
Attention-Based Transformer-BiGRU for Question Classification


Abstract
:1. Introduction
- A brief introduction to traditional machine learning question classification models based on statistical methods is presented.
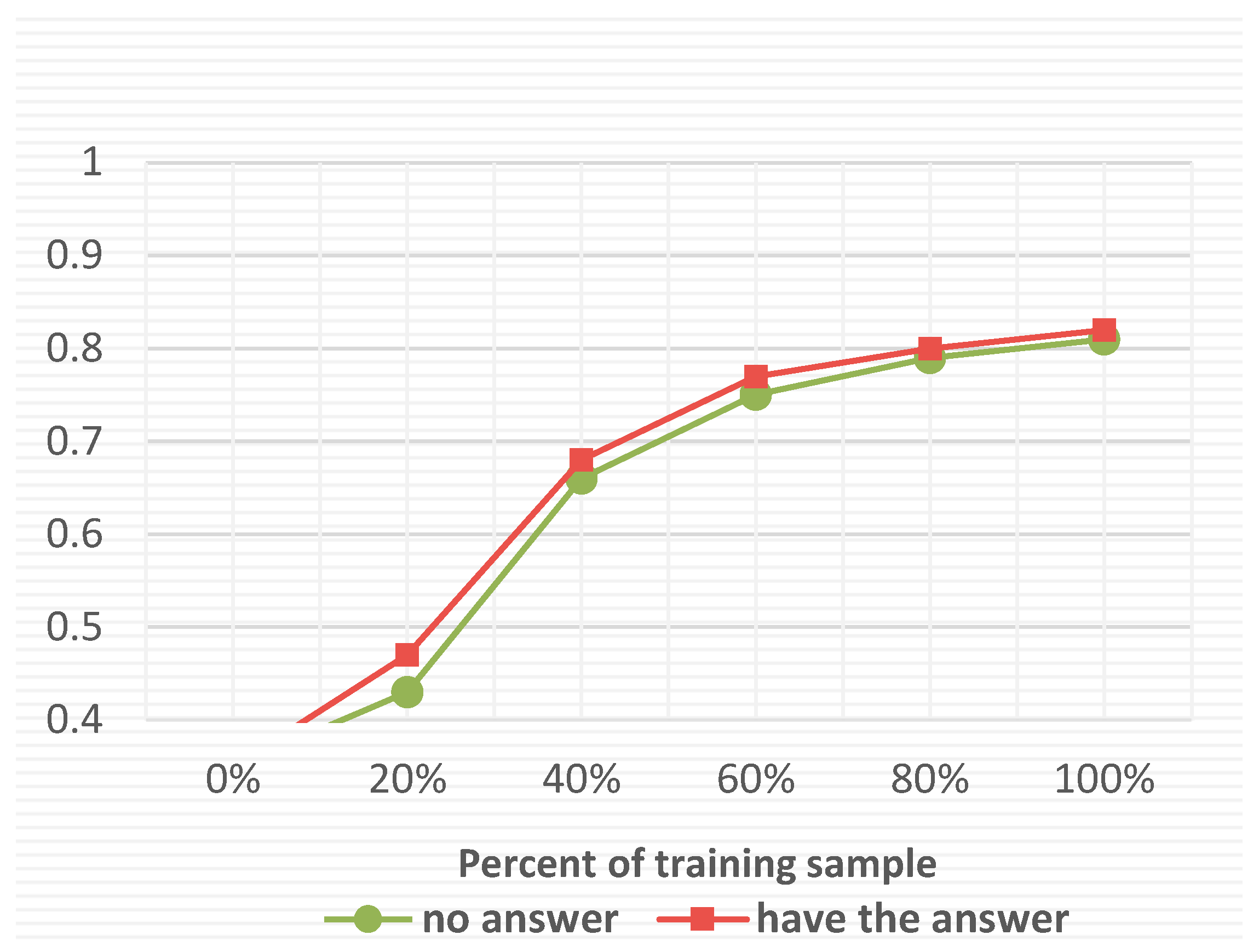
- There is no unified public dataset for the Chinese question and answer corpus compared to the English question and answer corpus, and the small amount of corpora for Chinese question classification and insufficient resources is one of the main reasons that restrict the accuracy of question classification. To solve the problem, thousands of question and answer sentences were captured from Chinese community question and answer platforms, including Baidu Know and Sogou Q&A, and the categories were manually marked and the missing and noisy samples were processed, finally, after manual verification. In addition, the difficulty of short questions with little information can be better solved by combining the answer information of the question with the classification of the question. Through experimental comparison, it is found that the question sentence containing the information-rich features of the answer has a better classification effect than the single question sentence.
- For longer question sentences that contain answer information, a hybrid neural network (TBGA) model that combines Transformer and Bi-GRU and includes the Attention mechanism is used. The input of Transformer’s encoder is the sum of word vector and position vector, which can obtain the relationship between words and capture the internal characteristics of question sentences; Bi-GRU can consider the context on the basis of a time series and has good dependence on long sequences. The effect of longer question information can also be captured well. The introduction of Attention can highlight the key feature information based on the features extracted from the above network, thus avoiding complicated words and lengthy interrogative sentences from affecting the classification results. In addition, the answer content of question sentences is introduced to enhance the information of question sentences, which ultimately improves the efficiency and accuracy of question sentence classification. The experimental results show that the question classification method used in this question helps to improve the accuracy of question classification.
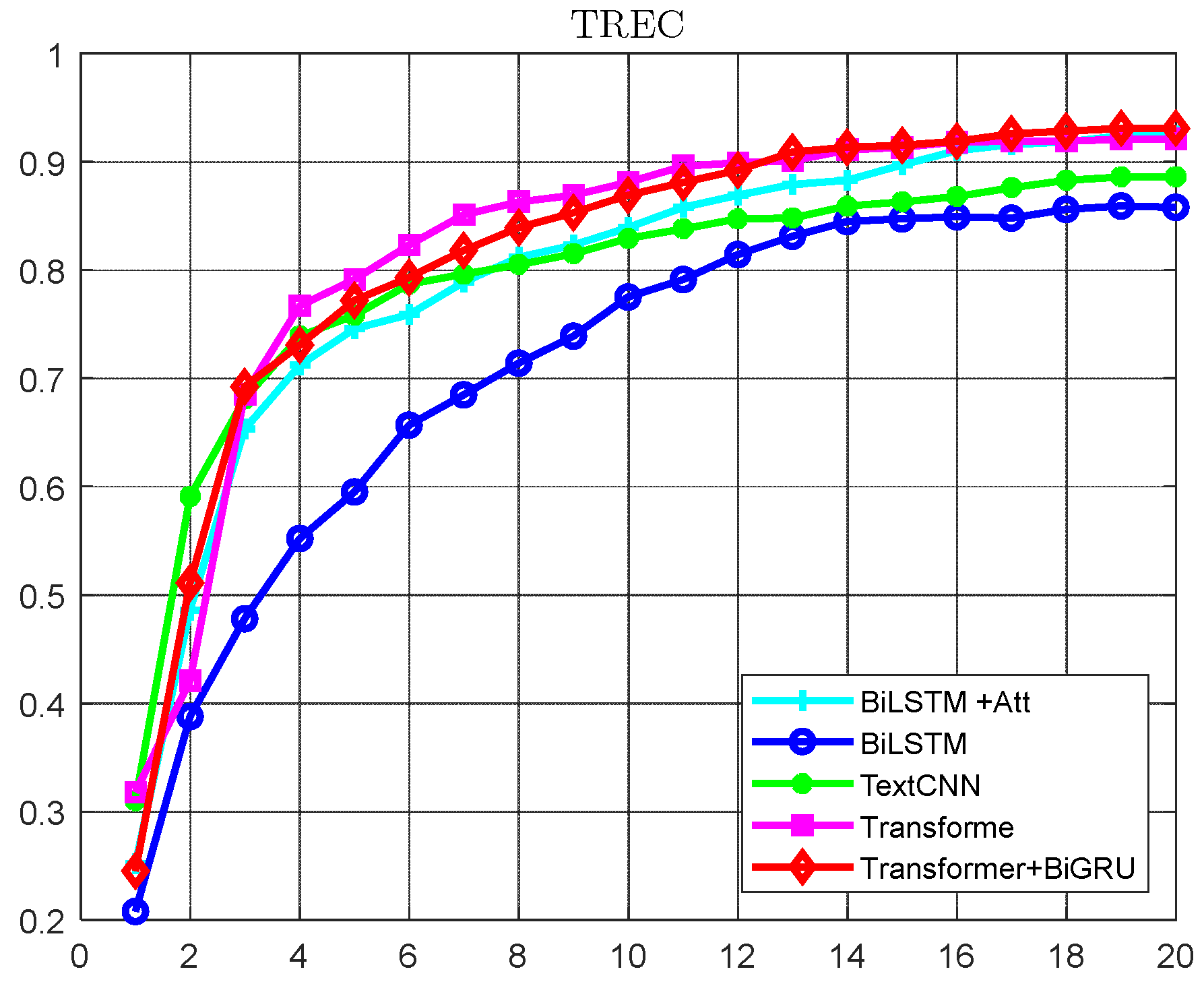
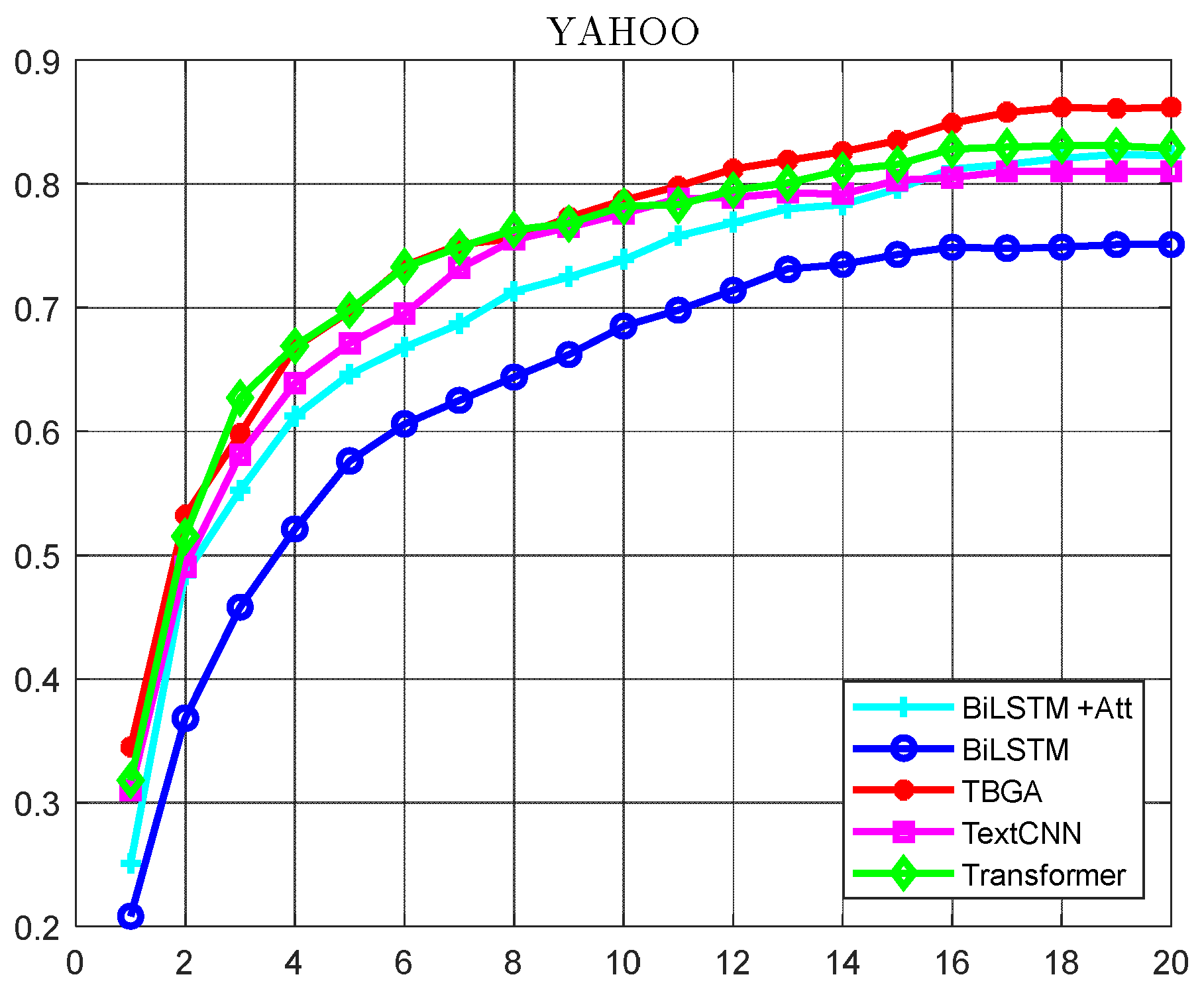
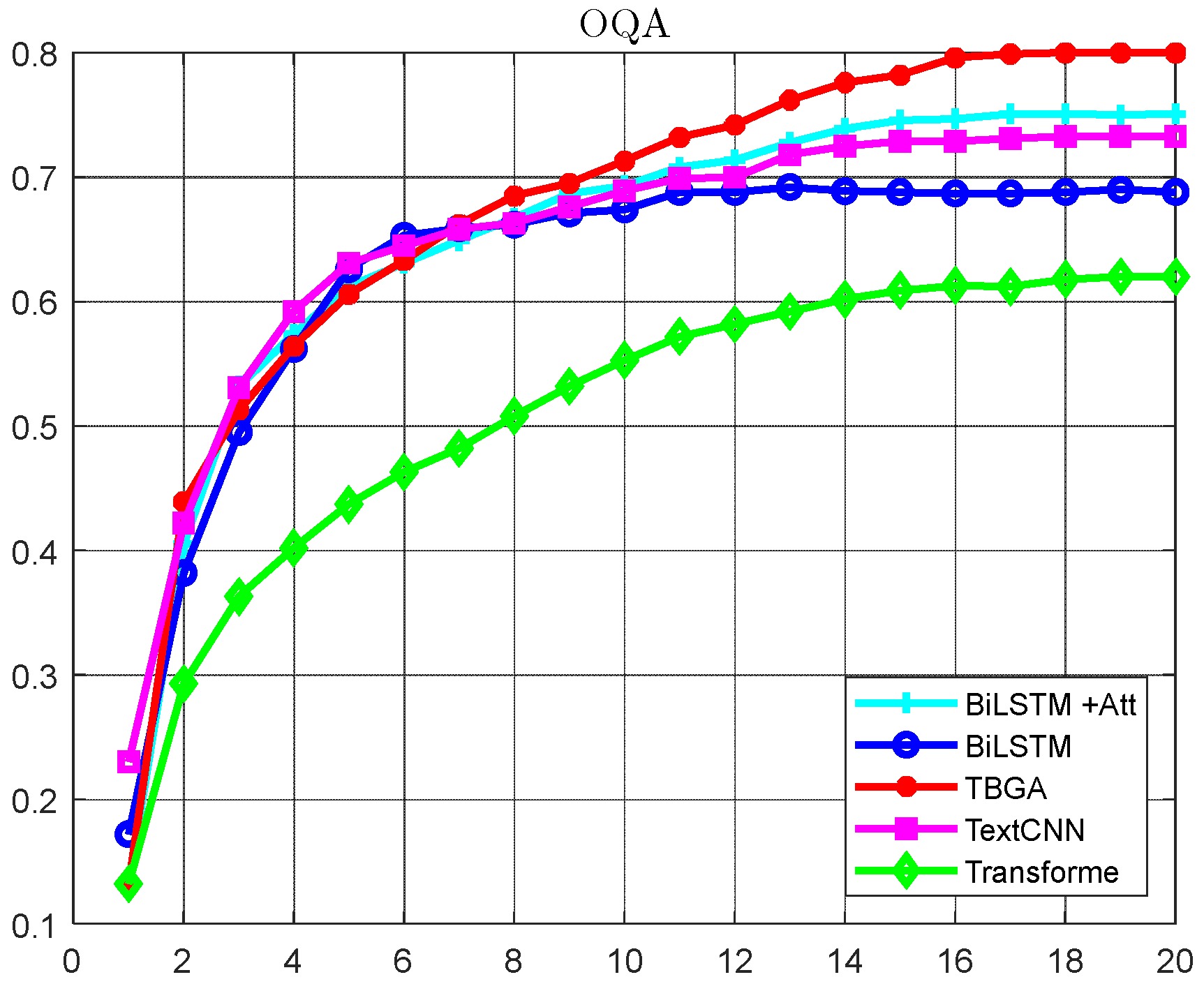
- Experimentation with multiple deep models on TREC, a classical dataset in the publicly available open domain, and comparison of fine-grained category accuracies are performed to identify classification models that are superior for application in different category domains.
2. Materials and Methods
2.1. Question Classification
2.2. Traditional Question Classification Method
2.3. Deep Learning Technology
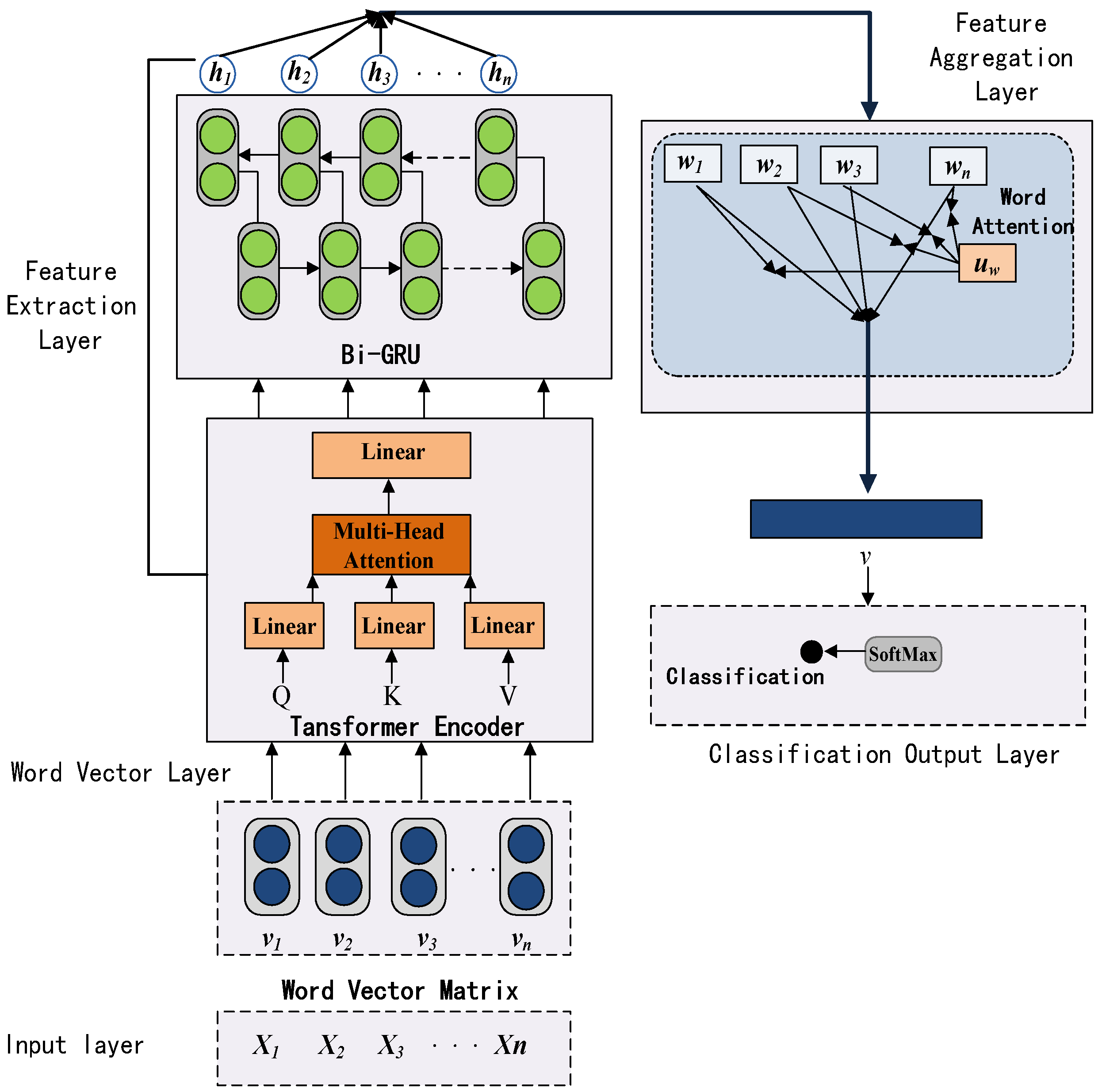
3. Question Classification Method Based on Deep Neural Network
3.1. Word Vector Representation Layer
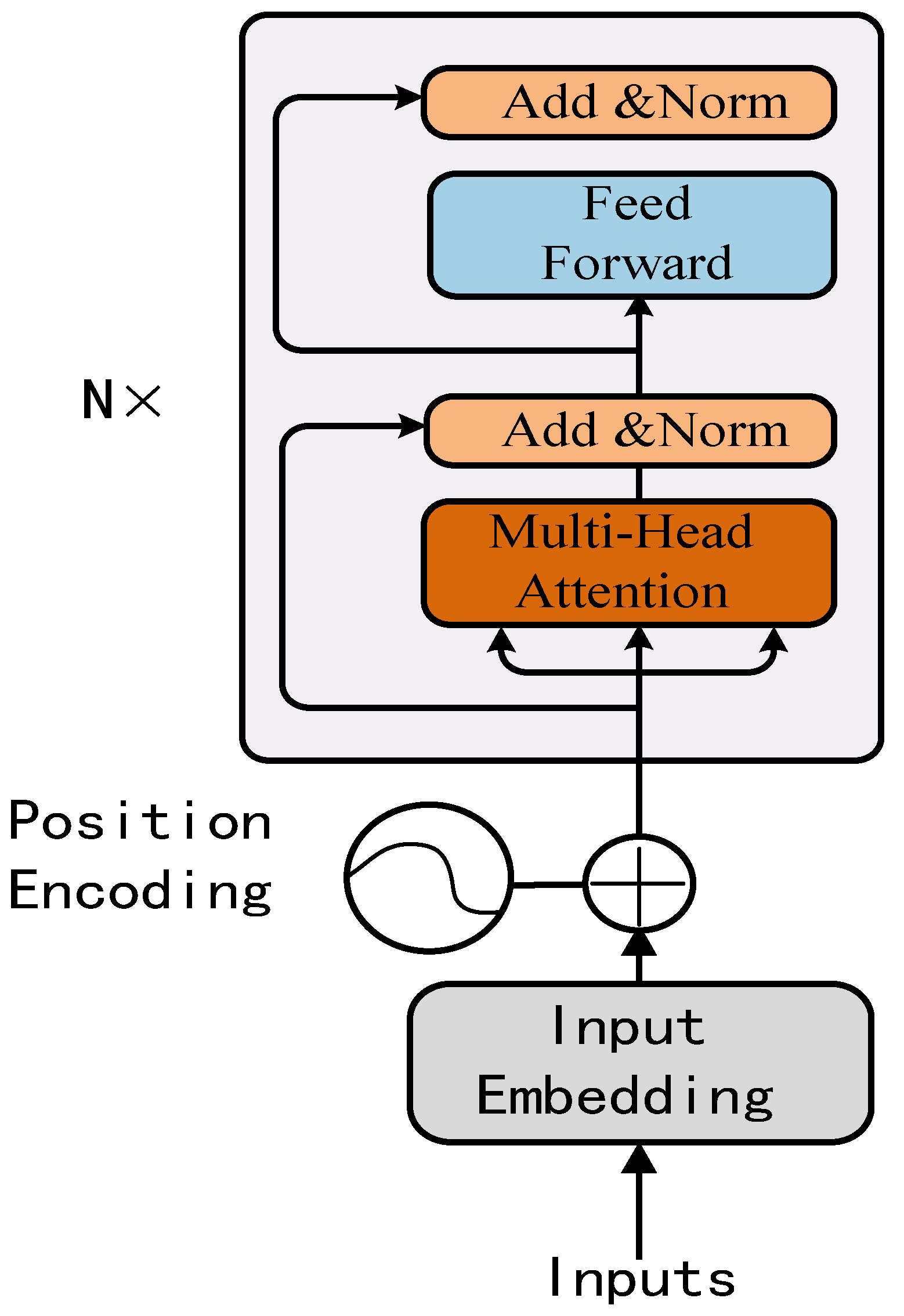
3.2. Transformer Layer
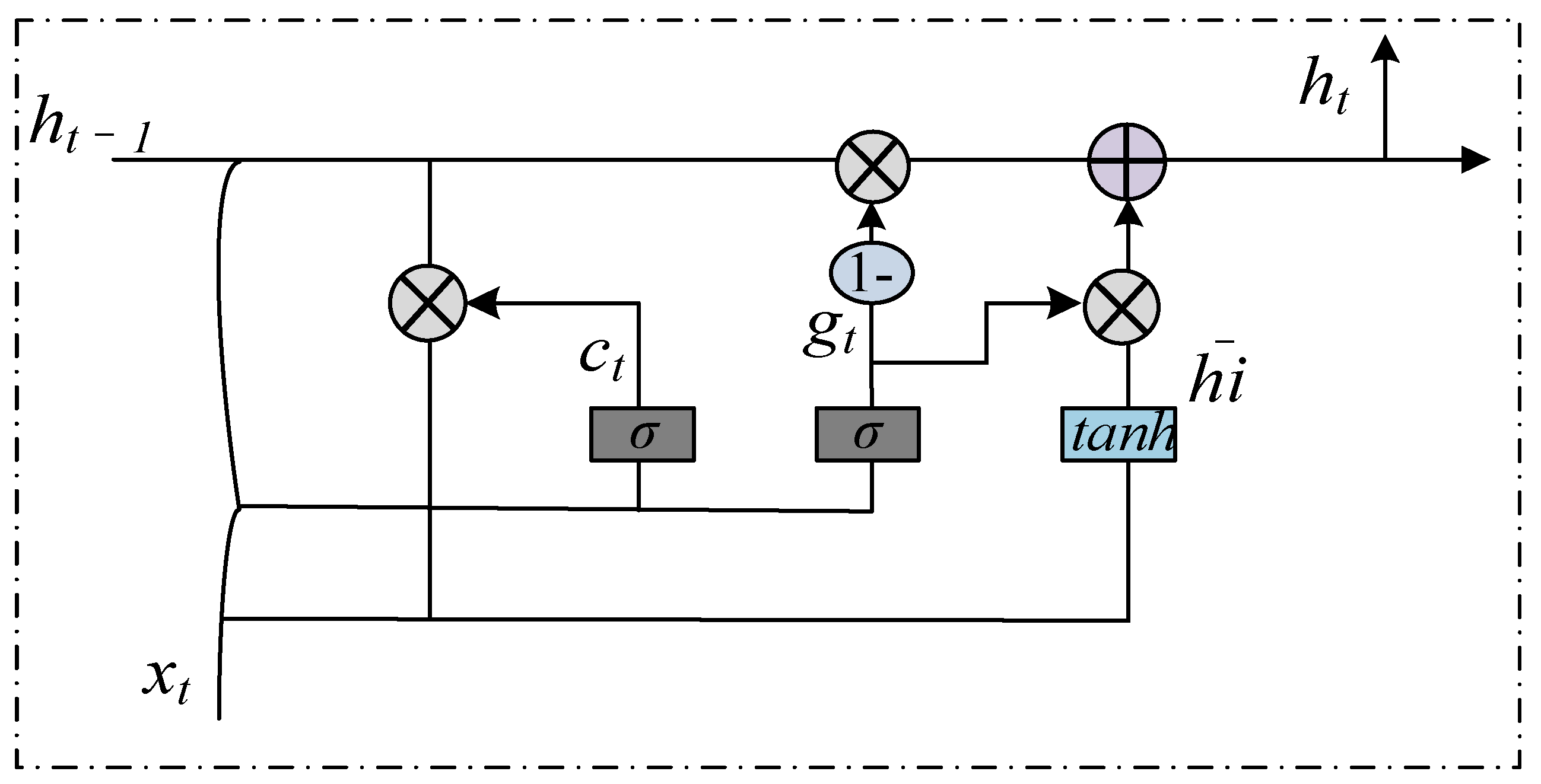
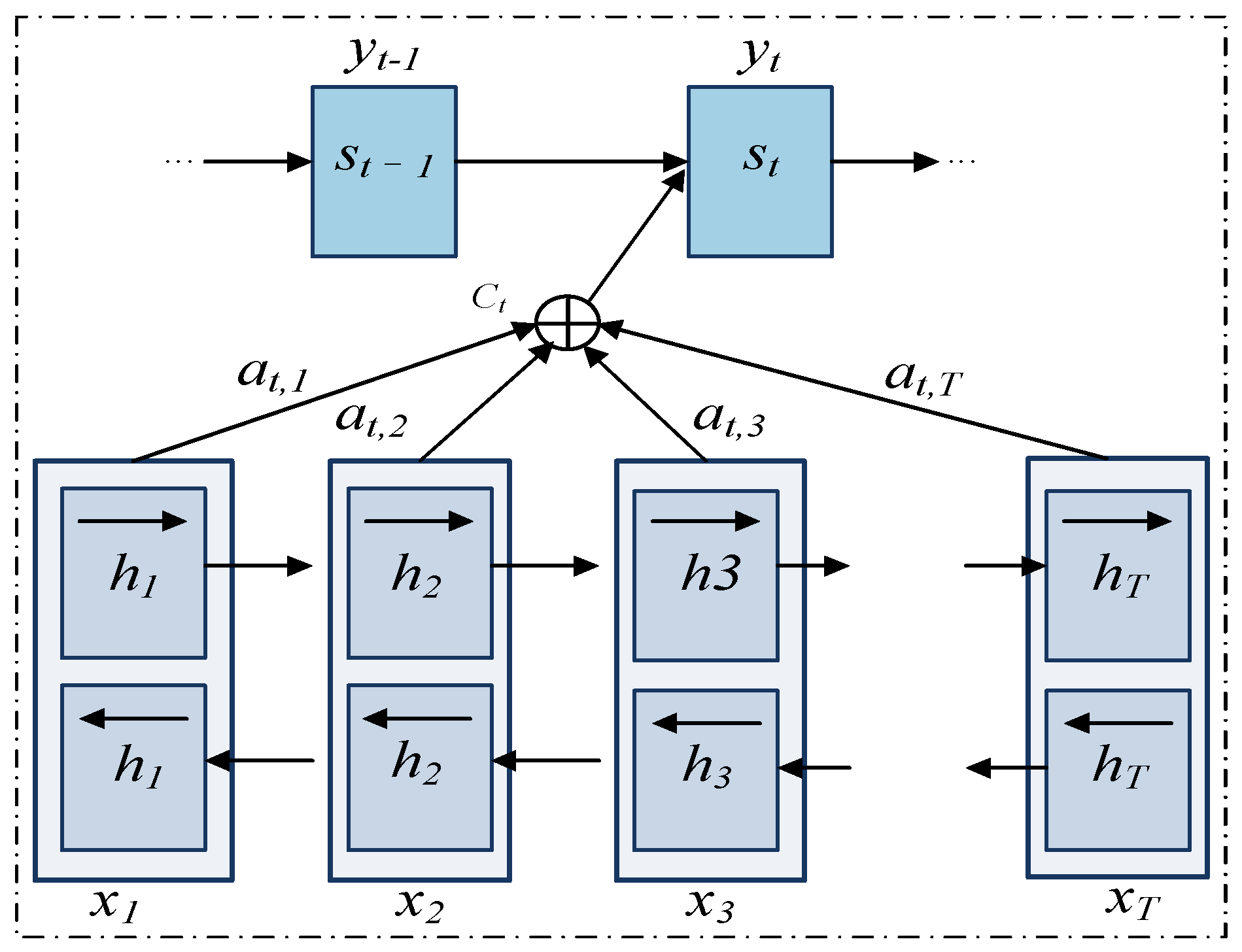
3.3. BiGRU Layer
3.4. Feature Aggregation Layer
3.5. Softmax Layer
3.6. Algorithm Steps
| Algorithm 1 Classification Using Deep Neural Network |
| Input: Traning dataset of Quetion Q = (x1, x2, …, xn) Convert to word vector V = (v1, v2, …, vn) 1. Enter Transormer layer T Initial model parameter p {Learning rate E Momentum α Batch size m Q = K = V ..} Multi-head self-attention calculation S = (s1, s2, …, sn) Output: S = (s1,s2,..,sn) 2. Enter BiGRU layer B Initial model parameter p {..} B to Hidden layer computing H = (h1, h2, …, hn) Output:H = (h1, h2, …, hn) 3. Enter Attention layer A Initial model parameter p {..} Attention computing A = (a1, a2, …, an) 4. Updated model parameter θ’ repeat Input to Softmax Output Q belongs to category |
4. Results and Analysis
4.1. Dataset
4.2. The Validity Threats
4.3. Experimental Setup
4.4. Evaluation Indicators
4.5. Hardware and Software Environment
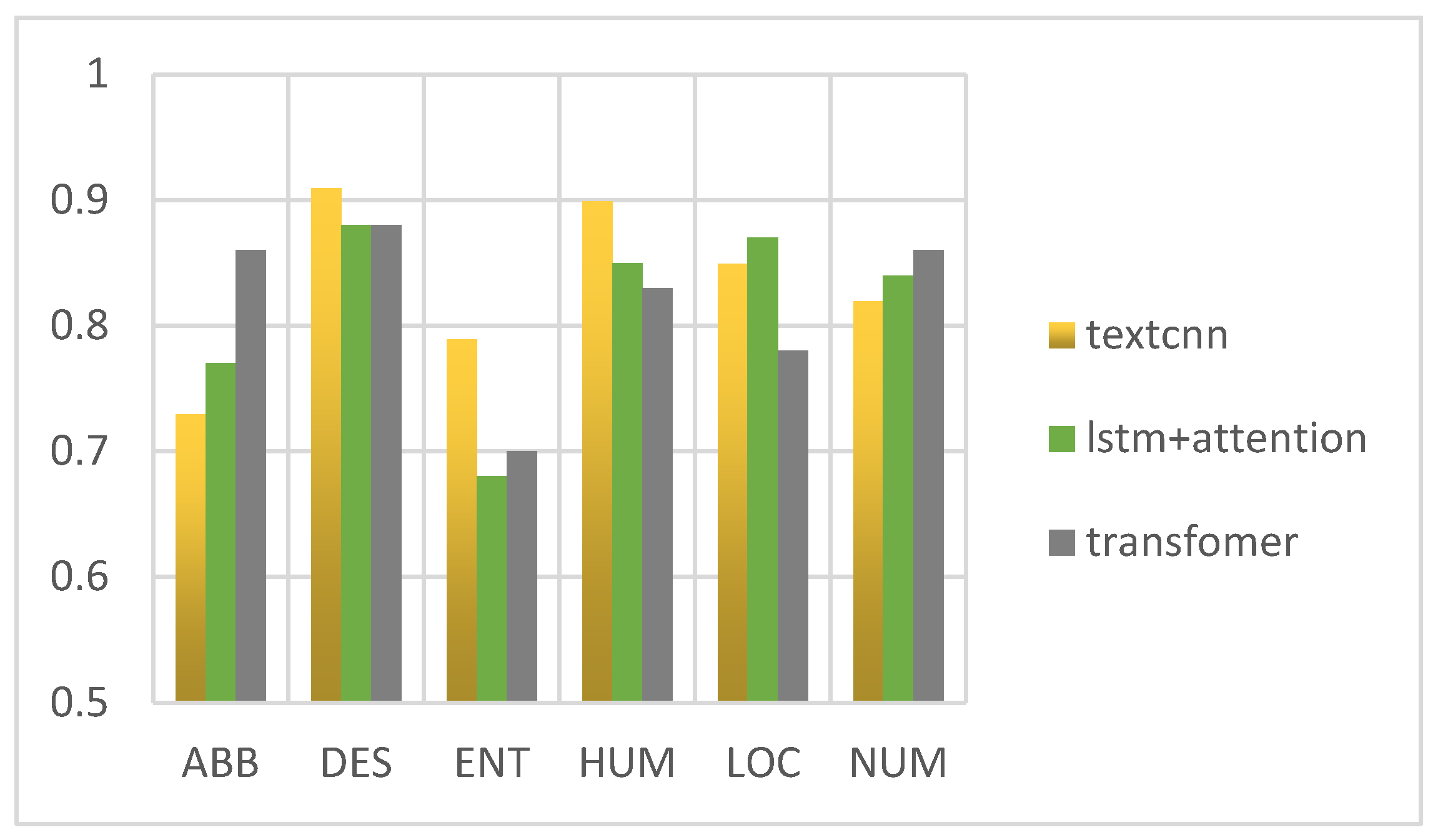
4.6. Experimental Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Data Age 2025 of IDC. Available online: https://www.seagate.com/cn/zh/our-story/data-age-2025/ (accessed on 2 March 2022).
- Green, B.F.; Wolf, A.K.; Chomsky, C.; Laughery, K. Baseball: An Automatic Question Answerer. In Proceedings of the Western Joint IRE-AIEE-ACM Computer Conference, New York, NY, USA, 9–11 May 1961; pp. 219–224. [Google Scholar]
- Woods, W.A. Lunar rocks in natural English: Explorations in natural language question answering. Linguist. Struct. Processing 1977, 5, 521–569. [Google Scholar]
- Wilensky, R.; Chin, D.N.; Luria, M.; Martin, J.; Mayfield, J.; Wu, D. The Berkeley UNIX consultant project. Comput. Linguist. 1988, 14, 35–84. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Comput. Lang. 2014, 2, 3104–3112. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. Comput. Sci. 2014, 19, 25–27. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. Comput. Sci. 2014, 20, 61–63. [Google Scholar]
- Sarker, S.; Monisha, S.T.A.; Nahid, M.M.H. Classification of Bengali Questions towards a Factoid Question Answering System. In Proceedings of the International Conference on Advances in Science Engineering and Robotics Technology, Dhaka, Bangladesh, 3–5 May 2019; pp. 1–5. [Google Scholar]
- Moldovan, D.; Pasca, M.; Harabagiu, S.; Surdeanu, M. Performance issues and error analysis in an open-domain question answering system. ACM Trans. Inf. Syst. 2003, 21, 133–154. [Google Scholar] [CrossRef]
- Faiz, A.; Manna, R.; Laskar, S.R.; Pakray, P.; Das, D.; Bandyopadhyay, S.; Gelbukh, A. Question Classification and Answer Extraction for Developing a Cooking QA System. Comput. Sist. 2020, 24, 24. [Google Scholar]
- Jia, K.; Fan, X.Z.; Xu, J.Z. Chinese qusetion classification based on KNN. Microellectronics Comput. 2008, 162–164. [Google Scholar]
- Hacioglu, K.; Ward, W. Question Classification with Support Vector Machines and Error Correcting Codes. In Proceedings of the Companion Volume of the Proceedings of HLT-NAACL 2003-Short Papers, Edmonton, AB, Canada, 27 May 2003; pp. 28–30. [Google Scholar]
- Silva, J.; Luísa, C.; Mendes, A.C.; Wichert, A. From symbolic to sub-symbolic information in question classification. Artif. Intell. Rev. 2011, 35, 137–154. [Google Scholar] [CrossRef]
- Wen, X.; Zhang, Y.; Liu, T.; Ma, J.-S. Syntactic structure parsing based chinese question classification. J. Chin. Inf. Processing 2006, 20, 35–41. [Google Scholar]
- Zhang, Y.; Liu, T. Research progress of open domain question answering technology. J. Electron. 2009, 37, 1058–1067. [Google Scholar]
- Hovy, E.; Gerber, L.; Hermjakob, U.; Lin, C.-Y.; Ravichandran, D. Toward Semantics-Based Answer Pinpointing. In Proceedings of the Second International Conference on Human Language Technology Research, San Diego, CA, USA, 18–22 March 2001; pp. 1–7. [Google Scholar]
- Zhang, D.; Lee, W.S. Question Classification Using Support Vector Machines. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; pp. 26–32. [Google Scholar]
- Sundblad, H.A. Re-Examination of Question Classification. In Proceedings of the 16th Nordic Conference of Computational Linguistics, Tartu, Estonia, 24–26 May 2007; pp. 394–397. [Google Scholar]
- Li, X.; Huang, X.J.; Wu, L.D. Combination classifier based on error- driven algorithm and its application in problem classification. J. Comput. Res. Dev. 2008, 45, 535–541. [Google Scholar]
- Huang, Z.; Thint, M.; Qin, Z. Question Classification Using Head Words and Their Hypernyms. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 927–936. [Google Scholar]
- Peng, X.Y.; Zhong, D. Survey of Cross-Lingual Word Embedding. J. Chin. Inf. Processing 2020, 34, 1–15, 26. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Komninos, A.; Manandhar, S. Dependency Based Embeddings for Sentence Classification Tasks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 174–179. [Google Scholar]
- Xu, J.; Zhang, D.; Li, S.; Wang, H. Research on question classification via bilingual information. J. Chin. Inf. Processing 2017, 31, 171–177. [Google Scholar]
- Shi, M.F.; Yang, Y.; He, L. Community Q&A question classification method based on Bi-LSTM and CNN and including attention mechanis. Comput. Syst. Appl. 2018, 27, 157–162. [Google Scholar]
- Yu, Z.T.; Fan, X.Z.; Guo, J.Y. Classification of Chinese Questions Based on Support Vector Machine. J. South China Univ. Technol. Nat. Sci. Ed. 2005, 33, 25–27. [Google Scholar]
- Tian, W.D.; Gao, Y.Y.; Zu, Y.L. Question classification based on self-learning rules and modified Bayes. Appl. Res. Comput. 2010, 27, 75–77. [Google Scholar]
- Li, R.; Song, X.X.; Wang, W.J. Chinese question classification based on Chinese Frame Net. Comput. Eng. Appl. 2009, 45, 111–115. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Liu, Y.H.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the 33th Conference and Workshop on Neural Information Processing Systems, Vancouver, BC, Canada, 10–12 December 2019; pp. 5754–5764. [Google Scholar]
- Ezen, C.A. A Comparison of LSTM and BERT for Small Corpus. arXiv 2020, arXiv:200 9.05451. [Google Scholar]
- Khandelwal, U.; He, H.; Qi, P.; Jurafsky, D. Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use Context. arXiv 2018, arXiv:1805.04623. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. arXiv 2015, arXiv:1508.06669. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- González, J.; Gómez, J. TREC: Experiment and evaluation in information retrieval. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 910–911. [Google Scholar]
- Choi, E.; Kitzie, V.; Shah, C. A Machine Learning-Based Approach to Predicting Success of Questions on Social Question Answering. In Proceedings of the iConference 2013, Fort Worth, TX, USA, 12–15 February 2013. [Google Scholar]
- Adamic, L.A.; Zhang, J.; Bakshy, E.; Ackerman, M.S. Knowledge Sharing and Yahoo Answers: Everyone Knows Something. In Proceedings of the International Conference on World Wide Web ACM, Beijing, China, 21–25 April 2008; pp. 665–674. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coarse | Fine |
|---|---|
| ABBR | abbreviation, expansion |
| DESC | definition, description, manner, reason |
| ENTY | animal, body, color, creation, currency, disease, event, food, instrument, language, letter,other, plant, product, religion, sport, substance, symbol, technique, term, vehicle, word |
| HUM | description, group, individual |
| LOC | city, country, mountain, other, state |
| NUM | code, count, date, distance, money, order, other, percent, period, speed, temperature, size,weight |
| Coarse | Fine |
|---|---|
| DESC | abbreviation, meaning, method, reason, definition, describes, description other |
| HUM | specific person, organization, character description, character list, human other |
| LOC | planet, city, continent, country, province, river, lake, mountain, range, ocean, island, location, listed, address, location other |
| NUM | number, quantity, price, percentage, distance, weight, temperature, age, area, frequency, speed, range, order, number list, number other |
| TIME | year, month, day, time, time range, time list, time other |
| OBJ | animals, plants, foods, colors, colors, currency, language, text, material, mechanical form, religious entertainment entity, entity, entity other |
| Unknown | unknown |
| Data Type | Categories | Dataset | Training Set | Test Set | Answer Set |
|---|---|---|---|---|---|
| TREC | 6 | 5985 | 500 | 500 | —— |
| YAHOO | 4 | 1185 | 885 | 150 | 1185 |
| OQA | 6 | 3250 | 300 | 300 | 3250 |
| No. | Type | Description |
|---|---|---|
| 1 | Operation System | Ubuntu 18.04.3 LTS |
| 2 | Experiment Environment | Pytorch 1.3 |
| 3 | CPU | Intel Core i7-8700K |
| 4 | RAM | DDR432GB |
| 5 | CUDA | 10.0 |
| 6 | GPU: | NVIDA GeForce GTX 1080Ti |
| 7 | Disk | 2TB NVMe SSD |
| Model | TREC | YAHOO | OQA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | |
| CNNs | 89.02 | 89.43 | 89.03 | 89.23 | 81.26 | 81.71 | 82.03 | 81.86 | 75.33 | 76.81 | 75.44 | 76.11 |
| BiLSTM | 85.03 | 85.75 | 85.00 | 85.37 | 75.18 | 75.42 | 75.63 | 75.52 | 69.01 | 68.22 | 69.02 | 68.61 |
| BiLSTM+Att | 92.63 | 92.61 | 92.60 | 92.60 | 82.43 | 82.37 | 82.45 | 82.40 | 75.21 | 75.43 | 75.03 | 75.23 |
| Transfomer | 92.21 | 92.22 | 92.20 | 92.20 | 83.17 | 83.36 | 83.30 | 83.32 | 62.76 | 60.48 | 61.77 | 61.12 |
| Trans + BiGRU | 93.22 | 92.88 | 93.20 | 93.03 | - | - | - | - | - | - | - | - |
| TBGA | - | - | - | - | 86.12 | 86.23 | 86.20 | 86.21 | 80.08 | 82.62 | 80.12 | 81.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, D.; Tohti, T.; Hamdulla, A. Attention-Based Transformer-BiGRU for Question Classification. Information 2022, 13, 214. https://doi.org/10.3390/info13050214
Han D, Tohti T, Hamdulla A. Attention-Based Transformer-BiGRU for Question Classification. Information. 2022; 13(5):214. https://doi.org/10.3390/info13050214
Chicago/Turabian StyleHan, Dongfang, Turdi Tohti, and Askar Hamdulla. 2022. "Attention-Based Transformer-BiGRU for Question Classification" Information 13, no. 5: 214. https://doi.org/10.3390/info13050214
APA StyleHan, D., Tohti, T., & Hamdulla, A. (2022). Attention-Based Transformer-BiGRU for Question Classification. Information, 13(5), 214. https://doi.org/10.3390/info13050214