
Semantic–Structural Graph Convolutional Networks for Whole-Body Human Pose Estimation


Abstract
:1. Introduction
- The existing methods do not sufficiently utilize the positional and semantic information of whole-body keypoints to integrate human whole-body pose estimation;
- Previous works did not make full use of the semantic relationship among the body, hand, and face keypoints to guide pose estimation.
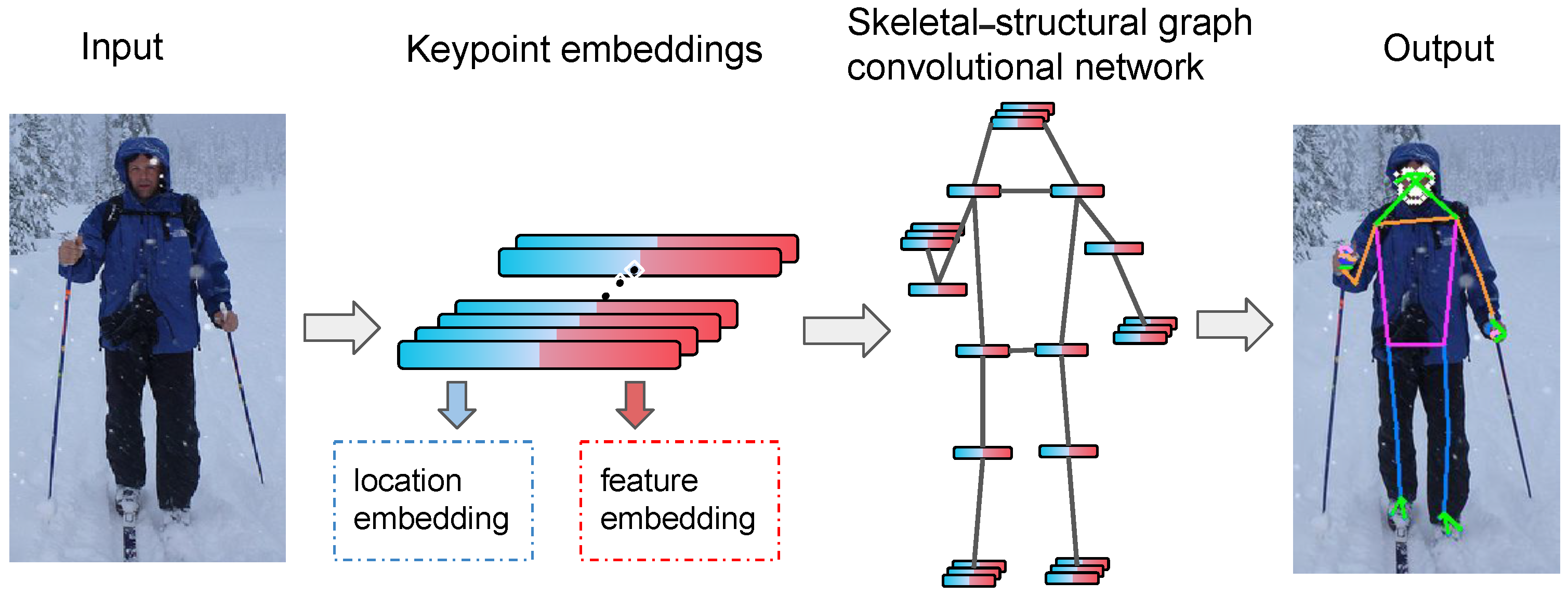
- This work presents a novel graph convolutional network framework for whole-body human pose estimation tasks, which leverages the whole-body graph structure to analyze the semantics of each part of the body through the graph convolutional network;
- We propose a novel heat-map-based keypoint embedding module, which encodes the position information and feature information of the keypoints of the human body;
- The proposed semantic–structural graph convolutional network consists of a structure-based graph layer to capture skeleton structure information and a data-dependent non-local layer to analyze the long-range grouped joint features;
- We represent groups of keypoints and construct a high-level abstract body graph to process the high-level semantic information of the whole-body keypoints.
2. Related Work
2.1. Human Pose Estimation
2.2. Whole-Body Pose Estimation
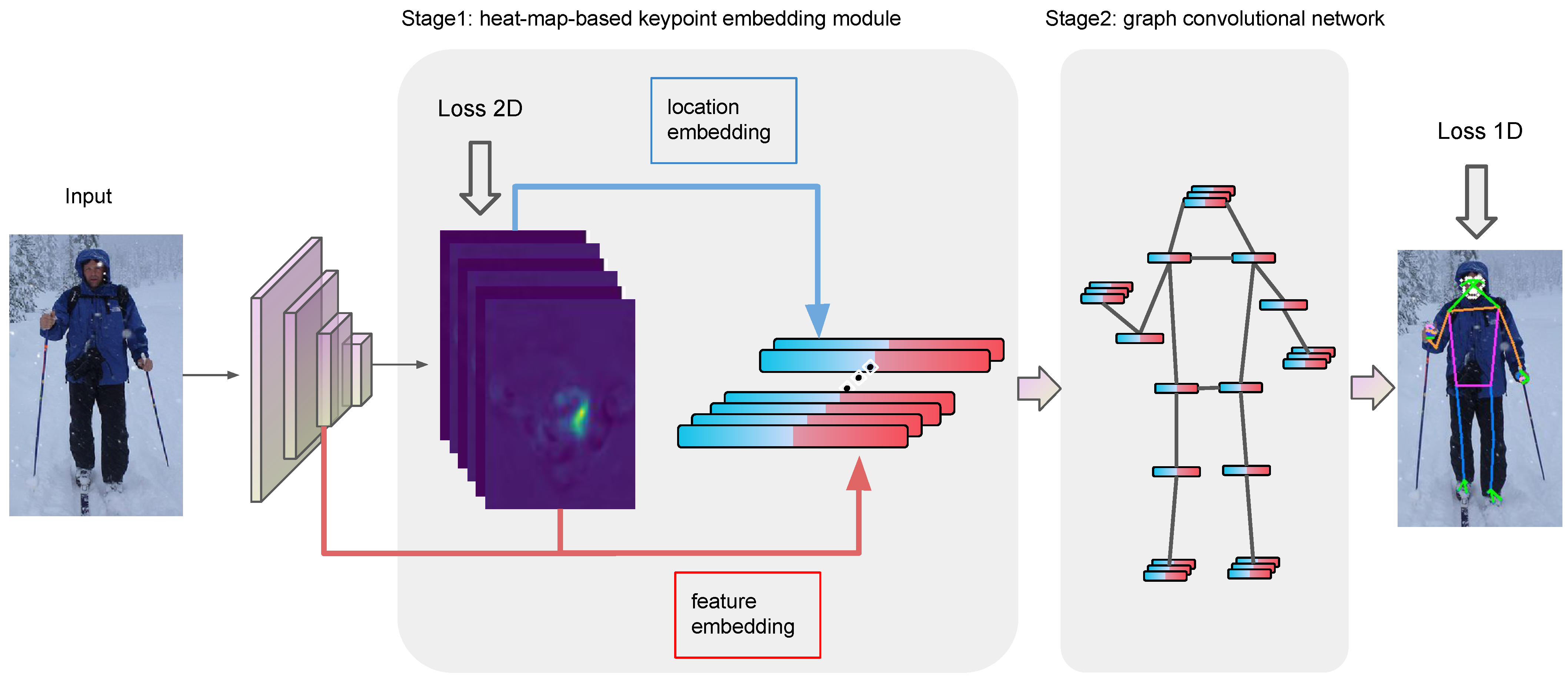
3. Heat-Map-Based Skeletal–Structural Graph Convolutional Network
3.1. One-Dimensional Heat-Map-Based Keypoint Embedding
3.1.1. Heat-Map-Based Keypoint Position Embedding
3.1.2. Heat-Map-Based Keypoint Feature Embedding
3.2. Skeletal–Structural Graph Convolutional Network
3.2.1. Structure-Based Graph Layer
3.2.2. Data-Dependent Non-Local Layer
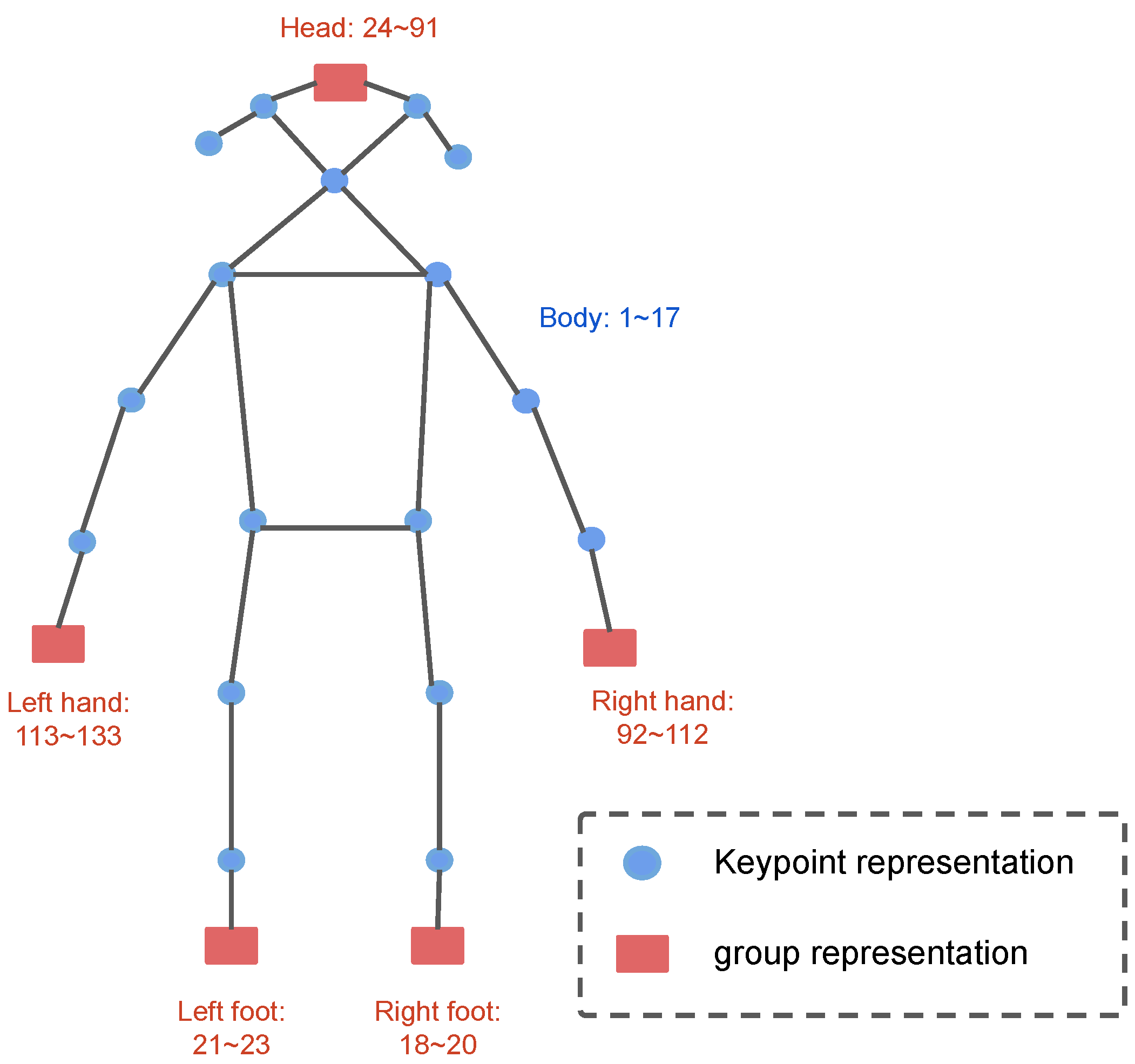
3.2.3. Keypoint Group Representations
3.3. Keypoint-Based Pose Estimation
3.4. Loss Functions
3.4.1. 2D Heat Map Loss
3.4.2. 1D Heat Map Loss
3.4.3. Overall Loss
4. Experiments and Results
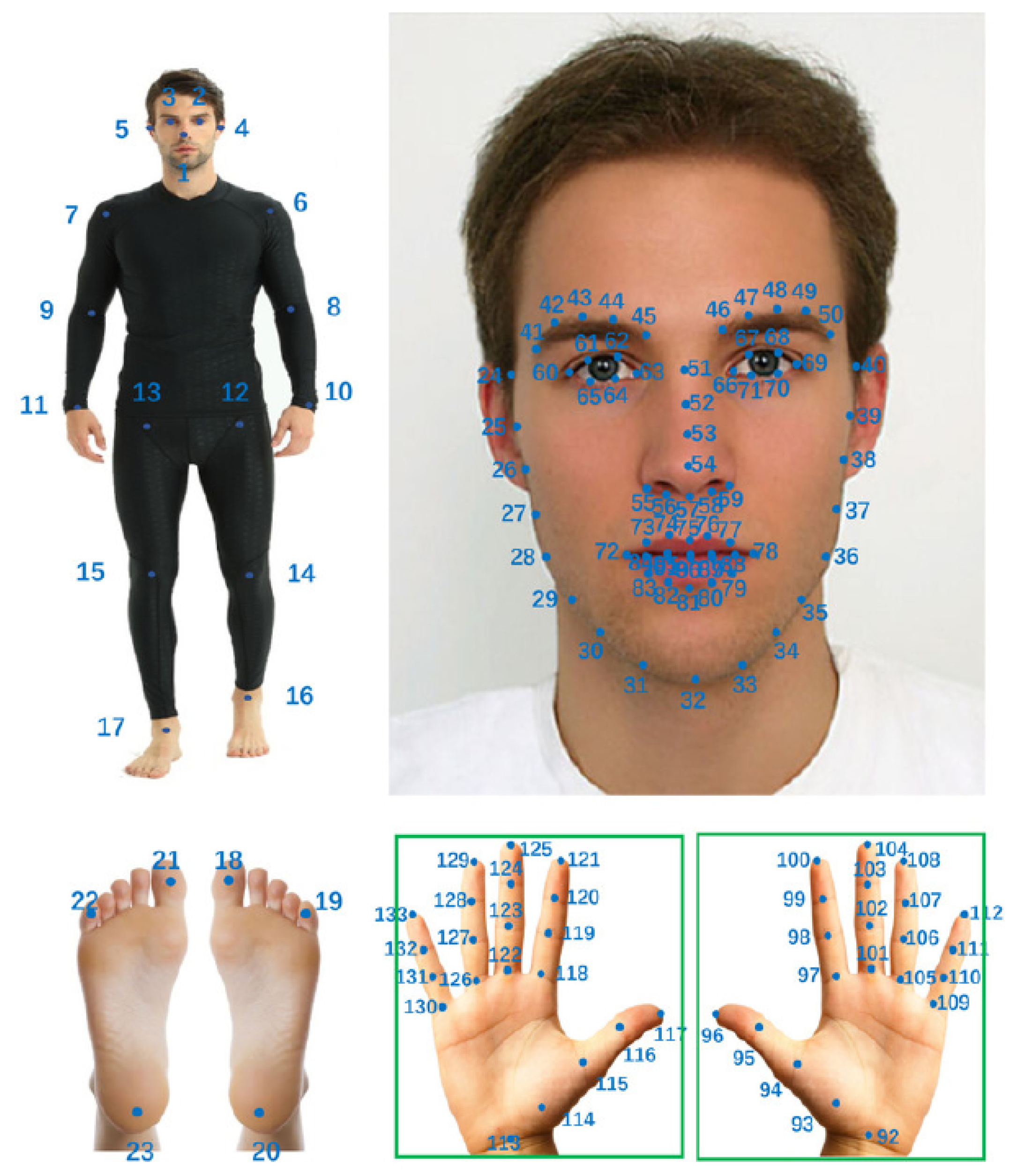
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Experimental Results
4.4. Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cimen, G.; Maurhofer, C.; Sumner, B.; Guay, M. Ar poser: Automatically augmenting mobile pictures with digital avatars imitating poses. In Proceedings of the 12th International Conference on Computer Graphics, Visualization, Computer Vision and Image Processing, Madrid, Spain, 18–20 July 2018. [Google Scholar]
- Elhayek, A.; Kovalenko, O.; Murthy, P.; Malik, J.; Stricker, D. Fully automatic multi-person human motion capture for vr applications. In Proceedings of the International Conference on Virtual Reality and Augmented Reality, London, UK, 22–23 October2018. [Google Scholar]
- Xu, W.; Chatterjee, A.; Zollhoefer, M.; Rhodin, H.; Fua, P.; Seidel, H.P.; Theobalt, C. Mo2cap2: Real-time mobile 3d motion capture with a cap-mounted fisheye camera. IEEE Trans. Vis. Comput. Graph. 2019, 25, 2093–2101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Choi, H.; Moon, G.; Lee, K.M. Pose2Mesh: Graph convolutional network for 3D human pose and mesh recovery from a 2D human pose. In Proceedings of the European Conference on Computer Vision, online, 23–28 August 2020. [Google Scholar]
- Kundu, J.N.; Rakesh, M.; Jampani, V.; Venkatesh, R.M.; Babu, R.V. Appearance Consensus Driven Self-supervised Human Mesh Recovery. In Proceedings of the European Conference on Computer Vision, online, 23–28 August 2020. [Google Scholar]
- Iqbal, U.; Xie, K.; Guo, Y.; Kautz, J.; Molchanov, P. KAMA: 3D Keypoint Aware Body Mesh Articulation. arXiv 2021, arXiv:2104.13502. [Google Scholar]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-end recovery of human shape and pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yan, A.; Wang, Y.; Li, Z.; Qiao, Y. PA3D: Pose-action 3D machine for video recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Huang, L.; Huang, Y.; Ouyang, W.; Wang, L. Part-aligned pose-guided recurrent network for action recognition. Pattern Recognit. 2019, 92, 165–176. [Google Scholar] [CrossRef]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2D/3d pose estimation and action recognition using multitask deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Moeslund, T.B.; Granum, E. A Survey of Computer Vision-Based Human Motion Capture. Comput. Vis. Image Underst. 2001, 81, 231–268. [Google Scholar] [CrossRef]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using Convolutional Networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Tompson, J.; Jain, A.; LeCun, Y.; Bregler, C. Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation. Adv. Neural Inf. Process. Syst. 2014, 1, 1799–1807. [Google Scholar]
- Ramakrishna, V.; Munoz, D.; Hebert, M.; Bagnell, J.A.; Sheikh, Y. Pose machines: Articulated pose estimation via inference machines. In Proceedings of the European Conference on Computer Vision, Zürich, Switzerland, 6–12 September 2014. [Google Scholar]
- Yang, W.; Li, S.; Ouyang, W.; Li, H.; Wang, X. Learning feature pyramids for human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Luo, Y.; Ren, J.; Wang, Z.; Sun, W.; Pan, J.; Liu, J.; Pang, J.; Lin, L. Lstm pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Artacho, B.; Savakis, A. UniPose: Unified Human Pose Estimation in Single Images and Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Athitsos, V.; Sclaroff, S. Estimating 3D hand pose from a cluttered image. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; Volume 2, p. II–432. [Google Scholar] [CrossRef] [Green Version]
- de La Gorce, M.; Fleet, D.J.; Paragios, N. Model-Based 3D Hand Pose Estimation from Monocular Video. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1793–1805. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, X.; Wei, Y.; Wen, F.; Sun, J. Face alignment by explicit shape regression. Int. J. Comput. Vis. 2014, 107, 177–190. [Google Scholar] [CrossRef]
- Tzimiropoulos, G. Project-out cascaded regression with an application to face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Trigeorgis, G.; Snape, P.; Nicolaou, M.A.; Antonakos, E.; Zafeiriou, S. Mnemonic descent method: A recurrent process applied for end-to-end face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Learning deep representation for face alignment with auxiliary attributes. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 918–930. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Hands deep in deep learning for hand pose estimation. In Proceedings of the 20th Computer Vision Winter Workshop, Seggau, Austria, 9–11 February 2015. [Google Scholar]
- Oberweger, M.; Lepetit, V. DeepPrior++: Improving Fast and Accurate 3D Hand Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Sharp, T.; Keskin, C.; Robertson, D.; Taylor, J.; Shotton, J.; Kim, D.; Rhemann, C.; Leichter, I.; Vinnikov, A.; Wei, Y.; et al. Accurate, robust, and flexible real-time hand tracking. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015. [Google Scholar]
- Sridhar, S.; Mueller, F.; Oulasvirta, A.; Theobalt, C. Fast and robust hand tracking using detection-guided optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, S.; Xu, L.; Xu, J.; Wang, C.; Liu, W.; Qian, C.; Ouyang, W.; Luo, P. Whole-body human pose estimation in the wild. In Proceedings of the European Conference on Computer Vision, online, 23–28 August 2020. [Google Scholar]
- Hidalgo, G.; Raaj, Y.; Idrees, H.; Xiang, D.; Joo, H.; Simon, T.; Sheikh, Y. Single-network whole-body pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2D pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zürich, Switzerland, 6–12 September 2014. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 1, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Samet, N.; Akbas, E. HPRNet: Hierarchical Point Regression for Whole-Body Human Pose Estimation. arXiv 2021, arXiv:2106.04269. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. arXiv 2018, arXiv:1801.07455. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 2, pp. 60–65. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Newell, A.; Deng, J.; Huang, Z. Associative Embedding: End-to-End Learning for Joint Detection and Grouping. Adv. Neural Inf. Process. Syst. 2017, 1, 2274–2284. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Body | Foot | Face | Hand | Whole-Body | All Mean | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | AR | AP | AR | AP | AR | AP | AR | AP | AR | AP | AR | |
| Baseline (HRNet-w32) | 65.9 | 70.9 | 31.4 | 42.4 | 52.0 | 58.2 | 30.0 | 36.3 | 43.2 | 52.0 | 44.6 | 51.9 |
| GCN | 68.5 | 73.4 | 43.5 | 55.3 | 54.6 | 63.5 | 39.1 | 44.8 | 48.0 | 57.5 | 50.7 | 58.9 |
| GCN + IS | 74.2 | 79.6 | 79.1 | 84.9 | 63.2 | 73.7 | 47.0 | 58.8 | 54.5 | 66.6 | 63.6 | 72.7 |
| GCN + IS + Group (Full) | 73.8 | 79.3 | 80.7 | 87.1 | 75.9 | 87.9 | 52.5 | 65.2 | 55.0 | 67.2 | 67.5 | 77.3 |
| Method | Body | Foot | Face | Hand | Whole-Body | All Mean | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | AR | AP | AR | AP | AR | AP | AR | AP | AR | AP | AR | |
| Bottom-up methods: | ||||||||||||
| PAF [35] | 26.6 | 32.8 | 10.0 | 25.7 | 30.9 | 36.2 | 13.3 | 32.1 | 14.1 | 18.5 | 19.0 | 29.1 |
| SN [34] | 28.0 | 33.6 | 12.1 | 27.7 | 38.2 | 44.0 | 13.8 | 33.6 | 16.1 | 20.9 | 21.6 | 32.0 |
| AE [45] | 40.5 | 46.4 | 7.7 | 16.0 | 47.7 | 58.0 | 34.1 | 43.5 | 27.4 | 35.0 | 31.5 | 39.8 |
| HPRNet [40] | 59.4 | 68.3 | 53.0 | 65.4 | 75.4 | 86.8 | 50.4 | 64.2 | 34.8 | 49.2 | 54.6 | 66.8 |
| Top-down methods: | ||||||||||||
| OpenPose [32] | 56.3 | 61.2 | 53.2 | 64.5 | 48.2 | 62.6 | 19.8 | 34.2 | 33.8 | 44.9 | 42.3 | 53.5 |
| HRNet [38] | 65.9 | 70.9 | 31.4 | 42.4 | 52.3 | 58.2 | 30.0 | 36.3 | 43.2 | 52.0 | 44.6 | 51.9 |
| ZoomNet [33] | 74.3 | 80.2 | 79.8 | 86.9 | 62.3 | 70.1 | 40.1 | 49.8 | 54.1 | 65.8 | 62.1 | 70.6 |
| Ours | 73.8 | 79.3 | 80.7 | 87.1 | 75.9 | 87.9 | 52.5 | 65.2 | 55.0 | 67.2 | 67.5 | 77.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Du, R.; Chen, S. Semantic–Structural Graph Convolutional Networks for Whole-Body Human Pose Estimation. Information 2022, 13, 109. https://doi.org/10.3390/info13030109
Li W, Du R, Chen S. Semantic–Structural Graph Convolutional Networks for Whole-Body Human Pose Estimation. Information. 2022; 13(3):109. https://doi.org/10.3390/info13030109
Chicago/Turabian StyleLi, Weiwei, Rong Du, and Shudong Chen. 2022. "Semantic–Structural Graph Convolutional Networks for Whole-Body Human Pose Estimation" Information 13, no. 3: 109. https://doi.org/10.3390/info13030109
APA StyleLi, W., Du, R., & Chen, S. (2022). Semantic–Structural Graph Convolutional Networks for Whole-Body Human Pose Estimation. Information, 13(3), 109. https://doi.org/10.3390/info13030109