
Reliability Assurance Dynamic SSC Placement Using Reinforcement Learning

 ,
,
Abstract
:1. Introduction
- (1)
- We take the strict delay constraints of security services and the high failure probability of VSFs into account, and propose the LARA algorithm for an SSC orchestration problem with low latency and high reliability demands.
- (2)
- We apply AI algorithms to the SSC placement problem and use an RL-based Q-learning algorithm. This speeds up the security service response by reducing the end-to-end delay of the SSC. The end-to-end delay of an SSC defined in this paper includes the VSF processing delay on the substrate node and the transmission delay on the substrate link.
- (3)
- In the VSF backup phase, we quantify the node importance of VSF and minimize the backup resource overhead on the basis of ensuring the reliability of the SSC.
- (4)
- We compare the LARA algorithm with three classical algorithms. The simulation results show that the proposed LARA algorithm has a better performance in end-to-end delay and reliability assurance.
2. Related Work
2.1. Delay-Aware SFC Orchestration
2.2. Reliability Assurance SFC Orchestration
- Deficiencies in intelligent resource scheduling in dynamic scenarios;
- At present, there is little research on SSC, and there is no joint consideration of the impact of end-to-end delay and reliability on the quality of security services.
3. System Model
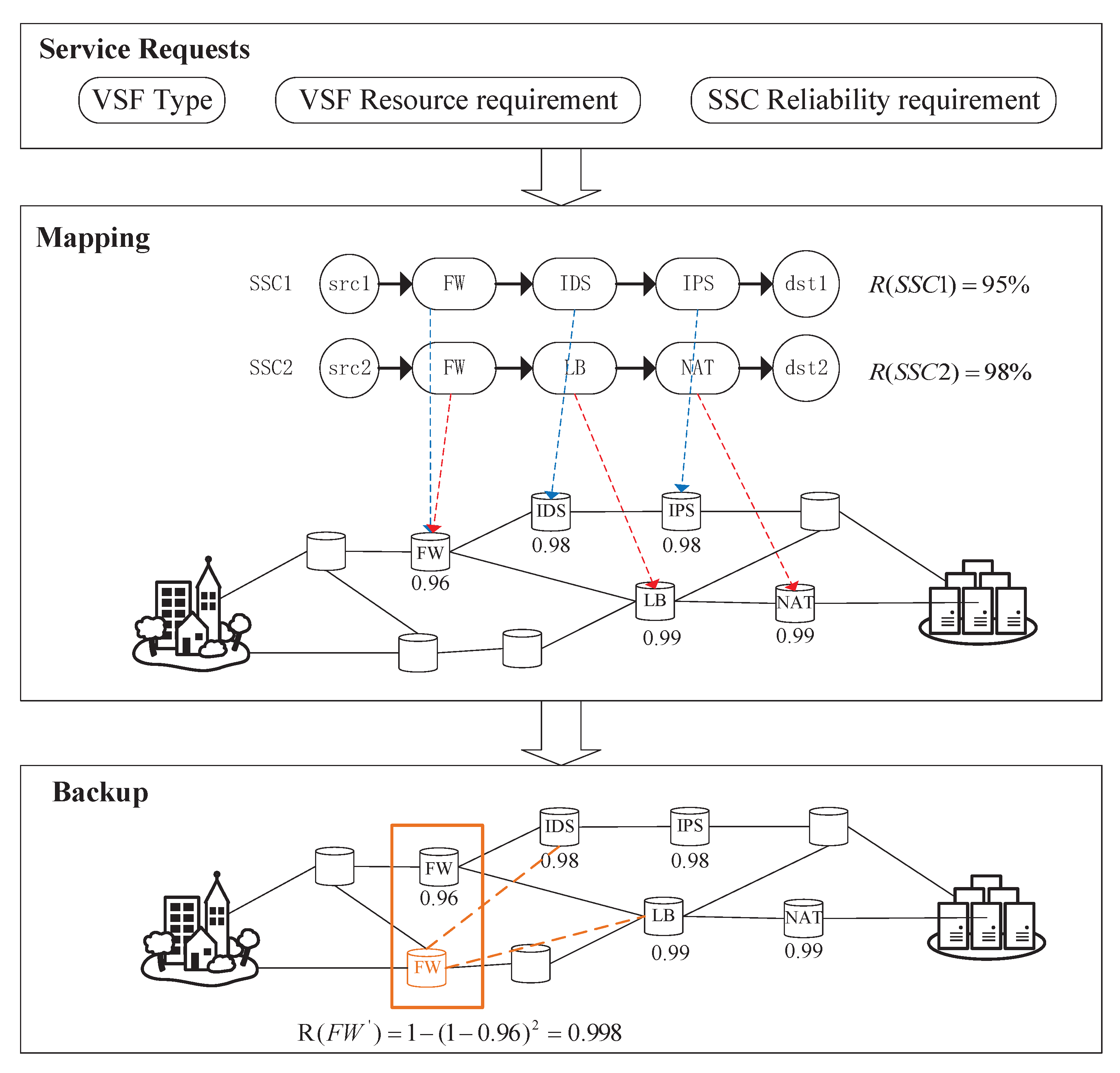
3.1. Problem Description
3.2. Network Model
3.2.1. Substrate Network
3.2.2. SSC Request
3.3. Modeling
3.3.1. SSC Orchestration
3.3.2. VSF Backup
4. Algorithm Description
4.1. Algorithm Introduction
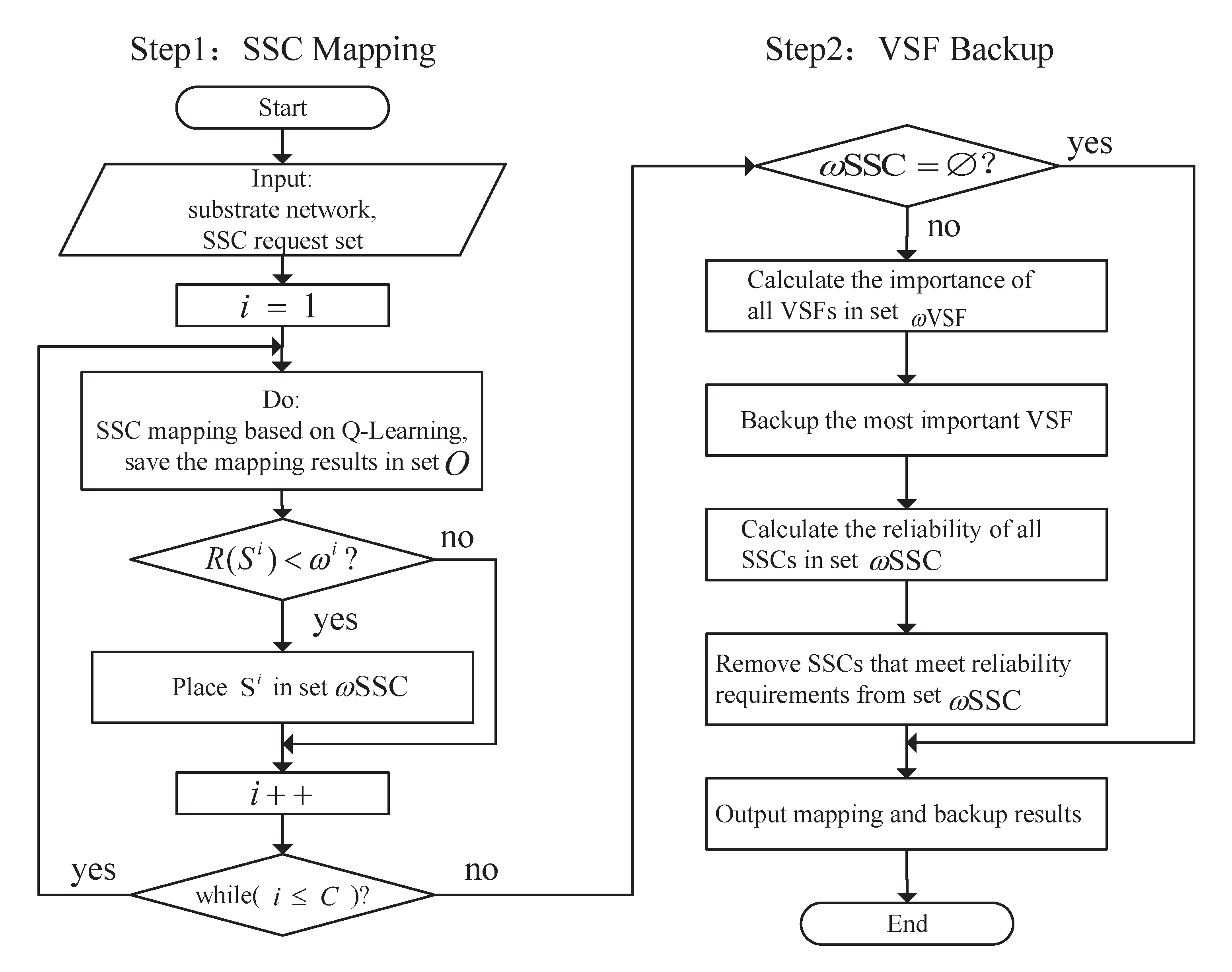
4.2. SSC Mapping Based on Q-Learning Algorithm
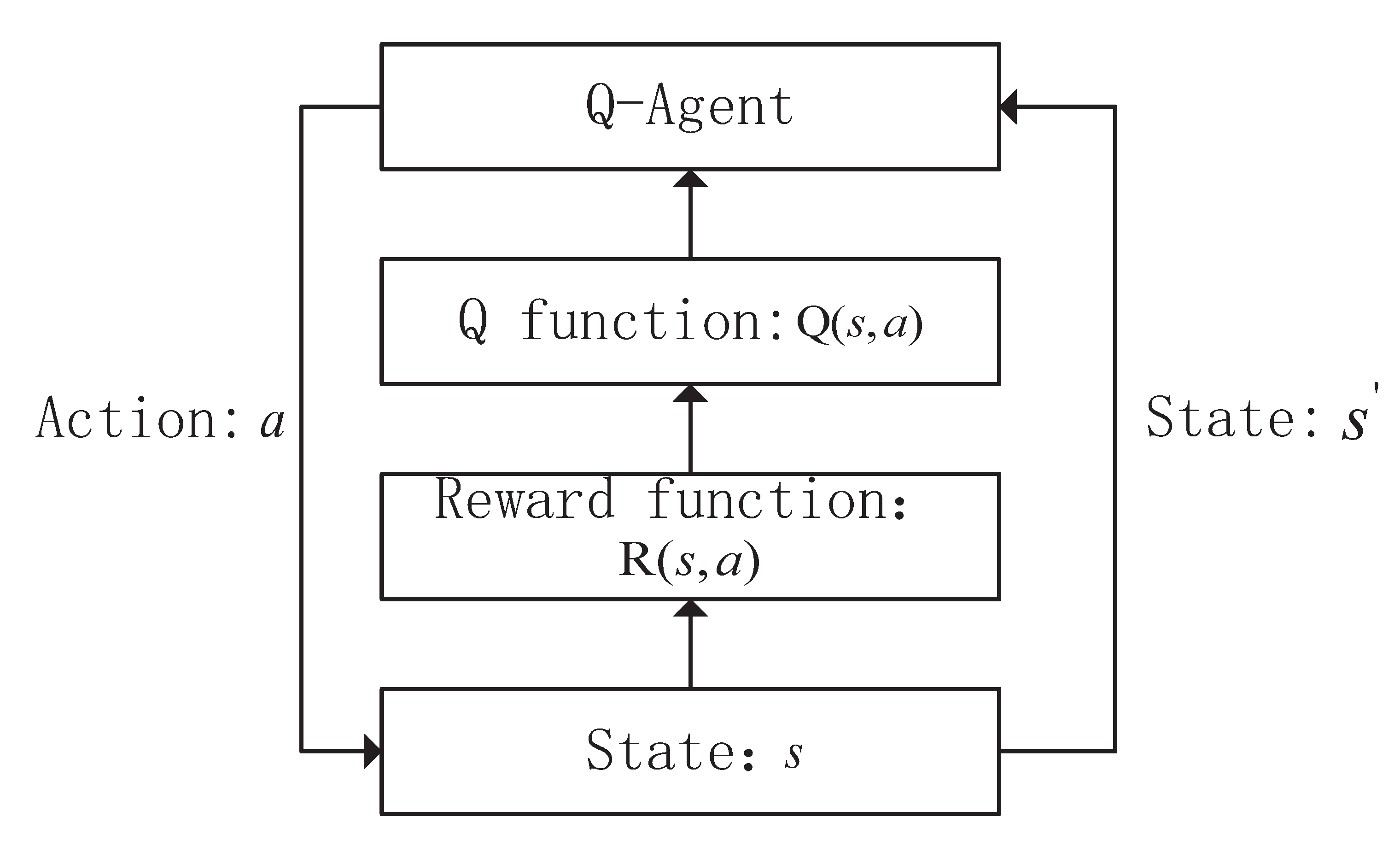
4.2.1. Q-Learning Model
- A.
- Environment state set
- B.
- Action set
- C.
- Reward function
4.2.2. Algorithm Procedure
| Algorithm 1: Q-Learning Algorithm for SSC mapping |
Input: Substrate network graph , SSC request . Output: Orchestration result set . 01: Initialize the learning factor and discount factor ; 02: for each request , do 03: if the available substrate network resources meet the needs of , then 04: select a substrate node as the starting point of randomly and define the current state . 05: while VSF(), do 06: deploy on the substrate node in the current state s. 07: if using the strategy to select the next action, 08: select action a from the action set randomly. 09: else 10: select action a according to Equation (12). 11: end if 12: execute action a to obtain the next state . 13: update the Q table using Equation (13). 14: . 15: end while 16: else 17: refuse request . 18: end if 19: update O. 20: end for 21: return O. |
| Algorithm 2: Q-table training |
Input: Substrate network graph , SSC request . Output:Q-table. 01: Initialize the learning factor and discount factor ; 02: Initialize ; 03: for each episode,do 04: while , do 05: use Algorithm 1 to orchestrate . 06: end while 07: update Q-table 08: restore the substrate network state. 09: end for 10: return Q-table. |
4.3. VSF Backup
4.3.1. Node Importance of VSF
4.3.2. Algorithm Procedure
| Algorithm 3: VSF backup based on node importance |
Input: Orchestration result set . Output: VSF backup results. 01: for each SSC , do 02: calculate the reliability of . 03: if , then 04: put in , put all the that makes up into 05: end if 06: end for 07: while , do 08: backup with the largest value 09: for each SSC , do 10: calculate the reliability of 11: if , then 12: delete from 13: end if 14: end for 15: end while 16: return VSF backup results. |
5. Evaluation
5.1. Simulation Setup
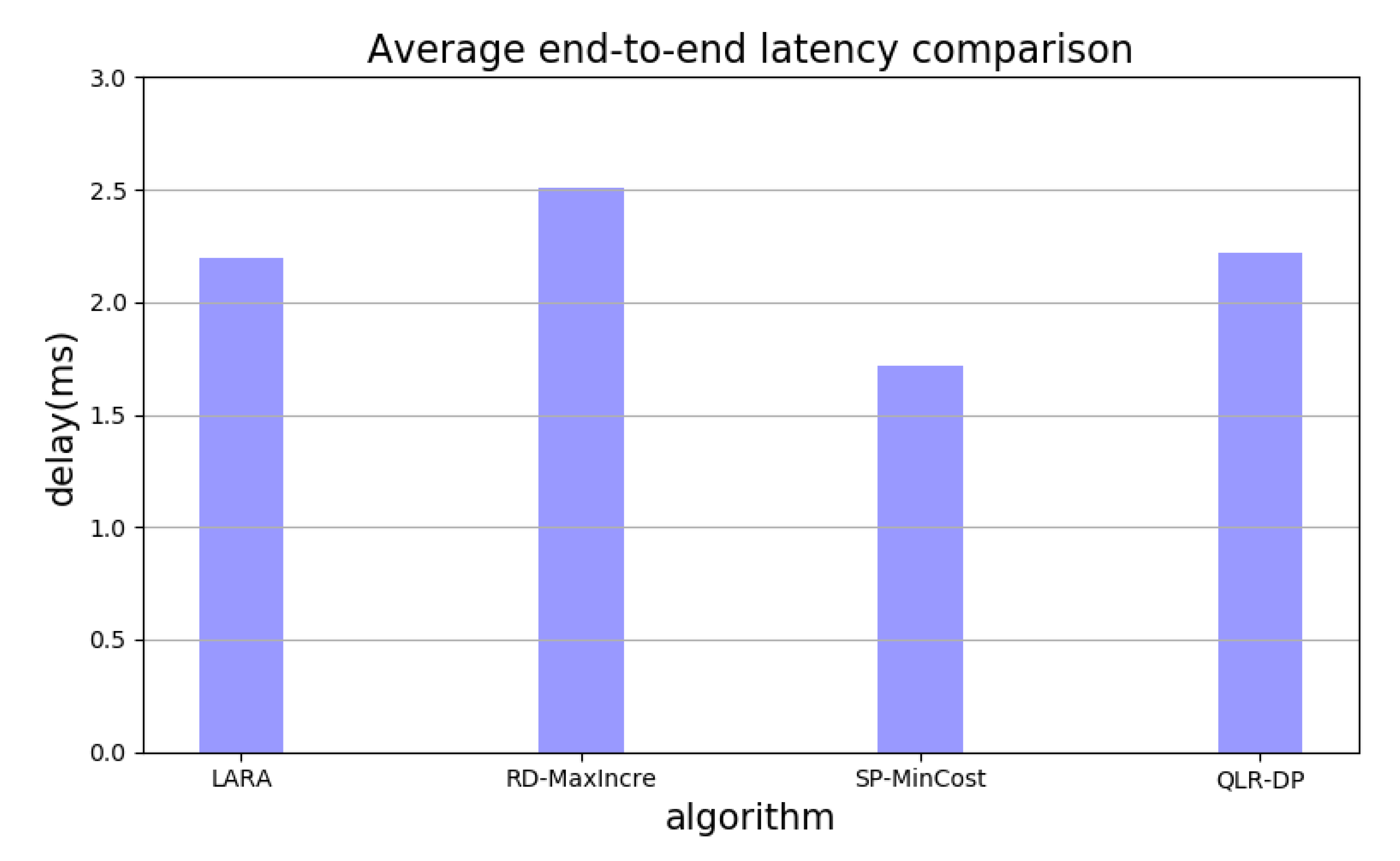
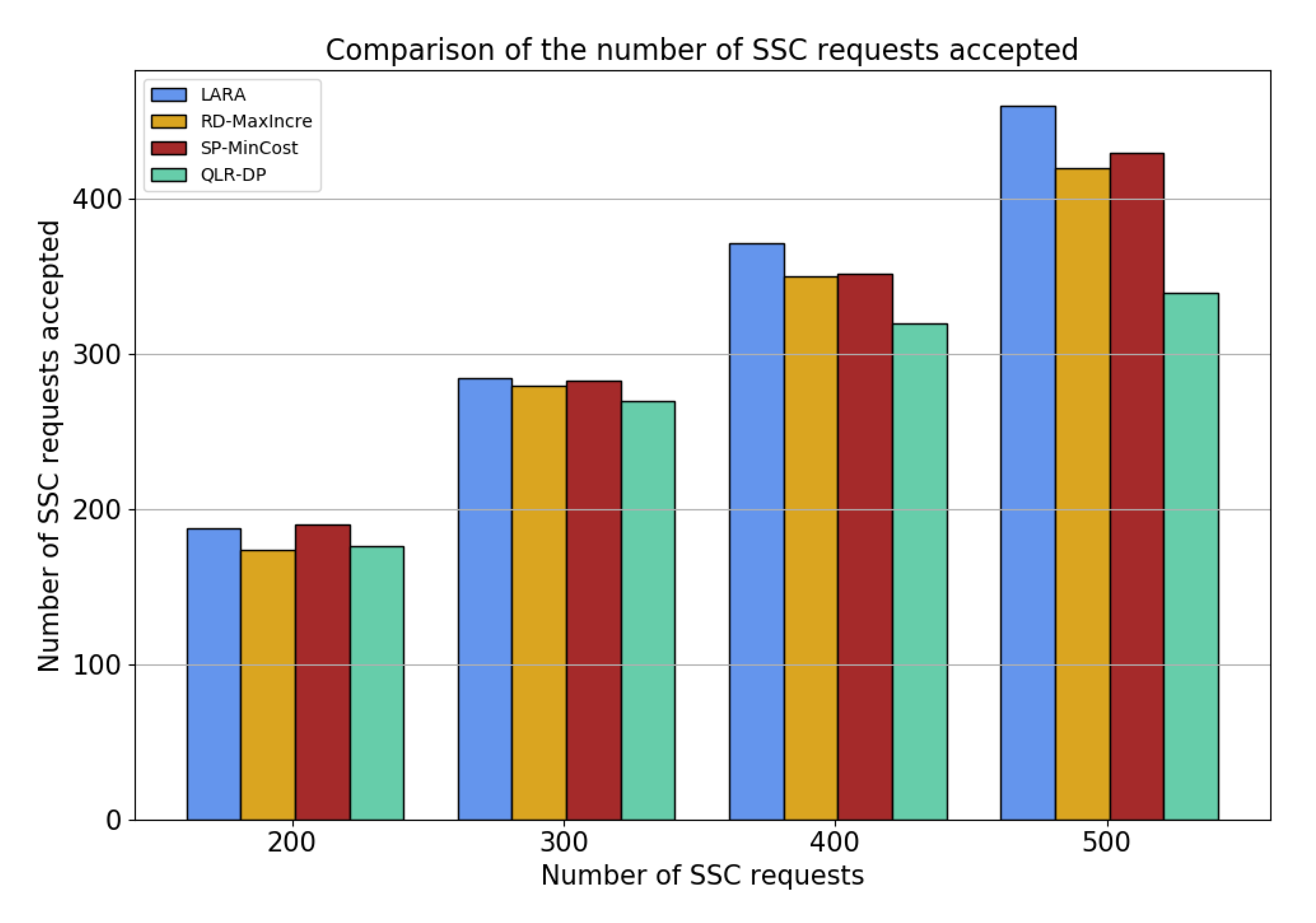
5.2. Results and Discussion
- RD-MaxIncre: The orchestration step randomly selects substrate nodes to place the VSF. In the backup step, each iteration selects the VSF with the lowest reliability on the SSC in the model for backup so as to achieve the goal of maximum SSC reliability increment and finally heuristically solve the redundant backup scheme.
- SP-MinCost: The orchestration step adopts the short path algorithm based on the greedy algorithm to directly calculate the shortest path between user endpoints as the basic path for data flow forwarding, then deploys VSF on the substrate node of the path. In the backup step, each round of iteration selects the VSF with the smallest physical resource demand on the SSC in the model for backup so as to achieve the goal of minimizing the backup cost used in each round, before finally heuristically solving the redundant backup scheme.
- QLR-DP: The orchestration step adopts SSC mapping based on the Q-learning algorithm proposed in this paper. The backup step adopts a dedicated backup, and the VSF with the lowest reliability on each SSC is backed up by multiple SSCs regardless of the sharing of the VSF.
- (1)
- METRIC1: average end-to-end latency.
- (2)
- METRIC2: resource consumption.
- (3)
- METRIC3: request acceptance rate.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VSF | Virtual Security Function |
| SSC | Security Service Chain |
| VNF | Virtual Network Function |
| SFC | Service Function Chain |
| RL | Reinforcement Learning |
References
- Luizelli, M.C.; Bays, L.R.; Buriol, L.S.; Barcellos, M.P.; Gaspary, L.P. Piecing together the NFV provisioning puzzle: Efficient placement and chaining of virtual network functions. In Proceedings of the 2015 IFIP/IEEE International Symposium on Integrated Network Management (IM), Ottawa, ON, Canada, 11–15 May 2015; pp. 98–106. [Google Scholar]
- Feng, B.; Zhou, H.; Li, G.; Zhang, Y.; Sood, K.; Yu, S. Enabling Machine Learning with Service Function Chaining for Security Enhancement at 5G Edges. IEEE Netw. 2021, 35, 196–201. [Google Scholar] [CrossRef]
- Nguyen, T.N. The Challenges in SDN/ML Based Network Security. In Proceedings of the 2018 2nd Cyber Security in Networking Conference (CSNet), Paris, France, 24–26 October 2018; pp. 1–9. [Google Scholar]
- Park, Y.; Kengalahalli, N.V.; Chang, S. Distributed Security Network Functions against Botnet Attacks in Software-defined Networks. In Proceedings of the IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Verona, Italy, 27–29 November 2018; pp. 1–7. [Google Scholar]
- Zhang, J.; Wang, Z.; Ma, N.; Huang, T.; Liu, Y. Enabling Efficient Service Function Chaining by Integrating NFV and SDN: Architecture, Challenges and Opportunities. IEEE Netw. 2018, 32, 152–159. [Google Scholar] [CrossRef]
- Farris, I.; Taleb, T.; Khettab, Y.; Song, J. A Survey on Emerging SDN and NFV Security Mechanisms for IoT Systems. IEEE Commun. Surv. Tutor. 2019, 21, 812–837. [Google Scholar] [CrossRef]
- Doriguzzi-Corin, R.; Scott-Hayward, S.; Siracusa, D.; Savi, M.; Salvadori, E. Dynamic and Application-Aware Provisioning of Chained Virtual Security Network Functions. IEEE Trans. Netw. Serv. Manag. 2020, 17, 294–307. [Google Scholar] [CrossRef]
- Menouer, T.; Khedimi, A.; Cérin, C.; Chahbar, M. Scheduling Service Function Chains with Dependencies in the Cloud. In Proceedings of the 2020 IEEE 9th International Conference on Cloud Networking (CloudNet), Piscataway, NJ, USA, 9–11 November 2020; pp. 1–3. [Google Scholar]
- Xu, Y.; Kafle, V.P. Optimal Service Function Chain Placement Modeling for Minimizing Setup and Operation Cost. In Proceedings of the 2018 IEEE 7th International Conference on Cloud Networking (CloudNet), Tokyo, Japan, 22–24 October 2018; pp. 1–3. [Google Scholar]
- Kim, S.I.; Kim, H.S. Method for VNF Placement for Service Function Chaining optimized in the NFV Environment. In Proceedings of the 2019 Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Zagreb, Croatia, 2–5 July 2019; pp. 721–724. [Google Scholar]
- Wang, Z.; Zhao, Z.; Shu, C.; Min, G.; Han, Y.; Jiang, Y. Orchestrating Service Function Chains with Joint Resource Optimization in NFV Networks. In Proceedings of the IEEE International Conference on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Xiamen, China, 16–18 December 2019; pp. 1115–1122. [Google Scholar]
- Guo, H.; Wang, Y.; Li, Z.; Qiu, Z.; An, H.; Yu, P.; Yuan, N. Cost-aware Placement and Chaining of Service Function Chain with VNF Instance Sharing. In Proceedings of the NOMS 2020–2020 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 20–24 April 2020; pp. 1–8. [Google Scholar]
- Khatiri, A.; Mirjalily, G. Resource Balanced Service Chaining in NFV-enabled Inter-Datacenter Elastic Optical Networks. In Proceedings of the 2020 12th International Conference on Knowledge and Smart Technology (KST), Pattaya, Thailand, 29 January–1 February 2020; pp. 168–171. [Google Scholar]
- Qiao, W.; Liu, Y.; Xi, L.; Li, X.; Li, Z.; Zhao, D.; Lu, Y. A Novel Method for Resource Efficient Security Service Chain Embedding Oriented to Cloud Datacenter Networks. IEEE Access 2021, 9, 77307–77324. [Google Scholar] [CrossRef]
- Dwiardhika, D.; Tachibana, T. Virtual Network Embedding Based on Security Level with VNF Placement. Secur. Commun. Netw. 2019, 2019, 5640134. [Google Scholar] [CrossRef] [Green Version]
- Chua, F.C.; Ward, J.; Zhang, Y.; Sharma, P.; Huberman, B.A. Stringer: Balancing Latency and Resource Usage in Service Function Chain Provisioning. IEEE Internet Comput. 2016, 20, 22–31. [Google Scholar] [CrossRef] [Green Version]
- Cho, D.; Taheri, J.; Zomaya, A.Y.; Wang, L. Virtual Network Function Placement: Towards Minimizing Network Latency and Lead Time. In Proceedings of the IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Hong Kong, China, 11–14 December 2017; pp. 90–97. [Google Scholar]
- Liu, J.; Li, Y.; Zhang, Y.; Su, L.; Jin, D. Improve Service Chaining Performance with Optimized Middlebox Placement. IEEE Trans. Serv. Comput. 2017, 10, 560–573. [Google Scholar] [CrossRef]
- Hmaity, A.; Savi, M.; Musumeci, F.; Tornatore, M.; Pattavina, A. Virtual Network Function placement for resilient Service Chain provisioning. In Proceedings of the 2016 8th International Workshop on Resilient Networks Design and Modeling (RNDM), Halmstad, Sweden, 13–15 September 2016; pp. 245–252. [Google Scholar]
- Casazza, M.; Fouilhoux, P.; Bouet, M.; Secci, S. Securing virtual network function placement with high availability guarantees. In Proceedings of the 2017 IFIP Networking Conference (IFIP Networking) and Workshops, Stockholm, Sweden, 12–16 June 2017; pp. 1–7. [Google Scholar]
- Wang, C.; Tang, H.; You, W.; Niu, B. Method for virtual network function backup based on backup-cost importance. Appl. Res. Comput. 2019, 36, 3. [Google Scholar]
- Hmaity, A.; Savi, M.; Musumeci, F.; Tornatore, M. Protection strategies for virtual network functions placement and service chains provisioning. Networks 2017, 70, 373–387. [Google Scholar] [CrossRef]
- Lee, D.; Yoo, J.H.; Hong, W.K. Q-learning based Service Function Chaining using VNF Resource-aware Reward Model. In Proceedings of the 2020 21st Asia-Pacific Network Operations and Management Symposium (APNOMS), Daegu, Korea, 22–25 September 2020; pp. 279–282. [Google Scholar]
- Dai, M.; Su, Z.; Xu, Q.; Chen, W. A Q-Learning Based Scheme to Securely Cache Content in Edge-Enabled Heterogeneous Networks. IEEE Access 2019, 7, 163898–163911. [Google Scholar] [CrossRef]
- Alnagar, S.I.; Salhab, A.M.; Zummo, S.A. Q-Learning-Based Power Allocation for Secure Wireless Communication in UAV-Aided Relay Network. IEEE Access 2021, 9, 33169–33180. [Google Scholar] [CrossRef]
- Iqbal, M.U.; Ansari, E.A.; Akhtar, S. Interference Mitigation in HetNets to Improve the QoS Using Q-Learning. IEEE Access 2019, 9, 32405–32424. [Google Scholar] [CrossRef]
- Google Company. Google Apps Service Level Agreement[OL]. Available online: http://www.google.com/apps/intl/en/terms/sla.html (accessed on 10 November 2021).
- Liu, Y.; Lu, Y.; Li, X.; Yao, Z.; Zhao, D. On Dynamic Service Function Chain Reconfiguration in IoT Networks. IEEE Internet Things J. 2020, 7, 10969–10984. [Google Scholar] [CrossRef]
- Che, X.; Kang, W.; Deng, B.; Yang, K.; Li, J. A SDN routing performance prediction model based on graph neural network. Chin. J. Electron. 2021, 49, 484–491. [Google Scholar]
- Subramanya, T.; Harutyunyan, D.; Riggio, R. Machine learning-driven service function chain placement and scaling in MEC-enabled 5G networks. Comput. Netw. 2020, 166, 1–16. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Definitions |
|---|---|
| The processing time of the VSF on the substrate node | |
| The transmission delay on the substrate path | |
| The reliability of SSC | |
| The sum of and | |
| The reliability of VSF | |
| The failure probability of | |
| The reliability of SSC after backup | |
| The reliability of VSF | |
| The CPU resource consumption of the substrate node after backup | |
| The memory resource consumption of the substrate node after backup | |
| The length of the link between the backup VSF and the previous VSF of the original VSF, that is, the number of hops between physical nodes | |
| The length of the link between the backup VSF and the post VSF of the original VSF—that is, the number of hops between physical nodes | |
| The outflow bandwidth of the previous VSF | |
| The outflow bandwidth of the backup VSF | |
| A given Boolean variable.It is 1 if a request ’s requested VSF is embedded on the substrate node ; and 0 otherwise | |
| A given Boolean variable. It is 1 if the link between two adjacent security functions on the SSC passes through the substrate link and 0 otherwise | |
| A given Boolean variable. It is 1 if VSF s backed up and 0 otherwise |
| Parameters | Value | Definitions |
|---|---|---|
| 0.01 | Learning rate | |
| 0.9 | Discounting factor | |
| 0.5 | Greedy rate |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Jiang, Y.; Zhang, X.; Dang, F.; Gao, F.; Wang, H.; Fan, Q. Reliability Assurance Dynamic SSC Placement Using Reinforcement Learning. Information 2022, 13, 53. https://doi.org/10.3390/info13020053
Li W, Jiang Y, Zhang X, Dang F, Gao F, Wang H, Fan Q. Reliability Assurance Dynamic SSC Placement Using Reinforcement Learning. Information. 2022; 13(2):53. https://doi.org/10.3390/info13020053
Chicago/Turabian StyleLi, Wei, Yuan Jiang, Xiaoliang Zhang, Fangfang Dang, Feng Gao, Haomin Wang, and Qi Fan. 2022. "Reliability Assurance Dynamic SSC Placement Using Reinforcement Learning" Information 13, no. 2: 53. https://doi.org/10.3390/info13020053
APA StyleLi, W., Jiang, Y., Zhang, X., Dang, F., Gao, F., Wang, H., & Fan, Q. (2022). Reliability Assurance Dynamic SSC Placement Using Reinforcement Learning. Information, 13(2), 53. https://doi.org/10.3390/info13020053