
SPMOO: A Multi-Objective Offloading Algorithm for Dependent Tasks in IoT Cloud-Edge-End Collaboration


Abstract
:1. Introduction
- We integrate the characteristics of edge computing and cloud computing, and then fully integrate and, based on heterogeneous computing resources, establish an IoT cloud-edge-end-collaborative computing offload architecture.
- Defining tasks as a directed, acyclic graph (DAG) composed of a set of nodes with interdependent subtasks, we then establish latency and energy consumption models by introducing two-dimensional offloading factors.
- Based on the delay and energy consumption models, the offloading problem is formalized as a multi-objective optimization problem with the objective of minimizing the average delay and average energy consumption of task offloading, and a multi-objective offloading (SPMOO) algorithm based on an improved strength Pareto evolutionary algorithm (SPEA2) is proposed for solving the problem.
2. Related Work
2.1. Offloading Strategies for Independent Tasks
2.2. Offloading Strategies for Dependent Tasks
3. System Model and Problem Formulation
3.1. Overview
3.1.1. Delay Model
3.1.2. Energy Consumption Model
3.2. Problem Formulation
4. The Proposed SPMOO Algorithm
| Algorithm 1: SPMOO |
 |
4.1. Fitness Calculation
4.2. Local Search Update
4.3. Intergenerational Crossover
4.4. Algorithm Complexity Analysis
5. Simulation Results
5.1. Simulation Settings
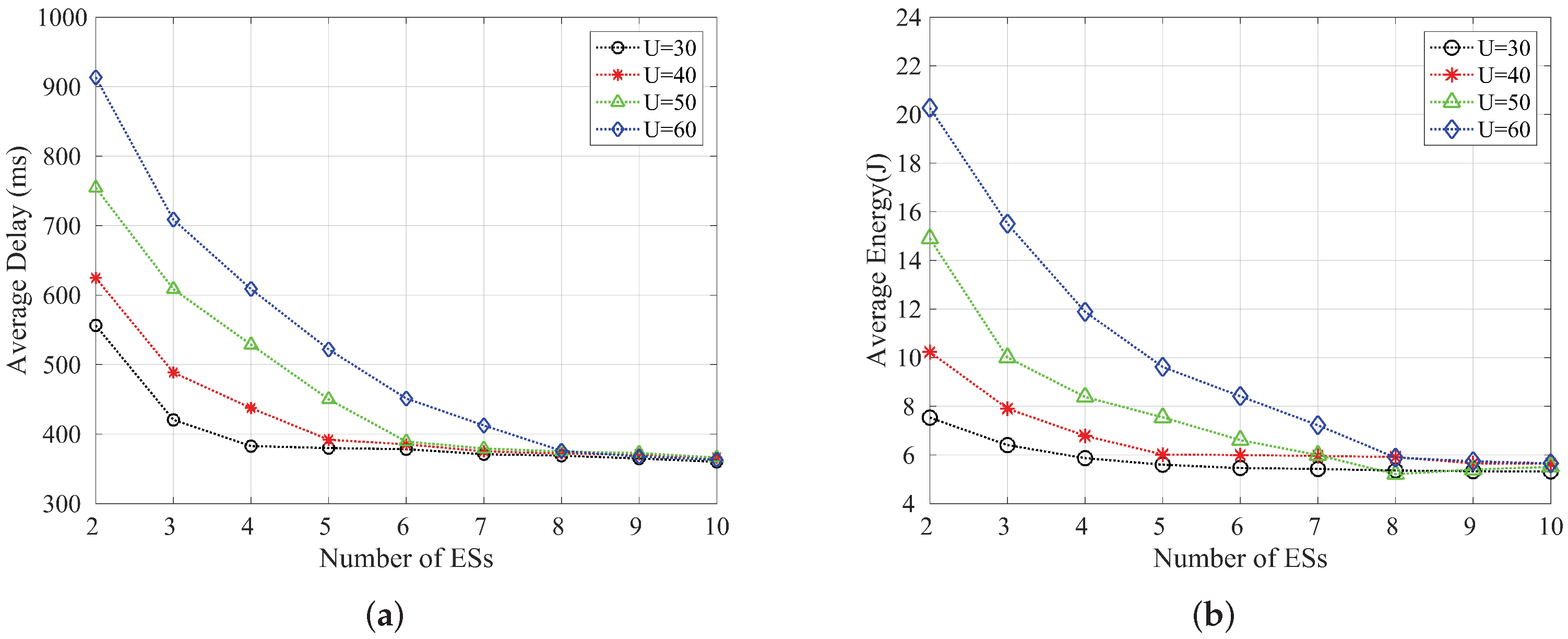
5.2. Analysis and Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mehmood, Y.; Ahmad, F.; Yaqoob, I.; Adnane, A.; Imran, M.; Guizani, S. Internet-of-Things-Based Smart Cities: Recent Advances and Challenges. IEEE Commun. Mag. 2017, 55, 16–24. [Google Scholar] [CrossRef]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A Survey on the Edge Computing for the Internet of Things. IEEE Access 2018, 6, 6900–6919. [Google Scholar] [CrossRef]
- Mallapuram, S.; Ngwum, N.; Yuan, F.; Lu, C.; Yu, W. Smart City: The State of the Art, Datasets, and Evaluation Platforms. In Proceedings of the 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 447–452. [Google Scholar] [CrossRef]
- Wang, K. Migration strategy of cloud collaborative computing for delay-sensitive industrial IoT applications in the context of intelligent manufacturing. Comput. Commun. 2020, 150, 413–420. [Google Scholar] [CrossRef]
- Arias, O.; Wurm, J.; Hoang, K.; Jin, Y. Privacy and Security in Internet of Things and Wearable Devices. IEEE Trans. Multi-Scale Comput. Syst. 2015, 1, 99–109. [Google Scholar] [CrossRef]
- Zhang, J.; Dai, M.; Su, Z. Task Allocation with Unmanned Surface Vehicles in Smart Ocean IoT. IEEE Internet Things J. 2020, 7, 9702–9713. [Google Scholar] [CrossRef]
- Lee, I.; Lee, K. The Internet of Things (IoT): Applications, investments, and challenges for enterprises. Bus. Horiz. 2015, 58, 431–440. [Google Scholar] [CrossRef]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, Present, and Future of Face Recognition: A Review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Premsankar, G.; Di Francesco, M.; Taleb, T. Edge Computing for the Internet of Things: A Case Study. IEEE Internet Things J. 2018, 5, 1275–1284. [Google Scholar] [CrossRef] [Green Version]
- Hu, L.; Tian, Y.; Yang, J.; Taleb, T.; Xiang, L.; Hao, Y. Ready Player One: UAV-Clustering-Based Multi-Task Offloading for Vehicular VR/AR Gaming. IEEE Netw. 2019, 33, 42–48. [Google Scholar] [CrossRef] [Green Version]
- Ning, H.; Farha, F.; Mohammad, Z.N.; Daneshmand, M. A Survey and Tutorial on “Connection Exploding Meets Efficient Communication” in the Internet of Things. IEEE Internet Things J. 2020, 7, 10733–10744. [Google Scholar] [CrossRef]
- Bouras, M.A.; Farha, F.; Ning, H. Convergence of Computing, Communication, and Caching in Internet of Things. Intell. Converg. Netw. 2020, 1, 18–36. [Google Scholar] [CrossRef]
- Reznik, A.; Murillo, L.M.C.; Fang, Y.; Featherstone, W.; Filippou, M.; Fontes, F.; Giust, F.; Huang, Q.; Li, A.; Turyagyenda, C.; et al. Cloud RAN and MEC: A Perfect Pairing; ETSI White Paper; ETSI: Sophia Antipolis, France, 2018; pp. 1–24. [Google Scholar]
- Hu, X.; Wang, L.; Wong, K.K.; Tao, M.; Zhang, Y.; Zheng, Z. Edge and Central Cloud Computing: A Perfect Pairing for High Energy Efficiency and Low-Latency. IEEE Trans. Wirel. Commun. 2020, 19, 1070–1083. [Google Scholar] [CrossRef]
- Han, Z.; Tan, H.; Li, X.Y.; Jiang, S.H.C.; Li, Y.; Lau, F.C.M. OnDisc: Online Latency-Sensitive Job Dispatching and Scheduling in Heterogeneous Edge-Clouds. IEEE/ACM Trans. Netw. 2019, 27, 2472–2485. [Google Scholar] [CrossRef]
- Li, L.; Guo, M.; Ma, L.; Mao, H.; Guan, Q. Online Workload Allocation via Fog-Fog-Cloud Cooperation to Reduce IoT Task Service Delay. Sensors 2019, 19, 3830. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meng, J.; Tan, H.; Li, X.Y.; Han, Z.; Li, B. Online Deadline-Aware Task Dispatching and Scheduling in Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1270–1286. [Google Scholar] [CrossRef]
- Wu, H.; Wolter, K.; Jiao, P.; Deng, Y.; Zhao, Y.; Xu, M. EEDTO: An Energy-Efficient Dynamic Task Offloading Algorithm for Blockchain-Enabled IoT-Edge-Cloud Orchestrated Computing. IEEE Internet Things J. 2021, 8, 2163–2176. [Google Scholar] [CrossRef]
- Ouyang, T.; Li, R.; Chen, X.; Zhou, Z.; Tang, X. Adaptive User-managed Service Placement for Mobile Edge Computing: An Online Learning Approach. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Paris, France, 29 April–2 May 2019; pp. 1468–1476. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, Z.; Guan, C.; Wolter, K.; Xu, M. Collaborate Edge and Cloud Computing with Distributed Deep Learning for Smart City Internet of Things. IEEE Internet Things J. 2020, 7, 8099–8110. [Google Scholar] [CrossRef]
- Alfakih, T.; Hassan, M.M.; Gumaei, A.; Savaglio, C.; Fortino, G. Task Offloading and Resource Allocation for Mobile Edge Computing by Deep Reinforcement Learning Based on SARSA. IEEE Access 2020, 8, 54074–54084. [Google Scholar] [CrossRef]
- Lakhan, A.; Li, X. Content Aware Task Scheduling Framework for Mobile Workflow Applications in Heterogeneous Mobile-Edge-Cloud Paradigms: CATSA Framework. In Proceedings of the 2019 IEEE Intl Conf on Parallel Distributed Processing with Applications, Big Data Cloud Computing, Sustainable Computing Communications, Social Computing Networking (ISPA/BDCloud/SocialCom/SustainCom), Xiamen, China, 16–18 December 2019; pp. 242–249. [Google Scholar] [CrossRef]
- De Maio, V.; Kimovski, D. Multi-objective Scheduling of Extreme Data Scientific Workflows in Fog. Future Gener. Comput. Syst. 2020, 106, 171–184. [Google Scholar] [CrossRef]
- Ding, S.; Yang, L.; Cao, J.; Cai, W.; Tan, M.; Wang, Z. Partitioning Stateful Data Stream Applications in Dynamic Edge Cloud Environments. IEEE Trans. Serv. Comput. 2021, 1, 1. [Google Scholar] [CrossRef]
- Wang, S.; Ding, Z.; Jiang, C. Elastic Scheduling for Microservice Applications in Clouds. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 98–115. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, W. Computation Offloading in Heterogeneous Mobile Edge Computing with Energy Harvesting. IEEE Trans. Green Commun. Netw. 2021, 5, 552–565. [Google Scholar] [CrossRef]
- Naouri, A.; Wu, H.; Nouri, N.A.; Dhelim, S.; Ning, H. A Novel Framework for Mobile-Edge Computing by Optimizing Task Offloading. IEEE Internet Things J. 2021, 8, 13065–13076. [Google Scholar] [CrossRef]
- Miao, Y.; Wu, G.; Li, M.; Ghoneim, A.; Al-Rakhami, M.; Hossain, M.S. Intelligent Task Prediction and Computation Offloading based on Mobile-Edge Cloud Computing. Future Gener. Comput. Syst. 2020, 102, 925–931. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A Fast and Elitist Multiobjective Genetic Algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Sun, H.; Yu, H.; Fan, G.; Chen, L. Energy and Time Efficient Task Offloading and Resource Allocation on the Generic IoT-Fog-Cloud Architecture. Peer-to-Peer Netw. Appl. 2020, 13, 548–563. [Google Scholar] [CrossRef]
- Liu, H.; Eldarrat, F.; Alqahtani, H.; Reznik, A.; de Foy, X.; Zhang, Y. Mobile Edge Cloud System: Architectures, Challenges, and Approaches. IEEE Syst. J. 2018, 12, 2495–2508. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the Strength Pareto Evolutionary Algorithm; Eidgenössische Technische Hochschule Zürich (ETH): Zürich, Switzerland, 2001. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Xu, X.; Wu, Q.; Qi, L.; Dou, W.; Tsai, S.B.; Bhuiyan, M.Z.A. Trust-Aware Service Offloading for Video Surveillance in Edge Computing Enabled Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1787–1796. [Google Scholar] [CrossRef]
- Strasser, S.; Goodman, R.; Sheppard, J.; Butcher, S. A New Discrete Particle Swarm Optimization Algorithm. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), Denver, CO, USA, 20–24 July 2016; pp. 53–60. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Description |
|---|---|
| U | the total number of tasks |
| K | the total number of edge servers |
| S | the total number of cloud servers |
| N | the total number of subtasks |
| u | index of tasks |
| k | index of edge devices |
| s | index of cloud devices |
| i | index of subtasks |
| index of the predecessor of the subtask | |
| the offloading decision factor to indicate whether the subtask is offloaded or not | |
| the offloading location factor to indicate the specific location where the subtask is offloaded | |
| the size of data to be transferred between and | |
| the CPU resources required to execute subtask | |
| the time when the subtask started to be executed | |
| the time when the subtask finished to be executed | |
| the CPU frequency of local device | |
| the CPU frequency of edge server | |
| the CPU frequency of cloud server | |
| the transmission rate between the end device and the edge server | |
| the transmission rate between the end device and the cloud server | |
| the transmission rate between the edge server and the cloud server | |
| B | wireless transmission channel bandwidth |
| channel gain | |
| transmission power of the end device for wireless transmission | |
| path loss between the end device and the edge server | |
| path loss between the end device and the cloud server | |
| the set of all predecessor nodes of subtask | |
| the total delay required for the execution of task u | |
| the CPU energy factors of the end device | |
| the CPU energy factors of the edge server | |
| the computing energy consumption of the task u | |
| the transmission energy consumption of the task u | |
| the total energy consumption |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| U | [20, 60] | 20 GHz | |
| K | [2, 10] | [1000, 1500] megacycles | |
| S | [1, 2] | [200, 500] kB | |
| N | [4, 12] | [1, 2] W | |
| B | 10 MHz | [2, 4] | |
| [0.5, 1] GHz | [0.0001, 0.0005] | ||
| [2, 10] GHz | 30 dBm |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Chen, H.; Xu, Z. SPMOO: A Multi-Objective Offloading Algorithm for Dependent Tasks in IoT Cloud-Edge-End Collaboration. Information 2022, 13, 75. https://doi.org/10.3390/info13020075
Liu L, Chen H, Xu Z. SPMOO: A Multi-Objective Offloading Algorithm for Dependent Tasks in IoT Cloud-Edge-End Collaboration. Information. 2022; 13(2):75. https://doi.org/10.3390/info13020075
Chicago/Turabian StyleLiu, Liu, Haiming Chen, and Zhengtao Xu. 2022. "SPMOO: A Multi-Objective Offloading Algorithm for Dependent Tasks in IoT Cloud-Edge-End Collaboration" Information 13, no. 2: 75. https://doi.org/10.3390/info13020075
APA StyleLiu, L., Chen, H., & Xu, Z. (2022). SPMOO: A Multi-Objective Offloading Algorithm for Dependent Tasks in IoT Cloud-Edge-End Collaboration. Information, 13(2), 75. https://doi.org/10.3390/info13020075