
Semantic Residual Pyramid Network for Image Inpainting



Abstract
:1. Introduction
- We designed a novel residual pyramid encoder to obtain high-level semantic features by adding the residual blocks to the semantic pyramid encoder;
- We introduced multi-scale discriminators based on generating adversarial networks to judge whether the semantic features of images at different scales are consistent. Thus, we can obtain richer texture details and semantic features that are more consistent with the ground truth.
2. Related Work
2.1. Image Inpainting
2.2. Semantic Pyramid Network
2.3. Contextual Attention Model
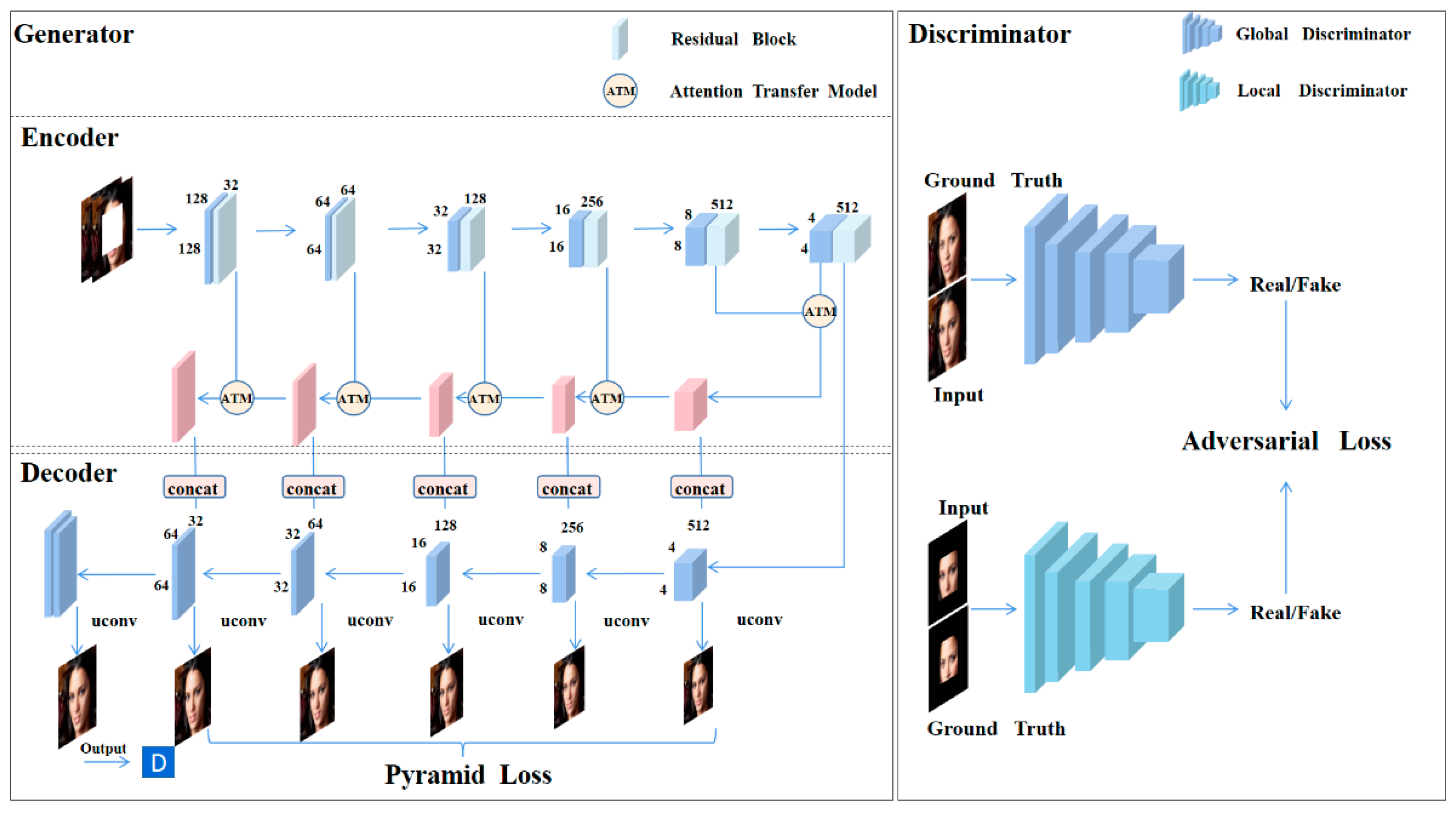
3. Semantic Residual Pyramid Network
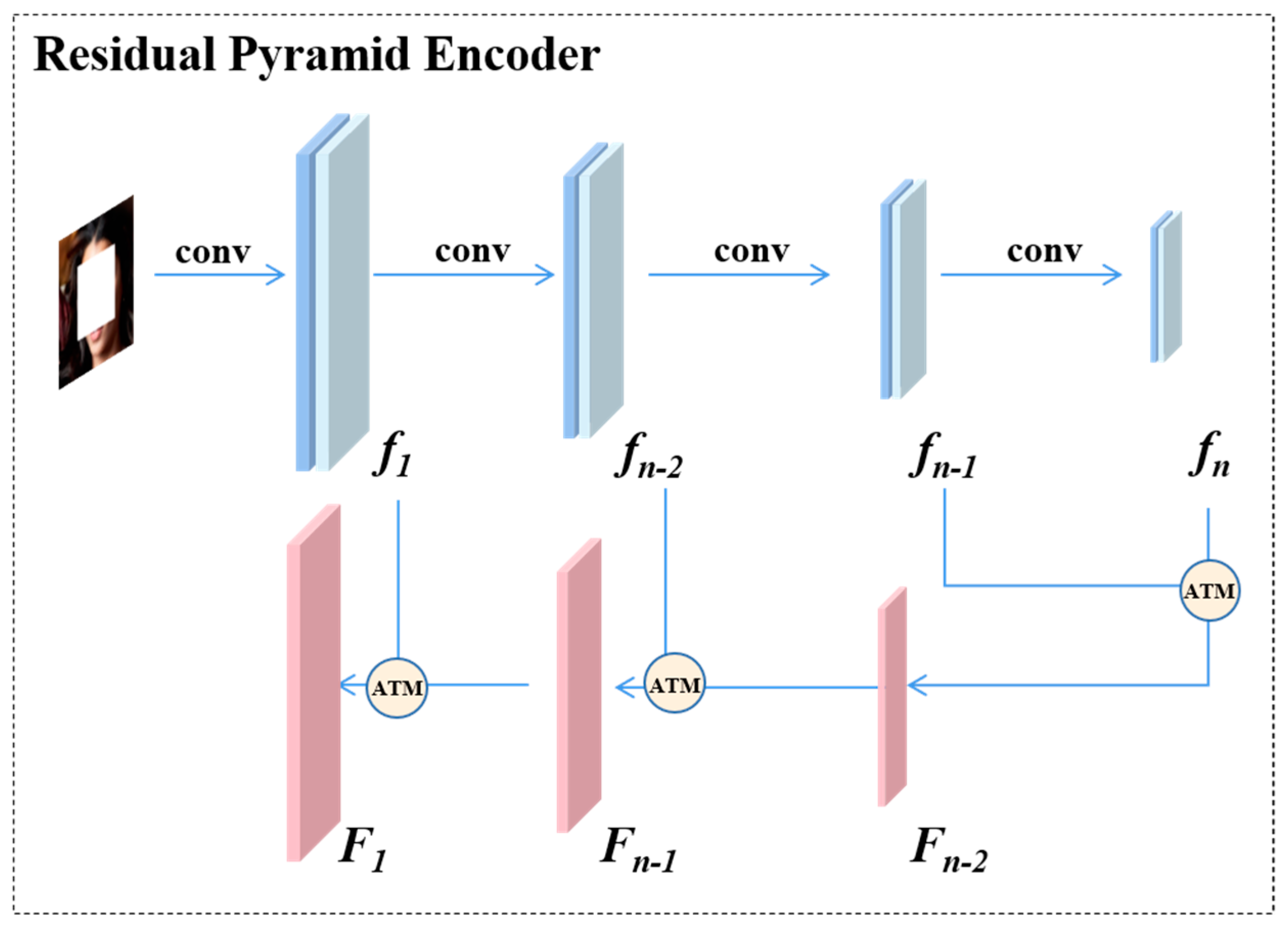
3.1. Residual Pyramid Encoder
Fn−2 = ψ (fn−2, Fn−1),
…,
F1 = ψ (f1, F2) = ψ (f1, ψ (f2 …, ψ (fn−1, fn))),
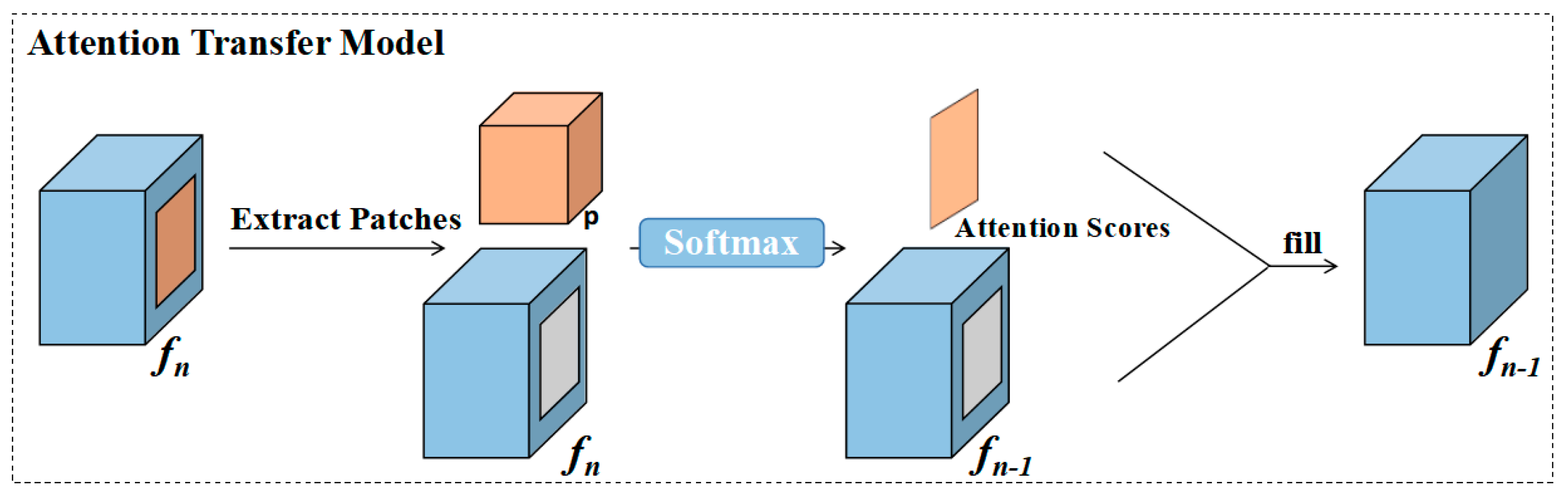
3.2. Attention Transfer Model
3.3. Multi-Layer Decoder
3.4. Multi-Scale Discriminators
4. Experiments and Analysis
4.1. Experimental Settings
4.2. Experiments Results
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Structure |
|---|---|
| Input | 4 × 256 × 256 (Image + Mask) |
| Conv | input: 4, kernel: 3, stride: 2, padding: 1, LReLU, output: 32 |
| Residual_blocks | input: 32, kernel: 3, stride: 2, padding: 0, ReLU, output: 32 |
| Conv | input: 32, kernel: 3, stride: 2, padding: 1, LReLU, output: 64 |
| Residual_blocks | input: 64, kernel: 3, stride: 2, padding: 0, ReLU, output: 64 |
| Conv | input: 64, kernel: 3, stride: 2, padding: 1, LReLU, output: 128 |
| Residual_blocks | input: 128, kernel: 3, stride: 2, padding: 0, ReLU, output: 128 |
| Conv | input: 128, kernel: 3, stride: 2, padding: 1, LReLU, output: 256 |
| Residual_blocks | input: 256, kernel: 3, stride: 2, padding: 0, ReLU, output: 256 |
| Conv | input: 256, kernel: 3, stride: 2, padding: 1, LReLU, output: 512 |
| Residual_blocks | input: 512, kernel: 3, stride: 2, padding: 0, ReLU, output: 512 |
| Conv | input: 512, kernel: 3, stride: 2, padding: 1, LReLU, output: 512 |
| Residual_blocks | input: 512, kernel: 3, stride: 2, padding: 0, ReLU, output: 512 |
| ATMConv | input: 512, kernel: 1, stride: 1, output: 512 |
| ATMConv | input: 256, kernel: 1, stride: 1, output: 256 |
| ATMConv | input: 128, kernel: 1, stride: 1, output: 128 |
| ATMConv | input: 64, kernel: 1, stride: 1, output: 64 |
| ATMConv | input: 32, kernel: 1, stride: 1, output: 32 |
| DeConv | input: 512, kernel: 3, stride: 1, padding: 1, ReLU, output: 512 |
| DeConv | input: 1024, kernel: 3, stride: 1, padding: 1, ReLU, output: 256 |
| DeConv | input: 512, kernel: 3, stride: 1, padding: 1, ReLU, output: 128 |
| DeConv | input: 256, kernel: 3, stride: 1, padding: 1, ReLU, output: 64 |
| DeConv | input: 128, kernel: 3, stride: 1, padding: 1, ReLU, output: 32 |
| Output1 | input: 1024, kernel: 1, stride: 1, padding: 0, Tanh, output: 3 |
| Output2 | input: 512, kernel: 1, stride: 1, padding: 0, Tanh, output: 3 |
| Output3 | input: 256, kernel: 1, stride: 1, padding: 0, Tanh, output: 3 |
| Output4 | input: 128, kernel: 1, stride: 1, padding: 0, Tanh, output: 3 |
| Output5 | input: 64, kernel: 1, stride: 1, padding: 0, Tanh, output: 3 |
| Output6 | input: 64, kernel: 3, stride: 1, padding: 1, ReLU, output: 32input: 32, kernel: 3, stride: 1, padding: 1, Tanh, output: 3 |
| Type | Structure |
|---|---|
| Conv | input: 3, kernel: 5, stride: 2, padding: 1, LReLU, output: 64 |
| Conv | input: 64, kernel: 5, stride: 2, padding: 1, LReLU, output: 128 |
| Conv | input: 128, kernel: 5, stride: 2, padding: 1, LReLU, output: 256 |
| Conv | input: 256, kernel: 5, stride: 2, padding: 1, LReLU, output: 512 |
| Conv | input: 512, kernel: 5, stride: 2, padding: 1, LReLU, output: 1 |
| Mask | Methods | L1 (↓) | PSNR (↑) | MS-SSIM (↑) |
|---|---|---|---|---|
| [0.01,0.1] | PIC-NET | 0.83% | 31.14 | 95.83% |
| GLCIC | 1.01% | 32.67 | 96.52% | |
| PEN-NET | 0.67% | 32.37 | 96.57% | |
| Ours | 0.66% | 32.75 | 96.55% | |
| (0.1,0.2] | PIC-NET | 2.10% | 26.07 | 90.88% |
| GLCIC | 2.87% | 26.36 | 89.82% | |
| PEN-NET | 1.79% | 26.72 | 91.91% | |
| Ours | 1.76% | 26.78 | 92.01% | |
| (0.2,0.3] | PIC-NET | 3.60% | 23.49 | 83.44% |
| GLCIC | 5.19% | 22.60 | 78.60% | |
| PEN-NET | 3.27% | 23.68 | 84.29% | |
| Ours | 3.13% | 24.05 | 85.32% | |
| (0.3,0.4] | PIC-NET | 5.22% | 21.58 | 75.08% |
| GLCIC | 7.41% | 20.08 | 66.32% | |
| PEN-NET | 4.90% | 21.65 | 75.42% | |
| Ours | 4.59% | 22.23 | 77.89% | |
| (0.4,0.5] | PIC-NET | 7.11% | 19.94 | 65.36% |
| GLCIC | 9.51% | 18.39 | 54.08% | |
| PEN-NET | 6.61% | 20.17 | 65.90% | |
| Ours | 6.24% | 20.70 | 69.23% | |
| (0.5,0.6] | PIC-NET | 9.90% | 17.85 | 51.65% |
| GLCIC | 11.51% | 16.95 | 40.43% | |
| PEN-NET | 8.61% | 18.81 | 54.91% | |
| Ours | 8.18% | 19.26 | 57.48% |
| Mask | Methods | L1 (↓) | PSNR (↑) | MS-SSIM (↑) |
|---|---|---|---|---|
| [0.01,0.1] | PIC-NET | 0.86% | 29.28 | 96.28% |
| GLCIC | 0.98% | 31.48 | 97.92% | |
| PEN-NET | 0.58% | 31.98 | 97.60% | |
| Ours | 0.54% | 32.20 | 97.85% | |
| (0.1,0.2] | PIC-NET | 2.68% | 22.89 | 90.81% |
| GLCIC | 2.71% | 25.38 | 84.75% | |
| PEN-NET | 1.75% | 24.94 | 93.43% | |
| Ours | 1.45% | 26.34 | 95.19% | |
| (0.2,0.3] | PIC-NET | 4.81% | 20.04 | 82.11% |
| GLCIC | 4.76% | 19.98 | 76.06% | |
| PEN-NET | 3.40% | 21.67 | 86.66% | |
| Ours | 2.71% | 23.41 | 89.33% | |
| (0.3,0.4] | PIC-NET | 6.85% | 18.48 | 72.83% |
| GLCIC | 6.67% | 19.98 | 76.06% | |
| PEN-NET | 5.10% | 19.84 | 79.35% | |
| Ours | 4.33% | 20.92 | 82.36% | |
| (0.4,0.5] | PIC-NET | 9.11% | 17.02 | 63.72% |
| GLCIC | 9.06% | 18.21 | 66.51% | |
| PEN-NET | 6.89% | 18.45 | 70.21% | |
| Ours | 6.16% | 19.19 | 74.51% | |
| (0.5,0.6] | PIC-NET | 11.88% | 15.53 | 50.26% |
| GLCIC | 11.16% | 16.65 | 53.59% | |
| PEN-NET | 9.27% | 16.95 | 59.52% | |
| Ours | 8.20% | 17.67 | 64.01% |
| Mask | Methods | L1 (↓) | PSNR (↑) | MS-SSIM (↑) |
|---|---|---|---|---|
| [0.01,0.1] | PIC-NET | 0.45% | 34.71 | 97.53% |
| GLCIC | 0.74% | 32.11 | 95.64% | |
| PEN-NET | 0.49% | 33.61 | 97.06% | |
| Ours | 0.41% | 34.35 | 97.54% | |
| (0.1,0.2] | PIC-NET | 1.16% | 29.37 | 93.48% |
| GLCIC | 2.10% | 28.29 | 91.87% | |
| PEN-NET | 1.35% | 27.49 | 91.47% | |
| Ours | 1.06% | 29.38 | 93.84% | |
| (0.2,0.3] | PIC-NET | 2.02% | 26.40 | 88.11% |
| GLCIC | 3.77% | 24.45 | 83.00% | |
| PEN-NET | 2.46% | 24.36 | 84.25% | |
| Ours | 1.89% | 26.47 | 88.73% | |
| (0.3,0.4] | PIC-NET | 2.99% | 24.28 | 81.80% |
| GLCIC | 5.52% | 21.80 | 72.63% | |
| PEN-NET | 3.76% | 22.28 | 76.27% | |
| Ours | 2.82% | 24.47 | 82.64% | |
| (0.4,0.5] | PIC-NET | 4.16% | 22.41 | 73.96% |
| GLCIC | 7.17% | 19.90 | 62.01% | |
| PEN-NET | 5.42% | 20.55 | 66.94% | |
| Ours | 3.98% | 22.56 | 74.94% | |
| (0.5,0.6] | PIC-NET | 6.45% | 19.55 | 58.67% |
| GLCIC | 9.03% | 18.01 | 49.70% | |
| PEN-NET | 7.76% | 19.13 | 56.79% | |
| Ours | 5.73% | 20.44 | 63.27% |

References
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000; pp. 417–424. [Google Scholar]
- Qureshi, M.A.; Deriche, M. A bibliography of pixel-based blind image forgery detection techniques. Signal Process. Image Commun. 2015, 39, 46–74. [Google Scholar] [CrossRef]
- Qureshi, M.A.; Deriche, M.; Beghdadi, A.; Amin, A. A critical survey of state-of-the-art image inpainting quality assessment metrics. J. Vis. Commun. Image Represent. 2017, 49, 177–191. [Google Scholar] [CrossRef]
- Shen, J.; Chan, T.F. Mathematical Models for Local Nontexture Inpaintings. SIAM J. Appl. Math. 2002, 62, 1019–1043. [Google Scholar] [CrossRef]
- Chan, T.F.; Shen, J. Nontexture Inpainting by Curvature-Driven Diffusions. J. Vis. Commun. Image Represent. 2001, 12, 436–449. [Google Scholar] [CrossRef]
- Efros, A.A.; Freeman, W.T. Image quilting for texture synthesis and transfer. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA; 2001; pp. 341–346. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Jain, V.; Seung, S. Natural image denoising with convolutional networks. Adv. Neural Inf. Processing Syst. 2008, 21, 769–776. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–1 July 2016; pp. 2536–2544. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Yi, Z.; Tang, Q.; Azizi, S.; Jang, D.; Xu, Z. Contextual residual aggregation for ultra high-resolution image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7508–7517. [Google Scholar]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Learning pyramid-context encoder network for high-quality image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1486–1494. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Ying, X. An Overview of Overfitting and its Solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. Edgeconnect: Generative image inpainting with adversarial edge learning. arXiv 2019, arXiv:1901.00212. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Tyleček, R.; Šára, R. Spatial pattern templates for recognition of objects with regular structure. In Proceedings of the German Conference on Pattern Recognition, Saarbrücken, Germany, 3–6 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 364–374. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtine, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, P. Convolutional neural network. In MATLAB Deep Learning; Apress: Berkeley, CA, USA, 2017; pp. 121–147. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 85–100. [Google Scholar]
- Zheng, C.; Cham, T.J.; Cai, J. Pluralistic image completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1438–1447. [Google Scholar]
- Adelson, E.H.; Anderson, C.H.; Bergen, J.R.; Burt, P.J.; Ogden, J.M. Pyramid methods in image processing. RCA Eng. 1984, 29, 33–41. [Google Scholar]
- Shocher, A.; Gandelsman, Y.; Mosseri, I.; Yarom, M.; Irani, M.; Freeman, W.T.; Dekel, T. Semantic pyramid for image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7457–7466. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dillon, J.V.; Langmore, I.; Tran, D.; Brevdo, E.; Vasudevan, S.; Moore, D.; Saurous, R.A. Tensorflow distributions. arXiv 2017, arXiv:1711.10604. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Chintala, S. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Processing Syst. 2019, 32, 8026–8037. [Google Scholar]
- Johnson, D.H. Signal-to-noise ratio. Scholarpedia 2006, 1, 2088. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]





| Datasets | Training | Testing | Total |
|---|---|---|---|
| DTD [17] | 4512 | 1128 | 5640 |
| Façade [18] | 506 | 100 | 606 |
| CELEBA-HQ [19] | 28,000 | 2000 | 30,000 |
| Places2 [20] | 1,829,960 | 10,000 | 1,839,960 |
| Mask [24] | − | − | 12,000 |
| Datasets | Methods | L1 (↓) | PSNR (↑) | MS-SSIM (↑) |
|---|---|---|---|---|
| DTD | PIC-NET | 3.72% | 22.56 | 72.69% |
| GLCIC | 3.49% | 23.48 | 73.78% | |
| PEN-NET | 3.44% | 23.73 | 75.13% | |
| Ours | 3.25% | 24.17 | 76.62% | |
| Facade | PIC-NET | 4.04% | 20.92 | 74.40% |
| GLCIC | 3.63% | 21.87 | 77.87% | |
| PEN-NET | 3.69% | 21.87 | 77.59% | |
| Ours | 3.02% | 23.22 | 82.49% | |
| CELEBA-HQ | PIC-NET | 2.69% | 24.29 | 87.26% |
| GLCIC | 2.63% | 24.96 | 88.94% | |
| PEN-NET | 2.40% | 25.47 | 89.03% | |
| Ours | 2.18% | 26.31 | 90.76% | |
| Places2 | PIC-NET | 3.10% | 22.64 | 76.78% |
| GLCIC | 2.76% | 22.96 | 73.39% | |
| PEN-NET | 2.75% | 23.80 | 78.68% | |
| Ours | 2.58% | 24.37 | 80.52% |
| Datasets | Methods | L1 (↓) | PSNR (↑) | MS-SSIM (↑) |
|---|---|---|---|---|
| DTD | PIC-NET | 0.82% | 31.14 | 95.83% |
| GLCIC | 1.92% | 29.66 | 93.51% | |
| PEN-NET | 0.62% | 33.01 | 96.28% | |
| Ours | 0.67% | 31.75 | 96.35% | |
| Facade | PIC-NET | 0.86% | 29.28 | 96.28% |
| GLCIC | 0.98% | 28.04 | 94.87% | |
| PEN-NET | 0.58% | 31.98 | 97.60% | |
| Ours | 0.53% | 32.19 | 97.85% | |
| CELEBA-HQ | PIC-NET | 0.46% | 35.68 | 98.93% |
| GLCIC | 1.35% | 28.65 | 93.37% | |
| PEN-NET | 0.84% | 32.06 | 96.94% | |
| Ours | 0.45% | 35.73 | 98.99% | |
| Places2 | PIC-NET | 2.17% | 27.47 | 87.00% |
| GLCIC | 1.42% | 31.72 | 94.79% | |
| PEN-NET | 0.83% | 31.11 | 94.83% | |
| Ours | 0.67% | 32.32 | 96.08% |
| Mask | Methods | L1 (↓) | PSNR (↑) | MS-SSIM (↑) |
|---|---|---|---|---|
| [0.01,0.1] | PIC-NET | 0.41% | 35.67 | 98.93% |
| GLCIC | 1.24% | 32.09 | 96.94% | |
| PEN-NET | 0.48% | 33.56 | 98.48% | |
| Ours | 0.36% | 35.73 | 98.99% | |
| (0.1,0.2] | PIC-NET | 1.06% | 30.13 | 96.85% |
| GLCIC | 3.59% | 24.70 | 89.55% | |
| PEN-NET | 1.34% | 27.85 | 95.40% | |
| Ours | 0.96% | 30.42 | 97.13% | |
| (0.2,0.3] | PIC-NET | 1.92% | 26.94 | 93.84% |
| GLCIC | 6.45% | 20.53 | 78.02% | |
| PEN-NET | 2.46% | 24.73 | 91.13% | |
| Ours | 1.75% | 27.35 | 94.44% | |
| (0.3,0.4] | PIC-NET | 2.94% | 24.52 | 89.79% |
| GLCIC | 9.46% | 17.84 | 65.20% | |
| PEN-NET | 3.76% | 22.57 | 86.10% | |
| Ours | 2.67% | 25.11 | 91.13% | |
| (0.4,0.5] | PIC-NET | 4.18% | 22.44 | 84.53% |
| GLCIC | 12.19% | 16.12 | 53.44% | |
| PEN-NET | 5.42% | 20.66 | 79.29% | |
| Ours | 3.77% | 23.23 | 86.94% | |
| (0.5,0.6] | PIC-NET | 6.73% | 19.41 | 73.08% |
| GLCIC | 15.38% | 14.68 | 41.36% | |
| PEN-NET | 7.76% | 18.72 | 69.40% | |
| Ours | 5.69% | 20.79 | 78.67% |
| Datasets | Methods | L1 (↓) | PSNR (↑) | MS-SSIM (↑) |
|---|---|---|---|---|
| Facade | Baseline | 3.69% | 21.87 | 77.59% |
| +Discriminator | 3.02% | 22.47 | 80.11% | |
| +Residual blocks (ours) | 3.36% | 23.22 | 82.49% | |
| CELEBA-HQ | Baseline | 2.40% | 25.47 | 89.03% |
| +Discriminator | 2.39% | 25.43 | 88.70% | |
| +Residual blocks (ours) | 2.18% | 26.27 | 90.64% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, H.; Zheng, Y. Semantic Residual Pyramid Network for Image Inpainting. Information 2022, 13, 71. https://doi.org/10.3390/info13020071
Luo H, Zheng Y. Semantic Residual Pyramid Network for Image Inpainting. Information. 2022; 13(2):71. https://doi.org/10.3390/info13020071
Chicago/Turabian StyleLuo, Haiyin, and Yuhui Zheng. 2022. "Semantic Residual Pyramid Network for Image Inpainting" Information 13, no. 2: 71. https://doi.org/10.3390/info13020071
APA StyleLuo, H., & Zheng, Y. (2022). Semantic Residual Pyramid Network for Image Inpainting. Information, 13(2), 71. https://doi.org/10.3390/info13020071