
Translation Performance from the User’s Perspective of Large Language Models and Neural Machine Translation Systems


_김_(김).png)
Abstract
:1. Introduction
2. Theoretical Background
2.1. Machine Translation Approaches and Evolution
2.2. Metrics for Evaluating Machine Translation Performance
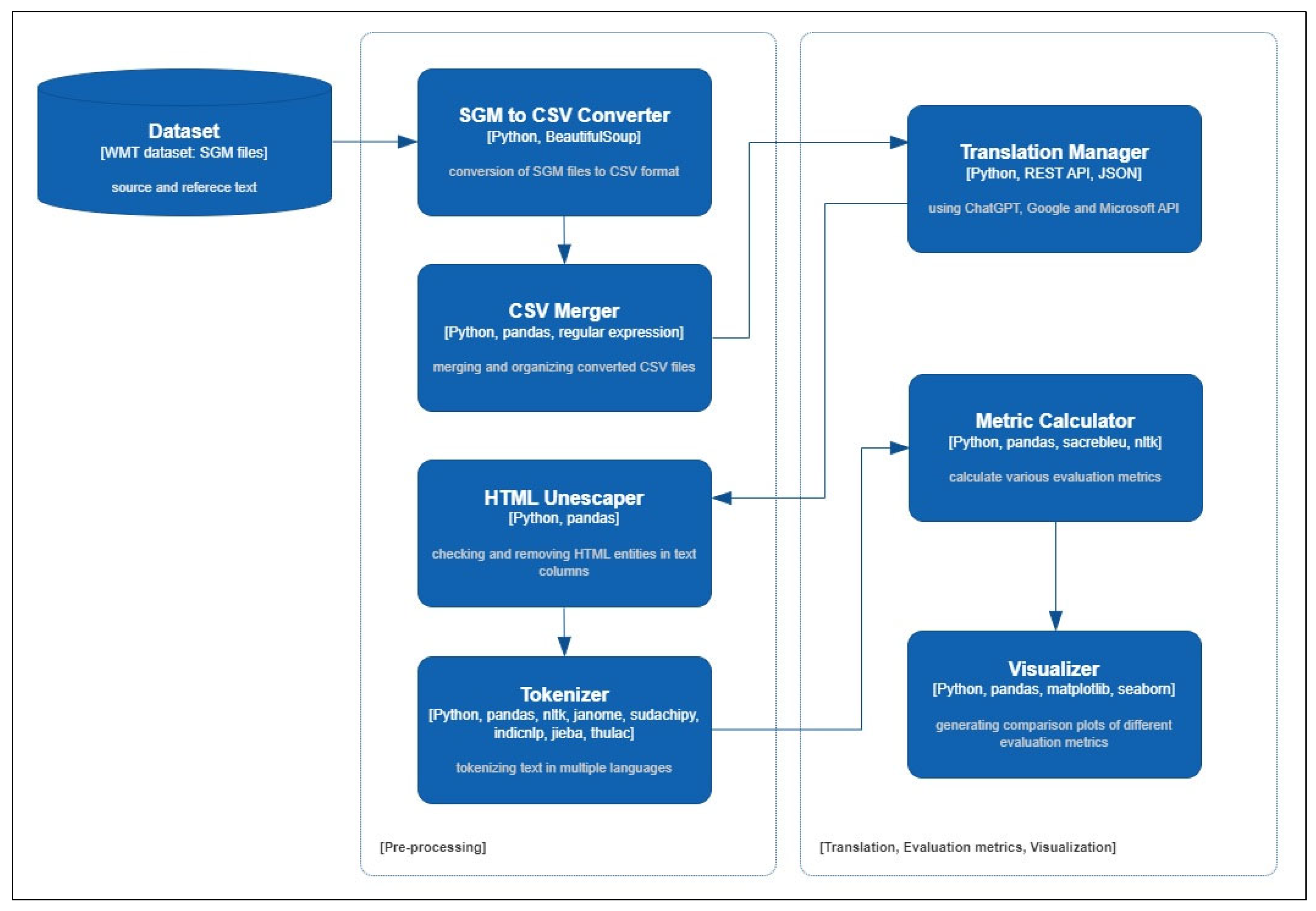
3. Method
3.1. Selection of Test Subjects
3.1.1. Selection of Test Systems
3.1.2. Selection of Metrics and Libraries
3.2. Experimental Design
3.2.1. Experimental Process
3.2.2. Evaluation Dataset
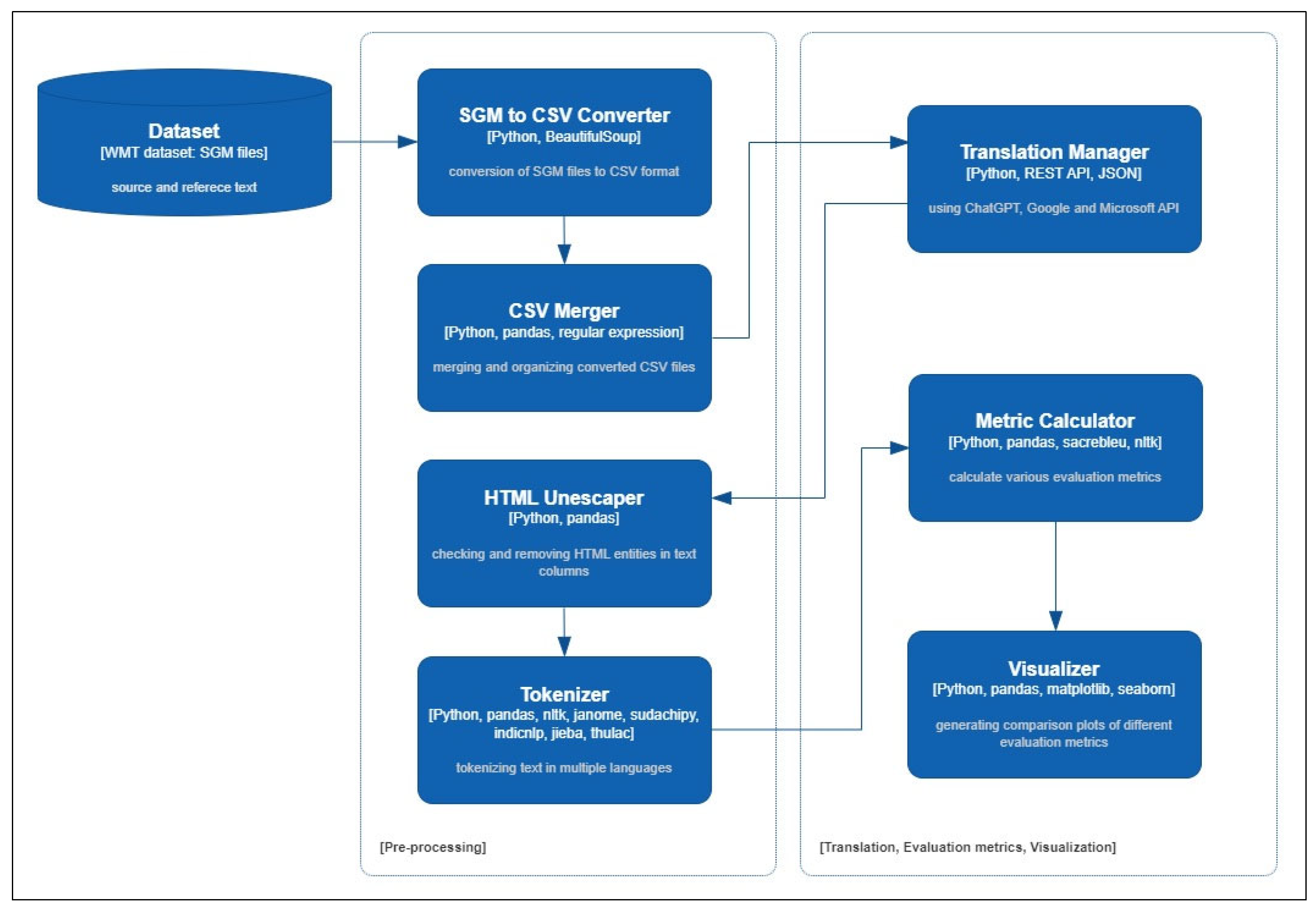
3.2.3. Data Preprocessing and Translation Using API
4. Results
4.1. Translation Performance Results by chatGPT Models
4.2. Translation Performance Results of the Systems
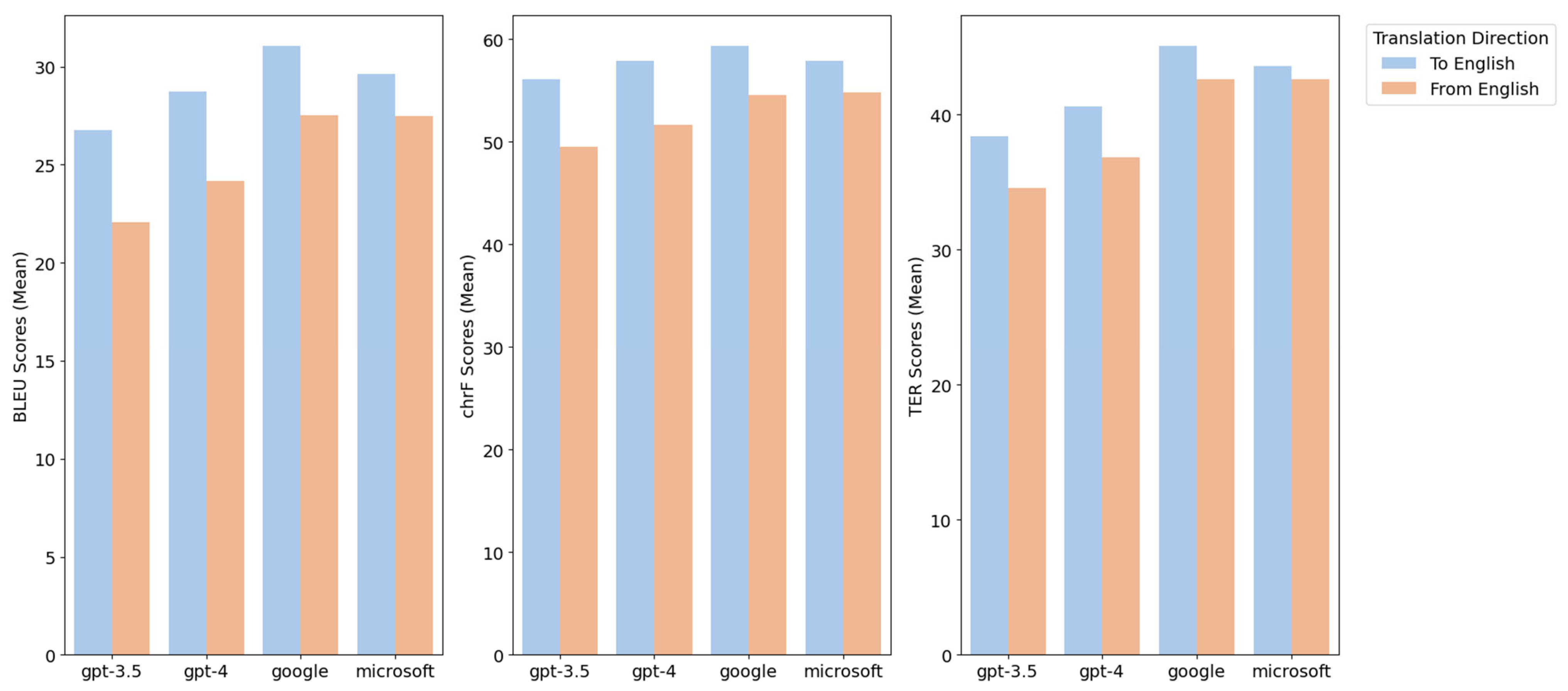
4.3. Translation Performance Comparison for English and Non-English
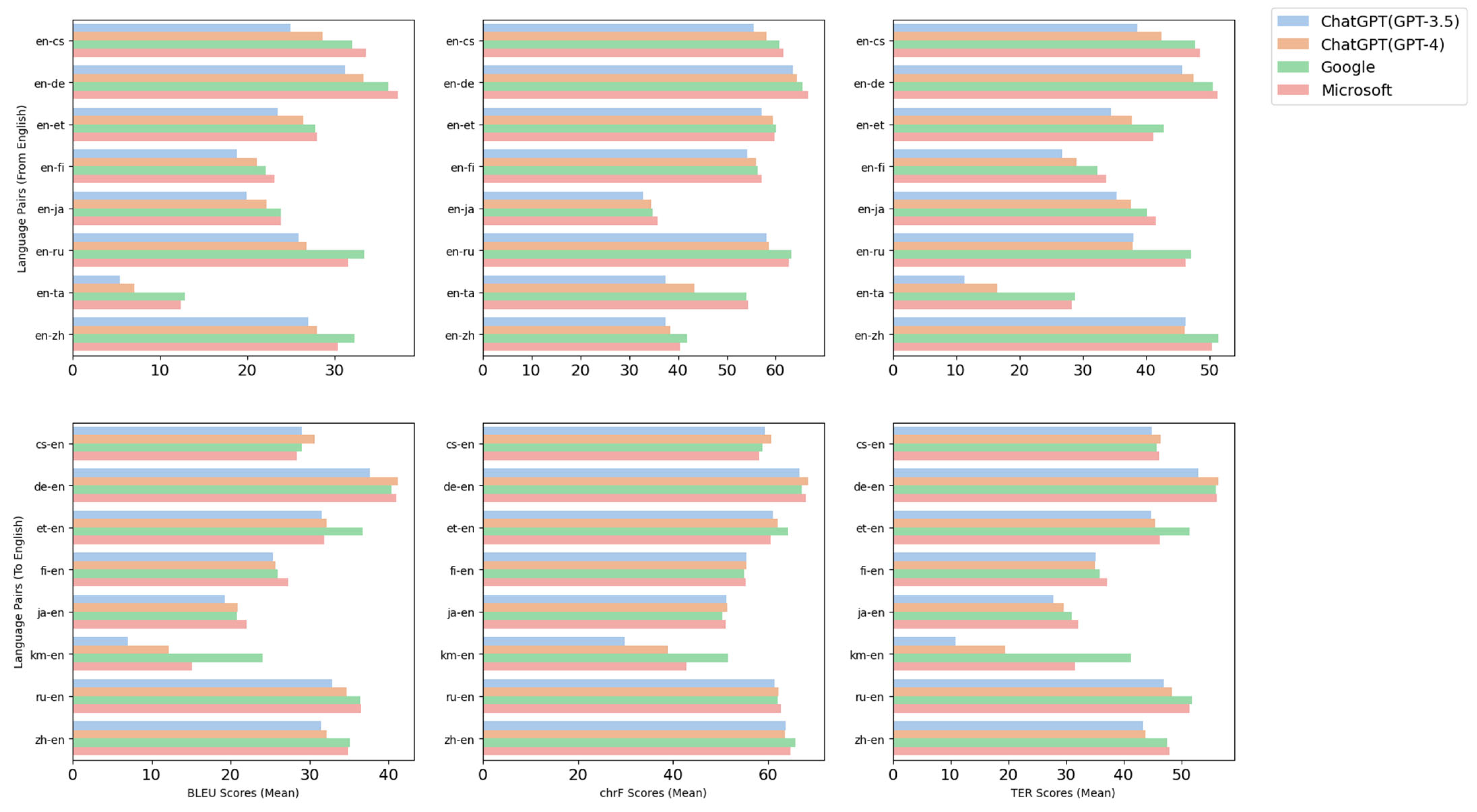
4.4. Translation Performance Comparison by Language Pairs
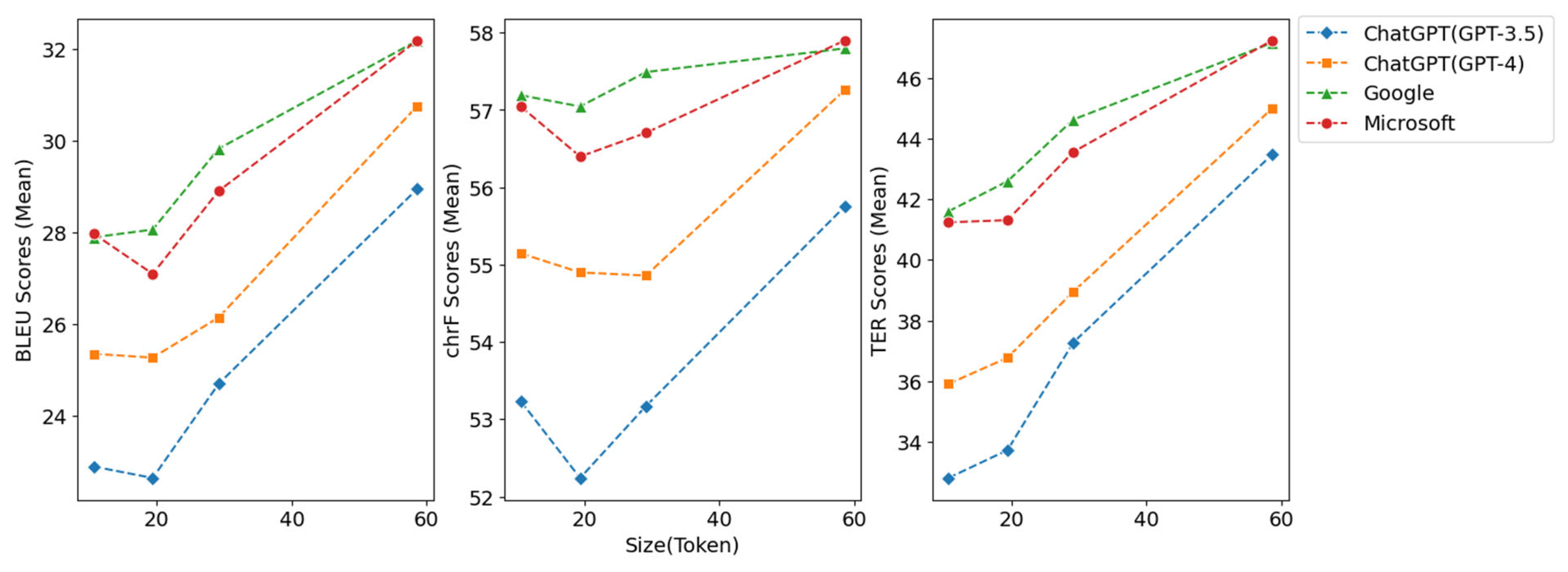
4.5. The Impact of Reference Text Token Size
5. Conclusions
5.1. Findings and Discussion
5.2. Research Implications
5.3. Research Limitations and Future Plans
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ray, P.P. ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber-Phys. Syst. 2023, 3, 121–154. [Google Scholar] [CrossRef]
- Acumen Research and Consulting. Available online: https://www.acumenresearchandconsulting.com/press-releases/machine-translation-market (accessed on 20 May 2023).
- Biswas, S.S. Potential use of chatGPT in global warming. Ann. Biomed. Eng. 2023, 51, 1126–1127. [Google Scholar] [CrossRef] [PubMed]
- Wu, T.; He, S.; Liu, J.; Sun, S.; Liu, K.; Han, Q.L.; Tang, Y. A brief overview of ChatGPT: The history, status quo and potential future development. IEEE/CAA J. Autom. Sin. 2023, 10, 1122–1136. [Google Scholar] [CrossRef]
- Mathew, A. Is artificial intelligence a world changer? A case study of OpenAI’s Chat GPT. Recent Prog. Sci. Technol. 2023, 5, 35–42. [Google Scholar]
- Meng, F.; Zhang, J. DTMT: A novel deep transition architecture for neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 224–231. [Google Scholar]
- Hutchins, J. The history of machine translation in a nutshell. Retrieved Dec. 2005, 20, 1–5. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar]
- Chand, S. Empirical survey of machine translation tools. In Proceedings of the 2016 Second International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN), Kolkata, India, 23–25 September 2016; IEEE: New York, NY, USA, 2016; pp. 181–185. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 18 April 2023).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, New York, NY, USA, 3–10 March 2021; pp. 610–623. [Google Scholar]
- Hutchins, W.J.; Somers, H.L. An Introduction to Machine Translation; Academic Press Limited: London, UK, 1992. [Google Scholar]
- Wang, H.; Wu, H.; He, Z.; Huang, L.; Church, K.W. Progress in Machine Translation. Engineering 2022, 18, 143–153. [Google Scholar] [CrossRef]
- Taravella, A.; Villeneuve, A.O. Acknowledging the needs of computer-assisted translation tools users: The human perspective in human-machine translation. J. Spec. Transl. 2013, 19, 62–74. [Google Scholar]
- Rodríguez-Castro, M. An integrated curricular design for computer-assisted translation tools: Developing technical expertise. Interpret. Transl. Train. 2018, 12, 355–374. [Google Scholar] [CrossRef]
- Ragni, V.; Nunes Vieira, L. What has changed with neural machine translation? A critical review of human factors. Perspectives 2022, 30, 137–158. [Google Scholar] [CrossRef]
- Chopra, D.; Joshi, N.; Mathur, I. Improving translation quality by using ensemble approach. Eng. Technol. Appl. Sci. Res. 2018, 8, 3512–3514. [Google Scholar] [CrossRef]
- Hearne, M.; Way, A. Statistical machine translation: A guide for linguists and translators. Lang. Linguist. Compass 2011, 5, 205–226. [Google Scholar] [CrossRef]
- Hutchins, J. Example-based machine translation: A review and commentary. Mach. Transl. 2005, 19, 197–211. [Google Scholar] [CrossRef]
- Cui, Y.; Surpur, C.; Ahmad, S.; Hawkins, J. A comparative study of HTM and other neural network models for online sequence learning with streaming data. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; IEEE: New York, NY, USA, 2016; pp. 1530–1538. [Google Scholar]
- Mara, M. English-Wolaytta Machine Translation Using Statistical Approach; St. Mary’s University: San Antonio, TX, USA, 2018. [Google Scholar]
- Maruf, S.; Saleh, F.; Haffari, G. A survey on document-level neural machine translation: Methods and evaluation. ACM Comput. Surv. (CSUR) 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Zhu, J.; Xia, Y.; Wu, L.; He, D.; Qin, T.; Zhou, W.; Li, H.; Liu, T. Incorporating BERT into Neural Machine Translation. arXiv 2020, arXiv:2002.06823. [Google Scholar]
- Kulshreshtha, S.; Redondo-García, J.L.; Chang, C.Y. Cross-lingual alignment methods for multilingual BERT: A comparative study. arXiv 2020, arXiv:2009.14304. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. Assoc. Comput. Linguist. 2020, 8440–8451. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- OpenAI. GPT-4 Is OpenAI’s Most Advanced System, Producing Safer and More Useful Responses. Available online: https://openai.com/gpt-4 (accessed on 28 May 2023).
- Freedman, J.D.; Nappier, I.A. GPT-4 to GPT-3.5:’Hold My Scalpel’—A Look at the Competency of OpenAI’s GPT on the Plastic Surgery In-Service Training Exam. arXiv 2023, arXiv:2304.01503. [Google Scholar]
- Koehn, P.; Haddow, B. Interactive assistance to human translators using statistical machine translation methods. In Proceedings of the Machine Translation Summit XII: Papers, Ottawa, ON, Canada, 26–30 August 2009. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Callison-Burch, C.; Osborne, M.; Koehn, P. Re-evaluating the role of BLEU in machine translation research. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 3–7 April 2006; pp. 249–256. [Google Scholar]
- Popović, M. chrF: Character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisbon, Portugal, 17–18 September 2015; pp. 392–395. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A study of translation edit rate with targeted human annotation. In Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers, Cambridge, MA, USA, 8–12 August 2006; pp. 223–231. [Google Scholar]
- Wieting, J.; Berg-Kirkpatrick, T.; Gimpel, K.; Neubig, G. Beyond BLEU: Training Neural Machine Translation with Semantic Similarity. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4344–4355. [Google Scholar]
- Castilho, S.; Moorkens, J.; Gaspari, F.; Calixto, I.; Tinsley, J.; Way, A. Is neural machine translation the new state of the art? Prague Bull. Math. Linguist. 2017, 108, 109–120. [Google Scholar] [CrossRef]
- Callison-Burch, C.; Koehn, P.; Monz, C.; Peterson, K.; Przybocki, M.; Zaidan, O. Findings of the 2010 joint workshop on statistical machine translation and metrics for machine translation. In Proceedings of the Joint Fifth Workshop on Statistical Machine Translation and MetricsMATR, Uppsala, Sweden, 15–16 July 2010; pp. 17–53. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Nichols, J.; Warnow, T. Tutorial on computational linguistic phylogeny. Lang. Linguist. Compass 2008, 2, 760–820. [Google Scholar] [CrossRef]
- Birch, A. Neural Machine Translation; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.G.; Le, Q.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar]
- Roumeliotis, K.I.; Tselikas, N.D. ChatGPT and Open-AI Models: A Preliminary Review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- Christiano, P.F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; Amodei, D. Deep reinforcement learning from human preferences. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1–9. [Google Scholar]
- Hariri, W. Unlocking the Potential of ChatGPT: A comprehensive exploration of its applications, advantages, limitations, and future directions in natural language processing. arXiv 2023, arXiv:2304.02017. [Google Scholar]
- Post, M. A call for clarity in reporting BLEU scores. arXiv 2018, arXiv:1804.08771. [Google Scholar]
- WMT 18. Available online: https://www.statmt.org/wmt18/translation-task.html (accessed on 15 April 2023).
- WMT 20. Available online: https://www.statmt.org/wmt20/translation-task.html (accessed on 15 April 2023).
- Koehn, P.; Chaudhary, V.; El-Kishky, A.; Goyal, N.; Chen, P.J.; Guzmán, F. Findings of the WMT 2020 shared task on parallel corpus filtering and alignment. In Proceedings of the Fifth Conference on Machine Translation, Association for Computational Linguistics, Online, 19–20 November 2020; pp. 726–742. [Google Scholar]
- Bojar, O.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Huck, M.; Koehn, P.; Monz, C. WMT18; Association for Computational Linguistics: Belgium, Brussels, 2018. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Section | System Characteristics |
|---|---|
| Google Translate | Google Translate is a widely used NMT system that leverages Google’s extensive research in the field of machine translation. It supports a vast number of languages and has been continually improved over the years, resulting in high-quality translations across various language pairs. |
| Microsoft Translator | Developed by Microsoft Azure Cognitive Services, Microsoft Translator is another leading NMT system that offers translation capabilities for numerous languages. It employs advanced neural network techniques and benefits from Microsoft’s extensive research on machine translation, providing accurate translations for a diverse set of language pairs. |
| ChatGPT | ChatGPT is a family of advanced LLMs developed by OpenAI to excel in tasks such as conversation, question answering, and content generation. ChatGPT has also shown remarkable efficacy in translation applications despite not being initially designed for this purpose. |
| Metric | GPT-3 (Text-Curie-001) | GPT-3.5 (Text-Davinci-003) | GPT-3.5 (gpt-3.5-Turbo) | GPT-4 (Limited Beta) |
|---|---|---|---|---|
| BLEU | 13.51 | 25.33 | 28.35 | 30.16 |
| chrF | 39.32 | 56.69 | 56.67 | 60.84 |
| TER 1 | 19.37 | 37.14 | 40.60 | 42.20 |
| Metric | H * | df ** | p-Value *** |
|---|---|---|---|
| BLEU | 149.07 | 3 | <0.001 |
| chrF | 96.34 | 3 | <0.001 |
| TER | 225.45 | 3 | <0.001 |
| Metric | ChatGPT (GPT-3.5) | ChatGPT (GPT-4) | Microsoft | |
|---|---|---|---|---|
| BLEU | 24.79 | 26.86 | 29.47 | 29.05 |
| chrF | 53.62 | 55.54 | 57.38 | 57.03 |
| TER | 36.76 | 39.10 | 43.96 | 43.32 |
| Section | ChatGPT (GPT-3.5) | ChatGPT (GPT-4) | Microsoft | ||
|---|---|---|---|---|---|
| BLEU | Non-English–English | 26.77 | 28.71 | 31.07 | 29.64 |
| English–non-English | 22.05 | 24.16 | 27.54 | 27.49 | |
| chrF | Non-English–English | 56.10 | 57.86 | 59.35 | 57.90 |
| English–non-English | 49.52 | 51.61 | 54.56 | 54.81 | |
| TER | Non-English–English | 38.38 | 40.62 | 45.11 | 43.61 |
| English–non-English | 34.56 | 36.85 | 42.61 | 42.63 | |
| Target | ChatGPT (GPT-3.5) | ChatGPT (GPT-4) | Microsoft | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BLEU | chrF | TER | BLEU | chrF | TER | BLEU | chrF | TER | BLEU | chrF | TER | |
| de-en | 37.65 | 66.57 | 52.93 | 41.23 | 68.43 | 56.39 | 40.39 | 67.06 | 56.07 | 40.98 | 67.89 | 56.16 |
| ru-en | 32.91 | 63.7 | 46.97 | 34.67 | 63.63 | 48.41 | 36.41 | 65.76 | 51.85 | 36.5 | 64.76 | 51.39 |
| et-en | 31.52 | 63.46 | 44.76 | 32.18 | 64.39 | 45.52 | 36.76 | 65.50 | 51.40 | 31.87 | 66.64 | 46.28 |
| zh-en | 31.48 | 61.35 | 43.43 | 32.13 | 62.17 | 43.84 | 35.13 | 62.08 | 47.53 | 34.97 | 62.65 | 48.02 |
| en-de | 31.21 | 61.06 | 45.70 | 33.26 | 62.07 | 47.46 | 36.11 | 64.19 | 50.51 | 37.24 | 60.52 | 51.27 |
| de-fr | 30.52 | 60.17 | 45.02 | 32.51 | 61.91 | 47.27 | 32.23 | 60.46 | 47.39 | 35.41 | 62.44 | 48.13 |
| cs-en | 29.00 | 59.98 | 44.97 | 30.65 | 61.96 | 46.49 | 29.08 | 61.12 | 45.78 | 28.45 | 62.30 | 46.22 |
| en-zh | 26.93 | 59.41 | 46.23 | 27.99 | 60.69 | 46.08 | 32.28 | 58.77 | 51.39 | 30.35 | 58.17 | 50.36 |
| en-ru | 25.84 | 58.16 | 38.07 | 26.76 | 58.54 | 37.95 | 33.40 | 63.22 | 47.11 | 31.55 | 62.65 | 46.25 |
| fi-en | 25.40 | 57.11 | 35.23 | 25.73 | 59.51 | 35.05 | 25.99 | 60.03 | 35.95 | 27.29 | 59.80 | 37.09 |
| fr-de | 25.07 | 55.57 | 33.20 | 28.03 | 58.19 | 36.88 | 29.33 | 60.81 | 42.12 | 30.40 | 61.63 | 41.71 |
| en-cs | 24.92 | 55.51 | 38.7 | 28.63 | 55.54 | 42.40 | 32.01 | 54.95 | 47.77 | 33.53 | 55.34 | 48.48 |
| en-et | 23.47 | 54.16 | 34.46 | 26.38 | 56.05 | 37.73 | 27.80 | 56.26 | 42.83 | 27.95 | 57.15 | 41.21 |
| en-ja | 19.85 | 51.30 | 35.33 | 22.15 | 51.45 | 37.66 | 23.84 | 50.41 | 40.15 | 23.84 | 51.02 | 41.51 |
| ja-en | 19.25 | 37.47 | 27.81 | 20.89 | 38.37 | 29.7 | 20.77 | 41.87 | 30.98 | 22.01 | 40.37 | 32.20 |
| en-fi | 18.79 | 37.46 | 26.70 | 21.05 | 43.34 | 29.07 | 22.09 | 54.01 | 32.33 | 23.09 | 54.39 | 33.76 |
| km-en | 6.97 | 32.78 | 10.95 | 12.20 | 34.51 | 19.56 | 24.03 | 34.82 | 41.28 | 15.07 | 35.86 | 31.53 |
| en-ta | 5.38 | 29.87 | 11.28 | 7.09 | 38.93 | 16.44 | 12.82 | 51.57 | 28.81 | 12.36 | 42.88 | 28.22 |
| Section | Token Size (Mean) | ChatGPT (GPT-3.5) | ChatGPT (GPT-4) | Microsoft | |
|---|---|---|---|---|---|
| BLEU | 10.59 | 22.90 | 25.35 | 27.89 | 27.97 |
| 19.37 | 22.65 | 25.27 | 28.06 | 27.10 | |
| 29.14 | 24.70 | 26.15 | 29.82 | 28.90 | |
| 58.62 | 28.95 | 30.75 | 32.18 | 32.18 | |
| chrF | 10.59 | 53.23 | 55.14 | 57.19 | 57.04 |
| 19.37 | 52.24 | 54.90 | 57.05 | 56.40 | |
| 29.14 | 53.17 | 54.86 | 57.49 | 56.70 | |
| 58.62 | 55.75 | 57.26 | 57.80 | 57.90 | |
| TER | 10.59 | 32.80 | 35.91 | 41.60 | 41.24 |
| 19.37 | 33.72 | 36.77 | 42.60 | 41.31 | |
| 29.14 | 37.28 | 38.96 | 44.64 | 43.57 | |
| 58.62 | 43.48 | 45.00 | 47.17 | 47.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, J.; Kim, B. Translation Performance from the User’s Perspective of Large Language Models and Neural Machine Translation Systems. Information 2023, 14, 574. https://doi.org/10.3390/info14100574
Son J, Kim B. Translation Performance from the User’s Perspective of Large Language Models and Neural Machine Translation Systems. Information. 2023; 14(10):574. https://doi.org/10.3390/info14100574
Chicago/Turabian StyleSon, Jungha, and Boyoung Kim. 2023. "Translation Performance from the User’s Perspective of Large Language Models and Neural Machine Translation Systems" Information 14, no. 10: 574. https://doi.org/10.3390/info14100574
APA StyleSon, J., & Kim, B. (2023). Translation Performance from the User’s Perspective of Large Language Models and Neural Machine Translation Systems. Information, 14(10), 574. https://doi.org/10.3390/info14100574