1. Introduction
Usage of emerging advanced technologies such as smartphones has grown rapidly and has substantially impacted customer behaviour in online shopping, specifically during the COVID-19 pandemic. Today, online food delivery businesses are considered one of the most widespread businesses worldwide and have grown globally. It is expected that online food delivery will grow to 2.5 bn users by 2027, and it is expected that in the grocery delivery segment, the average revenue per user will be USD 449.00 in 2023 [
1]. Today, many people, especially in urban areas, do not have enough time to prepare meals for many reasons such as long working hours; hence, they often turn to online food delivery services that connect restaurants or food outlets with couriers, who then deliver the food to the customer.
Online food delivery applications are considered essential for many people nowadays. However, many of these applications experience many operational issues that reduce their efficiency. In cities, each area has a different number of food delivery orders compared with other areas. Most food delivery couriers rely on their experience to find areas with high food delivery order demands. However, sometimes they may go to areas with low demand. This issue can reduce the number of orders received by the couriers and lead to a decrease in their income in the long term and can increase the customer waiting time in a busy area as there are not enough couriers, which could reduce customer satisfaction. This is why many companies seek to improve their applications and attempt to increase the number of acquired food delivery orders to help increase the company’s and couriers’ income and reduce the waiting time for customers in busy areas in order to increase customer satisfaction.
This study introduces a method based on multi-agent reinforcement learning for online food delivery services that utilizes two multi-agent reinforcement learning algorithms. The primary objective of this method is to increase the number of received food delivery orders and increase the long-term income for the couriers. This method also helps to reduce the waiting time for customers in busy areas by guiding couriers to areas with high demand for food orders. A map of the city is split into small grids, each grid represents a small city area, and the agent has to learn to locate the area with high food delivery order demands. This approach enables couriers to find areas with high demand for food delivery orders so that the couriers get more orders, which helps them to increase their long-term income.
While enhancing online food delivery services is important and provides numerous benefits for many people, protecting customer information in online food delivery services is crucial. There are some privacy concerns about leaking sensitive information to users, such as customer location information for online food delivery services. Thousands of food delivery orders are received each day by these platforms, with vast amounts of information collected from the users. These data may be hosted by a third party and may be further processed for training and analysis purposes. Also, the IT department may be operated by a third party. Various access authorities are granted access to different types of data, which allows illegal access to customer data. Furthermore, adversaries can employ various attacks, such as inference attacks, and be able to infer some private information that could pose a serious threat to disclosing customer information, such as the customer’s location.
To tackle this issue, a defence method has been proposed to protect the customer’s location. The proposed method, called the ’Protect User Location Method’ (PULM), aims to maintain the privacy of the customer’s location in online food delivery services. This method uses differential privacy (DP) and the Laplace mechanism by injecting Laplace noise into the customer’s location and the courier’s trajectory. The privacy parameter that affects the amount of injected noise depends on two parameters: the city area size and the frequency of customers’ online food delivery orders. In small cities, the adversary has a higher opportunity to identify the customer’s location due to the small area and fewer number of routes, which makes it easier for the adversary to find the location of the user, whereas it could be more difficult in large cities due to the large geographical area and increased number of roads. Also, when there are a number of food delivery requests from the same customer, the adversary may be able to link the records of the same customer and obtain the customer’s private information. Therefore, we inject more noise into the records requested from small cities and for customers with a high number of records of online food delivery orders.
The main contributions of this research are the following:
- (i)
We propose a method that aims to improve the efficiency of online food delivery applications by guiding the courier to areas with high demand in order to increase income in the long term.
- (ii)
We consider weekdays and weekends as a factor in the agent’s learning process to gain better results as the number of orders can vary on weekdays vs. weekends.
- (iii)
To show more results and comparisons, this research employs two multi-agent reinforcement learning methods, QMIX and IQL, which aim to increase the number of received orders by couriers and raise long-term income.
- (iv)
We use two datasets with different city sizes and different geographic areas to present more results.
- (v)
We invent a privacy method called the ’Protect User Location Method’ (PULM). This method uses the city area size and customer frequency of online food delivery orders to determine the privacy parameter.
- (vi)
We employ differential privacy (DP) by injecting Laplace noise to preserve the customer’s location along with the courier’s trajectory.
Author Contributions
Conceptualization, Suleiman. Abahussein and D.Y.; methodology, C.Z., Z.C. and S.S.; software, S.A.; U.S.; validation, D.Y. and S.A.; formal analysis, S.A; investigation, S.A.; resources, S.A.; data curation, S.A.; writing—original draft preparation, S.A.; writing—review and editing, S.A. and D.Y.; visualization, S.A. and D.Y.; supervision, C.Z. and D.Y.; project administration, C.Z. and D.Y.; funding acquisition, C.Z. and D.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
We already mentioned the source of data and we cite the source in Datasets section.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MARL | Multi-agent reinforcement learning |
| DRL | Deep reinforcement learning |
| DQN | Deep Q-network |
| IQL | Independent Q-learning |
| PULM | Protect User Location Method |
| DP | Differential privacy |
References
- Statista. Online Food Delivery—Worldwide. Available online: https://www.statista.com/outlook/dmo/online-food-delivery/worldwide?currency=usd (accessed on 30 August 2023).
- Chen, X.; Ulmer, M.W.; Thomas, B.W. Deep Q-learning for same-day delivery with vehicles and drones. Eur. J. Oper. Res. 2022, 298, 939–952. [Google Scholar] [CrossRef]
- Liu, S.; Jiang, H.; Chen, S.; Ye, J.; He, R.; Sun, Z. Integrating Dijkstra’s algorithm into deep inverse reinforcement learning for food delivery route planning. Transp. Res. Part Logist. Transp. Rev. 2020, 142, 102070. [Google Scholar] [CrossRef]
- Xing, E.; Cai, B. Delivery route optimization based on deep reinforcement learning. In Proceedings of the 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 23–25 October 2020; pp. 334–338. [Google Scholar]
- Ding, Y.; Guo, B.; Zheng, L.; Lu, M.; Zhang, D.; Wang, S.; Son, S.H.; He, T. A City-Wide Crowdsourcing Delivery System with Reinforcement Learning. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, Virtual, 24–28 October 2021; Volume 5, pp. 1–22. [Google Scholar]
- Bozanta, A.; Cevik, M.; Kavaklioglu, C.; Kavuk, E.M.; Tosun, A.; Sonuc, S.B.; Duranel, A.; Basar, A. Courier routing and assignment for food delivery service using reinforcement learning. Comput. Ind. Eng. 2022, 164, 107871. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Bozanta, A.; Cevik, M.; Kavuk, E.M.; Tosun, A.; Sonuc, S.B.; Kosucu, B.; Başar, A. A deep reinforcement learning approach for the meal delivery problem. Knowl.-Based Syst. 2022, 243, 108489. [Google Scholar] [CrossRef]
- Zou, G.; Tang, J.; Yilmaz, L.; Kong, X. Online food ordering delivery strategies based on deep reinforcement learning. Appl. Intell. 2022, 52, 6853–6865. [Google Scholar] [CrossRef]
- Hu, S.; Guo, B.; Wang, S.; Zhou, X. Effective cross-region courier-displacement for instant delivery via reinforcement learning. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications, Nanjing, China, 25–27 June 2021; pp. 288–300. [Google Scholar]
- Zhao, X.; Pi, D.; Chen, J. Novel trajectory privacy-preserving method based on clustering using differential privacy. Expert Syst. Appl. 2020, 149, 113241. [Google Scholar] [CrossRef]
- Zhang, L.; Jin, C.; Huang, H.P.; Fu, X.; Wang, R.C. A trajectory privacy preserving scheme in the CANNQ service for IoT. Sensors 2019, 19, 2190. [Google Scholar] [CrossRef]
- Tu, Z.; Zhao, K.; Xu, F.; Li, Y.; Su, L.; Jin, D. Protecting Trajectory From Semantic Attack Considering k -Anonymity, l -Diversity, and t -Closeness. IEEE Trans. Netw. Serv. Manag. 2018, 16, 264–278. [Google Scholar] [CrossRef]
- Chiba, T.; Sei, Y.; Tahara, Y.; Ohsuga, A. Trajectory anonymization: Balancing usefulness about position information and timestamp. In Proceedings of the 2019 10th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Canary Islands, Spain, 24–26 June 2019; pp. 1–6. [Google Scholar]
- Zhou, K.; Wang, J. Trajectory protection scheme based on fog computing and K-anonymity in IoT. In Proceedings of the 2019 20th Asia-Pacific Network Operations and Management Symposium (APNOMS), Matsue, Japan, 18–20 September 2019; pp. 1–6. [Google Scholar]
- Zhou, S.; Liu, C.; Ye, D.; Zhu, T.; Zhou, W.; Yu, P.S. Adversarial attacks and defenses in deep learning: From a perspective of cybersecurity. Acm Comput. Surv. 2022, 55, 1–39. [Google Scholar] [CrossRef]
- Andrés, M.E.; Bordenabe, N.E.; Chatzikokolakis, K.; Palamidessi, C. Geo-indistinguishability: Differential privacy for location-based systems. In Proceedings of the Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; pp. 901–914. [Google Scholar]
- Deldar, F.; Abadi, M. PLDP-TD: Personalized-location differentially private data analysis on trajectory databases. Pervasive Mob. Comput. 2018, 49, 1–22. [Google Scholar] [CrossRef]
- Yang, M.; Zhu, T.; Xiang, Y.; Zhou, W. Density-based location preservation for mobile crowdsensing with differential privacy. IEEE Access 2018, 6, 14779–14789. [Google Scholar] [CrossRef]
- Yang, Y.; Ban, X.; Huang, X.; Shan, C. A Dueling-Double-Deep Q-Network Controller for Magnetic Levitation Ball System. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 1885–1890. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1995–2003. [Google Scholar]
- Lapan, M. Deep Reinforcement Learning Hands-On, 2nd ed.; Packt Publishing Ltd.: Birmingham, UK, 2020. [Google Scholar]
- Sewak, M. Deep Reinforcement Learning; Springer: Singapore, 2019. [Google Scholar]
- Cheng, Z.; Ye, D.; Zhu, T.; Zhou, W.; Yu, P.S.; Zhu, C. Multi-agent reinforcement learning via knowledge transfer with differentially private noise. Int. J. Intell. Syst. 2022, 37, 799–828. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Wan, Y.; Lewis, F.L.; Cansever, D. Handbook of Reinforcement Learning and Control; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Ye, D.; Zhang, M.; Sutanto, D. Cloning, resource exchange, and relationadaptation: An integrative self-organisation mechanism in a distributed agent network. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 887–897. [Google Scholar]
- Ye, D.; Zhu, T.; Cheng, Z.; Zhou, W.; Yu, P.S. Differential advising in multiagent reinforcement learning. IEEE Trans. Cybern. 2020, 52, 5508–5521. [Google Scholar] [CrossRef] [PubMed]
- Rashid, T.; Samvelyan, M.; Schroeder de Witt, C.; Farquhar, G.; Foerster, J.N.; Whiteson, S. Monotonic value function factorisation for deep multi-agent reinforcement learning. J. Mach. Learn. Res. 2020, 21, 7234–7284. [Google Scholar]
- Zhang, X.; Zhao, C.; Liao, F.; Li, X.; Du, Y. Online parking assignment in an environment of partially connected vehicles: A multi-agent deep reinforcement learning approach. Transp. Res. Part Emerg. Technol. 2022, 138, 103624. [Google Scholar] [CrossRef]
- Yun, W.J.; Jung, S.; Kim, J.; Kim, J.H. Distributed deep reinforcement learning for autonomous aerial eVTOL mobility in drone taxi applications. ICT Express 2021, 7, 1–4. [Google Scholar] [CrossRef]
- Tampuu, A.; Matiisen, T.; Kodelja, D.; Kuzovkin, I.; Korjus, K.; Aru, J.; Aru, J.; Vicente, R. Multiagent cooperation and competition with deep reinforcement learning. PloS ONE 2017, 12, e0172395. [Google Scholar] [CrossRef]
- Rehman, H.M.R.U.; On, B.W.; Ningombam, D.D.; Yi, S.; Choi, G.S. QSOD: Hybrid policy gradient for deep multi-agent reinforcement learning. IEEE Access 2021, 9, 129728–129741. [Google Scholar] [CrossRef]
- Du, Y.; Han, L.; Fang, M.; Liu, J.; Dai, T.; Tao, D. Liir: Learning individual intrinsic reward in multi-agent reinforcement learning. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Chen, R.; Fung, B.; Desai, B.C. Differentially private trajectory data publication. arXiv 2011, arXiv:1112.2020. [Google Scholar]
- Ma, P.; Wang, Z.; Zhang, L.; Wang, R.; Zou, X.; Yang, T. Differentially Private Reinforcement Learning. In Proceedings of the International Conference on Information and Communications Security, London, UK, 11–15 November 2019; pp. 668–683. [Google Scholar]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our data, ourselves: Privacy via distributed noise generation. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, 28 May–1 June 2006; pp. 486–503. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Theory of Cryptography Conference, New York, NY, USA, 4–7 March 2006; pp. 265–284. [Google Scholar]
- Zhu, T.; Li, G.; Zhou, W.; Philip, S.Y. Differentially private data publishing and analysis: A survey. IEEE Trans. Knowl. Data Eng. 2017, 29, 1619–1638. [Google Scholar] [CrossRef]
- Zhu, T.; Philip, S.Y. Applying differential privacy mechanism in artificial intelligence. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 1601–1609. [Google Scholar]
- Zhu, T.; Ye, D.; Wang, W.; Zhou, W.; Philip, S.Y. More than privacy: Applying differential privacy in key areas of artificial intelligence. IEEE Trans. Knowl. Data Eng. 2020, 34, 2824–2843. [Google Scholar] [CrossRef]
- Assam, R.; Hassani, M.; Seidl, T. Differential private trajectory protection of moving objects. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on GeoStreaming, Redondo Beach, CA, USA, 6 November 2012; pp. 68–77. [Google Scholar]
- Tokyo’s History, Geography and Population. Available online: https://www.metro.tokyo.lg.jp/ENGLISH/ABOUT/HISTORY/history03.htm (accessed on 30 August 2023).
- U.S. Census Bureau Quickfacts: United States. Available online: https://www.census.gov/quickfacts/fact/table/US/PST045221 (accessed on 30 August 2023).
- Baker, C. City & Town Classification of Constituencies & Local Authorities. Brief. Pap. 2018, 8322. [Google Scholar]
- Liu, D.; Chen, N. Satellite monitoring of urban land change in the middle Yangtze River Basin urban agglomeration, China between 2000 and 2016. Remote Sens. 2017, 9, 1086. [Google Scholar] [CrossRef]
- Li, M.; Zhu, L.; Zhang, Z.; Xu, R. Achieving differential privacy of trajectory data publishing in participatory sensing. Inf. Sci. 2017, 400, 1–13. [Google Scholar] [CrossRef]
- Ulmer, M.W.; Thomas, B.W.; Campbell, A.M.; Woyak, N. The restaurant meal delivery problem: Dynamic pickup and delivery with deadlines and random ready times. Transp. Sci. 2021, 55, 75–100. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).

 and
and 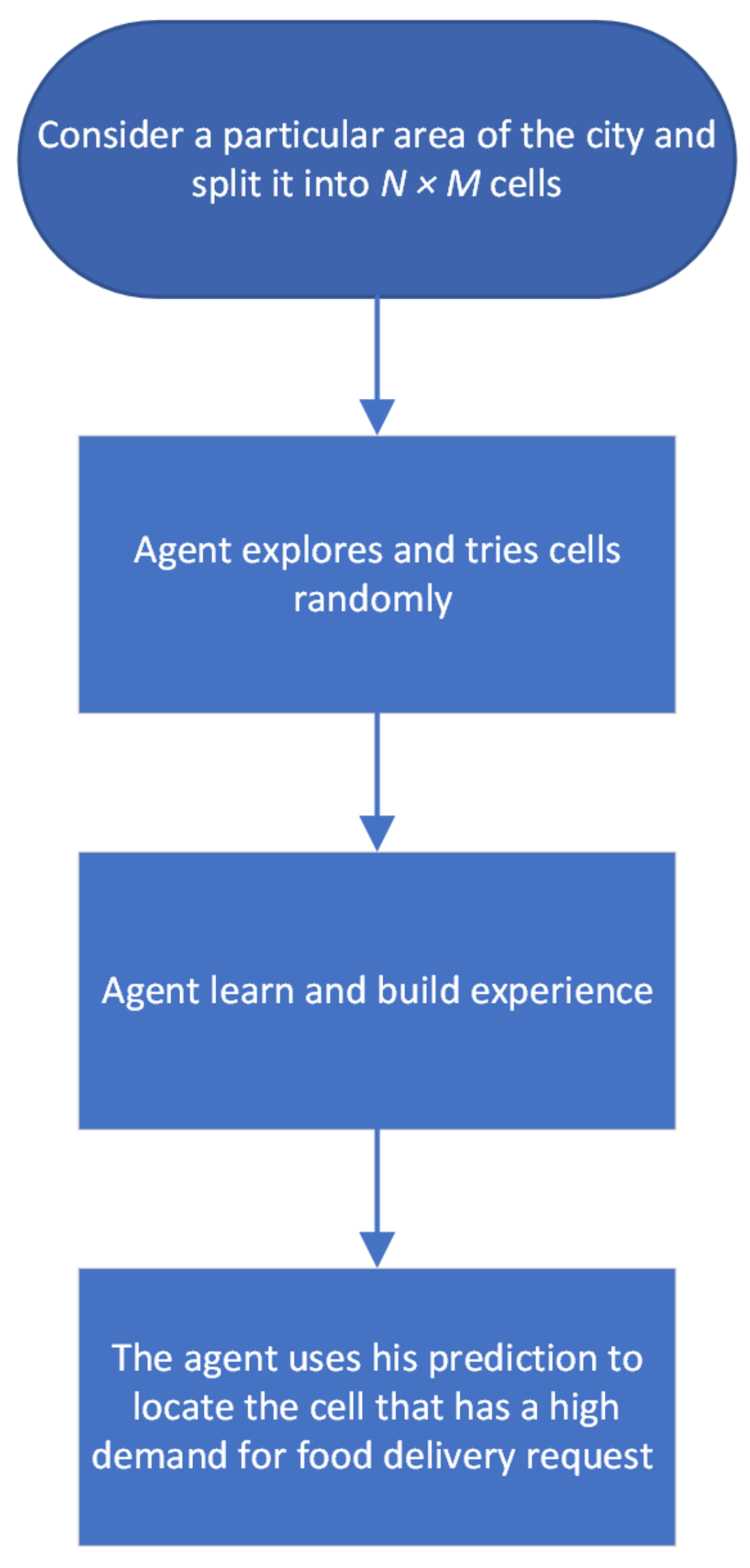










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}