
Local Transformer Network on 3D Point Cloud Semantic Segmentation


Abstract
:1. Introduction
- We propose a novel multi-scale transformer network to learn local context information and global features, which makes applying the transformer on more sophisticated tasks from the large-scale point cloud datasets possible.
- In order to obtain the feature similarity and local geometry relationship between points, we propose two different key matrices to obtain two attention weight matrices in the local transformer structure, and propose two different fusion strategies to fuse them.
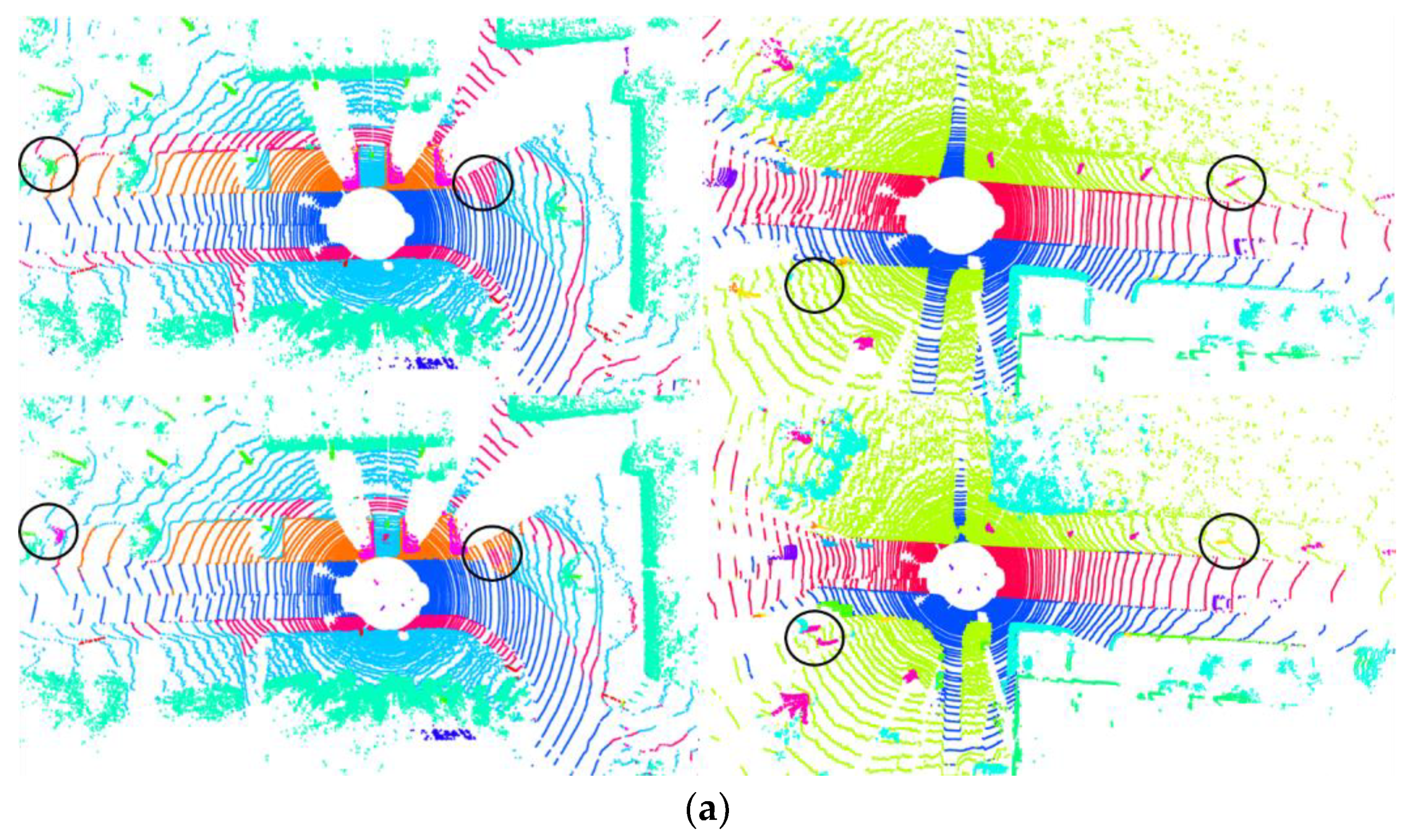
- We also propose a novel neighbor selection method called cross-skip selection to obtain more accurate results on the junction of multiple objects.
2. Related Work
3. Proposed Approach
3.1. Network Architecture
3.2. Neighbor Embedding Module
3.3. Feature Extraction Module based on a Transformer
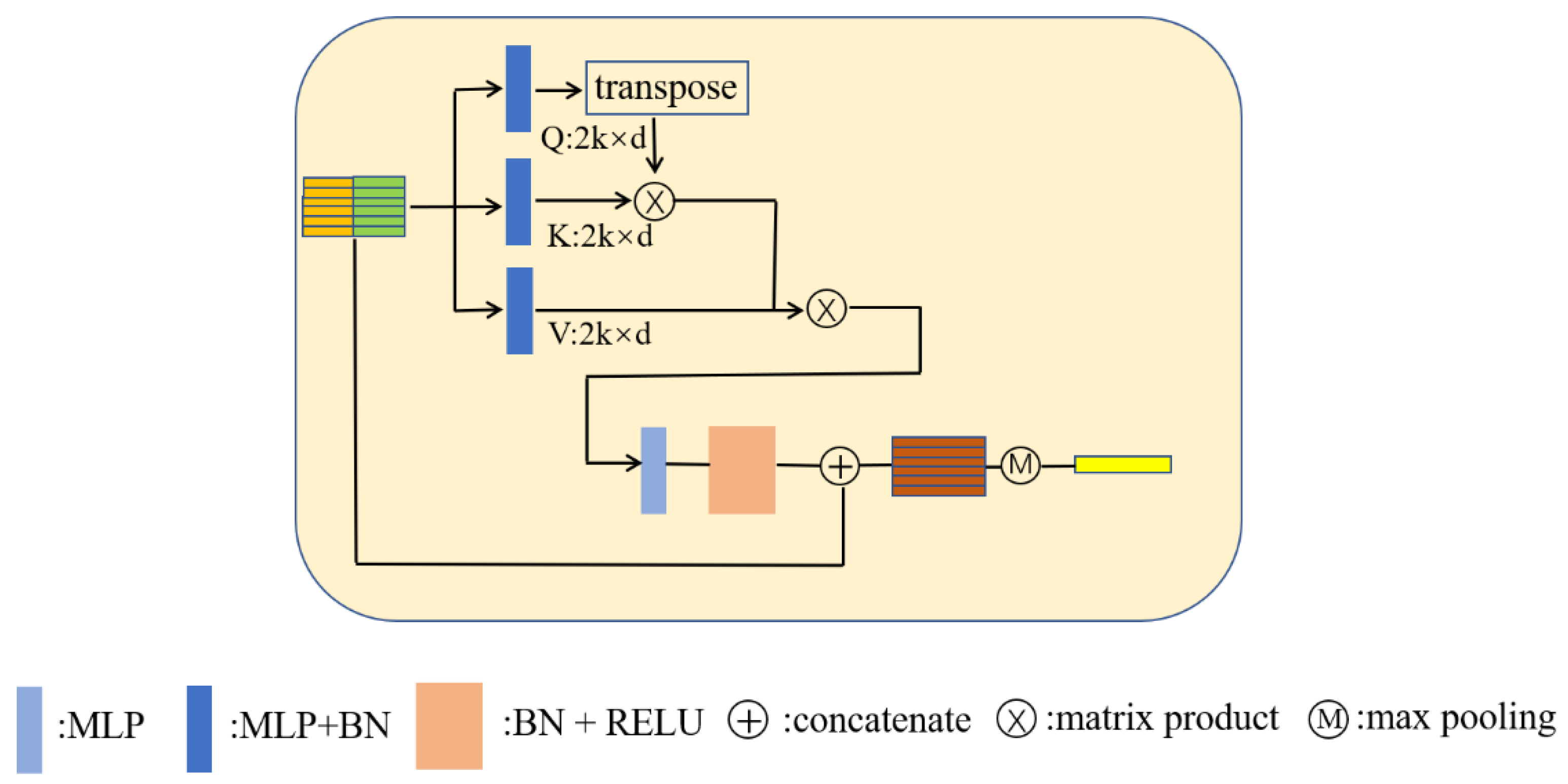
3.3.1. Naïve Transformer Structure
3.3.2. Improve Transformer Structure
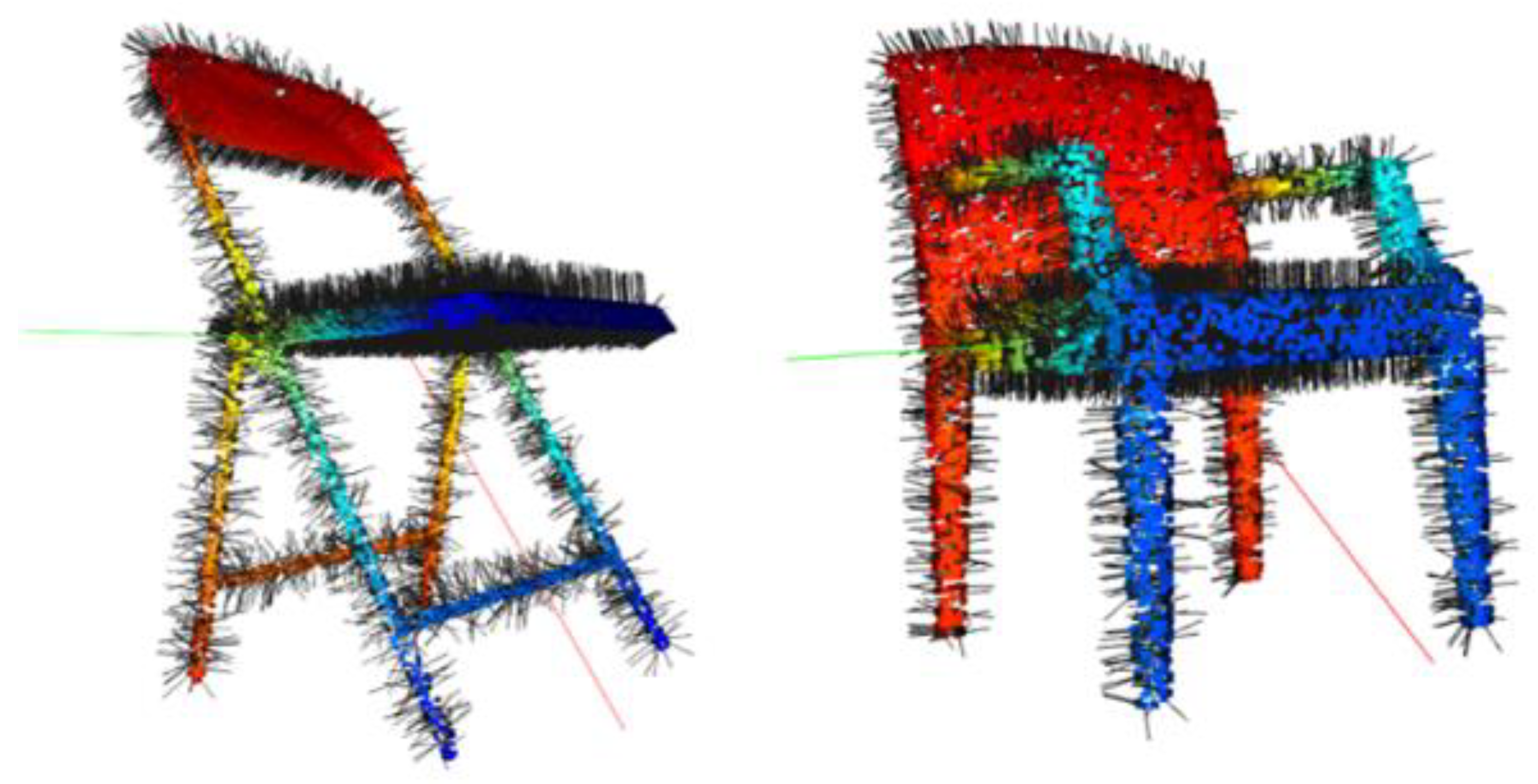
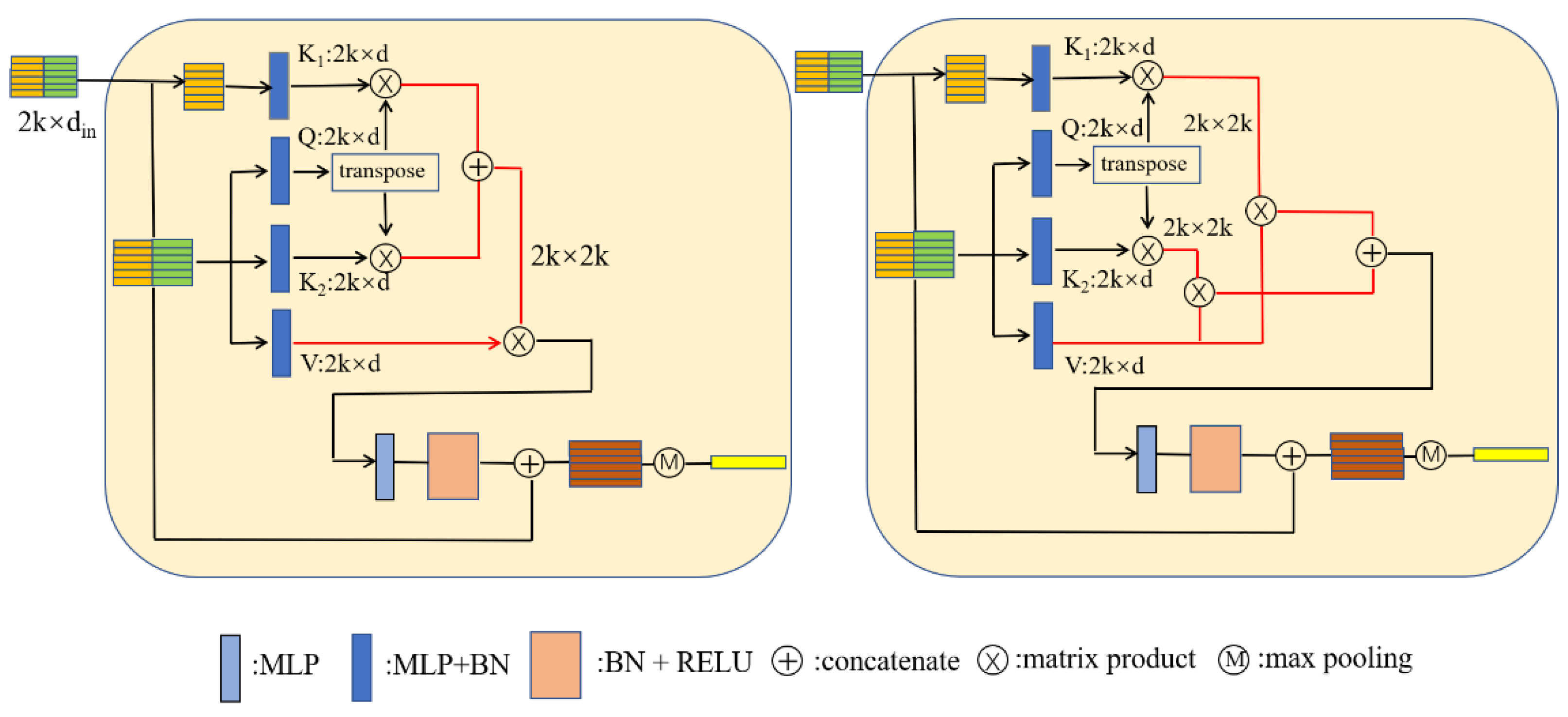
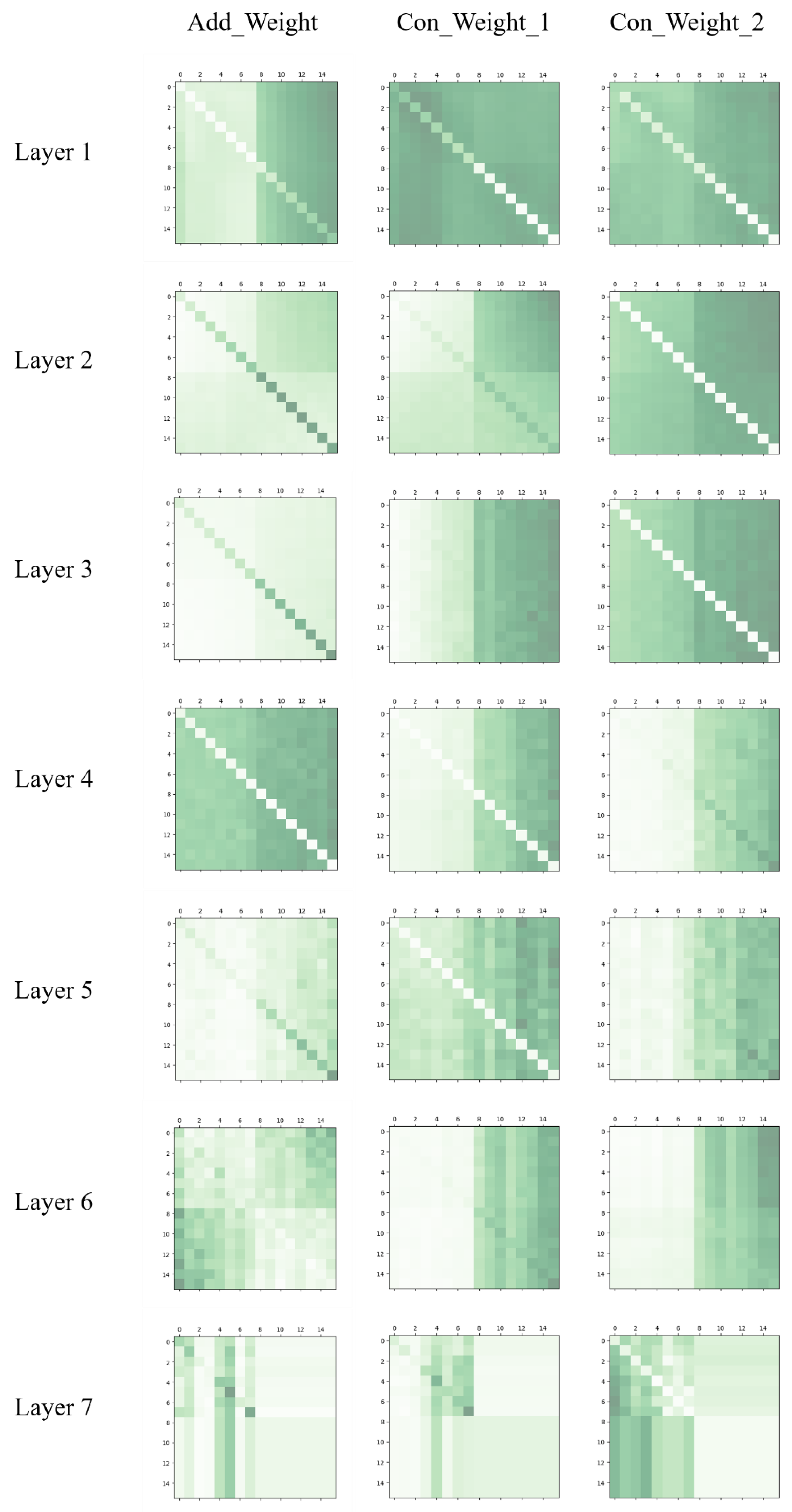
3.4. Local Transformer Structure
3.5. Parallel Encoder Layer with Cross-Skip Selection
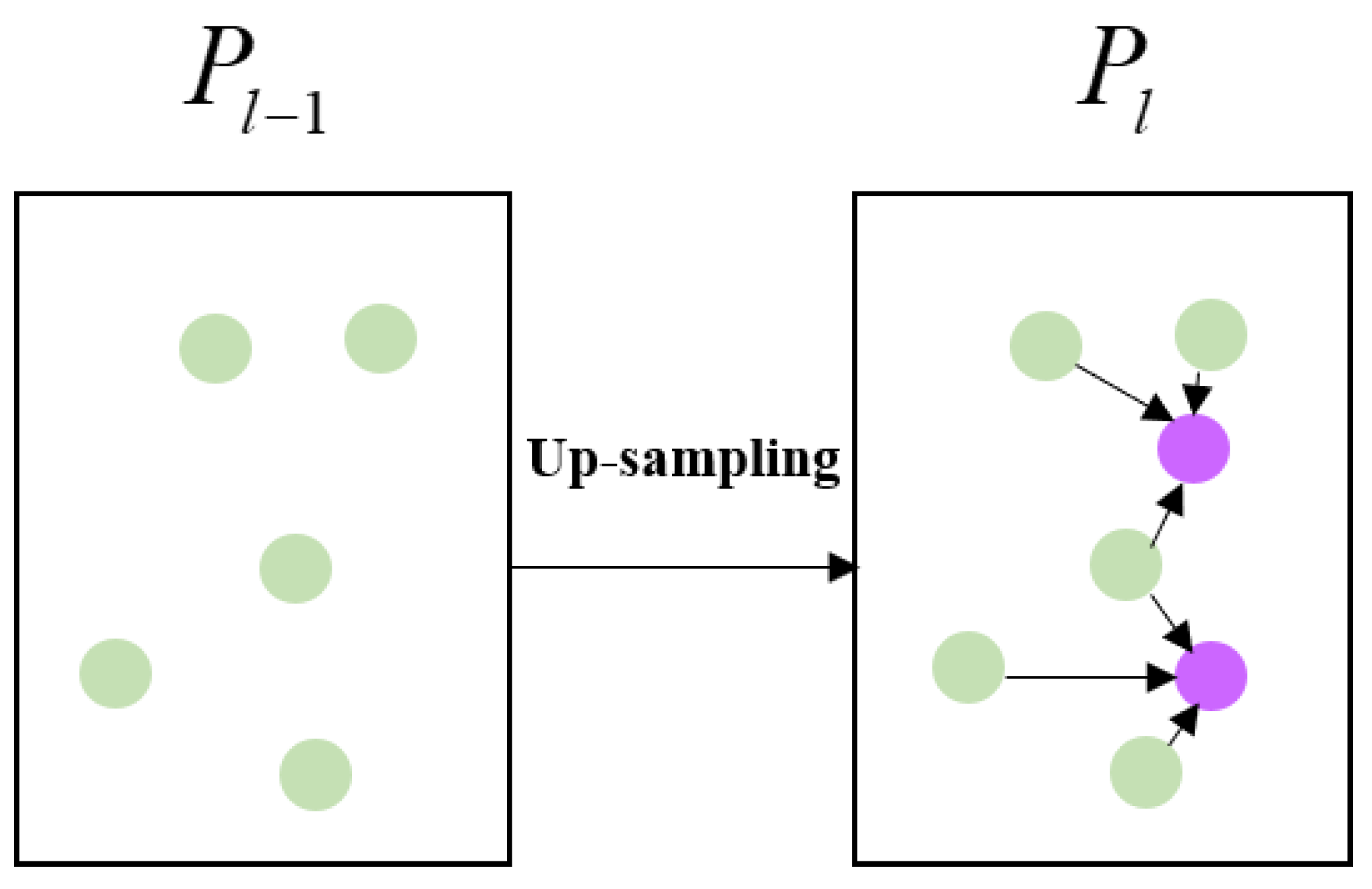
3.6. Decoder Layer
4. Experiments and Analysis
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Experimental Results
4.5. Ablation Experiment
4.5.1. Naïve Local Transformer Structure and Improved Local Transformer Structure
4.5.2. Cross-Skip Selection Method
4.5.3. Normal Feature
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Tran, L.V.; Lin, H.Y. BiLuNetICP: A Deep Neural Network for Object Semantic Segmentation and 6D Pose Recognition. IEEE Sens. J. 2021, 21, 11748–11757. [Google Scholar] [CrossRef]
- Claudine, B.; Rânik, G.; Raphael, V.C.; Pedro, A.; Vinicius, B.C.; Avelino, F.; Luan, J.; Rodrigo, B.; Thiago, M.P.; Filipe, M.; et al. Self-Driving Cars: A Survey. Expert Syst. Appl. 2021, 165, 113816. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, Uncertainty-Aware Semantic Segmentation of LiDAR Point Clouds. arXiv 2020, arXiv:2003.03653. [Google Scholar]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Gong, B.; Foroosh, H. PolarNet: An Improved Grid Representation for Online LiDAR Point Clouds Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 9598–9607. [Google Scholar]
- Rao, Y.; Lu, J.; Zhou, J. Spherical Fractal Convolutional Neural Networks for Point Cloud Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27–28 October 2019; pp. 452–460. [Google Scholar]
- Gerdzhev, M.; Razani, R.; Taghavi, E.; Liu, B. TORNADO-Net: MulTiview tOtal vaRiatioN semAntic segmentation with Diamond inception module. In Proceedings of the IEEE international Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 9543–9549. [Google Scholar]
- Zhou, Z.; Zhang, Y.; Foroosh, H. Panoptic-PolarNet: Proposal-Free LIDAR Point Cloud Panoptic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13194–13203. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.; Koltun, V. Point Transformer. arXiv 2020, arXiv:2012.09164. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Macau, China, 4–8 November 2019; pp. 4213–4220. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the International Conference on Robotics and Automation, Orlando, FL, USA, 21–26 May 2018; pp. 1887–1893. [Google Scholar]
- Liong, V.E.; Nguyen, T.N.T.; Widjaja, S.; Sharma, D.; Chong, Z.J. AMVNet: Assertion-based Multi-View Fusion Network for LiDAR Semantic Segmentation. arXiv 2020, arXiv:2012.04934. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Graham, B.; Engelcke, M.; Maaten, L.V.D. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9224–9232. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–7 December 2017; pp. 5105–5114. [Google Scholar]
- Wu, W.; Qi, Z.; Li, F. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9613–9622. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C. PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5560–5568. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6410–6419. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, A.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11105–11114. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Transact. Graph. 2019, 149, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10288–10297. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Li, Y.; Zhang, K.; Gao, J. LocalViT: Bringing Locality to Vision Transformers. arXiv 2021, arXiv:2104.05707. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2D-3D-semantic data for indoor scene understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Hackel, T.; Savimov, N.; LADICKY, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3D.net: A new Large-scale Point Cloud Classification Benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar] [CrossRef] [Green Version]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9297–9307. [Google Scholar]
- Tatarchenko, M.; Park, J.; Koltun, V.; Zhou, Q. Tangent Convolutions for Dense Prediction in 3D. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3887–3896. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. arXiv 2018, arXiv:1801.07791. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4558–4567. [Google Scholar]
- Qiu, S.; Anwar, S.; Barnes, N. Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1757–1767. [Google Scholar]
- Boulch, A.; Puy, G.; Marlet, R. FKAConv: Feature-Kernel Alignment for Point Cloud Convolution. In Proceedings of the Asian Conference on Computer Vision, Cham, Switzerland, 30 November–4 December 2020. [Google Scholar]
- Fan, S.; Dong, Q.; Zhu, F.; Lv, Y.; Ye, P.; Wang, F.Y. SCF-Net: Learning Spatial Contextual Features for Large-Scale Point Cloud Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14499–14508. [Google Scholar]
- Zhang, Z.; Hua, B.S.; Yeung, S.K. ShellNet: Efficient Point Cloud Convolutional Neural Networks using Concentric Shells Statistics. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1607–1616. [Google Scholar]
- Truong, G.; Gilani, S.Z.; Islam, S.M.S.; Suter, D. Fast Point Cloud Registration using Semantic Segmentation. In Proceedings of the Digital Image Computing: Techniques and Applications, Perth, Australia, 2–4 December 2019; pp. 1–8. [Google Scholar]
- Gong, J.; Xu, J.; Tan, X.; Song, H.; Qu, Y.; Xie, Y.; Ma, L. Omni-supervised Point Cloud Segmentation via Gradual Receptive Field Component Reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11668–11677. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the International Conference on Robotics and Automation, Montreal, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | OA | mAcc | mIoU | Ceiling | Floor | Wall | Beam | Column | Window | Door | Table | Chair | Sofa | Bookcase | Board | Clutter |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TangentConv [28] | - | 62.2 | 52.6 | 90.5 | 97.7 | 74.0 | 0.0 | 20.7 | 39.0 | 31.3 | 77.5 | 69.4 | 57.3 | 38.5 | 48.8 | 39.8 |
| PointCNN [29] | 85.9 | 63.9 | 57.3 | 92.3 | 98.2 | 79.4 | 0.0 | 17.6 | 22.8 | 62.1 | 74.4 | 80.6 | 31.7 | 66.7 | 62.1 | 56.7 |
| SPG [30] | 86.4 | 66.5 | 58.0 | 89.4 | 96.9 | 78.1 | 0.0 | 42.8 | 48.9 | 61.6 | 84.7 | 75.4 | 69.8 | 52.6 | 2.1 | 52.2 |
| PointWeb [17] | 87.0 | 66.6 | 60.3 | 92.0 | 98.5 | 79.4 | 0.0 | 21,1 | 59.7 | 34.8 | 76.3 | 88.3 | 46.9 | 69.3 | 64.9 | 52.5 |
| KPConv [18] | - | 72.8 | 67.1 | 92.8 | 97.3 | 82.4 | 0.0 | 23.9 | 58.0 | 69.0 | 81.5 | 91.0 | 75.4 | 75.3 | 66.7 | 58.9 |
| BAAF-Net [31] | 88.9 | 73.1 | 65.4 | 92.9 | 97.9 | 82.3 | 0.0 | 23.1 | 65.5 | 64.9 | 78.5 | 87.5 | 61.4 | 70.7 | 68.7 | 57.2 |
| Ours(add) | 87.6 | 71.9 | 64.1 | 92.8 | 97.4 | 79.9 | 0.0 | 22.6 | 59.4 | 52.7 | 77.0 | 87.6 | 73.3 | 70.4 | 66.8 | 53.1 |
| Ours(con) | 87.8 | 72.1 | 63.7 | 91.8 | 97.7 | 82.1 | 0.0 | 26.9 | 58.6 | 51.7 | 78.8 | 86.6 | 62.0 | 70.8 | 68.5 | 52.4 |
| Methods | OA | mAcc | mIoU | Ceiling | Floor | Wall | Beam | Column | Window | Door | Table | Chair | Sofa | Bookcase | Board | Clutter |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SPG [30] | 85.5 | 73.0 | 62.1 | 89.9 | 95.1 | 76.4 | 62.8 | 47.1 | 55.3 | 68.4 | 73.5 | 69.2 | 63.2 | 45.9 | 8.7 | 52.9 |
| PointWeb [17] | 87.3 | 76.2 | 66.7 | 93.5 | 94.2 | 80.8 | 52.4 | 41.3 | 64.9 | 68.1 | 71.4 | 67.1 | 50.3 | 62.7 | 62.2 | 58.5 |
| KPConv [18] | - | 79.1 | 70.6 | 93.6 | 92.4 | 83.1 | 63.9 | 54.3 | 66.1 | 76.6 | 64.0 | 57.8 | 74.9 | 69.3 | 61.3 | 60.3 |
| FKAConv [32] | - | - | 68.4 | 94.5 | 98.0 | 82.9 | 41.0 | 46.0 | 57.8 | 74.1 | 71.7 | 77.7 | 60.3 | 65.0 | 55.0 | 65.5 |
| SCF-Net [33] | 88.4 | 82.7 | 71.6 | 93.3 | 96.4 | 80.9 | 64.9 | 47.4 | 64.5 | 70.1 | 71.4 | 81.6 | 67.2 | 64.4 | 67.5 | 60.9 |
| BAAF-Net [31] | 88.9 | 83.1 | 72.2 | 93.3 | 96.8 | 81.6 | 61.9 | 49.5 | 65.4 | 73.3 | 72.0 | 83.7 | 67.5 | 64.3 | 67.0 | 62.4 |
| Ours(add) | 87.4 | 80.1 | 68.8 | 92.8 | 97.0 | 80.0 | 58.2 | 48.5 | 62.4 | 68.7 | 71.7 | 70.2 | 58.9 | 63.3 | 65.6 | 57.3 |
| Ours(con) | 87.7 | 80.1 | 69.1 | 93.2 | 96.8 | 80.4 | 56.5 | 48.0 | 63.4 | 69.8 | 71.5 | 69.4 | 63.0 | 64.0 | 64.0 | 58.7 |
| Methods | mIoU | OA | Man-Made | Natural. | High Veg. | Low veg. | Buildings | Hard Scape | Scanning Art. | Cars |
|---|---|---|---|---|---|---|---|---|---|---|
| ShellNet [34] | 69.3 | 93.2 | 96.3 | 90.4 | 83.9 | 41.0 | 94.2 | 34.7 | 43.9 | 70.2 |
| KPConv [18] | 74.6 | 92.9 | 90.9 | 82.2 | 84.2 | 47.9 | 94.9 | 40.0 | 77.3 | 79.7 |
| RGNet [35] | 74.7 | 94.5 | 97.5 | 93.0 | 88.1 | 48.1 | 94.6 | 36.2 | 72.0 | 68.0 |
| RandLA-Net [19] | 77.4 | 94.8 | 95.6 | 91.4 | 86.6 | 51.5 | 95.7 | 51.5 | 69.8 | 79.7 |
| BAAF-Net [31] | 75.4 | 94.9 | 97.9 | 95.0 | 70.6 | 63.1 | 94.2 | 41.6 | 50.2 | 90.3 |
| RFCR [36] | 77.8 | 94.3 | 94.2 | 89.1 | 85.7 | 54.4 | 95.0 | 43.8 | 76.2 | 83.7 |
| Ours(add) | 74.4 | 94.0 | 96.7 | 92.4 | 85.6 | 50.5 | 93.5 | 31.4 | 63.8 | 81.2 |
| Ours(con) | 75.7 | 94.3 | 97.0 | 93.4 | 88.2 | 49.9 | 94.1 | 34.8 | 67.8 | 80.6 |
| Methods | mIoU | Road | Sidewalk | Parking | Other-Ground | Building | Car | Truck | Bicycle | Motorcycle | Other-vehicle | Vegetation | Trunk | Terrain | Person | Bicyclist | Motorcyclist | Fence | Pole | Traffic-sign | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SqueezeSge [10] | 29.5 | 85.4 | 54.3 | 26.9 | 4.5 | 57.4 | 68.8 | 3.3 | 16.0 | 4.1 | 3.6 | 60.0 | 24.3 | 53.7 | 12.9 | 13.1 | 0.9 | 29.0 | 17.5 | 24.5 | |
| TangentConv [28] | 40.9 | 83.9 | 63.9 | 33.4 | 15.4 | 83.4 | 90.8 | 15.2 | 2.7 | 16.5 | 12.1 | 79.5 | 49.3 | 58.1 | 23.0 | 28.4 | 8.1 | 49.0 | 35.8 | 28.5 | |
| SqueezeSegV2 [37] | 39.7 | 88.6 | 67.6 | 45.8 | 17.7 | 73.7 | 81.8 | 13.4 | 18.5 | 17.9 | 14.0 | 71.8 | 35.8 | 60.2 | 20.1 | 25.1 | 3.9 | 41.1 | 20.2 | 36.3 | |
| DarkNet53Seg [27] | 49.9 | 91.8 | 74.6 | 64.8 | 27.9 | 84.1 | 86.4 | 25.5 | 24.5 | 24.5 | 22.6 | 78.3 | 50.1 | 64.0 | 36.2 | 33.6 | 4.7 | 55.0 | 38.9 | 52.2 | |
| RandLA-Net [19] | 53.9 | 90.7 | 73.7 | 60.3 | 20.4 | 86.9 | 94.2 | 40.1 | 26.0 | 25.8 | 38.9 | 81.4 | 61.3 | 66.8 | 49.2 | 48.2 | 7.2 | 56.3 | 49.2 | 47.7 | |
| PolarNet [4] | 54.3 | 90.8 | 74.4 | 61.7 | 21.7 | 90.0 | 93.8 | 22.9 | 40.3 | 30.1 | 28.5 | 84.0 | 65.5 | 67.8 | 43.2 | 40.2 | 5.6 | 67.8 | 51.8 | 57.5 | |
| Ours(add) | 49.8 | 89.7 | 71.2 | 58.1 | 29.2 | 86.6 | 92.4 | 40.6 | 44.1 | 21.8 | 29.2 | 79.6 | 60.3 | 62.1 | 45.5 | 44.1 | 3.5 | 54.9 | 46.0 | 36.9 | |
| Ours(con) | 49.3 | 89.4 | 69.7 | 57.4 | 5.7 | 85.7 | 92.6 | 28.7 | 19.3 | 27.2 | 26.5 | 80.0 | 61.3 | 60.6 | 47.7 | 45.2 | 1.0 | 51.2 | 48.4 | 39.7 | |
| Methods | OA | mAcc | mIoU |
|---|---|---|---|
| Naïve | 86.8 | 70.3 | 62.6 |
| Without cross-skip selection | 87.0 | 70.1 | 62.5 |
| Without normal | 87.1 | 68.9 | 61.6 |
| Improved | 87.6 | 71.9 | 64.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Wang, Y.; An, L.; Liu, J.; Liu, H. Local Transformer Network on 3D Point Cloud Semantic Segmentation. Information 2022, 13, 198. https://doi.org/10.3390/info13040198
Wang Z, Wang Y, An L, Liu J, Liu H. Local Transformer Network on 3D Point Cloud Semantic Segmentation. Information. 2022; 13(4):198. https://doi.org/10.3390/info13040198
Chicago/Turabian StyleWang, Zijun, Yun Wang, Lifeng An, Jian Liu, and Haiyang Liu. 2022. "Local Transformer Network on 3D Point Cloud Semantic Segmentation" Information 13, no. 4: 198. https://doi.org/10.3390/info13040198
APA StyleWang, Z., Wang, Y., An, L., Liu, J., & Liu, H. (2022). Local Transformer Network on 3D Point Cloud Semantic Segmentation. Information, 13(4), 198. https://doi.org/10.3390/info13040198