
Building Knowledge Graphs and Recommender Systems for Suggesting Reskilling and Upskilling Options from the Web

 , , , and
, , , and
Abstract
:1. Introduction
- the adaptation of knowledge extraction methods to the human resources and continuing education domain;
- applying these methods to a complex industry-driven setting that requires robust methods capable of operating on content retrieved from a multitude of education providers for automatic knowledge graph construction;
- the creation of a continuing education knowledge graph that comprises 73,969 nodes and 734,447 edges;
- developing a knowledge-driven recommender system that draws upon this background knowledge to support users in identifying useful reskilling and upskilling options;
- evaluating the created systems based on a slot-filling benchmark and domain expert assessments.
2. Related Work
2.1. Knowledge Extraction and Knowledge Base Population
2.2. Slot Filling
2.3. Open Knowledge Extraction
2.4. Recommender Systems
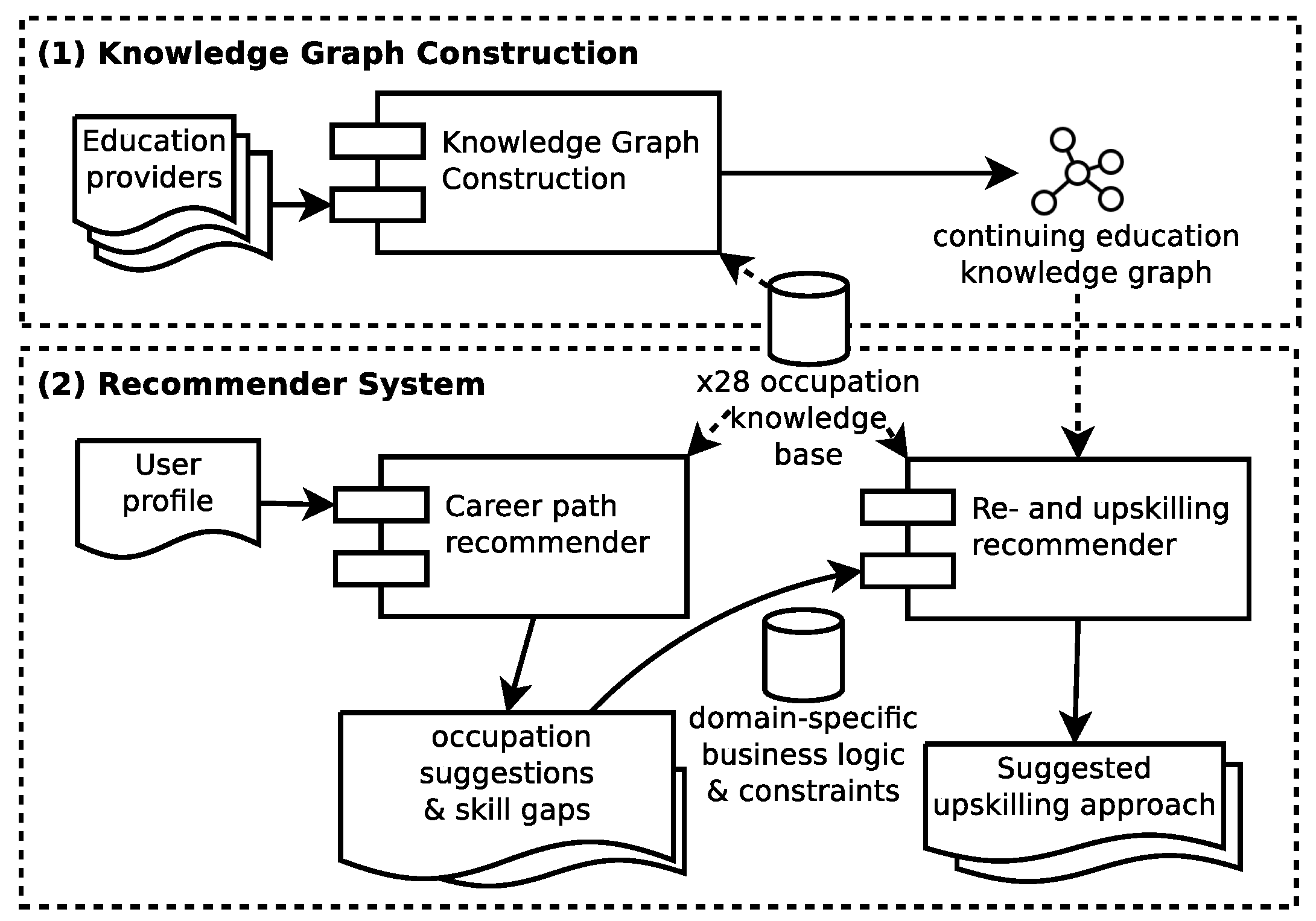
3. Method
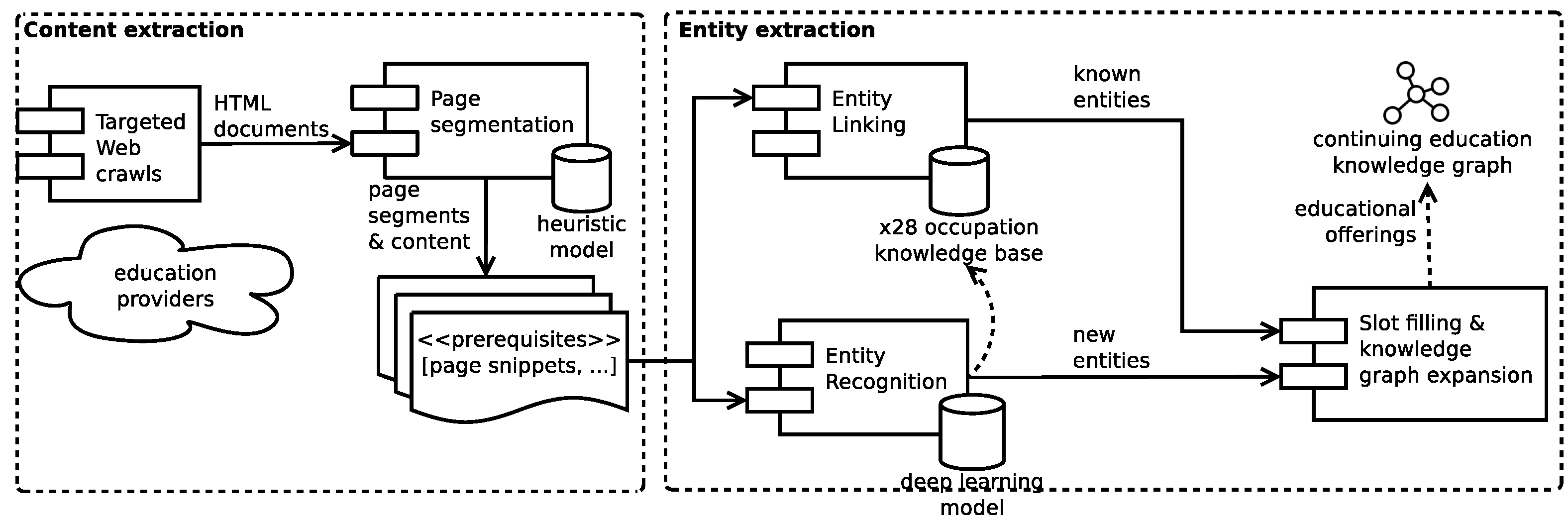
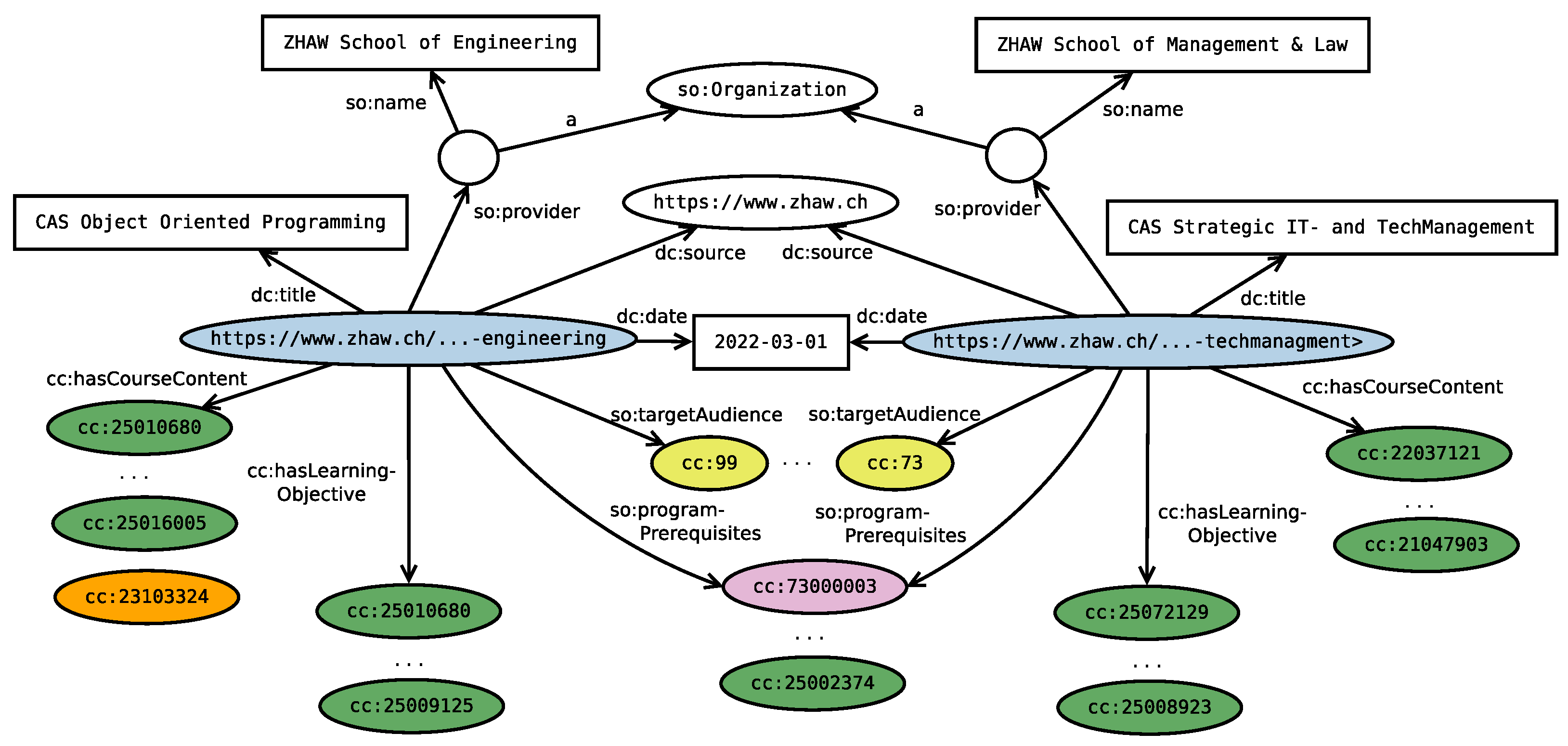
3.1. Knowledge Graph Construction from the Web
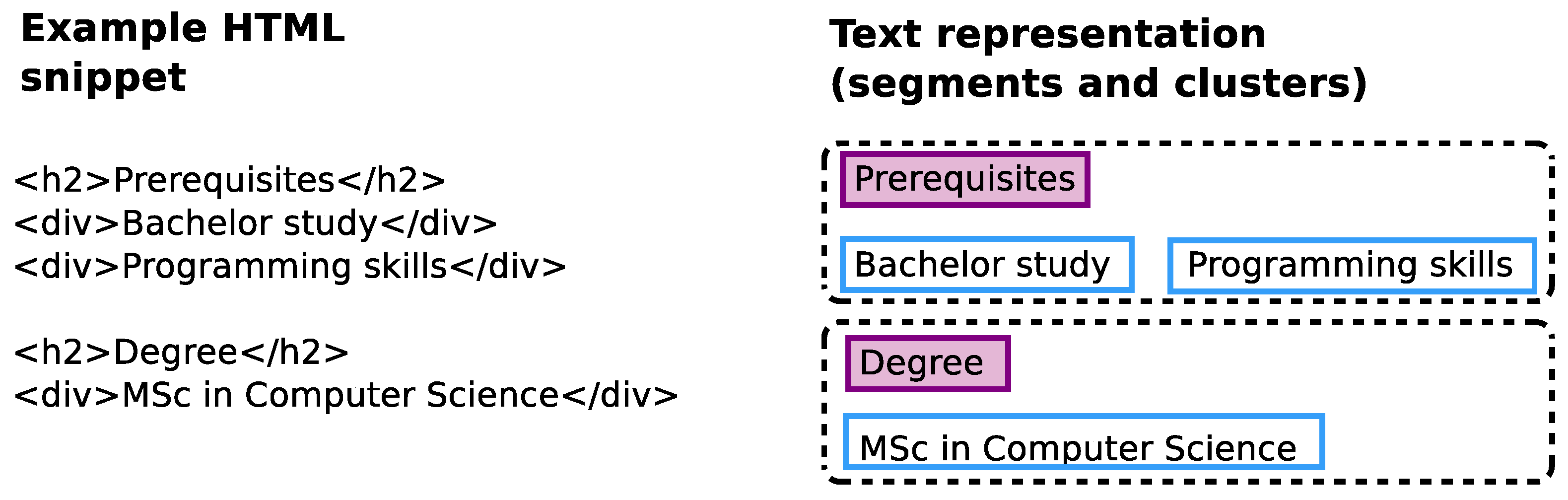
3.1.1. Page Segmentation
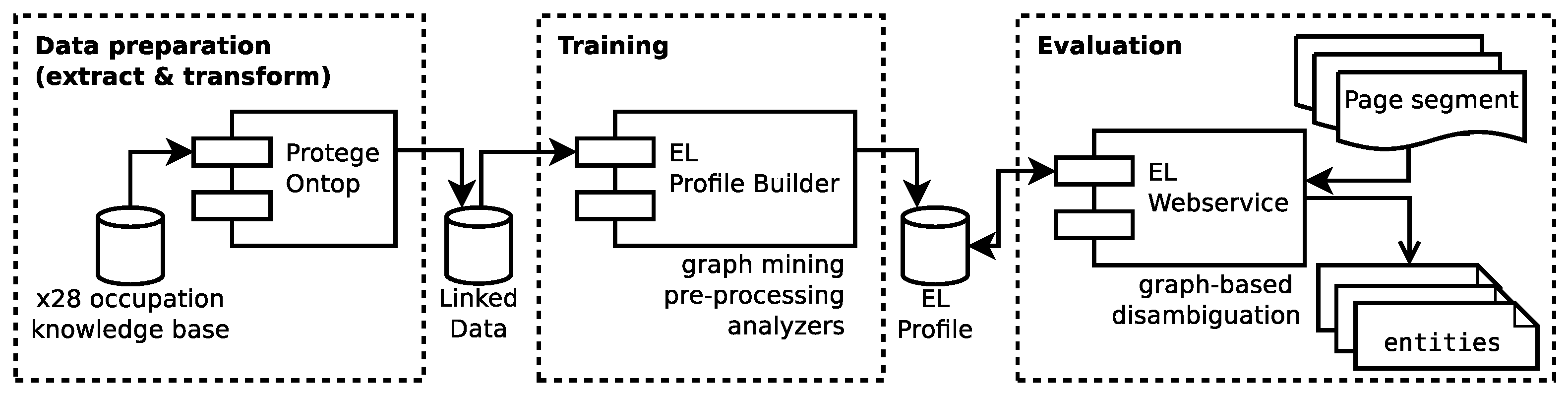
3.1.2. Entity Linking
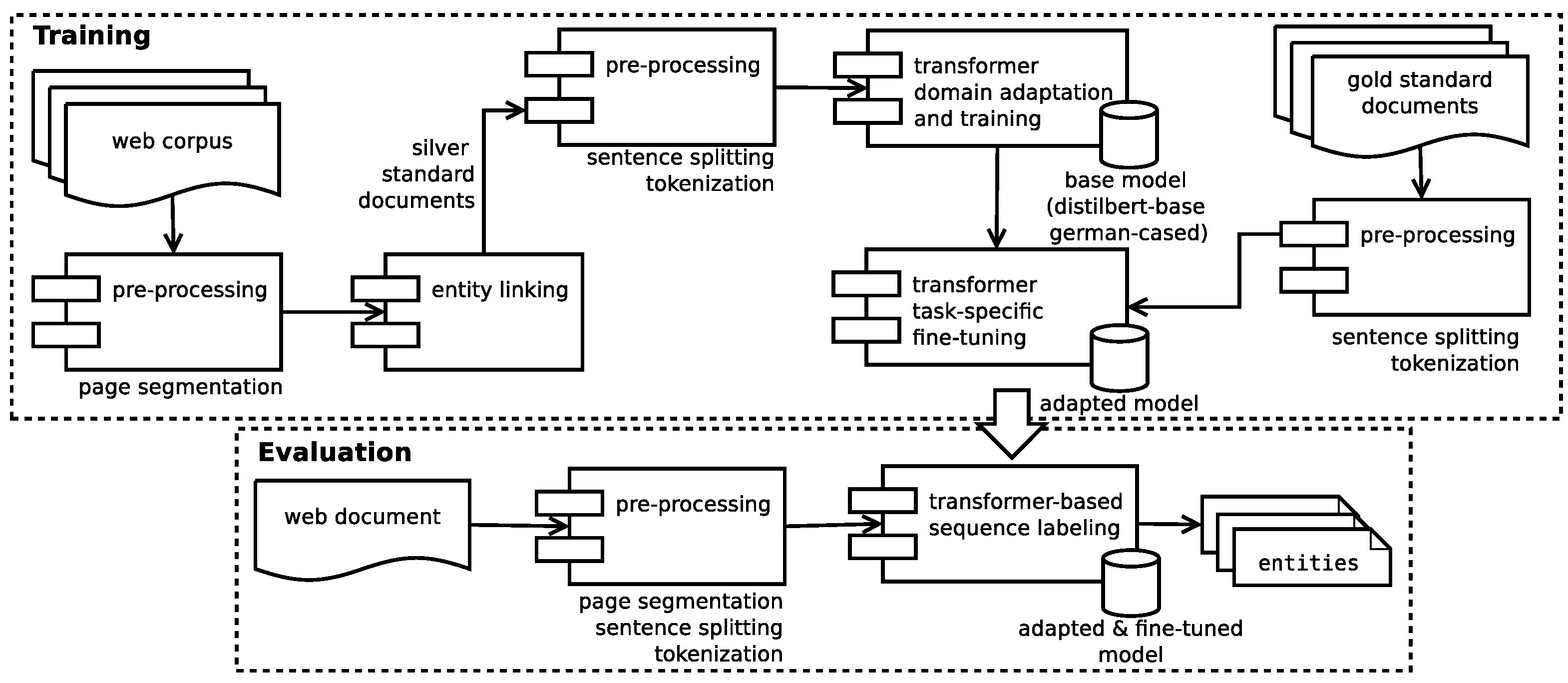
3.1.3. Entity recognition and Entity Classification
3.1.4. Knowledge Graph Expansion
- cc: project-specific CareerCoach namespace that is used for custom vocabulary (e.g., course content, learning objectives) and for referring to entities within the industry partner’s knowledge base
- dc: Dublin Core namespace used for the title, source, and date properties
- skos: Simple Knowledge Organization System namespace to indicate entities that haven’t been assigned to a slot with the skos:related property
- so: Schema.org namespace to describe educational programs (e.g., credits and degrees awarded, program prerequisites, and target audiences) and the organizations offering these programs
3.2. Knowledge-Driven Recommender System
3.2.1. Background Knowledge
- queries the occupation knowledge base for all skills required for the given target occupation; the query also considers hierarchical relations between skills (e.g., the skill “Java programming” will automatically imply “Programming”);
- returns the number of occupations that require skill from the occupation knowledge base; and
- uses the continuing education graph to determine whether the given provides skill , considering hierarchical relations between skills specified in the occupation knowledge base.
3.2.2. Business Logic and Constraints
- job similarity, which considers work activities, necessary knowledge (e.g., completed educations), skills (i.e., cross-functional and specialized skills), abilities (e.g., physical and cognitive capabilities), and expertise (education, years of work experience in the job or job family)
- similar job zones (i.e., expected level of education)
- stable long-term prospects (i.e., demand for the occupation is not declining)
- wage continuity or increase
- prefer similar jobs over less similar ones, since they require lower reskilling or upskilling efforts
- the suggested jobs should expect a similar level of education (i.e., do not suggest paths that would require significant additional education or would devaluate past educations)
- provides optional filters and ranking rules that consider a user’s preferences regarding wage continuity or increase, expected long-term prospects, and geography (i.e., availability of suitable positions in a particular region)
3.2.3. Knowledge-Driven Occupation Recommendations
3.2.4. Knowledge-Driven Continuing Education Recommendations
4. Evaluation
- The evaluation of the knowledge extraction and knowledge graph population components uses the CareerCoach 2022 gold standard which has been introduced at the 27th International Conference on Natural Language & Information Systems (NLDB 2022) [57] (Section 4.1);
- The career path recommender is evaluated based on a gold standard of expert recommendations (Section 4.2). Afterward, experts assess the usefulness of the provided continuing education recommendations (Section 4.3).
4.1. Knowledge Graph Population
4.1.1. Gold Standard
4.1.2. Content Extraction
- T1: page segment recognition—locates page segments within HTML pages and extracts the text string from these segments.
- T2: page segment classification—assigns each extracted text segment to a class . The page segment classification considers the classes ‘target_groups’, ‘prerequisites’, ‘learning_objectives’, ‘course_contents’, and ‘degrees & certificates’.
4.1.3. Entity Extraction
- T3: entity recognition—locates mentions of entities within text segments.
- T4: entity classification—assigns each mention to the corresponding entity type
- T5: entity linking—links mentions to the appropriate entity in the knowledge graph . Entities that are not yet available in the knowledge graph are handled as NIL entities (i.e., they are assigned a temporary identifier that is unique for all mentions which refer to the same entity).
4.1.4. Slot Filling
4.1.5. Experiments and Discussion
4.1.6. Automatic Knowledge Graph Population
4.2. Career Path Recommender
4.2.1. Gold Standard
- similarity between the current occupation and the suggested target job, and
- availability of shortened reskilling and upskilling programs for a given job pair.
- employees with no formal vocational education that work in occupations requiring little training (office assistant, production employee)
- employees working in a skilled craft or trade (painter, electrician)
- highly-skilled employees in occupations that require a university degree (junior business analyst, commercial computer scientist)
4.2.2. Evaluation Metrics and Results
- The recommender works well if closely related target occupations exist. An office assistant, for example, shares many skills with management assistants, office managers, and commercial employees, which makes all three professions suitable career paths. The same is true for the painter, which yields a plasterer as an alternative. Again, these two occupations are highly related and, therefore, share a considerable amount of skills.
- If direct reskilling paths are not available, the recommendations become much more difficult, which is also illustrated in a lower agreement between the domain experts (column “avg. experts” in Table 7). Consequently, suggesting career pathways for an electrician and production employee is a considerably harder task, which yields even significant disagreement among experts.
- A notable exception to these observations is the commercial computer specialist, for whom a lot of useful alternatives have been proposed. The low score for this use case has been caused by the different rankings produced by experts and the system. Nevertheless, the experts also considered the system’s three target occupations useful career suggestions.
4.3. Continuing Education Recommender
4.3.1. Limitations
- the perceived value of education options differed considerably between experts, which made it infeasible to provide a consolidated ranking;
- some suggested career paths do not necessarily require any further education (e.g., the promotion from an office assistant to an office manager); and
- a considerable number of career paths are not yet covered in the continuing education knowledge graph so no useful recommendations could be found. As outlined in Section 3.1, the knowledge graph population component draws upon the offerings of a curated list of education providers. Consequently, its recall is fairly well for formal education (e.g., studies and post-graduate courses), and popular continuing education topics (e.g., languages, computer skills, etc.). Apprenticeships, in contrast, are rarely covered, since they are typically offered by companies and trades rather than educational institutions. Future work will address this issue, by integrating knowledge from apprentice position directories.
4.3.2. Evaluation Metrics and Results
- benefit, i.e., whether the suggested education facilitates working in the aspired target occupation (e.g., by providing required skills); and
- sufficiency which requires the experts to judge whether candidates will be able to work in the target occupation once they complete the proposed education.
5. Discussion
- a knowledge graph construction method used for creating a real-time continuing education knowledge graph that summarizes knowledge extracted from education provider websites; and
- a recommender system that draws upon an occupation knowledge base and the extracted knowledge on continuing education for suggesting career paths and education facilitating them.
- suggesting education is a challenging task and even experts struggle with providing consistent recommendations. Future work will mitigate this issue by developing strategies for edge cases such as education that only covers parts of the relevant skills.
- one of the system’s biggest strengths, the availability of real-time information on online courses and educational offerings that have been directly obtained from the provider’s websites, also became its major weakness, since education that has not been covered in the input sources are not considered. In Switzerland, crafts, and trades, for example, are taught through apprenticeships. Consequently, the coverage of continuing education for crafts and trades has been insufficient within the continuing education ontology forcing us to remove a total of eight career paths from the evaluation. In addition, the career path to SAP business analyst had to be discarded, since no suitable education had been available in the knowledge graph.
- the system does not yet consider the efforts required for completing further education. Consequently, it preferred more comprehensive education over quicker ones. Edge cases demonstrating this problem have been career paths where on-the-job experience could have been sufficient for advancing to a more prestigious occupation (e.g., from office assistant to office manager). Although all the system’s recommendations have been suitable and would have been beneficial towards a possible promotion, domain experts did not see a requirement for further education.
6. Outlook and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Daiber, J.; Jakob, M.; Hokamp, C.; Mendes, P.N. Improving Efficiency and Accuracy in Multilingual Entity Extraction. In Proceedings of the 9th International Conference on Semantic Systems, I-SEMANTICS ’13, Graz, Austria, 4–6 September 2013; ACM: New York, NY, USA, 2013; pp. 121–124. [Google Scholar] [CrossRef]
- Weichselbraun, A.; Kuntschik, P.; Brasoveanu, A.M. Name Variants for Improving Entity Discovery and Linking. In Proceedings of the Second Conference on Language, Data and Knowledge (LDK 2019), Leipzig, Germany, 20–23 May 2019; OpenAccess Series in Informatics: Leipzig, Germany, 2019; Volume 70, pp. 14:1–14:15. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; de Melo, G.; Gutierrez, C.; Gayo, J.E.L.; Kirrane, S.; Neumaier, S.; Polleres, A.; et al. Knowledge Graphs. ACM Comput. Surv. 2022, 54, 1–37. [Google Scholar] [CrossRef]
- World Economic Forum-Centre for the New Economy and Society. The Future of Jobs Report 2020; Technical report; World Economic Forum-Centre for the New Economy and Society: Davos, Switzerland, 2020. [Google Scholar]
- Noy, N.; Gao, Y.; Jain, A.; Narayanan, A.; Patterson, A.; Taylor, J. Industry-scale Knowledge Graphs: Lessons and Challenges. Commun. ACM 2019, 62, 36–43. [Google Scholar] [CrossRef] [Green Version]
- Bizer, C.; Lehmann, J.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. DBpedia—A crystallization point for the Web of Data. J. Web Semant. Sci. Serv. Agents World Wide Web 2009, 7, 154–165. [Google Scholar] [CrossRef]
- Vrandečić, D.; Krötzsch, M. Wikidata: A Free Collaborative Knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef] [Green Version]
- Lin, X.; Chen, L. Canonicalization of Open Knowledge Bases with Side Information from the Source Text. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 950–961. [Google Scholar] [CrossRef]
- Dubey, M.; Banerjee, D.; Abdelkawi, A.; Lehmann, J. LC-QuAD 2.0: A Large Dataset for Complex Question Answering over Wikidata and DBpedia. In Proceedings of the The Semantic Web—ISWC 2019, Auckland, New Zealand, 26–30 October 2019; Ghidini, C., Hartig, O., Maleshkova, M., Svátek, V., Cruz, I., Hogan, A., Song, J., Lefrançois, M., Gandon, F., Eds.; Lecture Notes in Computer Science. Springer International Publishing: Cham, Switzerland, 2019; pp. 69–78. [Google Scholar] [CrossRef]
- Usbeck, R.; Ngomo, A.C.N.; Haarmann, B.; Krithara, A.; Röder, M.; Napolitano, G. 7th Open Challenge on Question Answering over Linked Data (QALD-7). In Proceedings of the Semantic Web Challenges, Portoroz, Slovenia, 28 May–1 June 2017; Communications in Computer and Information Science. Dragoni, M., Solanki, M., Blomqvist, E., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 59–69. [Google Scholar] [CrossRef]
- Elsahar, H.; Vougiouklis, P.; Remaci, A.; Gravier, C.; Hare, J.; Laforest, F.; Simperl, E. T-REx: A Large Scale Alignment of Natural Language with Knowledge Base Triples. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; European Language Resources Association (ELRA): Miyazaki, Japan, 2018. [Google Scholar]
- Glass, M.; Gliozzo, A. A Dataset for Web-Scale Knowledge Base Population. In Proceedings of the The Semantic Web, Heraklion, Greece, 3–7 June 2018; Lecture Notes in Computer Science. Gangemi, A., Navigli, R., Vidal, M.E., Hitzler, P., Troncy, R., Hollink, L., Tordai, A., Alam, M., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 256–271. [Google Scholar] [CrossRef]
- Mesquita, F.; Cannaviccio, M.; Schmidek, J.; Mirza, P.; Barbosa, D. KnowledgeNet: A Benchmark Dataset for Knowledge Base Population. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 749–758. [Google Scholar] [CrossRef] [Green Version]
- Lin, X.; Li, H.; Xin, H.; Li, Z.; Chen, L. KBPearl: A knowledge base population system supported by joint entity and relation linking. Proc. Vldb Endow. 2020, 13, 1035–1049. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. In IEEE Transactions on Knowledge & Data Engineering; IEEE Computer Society: Los Alamitos, CA, USA, 2020; pp. 50–70. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Huang, X.; Liu, P. SpanNER: Named Entity Re-/Recognition as Span Prediction. arXiv 2021, arXiv:2106.00641. [Google Scholar]
- Yosef, M.A.; Hoffart, J.; Bordino, I.; Spaniol, M.; Weikum, G. AIDA: An Online Tool for Accurate Disambiguation of Named Entities in Text and Tables. PVLDB 2011, 4, 1450–1453. [Google Scholar] [CrossRef]
- Guo, Y.; Che, W.; Liu, T.; Li, S. A Graph-based Method for Entity Linking. In Proceedings of the 5th International Joint Conference on Natural Language Processing, Chiang Mai, Thailand, 9–11 November 2011; Asian Federation of Natural Language Processing: Chiang Mai, Thailand, 2011; pp. 1010–1018. [Google Scholar]
- Moro, A.; Raganato, A.; Navigli, R. Entity Linking meets Word Sense Disambiguation: A Unified Approach. Trans. Assoc. Comput. Linguist. 2014, 2, 231–244. [Google Scholar] [CrossRef]
- Usbeck, R.; Ngonga Ngomo, A.C.; Röder, M.; Gerber, D.; Coelho, S.; Auer, S.; Both, A. AGDISTIS - Graph-Based Disambiguation of Named Entities Using Linked Data. In Proceedings of the Semantic Web—ISWC 2014, Riva del Garda, Italy, 19–23 October 2014; Lecture Notes in Computer Science. Springer International Publishing: Cham, Switzerland, 2014; Volume 8796, pp. 457–471. [Google Scholar]
- Moussallem, D.; Usbeck, R.; Röder, M.; Ngomo, A.C.N. MAG: A Multilingual, Knowledge-base Agnostic and Deterministic Entity Linking Approach. In Proceedings of the Knowledge Capture Conference on—K-CAP 2017, Austin, TX, USA, 4–6 December 2017; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Cao, Y.; Hou, L.; Li, J.; Liu, Z. Neural Collective Entity Linking. arXiv 2018, arXiv:1811.08603. [Google Scholar]
- Wu, J.; Zhang, R.; Mao, Y.; Guo, H.; Soflaei, M.; Huai, J. Dynamic Graph Convolutional Networks for Entity Linking. In Proceedings of the Web Conference, WWW ’20, Taipei, Taiwan, 20–24 April 2020; Association for Computing Machinery: Taipei, Taiwan, 2020; pp. 1149–1159. [Google Scholar] [CrossRef]
- Ding, W.; Chaudhri, V.K.; Chittar, N.; Konakanchi, K. JEL: Applying End-to-End Neural Entity Linking in JPMorgan Chase. Proc. Aaai Conf. Artif. Intell. 2021, 35, 15301–15308. [Google Scholar] [CrossRef]
- Lim, S.; Kwon, S.; Lee, S.; Choi, J. UNIST SAIL System for TAC 2017 Cold Start Slot Filling. In Proceedings of the Text Analysis Conference TAC 2017, Gaithersburg, MD, USA, 13–14 November 2017. [Google Scholar]
- Roth, B.; Barth, T.; Wiegand, M.; Singh, M.; Klakow, D. Effective Slot Filling Based on Shallow Distant Supervision Methods. arXiv 2014, arXiv:1401.1158. [Google Scholar]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Exploring High-Order User Preference on the Knowledge Graph for Recommender Systems. ACM Trans. Inf. Syst. 2019, 37, 32:1–32:26. [Google Scholar] [CrossRef]
- Ritze, D.; Lehmberg, O.; Oulabi, Y.; Bizer, C. Profiling the Potential of Web Tables for Augmenting Cross-domain Knowledge Bases. In Proceedings of the 25th International Conference on World Wide Web, WWW ’16, Montréal, QC, Canada, 11–15 April 2016; International World Wide Web Conferences Steering Committee: Montréal, QC, Canada, 2016; pp. 251–261. [Google Scholar] [CrossRef]
- Siddique, A.; Jamour, F.; Hristidis, V. Linguistically-Enriched and Context-AwareZero-shot Slot Filling. In Proceedings of the Web Conference, WWW ’21, 2021, Virtual Event/Ljubljana, Slovenia, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3279–3290. [Google Scholar] [CrossRef]
- Coucke, A.; Saade, A.; Ball, A.; Bluche, T.; Caulier, A.; Leroy, D.; Doumouro, C.; Gisselbrecht, T.; Caltagirone, F.; Lavril, T.; et al. Snips Voice Platform: An embedded Spoken Language Understanding system for private-by-design voice interfaces. arXiv 2018, arXiv:1805.10190. [Google Scholar]
- Liu, X.; Eshghi, A.; Swietojanski, P.; Rieser, V. Benchmarking natural language understanding services for building conversational agents. In Increasing Naturalness and Flexibility in Spoken Dialogue Interaction; Marchi, E., Siniscalchi, S.M., Cumani, S., Salerno, V.M., Li, H., Eds.; Springer: Singapore, 2021. [Google Scholar] [CrossRef]
- Zang, X.; Rastogi, A.; Sunkara, S.; Gupta, R.; Zhang, J.; Chen, J. MultiWOZ 2.2: A Dialogue Dataset with Additional Annotation Corrections and State Tracking Baselines. In Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI, Online, 9 July 2020; Association for Computational Linguistics: Florence, Italy, 2020; pp. 109–117. [Google Scholar] [CrossRef]
- Rastogi, A.; Zang, X.; Sunkara, S.; Gupta, R.; Khaitan, P. Towards Scalable Multi-domain Conversational Agents: The Schema-Guided Dialogue Dataset. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8689–8696. [Google Scholar]
- Liu, Z.; Winata, G.I.; Xu, P.; Fung, P. Coach: A Coarse-to-Fine Approach for Cross-domain Slot Filling. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Florence, Italy, 2020; pp. 19–25. [Google Scholar] [CrossRef]
- Shah, D.; Gupta, R.; Fayazi, A.; Hakkani-Tur, D. Robust Zero-Shot Cross-Domain Slot Filling with Example Values. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 5484–5490. [Google Scholar] [CrossRef]
- Bapna, A.; Tur, G.; Hakkani-Tur, D.; Heck, L. Towards zero-shot frame semantic parsing for domain scaling. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 2476–2480. [Google Scholar] [CrossRef] [Green Version]
- Cerezo-Costas, H.; Martín-Vicente, M. Relation Extraction for Knowledge Base Completion: A Supervised Approach. In Proceedings of the Semantic Web Challenges, Heraklion, Greece, 3–7 June 2018; Communications in Computer and Information, Science. Buscaldi, D., Gangemi, A., Reforgiato Recupero, D., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 52–66. [Google Scholar] [CrossRef]
- Chabchoub, M.; Gagnon, M.; Zouaq, A. Collective Disambiguation and Semantic Annotation for Entity Linking and Typing. In Proceedings of the Semantic Web Challenges, Heraklion, Greece, 29 May–2 June 2016; Communications in Computer and Information Science. Sack, H., Dietze, S., Tordai, A., Lange, C., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 33–47. [Google Scholar] [CrossRef]
- Sakor, A.; Onando Mulang’, I.; Singh, K.; Shekarpour, S.; Esther Vidal, M.; Lehmann, J.; Auer, S. Old is Gold: Linguistic Driven Approach for Entity and Relation Linking of Short Text. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 2336–2346. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep Learning Based Recommender System: A Survey and New Perspectives. ACM Comput. Surv. 2019, 52, 5. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Hu, B.; Shi, C.; Zhao, W.X.; Yu, P.S. Leveraging Meta-path based Context for Top- N Recommendation with A Neural Co-Attention Model. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD’18, London, UK, 19–23 August 2018; Association for Computing Machinery: London, UK, 2018; pp. 1531–1540. [Google Scholar] [CrossRef]
- Yu, X.; Ren, X.; Sun, Y.; Gu, Q.; Sturt, B.; Khandelwal, U.; Norick, B.; Han, J. Personalized entity recommendation: A heterogeneous information network approach. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, WSDM ’14, New York, NY, USA, 24–28 February 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 283–292. [Google Scholar] [CrossRef]
- Zhao, H.; Yao, Q.; Li, J.; Song, Y.; Lee, D.L. Meta-Graph Based Recommendation Fusion over Heterogeneous Information Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’17, Halifax, Canada, 13–17 August 2017; Association for Computing Machinery: Halifax, NS, Canada, 2017; pp. 635–644. [Google Scholar] [CrossRef]
- Huang, J.; Zhao, W.X.; Dou, H.; Wen, J.R.; Chang, E.Y. Improving Sequential Recommendation with Knowledge-Enhanced Memory Networks. In Proceedings of the The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR ’18, Ann Arbor, MI, USA, 8–12 July 2018; Association for Computing Machinery: Ann Arbor, MI, USA, 2018; pp. 505–514. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation. In Proceedings of the The World Wide Web Conference, WWW ’19, San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: San Francisco, CA, USA, 2019; pp. 2000–2010. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep Knowledge-Aware Network for News Recommendation. In Proceedings of the 2018 World Wide Web Conference, WWW ’18, Lyon, France, 23–27 April 2018; International World Wide Web Conferences Steering Committee: Lyon, France, 2018; pp. 1835–1844. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative Knowledge Base Embedding for Recommender Systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: San Francisco, CA, USA, 2016; pp. 353–362. [Google Scholar] [CrossRef]
- Sun, Z.; Yang, J.; Zhang, J.; Bozzon, A.; Huang, L.K.; Xu, C. Recurrent knowledge graph embedding for effective recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems, RecSys ’18, Vancouver, Canada, 2–7 October 2018; Association for Computing Machinery: Vancouver, BC, Canada, 2018; pp. 297–305. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, CIKM ’18, Torino, Italy, 22–26 October 2018; Association for Computing Machinery: Torino, Italy, 2018; pp. 417–426. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge Graph Convolutional Networks for Recommender Systems. In Proceedings of the The World Wide Web Conference, WWW ’19, San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: San Francisco, CA, USA, 2019; pp. 3307–3313. [Google Scholar] [CrossRef] [Green Version]
- Turhan, A.Y.; Bechhofer, S.; Kaplunova, A.; Liebig, T.; Luther, M.; Möller, R.; Noppens, O.; Patel-Schneider, P.; Suntisrivaraporn, B.; Weithöner, T. DIG 2.0—Towards a Flexible Interface for Description Logic Reasoners. In Proceedings of the CEUR Workshop on OWL: Experiences and Directions, Athens, GA, USA, 10–11 November 2006; RWTH Aachen University: Aachen, Germany, 2006. [Google Scholar]
- Weichselbraun, A.; Kuntschik, P.; Brasoveanu, A.M.P. Mining and Leveraging Background Knowledge for Improving Named Entity Linking. In Proceedings of the 8th International Conference on Web Intelligence, Mining and Semantics, WIMS 2018, Novi Sad, Serbia, 25–27 June 2018. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics: Florence, Italy, 2020; pp. 38–45. [Google Scholar]
- World Economic Forum—Centre for the New Economy and Society. Towards a Reskilling Revolution; Technical Report; World Economic Forum-Centre for the New Economy and Society: Davos, Switzerland, 2018. [Google Scholar]
- World Economic Forum. Towards a Reskilling Revolution: Industry-Led Action for the Future of Work; Technical Report; World Economic Forum: Cologny, Switzerland, 2019. [Google Scholar]
- Weichselbraun, A.; Waldvogel, R.; Fraefel, A.; van Schie, A.; Kuntschik, P. Slot Filling for Extracting Reskilling and Upskilling Options from the Web. In Proceedings of the 27th International Conference on Natural Language & Information Systems, Valencia, Spain, 15–17 June 2022. [Google Scholar]
- Inglin, M. Re- Und Upskilling-Empfehlung: Kriterien Für Die Automatische Auswahl von Re- Und Upskilling-Angeboten. Bachelor Thesis, University of Applied Sciences of the Grisons, Chur, Switzerland, 2022. [Google Scholar]
- Heß, P.; Janssen, S.; Leber, U. Digitalisierung Und Berufliche Weiterbildung: Beschäftigte, Deren Tätigkeiten Durch Technologien Ersetzbar Sind, Bilden Sich Seltener Weiter; Institut Für Arbeitsmarkt- Und Berufsforschung (IAB) 16/2019: Nürnberg, Germany, 2019. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Slot | (Entity) Type (min, max) | Cardinality |
|---|---|---|
| title | title extracted from the page metadata | (1, 1) |
| school | school | (1, 1) |
| target group | degree, education, occupation, position, industry, topic | (0, *) |
| prerequisite | degree, education, occupation, position, skill, topic | (0, *) |
| learning objective | occupation, skill, topic | (1, *) |
| course content | skill, topic | (1, *) |
| certificates | degree, education | (0, *) |
| Parameter | Value |
|---|---|
| Solver (learning rate) | Adam (5 × 10) |
| Activation | Gaussian Error Linear Unit (GELU) |
| Base model | distilbert-base-german-cased |
| Attention dropout | 0.1 |
| Dimension | 768 |
| Dropout | 0.1 |
| Hidden layer dimensions | 3072 |
| Initializer range | 0.02 |
| Max position embeddings | 512 |
| N heads (N layers) | 12 (6) |
| Qa dropout | 0.1 |
| Seq classification dropout | 0.2 |
| Slot | RDF Property |
|---|---|
| title | dc:title |
| school | so:provider |
| target grop | so:targetAudience |
| prerequisite | so:programPrerequisites |
| learning objectives | cc:hasLearningObjective |
| course content | cc:hasCourseContent |
| certificates | so:educationalCredentialAwarded |
| Component | Evaluation Metrics | Objective |
|---|---|---|
| Page segment recognition | P, R, F1 | evaluate content extraction |
| Page segment classification | P, R, F1 | |
| Entity Recognition | P, R, F1 | evaluate entity extraction |
| Entity Classification | P, R, F1 | |
| Entity Linking | P, R, F1 | |
| Slot filling | P, R, F1 | evaluate overall slot filling process |
| Component | Evaluation Metrics | Objective |
|---|---|---|
| career path recommender | P@3, MAP@3 | evaluate feasibility and beneficialness of the suggested career paths |
| continuing education recommender | Pb@3, Ps@3 | evaluate usefulness of the suggested educations |
| Component | P | R | F1 |
|---|---|---|---|
| T1: page segment recognition | 0.82 | 0.84 | 0.83 |
| T2: page segment classification | 0.82 | 0.84 | 0.83 |
| T3: entity recognition | 0.82 | 0.66 | 0.73 |
| T4: entity classification | 0.78 | 0.63 | 0.70 |
| T5: entity linking (strict) | 0.67 | 0.80 | 0.73 |
| T5: entity linking (relaxed) | 0.67 | 0.82 | 0.74 |
| T6: slot filling (strict) | 0.48 | 0.60 | 0.54 |
| T6: slot filling (relaxed) | 0.50 | 0.62 | 0.55 |
| System | avg. Experts | ||||
|---|---|---|---|---|---|
| Prior Education | Occupation | MAP(3) | P@3 | MAP(3) | P@3 |
| no formal education | office assistant | 1.00 | 1.00 | 1.00 | 1.00 |
| production employee | 0.28 | 0.33 | 0.87 | 0.78 | |
| craft or trade | electrician | 0.28 | 0.33 | 0.83 | 0.67 |
| painter | 0.61 | 0.33 | 1.00 | 1.00 | |
| university degree | junior business analyst | 0.89 | 0.67 | 1.00 | 1.00 |
| commercial computer scientist | 0.28 | 0.33 | 1.00 | 1.00 | |
| Occupation | System | ||
|---|---|---|---|
| Start | Target | P@3 | P@3 |
| office assistant | assistant to the manager | 0.33 | 1.00 |
| office manager | 0.33 | 1.00 | |
| production employee | warehouse clerk | 0.67 | 0.00 |
| logistician | 0.67 | 0.33 | |
| production specialist | 1.00 | 0.67 | |
| junior business analyst | business analyst | 0.67 | 1.00 |
| business analysis manager | 0.67 | 1.00 | |
| commercial computer scientist | application integrator | 0.33 | 1.00 |
| data architect | 0.33 | 0.33 | |
| IT business analyst | 0.00 | 1.00 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weichselbraun, A.; Waldvogel, R.; Fraefel, A.; van Schie, A.; Kuntschik, P. Building Knowledge Graphs and Recommender Systems for Suggesting Reskilling and Upskilling Options from the Web. Information 2022, 13, 510. https://doi.org/10.3390/info13110510
Weichselbraun A, Waldvogel R, Fraefel A, van Schie A, Kuntschik P. Building Knowledge Graphs and Recommender Systems for Suggesting Reskilling and Upskilling Options from the Web. Information. 2022; 13(11):510. https://doi.org/10.3390/info13110510
Chicago/Turabian StyleWeichselbraun, Albert, Roger Waldvogel, Andreas Fraefel, Alexander van Schie, and Philipp Kuntschik. 2022. "Building Knowledge Graphs and Recommender Systems for Suggesting Reskilling and Upskilling Options from the Web" Information 13, no. 11: 510. https://doi.org/10.3390/info13110510
APA StyleWeichselbraun, A., Waldvogel, R., Fraefel, A., van Schie, A., & Kuntschik, P. (2022). Building Knowledge Graphs and Recommender Systems for Suggesting Reskilling and Upskilling Options from the Web. Information, 13(11), 510. https://doi.org/10.3390/info13110510