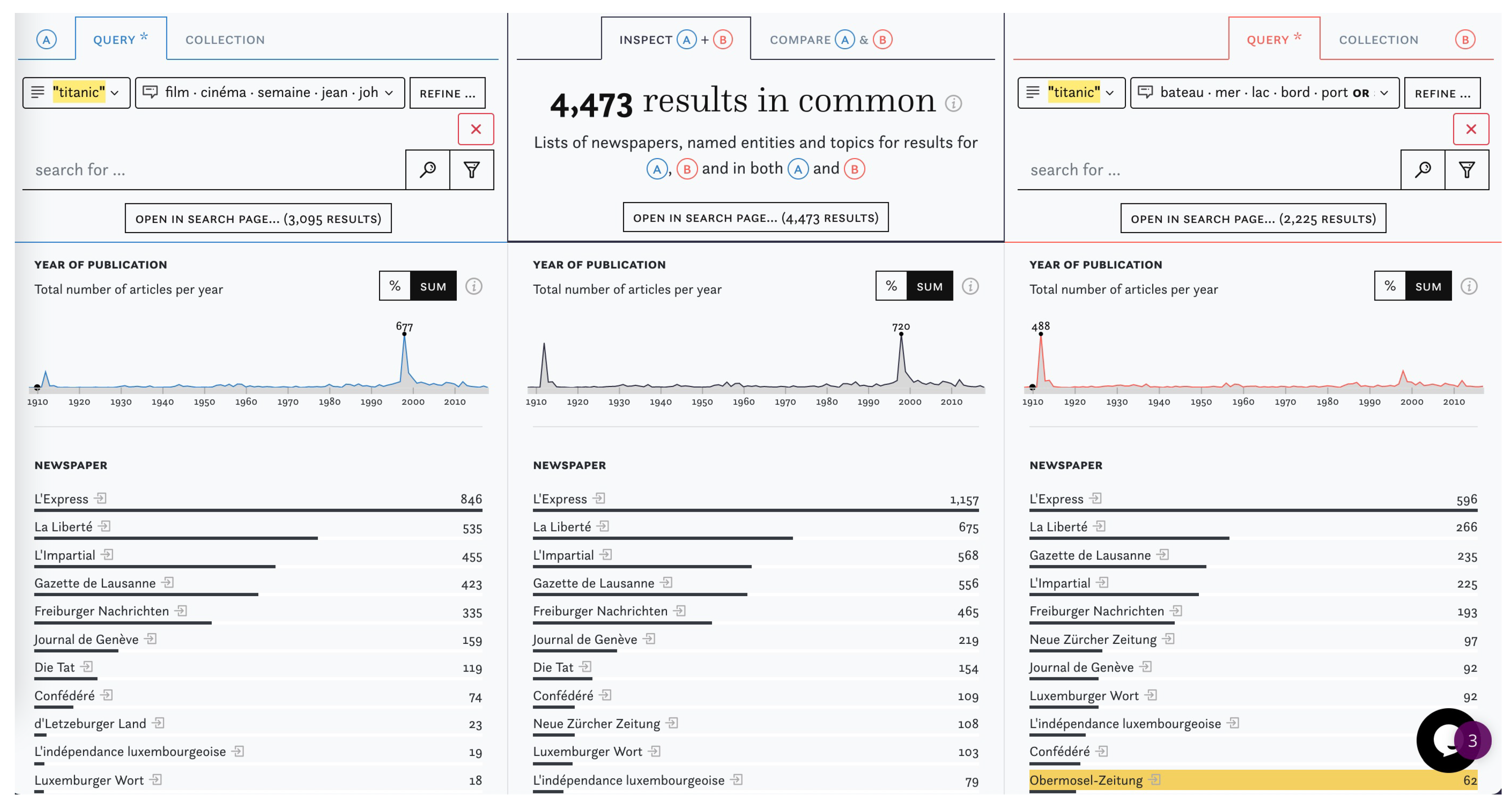
3.2. Content Exploration
3.3. Data Criticism
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alharbi, M.; Laramee, R.S. SoS TextVis: An Extended Survey of Surveys on Text Visualization. Computers 2019, 8, 17. [Google Scholar] [CrossRef] [Green Version]
- Windhager, F.; Federico, P.; Schreder, G.; Glinka, K.; Dörk, M.; Miksch, S.; Mayr, E. Visualization of Cultural Heritage Collection Data: State of the Art and Future Challenges. IEEE Trans. Visual. Comput. Graph. 2019, 25, 2311–2330. [Google Scholar] [CrossRef] [PubMed]
- Glinka, K.; Meier, S.; Dörk, M. Visualising the ’Un-seen’: Towards Critical Approaches and Strategies of Inclusion in Digital Cultural Heritage Interfaces. In Kultur und Informatik: Cross Media, 1st ed.; Verlag Werner Hülsbusch: Glückstadt, Germany, 2015; pp. 105–117. Available online: https://uclab.fh-potsdam.de/wp/wp-content/uploads/Visualising_the_Unseen_KuI15.pdf (accessed on 15 June 2021).
- Smith, D.A.; Cordell, R.; Mullen, A. Computational Methods for Uncovering Reprinted Texts in Antebellum Newspapers. Am. Lit. Hist. 2015, 27, E1–E15. [Google Scholar] [CrossRef]
- Pinson, G. La Réimpression dans la Presse Francophone du 19e Siècle—Numapresse. Available online: http://www.numapresse.org/2017/10/13/la-reimpression-dans-la-presse-francophone-du-19e-siecle-g-pinson-j-schuh-avec-p-c-langlais/ (accessed on 15 June 2021).
- Oiva, M.; Nivala, A.; Salmi, H.; Latva, O.; Jalava, M.; Keck, J.; Domínguez, L.M.; Parker, J. Spreading News in 1904. Media Hist. 2020, 26, 391–407. [Google Scholar] [CrossRef] [Green Version]
- Marjanen, J.; Zosa, E.; Hengchen, S.; Pivovarova, L.; Tolonen, M. Topic Modelling Discourse Dynamics in Historical Newspapers. In Proceedings of the 5th Conference Digital Humanities in the Nordic Countries (DHN 2020), Riga, Latvia, 21–23 October 2020; Schloss Dagstuhl Leibniz Center for Informatics: Riga, Latvia, 2020; pp. 63–77. [Google Scholar]
- Martinez-Ortiz, C.; Kenter, T.; Wevers, M.; Huijnen, P.; van Eijnatten, J. Design and implementation of ShiCo: Visualising shifting concepts over time. HistoInformatics 2016, 16, 9. [Google Scholar]
- Huistra, H.; Mellink, B. Phrasing history: Selecting sources in digital repositories. Hist. Methods A J. Quant. Interdiscip. Hist. 2016, 49, 220–229. [Google Scholar] [CrossRef] [Green Version]
- Willems, M.; Atanassova, R. Europeana Newspapers: Searching Digitized Historical Newspapers from 23 European Countries. Insights 2015, 28, 51–56. [Google Scholar] [CrossRef] [Green Version]
- Allen, R.B.; Sieczkiewicz, R. How Historians use Historical Newspapers. Proc. Am. Soc. Inf. Sci. Technol. 2010, 47. [Google Scholar] [CrossRef]
- Liu, S.; Wang, X.; Collins, C.; Dou, W.; Ouyang, F.; El-Assady, M.; Jiang, L.; Keim, D.A. Bridging Text Visualization and Mining: A Task-Driven Survey. IEEE Trans. Vis. Comput. Graph. 2019, 25, 2482–2504. [Google Scholar] [CrossRef] [Green Version]
- Unsworth, J. Scholarly Primitives: What Methods Do Humanities Researchers Have in Common, and How Might Our Tools Reflect This? Available online: https://johnunsworth.name/Kings.5-00/primitives.html (accessed on 15 June 2021).
- Thai, M.T.; Wu, W.; Xiong, H. (Eds.) Big Data in Complex and Social Networks; Chapman and Hall/CRC: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Fickers, A. Towards A New Digital Historicism? Doing History in the Age of Abundance. VIEW J. Eur. Telev. Hist. Cult. 2012, 1, 19–26. [Google Scholar] [CrossRef]
- Matteo, R.; Ehrmann, M.; Clematide, S.; Guido, D. The Impresso System Architecture in a Nutshell. Technical Report, EuropeanaTech Insights. 2020. Available online: https://infoscience.epfl.ch/record/283595 (accessed on 15 June 2021).
- Ehrmann, M.; Bunout, E.; Düring, M. Historical Newspaper User Interfaces: A Review. IFLA WLIC 2019. 2017. Available online: http://library.ifla.org/2578/ (accessed on 15 June 2021).
- Hechl, S.; Langlais, P.C.; Marjanen, J.; Oberbichler, S.; Pfanzelter, E. Digital Interfaces of Historical Newspapers: Opportunities, Restrictions and Recommendations. HistoInformatics 2021. [Google Scholar] [CrossRef]
- Moreux, J.P. Innovative Approaches of Historical Newspapers: Data Mining, Data Visualization, Semantic Enrichment. IFLA News Media Section. 2016. Available online: https://hal-bnf.archives-ouvertes.fr/hal-01389455 (accessed on 15 June 2021).
- Viola, L.; Verheul, J. The GeoNewsMiner: An Interactive Spatial Humanities Tool to Visualize Geographical References in Historical Newspapers. Dig. Human. 2020. [Google Scholar] [CrossRef]
- Franke, M.; John, M.; Knabben, M.; Keck, J.; Blascheck, T.; Koch, S. LilyPads: Exploring the Spatiotemporal Dissemination of Historical Newspaper Articles. In Proceedings of the 11th International Conference on Information Visualization Theory and Applications, Valletta, Malta, 27–29 February 2021; pp. 17–28. [Google Scholar] [CrossRef]
- Spenke, M.; Beilken, C.; Berlage, T. FOCUS: The Interactive Table for Product Comparison and Selection. In Proceedings of the 9th Annual ACM Symposium on User Interface Software and Technology—UIST’96, Seattle, DC, USA, 6–8 November 1996; ACM Press: Seattle, DC, USA, 1996; pp. 41–50. [Google Scholar] [CrossRef]
- Ahlberg, C.; Williamson, C.; Shneiderman, B. Dynamic Queries for Information Exploration: An Implementation and Evaluation. CHI 1992. [Google Scholar] [CrossRef]
- Ochigame, R.; Ye, K. Search Atlas: Visualizing Divergent Search Results Across Geopolitical Borders. In Designing Interactive Systems Conference 2021; ACM: New York, NY, USA, 2021; pp. 1970–1983. [Google Scholar] [CrossRef]
- Sun, L.; Dong, S.; Ge, Y.; Fonseca, J.P.; Robinson, Z.T.; Mysore, K.S.; Mehta, P. DiVenn: An Interactive and Integrated Web-Based Visualization Tool for Comparing Gene Lists. Front. Genet. 2019. [Google Scholar] [CrossRef] [PubMed]
- Ren, X.; Lv, Y.; Wang, K.; Han, J. Comparative Document Analysis for Large Text Corpora. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 325–334. [Google Scholar] [CrossRef] [Green Version]
- Jähnichen, P.; Oesterling, P.; Heyer, G.; Liebmann, T.; Scheuermann, G.; Kuras, C. Exploratory Search Through Visual Analysis of Topic Models. Dig. Human. Quart. 2017, 11. Available online: http://www.digitalhumanities.org/dhq/vol/11/2/000296/000296.html (accessed on 15 June 2021).
- Sievert, C.; Shirley, K. LDAvis: A Method for Visualizing and Interpreting Topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, MD, USA, 27 June 2014; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 63–70. [Google Scholar] [CrossRef]
- Jänicke, S.; Geßner, A.; Büchler, M.; Scheuermann, G. Visualizations for Text Re-use. In Proceedings of the 2014 International Conference on Information Visualization Theory and Applications (IVAPP), Lisbon, Portugal, 5–8 January 2014; pp. 59–70. [Google Scholar] [CrossRef]
- Azad, H.K.; Deepak, A. Query expansion techniques for information retrieval: A survey. Inf. Process. Manag. 2019, 56, 1698–1735. [Google Scholar] [CrossRef] [Green Version]
- Veerasamy, A.; Belkin, N.J. Evaluation of a Tool for Visualization of Information Retrieval Results. In Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Zurich, Switzerland, 18–22 August 1996; Association for Computing Machinery: New York, NY, USA, 1996; pp. 85–92. [Google Scholar] [CrossRef]
- Hearst, M.A. TileBars: Visualization of Term Distribution Information in Full Text Information Access. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; ACM Press/Addison-Wesley Publishing Co.: New York, NY, USA, 1995; pp. 59–66. [Google Scholar] [CrossRef]
- Hoeber, O.; Yang, X.D. Evaluating WordBars in Exploratory Web Search Scenarios. Inf. Process. Manag. 2008, 44, 485–510. [Google Scholar] [CrossRef]
- Hoeber, O.; Liu, H. Comparing Tag Clouds, Term Histograms, and Term Lists for Enhancing Personalized Web Search. In Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Los Alamitos, CA, USA, 31 August–3 September 2010. [Google Scholar] [CrossRef]
- Havre, S.; Hetzler, E.; Perrine, K.; Jurrus, E.; Miller, N. Interactive Visualization of Multiple Query Results. In Proceedings of the IEEE Symposium on Information Visualization 2001 (INFOVIS’01), Sacramento, CA, USA, 28 October–1 November 2007; IEEE Computer Society: Washington, DC, USA, 2001; p. 105. [Google Scholar]
- Klouche, K.; Ruotsalo, T.; Micallef, L.; Andolina, S.; Jacucci, G. Visual Re-Ranking for Multi-Aspect Information Retrieval. In Proceedings of the 2017 Conference on Conference Human Information Interaction and Retrieval, Oslo, Norway, 7–11 March 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 57–66. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.Y.; Strong, D.M. Beyond Accuracy: What Data Quality Means to Data Consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Taleb, I.; Serhani, M.A.; Dssouli, R. Big Data Quality: A Survey. In Proceedings of the 2018 IEEE International Congress on Big Data (BigData Congress), San Francisco, CA, USA, 2–7 July 2018; pp. 166–173. [Google Scholar] [CrossRef]
- Liu, S.; Andrienko, G.; Wu, Y.; Cao, N.; Jiang, L.; Shi, C.; Wang, Y.S.; Hong, S. Steering Data Quality with Visual Analytics: The Complexity Challenge. Vis. Inf. 2018, 2, 191–197. [Google Scholar] [CrossRef]
- Kandel, S.; Parikh, R.; Paepcke, A.; Hellerstein, J.M.; Heer, J. Profiler: Integrated Statistical Analysis and Visualization for Data Quality Assessment. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Capri Island, Italy, 21–25 May 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 547–554. [Google Scholar] [CrossRef]
- Bors, C.; Gschwandtner, T.; Miksch, S. Visually Exploring Data Provenance and Quality of Open Data. Posters 2018, 3. [Google Scholar] [CrossRef]
- Hitchcock, T. Confronting the Digital: Or How Academic History Writing Lost the Plot. Cult. Soc. Hist. 2013, 10, 9–23. [Google Scholar] [CrossRef]
- Hoekstra, R.; Koolen, M. Data Scopes for Digital History Research. Hist. Methods A J. Quant. Interdiscip. Hist. 2019, 52, 79–94. [Google Scholar] [CrossRef] [Green Version]
- Koolen, M.; van Gorp, J.; van Ossenbruggen, J. Toward a Model for Digital Tool Criticism: Reflection as Integrative Practice. Digit. Scholarsh. Humanit. 2019, 34, 368–385. [Google Scholar] [CrossRef] [Green Version]
- Bunout, E. Collections of Digitised Newspapers as Historical Sources—Parthenos Training. 2019. Available online: https://training.parthenos-project.eu/sample-page/digital-humanities-research-questions-and-methods/collections-of-digital-newspapers-as-historical-sources/ (accessed on 15 July 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Count |
|---|---|
| Newspaper titles | 76 |
| Newspaper issues | 600,919 |
| Pages | 5,429,656 |
| Content (articles, adverts, etc.) | 47,798,468 |
| Words | 12,493,358,703 |
| Linked named entities | 530,086 |
| Topics per language (fr, de, lu) | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Düring, M.; Kalyakin, R.; Bunout, E.; Guido, D. Impresso Inspect and Compare. Visual Comparison of Semantically Enriched Historical Newspaper Articles. Information 2021, 12, 348. https://doi.org/10.3390/info12090348
Düring M, Kalyakin R, Bunout E, Guido D. Impresso Inspect and Compare. Visual Comparison of Semantically Enriched Historical Newspaper Articles. Information. 2021; 12(9):348. https://doi.org/10.3390/info12090348
Chicago/Turabian StyleDüring, Marten, Roman Kalyakin, Estelle Bunout, and Daniele Guido. 2021. "Impresso Inspect and Compare. Visual Comparison of Semantically Enriched Historical Newspaper Articles" Information 12, no. 9: 348. https://doi.org/10.3390/info12090348
APA StyleDüring, M., Kalyakin, R., Bunout, E., & Guido, D. (2021). Impresso Inspect and Compare. Visual Comparison of Semantically Enriched Historical Newspaper Articles. Information, 12(9), 348. https://doi.org/10.3390/info12090348